UNIVERSITÉ MOHAMMED V – AGDAL
FACULTÉ DES SCIENCES
Rabat
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc
N° d’ordre : 2458
THÈSE DE DOCTORAT
Présentée par
IDBRAIM Soufiane
Discipline : Sciences de l’ingénieur
Spécialité : Informatique & Télécommunications
Titre :
Méthodes d’extraction de l'information spatiale et de classification
en imagerie de télédétection : Applications à la cartographie
thématique de la région d’Agadir (Maroc)
Soutenue le 16 juillet 2009. Devant le jury
Président :
Pr. Driss ABOUTAJDINE Professeur à la Faculté des Sciences de Rabat
Examinateurs :
M. Lhoussain MASMOUDI Professeur à la Faculté des Sciences de Rabat
M. Christian Puech Professeur Habilité CEMAGREF – ENGREF, Montpellier, France M. Aziz EL FAZZI Professeur à la Faculté des Sciences SEMLALIA de Marrakech M. Yannick Deville Professeur à l'université Paul Sabatier de Toulouse, France
Mme. Danielle DUCROT Professeur Habilité à l'université Paul Sabatier de Toulouse, France M. Driss MAMMASS Professeur à la Faculté des Sciences d’Agadir
Avant propos
Le travail de thèse dans ce mémoire a été effectué dans le cadre d’une co-tutelle entre le laboratoire LRIT (Laboratoire de Recherche en Informatique et Télécommunications) de la Faculté des Sciences de Rabat sous la direction du Professeur Driss ABOUTAJDINE et le centre français CESBIO (Centre d'Etudes Spatiales de la BIOsphère) sous la direction du Professeur Danielle DUCROT.
Je tiens en particulier à exprimer ma plus sincère gratitude à mes directeurs de thèse, Professeur Driss ABOUTAJDINE et Professeur Danielle DUCROT pour avoir accepté de diriger mes recherches, et pour m’avoir apporté leur expertise avec la plus grande disponibilité tout au long de cette thèse. Cette co-direction a donné lieu à des échanges riches, à des confrontations de points de vue différents, et c'est réellement de la synthèse de ces points de vue que sont nées les idées et les méthodes développées dans ce mémoire. Je leur suis profondément reconnaissant de la confiance qu'ils m'ont accordé en autorisant mes recherches à prendre cette orientation variée.
Je remercie Monsieur Aziz EL FAZZIK Professeur à la Faculté des Sciences SEMLALIA de Marrakech pour m’avoir fait l’honneur d’être rapporteur de ma thèse et Monsieur Christian Puech Professeur Habilité Chargé de recherches au Laboratoire Commun de Télédétection CEMAGREF – ENGREF, Maison de la télédétection à Montpellier pour avoir apporté son point de vue sur cette thèse en acceptant d'en être rapporteur
Je voudrais exprimer ma profonde reconnaissance envers mon co-directeur Monsieur Driss MAMMASS Professeur et Responsable du laboratoire IRF-SIC, à la Faculté des Sciences d’Agadir pour toute l’attention et le soutien qu’il m’a porté pendant ces années de thèse.
Je tiens à remercier Monsieur Lhoussain MASMOUDI Professeur à la Faculté des Sciences de Rabat pour avoir accepté de participer au jury de cette thèse et Monsieur Yannick Deville Professeur à l'université Paul Sabatier de Toulouse pour avoir accepté le rôle d’examinateur et d’avoir fait le déplacement malgré son temps chargé.
Je voudrais enfin remercier tous ceux qui m'ont entourée durant ces années de thèse. Les personnes du CESBIO avec qui j'ai eu l'occasion de travailler ou d'échanger des idées, permanents, postdoc, thésards ou stagiaires, pour l’ambiance très chaleureuse qu’ils ont su créer; les collègues et amis du LRIT et IRF-SIC à qui je souhaite beaucoup de bien.
Résumé
Les travaux de cette thèse s’articulent autour de deux axes : la classification pour la cartographie de l’occupation du sol et l’extraction du réseau routier à partir des images satellitaires et aériennes.
Le premier axe a pour objectif de proposer une méthode de classification visant à prendre en compte le contexte spatial de l’information contenue dans une image satellitaire. Ainsi, nous avons développé une méthode de classification markovienne, avec recherche de la solution optimale par l’algorithme d’ICM (Iterated Conditional Mode). Cette méthode est paramétrée par un facteur de température qui va permettre, premièrement, de régler la tolérance des configurations désavantageuses dans le processus d’évolution de la classification, et deuxièmement, d’assurer la convergence de l’algorithme en un temps de calcul raisonnable. Parallèlement, nous avons introduit une nouvelle contrainte contextuelle de segmentation dans l’algorithme. Cette contrainte va permettre au fil des itérations d’affiner la classification en accentuant les détails détectés par les contours de segmentation.
Le second axe de cette thèse est l’extraction du réseau routier à partir des images satellitaires et aériennes. Nous avons proposé une méthodologie complètement automatique à travers un système d’extraction par blocs qui agissent séparément et indépendamment sur l’image, le premier bloc opère un filtrage directionnel adaptatif, permettant ainsi de détecter les routes dans chaque fenêtre de l’image selon les directions dominantes. Quant au deuxième, il applique une segmentation, puis, il sélectionne les segments représentant des routes selon un critère de forme. Ces deux blocs apportent ainsi un type d’informations différent sur la scène étudiée. Ces résultats sont confrontés puis complétés dans un troisième bloc afin de générer une image du réseau routier.
Les performances des méthodologies proposées sont vérifiées à travers des exemples sur des images satellitaires et aériennes. Les résultats expérimentaux sont encourageants.
Mots clés : image de télédétection, Classification, Champs de Markov, ICM, extraction des
Abstract
The work of this thesis focuses around two axes: the classification for the mapping of land cover and the extraction of roads from satellite and aerial images.
The first axis aims to propose a method of classification which takes in account the spatial information contained in a satellite image. Thus, we developed a method of Markov classification with the search for the optimal solution by an ICM (Iterated Conditional Mode) algorithm. This method is parameterized by a new factor of temperature, this parameter will allow, first, to rule the tolerance of the disadvantageous configurations during the evolution of the classification process, and secondly, to ensure the convergence of the algorithm in a reasonable time of calculation. In parallel, we introduced a new contextual constraint of the segmentation in the algorithm. This constraint will allow, over the iterations, to refine the classification by accentuating the detected details by the segmentation contours.
The second axis of this thesis is the extraction of roads from satellite and aerial images. We proposed a completely automatic methodology with an extraction system in blocks which act separately and independently on the image. The first block operates a directional adaptive filtering, allowing detecting roads in each window of the image according to the dominant directions. The second one applies segmentation, and then selects the segments representing roads according to a criterion of the segment form. These two blocks provide a different type of information on the studied image. These results are then complemented with a third block to generate an image of the road network.
The performances of the proposed methodologies are verified through examples of satellite and aerial images. In general, the experimental results are encouraging.
Key words: Remote sensing image, Classification, Markov Random Fields, ICM, road
Sommaire
Sommaire
... 1Introduction
... 5Partie I
... 9Classification contextuelle
... 9 Chapitre 1... 11Classification non contextuelle en imagerie de télédétection ... 11
1.1 Introduction ... 12
1.2 Les catégories des classifications... 12
1.3 Classification par minimisation de distance... 13
1.3.1 Méthodes non itératives ... 13
1.3.1.1 Classification par la méthode du parallélépipède... 13
1.3.1.2 Classification par la méthode barycentrique ou K plus proches voisins ... 14
1.3.1.3 Classification selon la distance de Mahalanobis ... 16
1.3.2 Méthodes itératives ... 17
1.3.2.1 Classification par Kmeans... 18
1.3.2.2 Classification par ISODATA ... 18
1.4 Machines à Support Vecteurs... 19
1.4.1 Principe de base des SVM... 20
1.4.2 Cas non linéairement séparable... 21
1.5 Classification par réseaux de neurones ... 22
1.6 Classification statistique non contextuelle : maximum de vraisemblance... 24
1.7 Conclusion... 26
Chapitre 2... 27
Le contexte spatial dans la classification : utilisation des champs de Markov... 27
2.1. Introduction ... 28
2.2 Un Modèle markovien général d’images ... 28
2.2.1 Description de l'image... 28
2.2.2 Modélisation Markovienne de l'image ... 30
2.2.3 Champs de Markov - Champs de Gibbs... 30
2.2.3.1 Définition d'un champ de Markov... 30
2.2.3.2 Equivalence entre champs de Markov et champs de Gibbs ... 30
2.2.4 Echantillonnage de MRF... 32
2.2.4.1 L'échantillonneur de Gibbs... 32
2.2.4.2 L'algorithme de Metropolis ... 33
2.2.5 Recherche de la configuration la plus probable ... 34
2.2.5.1 Distribution de Gibbs avec température... 34
2.2.5.2 Algorithme du recuit simulé... 35
2.2.5.3 Algorithme des modes conditionnels itérés (ICM) ... 36
2.2.6 Quelques MRF fondamentaux ... 37
2.2.6.1 Modèle d'lsing ... 37
2.2.6.2 Modèle de Potts... 38
2.2.6.3 Modèle markovien gaussien... 40
2.3.1 Règle de Bayes ... 40
2.3.2 La classification... 41
2.4 Estimateurs dans un cadre markovien... 44
2.4.1 Modélisation bayésienne et fonction de coût ... 44
2.4.2 Maximum A Posteriori (MAP) ... 44
2.4.3 Mode à posteriori des marginales (MPM)... 45
2.5 Quelques travaux concernant la classification des images satellitaires par MRF... 46
Chapitre 3... 49
Méthode contextuelle et validation des résultats... 49
3.1 Introduction ... 50
3.2 La méthode ICM avec contraintes contextuelles ... 50
3.2.1 La solution MAP ... 50
3.2.2 Minimisation de l’énergie par l’ICM ... 51
3.2.3 Introduction des contraintes ... 52
3.2.3.1 Contrainte de régularisation ... 53
3.2.3.2 Contrainte de contour (segmentation) ... 53
3.2.3.3 Paramètre de température... 58
3.2.3.4 L’algorithme général ... 62
3.3 Validation de la méthode et résultats ... 63
3.3.1 Présentation des scènes d’étude et des images... 63
3.3.1.1 Les images Landsat - région de Souss ... 63
3.3.1.2 Les images Formosat – région toulousaine - Est de Marrakech (Maroc) ... 65
3.3.1.3 Critère d’évaluation... 65
3.3.2 Contrôle de la régularisation ... 67
3.3.3 Le paramètre de température... 69
3.3.4 Comparaison avec la classification non contextuelle... 71
3.3.5 Utilisation de la contrainte de segmentation ... 73
3.4 Conclusion... 76
Partie II
... 79Extraction automatique des routes
... 79Chapitre 4... 81
Etat de l’art sur l’extraction des routes ... 81
4.1 Introduction ... 82
4.2 Variabilité des réseaux routiers ... 82
4.2.1 Variabilité intrinsèque et extrinsèque des routes... 82
4.2.2 Variabilité typologique par rapport à l'environnement ... 82
4.2.3 Variabilité due au mode d'acquisition ... 83
4.2.3.1 L'angle de prise de vue... 83
4.2.3.2 La résolution spatiale et spectrale du capteur... 84
4.3 Méthodes semi-automatiques... 85
4.3.1 Méthodes de suivi et filtrage ... 85
4.3.2 Contours Actifs ... 86
4.3.3 Programmation dynamique ... 87
4.4 Méthodes automatiques... 87
4.4.1 Méthodes de segmentation et de classification ... 87
4.4.2 Morphologique mathématique ... 88
4.4.3 Détecteurs de lignes ... 89
4.4.4 Champs de Markov sur graphe... 89
4.4.5 Méthodes fondées sur l’analyse multi-échelle (multi-résolution)... 89
4.4.7 Apport de données cartographiques ... 91
4.5 Conclusion... 91
Chapitre 5... 93
Extraction semi-automatique des routes par contour actif... 93
5.1 Introduction ... 94
5.2 Principe du suivi par contour actif ... 94
5.2.1 Modélisation et énergie ... 94
5.2.2 Contrôle de la rigidité et l’élasticité du contour actif... 96
5.2.3 Évolution temporelle du contour actif... 98
5.3 Application du contour actif pour l’extraction des routes... 99
5.3.1 Paramètres d’initialisation... 99
5.3.2 Résultats expérimentales ... 100
5.4 Conclusion... 103
Chapitre 6... 104
Une nouvelle méthode d’extraction automatique des routes ... 104
6.1 Introduction ... 105
6.2 Vue globale de la méthodologie d’extraction ... 105
6.2.1 Schéma général ... 105
6.2.2 Prétraitement ... 106
6.3 Description des blocs de la méthodologie... 107
6.3.1 Bloc de filtrage directionnel adaptatif... 107
6.3.2 Bloc de segmentation ... 110
6.3.2.1 Filtrage Shen-Castan ... 110
6.3.2.2 Segmentation par Ligne de Partage des Eaux (LPE : watersheds) ... 111
6.3.3 Intégration et liaison... 113
6.3.3.1 Intégration des résultats des blocs de filtrage et de segmentation... 113
6.3.3.2 Liaison des segments routes... 113
6.4 Résultats et évaluations ... 114
6.4.1 Critère d’évaluation... 114
6.4.2 Evaluation des résultats... 115
6.5 Conclusion... 117
Conclusion... 119
Liste des publications et communications
... 123Bibliographie... 125
Annexes
... 133A. Présentation des données satellitaires FORMOSAT-2 et LANDSAT... 135
B. Segmentation par ligne de partage des eaux ... 139
Introduction
Contexte
On s’accorde à considérer que la télédétection a apporté une véritable révolution pour la connaissance et le suivi de la surface du sol. Le besoin en cartes fiables et actualisées est grandissant, le flux des images de télédétection est croissant, les systèmes d’information géographique (SIG) ont connu une évolution extrêmement rapide au cours de la dernière décennie. Ainsi, il devient nécessaire de développer des outils automatiques performants d'analyse de toutes ces données, et particulièrement les images.
L'interprétation des images de télédétection constitue pour les photo-interprètes un outil très important, et parfois indispensable, pour optimiser le temps passé sur le terrain tout en améliorant d'une façon très sensible la précision du document cartographique final. Jusqu'à l'avènement de l'image numérique, le photo-interprète identifiait sur les photos aériennes, plus tard, spatiales. Les thèmes d'intérêt, déterminait leur contour et, généralement, reproduisait les résultats de son analyse sur une carte sous forme d'unités spatiales ponctuelles, linéaires ou zonales. Ce processus est lent et coûteux, et par conséquent ne permet pas de répondre à la demande. Un besoin urgent d’automatiser la photo-interprétation sollicitant des techniques de compréhension d’images par ordinateur s’est avéré indispensable.
De nombreuses méthodes ont été développées pour répondre aux différents problèmes d’interprétation et d'extraction de l’information à partir d'images de satellites et aériennes, notamment dans les cas particuliers : de l’occupation du sol, de la détection et l’extraction d'objets surfaciques ou linéiques tel que les réseaux routiers.
Objectif
Dans cette thèse, nous considérons les deux principaux problèmes cités ci-dessus : le premier est lié à la cartographie de l’occupation du sol, le deuxième concerne l’extraction des routes à partir de l’imagerie satellitaire. Ce travail de thèse est organisé suivants deux objectifs principaux :
− le développement d’une méthode robuste, permettant d’effectuer la classification d’images de télédétection de façon contextuelle non supervisée ;
− la mise en oeuvre d’une méthode complètement automatique permettant de répondre à la problématique de l’extraction des routes ;
Ce premier objectif du travail de recherche consiste à proposer une méthode de classification non supervisée, sans aucune connaissance a priori de l’utilisateur. Dans cette étude, nous profitons de l’intérêt de traiter l’image contextuellement à travers une modélisation par champs de Markov. Cette méthode se distingue bien des méthodes classiques par la prise en compte des interactions locales entre chaque pixel et ses pixels voisins pour définir les différentes régions de l'image. Egalement, elle se caractérise par sa
faculté d’introduire, de manière souple, des contraintes du contexte spatial grâce à leur modélisation par des fonctions potentielles. Nous avons introduit, en supplément d’une contrainte de régularisation, une contrainte de segmentation afin d’affiner la classification. Ces contraintes contextuelles sont contrôlées par un nouveau paramètre de température dans un algorithme d’optimisation itératif ICM (Iterated Conditional Mode).
Dans le deuxième axe de la thèse, nous nous situons dans la catégorie d'approche, qui se propose de fournir une extraction complètement automatique du réseau routier. Ainsi, l’intervention d’un opérateur extérieur pour contrôler, corriger ou initialiser l’extraction, est réduite ; et la plupart des informations nécessaires au processus d’extraction sont obtenues directement de l’image. Dans le cas des méthodes semi-automatiques, l’initialisation s’effectue de telle sorte que les points de départ soient proches de la route à extraire, donc, les fausses détections sont exclues et c’est la précision de détection que l’on cherche à améliorer. Dans notre cas, automatique, la qualité de l'extraction se mesure alors en terme d'exhaustivité et de limitation des fausses détections et non en terme de précision. Un exemple de ces méthodes « modèle contour actif » fait partie des méthodes implémentées dans les travaux de cette thèse.
Afin d’obtenir le plus d’informations représentant les routes de l’image, nous proposons un système d’extraction avec deux blocs parallèles qui agissent séparément et indépendamment sur l’image, le premier bloc opère un filtrage directionnel adaptatif, permettant ainsi de détecter les routes dans chaque fenêtre de l’image selon la direction prédominante, ou bien les directions dominantes, s’il y en a plusieurs. Quant au deuxième, il applique une segmentation, puis, il sélectionne les segments représentant des routes selon un critère de forme. Ces deux approches apportent ainsi un type d’informations différent sur la scène étudiée. Les deux résultats peuvent, alors, se compléter pour remplir au mieux la mission de détection des routes.
Organisation du manuscrit
Ce document est divisé en deux parties. La première partie concerne la classification non contextuelle pour une élaboration de la carte d’occupation du sol. Elle est organisée comme suit :
− Nous dressons, au chapitre 1, un panorama des méthodes de classification non contextuelles des images de satellites. Nous constatons que ces approches n'exploitent pas le deuxième niveau d'information contenu dans une image c'est-à-dire, le contexte spatial du pixel, qui joue un rôle important dans la classification de l’occupation du sol, étant donné l’homogénéité des classes parcellaires.
− Dans le chapitre 2, nous décrivons le « background » du formalisme Markovien sur le quel se base une classification contextuelle, puis, nous présentons quelques modèles de cet aspect contextuel, ainsi que leurs avantages et leurs inconvénients. Nous terminons avec un état d’art des travaux liés à l’imagerie satellitaire.
− Le chapitre 3 présente le principe détaillé de la méthode de classification développée, puis, expose les résultats des applications sur deux types d’images de satellites et des évaluations et comparaisons des résultats.
La deuxième partie est consacrée à l’extraction des routes. Elle est organisée de la façon suivante :
− Le chapitre 4 présente en premier lieu, une description des caractéristiques principales des réseaux routiers et de leur variabilité dans les images satellitaires et aériennes, puis, il expose un état de l’art sur l'extraction de réseaux routiers.
− Dans le chapitre 5, nous décrivons de manière plus précise une technique semi-automatique d’extraction des routes appelée contour actif. Nous présentons son implémentation et son évaluation.
− Enfin, le chapitre 6 concerne l’extraction automatique des routes. Dans ce chapitre, nous présentons la méthodologie développée en décrivant en détails ces différentes étapes, et à la fin nous évaluons ces performances en utilisant des données de référence.
Cadre de la thèse
Cette thèse réalisée en cotutelle est le fruit d’une coopération franco-marocaine entre le LRIT-Faculté des Sciences-Université Mohammed V Agdal, le CESBIO-Université Paul Sabatier et le IRF-SIC -Faculté des Sciences-Université Ibn Zohr.
Partie I
Chapitre 1
Classification non contextuelle en imagerie de
télédétection
Sommaire
1.1 Introduction ... 12
1.2 Les catégories des classifications... 12
1.3 Classification par minimisation de distance... 13
1.3.1 Méthodes non itératives ... 13
1.3.1.1 Classification par la méthode du parallélépipède... 13
1.3.1.2 Classification par la méthode barycentrique ou k plus proches voisins... 14
1.3.1.3 Classification selon la distance de Mahalanobis... 16
1.3.2 Méthodes itératives ... 17
1.3.2.1 Classification par Kmeans... 18
1.3.2.2 Classification par ISODATA... 18
1.4 Machines à Support Vecteurs... 19
1.4.1 Principe de base des SVM... 20
1.4.2 Cas non linéairement séparable... 21
1.5 Classification par réseaux de neurones ... 22
1.6 Classification statistique non contextuelle : maximum de vraisemblance... 24
1.1 Introduction
L’objectif du traitement d’images de satellite est d’en extraire le maximum d’information qui intéresse le futur utilisateur de l’image, et d’évacuer tout ce qui est superflu.
Un but réaliste est la classification thématique de ces images.
Le processus de classification est souvent rapproché de celui de la segmentation, mais les différences entre les deux sont grandes : le but de la segmentation est d’opérer une partition de l’image en zones connexes homogènes sans aucune sémantique, alors que celui de la classification est de déterminer, pour chaque pixel ou groupe de pixels de l’image à traiter, la classe de référence à laquelle il appartient, c’est-à-dire dans le cas des images de télédétection, c’est la partition de l’image en ensembles de pixels représentant une même occupation du sol.
Dans ce chapitre, on s’intéresse aux méthodes de classification non contextuelles. Les méthodes de classification conventionnelles sont décrites dans une première étape dans l’ordre : la classification supervisée et la classification non supervisée. Une attention particulière est accordée ensuite à deux méthodes de classification apparues plus récemment en traitement d’images de télédétection : la classification basée sur les Machines à Support Vecteurs (SVM) et la classification par réseaux neuronaux. En dernier lieu, nous présentons un exemple de méthode de classification statistique très utilisée : celle du maximum de vraisemblance.
1.2 Les catégories des classifications
Une première partition des méthodes de classification peut être faite, entre les méthodes dites de classification supervisées et les méthodes non supervisées. Dans le premier cas l’algorithme nécessite l’intervention d’un utilisateur à un (ou plusieurs) stade(s) (le cas le plus fréquent étant l’apport d’échantillons d’apprentissage), alors que dans le second cas, aucune intervention n’est nécessaire.
La classification est un problème souvent étudié en télédétection, et il existe diverses façons d’effectuer cette opération. On distingue principalement dans le cas non contextuel deux catégories : les méthodes paramétriques dites approches de classification statistiques et les méthodes non paramétriques.
Un classifieur est dit paramétrique s'il associe à la signature spectrale une distribution statistique connue, le plus fréquemment pour le traitement d'images, la loi normale ou multinormale. Cette association offre la possibilité d'affecter à chaque pixel une probabilité d'appartenance à une classe donnée. Un classifieur probabiliste est donc généralement paramétrique. L'algorithme le plus connu de cette catégorie est celui du maximum de vraisemblance.
Un classifieur non paramétrique se définit alors en négatif de la première catégorie. Aucune distribution statistique paramétrique n'est exploitée; seule la distance spectrale est prise en compte. Cette catégorie comprend notamment : les méthodes fondées sur la minimisation de distance (hyperboîte ou parallélépipédique, la distance minimale et la distance de Mahalanobis, K plus proches voisins, Kmeans, ISODATA, etc), ainsi, de
nouvelles méthodes apparues récemment s’ajoutent à cette catégorie comme les réseaux neuronaux et les Machines à Support Vecteurs (SVM).
1.3 Classification par minimisation de distance
Le principe des méthodes reposant sur la minimisation de distance consiste à chercher la classe la plus proche pour chaque pixel, ou groupe de pixels si l’on travaille dans une fenêtre d’analyse centrée sur le pixel courant. La notion de proximité est liée à la distance considérée. Ces méthodes sont très simples et souvent utilisées, mais ne sont pas robustes au bruit car elles ne comportent pas le terme de régularisation.
1.3.1 Méthodes non itératives
1.3.1.1 Classification par la méthode du parallélépipède
Cette méthode est basée sur une logique booléenne. Des données d’entraînement dans d bandes spectrales sont utilisées pour effectuer la classification. Pour chaque classeλ, on calcule le vecteur µλ =
(
µλ1 L µλd)
où µλk représente le niveau de gris moyen des pixels de la classe λ dans la bande k.k
λ
σ est l’écart type des données d’entraînement de la classe λ dans la bande k. Si on utilise un seuil égal à σλk par exemple, l’algorithme du parallélépipède affecte un pixel de vecteur de mesures X
(
xij ... xijd)
1
=
λ à la classeλ, si et seulement si l’équation suivante est
satisfaite : k x k k k k k − λ ij λ + λ ,∀ λ σ µ σ µ p p (1.1)
{
dk = 1...
}
représente le nombre de bandes et est la luminance du pixel (i,j) dans la bande k. Par conséquent, si les frontières de décision inférieure et supérieure sont définies park ij x k k k
Lλ =µλ −σλ et Hλk =µλk +σλk respectivement, la règle de décision du parallélépipède devient : k H x L k k k ij λ ,∀ λ p p (1.2)
Ces règles de décision forment un parallélépipède multidimensionnel dans l’espace des caractéristiques. Si la valeur du pixel est comprise entre la borne inférieure et la borne supérieure pour les d bandes évaluées pour une classe donnée, il est affecté à cette classe, et dans le cas contraire il est affecté à une catégorie non classée.
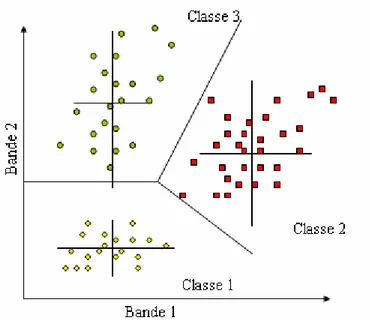
On prend garde que les classes ne se recoupent pas au moins dans une bande spectrale. Les seuls paramètres pris en compte sont le minimum et le maximum de luminance par classe et par bande spectrale. La figure 1.1 illustre le cas à deux dimensions.
Figure 1.1 Méthode parallélépipédique
Pour des dimensions supérieures à deux, on peut répéter l'opération par couple de bandes spectrales. Dans la pratique, la séparation des classes n'est pas aussi aisée qu'il parait dans la situation construite de la figure précédente. On doit généralement admettre des zones de superposition des signatures spectrales.
1.3.1.2 Classification par la méthode barycentrique ou K plus proches voisins
Cet algorithme [Cover et Hart, 1967], communément utilisé pour la classification des données de télédétection [Lee et al, 1990] se base sur la distance euclidienne simple. À partir des zones d'échantillonnage, les moyennes (centre de gravité) µi de chaque classe sont calculées. Il consiste à parcourir l’image et à déterminer la classe la plus proche parmi les K possibles. En chaque site s de valeur xs, nous calculons les K distances aux différentes classes.
Le pixel est affecté à la classe la plus proche, c'est-à-dire la plus proche de son centre de gravité. Autrement dit, l’étiquette k associée à la classe λkest attribuée au site s selon la formule :
(
s i)
...Kd x ar k g min ,λ 1 i= = (1.3) avec(
,) (
)
2 i s i s x x d λ = −µ (1.4) c’est-à-dire(
x)
d(
x)
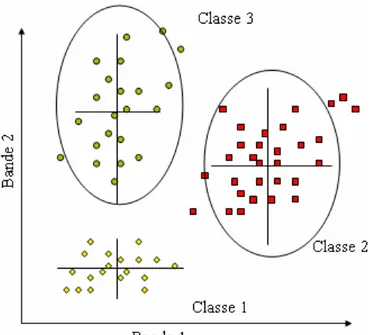
i j d xs∈λisi s,λi p s,λj pour tout ≠ (1.5)Sans fixer des limites à chacune des classes ou de critères d'appartenance, cet algorithme partage l'espace spectral en polygones de Thiessen ou de Voronoï, comme l'illustre la figure 1.2. Tout point de l'espace est rattaché au centre de classe le plus proche à l'exception des points situés sur les lignes de séparation., La totalité de l'image sera classée sous le nombre de signatures introduites.
Figure 1.2 Partition de l'espace selon la méthode barycentrique ou distance minimale
Cette forme de division n'est évidemment pas réaliste, car un pixel très éloigné du centre de classe est probablement fort dissemblant de la classe à laquelle il est censé appartenir. Il est donc nécessaire de fixer un seuil, une distance limite au-delà de laquelle le pixel n'est plus classé.
Si le seuil est posé indépendamment des bandes spectrales, il forme, dans un espace formé par deux bandes, une circonférence centrée sur le pixel moyen et de rayon égal à la distance limite admise. L'espace spectral est découpé alors tel qu'il apparaît sur la figure 1.3.
Figure 1.3 Partition de l'espace selon la méthode barycentrique avec un seuil de classe uniforme pour toutes les
bandes spectrales
Le modèle du cercle pour circonscrire une classe dans l'espace spectral s'avère simpliste, dans la mesure où il ne tient pas compte de la dynamique propre à chaque bande. Une amélioration est apportée en .fixant un seuil, en unité d'écart type, spécifique à chaque bande. La limite de classe devient alors une ellipse dont les axes sont parallèles à ceux des bandes spectrales, comme représenté à la figure 1.4.
Figure 1.4 Partition de l'espace selon la méthode barycentrique avec limite de classe spécifique à chaque bande
spectrale
Malgré une nette amélioration, on observe que l'orientation des axes ne coïncide pas encore avec celle de la distribution de certaines classes (classe 2, particulièrement), Cette méthode est une étape intermédiaire qui conduit en douceur à la distance de Mahalanobis.
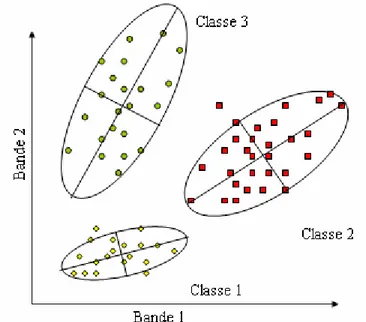
1.3.1.3 Classification selon la distance de Mahalanobis
Ce classifieur recourt à la distance euclidienne généralisée. Le poids accordé à chacun des éléments du calcul de la distance est posé égal à l'inverse des variances et des covariances. La distance dite de Mahalanobis s'écrit alors, sous forme matricielle
(
,) (
= −)
∑
−1(
− i s i t i s i s x x x d λ µ µ)
(1.6)Notons que la distance de Mahalanobis est similaire à la distance euclidienne calculée dans l'espace des variables décorrelées des luminances et ce, pour chaque classe prise séparément. La limite de classe est fixée en unité d'écart type pour chaque classe séparément. La figure 1.5 schématise la partition de l'espace spectral par classe selon le classifieur Mahalanobis.
Figure 1.5 limite de classe selon une classification basée sur la distance de Mahalanobis
Il existe autres distances possibles (voir [Basseville, 1985][Fukunaga, 1972][Kittler, 1975] par exemple)
− La distance de Bhattacharyya permet de mesurer la distance entre deux lois de distribution selon la formule
(
)
(
)
i s i s s s i s i s B m m m m x d σ σ σ µ λ 2 log 2 1 4 1 , 2 + + + − = (1.7)La classe λiétant définie par sa moyenne µiet son écart-typeσi, ms et σssont
respectivement la moyenne et l’écart type calculés dans le site s.
− La distance de Kullback dans le cas gaussien s’exprime de la façon ci-dessous, elle retourne la distance entre deux lois de probabilité
(
)
(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − + + + − = 2 2 1 2 1 , 2 s i i s s s i s i s K m m m m x d µ µ σ µ λ (1.8)L’article [Basseville, 1985] passe en revue un grand nombre de distances permettant de déterminer en chaque pixel la classe la plus proche et d’attribuer ainsi l’étiquette correspondante.
1.3.2 Méthodes itératives
Nous présentons ici deux algorithmes très utilisés dans les logiciels de traitement d’images de télédétection, connus sous les noms de Kmeans (ou K moyennes) [MacQueen, 1967] et ISODATA [Ball et Hall, 1965].
1.3.2.1 Classification par Kmeans
Cette méthode est supervisée dans le sens où le nombre de classes doit être donné, mais pas nécessairement leurs paramètres. Son algorithme est le suivant.
- Initialisation des paramètres µi0et σi0pour i=1...K
- Répéter n← n−1tant que le critère d’arrêt n’est pas vérifié en chaque site s calculer :
(
n)
i s ...K n ar d x k g min ,λ 1 i= =pour i=1...Krecalculer µinet σinde chaque classe λni test sur le critère d’arrêt
Lorsque les paramètres des classes ne sont pas connus, l’étape d’initialisation peut se résumer à sélectionner K sites de l’image pour initialiser les valeurs de , et prendre . Puis, on effectue des itérations jusqu’à convergence de l’algorithme. A chaque itération, on balaye l’image en attribuant une étiquette par minimisation de distance. Il s’agit en général de la distance euclidienne, mais d’autres distances peuvent être choisies, notamment pour prendre en compte les écart-types des classes. Une fois les étiquettes attribuées, on calcule les nouvelles valeurs et pour les K classes trouvées à l’itération n : 0 i µ i i0 =1.0,∀ σ n i µ n i σ
( )
∑
∈ = n i s x s n i n i x card λ λ µ 1 (1.9)( ) (
∑
∈)
− = n i s x n i s n i n i x card λ λ µ σ 1 2. (1.10)On réitère ces opérations jusqu’à ce que le critère d’arrêt soit vérifié. Le critère d’arrêt peut porter sur le nombre relatif de sites dont l’étiquette a changé entre deux étapes, ou sur la variation relative des paramètres µinet σin entre les étapes n et n+1.
1.3.2.2 Classification par ISODATA
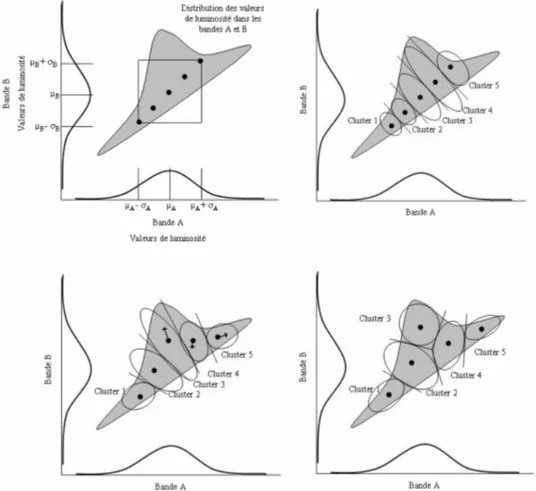
C’est une version améliorée de l’algorithme Kmeans, cet algorithme, nommé “Iterative Self-Organizing Data Analysis Technics” ISODATA [Ball et Hall, 1965], autorise, au cours des itérations, la fusion entre de nuages proches, la division d’un nuage à variance élevée et la suppression de nuage de petite taille.
L’utilisateur doit spécifier donc les paramètres suivants :
− Le nombre minimum de membres dans un segment nmin. Si un segment contient
moins de membres que le minimum spécifié, il est supprimé et ses membres sont affectés à un autre segment
− L’écart type maximumσmax. Lorsque l’écart type d’un segment dépasse le maximum spécifié, et que le nombre de membres dans le segment est deux fois
supérieur au minimum de membres spécifiés dans une classe, le segment est éclaté en deux segments.
− La distance minimum entre les segments dmin. Des segments ayant une distance
pondérée inférieure à cette valeur sont fusionnés.
Après l’initialisation, le nouveau vecteur moyen de chaque segment ms est calculé sur la
base des valeurs spectrales actuelles des pixels affectés à chaque segment. Ceci implique l’analyse des paramètres suivants : nmin, σmax et dmin. Ensuite, le processus complet est réitéré
avec chaque pixel candidat, une fois de plus comparé aux nouveaux vecteurs moyens de segments et affecté au segment le plus proche. Ce processus itératif continue jusqu’à ce que l’on ait un petit changement dans l’affectation des classes entre les itérations, ou que le nombre maximum d’itérations soit atteint.
Figure 1.6 l’initialisation et la variation du centre de gravité des classes au cours des itérations de l’ISODATA
1.4 Machines à Support Vecteurs
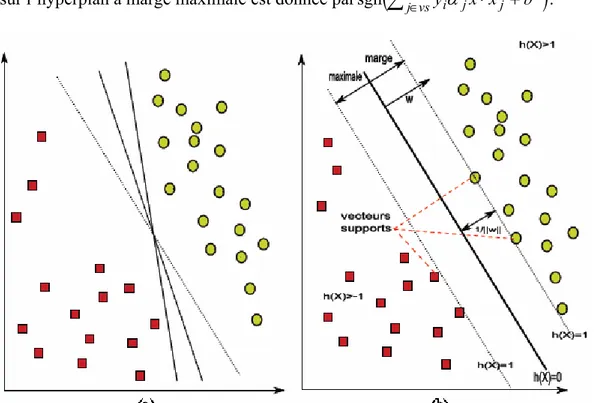
La classification par Support Vector Machines est une autre méthode non paramétrique récente [Vapnik, 1998]. Elle consiste à résoudre un problème de classification binaire en plaçant un hyperplan dans l’espace des données comme frontière de décision de manière à ce que :
− cet hyperplan maximise le taux de bonne classification des échantillons d’apprentissage,
Ce plan est alors défini par une combinaison des échantillons les plus proches de ce plan, qui sont appelés les vecteurs supports. Cette approche est intéressante, puisque l’optimisation est supposée maximiser directement la classification, mais ses développements concernent principalement le problème à deux classes. Néanmoins, les résultats sont satisfaisants, comme le montre certaines applications sur des images de télédétection [Huang et al, 2002] [Melgani et Bruzzone, 2004] [Roli et Fumera, 2001] [Zhang et al, 2001]
1.4.1 Principe de base des SVM
Initialement les approches SVM ont été proposées pour rechercher la séparation optimale entre deux classes. Un problème de classification en deux classes peut s’énoncer de la façon suivante : Soit X un ensemble de N exemples d’apprentissage dont chaque élément est représenté par une paire
(
x ,ri yi)
aveci=1...N, yi un label de classe pouvant prendre la valeur+1 ou −1 et un vecteur de dimensionxri k
(
xi∈ℜk)
. L’objectif du classifieur est de déterminer, à l’aide de ces données d’apprentissage, une fonction de décision f( )
x,α → y(avecαparamètres du classifieur) et de l’utiliser ensuite pour classifier de nouvelles données. Dans le cas d’un classifieur linéaire, la fonction f peut être définie à l’aide d’un hyperplan d’équation wr⋅X +b=0(où et b désignent les paramètres de l’hyperplan soit respectivement un vecteur normal au plan et le biais). La classification d’un vecteur
wr
i xr est alors donnée par le signe de la fonction f,sgn
[
fwr,b( )
rxi]
, c’est-à-dire yi =+1 si( )
[
]
0sgn fwr,b xri > ouyi =−1 si sgn
[
fwr,b( )
xri]
<0.Le principe des approches SVM est de trouver l’hyperplan optimal parmi l’ensemble des hyperplans possibles (figure 1.7-a) permettant de classifier correctement les données (i.e. les données des classes de label +1 et −1 se trouvent de chaque côté de l’hyperplan) mais également tel que sa distance aux vecteurs (exemple d’apprentissage) les plus proches soit maximale (i.e. le plus loin possible de tous les exemples). Les vecteurs les plus proches sont alors dénommés "vecteurs supports" et la distance constitue la marge optimale.
Les vecteurs supports sont situés sur deux hyperplans parallèles (H1 et H2) à l’hyperplan optimal d’équation wr⋅X +b=0et ont pour équation respective wr⋅X +b=−1et (figure 1.7-b). Aucun exemple d’apprentissage ne devant être situé dans la marge, ils satisfont les équations suivantes :
1 + = + ⋅X b wr N i y b x w y b x w i i i i ,..., 1 1 si 1 , 1 si 1 = ∀ − = − ≤ + ⋅ + = + ≥ + ⋅ r r r r (1.11) Ces contraintes peuvent être regroupées en une seule inégalité suivante :yi
(
wr⋅xri +b)
−1≥0.Ainsi, la marge est au moins égale à la distance entre les deux hyperplans H1 et H2 soit wr 2
, où wr fait référence à la norme du vecteur wr . Maximiser cette marge revient donc à minimiser wr sous la contrainte que l’hyperplan reste séparateur c’est-à-dire
(on retrouve ici la justification de l’appellation de "séparateur à vaste marge").
(
w x b)
i NOn peut ainsi montrer, en utilisant des méthodes d’optimisation adaptées (principe de dualité et multiplicateurs de Lagrange), que le vecteur wr réalisant l’optimum peut s’écrire ∗ sous la forme . Les sont les multiplicateurs de Lagrange déterminés et sont non nuls uniquement pour les points
i i N i i y x wr∗ =
∑
=1α∗ r αi∗ ixr se trouvant exactement "sur la marge" c’est-à-dire les vecteurs supports.
Le calcul de s’effectue soit en prenant un i particulier (un exemple d’apprentissage) soit en calculant la moyenne de tous les obtenus pour chaque vecteur support.
∗
b
∗
b
Soit vs=
{
j∈{
1,2,...,l}
telqueα∗j ≠0}
l’ensemble des indices des vecteurs supports. Une fois les paramètres α∗et b∗calculés, la règle de classification d’une nouvelle observation xr basée sur l’hyperplan à marge maximale est donnée parsgn(
∑
j∈vsyiα∗jxr⋅xrj +b∗)
.Figure 1.7 Principe des SVM : (a) Recherche de l’hyperplan optimal ; (b) Hyperplan optimal, marge et vecteurs
supports
1.4.2 Cas non linéairement séparable
Cependant, dans de nombreux cas, les échantillons d’entraînement ne sont pas linéairement séparables. La procédure consiste alors à introduire une fonction Φ permettant de projeter les données dans un espace de dimension supérieure (D) où elles deviennent linéairement séparables (voir figure 1.8) :
( )
x x d D D d r r →→Φℜ >> ℜ avec (1.12)Figure 1.8 Représentation de l’astuce du noyau (Trick Kernel)
De la même façon que précédemment, on recherche dans ce nouvel espace, l’hyperplan optimal donné cette fois par :
( )
∗( )
∗∗ x =w ⋅Φ x +b
f r r r (1.13)
avec wv∗ =
∑
in=1αiyiΦ( )
xri soit f∗( )
xr =∑
in=1αiyiΦ( ) ( )
xri ⋅Φ xr +b∗. (1.14) Une observation importante est que la seule connaissance des produits scalaires entre points est suffisante pour trouver et calculer la fonction .On n’a donc pas besoin de trouver une représentation∗
f
( )
xrΦ explicitement. Il suffit d’être capable de calculer
( )
xri ⋅Φ( ) (
xrj =k xri,xrj)
Φ . Le terme k
(
xr ,i xrj)
est appelé noyau. Vapnik [Vapnik, 1998] a montré que toute fonction satisfaisant les conditions (symétrique, définie positive) peut être utilisée comme noyau. Parmi les noyaux les plus classiquement utilisés pour la classification des images de télédétection, on trouve, le noyau gaussien ou noyau RBF (pour Radial Basis Function)( )
⎟⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − = 2 2 2 exp , σ y x y x k (1.15)ou encore le noyau polynomial [Gualtieri et Chettri, 2000] [Huang et al, 2002] [Camps-Valls et al., 2006].
( ) (
x y x y)
pk , = ⋅ +1 (1.16)
1.5 Classification par réseaux de neurones
Les classifieurs neuronaux offrent d'emblée un intérêt d'ordre pratique. Contrairement aux classifieurs précédents, ils n'exigent pas que la signature spectrale extraite des zones d'entraînement s'ajuste à une distribution statistique paramétrisable. Les paramètres du système neuronal s'adaptent progressivement aux propriétés de la signature, au fur et à mesure qu'on lui fournit des exemples connus, c'est-à-dire des pixels des zones d'entraînement et la catégorie thématique associée. Ils ne se basent sur aucune considération de propriétés physiques reliant une zone d'entraînement à sa catégorie thématique. Après la phase d'apprentissage, le système agit en « boîte noire»: à un pixel d'entrée correspond une catégorie en sortie. Aussi, les performances d'un tel système ne se jugent qu'en termes d'efficacité et de robustesse, ce dernier terme étant pris dans son sens statistique. Les réseaux neuronaux sont donc des classifieurs non paramétriques d'autant plus robustes que la distribution des pixels d'apprentissage n'est pas normale [Lippmann, 1987]
Le modèle de réseau de neurones le plus communément utilisé pour la classification d'images en télédétection est le perceptron multicouche, entraîné avec l'algorithme de rétro-propagation [Rumelhart et al, 1986].
Le perceptron multicouche comprend une couche d'entrée et de sortie, mais entre les deux s'intercalent une ou plusieurs couches appelées couches cachées. L'architecture d'un perceptron à trois couches présentée à la figure 1.9 propose une seule couche cachée située entre celle d'entrée et de sortie.
Figure 1.9 Perceptron à trois couches
Le nombre de paramètres internes ajustables croît avec le nombre de couches et de neurones par couche. L'exemple d'un réseau à trois couches met en évidence cette propriété. La couche d'entrée dispose de i possibilités, la couche cachée, de q neurones et la couche de sortie, de k neurones. Chaque entrée est connectée à tous les neurones et chaque neurone est connecté à tous ses suivants. Le nombre de poids à ajuster est donc dei× j×k. Prenons le cas d'une configuration adaptée à une classification d'une image TM de Landsat (six entrées) en 10 classes. En supposant que la couche cachée dispose de huit neurones, le système contiendra 480 paramètres d'ajustement.
La fonction du perceptron est de faire correspondre à un vecteur d'entrée x, un vecteur de sortie y. Les composantes du vecteur d'entrée sont les luminances ou d'autres variables dont dépendent les classes affectées aux sorties ; en règle générale, les entrées sont normalisées de sorte que ses valeurs soient comprises entre 0 et 1. Le vecteur de sortie représente les classes spectrales ou thématiques dans le sens d'une classification supervisée.
L'entrée nette d'une unité dans un perceptron multicouche est une somme pondérée des sorties des unités de la couche précédente selon l’équation
∑
=i ij i j w o
Cette somme pondérée est ensuite transformée par la fonction d'activation de l'unité (habituellement une fonction sigmoïde) pour produire la sortie de l'unité selon les équations suivantes.
(
j)
j net o 2 exp 1 1 β − + = [Tangente exponentielle] (1.18)(
j)
j neto =tanh β [Tangente hyperbolique] (1.19)
Dans les deux expressions précédentes, β est une constante réelle déterminant la pente de la fonction à l'origine. Les poids sont ajustés pendant l'apprentissage en utilisant la règle du delta généralisée.
(
n)
( )
o w( )
nwij + = j i + ∆ ij
∆ 1 ηδ α (1.20)
(
+1∆wij n
)
est la correction du poids de la connexion reliant les nœuds i et j à la (n + 1) ème itération. δ est le taux de changement d'erreur par rapport à la sortie de l'unité j. η est le taux j d'apprentissage et αest le terme d'inertie.La correspondance attendue entre entrée et sortie ne pouvant être absolue, le perceptron se comporte comme approximateur. Le lecteur intéressé trouvera plus de détails sur les algorithmes utilisés pour la procédure de rétropropagation de l'erreur et leur démonstration dans [Caloz et Collet, 2001].
1.6 Classification statistique non contextuelle : maximum de vraisemblance
Les méthodes statistiques consistent à déterminer des frontières de décision partitionnant l’espace des pixels en différentes zones étiquetées grâce aux échantillons d’apprentissage. La détermination des frontières de décision est faite à travers une modélisation probabiliste des pixels, et les notions de distances associées à ces modélisations. Ensuite, la classification peut se faire simplement pour chaque pixel en considérant la zone à laquelle il appartient, ou par des méthodes plus complexes impliquant le contexte de chaque pixel, à travers des champs de Markov (Chapitre 2), ce qui permet une prise en compte du contexte spatial pour aboutir à des classifications plus régulières.
Dans ce paragraphe on s’intéresse au cas non contextuel, une méthode très courante (que nous décrivons) est la classification par maximum de vraisemblance, avec modélisation gaussienne.
Notations
Une image est constituée d’un ensemble S de si ou pixels. Soit Λl’ensemble des classes
parmi lesquelles on choisit les étiquettes de chaque pixel. Une classe sera notéeλ. L’espace des états est noté E, sa dimension est égale au nombre de critères sélectionnés.
Soit ys le vecteur de E associé au site s de l’image S.
Soient ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ = S s s y y y ,..., 1 , ⎟⎠ ⎞ ⎜ ⎝ ⎛ = S s s x x x ,...,
1 xs la classe dans Λ attribuée à s.
X X Y
Ecriture du problème
Sous l’hypothèse gaussienne de la loi de probabilité P
(
ys /xs =λi)
et l’hypothèse d’indépendance conditionnelle des probabilités (détaillées ultérieurement dans Chapitre 2), nous cherchons à déterminer la meilleure classification des pixels de l’image, . Pour cela, on dispose de l’état global de l’image, y, et on cherche à déterminer :opt x
(
X x Y y)
P x xopt =argmax = / = (1.21)
(
) (
)
(
Y y)
P x X P x X y Y P x xopt =argmax = / == = (1.22)
(
Y y X x) (
P X x)
P x
x
opt =argmax = / = = (1.23)
En supposant que l’on ne dispose d’aucune information a priori sur les probabilités relatives d’occurrence des classes, P
(
Xs =λ)
est constant, pour tout s et toutλ.(
Y y X x)
P x
x
opt =argmax = / = (1.24)
(
)
∏
= = = s s s s s x opt PY y X x x argmax / (1.25)Le problème global est donc ramené à un problème d’optimisation local, grâce à l’hypothèse d’indépendance conditionnelle des pixels.
(
s s s s)
x opt s PY y X x x s = = =argmax / (1.26)Et sous l’hypothèse gaussienne, on obtient l’équation suivante :
(
)
[ ]
(
)
( ) ( )
12 2 1 2 det 2 1 exp max arg d i i s i t i s opt s y y x i π µ µ λ ∑ ⋅ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛− − ∑ − = − Λ ∈ (1.27)où d est la dimension de l’espace des états (nombre de bandes spectrales), soit le nombre de critères choisis. Pour des raisons pratiques, on préférera calculer le logarithme de l’expression ci-dessus.
(
)
[ ]
(
)
( )
(
s i t i s i i)
opt s y y x i ∑ + − ∑ − = − Λ ∈ logdet min arg µ 1 µ λ (1.28)Comme dans le cas du classifieur de Mahalanobis, les surfaces de décision du maximum de vraisemblance sont des hyperellipsoïdes dans l'espace spectral.
1.7 Conclusion
Toutes les méthodes de classification décrites dans ce chapitre regroupent les pixels sous le seul critère de la ressemblance spectrale estimée par la distance euclidienne simple, généralisée ou autre. Les réseaux neuronaux ne dérogent pas à ce principe dans la mesure où les poids sont accordés aux seules luminances du pixel. De même pour SVM, où on résout le problème de classification binaire en plaçant un hyperplan dans l’espace spectral des données comme frontière de décision. Ces approches n'exploitent donc pas le deuxième niveau d'information contenu dans une image : soit le contexte spatial du pixel qui se traduit parfois par un aspect textural.
La dimension spatiale joue pourtant un rôle prépondérant en analyse visuelle. Elle permet souvent de tracer avec une bonne précision les contours d'une zone malgré l'hétérogénéité spectrale des pixels qui la composent. L'interprète agit à la manière d'un filtre moyen ou modal en affectant un pixel isolé à la classe qui l'entoure, car la probabilité qu'il constitue à lui seul une autre classe thématique est faible. Il en est de même pour une petite région voisine ou entourée d'une classe différente. Si leur degré de similarité est proche, il est légitime de les fusionner.
De manière surprenante, la plupart des logiciels commerciaux de traitements d'images de télédétection n'offrent pas de procédures de classification contextuelles. La situation est différente dans le domaine de la recherche, où divers auteurs se sont penchées très tôt sur cette approche et que des procédures très performantes ont été proposées. Dans le cadre de ces travaux de thèse, nous nous sommes intéressés à cette catégorie de classification intégrant la contrainte spatiale en utilisant les champs de Markov.
Chapitre 2
Le contexte spatial dans la classification : utilisation des
champs de Markov
Sommaire
2.1. Introduction ... 28 2.2 Un Modèle markovien général d’images ... 28 2.2.1 Description de l'image... 28 2.2.2 Modélisation Markovienne de l'image ... 30 2.2.3 Champs de Markov - Champs de Gibbs... 30 2.2.3.1 Définition d'un champ de Markov... 30 2.2.3.2 Equivalence entre champs de Markov et champs de Gibbs ... 30 2.2.4 Echantillonnage de MRF... 32 2.2.4.1 L'échantillonneur de Gibbs... 32 2.2.4.2 L'algorithme de Metropolis ... 33 2.2.5 Recherche de la configuration la plus probable ... 34 2.2.5.1 Distribution de Gibbs avec température... 34 2.2.5.2 Algorithme du recuit simulé... 35 2.2.5.3 Algorithme des modes conditionnels itérés (ICM) ... 36 2.2.6 Quelques MRF fondamentaux ... 37 2.2.6.1 Modèle d'lsing ... 37 2.2.6.2 Modèle de Potts... 38 2.2.6.3 Modèle markovien gaussien... 40 2.3 Application dans la classification... 40 2.3.1 Règle de Bayes ... 40 2.3.2 La classification... 41 2.4 Estimateurs dans un cadre markovien... 44 2.4.1 Modélisation bayésienne et fonction de coût ... 44 2.4.2 Maximum A Posteriori (MAP) ... 44 2.4.3 Mode a posteriori des marginales (MPM)... 45 2.5 Quelques travaux concernant la classification des images satellitaires par MRF... 46
2.1. Introduction
Le chapitre précédent a permis d’évoquer le souci d’introduire l’aspect contextuel dans les approches de classification des images multi-spectrales. Dans ce contexte, nous proposons l’utilisation du formalisme Markovien (Markov random field, MRF) . L’essor des modélisations markoviennes en classification d’images date des années 80 [Kirkpatrick et al, 1982][ Geman et Geman, 1984][Besag, 1986]. Les MRF se sont bien distingués des méthodes classiquement utilisées (méthodes non contextuelles : chapitre 1) par la prise en compte des interactions locales entre chaque site (pixel) avec les pixels voisins pour définir les différentes régions de l'image.
Le modèle des MRF, qui suppose que l’image peut être représenté par un champ de Markov (processus 2D), nécessite le recours à des méthodes itératives du type de l’échantillonneur de Gibbs pour estimer la loi du champ ; de plus, le calcul des solutions bayésiennes n’étant pas explicite, ces dernières sont approchées grâce à des estimateurs (MAP, MPM,…) et à la mise en oeuvre des algorithmes itératifs type recuit simulé et ICM.
Dans ce chapitre, nous introduisons tout d'abord de façon intuitive la notion d'énergie locale avant de définir plus formellement un champ de Markov et d'énoncer le théorème d'équivalence entre champs de Markov et champs de Gibbs. Les algorithmes d'échantillonnage d'un champ de Markov et de calcul des configurations les plus probables sont ensuite présentés, ainsi que les modèles markoviens les plus courants. L'utilisation des champs markoviens dans la classification est ensuite décrite. A la fin, nous abordons deux exemples d’estimateurs (MAP et MPM).
Ce chapitre nous permettra d’appréhender les avantages et les inconvénients de chacune des méthodes évoquées, de proposer et de justifier les grandes lignes de l’approche de classification présentée dans ce mémoire.
2.2 Un Modèle markovien général d’images
2.2.1 Description de l'image
L’image est représentée comme une grille rectangulaire finie bidimensionnelle de taille contenant un ensemble de sites
N n
m× = S = avec si 1<i<N appelés pixels. Á chaque site est associé un descripteur, représentant l’état du site et pouvant être un scalaire (niveau de gris, label (ou étiquette)) ou encore un vecteur (spectre), et prenant ses valeurs dans l’espace des états E.
La notion d'interactions locales nécessite de structurer les relations spatiales entre les différents sites du réseau. Pour ce faire, on munit S d'un système de voisinage ϑ défini de la façon suivante:
{ }
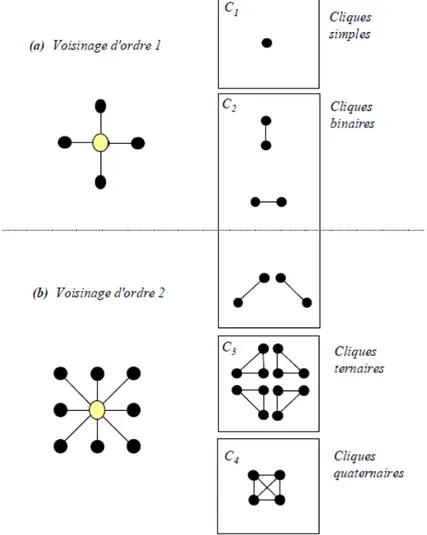
t s = ϑ tels que (2.1) ⎩ ⎨ ⎧ ∈ ⇒ ∈ ∉ t s s s t s ϑ ϑ ϑA un système de voisinage donné correspond un ensemble de cliques, une clique étant un ensemble de points du treillis mutuellement voisins, l’ordre d’une clique étant le nombre de sites
qui la compose (on s’intéresse en général aux cliques d’ordre 2). En fonction du système de
voisinage utilisé, le système de cliques sera différent et fera intervenir plus ou moins de sites comme illustré sur la figure 2.1. On notera C l'ensemble des cliques relatif àϑ, et Ck
l'ensemble des cliques de cardinal k.
Figure 2.1. Les cliques associées à deux systèmes de voisinage en dimension 2
Les interactions locales entre niveaux de gris (ou descripteurs) de sites voisins peuvent alors s'exprimer comme un potentiel de clique. Soit c une clique, on lui associe le potentiel Uc
dont la valeur dépend des niveaux de gris des pixels constituant la clique. En poursuivant ce raisonnement, on peut définir l'énergie globale de l'image comme la somme des potentiels de toutes les cliques:
∑
∈ = C c c U U (2.2)et l'énergie locale en un site comme la somme des potentiels de toutes les cliques auxquelles il appartient: .
∑
∈ ∈ = c s C c c s U U (2.3)2.2.2 Modélisation Markovienne de l'image
Dans la modélisation Markovienne, l'image est considérée comme une réalisation x d'un champ aléatoire. Soit s un site de l'image, on peut en effet lui associer une variable aléatoire (v.a) Xs prenant ses valeurs dans E. Le niveau de gris xs en s est donc une réalisation de la v.a
Xs. On définit alors le champ aléatoire X =
(
Xs,Xt,K)
prenant ses valeurs dansΩ=E S .La probabilité globale de x,P
(
X = , permet d'accéder en quelque sorte à la x)
vraisemblance de l'image et les probabilités conditionnelles locales d'une valeur en un site permettent de mesurer le lien statistique entre un niveau de gris et le reste de l'image.2.2.3 Champs de Markov - Champs de Gibbs
2.2.3.1 Définition d'un champ de Markov
Considérons Xs la valeur prise au site s et xs =
( )
xt t≠s la configuration de l'image exceptéle site s. Un champ de Markov X est un champ aléatoire si et seulement si il vérifie la propriété suivante :
(
)
(
)
(
⎩ ⎨ ⎧ ∈ = = = Ω ∈ ∀ > = s t s s s s s x x P X x x t X P x x X P ϑ , / / 0)
(2.4)Cela signifie que la probabilité en un site s conditionnellement au reste du champ est égale à la probabilité en ce site connaissant uniquement ses voisins. Ainsi, tout l’intérêt d’une modélisation Markovienne réside donc dans la possibilité de spécifier localement un modèle qui est en fait global.
Cette hypothèse markovienne se justifie bien dans le cas des images satellitaires et plus généralement dans le cas de la plupart des images naturelles constituées de zones homogènes ou texturées.
2.2.3.2 Equivalence entre champs de Markov et champs de Gibbs
La modélisation markovienne prend toute sa puissance grâce au théorème Hammersley-Clifford [Besag, 1974]. En effet, Il permet d'établir une correspondance entre un champ de
Markov et un champ de Gibbs lorsqu’aucune réalisation de X n'est de probabilité nulle. Il nous
faut au préalable définir un certain nombre de notions relatives aux mesures et champs de Gibbs.
Définition 2.1 (mesure de Gibbs).
La mesure de Gibbs de fonction d'énergie U:Ω→ℜ est la probabilité P définie sur Ω par:
(
)
1 exp(
U( )
x)
, Z x X P = = − (2.5) avec( )
∑
( )
, ∈ = C c c x U x U (2.6)où C est le système de cliques associé au système de voisinage ϑ de U. Z est une constante de normalisation sur l’ensemble des réalisations de Ω de cette fonction d’énergie, elle est appelée fonction de partition et peut être exprimée par :
( )
(
)
∑
Ω ∈ − = x x U Z exp (2.7)Nous pouvons maintenant définir le champ de Gibbs de potentiel associé au système de voisinage ϑ : c'est le champ aléatoire X dont la probabilité est une mesure de Gibbs associée au système de voisinageϑ, ce qui implique:
(
)
(
( )
)
( )
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = − = =∑
∈C c c x U Z x U Z x X P 1 exp 1 exp . (2.8)La probabilité d’une configuration dépend donc d’un ensemble d’interactions locales (au niveau des cliques). Plus l’énergie totale U(x) est grande, moins la configuration est probable.
Un résultat fondamental est l’équivalence des champs de Markov et des champs de Gibbs grâce au théorème suivant :
Le théorème de Hammersley-Clifford [Besag, 1974]
Sous les hypothèses : - S fini ou dénombrable;
- le système de voisinage ϑ est borné; - l'espace des états E est discret.
X est un champ de Markov relativement à ϑ si et seulement si X est un champ de Gibbs de potentiel associé à ϑ.
En fonction du système de voisinage, U(x) peut prendre diverses formes ; par exemple, si nous considérons un champ de Markov de voisinage 4-connexe, nous pouvons écrire l'énergie de la configuration x sous la forme :
( )
( )
(
,)
. 2 1 ( ,) ) (s C s c st Cc s t c c x x U x U x U∑
∑
∈ = ∈ = + = (2.9)où C1 et C2 sont respectivement les cliques d’ordre 1 et 2.
Si nous cherchons à écrire la probabilité conditionnelle localeP
(
xs /Xs =xs)
, nous avons grâce au résultat précédent :(
)
(
)
(
)
∑
(
(
(
(
)
)
))
∈ − − = = = = = = E x s s s s s s s s s s s x x U x x U x X P x X P x X x X P , exp , exp / (2.10)Définissons l'énergie locale Us par: