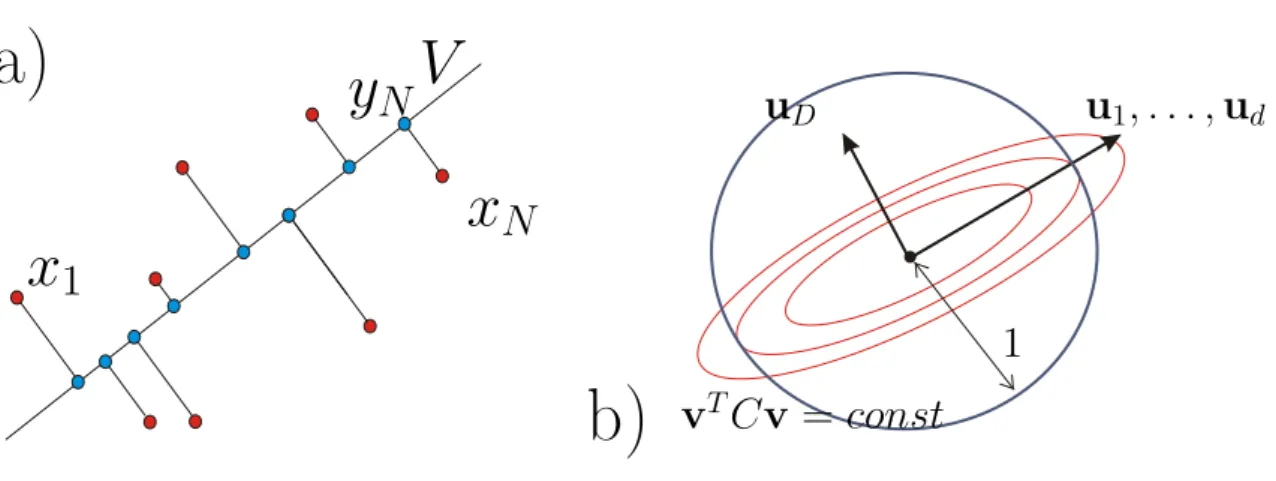
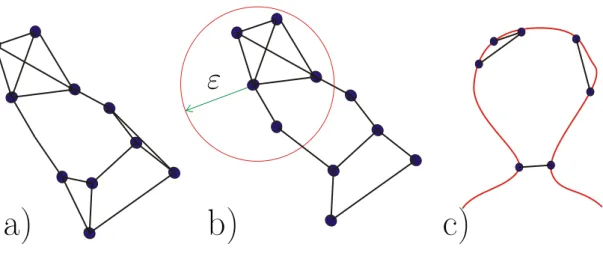
Manifold learning and applications to shape and image processing
176
0
0
Texte intégral
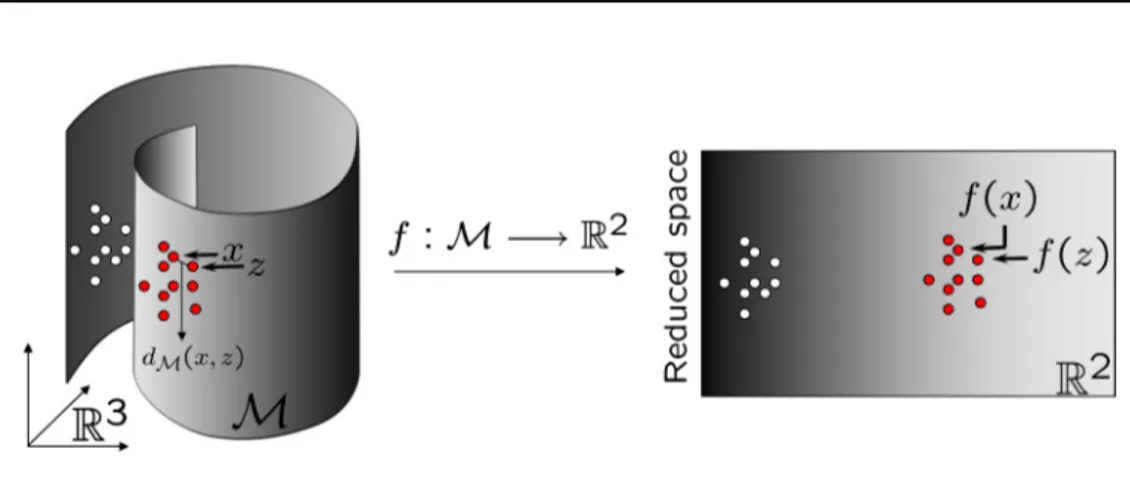
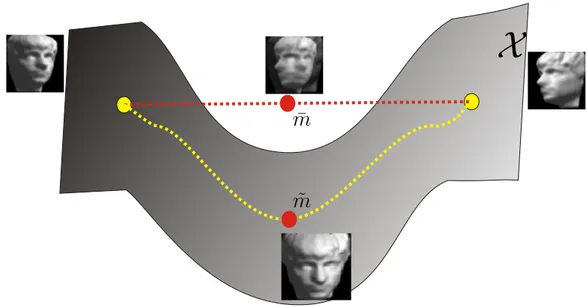
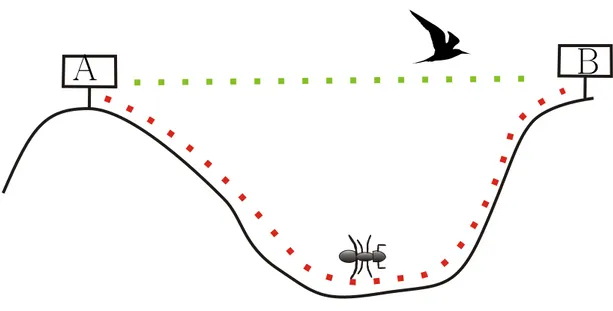
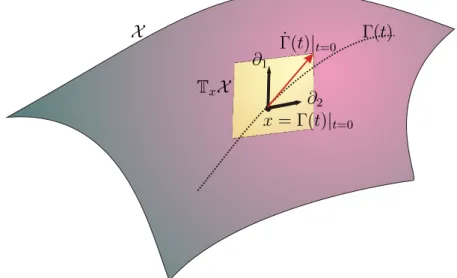
Figure

+7



Documents relatifs