HAL Id: hal-02497290
https://hal.archives-ouvertes.fr/hal-02497290
Submitted on 3 Mar 2020HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de
Sécurité. Session 2 - Sens et machine
Mohand Beddar
To cite this version:
Mohand Beddar. Approche Systémique et Contrôle Intra et Inter-langues dans le Système de Traduc-tion Automatique TACCT Contrôlée Français-Arabe Appliqué aux Protocoles de Sécurité. Session 2 - Sens et machine. Tralogy II. Trouver le sens : où sont nos manques et nos besoins respectifs ?, Jan 2013, Paris, France. 19p. �hal-02497290�
lien video : http://webcast.in2p3.fr/videos-discussion_s2
de Traduction Automatique TACCT
Contrôlée Français-Arabe Appliqué
aux Protocoles de Sécurité
Mohand Beddar
Centre Lucien Tesnière, Université de Franche-Comté mohand.beddar@univ-fcomte.fr
TRALOGY II - Session 2 Date d’intervention : 17/01/2013
Un système de traduction fiable, basé sur un formalisme simple mais efficace et sur des descriptions précises du fonctionnement des langues qu’il traite, requiert une approche microsystémique fragmentaire. Il s’agit de faire intervenir des règles d’équivalences et de transfert, non pas sur la langue dans sa totalité, mais sur des parties définies isolément. Ces parties sont ensuite mises en contact dans l’optique d’appréhender le comportement holistique de la langue objet même de cette traduction automatique. Cette méthode d’analyse permet de saisir d’une part le mode de fonctionnement de chaque microsystème et d’autre part de comprendre les rapports qu’ils entretiennent une fois mis en relation. Si la particularité de toute langue est de posséder sa propre configuration linguistique, avec des codes de fonctionnement particuliers (syntaxiques, morphosyntaxiques, sémantiques, etc.), le défi d’un système de TA quant à lui est d’effectuer un rapprochement entre toutes ces composantes via une interface linguistique adaptée au système. Cet article se propose alors d’être une mise en relief de l’approche microsystémique dans le domaine de sécurité à travers le système de traduction automatique contrôlée français-arabe TACCT.
Introduction
La construction d’un système de traduction automatique se heurte à une série de difficultés qui peuvent être rangées en deux catégories principales. Les premières sont monolingues, elles proviennent de la difficulté de modéliser avec précision les connaissances formelles de la langue source et cible. En d’autres termes, il est difficile de créer un schéma biunivoque entre représentations sémantiques et représentations syntaxiques, la langue étant un ensemble de relations rarement bijectives entre formes syntaxiques et concepts sémantiques. Les secondes sont contrastives, et concernent toute forme de divergence qu’il est nécessaire de transcender afin d’engager le processus de traduction automatique.
Il est donc nécessaire de disposer d’un modèle syntaxique et d’un modèle sémantique bien définis capables d’assurer le passage de la langue source à la langue cible. Le modèle syntaxique est chargé de représenter les structures syntaxiques abstraites de la langue, de recenser toutes les constructions que le système de traduction prendra en charge. La reconnaissance parfaite et efficace de la syntaxe d’une langue passe par la résolution des écueils de l’explosion combinatoire qui génère des ambigüités structurales et cause un temps d’analyse insoutenable. Le modèle sémantique doit être souple, permettant une représentation fine de la sémantique de chaque langue et doit être, autant que le modèle syntaxique, en parfaite harmonie avec la nature linguistique des langues en question. Autrement dit, la formalisation linguistique doit respecter les aspects langagiers de chaque langue : langue de départ et langue d’arrivée.
Une fois les deux modèles établis, il est essentiel de définir une théorie qui fera le lien entre les deux modèles syntaxique et sémantique a priori indépendant l’un de l’autre. Cette partie de modélisation est très délicate de part le rôle décisif qu’elle joue. C’est elle qui détermine la finesse du système de traduction automatique et sa qualité en termes de précision, de rapidité et d’efficacité.
L’architecture du système TACCT (Traduction Automatique Contrôlée Centre Tesnière), nous le montrerons d’ailleurs à travers cet article, puise sa force de deux principales orientations gouvernées par l’approche microsystémique : le langage contrôlé LiSe (linguistique et sécurité) et l’analyse comparative.
Les deux orientations sont complémentaires et interagissent au point qu’il est difficile de poser des frontières entre les deux. Le modèle syntactico-sémantique inhérent au système TACCT est le fruit de cette nouvelle approche bipolaire basée, d’un coté, sur l’étude des divergences entre le français et l’arabe menée sur un large corpus d’alertes et de protocoles de sécurité bilingues et, de l’autre coté, sur le contrôle approprié à ces divergences. Les deux modèles syntaxique et sémantique de chaque langue sont construits simultanément, non seulement en tenant compte du particularisme de chacune d’elles, mais aussi des spécificités émanant du contact entre les deux langues.
1. Langue contrôlée LiSe et système TACCT
La langue contrôlée LiSe dans le système TACCT est créée par le système et pour le système lui-même. Sa création répond exactement aux besoins de traduction automatique français-arabe et aux objectifs définis pendant la conception du système, à savoir l’efficacité, la précision et la rapidité. La langue contrôlée LiSe vise à augmenter la lisibilité des protocoles de sécurité et à éviter au système de traduction une panoplie d’ambigüités dues principalement à la complexité du langage humain. Elle tend à simplifier à la fois la langue de départ et la langue d’arrivée, tout en préservant leurs richesses et leurs particularités. Elle vise aussi à donner au rédacteur un outil normatif de rédaction, afin que les textes soient standardisés et conformes aux normes de lisibilité et de non ambiguïté. La langue contrôlée LiSe et le système TACCT sont indissociables. Le contenu de la langue contrôlée LiSe est le reflet de l’architecture du
système TACCT français-arabe, il correspond au travail d’analyse et de réflexion mené pour sa conception. Inversement, le mécanisme de fonctionnement du système est en rapport direct avec chaque règle de contrôle et chaque modélisation structurale. Cette interrelation s’explique par les choix stratégiques de construction et d’orientation théorique adoptés à la fois pour la langue contrôlée et pour le système de TA. Ils sont communs pour les deux applications, guidés par les aspects distinctifs de chaque langue, mais aussi par les points de convergence qu’elles manifestent.
1.1 Contrôle par analyse comparative
Le cadre général de la démarche sur le corpus est un cadre contrastif bilingue, il vise à mettre en relief par alignement des textes bilingues les zones d’entrecroisement et les zones de démarcation entre le français et l’arabe. Il s’agit d’opposer les deux systèmes linguistiques, afin de dégager les convergences et les divergences qui les caractérisent.
Cette analyse comparative, menée pour comprendre le fonctionnement des deux langues dans le domaine de sécurité, a servi de base commune pour la langue contrôlée et le système de traduction automatique. Le contrôle est effectué dans l’optique d’aplanir les divergences, ou du moins les rapprocher, pour permettre ensuite une traduction efficace et correcte des textes vers l’arabe.
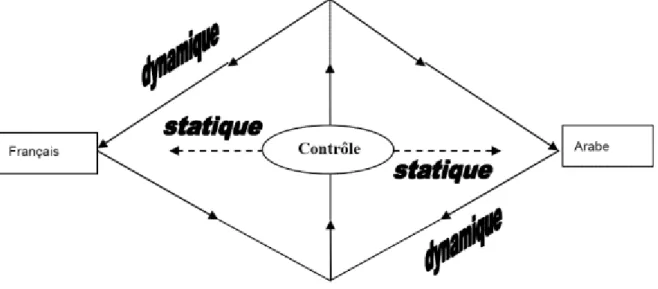
Cependant, si les visées du contrôle dans le système TACCT français arabe, effectué sur la langue, sont claires et bien définies, son processus mérite une attention particulière. Chaque contrainte linguistique qui vient renforcer le dispositif de contrôle est justifiée. Elle provient directement de l’analyse menée sur deux axes différents, un axe monolingue qui concerne chaque langue, indépendamment l’une de l’autre, et un axe contrastif qui met l’accent sur les convergences et divergences entre les deux langues. Nous avons au cours de notre travail mis en exergue deux contrôles différents : un contrôle statique et un contrôle dynamique.
1.1.1 Contrôle statique
Le contrôle statique s’effectue sur chaque langue indépendamment l’une de l’autre, grâce à des connaissances acquises préalablement sur les deux langues source et cible, d’où l’intérêt de maîtriser et la langue de départ et la langue d’arrivée (voir 2°/ difficultés de liaison). Le contrôle statique s’applique dans la majorité des cas sur la langue source mais peut concerner aussi la langue cible. Dans ce dernier cas, le contrôle sert plutôt à éviter des complications liées à la formation morphologique et syntaxique comme c’est le cas pour la langue arabe. Cette dernière est dotée d’un système morphologique extrêmement riche dont dépend l’interprétation des énoncés. La morphosyntaxe est un phénomène qui prend de l’ampleur une fois la phrase traduite vers la langue arabe, De ce fait, l’interdiction de certaines catégories ou certaines structures diminue la complexité, sans nuire à l’effet communicatif de la langue. L’exemple 1(a) montre une règle de contrôle statique sur l’arabe. Elle est établie exclusivement grâce à des connaissances linguistiques sur la langue arabe. Elle n’est donc en aucun cas motivée par les particularités de la langue source, le français, et n’émane pas d’une étude contrastive. L’interdiction d’utiliser certains pronoms vise à alléger le système de conjugaison arabe que nous savons d’ores et déjà très flexionnel si nous prenons en compte toutes les catégories de verbe qui existent dans cette langue et leur morphologie sensible à plusieurs facteurs (genre, temps, négation, etc). Cependant, il est clair qu’une telle restriction impacte la langue source, puisque toute restriction sur l’arabe est une restriction indirecte sur le français.
Le contrôle statique dans la langue source, quant à lui, vise plutôt à désambiguïser l’énoncé par des restrictions linguistiques, mais aussi à accroître la lisibilité des textes par des restrictions de format. Il sert aussi à donner au rédacteur des moyens de rédaction faciles à l’utilisation et légers en information linguistique. Dans l’exemple 1(b) la règle de contrôle interdit l’utilisation
dans les protocoles de sécurité de plusieurs verbes dans la même phrase. Cela revient à tolérer un seul verbe dans une condition ou une instruction.
Ex1 :
Règle de contrôle statique sur l’arabe :
1(a) Seule la conjugaison à la 3ème personne féminin/masculin du singulier وه /يه , la 3ème personne féminin/masculin du pluriel « مه /نه » et la 2ème personne masculin pluriel « متنأ » est autorisée
Règle de contrôle statique sur le français : utiliser une seule action par phrase 1 (b) Parler régulièrement à la victime et la rassurer.
Parler régulièrement à la victime Rassurer la victime
1.1.2 Contrôle dynamique
Le contrôle dynamique s’effectue pendant la mise en contact des deux langues. Il est le résultat du va-et-vient qu’effectue le traducteur entre langue source et langue cible, et s’inspire des divergences que l’étude comparative met en exergue. Il vise à aplanir les écarts quand ces derniers dépassent les limites d’une simple formalisation et mobilisent des moyens qui alourdissent le système. L’exemple 2(a) montre une règle de contrôle dynamique qui est dû à un problème de traduction du français vers l’arabe. L’adjectif numéral cardinal en arabe est sensible au genre, il est au masculin quand il précède un nom féminin et il est au féminin quand il précède un nom masculin. Par conséquent, l’utilisation des chiffres arabes permet d’éviter des règles de transfert complexes et diminue le temps de traduction.
Ex2 :
Règle de contrôle dynamique : utiliser des chiffres arabes 2(a) Refroidir la peau sous l’eau courante pendant 15 minutes
Figure 1 : Contrôle statique et contrôle dynamique
La majorité des contrôles dynamiques que nous avons effectués sont issus d’ambiguïtés linguistiques lexicales ou syntaxiques ou liées à des divergences d’ordre pragmatique.
1.2 Ambiguïtés lexicales
Les sens que portent les mots de la langue sont souvent ambigus. Il suffira d’ouvrir le dictionnaire de n’importe qu’elle langue pour se rendre compte de cette polysémie surprenante. Cette richesse
du langage humain constitue une pierre d’achoppement à la traduction automatique qui peine à trouver la parade. La désambiguïsation du lexique de la langue source pendant l’analyse ne permet qu’un transfert partiel du sens. La charge sémantique du lexique est complétée au cours de l’analyse par des entités supérieures à celles des unités lexicales isolées car l’équivalence référentielle ne suffit pas à elle seule pour décrire le sens. Une analyse sémantique qui se réduit à une analyse lexicale serait, par définition, insuffisante car la compréhension des relations entre les mots est aussi importante que la compréhension des mots eux-mêmes. Quand la langue française exprime deux sens différents avec un seul mot, la langue arabe utilise deux mots différents. C’est le cas dans cet exemple tiré d’un protocole de sécurité.
3 (a) présenter vos papiers aux autorités. 3 (b) ne pas jeter les papiers par terre.
Dans cet exemple, le mot papier est polysémique. L’ambiguïté est donc due à la différence de sens qu’il introduit dans les deux phrases. Son utilisation tel qu’il est, dans ces instructions, induira forcément le système de traduction en erreur, car l’arabe utilise deux mots distincts pour rendre les deux sens différents. Dans l’exemple 3 (a) le mot papiers sera traduit par le mot قئاثولا pour désigner des papiers administratifs quelle que soit leur nature (ceux que nous présentons à un agent de police, par exemple). Dans l’exemple 3 (b) le même mot papiers se traduira par le mot قارولأا qui désigne du papier simple qu’on utilise pour écrire ou la matière.
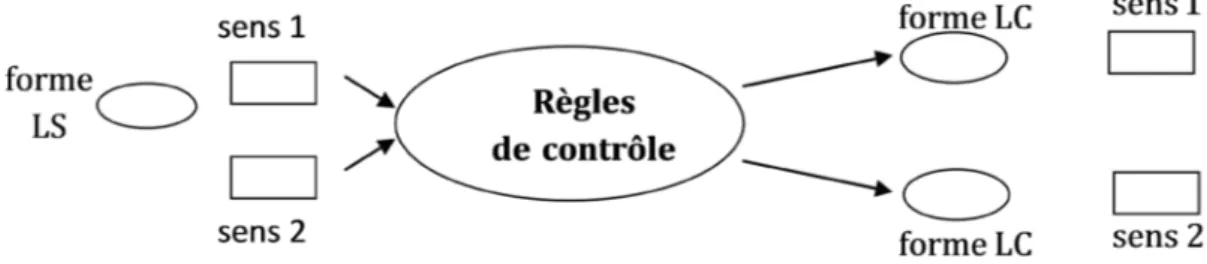
Nous constatons à travers cet exemple la difficulté que pose une telle polysémie qui n’est jusqu’ici que lexicale. Des mots simples dans un contexte intraphrastique démontrent les limites d’un système qui ne prend pas en compte les phénomènes d’ambiguïté lexicale. La langue contrôlée appliquée sur une langue de spécialité pourra désambiguïser cette unité lexicale, en fixant des contraintes d’utilisation lexicale. Ainsi la désambiguïsation du mot papier dans la première phrase passera par l’ajout d’un complément du nom tel que (d’identité, de la voiture, etc.) et dans la deuxième phrase par l’absence de ce dernier. (Voir figure 2)
Figure 2 : Les contraintes lexicales facilitent les équivalences référentielles
1.3 Ambiguïtés syntaxiques
Le problème des rattachements des groupes nominaux est l’une des ambiguïtés qui entrave la traduction automatique. Cette phrase non contrôlée adresser vous au poste de contrôle
sanitaire aux frontières dès votre arrivée, tirée d’un protocole de sécurité pour la prévention
contre la grippe porcine émis par le ministère de la santé algérien, montre la difficulté de traduire automatiquement pour plusieurs raisons. Nous nous contentons de soulever le problème du rattachement des GNs. La suite syntaxique poste de contrôle sanitaire met le système de TA en difficulté. Quel est le gouverneur de l’adjectif sanitaire ?, est-ce le nom poste ou le nom contrôle ? Le choix du rattachement syntaxique est dans ce cas crucial pour l’interprétation du GN, mais parfois de toute la phrase à laquelle il appartient. Si la distinction n’a pas d’effet sur la langue française, vu que la morphologie de l’adjectif ne change pas avec le changement du genre du nom qu’il qualifie, en arabe ce n’est pas le cas, le genre d’un des deux noms traduits en arabe change. Le nom « poste » reste au masculin زكرم alors que le nom « contrôle » devient féminin
ةبقارم d’où l’importance de définir dès la phase d’analyse le point de rattachement de l’adjectif sanitaire morphologiquement variable en langue arabe.
4(a) poste de contrôle sanitaire 4(b) زكرم ةبقارم ةيحص
4(c) زكرم ةبقارم يحص
La langue contrôlée intervient, dans ce cas précis, pour éviter cette ambiguïté syntaxique. La règle de contrôle imposera un voisinage direct de l’adjectif avec le nom qu’il qualifie. Dans l’exemple 4(a), l’adjectif est bien placé si le rédacteur du protocole désigne un contrôle sanitaire, et mal placé s’il fait référence à un poste sanitaire, puisque la traduction en arabe est différente dans les deux cas. La morphologie en arabe de l’adjectif sanitaire n’est pas la même dans l’exemple 4(b) et l’exemple 4(c). Dans l’exemple 4(b) l’adjectif sanitaire/ ةيحص qualifie le nom contrôle/ ةبقارم qui est au féminin en arabe, et dans l’exemple 4(c) l’adjectif sanitaire/ يحص qualifie le nom poste/ زكرم qui est resté masculin en arabe.
1.4 Divergences pragmatiques
Pour peu que l’objectif principal de la traduction est de transposer fidèlement un sens dans la langue cible, il est indispensable, afin d’atteindre cet objectif, d’avoir une idée claire de ce qu’est vraiment le sens. Nous considérons que le sens n’est pas un simple produit de facteurs intralinguistiques, mais le résultat d’interaction entre facteurs intralinguistiques et extralinguistiques. Par conséquent, la traduction du lexique doit prendre en compte la dimension pragmatique de la langue, afin de comprendre mieux sa portée sémantique et d’établir ensuite des équivalences. Dans les protocoles de sécurité, certaines unités lexicales posent le problème de l’aspect pragmatique, et déclenchent au moment de leur traduction un conflit entre les deux notions de connotation et de dénotation. La traduction de ce type d’unités lexicales montre à quel point la traduction ne doit pas s’en tenir qu’au sens dénotatif, mais doit prendre en compte aussi le sens connotatif des lexies. Le verbe arroser pris hors contexte ne semble pas poser problème lors de sa traduction vers l’arabe qui donne يقس . Une fois mis en contexte, ce verbe, dans l’expression non contrôlée refroidir immédiatement la brûlure, en l’arrosant avec de l’eau
froide durant 5 minutes, prend par contre un sens supplémentaire qui vient s’ajouter au sens
dénotatif. Dans cette phrase, c’est le sens connotatif du verbe arroser qui l’emporte, il serait donc incorrect, voire risible, de traduire la phrase arroser la brûlure par ىقس قرحلا, car la langue arabe n’exprimera jamais ce sens de cette manière. Nous dirons plutôt بص ءاملا ىلع قرحلا (verser de l’eau sur la brûlure).
Cet exemple et bien d’autres montrent combien il est important d’associer à l’aspect lexico-syntaxique l’aspect pragmatique de la traduction. Reconnaître que l’activité de traduction est une activité de médiation entre deux cultures et entre deux génies de langues différentes, nous oblige à considérer des cas comme celui que nous venons de mettre en exergue. Le contrôle dynamique montre que chaque langue découpe le réel à sa façon, et derrière chaque opération de traduction il y a souvent une dimension pragmatique à prendre en considération. La langue contrôlée imposera donc de retenir pour le verbe arroser soit le sens dénotatif soit le sens connotatif, sachant que chacun des deux sens donne une traduction différente en langue arabe.
1.4.1 La nominalisation outil de contrôle
La nominalisation est un procédé abondamment utilisé dans la rédaction des protocoles de sécurité non contrôlés, compte tenu de sa productivité et compte tenu de la facilité d’utilisation qu’il propose aux rédacteurs de ces protocoles. Cette abondance des syntagmes nominaux est certainement un signe fort de la spécialisation des textes de sécurité, notamment ceux destinés au professionnel, mais c’est aussi et probablement une caractéristique spécifique de ce domaine qui a pour souci l’information concise, rapide et correcte.
Nous estimons que cette caractéristique inhérente au texte de sécurité peut être exploitée davantage afin d’affiner l’information et d’éviter sa dispersion dans des phrases longues généralement. Cela permettra aussi de préserver la nature discursive de ce type de texte.
De ce fait, le contrôle effectué pour limiter les champs syntaxique et sémantique des textes de sécurité s’est, entre autre, basé sur la nominalisation. Les règles de contrôle syntaxiques favorisent le recours à la notion de nominalisation et aux syntagmes nominaux qui font une économie de langage considérable et évitent des structures complexes difficilement traduisibles automatiquement. Toutefois, il est nécessaire de comprendre le fonctionnement de ces syntagmes nominaux pour assurer leur bonne traduction vers l’arabe et éviter des chevauchement entre les règles algorithmiques destinées plutôt à traiter des syntagmes nominaux libres et le dictionnaire lexical en charge d’une simple instanciation lexicale des syntagmes lexicaux (Beddar, 2009).
1.4.2 La nominalisation outil normatif et génératif de structures
Dans les protocoles de sécurité, deux types de structures prédominent, les structures conditionnelles et les structures instructives. Les structures conditionnelles servent à décrire l’environnement dans lequel les instructions pourraient ou devront être réalisées, les instructions quant à elles, donnent l’action à effectuer quand les conditions sont réunies.
5 (a) Si la fumée passe sous la porte : arroser la porte.
C’est sur la base de ces deux types de structures que la nominalisation agit pour générer des modèles de structures qui rentreront dans le système de traduction automatique contrôlé TACCT.
La notion de nominalisation dans le protocole de sécurité contrôlé est très fructueuse, car elle permet la génération d’un nombre considérable de syntagmes nominaux. Elle est aussi un outil normatif pour le contrôle, puisqu’elle crée des bases syntaxiques génératives qui encadrent la rédaction des protocoles de sécurité en assurant le respect des structures établies, et permet de mettre en place plus facilement les règles de transfert vers l’arabe. La nominalisation consiste à transformer une phrase source en un syntagme nominal et à enchâsser ce syntagme dans la structure type. L’exemple suivant 6 (a) montre comment la nominalisation s’effectue au sein d’une phrase non contrôlée pour donner ensuite une phrase contrôlée.
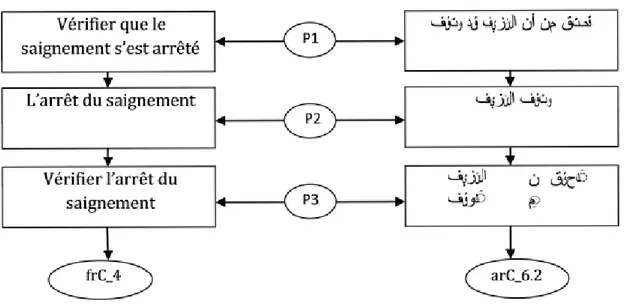
6 (a) vérifier que le saignement s’est arrêté 6 (b) l’arrêt du saignement
6 (c) vérifier l’arrêt du saignement
La phrase 6 (b), devenue syntagme libre après sa nominalisation, est enchâssée dans la phrase source 6 (a) et prend la fonction de l’argument 1 du verbe vérifier dans l’exemple 6 (c) qui est une structure finale contrôlée.
La nominalisation peut être à source verbale (pendant que l’avion décolle --> pendant le décollage de l’avion) ou à source adjectivale (assurez-vous que les installations soient conformes à la réglementation en vigueur -- > s’assurer de la conformité des installations à la réglementation en vigueur). Le procédé de nominalisation a une capacité de création considérable, car la phrase nouvelle dans laquelle le syntagme nominal cible, issu de la nominalisation, a été enchâssé, peut elle-même subir la nominalisation. Ce procédé est récursif, il peut être répété de sorte qu’il produit une série de syntagmes nominaux à complexité croissante. Dans ce cas, la forme du syntagme peut être modifiée par divers phénomènes de la cohérence textuelle tels que : l’ellipse, la synonymie, l’emploi des déterminants.
7 (a) Si le système qui détecte la fumée est totalement défaillant 7 (b) Le système de détection de fumée
7 (c) Si le système de détection de fumée est totalement défaillant --> structure (1) 7 (d) Défaillance totale du système de détection de fumée
7 (e) En cas de défaillance totale du système de détection de fumée --> structure (2)
La phrase 7 (a) « le système qui détecte la fumée » est nominalisée en syntagme nominal libre « le système de détection de fumée » et enchâssée en même temps dans la phrase source « Si Qch est totalement défaillant » qui renvoie à la structure frC_17 [arg0 + opt(neg1) + vconj + opt(neg2) + att + opt(opt(prep_comp1), comp1(n)) + opt(opt(prep_ comp2), comp2(n)) + pt1. Ensuite la structure obtenue est à son tour nominalisée et enchâssée dans la phrase « En cas
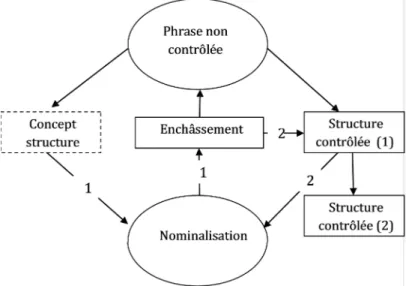
de Qch », ainsi on obtient la phrase « En cas de défaillance totale du système de détection de fumée » qui renvoie à une structure nominale faisant partie de l’ensemble des microstructures [En cas de + gn_sd]2. (voir la figure 3).
Figure 3 : Contrôle LiSe et nominalisation
Dans la figure ci-dessus, deux nominalisations et deux enchâssements ont été effectués, une fois sur la phrase non contrôlée pour obtenir la structure (1) et une deuxième fois sur la structure contrôlée (1) pour obtenir la structure contrôlée(2).
1.5 Contrôle bilingue par nominalisation
Pour démontrer l’efficacité du contrôle bilingue par nominalisation, il est essentiel de considérer le nom non pas comme une unité indépendante mais comme un constituant d’un syntagme nominal, et la nominalisation non pas comme une simple conversion d’un verbe ou d’un adjectif en un substantif mais comme une conversion d’une phrase en un nom ou en un syntagme nominal. En effet, la nominalisation n’est pas seulement l’obtention d’un syntagme nominal à partir d’une phrase simple, mais 1 Abréviations : “frC” français contrôlé, “arg0” est le sujet du verbe conjugué, c’est une transformation généralisée qui consiste à la conversion de deux phrases en une seule par le moyen de l’enchâssement de la première sous la forme d’un groupe nominal constituant dans une seconde dite phrase principale ou matrice. Le principe de nominalisation est valable aussi pour la langue arabe très riche sur le plan dérivationnelle. La nominalisation est un moyen de contrôle bilingue qui participe au rapprochement des deux langues français et arabe comme le montre l’exemple ci-dessous. L’arabe s’appuyant sur les différents procédés de translation, dont celui du verbe en nom verbal (masdar), manifeste un isomorphisme linguistique avec le français visible dans un nombre fini de structures françaises et arabes contrôlées appelées macrostructures miroirs.
(1) Abréviations : “frC” français contrôlé, “arg0” est le sujet du verbe conjugué “vconj”, “att” est le mot ou groupe de mots qui suit le verbe d’état “vconj”.
Figure 4 : Contrôle bilingue par nominalisation
2. Systémique linguistique
La première application de la microsystémique à la langue revient aux travaux du professeur Sylviane Cardey (Cardey 1987, Cardey et al. 2004) et à la théorie SyGULAC (Systemic Grammar Using a Linguistically motivated Algebra and Calculus) élaborée au centre Tesnière. L’analyse linguistique microsystémique du Centre Tesnière propose l’idée que, pour être traitées en toute sécurité, les langues doivent être décomposées en microsystèmes assez petits mais aussi complets, analysable par un être humain et une machine. Les systèmes ainsi délimités peuvent avoir des interactions avec d’autres systèmes, et cette interaction est une propriété du langage. Rien n’est indépendant : lexique, morphologie et syntaxe sont liés.
La langue est donc un « système complexe composé d’un ensemble de microsystèmes dynamique organisé les uns en fonction des autres. Un microsystème est un élément parmi d’autres qui ne peut fonctionner indépendamment mais qui peut avoir un comportement unique ». L’analyse de la langue par la théorie SyGULAC est exclusivement linguistique, basée sur des calculs mathématiques et logiques. Le découpage de la langue en microsystèmes permet d’appliquer des calculs qui permettent d’aller vers différentes applications en traitement automatique des langues, comme la traduction automatique donnant des résultats rapides et fiables.
2.1 Théorie SyGULAC
L’un des avantages capitaux de la théorie SyGULAC est sa capacité d’analyse et de modélisation. La langue est minutieusement décomposée en microsystèmes, éléments petits mais complets, analysable par la machine. La décomposition est étroitement liée à un problème sciemment identifié et cerné. L’approche SyGULAC préconise d’identifier préalablement le problème et les besoins d’analyse en vue d’une application précise. En fonction de ces besoins, construire ensuite un ensemble consistant de règles logiques et précises qui permettrait une manipulation et une représentation de toute la langue sous formes de microsystèmes. Les règles mises en place ne concernèrent que les éléments morphologiques, lexicaux ou syntaxiques nécessaires à l’analyse. Ces éléments restent cependant en interaction avec le reste de la langue. Il n’est pas nécessaire dans l’approche SyGULAC de traiter l’ensemble de la langue, il est plutôt question d’identifier les problèmes, de définir les besoins et de mettre en place des règles précises représentatives de toute la langue.
2.2 Difficultés de traduire automatiquement
La traduction automatique fait face à plusieurs difficultés liées principalement à la complexité du langage naturel. La phase d’analyse et de transfert démontre que même après l’application du contrôle sur la langue, des ambiguïtés à tous les niveaux persistent. Nous avons recensés plusieurs de ces difficultés que nous rangeons dans deux catégories principales :
2.2.1 Difficultés de modélisation
Cette catégorie de difficultés renvoie à la manière dont les connaissances formelles de chaque langue doivent être modélisées et aux liens à établir entre matière cognitive et matière linguistique. La formalisation des connaissances d’une langue n’est pas une tache facile. La langue présente, en effet, peut de relations biunivoques entre un ensemble de formes lexicales, syntaxiques et un ensemble de concepts sémantiques.
La forme simple opération, par exemple, suivant le contexte peut avoir plusieurs référents tels que :
• intervention chirurgicale pratiquée sur l’organisme vivant dans un but thérapeutique, préventif, esthétique ou expérimental dans le domaine médical ;
• ensemble de mouvements stratégiques ou de manoeuvres tactiques d’une armée en campagne, exécutés en vue d’atteindre un objectif donné dans le domaine militaire ; • dans le domaine économique, la lexie opération désignera tout acte par lequel une unité économique manifeste sa participation à la vie économique ; ...
De plus, le concept sémantique associé à une forme lexicale ou syntaxique peut ne pas être explicite dans le contexte du texte à traduire, car la langue de spécialité rend l’accès au sens difficile, car réservé uniquement aux spécialistes qui la pratiquent (voir Ambiguïté lexicale)
2.2.2 Difficultés de liaison
Dans toute opération traduisante, il est nécessaire d’établir des liens directs entre langue source et langue cible respectueux des particularités de chacune d’elles. La mise en contact des langues source et cible est la démarche la plus risquée puisque on se positionne sur deux terrains complètement différents qu’il faut parfaitement connaitre. Toutefois, la connaissance de ces langues n’a pas le même niveau d’exigence, un traducteur humain dans l’acte de traduction se contente de saisir le sens des énoncés à traduire sans se soucier des constructions lexicales ou syntaxiques. Une fois le sens appréhendé, il se libère rapidement de la langue source et procède à la traduction en reproduisant l’énoncé dans la langue cible.
La traduction automatique, quant à elle, exige la maîtrise des deux langues. Il ne suffit pas de comprendre simplement les énoncés de la langue source, il faut aussi comprendre leur mode de fonctionnement lexical et syntaxique. L’analyse de la langue source n’est pas une analyse de surface, elle doit être profonde morphologique, lexical syntaxique, sémantique afin que chaque détail lié à son fonctionnement soit mis en valeur.
La formalisation des données et l’appréhension du sens exige que chaque construction lexicale, syntaxique, chaque désinence ou flexion soit prise en compte.
3. Systémique et système de traduction TACCT
Compte tenu de la complexité du langage naturel objet de la traduction automatique même après son contrôle et dans la perspective de trouver la méthode adéquate, qui sera en mesure de faire face à toute cette panoplie de difficultés, nous estimons que la systémique via la théorie SYGULAC est sans doute un atout de taille et un moyen infaillible de modélisation, car les problèmes relèvent de différents niveaux d’un système général, celui de la langue.
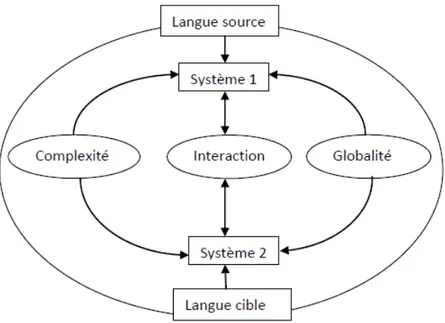
Les trois notions que la systémique apporte (voir ci-dessus), permettent d’analyser les deux langues source et cible en tant que systèmes complexes.
3.1 Complexité
Le concept de complexité dans le langage naturel renvoie à toutes les difficultés de compréhension dues à plusieurs phénomènes linguistiques (ambiguïté, anaphore, polysémie, etc.) et extralinguistiques (situation de communication, locuteur, culture, etc.). Cette complexité se retrouve même après le contrôle, car de part l’extrême richesse de la langue, nous ne pouvons dissiper toutes ces ambiguïtés.
Dans le domaine de la traduction automatique, la dimension du problème est double puisqu’il s’agit de comprendre une langue-source et de traduire dans une autre langue-cible de façon à rendre le sens intégral tout en respectant son mode de fonctionnement linguistique. Donc la complexité est à la fois intralangue par le processus d’analyse de chaque langue et interlangue par l’opération de traduction.
3.2 Globalité
La langue en tant que système est un tout et ne peut être appréhendée totalement que par une approche holistique. Les phénomènes linguistiques qui caractérisent une langue ne sont pas isolés mais appartiennent à un ensemble qu’il est important de considérer en tant que tel pour pouvoir comprendre les éléments qui le composent. Le caractère global de la langue démontre l’interdépendance des éléments et l’harmonie de l’ensemble. En arabe par exemple, des phénomènes de morphologie ne peuvent être expliqués si l’on ne se réfère pas dans certains cas à la syntaxe, ce qui donne l’ensemble appelé morphosyntaxe. Donc c’est le tout qui définit une partie de ce tout.
Le mot est composé de deux morphèmes, le morphème رممّض appartenant explicitement au système morphologique et le morphème (نو ) qui empiètent sur deux systèmes différents, la morphologie et la syntaxe. Les deux microsystèmes morphologique et syntaxique trouvent leurs sens dans un système global, celui de la morphosyntaxe.
Le but de la systémique est donc de considérer les problèmes de la traduction automatique comme un tout et de rentrer ensuite progressivement dans les détails. Cette entreprise évitera le traitement séquentiel des problèmes, et favorisera plutôt une vue d’ensemble avec une analyse progressive.
3.3 Interaction
La langue est un ensemble de microsystèmes qui interagissent. Les morphèmes, le lexique, la syntaxe sont autant de microsystèmes qui composent une langue et entretiennent des liens de dépendances que la notion d’interaction met en exergue.
Contrairement à l’approche analytique traditionnelle, la systémique ne considère pas les relations entre les éléments constituant un système comme de simples relations de cause à effet, mais des relations qui interagissent. La nature des relations est le plus souvent circulaire, une action (cause) produit un effet (réaction) qui modifie l’environnement, qui à son tour modifie la cause à l’origine de l’effet.
Le changement d’une lexie dans une structure syntaxique peut amener à reconsidérer sa construction voire même sa sémantique. L’expression suivante : un verre de vin peut être affecté parce qu’un changement est survenu dans sa composition, l’introduction de la préposition « à » amène à revoir sa structure syntaxique et donc son statut lexical.
De la structure N1-de-N2, nous passons à la structure N1-à-N2 à cause de la lexie « à » qui par conséquent a changé l’environnement sémantique puisque les deux expressions n’ont pas le même sens. Dans ce cas, la cause n’est plus la préposition « de » mais toute l’expression verre à vin en tant qu’une seule unité de sens. La relation est de ce fait circulaire entre 3 microsystèmes distincts, lexique, syntaxe, sémantique.
Cet aspect d’interaction et d’interdépendance n’est pas simplement intrasystémique, mais également intersystémique applicable aux relations qui existent entre les systèmes, comme le montre la figure 5 où les deux systèmes dans notre système de TA, langue source et langue cible interagissent. Donc le concept «interaction» est la prise de conscience qu’il n’y a pas qu’une cause qui mène à une conséquence mais que tout interagit.
4. Modèle syntactico-sémantique TACCT d’un
point de vue systémique
D’un point de vue systémique, le système TACCT s’appuie sur deux axes principaux de description : l’axe analytique et l’axe classificatoire. Les deux axes n’agissent pas isolément mais interagissent continuellement, c’est le principe même des systèmes et de la systémique.
4.1 Axe analytique
L’axe analytique s’occupe d’analyser l’aspect structurel des phrases sur un axe horizontal. Il ne s’agit pas pour autant d’une analyse linéaire traditionnelle qui serait superficielle à notre sens, mais plutôt d’une analyse microsystémique des relations entre les différents groupements de mots. Ainsi les dépendances et les régimes sont mis en évidence.
Les microsystèmes mis en évidence par cet aspect de description correspondent à plusieurs structures contrôlées. L’analyse vise à identifier toutes les structures contrôlées possibles, les répertorier et donner ensuite les correspondances dans la langue arabe en appliquant le principe d’équivalence et d’isomorphisme. L’axe analytique opère sur deux niveaux distincts, un niveau supérieur macrostructural qui renvoie aux structures argumentales et où chaque macrostructure est identifiée par un numéro appelé clé argumentale et le niveau microstructural qui renvoie aux différentes microstructures inférieures aux structures argumentales.
L’axe analytique et l’axe classificatoire que nous aborderons par la suite agissent conjointement, le noyau de la description étant la classe du verbe dans les macrostructures et les classes déterminant, nom, adjectif dans les microstructures.
4.1.1 Groupe verbal /macrostructure
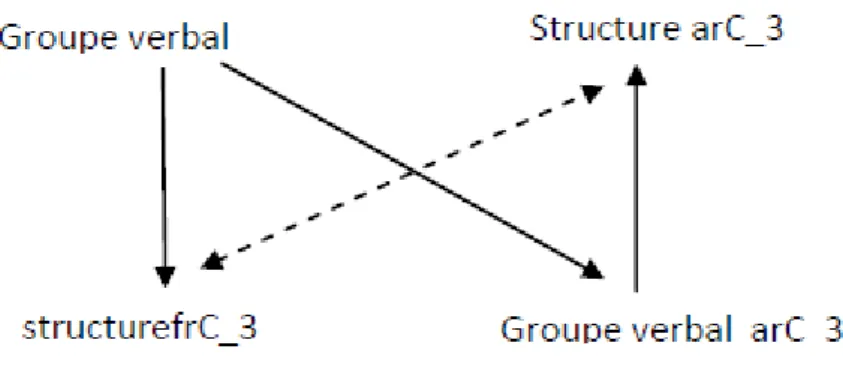
La macrostructure dans les deux langues contrôlées frC et arC correspond à la structure argumentale type de chaque verbe. Chaque verbe renvoie à une seule et unique structure argumentale et est muni d’une clé argumentale qui renvoie à cette même structure. Les verbes sont rangés ensuite par groupes verbaux selon qu’ils portent la même clé argumentale ou pas. A chaque macrostructure française correspond une macrostructure arabe et l’équivalence s’effectue par la clé argumentale. Autrement dit, l’équivalent du verbe en français portant une clé argumentale et renvoyant à une structure argumentale est un nom verbal en arabe portant sa propre clé argumentale renvoyant à une structure argumentale unique. Ainsi les verbes autorisés dans la langue contrôlée sont répartis en groupes, en français comme en arabe.
Dans l’exemple 8 (a) le numéro du verbe (notifier) est frC_3 qui renvoie à la structure frC_3 [opt(neg1)+ opt(neg2) + vinf + arg1 + opt(opt(prep_comp), comp1(n)) + opt(opt(prep_comp), comp2(n)) + pt]. Certains éléments de la structure sont mis en optionnel et ne nécessitent donc pas une instanciation obligatoire.
8 (a) notifier le contrôle aérien immédiatement. 8 (b) اروف وجلاّةي ةبقارملا ملاعإ بجي
Une fois la macrostructure du verbe français définie et le numéro structural attribué, le système lui fait correspondre une macrostructure arabe équivalente et isomorphique (Beddar, 2010). L’équivalence s’effectue de groupe verbal à groupe verbal et par la structure que chaque groupe implique. Dans l’exemple 8 (b), le nom verbal correspondant au verbe français est donc le nom verbal « ملاعإ » qui appartient au groupe arC_3 et qui renvoie à la structure arC_3 [opt(neg1) +
lexis(‘بجي ‘) + opt(neg2) + nver + arg1(acc)+ opt(opt(prep_comp1), comp1(n)) + opt(opt(prep_ comp2),comp2(n)) + pt (voir figure 6).
Figure 6 : Exemple d’isomorphisme par paire (groupe verbal/macrostructure) entre le français et l’arabe
4.1.2 Microstructures
L’analyse se poursuit jusqu’aux microstructures obligatoires ou optionnelles. Les microstuctures obligatoires se résument à l’argument 0 arg(0), l’argument 1 (arg1), l’argument 2 (arg2) et l’attribut (att), les microstructures optionnelles correspondent aux compléments. Les microstructures renvoient à tous les syntagmes nominaux autorisés par la langue contrôlée. Le transfert des microstructures vers l’arabe prend en compte le paramètre de la casualité lié à la fonction syntaxique assumée au sein de la macrostructure.
Dans l’exemple 8 (a), le syntagme nominal « le contrôle aérien », qui représente l’argument 1 (arg1_frC), renvoie à la seule microstructure [ad + n + adj] de la macrostrcuture frC_3. Les variables ad, n, adj, comme le montre la microstructure, sont génériques basées sur le concept de super-catégorisation. Cette conception catégorielle permet la condensation des parties de discours et évite l’explosion combinatoire due principalement à deux paramètres qui affectent certaines classes : le genre et le nombre. L’axe analytique n’offre pas aux microstructures un inventaire par numéro d’identification, comme c’est le cas dans les macrostructures, mais un ensemble de structures répertoriées selon les contraintes de rédaction imposées par la langue contrôlée, leur transfert se fait par le biais de règles.
L’axe classificatoire intervient davantage sur les microstructures compte tenu de l’importance des classes et des parties de discours. Cet axe permet de saisir les dépendances existantes entre les classes, de comprendre les interactions qui les caractérisent et d’établir en se basant sur ces données syntaxiques, des structures de correspondances entre le français et l’arabe qui tiennent compte de la particularité de chaque langue (analyse monolingue).
4.2 Axe classificatoire
Cet axe de description s’occupe de décrire les classes (parties de discours) et de définir le fonctionnement de chacune d’elle. Ainsi chaque microsystème en rapport avec une partie de discours (système adjectival, système nominal, …) est analysé et son mode de fonctionnement détaillé. Pour ce faire, cet axe adopte à la fois une démarche monolingue visant à dégager les particularités de chaque langue, comme le système des cas en arabe avec toutes les variations morphologiques qu’il induit et, une démarche contrastive bilingue qui met en relief les divergences ainsi que les convergences entre les deux langues source et cible. L’axe classificatoire interagit avec l’axe analytique, la classe des verbes étant le noyau de construction des macrostructures
argumentales, et les classes des adjectifs, noms ou déterminants sont centrales dans la construction des microstructures. L’étude des classes dans le système TACT vise à décrire en premier lieu le comportement de certaines parties de discours, notamment les noms, et les adjectifs et formaliser par la suite leur apparition en contexte. Ces deux classes présentent beaucoup d’intérêt, d’autant plus que la construction et la modélisation des microstructures en dépendent. La traduction automatique au niveau microstructural plus qu’au niveau macrostructural nécessite une formalisation minutieuse et précise pour plusieurs raisons, premièrement parce que le nombre des microstructures est largement supérieur à celui des macrostructures, et deuxièmement parce que les microstructures font entrer en jeu plus de parties de discours, et par conséquent plus de phénomènes linguistiques qui doivent être formalisés. (voir exemple 9)
9 (a) installer un détecteur de fumée près des chambres. 9 (b) mettre les allumettes hors de portée des enfants. 9 (c) s’éloigner de la voie ferrée.
Dans les deux exemples 9 (a) et 9 (b), les deux lexies détecteur de fumée et allumettes montrent l’importance de l’axe classificatoire dans la traduction automatique du français vers l’arabe et la nécessité d’un travail approfondi sur toutes les classes en contexte. Le mot allumette se scinde en arabe en deux lexies « ناديع , تيربك » admettant ainsi, contrairement aux autres noms simples, une détermination par annexion. De ce fait, la détermination de la lexie allumette par l’article « les » en français se traduira en arabe par l’insertion de l’article défini équivalent « لا » entre les deux lexies séparées par un blanc graphiquement mais sémantiquement indivisibles. Autrement dit, l’entrée lexicale sera une entrée unique « تيربك ناديع » avec un procédé formel qui lui conférera le comportement d’un syntagme libre. (Beddar, 2010)
Le syntagme détecteur de fumée pour sa part pose la question de l’unité lexicale. Est-ce que sa traduction exige un traitement séquentiel lexie par lexie ou un traitement par bloc lexical ? C’est le rapport sémantique entre les deux lexies une fois traduites en arabe qui déterminera si le syntagme est un syntagme libre ou un syntagme lexical. Dans cet exemple, le syntagme
détecteur de fumée est bel est bien libre compte tenu de la traduction des deux lexies détecteur
et fumée en arabe « فشاك », « ناخد » qui sont sémantiquement indépendantes l’une vis-à-vis de l’autre. Par ailleurs, la traduction de la suite voie ferrée vers l’arabe dans l’exemple 9 (c) montre que cette suite n’est pas libre. L’association du nom voie polysémique, avec le participe passé ferrée utilisé comme adjectif dans ce cas de figure, restreint le sens du mot voie et par conséquent le sens de l’association (n + adj). La règle générale de transfert des suites (ad + n + adj) vers l’arabe se trouve ainsi modifiée, puisque les deux sous-systèmes n et adj se confondent en langue source mais se distinguent en langue arabe. La règle générale prévoit l’insertion de l’article défini devant l’adjectif en arabe si le nom est précédé d’un article défini, autrement dit l’adjectif suit le nom en détermination [artu + n + artu + adj]. Dans l’exemple 9 (c), la suite la voie ferrée est une unité n à part entière en français mais ne l’est pas en arabe, car elle requiert l’application de la règle générale de transfert avec l’insertion de l’article défini entre les deux lexies n et adj « ةيديدح لا كسّة لا ».
Un autre aspect peut être aussi soulevé dans l’axe classificatoire, c’est le marquage casuel des noms et des adjectifs qui est important pour la traduction vers l’arabe. La morphologie de ces classes, contrairement au français, varie pour indiquer la fonction syntaxique qu’elles assument dans l’énoncé, d’où l’intérêt d’un travail approfondi sur le système des cas entre le français et l’arabe.
5. Systémique et isomorphisme dans le système
TACT contrôle français-arabe
La systémique est un outil utile qui peut fournir des modèles universels et utilisables par différentes disciplines. Notre travail sur la traduction automatique du français vers l’arabe avec
la systémique linguistique comme outil, démontre que l’aspiration à un modèle parfaitement isomorphique entre deux langues, en l’occurrence le français et l’arabe, est maintenant une réalité. L’isomorphisme dont nous parlons est plus qu’une simple analogie vague et superficielle, c’est la conséquence du fait que, sous certains aspects, des abstractions et des modèles conceptuels peuvent rapprocher deux systèmes totalement différents en se focalisant sur les sous-systèmes qui les constituent. La systémique est dans le système TACCT français-arabe, un moyen normatif et méthodologique qui fournit des règles de transfert exactes, des correspondances et des isomorphismes parfaits, et qui écarte toute analogie superficielle nuisible à la traduction automatique.
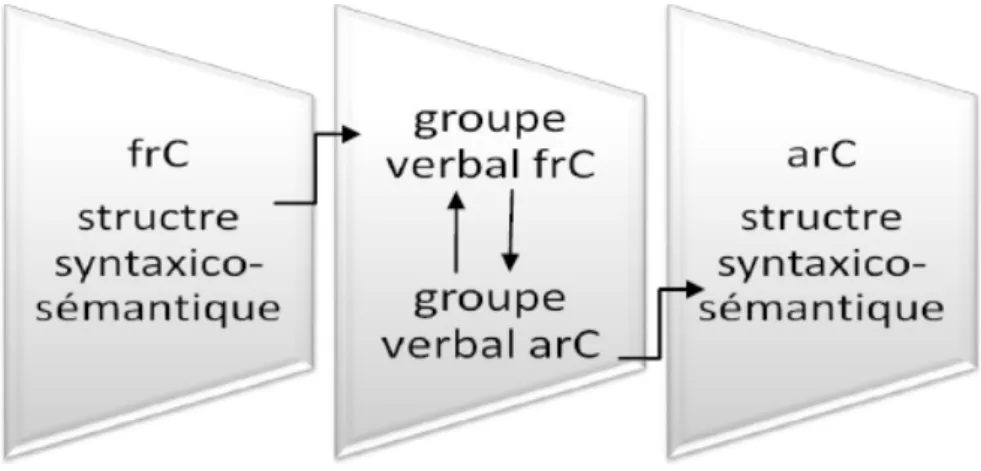
5.1 Structures syntaxico-sémantiques miroir
Les structures syntaxico-sémantiques miroir sont le fruit de la démarche systémique menée dans l’élaboration du système TACCT français-arabe. L’approche en microsystèmes nous a permis d’imaginer un moyen de passage sûr du français vers l’arabe, en ayant comme objectif le parallélisme entre les deux langues éloignées d’un point de vue global mais assez proches d’un point de vue systémique.
Les structures syntaxico-sémantiques miroir sont des structures appartenant à la catégorie des macrostructures (voir 1°/ Groupe verbal /macrostructure) et dont le noyau de construction est le verbe. Chaque structure est donc pilotée par un verbe et dans certains cas par le verbe et sa dépendance (préposition, adjectif, partV, …). L’aspect sémantique de ces structures émane du fait que chaque verbe possède un seul sens et donc monosémique. Le contrôle qui stipule par une règle générale (un mot, un sens) qui s’applique d’ailleurs sur les autres classes, rend les structures miroir dépourvues de toute ambiguïté. L’équivalence entre le français et l’arabe est de structure à structure et s’effectue via un numéro verbal et une clé argumentale. Le numéro verbal attribué au verbe est le même que celui attribué à la structure à laquelle il renvoie. De ce fait, les verbes qui portent le même numéro renvoient à la même structure et constituent par conséquent un groupe verbal (voir figure 7).
Figure 7 : Structures syntaxico-sémantiques miroir (français-arabe)
L’avantage d’une telle approche isomorphique et de maîtriser à la fois la syntaxe et la sémantique de la langue source et cible et de pouvoir ainsi établir des règles de transfert simples et exactes. La syntaxe et la sémantique se trouvent représentées au même niveau, la syntaxe par la construction articulée autour du verbe, et la sémantique par le verbe lui-même limité à un sens par la langue contrôlée. La macrostructure miroir permet aussi de prévoir des variations éventuelles des diathèses. (voir exemple 10)
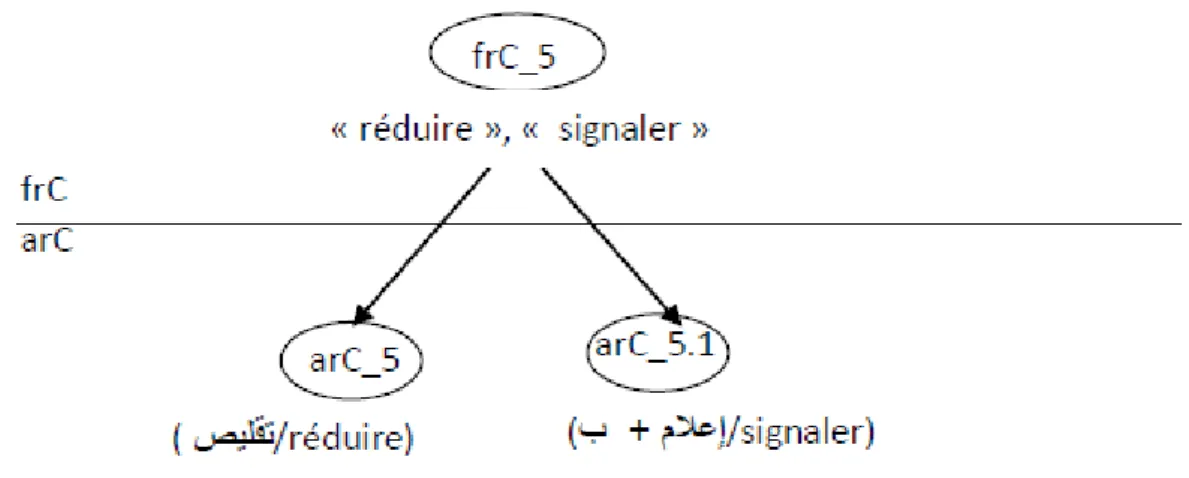
10 (a) réduire la vitesse en dessous de 205/.55. réduire -- > frC_5
opt(neg1) + opt(neg2) + Vinf+arg1+prép_v + arg2+opt(opt(prep_comp1), comp1(n)) + opt(opt(prep_ comp2),comp2(n))+pt
10 (b) . تحت لاسرعة تقليص يجب 502 ./ 22 صيلقت -- > arC_5.1
opt(neg1) + lexis(‘بجي ‘) +opt(neg2) + nver + arg1+ prep_v + arg2+ opt(opt(prep_comp1), comp1(n)) + opt(opt(prep_comp2),comp2(n)) + pt
10 (c) signaler le cas à l’Institut de Veille Sanitaire immédiatement. signaler -- > frC_5
opt(neg1) + opt(neg2) + vinf + arg1 + prep_v + arg2 + opt(opt(prep_comp), comp1(n)) + opt(opt(prep_comp), comp2(n)) + pt
10 (d). فورا بلاحلاة لاصحية لامراقبة مركز إعلام يجب (signaler l’Institut de Veille Sanitaire immédiatement du cas) ملاعإ + ب -- > arC_5.2
opt(neg1)+lexis(‘بجي ’)+opt(neg2)+nver+arg2(acc)+prep_v+arg1(acc)+opt(opt(prep_ comp1), comp1(n)) + opt(opt(prep_comp2),comp2(n)) + pt
Nous notons à travers les deux exemples 10 (a) et 10 (c) que la même structure française frC_5 qui renvoie aux deux verbes français « réduire » et « signaler » donne deux structures arabes différentes « arC.5 » et « arC.5.1 » dans les exemples 10 (b) et 10 (d). Si la structure du premier verbe « réduire » est presque identique à celle du nom verbal « صيلقت » en arabe avec la même diathèse, la même structure frC.5 du verbe « signaler » nécessite une permutation des deux arguments arg1 et arg2 en arabe, donc une variation de la diathèse, ce qui donne une structure arabe arC.5.1 totalement différente de celle du français (voir figure 8).
Figure 8 : Exemple de variation de diathèse entre le français et l’arabe dans les structures syntaxico-sémantiques miroir
Conclusion
L’approche systémique appliquée à la traduction automatique dans le système TACCT contrôlé français-arabe appliqué aux protocoles de sécurité est considérée comme une approche novatrice et intelligente appropriée à la solution de problèmes de grande complexité. En effet, les problèmes que présente la traduction automatique du français vers l’arabe sont caractérisés par leur grande complexité, et la recherche de solutions implique une stratégie intellectuelle qui soit fondée sur l’analyse systémique, apte à l’appréhension de problèmes complexes. Il est clair que pour comprendre un ensemble, il faut connaître non seulement ses éléments mais aussi ses relations. Il est avéré en outre que l’adoption de l’approche systémique en traduction automatique conduit au rapprochement des deux systèmes, celui de la langue source et celui de la langue cible. Des parallélismes et des isomorphismes apparaissent entre les microsystèmes analysés facilitant ainsi l’établissement d’un modèle syntaxique et sémantique fiable et précis.
Bibliographie
Beddar M, (2009), French to Arabic Machine Translation Isomorphic Syntax, Use of Terminal Sequences, in ISMTCL Proceedings, International Review Bulag, PUFC, ISSN 0758 6787, ISBN 978-2-84867-261-8, pp 38-42, Besançon.
Beddar M. (2010) “ Traduction Automatique des Syntagmes Nominaux (N1-de-N2) du français vers l’arabe Dans les Protocoles de Sécurité ”, IIIème édition de la Conférence internationale LEXIQUE COMMUN / LEXIQUE SPÉCIALISÉ, Galaţi, Roumanie.
S. Cardey, P. Greenfield, R. Anantalapochai, M. Beddar, D. Devitre, and G. Jin, (2008), “Modelling of Multiple Target Machine Translation of Controlled Languages Based on Language Norms and Divergences”, Proceedings of ISUC2008 (Second International Symposium on Universal Communication) published by the IEEE Computer Society, Osaka, Japan, 15-16 December, pp 322-329.
Cardey, S., Greenfield, P., (2008), Micro-systemic linguistic analysis and software engineering: a synthesis, in revue RML6, 2008, Acte du Colloque International en Traductologie et TAL, Oran.
El-Dahdah Antoine, (1991), Dictionnaire de la grammaire arabe universelle, arabe-français, Librairie du Liban.
Gross Maurice, (1986) Grammaire transformationnelle du français, I) analyse du verbe, Cantilène.
Galisson R. et Coste D. (1976), Dictionnaire de didactique des langues, Hachette.
Gentilhomme, Yves, (1985), Essai d’approche microsystémique : théorie et pratique. Application dans le domaine des sciences du langage, Berne, Editions Lang.
Cardey, S., (1987), Traitement algorithmique de la grammaire normative du français pour une utilisation automatique et didactique, thèse d’état sous la direction de M. le Professeur Y.Gentilhomme, Université de Franche-Comté, Besançon, pages 1 à 52.
Cardey, S.(2003), Modélisation, systémique, traductibilité, BULAG, 28, Université de Franche-Comté, Besançon,.
Cardey, S., Greenfield, P., (2002), Systemic Language Analysis and Processing In actes de la Conférence internationale sur Language, Brain and Computation, 3-5 Octobre 2002, Venise, Italie
Blachère R. et Gaudefroiy-Demombynes M., (2004), Grammaire de l’arabe classique, Paris : Maisonneuve et Larose.
Neyreneuf Michel, Al-Hakkak Ghalib, (1996), Grammaire active de l’arabe, Paris : Le Livre de Poche, collection « Les langues modernes ».
Daniel Durand, (1979), La systémique, PUF «Que sais-je ?» n° 1795. Rosnay, J., (1975), Le macroscope : vers une vision globale, Paris : Seuil.
Ludwig von Bertalanffy, K (1980), Théorie générale des systèmes, Bordas-Dunod. Kocourek R.(1982) La langue française de la technique et de la science, Wiesbaden.
Badawi, E., Carter, M. et Gully, A., (2004), Modern Written Arabic. A comprehensive Grammar. London and New York, Routledge, Collection Comprehensive Grammars.
Gifas, (1990), Guide du rédacteur, Groupement des Industries Françaises Aéronautiques et Spatiales, Paris.
Chairet, Mohamed, (1996), Fonctionnement du système verbal en arabe et en français, Orphys, Paris.
Condamines, A., (2008). Peut-on prévenir le risque langagier dans la communication écrite ? In P. Vergely (dir.) Langage et Société, Communiquer au travail en situation de risque, 2008/3, n° 125, 77-97.
Seleskovitch Danica et Lederer Marianne, (1986), Interpréter pour traduire, Didier érudition, paris.
Lerat, Pierre, (1995), Les langues spécialisées, PUF, Paris.
Heurley, L., (2001), Compréhension et utilisation de textes procéduraux : l’effet de l’ordre de mention des informations, Revue Française de Linguistique Appliquée 2001/2, Volume VI, pp. 29-46.
Tesnière, Lucien, (1959), Eléments de syntaxe structurale, Klincksieck, Paris.
AECMA, (1989), A guide for the preparation of aircraft maintenance documentation in the international aerospace maintenance language, Association Européenne des Constructeurs de Matériel Aérospatial, Paris.
El-Dahdah, Antoine, (1991), Dictionnaire de la grammaire arabe universelle, arabe-français, Librairie du Liban.
Riegel, Martin, Pellat, Jean-Christophe & Rioul, René, (1994), Grammaire méthodique du français, Paris : Presses Universitaires de France.
Abi Aad, A., (2001), Le système verbal de l’arabe comparé au français. Paris : Maisonneuve et Larose.