2006 — PSO pour l'apprentissage supervisé des réseaux neuronaux de type fuzzy ARTMAP
Texte intégral
Figure

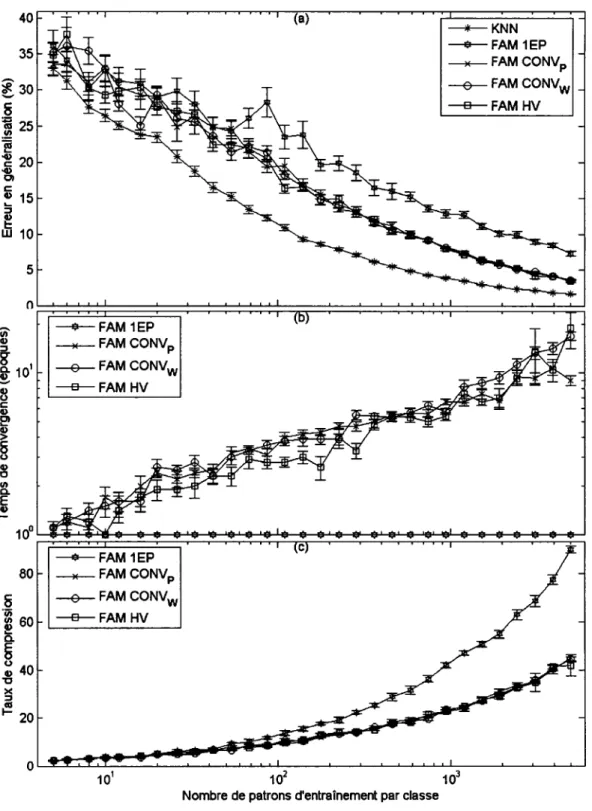



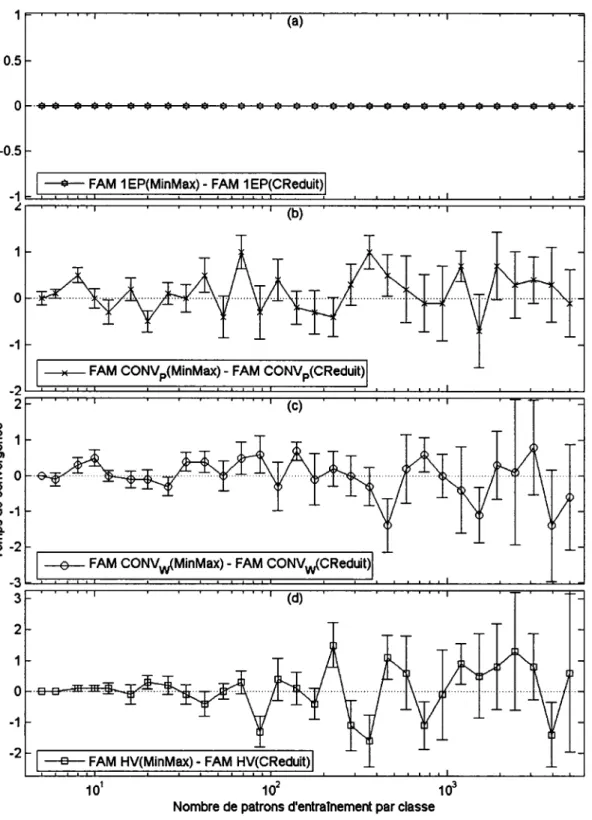

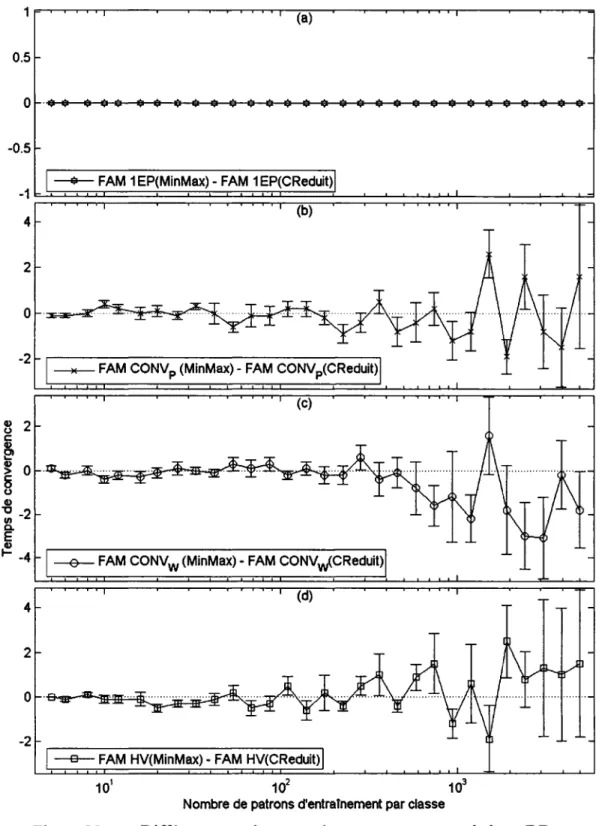


Documents relatifs
Nous avons ainsi estim´e la capacit´e maximale des r´eseaux POPI, E-POPI et POPI+, avec le format de modulation PAM 4 et 8, `a des d´ebits de 14, 28, 56 et 112 Gbit/s, pour les
D’après l’étude précédente, nous voyons bien que plus (respectivement moins) la capacité d’une classe de fonctions est grande, plus (respectivement moins) on a de
Le double obje tif que nous nous sommes xé dans ette thèse est d'une part l'adaptation des statégies d'é hantillonnage et de onstru tion de va- riables au problème des jeux
Nous reprenons le modèle I-RNN (Dinarelli & Tellier, 2016c) comme modèle de base pour concevoir des modèles profonds encore plus efficaces. Nous exploitons dans cet article
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Vu les résultats obtenus du régulateur de réseau de neurones pour le remplacement de la commande, nous pouvons dire que ce régulateur peut remplacer la commande conçue, en
Différentes dispersions de groupe: Placez 20 poitns rouges (1) dans un très petit groupe (points fortement corrélés) et 5 points bleus (0) dans un très large groupe de manière
Dans cette partie, nous avons donc présenté comment l’utilisation des matrices d’auto- similarité peut être intéressante pour l’apprentissage d’un réseau de
