UNIVERSITÉ MOHAMMED V de RABAT
FACULTÉ DES SCIENCES
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
N° d’ordre : 2819
Thèse de Doctorat
Présentée par
Sara BAKKALI
Titre
Gestion de la Qualité de Service de Bout en Bout dans les Réseaux
Inter-domaines
Discipline : Informatique
Spécialité : Réseaux
Soutenue le 12 décembre 2015, devant le jury composé de :
Président :
Bouabid EL OUAHIDI PES, FSR, Rabat.
Examinateurs :
Zohra BAKKOURY PES, EMI, Rabat.
Ahmed BATTAS PES, INPT, Rabat.
Saiida LAZAAR PH, ENSA, Tanger.
Hafssa BENABOUD PH, FSR, Rabat.
Mouad BEN MAMOUN PH, FSR, Rabat.
Je tiens à exprimer ma gratitude à tous les membres de ma famille et mes amis.
En particulier je remercie ma mère et mon père pour leur amour, leurs efforts, leurs sacrifices, leurs soutiens sans limites et aussi pour avoir financé de si longues études, je leur resterai toujours reconnaissante.
Je remercie aussi mon mari et mes frères pour m’avoir soutenue toujours avec amour, et m’avoir donnée le goût de savourer ma réussite après si longues et si difficiles années de thèse. Je tiens à remercier également Madame Fatima Sijilmassi Idrissi, Monsieur Mohammed Senhaji, Madame Meryem Senhaji et Monsieur Mohammed Toummini qui n’ont pas cessé de m’encourager et de prier pour moi.
A ma mère, A mon père A mon mari A mes frères Un grand merci à tous.
Les travaux présentés dans le mémoire ont été effectués au sein du Laboratoire De Recherche en Informatique (LRI) à la faculté des sciences de Rabat sous la direction du Pr. Mouad BEN MAMOUN et le co-encadrement du Pr. Hafssa BENABOUD.
J’adresse tous mes remerciements à mon Directeur de Thèse Pr. Mouad BEN MA-MOUN pour avoir dirigé les travaux de ma thèse et également m’avoir orientée et conseillée durant les années de ma recherche.
Je tiens à exprimer tous mes remerciements à mon co-encadrante Pr. Hafssa BENA-BOUD pour m’avoir encadrée et aidée durant les années de ma thèse.
Je tiens également à remercier le président du jury le Professeur Bouabid EL OUA-HIDI, Professeur d’Enseignement Supérieur à la Faculté des Sciences de Rabat, pour avoir accepté de présider le Jury de ma soutenance ainsi que de rapporter cette thèse .
Je remercie aussi Madame Saiida LAZAAR, Professeure Habilitée à l’École Nationale des Sciences Appliquées de Tanger, qui m’a fait l’honneur d’accepter d’être rapporteur et examinateur de cette thèse.
Mes remerciements vont aussi à Madame Zohra BAKKOURY, Professeure d’Ensei-gnement Supérieur à l’École Mohammadia des Ingénieurs à Rabat, qui m’ont honorée en acceptant d’être examinateur.
Je tiens également à remercier Monsieur Ahmed BATTAS, Professeur d’Enseignement Supérieur à l’Institut National des Postes et Télécommunications à Rabat pour avoir accepté d’être examinateur.
Je tiens également à exprimer ma gratitude au Pr. Fouzia OMARY directrice du La-boratoire de Recherche en Informatique (LRI) de la Faculté des Sciences de Rabat.
Je tiens aussi à remercier le Centre National pour la Recherche Scientifique et Technique (CNRST) pour m’avoir attribuée la bourse de mérite dont j’ai bénéficié pendant trois années et qui m’a permis de mener mes recherches dans de bonnes conditions.
Mes remerciements vont également à l’Agence Universitaire de Francophonie et au Pr. José ROLIM, Directeur du Centre Universitaire d’Informatique à Genève, pour m’avoir accordée une bourse de mobilité pour un séjour scientifique de trois mois au sein du CUI en Suisse.
Avec l’évolution que connait l’utilisation d’Internet aujourd’hui s’exposent différents problèmes. L’un de ces principaux problèmes concerne le routage inter-domaine tout en garantissant une Qualité de Service (QoS). En effet, les réseaux IP ont été initialement conçus pour fournir un service au mieux (best-effort) pour la livraison de paquets de données et pour s’exécuter sur pratiquement tous les supports de transmission réseau et plate-formes système. Mais par la suite, ces réseaux devaient gérer de nouveaux services multimédia variés à forte demande en termes de délai de transmission, de taux de pertes ou de gigue, comme les transmissions vidéo, la Voix sur IP et les applications distribuées, etc. Ces services nécessitent la garantie d’une QoS pour fonctionner correctement et répondre aux besoins des clients. Plusieurs architectures telles que IntServ, Diffserv et MPLS ont été proposées pour assurer la QoS mais seulement pour les trafics circulant à l’intérieur d’un seul domaine ou Système Autonome (AS). Cependant, le problème de QoS dans un réseau contenant plusieurs ASs, qu’on peut appeler QoS inter-domaines, présente encore un défi et aucune solution n’a été standardisée jusqu’aujourd’hui.
Notre objectif dans cette thèse est d’étudier le problème de la gestion de QoS de bout-en-bout dans un environnement inter-domaines. Ainsi, nous présentons certains travaux de recherche concernant notre problématique. Ensuite, nous proposons un nouveau mé-canisme pour assurer la QoS inter-domaines nommé QoS-CMS. Notre mémé-canisme permet d’assurer une continuité de la QoS offerte au trafic lors d’un passage d’un domaine vers un autre. Nous traitons également la sécurité des communications dans notre mécanisme. Nous évaluons les performances de ce dernier à travers des simulations de plusieurs études de cas. Les résultats montrent que l’implémentation du mécanisme QoS-CMS permet d’as-surer la QoS pour les trafics inter-domaines et améliore leurs conditions d’acheminement. Enfin, nous montrons comment notre mécanisme peut être intégré dans les réseaux actuels et futurs.
Mots-Clès : Routage Inter-domaines, Qualité de service, Réseaux multi-domaines, DiffServ, Evaluation des performances.
IP networks were originally designed to provide a best effort service to deliver data packets and to run on any network transmission media and system platform. However, after there evoluation, they had to manage various multimedia services which have strong demand in terms of transmission time, loss ratio or jitter, such as video transmission, VoIP, distributed applications, etc. So, these services require the guarantee of (QoS) to function properly and meet the needs of customers. Then, IP networks have to ensure inter-domain routing with QoS. Thus, several architectures such as IntServ, DiffServ and MPLS have been proposed for ensuring QoS but only for traffic flowing within a single domain or AS. However, the QoS problem in a network containing multiple ASs as Internet (inter-domain QoS) still presents a challenge and no solution has been standardized to date.
Our objective in this thesis is to study the problem of managing QoS end-to-end in a inter-domain environment. Thus, we present some research work concerning our problem. Then we propose a new mechanism to ensure QoS inter-domain called QoS-CMS. Our mechanism ensures continuity of QoS guarantees for traffic during transition from one domain to another. We also discuss the security of communications in our mechanism. Also, we evaluate the performance of the new mechanism by simulating several case studies. The results show that the implementation of QoS-CMS mechanism ensures QoS for inter-domain traffic and improves their delivery conditions. Finally, we introduce a thinking to integrate our mechanism in current and future networks.
Key- words : Inter-domains Routing, Quality of service, Multi-domains Networks,
DiffServ, Evaluation of performances.
1 Introduction générale 8
1.1 Contexte général et problématique . . . 8
1.2 Objectif et contributions de la thèse . . . 9
1.3 Organisation du document . . . 10
2 La gestion de la qualité de service dans les réseaux IP 12 2.1 Introduction . . . 12
2.2 Le modèle IntServ . . . 14
2.2.1 Les services de IntServ . . . 14
2.2.2 Les mécanismes de IntServ . . . 15
2.2.2.1 Le contrôle d’admission (Admission Control) . . . 16
2.2.2.2 Le classificateur . . . 16
2.2.2.3 L’ordonnanceur de paquets (packet scheduler) . . . 16
2.2.3 Le protocole RSVP . . . 17
2.2.3.1 Les objets RSVP (RSVP Object) . . . 17
2.2.3.2 Le mode de fonctionnement de RSVP . . . 18
2.2.3.3 Les styles de réservation . . . 19
2.2.3.4 Les limites de IntServ . . . 20
2.3 Le modèle DiffServ . . . 20
2.3.1 L’architecture du modèle DiffServ . . . 21
2.3.1.1 Le domaine DiffServ . . . 21
2.3.1.2 Les nœuds de bordure et les nœuds intérieurs dans DiffServ . . . 22
2.3.2 La classification et le conditionnement de trafic . . . 22
2.3.2.1 La classification . . . 23
2.3.2.2 Les profils de trafic . . . 23
2.3.2.3 Le conditionnement de trafic . . . 24
2.3.3 Les comportements-par-saut (PHB) . . . 25
2.3.3.1 Le PHB par défaut . . . 26
2.3.3.2 Le PHB EF . . . 26
2.3.3.3 Le PHB AF . . . 26
2.3.4 Les limites du modèle DiffServ . . . 27
2.4 Le Modèle Multi-Protocol Label Switching (MPLS) . . . 28
2.4.1 L’architecture de MPLS . . . 28
2.4.2 Les éléments de base de MPLS . . . 29
2.4.2.1 Les étiquettes (Labels) . . . 29
2.4.2.2 Le routeur à commutation d’étiquettes (LSR) . . . 30
2.4.2.3 Le chemin à commutation d’étiquettes (LSP) . . . 31
2.4.2.4 Les protocoles de distribution d’étiquettes LDP . . . 32
2.4.2.5 La procédure de sélection de route . . . 34
2.4.3 La QoS dans MPLS . . . 34
2.4.3.1 MPLS-TE . . . 35
2.4.3.2 DiffServ dans MPLS . . . 36
2.5 Conclusion . . . 37
3 État de l’art des solutions de QoS en inter-domaines 39
3.1 Introduction . . . 39
3.2 Les solutions analytiques . . . 40
3.2.1 La formulation analytique du problème . . . 40
3.2.1.1 Notations et définitions . . . 40
3.2.1.2 Concepts . . . 41
3.2.1.3 Définition du problème Inter-MCP . . . 41
3.2.2 Les algorithmes de routage inter-domaines multi-contraintes . . . 42
3.2.2.1 Les algorithmes SAMCRA et H-MCOP . . . 42
3.2.2.2 L’algorithme inter-domaines MCP . . . 42
3.2.2.3 Les algorithmes pID-MCP et kpID-MCP . . . 43
3.2.2.4 L’algorithme ID-MCOP-MDR . . . 44
3.2.3 Un routage fiable avec garanties de QoS pour les réseaux multi-domaines . . . 45
3.2.3.1 PCE . . . 45
3.2.3.2 Les principes de l’approche . . . 47
3.2.4 Une approche Hybride pour le calcul de chemin inter-domaines multi-contraintes . 49 3.2.4.1 Le pré-calcul de chemins inter-domaines multi-contraintes . . . 50
3.2.4.2 L’architecture hybride . . . 51
3.2.4.3 L’algorithm HID-MCP . . . 51
3.2.5 Le Calcul de chemin multi-contraintes optimal en explorant plusieurs routes inter-domaines . . . 54
3.2.5.1 Les défis liés à l’exploration de multiples chemins inter-domaines . . . . 54
3.2.5.2 Un nouveau protocole pour le calcul de chemins multi-contraintes à travers plusieurs routes inter-domaines . . . 55
3.3 Les solutions techniques . . . 56
3.3.1 L’ingénierie de trafic inter-domaines de MPLS . . . 56
3.3.1.1 Les Techniques de distribution des informations d’accessibilité et d’ingé-nierie de trafic . . . 56
3.3.1.2 Les Techniques de calcul de chemins LSPs . . . 57
3.3.1.3 Les Techniques de signalisation des LSPs . . . 58
3.3.2 Une extension de BGP utilisant l’algorithme d’exploration aveugle . . . 58
3.3.2.1 La description du principe de l’algorithme . . . 59
3.3.2.2 Le nombre de messages échangés . . . 59
3.3.2.3 Les avantages et les limites . . . 60
3.3.3 Le projet MESCAL . . . 61
3.3.3.1 Les modèles de QoS du projet MESCAL . . . 61
3.3.3.2 L’architecture fonctionnelle de MESCAL . . . 62
3.3.3.3 Les options d’implémentation de l’architecture MESCAL . . . 63
3.3.4 L’échange inter-domaines de SLA . . . 63
3.3.4.1 La description du sous-type SLA de l’attribut QoS . . . 64
3.3.4.2 Générer les notifications SLA . . . 64
3.3.4.3 La gestion de l’attribut SLA . . . 65
3.4 Conclusion . . . 66
4 Mécanisme pour la gestion de la QoS en inter-domaines 68 4.1 Introduction . . . 68
4.2 Présentation du mécanisme QoS-CMS . . . 69
4.2.1 Le principe de fonctionnement . . . 69
4.2.2 La classification en intra-domain . . . 70
4.2.3 La structure de la table CT . . . 71
4.2.4 L’envoi des informations des routeurs au serveur CM . . . 71
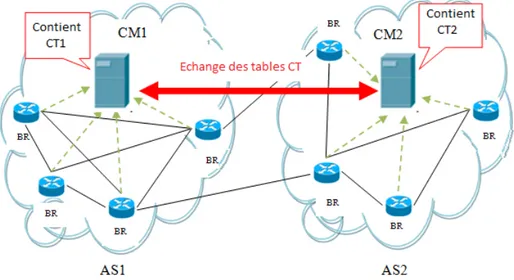
4.2.5 L’échange des tables CT entre les serveurs CM . . . 71
4.2.6 La Diffusion des Tables CT . . . 73
4.2.7 L’implémentation du mécanisme . . . 73
4.3 Sécurité du mécanisme . . . 73
4.3.1 Les problèmes de sécurité . . . 74
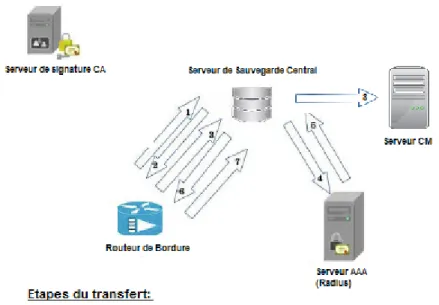
4.3.1.1 La communication entre les routeurs de bordure et le serveur CM . . . . 74
4.3.2 Les solutions proposées pour la sécurité du mécanisme QoS-CMS . . . 75
4.3.2.1 La communication entre les routeurs de bordure et le serveur CM . . . . 75
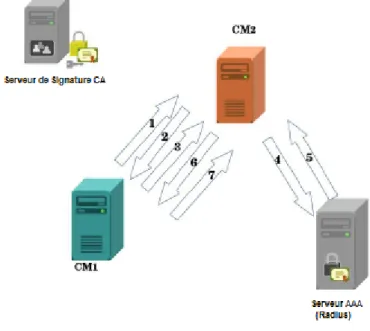
4.3.2.2 L’échange entre les serveurs CM Voisins . . . 77
4.4 Conclusion . . . 78
5 Simulation du mécanisme QoS-CMS 80 5.1 Introduction . . . 80
5.2 Étude de cas n° 1 . . . 81
5.2.1 La topologie et la configuration des scénarios . . . 81
5.2.2 les résultats de simulation . . . 82
5.3 Étude de cas n° 2 . . . 85
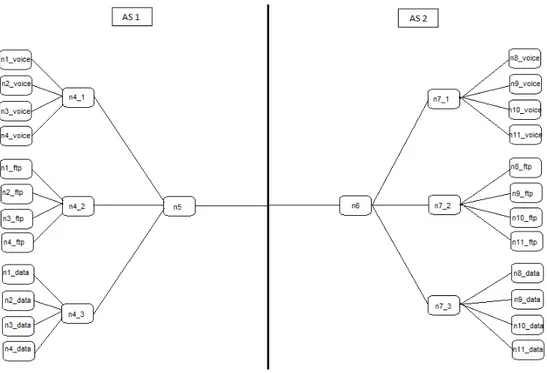
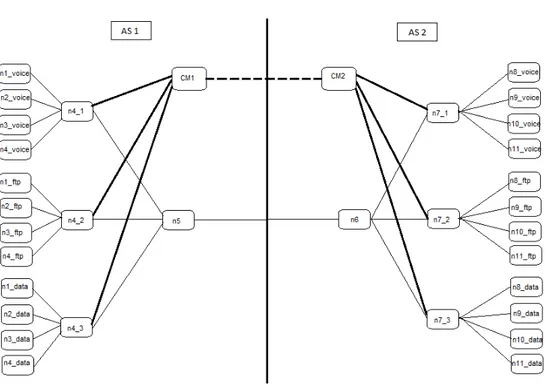
5.3.1 La Topologie des scénarios . . . 85
5.3.2 La Configuration des paramètres de QoS . . . 86
5.3.3 Les résultats de la simulation . . . 88
5.3.3.1 Le trafic voix . . . 88
5.3.3.2 Le trafic FTP . . . 89
5.3.3.3 Le trafic de données . . . 89
5.4 Étude de cas n° 3 . . . 91
5.4.1 La Configuration des Paramètres de QoS . . . 92
5.4.2 Les résultats de la simulation . . . 93
5.4.2.1 Le trafic voix . . . 93
5.4.2.2 Le Trafic FTP . . . 94
5.4.2.3 Le trafic de données . . . 95
5.4.2.4 Analyse des résultats et conclusion . . . 95
5.5 Étude de cas n° 4 . . . 97
5.5.1 La topologie des scénarios . . . 97
5.5.2 La configuration des paramètres de QoS . . . 98
5.5.3 Les résultats de la simulation . . . 99
5.5.3.1 Le trafic voix . . . 99
5.5.3.2 Le trafic de données . . . 100
5.6 Conclusion . . . 102
6 Intégration du QoS-CMS dans le protocole BGP et l’architecture SDN 103 6.1 Introduction . . . 103
6.2 Intégration du mécanisme QoS-CMS au protocole BGP . . . 103
6.2.1 Présentation du protocole BGP . . . 103
6.2.1.1 Le fonctionnement de BGP . . . 104
6.2.1.2 Les messages BGP . . . 104
6.2.1.3 Les attributs de chemin . . . 105
6.2.1.4 Le processus de sélection de chemin . . . 105
6.2.2 Intégration du mécanisme QoS-CMS au processus de sélection de routes de BGP . 106 6.2.2.1 Définition d’un nouvel attribut de chemin . . . 106
6.2.2.2 Le traitement des erreurs concernant l’attribut «QoS_agrmt» . . . 107
6.2.2.3 Modification de l’algorithme de « breaking tie » . . . 107
6.3 Intégration du mécanisme QoS-CMS dans un réseau SDN . . . 108
6.3.1 Présentation de l’approche SDN . . . 108
6.3.1.1 Concept et avantages de SDN . . . 108
6.3.1.2 L’architecture SDN . . . 109
6.3.1.3 Structure du plan de contrôle : centralisé ou distribué . . . 110
6.3.2 Intégration du serveur CM dans l’architecture SDN . . . 112
6.3.3 L’échange entre les contrôleurs SDN . . . 113
6.4 Conclusion . . . 113
7 Conclusion Générale 115 Liste des Acronymes . . . 118
2.1 Les éléments de IntServ implémentés dans chaque nœud du réseau [86] . . . 15
2.2 La structure du champ DS [73] . . . 23
2.3 La structure d’un classificateur et d’un conditionneur de trafic [17] . . . 25
2.4 L’architecture MPLS [82] . . . 29
2.5 L’étiquette MPLS [82] . . . 29
3.1 Le problème Inter-MCP[38] . . . 42
3.2 Les blocs de l’architecture de pré-calcul de chemins[38] . . . 50
3.3 Les blocs de l’architecture hybride [39] . . . 52
3.4 Le nombre de messages échangés dans l’algorithme d’exploration aveugle[98] . . . 60
3.5 Le modèle commercial de MESCAL[46] . . . 61
3.6 Le format du message SLA[85]. . . 65
4.1 Le mécanisme de gestion de QoS en inter-domaines . . . 70
4.2 Le format du message d’identification . . . 72
4.3 Le format du « Announcement message » . . . 72
4.4 Sécurisation de la communication entre les routeurs de bordure et le serveur CM . . . 76
4.5 Sécurisation de la communication entre les Serveurs CM voisins . . . 78
5.1 La topologie de l’étude n° 1 . . . 81
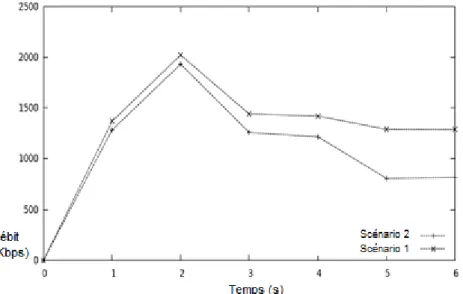
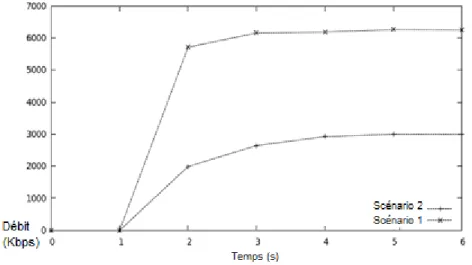
5.2 Les variations du débit pour le trafic ftp dans l’étude de cas n°1 . . . 83
5.3 Les variations du débit pour le trafic cbr dans l’étude de cas n°1 . . . 84
5.4 Les variations du taux de pertes pour le trafic ftp dans l’étude de cas n°1 . . . 84
5.5 Les variations du taux de pertes pour le trafic cbr dans l’étude de cas n°1 . . . 84
5.6 La topologie du premier scénario de l’étude n°2 . . . 86
5.7 La topologie du deuxième scénario de l’étude n°2 . . . 87
5.8 La variation du taux de pertes du trafic voix dans l’étude n° 2 . . . 88
5.9 La variation du délai du trafic voix dans l’étude n° 2 . . . 89
5.10 La variation du taux de pertes du trafic FTP dans l’étude n° 2 . . . 90
5.11 La variation du délai du trafic FTP dans l’étude n° 2 . . . 90
5.12 La variation du taux de pertes du trafic de données dans l’étude n° 2 . . . 91
5.13 La variation du délai du trafic de données dans l’étude n° 2 . . . 92
5.14 Les pourcentage d’amélioration du taux de pertes du trafic voix dans l’étude n°3 . . . 93
5.15 Les taux d’amélioration du délai du trafic voix dans l’étude n°3 . . . 94
5.16 Les pourcentages d’amélioration du taux de pertes du trafic FTP dans l’étude n°3 . . . . 94
5.17 Les taux d’amélioration du délai du trafic FTP dans l’étude n°3 . . . 95
5.18 Les pourcentages d’amélioration du taux de pertes du trafic de Données dans l’étude n°3 . 96 5.19 Les taux d’amélioration du délai du trafic de Données dans l’étude n°3 . . . 96
5.20 La Topologie des scénarios de l’étude n°4 . . . 98
5.21 Les variations du taux de pertes en fonction pour le trafic voix pour l’étude n°4 . . . 99
5.22 Les variations du délai en fonction pour le trafic voix pour l’étude n°4 . . . 100
5.23 Les variations du taux de pertes en fonction pour le trafic de Données pour l’étude n°4 . . 101
5.24 Les variations du délai en fonction pour le trafic de Données pour l’étude n°4 . . . 101
6.1 L’architecture SDN . . . 109
6.2 Communication entre contrôleurs SDN distribués . . . 111
2.1 L’entête du protcole RSVP[99] . . . 18
2.2 Les valeurs DSCP des classes AF [43] . . . 27
5.1 Les valeurs moyennes de bout en bout de l’étude de cas n°1 . . . 83
5.2 Les paramètres de QoS des classes dans le scénario 1 de l’étude n°1 . . . 87
5.3 Les paramètres de QoS des classes dans le scénario 2 de l’étude n°1 . . . 88
5.4 Les valeurs du paramètres CIR dans l’étude n°3 . . . 92
5.5 Les paramètres de QoS du scénario 1 de l’étude n°4 . . . 98
Introduction générale
1.1 Contexte général et problématique
Les réseaux IP étaient initialement conçus pour échanger de simples données (mail, FTP, etc), qui n’exigeaient aucune garantie concernant leurs conditions d’acheminement. En fait, les réseaux IP fonctionnaient selon le modèle « Best Effort », c’est à dire que le réseau fait de son mieux pour acheminer les données mais sans garanties ni de délai, ni de débit, ni même de leur arrivée à la destination.
Par la suite, ces réseaux ont rapidement évolué pour transporter des applications mul-timédia tels que les services de téléphonie, la vidéoconférence, le partage peer-to-peer, et d’autres applications plus exigeantes en termes de délai, de bande passante et de gigue. Ces dernières années ont été marquées par le grand essor des terminaux mobiles (tablettes et smartphones) qui ont facilité l’accès à Internet, et également l’apparition et l’utilisation massives des réseaux sociaux tels que facebook et tweeter ce qui a fait exploser la quantité de trafic transitant dans les réseaux, puisque le nombre d’utilisateurs qui se servent des applications multimédia pour assurer des services de partage de vidéos et de streaming s’est excessivement multiplié ; par exemple chaque minute 72 heures de vidéo sont télé-chargés sur YouTube, 277 000 tweets sont envoyés, 2.46 millions de contenus sont partagés sur facebook, et le 24 août 2015 un milliard de personnes se sont connectées sur facebook. Par ailleurs, chaque type de ces différentes applications exige des paramètres différents permettant de caractériser les garanties qui peuvent être fournies à chaque flux transitant par le réseau. Ces paramètres sont généralement la bande passante, le délai de bout en bout, la gigue ou le taux de perte des données. Ces paramètres représentent les critères de base de la QoS dans les réseaux IP.
Cependant, les réseaux IP initiaux ne répondaient plus aux exigences de ces applica-tions en termes de QoS. Ceci, a donc créé un grand besoin de techniques pour assurer la QoS dans les réseaux IP. Pour cela, plusieurs techniques et solutions ont été proposées dans la littérature pour assurer la QoS, notamment le modèle IntServ/RSVP (Integra-ted Services/ Resource reSerVation Protocol) [86, 21], le modèle DiffServ (Differentiated
Services) [17] et le modèle MPLS (MultiProtocol Label Switching)[82].
Cependant, un autre problème s’est posé concernant les trafics qui traversent plusieurs domaines ou Systèmes Autonomes (Autonomous System : AS). En effet, plusieurs services utilisent les ressources de différents opérateurs (ASs) afin de répondre aux besoins de leurs utilisateurs, et ainsi les trafics associés à ces services traversent différents ASs. Dans ce cas, les techniques proposées pour la QoS ne garantissent pas à elles seules la QoS de bout en bout pour ces trafics.
Ceci est principalement dû au fait que les contraintes de QoS, requises par le client et que l’opérateur s’engage à fournir dans l’accord de niveau de service SLA (Service Level Agreement) [19], sont définies dans les classes de service. Alors que la définition de ces
classes est assurée, dans la majorité des cas par l’administrateur de l’AS, elles sont donc spécifiques à chaque AS et valables uniquement dans cet AS. Ainsi, lors de la transition vers un autre domaine, la QoS offerte aux trafics risque de ne pas être la même que dans le domaine source. Par conséquent, la QoS requise par le client au début n’est pas fournie de bout en bout jusqu’à la destination.
Plusieurs chercheurs se sont intéressés à cette problématique dans le but d’assurer la QoS de bout-en-bout pour les trafics clients inter-domaines. Cette problématique constitue le principal sujet traité dans le cadre des travaux présentés dans cette thèse.
1.2 Objectif et contributions de la thèse
Dans ce travail de thèse, notre objectif est de traiter la problématique de garantie de la QoS de bout-en-bout dans un environnement inter-domaines, d’analyser les différentes solutions qui ont été proposées pour la traiter et de proposer d’autres solutions.
Pour cela, nous avons d’abord fait une étude sur les différentes solutions proposées dans la littérature traitant la QoS dans un environnement inter-domaines. Nous avons classé ces solutions en deux principales catégories [9] : les solutions théoriques (ou analytiques) qui
sont principalement basées sur des algorithmes pour le calcul d’un chemin qui satisfait les diverses contraintes imposées par les différents domaines traversés, et les solutions techniques qui sont principalement des extensions ou des améliorations des technologies et protocoles déjà opérationnels sur les réseaux comme le protocole MPLS ou BGP (Border Gateway Protocol) [81]. Dans notre étude, nous avons décrit des exemples de solutions
proposées dans chaque catégorie et discuter les avantages et les limites de chaque solution. Par la suite, nous avons proposé une nouvelle solution pour garantir la QoS dans un environnement inter-domaines [10]. Notre solution baptisée QoS-CMS se base
principale-ment sur l’impléprincipale-mentation d’un serveur nommé serveur CM (Class Manager) dans chaque AS. Ce serveur est d’abord chargé de collecter les informations sur la QoS et les classes de services définies dans chaque AS, pour ensuite échanger ces informations entre les ASs voisins. Ceci permet d’assurer une continuité de la QoS offerte au trafic client traversant
différents AS de bout en bout jusqu’à sa destination finale. Plus précisément, chaque ser-veur CM communique d’abord avec les routeurs du domaine afin de récolter les différentes informations sur la QoS définie en intra-domaine, et ensuite il enregistre ces informations dans des tables nommées tables CT (Class Table). On note, que la communication entre les serveurs CM voisins est assurée via un ensemble de messages, dont nous avons défini les formats.
Ensuite, nous avons procédé à l’évaluation des performances de notre mécanisme QoS-CMS afin de prouver l’intérêt de son déploiement [11]. Cette évaluation s’est faite en
utilisant le simulateur ns2 (network simulator), qui est largement utilisé dans la commu-nauté de recherches en réseaux. Nous avons ainsi établi différents scénarios en variant les topologies, les types de trafic et les paramètres de QoS. Comme nous allons voir plus loin dans ce manuscrit, les résultats de simulation montrent que l’implémentation du mécanisme QoS-CMS permet d’améliorer la QoS dans les différents scénarios considérés. Par ailleurs, actuellement et avec le développement de la cybercriminalité et des at-taques contre les réseaux, nous avons pensé qu’il est indispensable de traiter la sécurité dans notre mécanisme. En effet, pendant la communication entre les routeurs et le serveur CM toutes les informations concernant la QoS offerte aux différents trafics clients sont envoyés en clair, ce qui signifie qu’elles peuvent être facilement interceptées par des tiers non autorisés. Aussi, l’échange des tables CT entre les CM voisins pourra représenter une vulnérabilité du mécanisme. Pour cela nous avons étudié les problèmes de sécurité de notre mécanisme, et nous avons proposé quelques solutions qui peuvent les résoudre et permettre ainsi d’assurer la sécurité des communications, d’une part, entre les routeurs du domaine et le serveur CM, et d’autre part, entre les serveurs CM voisins [13].
Enfin, nous avons commencé une réflexion sur la manière d’implémenter notre méca-nisme QoS-CMS dans les réseaux actuels et futurs. Ainsi, nous avons étudié son intégration d’une part dans le protocole BGP qui est le seul protocole utilisé dans internet pour le routage inter-domaines, et d’autre part, dans les réseaux SDN ( Software Defined Networ-king) qui représentent une grande tendance qui est actuellement en plein développement.
1.3 Organisation du document
Ce mémoire de thèse est composé de cinq chapitres :
Étant donné que nos travaux sont consacrés à la QoS, dans le premier chapitre nous allons d’abord élaborer une description de l’architecture et du fonctionnement des trois modèles de base pour assurer la QoS intra-domaine dans les réseaux IP à savoir le modèle IntServ, le modèle DiffServ et le modèle MPLS, et nous discuterons les avantages et les limites de chaque modèle.
Dans le deuxième chapitre nous présenterons les solutions qui ont été proposées pour la gestion de la QoS dans un réseau inter-domaines. La première partie de ce chapitre sera consacrée à la description de quelques solutions analytiques, notamment : l’approche de routage fiable avec des garanties de QoS pour les réseaux multi-domaines [88], l’approche
hybride pour le calcul de chemins inter-domaines multi-contraintes [39], et une nouvelle
méthode pour le calcul de chemin multi-contraintes optimal en explorant plusieurs routes inter-domaines[28]. La seconde partie sera destinée à présenter des solutions techniques,
parmi lesquels une extension de l’ingénierie de trafic MPLS au cas inter-domaines [35],
et une amélioration du protocole BGP présentée dans[98]. Nous présenterons, également,
d’autres solutions qui introduisent de nouveaux principes comme l’approche décrite dans
[46], et le nouveau mécanisme pour l’échange de SLA présenté dans[85].
Dans le troisième chapitre nous donnerons une description détaillée du mécanisme QoS-CMS que nous avons proposé pour assurer la QoS de bout en bout pour les trafics inter-domaines. Ainsi, nous présenterons son principe, les entités nécessaires pour son fonctionnement notamment la le serveur « Class Manager », la table CT et les différents types de messages échangés entre les différents nœuds participant au mécanisme, et les phases de son déroulement. En outre, nous présenterons les solutions proposées afin de sécuriser les échanges entre les différentes entités de notre mécanisme.
Dans le quatrième chapitre, nous allons présenter et décrire les topologies et les confi-gurations des différentes études de cas que nous avons considérées afin d’évaluer les per-formances de notre mécanisme. Nous allons par la suite présenter et analyser les résultats de simulation que nous avons obtenus.
Finalement, dans le cinquième chapitre, nous donnerons quelques idées et propositions pour l’implémentation de notre solution dans les réseaux IP actuels et futurs. Pour cela, nous expliquerons comment le mécanisme QoS-CMS pourra être pris en considération dans le processus de sélection de routes du protocole BGP, et comment il pourra être intégré dans une architecture SDN[68].
La gestion de la qualité de service dans
les réseaux IP
Avant de présenter l’état de l’art sur la QoS en inter-domaines, nous pensons qu’il est plus judicieux d’introduire d’abord la notion de QoS, ainsi que les différents standards qui ont été proposés afin d’assurer la QoS dans les réseaux IP. Ceci fera l’objectif de ce deuxième chapitre.
2.1 Introduction
La Qualité de Service (QoS) dans un réseau IP peut être définie comme la capacité du réseau à fournir un certain niveau de performances requis par une application afin qu’elle fonctionne correctement. Ces performances peuvent être exprimées par certains paramètres qui permettent de mesurer la QoS. Les paramètres de QoS les plus utilisés sont les suivants :
— Le Délai : qui exprime le temps écoulé depuis l’émission d’un paquet par une source,
jusqu’à sa réception par la destination.
— La gigue : qui exprime les variations des délais des paquets envoyés à partir d’une
source vers une destination.
— Le débit : qui exprime la vitesse de transfert de données entre deux points
d’extré-mité.
— Le taux de perte de paquets : qui exprime le nombre des paquets perdus par unité
de temps.
Au début, les réseaux IP étaient destinés à transporter un seul type de trafic, qui est le trafic de données, en offrant un service connu sous le nom de best-effort qui permet de transmettre les flux de données sans aucune garantie, et dans des conditions d’achemine-ment non-spécifiées qui dépendent seuled’achemine-ment de la charge du réseau et non des besoins requis par les applications. Par la suite, les réseaux IP ont évolué pour transporter de nouvelles applications notamment les applications en temps réel comme la VoIP, la vidéo
conférence, les applications multimédias. Ces applications ont généralement des exigences en termes de débit, de délai, de gigue, et de taux de perte, ou peuvent parfois nécessiter une priorité relative pour l’accès aux ressources du réseau, ce qui ne pouvait pas être garanti par les réseaux IP initiaux. Ce problème peut être résolu en prévoyant plus de ressources réseaux que celles requises par les différentes applications, ou ce qu’on appelle un sur-dimensionnement des ressources réseau. Cependant, c’est une solution couteuse pour les opérateurs réseau qui peut être très difficile à assurer. En outre, les opérateurs réseau doivent contrôler le partage des ressources réseau entre ces différentes applications. La solution qui permet de répondre aux exigences des applications et aux objectifs des opérateurs est la mise en œuvre d’une technologie qui implémente et gère la QoS dans les réseaux IP.
Afin de répondre à cet objectif, différentes approches de QoS ont été proposées. Les plus connus, et les plus déployées sont : le modèle IntServ, le modèle DiffServ , et l’architecture MPLS.
Le modèle IntServ traite chaque flux de trafic individuellement et lui garantit les contraintes de QoS qu’il exige pour qu’il soit acheminé dans le réseau dans des condi-tions appropriées. Pour cela, IntServ doit réserver les ressources nécessaires au niveau de chaque nœud du réseau traversé par ce flux. La réservation de ressources est assurée en utilisant le protocole RSVP.
Le modèle DiffServ utilise les fonctions principales de gestion de QoS, au niveau des nœuds de bordure du réseau. Lorsque les paquets sont classés à la périphérie du réseau, ils sont transférés dans le réseau selon un traitement spécifique prédéfini appelé PHB (Per-Hop Behavior) [24, 43], qui leur garantit les différentes contraintes de QoS requises. Aussi, Le modèle DiffServ n’implémente aucun protocole de signalisation.
Finalement, le modèle MPLS offre à un réseau la possibilité de diriger les données d’un nœud vers un autre sur la base d’une courte étiquette au lieu d’utiliser les adresses réseau longues, ce qui permet d’éviter les recherches complexes dans la table de routage. Dans MPLS, chaque paquet est marqué par une étiquette dès son entrée dans le réseau de l’opérateur, et cette étiquette détermine le chemin prédéfini que le paquet va suivre. Les chemins, appelés chemins à commutation d’étiquettes (LSP : Label Switeched Path) [53], permettent aux fournisseurs de services de décider, à l’avance, ce que sera la meilleure façon de router certains types de trafic dans un réseau privé ou public, ceci permet de détourner et de rediriger le trafic en cas de défaillances de liaison, ou de congestion. Ainsi, MPLS garantit un certain niveau de QoS, car les opérateurs pourront gérer différents types de flux de trafic selon leur priorité et le niveau de services qu’ils requièrent.
L’objectif de ce chapitre est de présenter une description de l’architecture et du fonc-tionnement de ces trois modèles de QoS, tout en relevant leurs avantages et leurs limites.
2.2 Le modèle IntServ
Le premier modèle, qui a été proposé par l’IETF (Internet Engineering Task Force) dans la RFC 1633 [20], est le modèle IntServ. Ce modèle fournit un moyen de satisfaire les différentes contraintes de QoS exigées par les applications, et cela à travers la gestion directe des ressources du réseau ce qui permet de fournir la QoS appropriée à des flux de paquets bien spécifiques du trafic client selon le modèle de service.
Le modèle IntServ comprend deux sortes de services destinés au trafic temps réel : service garanti et service prédictif. Pour assurer ces deux types de services, IntServ se base sur deux principaux mécanismes pour établir et maintenir la QoS : « le contrôle de flux» et « la réservation de ressources ». Le contrôle de flux englobe quatre principales fonctions qui doivent être implémentées par les différents nœuds du réseau : l’ordonnan-cement des paquets (scheduling), la classification des paquets, la suppression des paquets (packet dropping) et le contrôle d’admission. La réservation de ressources est assurée par le protocole de signalisation RSVP.
Les différents services assurés par IntServ, les différents mécanismes implémentés par ce modèle ainsi que le protocole RSVP seront présentés en détails dans le reste de cette section.
2.2.1 Les services de IntServ
Pour différencier les flux des différentes applications circulant dans le réseau, le modèle IntServ propose deux types de services : garanti et prédictif.
— Le service garanti (Guaranteed Service : GS) : ce type de service garantit la
réserva-tion de la bande passante nécessaire, et assure que les datagrammes vont atteindre leurs destinations dans un délai limité et qu’ils ne seront pas rejetés en cas de sa-turation des files d’attente. Ceci à condition que les flux de trafic ne dépassent pas les paramètres spécifiés à l’avance. Notons que ce type de service est attribué aux applications temps réel qui ont des exigences très strictes en termes de délai. Ce-pendant, il ne permet pas de minimiser la gigue qui exprime la différence entre le délai maximal et le délai minimal.
— Le service prédictif/contrôle de charge (Controlled load) : dans ce type de service,
on assure que la majorité du flux de paquets transmis sera délivrée avec succès aux destinations, et donc le pourcentage des paquets non transmis exprimé par le taux de pertes doit être égal au taux d’erreurs de base du support de transmission. Ce type de service est destiné principalement aux applications qui n’exigent pas un délai faible ou limité mais exigent un faible taux de pertes, comme le transfert de fichiers ou la messagerie.
Figure 2.1 – Les éléments de IntServ implémentés dans chaque nœud du réseau [86]
2.2.2 Les mécanismes de IntServ
Le modèle IntServ se traduit par l’implémentation au niveau de chaque nœud du réseau des éléments présentés sur la figure 2.1.
Comme le montre la figure, chaque nœud est divisé en deux blocs fonctionnels : le bloc de transmission de chemin assuré par les éléments présentés en-dessous de la ligne horizontale, et le bloc d’algorithmes de fond (background code) exécutés par les éléments présentés en-dessus de la ligne horizontale.
Le bloc de transmission de chemin est composé de trois sections : le pilote d’entrée (input Driver), le classificateur et le pilote de sortie (output Driver) qui implémente l’or-donnanceur de paquet (Packet Scheduler).
Les algorithmes de fond (background code) sont chargés dans la mémoire du routeur et exécutés par son CPU. L’agent de routage (routing agent) implémente un protocole de routage et construit une base de données de routage. L’agent de réservation de ressource implémente le protocole RSVP qui sera détaillé dans la suite de cette section. Quand l’unité de contrôle d’admission (admission control) accorde une nouvelle demande, les modifications appropriées seront apportées à la base de données du classificateur et de l’ordonnanceur pour assurer la QoS demandée.
Enfin, chaque routeur prend en charge un agent de gestion de réseau. Cet agent doit être en mesure de modifier les bases de données du classificateur et de l’ordonnanceur de paquets pour mettre en place le partage de lien contrôlé et établir des politiques de contrôle d’admission.
Dans la suite de cette sous-section, on va présenter en détails les trois principaux éléments sur lesquels se base le modèle IntServ : le contrôle d’admission, le classificateur,
et l’ordonnanceur de paquets.
2.2.2.1 Le contrôle d’admission (Admission Control)
Afin d’assurer que les engagements de QoS puissent être remplis par les éléments du réseau, il est nécessaire que des ressources soient explicitement demandées, ces demandes peuvent être refusées si les ressources ne sont pas disponibles. La décision sur la disponi-bilité des ressources est appelé contrôle d’admission.
Ce mécanisme implémente un algorithme de décision qui permet de déterminer si la demande de QoS établie par un nouveau flux peut être accordée sans influencer les réservations de ressources et garanties de QoS déjà existantes.
Le contrôle d’admission est invoquée au niveau de chaque nœud pour prendre une décision locale d’accepter ou de rejeter une demande de QoS. L’algorithme de contrôle d’admission doit être compatible avec le modèle de service, et il fait partie du contrôle de trafic.
2.2.2.2 Le classificateur
Pour permettre et assurer le contrôle de trafic chaque paquet entrant doit être affecté à une classe de service bien précise. Les paquets appartenant à la même classe sont traités de la même manière par l’ordonnanceur de paquet. Cette opération est assurée par le classificateur.
Le choix de la classe peut se faire selon l’entête initiale du paquet et/ou selon un numéro de classification supplémentaire ajouté à chaque paquet. Ainsi, le classificateur dans son choix peut se baser sur l’adresse source du paquet, le numéro de protocole ou même le numéro de port. Donc, on pourra reconnaitre par exemple un flux video-streaming à travers un numéro de port bien défini dans son entête UDP, ou alors identifier un type de flux en fonction des numéros de port source et destination.
Une classe est une abstraction qui peut être locale à un routeur particulier, cela veut dire que le même paquet peut être classé différemment par les différents routeurs qu’il traverse tout au le long du chemin.
2.2.2.3 L’ordonnanceur de paquets (packet scheduler)
L’ordonnanceur de paquets gère l’acheminement des différents flux de paquets en uti-lisant un ensemble de files d’attente et d’autres mécanismes tels que les temporisateurs. L’ordonnanceur doit être implémenté au niveau du point où les paquets sont mis en at-tente, et ça correspond au protocole de couche de liaison. Le principal objectif de l’ordon-nancement des paquets est de réorganiser la file d’attente de sortie. Plusieurs algorithmes et approches ont été proposés pour la gestion de la file d’attente de sortie.
L’approche la plus simple est le système de priorité, dans lequel les paquets sont classés par ordre de priorité, et les paquets qui ont la priorité la plus élevée quittent la file d’attente en premier. Ce fait pourra donner à certains paquets une priorité absolue par rapport à d’autres, puisque si le nombre de paquets de priorité supérieure est assez suffisant pour remplir la file d’attente les paquets de priorité inférieure ne pourront pas être transmis.
L’algorithme Round-Robin et ses différentes améliorations ont été proposes également pour l’ordonnancement des paquets en assurant aux différentes classes une part de la bande passante du lien. Il existe d’autres approches plus complexes pour la gestion des files d’attente comme WFQ (Weighted Fair Queuing) qui assure à chaque classe une partie de la bande passante et partage l’excès de bande passante de façon équitable entre les différentes classes.
2.2.3 Le protocole RSVP
Le modèle IntServ définit une architecture capable de prendre en charge la QoS indé-pendamment du protocole IP. Pour cela, IntServ se base sur un protocole spécifique de signalisation appelé RSVP, comme décrit dans la RFC 2210 [99]. RSVP permet d’assurer l’allocation dynamique de la bande passante et de garantir un délai limité pour les appli-cations ayant des contraintes de QoS. Le protocole est opérationnel au dessus du protocole IP et donc il occupe le niveau de la couche transport dans la pile des protocoles, cepen-dant il ne transporte pas des données clients comme ICMP (Internet Control Message Protocol) [78]. Dans la suite de cette sous-section, on va présenter les objets du protocole RSVP ( RSVP Object), et par la suite, le mode de fonctionnement de ce protocole.
2.2.3.1 Les objets RSVP (RSVP Object)
Plusieurs types d’informations doivent être transportés entre les applications et les élé-ments de réseau pour invoquer correctement les services QoS. Chaque type d’informations est transporté par un objet RSVP spécifique. Les trois types d’objets sont les suivants :
1. L’objet RSVP SENDER_TSPEC transporte les informations sur le trafic (expé-diteur TSpec) générées par chaque source de données au sein de la session RSVP. L’objet ne peut pas être modifié tout au long de son chemin dans le réseau, et il est transmis aux nœuds intermédiaires et aux applications réceptrices.
2. L’objet RSVP ADSPEC transporte les informations générées par les sources de
données ou les nœuds intermédiaires du réseau. Il est transmis en aval vers les ré-cepteurs, et peut être utilisé et mis à jour par les différents nœuds du réseau avant d’être transmis aux applications réceptrices. Ces informations comprennent les pa-ramètres décrivant les propriétés du chemin de données, y compris la disponibilité
Version Flags Type du Message Checksum Send_TTL Réservé Longueur du Messge
Table 2.1 – L’entête du protcole RSVP[99]
de services QoS spécifiques, et les paramètres requis par les services QoS pour fonc-tionner correctement.
3. L’objet RSVP FLOWSPEC transporte les informations concernant les demandes
de réservation (Receiver_TSpec et RSpec) générées par les récepteurs données. Les informations contenues dans les flux FLOWSPEC sont transportées en amont vers les sources de données, et peuvent être utilisées ou mises à jour au niveau des nœuds intermédiaires avant d’arriver à l’application émettrice.
2.2.3.2 Le mode de fonctionnement de RSVP
Dans le protocole RSVP, le récepteur est responsable de l’initiation d’une demande de réservation. Un récepteur est supposé apprendre les « FLOWSPEC » offerts par l’émetteur par un mécanisme de niveau supérieur, il génère alors son propre« FLOWSPEC » et le fait propager vers l’émetteur tout en réservant les ressources nécessaires dans chaque routeur traversé tout au le long du chemin vers l’émetteur.
En général, une demande de réservation RSVP indique la quantité de ressources qui doit être réservée pour l’ensemble, ou un sous-ensemble de paquets dans une session bien précise. La quantité de ressources est spécifiée dans un objet « FLOWSPEC » tandis que le sous-ensemble de paquets, qui va recevoir ces ressources, est spécifié par un objet « FILTERSPEC ».
Après l’accord de l’unité de contrôle d’admission, le « FLOWSPEC » sera utilisé pour paramétrer une classe de ressources dans l’ordonnanceur de paquets, et le « FILTERS-PEC» sera instancié dans le classificateur de paquets pour affecter les paquets appropriés dans cette classe.
Après l’établissement d’une session, l’émetteur et le récepteur peuvent s’échanger sept types de messages, et chaque message est composé d’une entête de 64 bits et d’un ensemble d’objets en fonction du type de message. L’entête est constituée des champs présentés dans le tableau 2.1.
1. Version (4 bits) : pour indiquer la version du protocole RSVP. 2. Flags (4 bits) : non utilisé.
3. Type de Msg (8 bits) : pour indiquer le type du message (de 1 à 7 selon le type de
messages présentés ci-après).
4. Checksum (16 bits) : pour le contrôle d’erreurs.
5. Send_TTL (8 bits) : pour indiquer la valeur du TTL IP et la comparer avec le TTL
6. Longueur (16 bits) : pour indiquer la longueur globale du message en octets (en-tête
et objets).
Les sept types de messages RSVP sont les suivants :
1. Path : le premier message envoyé par l’émetteur pour mentionner la liste des rou-teurs traversés jusqu’au récepteur et établir ainsi le chemin qui sera suivi, par la suite, par les demandes de réservation.
2. Resv : pour initier une demande de réservation, il inclut les objets « FLOWSPEC » et « FILTERSPEC ».
3. PathErr : pour annoncer une erreur au niveau du chemin.
4. ResvErr : pour annoncer une erreur au niveau de la demande de réservation.
5. PathTear: pour demander aux routeurs d’annuler les états concernant un chemin spécifique.
6. ResvTear : pour demander aux routeurs d’annuler les états d’une réservation spé-cifique et fermer ainsi la session.
7. ResvConf : message de confirmation envoyé par un nœud intermédiaire (le routeur) au demandeur de la réservation.
2.2.3.3 Les styles de réservation
RSVP offre plusieurs «styles» de réservation qui déterminent la manière dont les be-soins en ressources de plusieurs récepteurs sont regroupés dans les routeurs. Ces styles permettent d’assurer que les ressources réservées répondent plus efficacement aux be-soins de l’application. Actuellement, trois styles de réservation sont définis : «wildcard», «fixed-filter» et «dynamic-filter».
La réservation «wildcard» utilise un objet« FILTERSPEC » qui n’est pas spécifique à la source, alors, tous les paquets destinés à la destination associée (par la session) peuvent utiliser le même pool de ressources réservées. Ce style de réservation est utilisé pour les applications audio-conférence, où un nombre réduit de sources sont actives simultanément et peuvent partager l’allocation de ressources.
Les deux autres styles de réservation utilisent des objets « FILTERSPEC » qui sélec-tionnent des sources bien précises. Un récepteur peut souhaiter recevoir le flux de trafic d’un ensemble fixe de sources, ou bien demander au réseau de basculer entre plusieurs sources, en changeant dynamiquement son « FILTERSPEC ». Une réservation de style «fixed-filter» ne peut être modifiée sans re-consulter l’unité contrôle d’admission, alors que les réservations «dynamic-filter» permettent à un récepteur de modifier son choix de la source sans revenir vers l’unité de contrôle d’admission.
2.2.3.4 Les limites de IntServ
Comme nous avons expliqué, le modèle IntServ se base sur le protocole RSVP pour assurer les différentes contraintes de QoS exigées par les différents flux clients. Le proto-cole RSVP permet la réservation des ressources nécessaires pour chaque flux. Pour cela le protocole maintient des informations d’état sur chaque flux transitant sur le réseau. Ce point constitue l’inconvénient majeur de IntServ, puisque quand le nombre d’appli-cations augmente et donc le nombre de flux circulant dans le réseau augmente, alors le maintien d’informations d’état sur chaque flux devient difficile ce qui peut réduire les performances du réseau. Ceci pose des problèmes d’évolutivité du réseau et peut ainsi limiter l’implémentation de IntServ à grande échelle.
Aussi, parmi les inconvénients du modèle IntServ on peut noter la complexité du sys-tème, et l’importante charge supplémentaire que chaque nœud (routeur) du réseau doit supporter, puisque chaque nœud doit implémenter le protocole RSVP, et les différents mécanismes de contrôle d’admission, de classification et d’ordonnancement de paquet, cela peut également réduire les performances du réseau quand le nombre de nœud est important. L’apparition d’autres architectures plus simples, et qui reposent sur les mêmes principes d’étiquetage, de priorité des paquets et de classification des services tout en allégeant les opérations complexes de maintien d’informations d’état et de réservation de ressources, a réduit d’une façon remarquable l’implémentation de IntServ. Parmi ces architectures, on présente dans la section suivante le modèle DiffServ qui est considéré comme le principal concurrent de IntServ, mais aussi comme une adaptation de IntServ pour l’implémentation à grand échelle.
2.3 Le modèle DiffServ
Après avoir défini, le modèle Intserv qui permet d’assurer les différentes contraintes de QoS pour chaque flux client dans le réseau en se basant principalement sur le protocole RSVP, l’IETF a présenté le modèle DiffServ en 1998 dans les RFC 2474 [73] et 2475 [17]. DiffServ a été proposé pour pallier aux limites de IntServ que nous avons présenté dans la section précédente.
Le modèle DiffServ repose sur le principe d’agrégation des différents flux clients dans des classes de services (Class of Service : CoS) en fonction des contraintes de QoS qu’ils exigent. Les paquets appartenant à des classes spécifiques sont transmis en fonction d’un comportement par saut (PHB) associé à leur entête DiffServ (DiffServ Code Point : DSCP) [8] , cette entête est incluse dans le champ type de service (Type of Service :ToS) de l’en-tête de chaque paquet IP pour les paquets IPv4, et dans le champ Traffic Class pour les paquets IPv6.
Actuellement, le modèle DiffServ définit deux principaux types de PHB : le premier est Expedited Forwarding (EF) [24], il est destiné à offrir un service de type «ligne virtuelle louée» avec des garanties de débit et un délai limité. DiffServ prend également en charge
le comportement Assured Forwarding (AF) [43] qui présente un comportement similaire à un réseau à faible charge pour le trafic qui est en conformité avec le contrat de service. Le modèle DiffServ se base sur une architecture qui se compose de plusieurs éléments fonctionnels implémentés dans les différents nœuds du réseau. Ces éléments comprennent les fonctions de classification de paquets, et les fonctions de conditionnement de trafic qui regroupent : la mesure (meter), le marquage (marking), la régulation (shaping) et le contrôle/rejet de paquet (policing/dropping).
L’avantage de cette architecture est qu’elle permet d’assurer une certaine évolutivité du réseau en mettant en œuvre les fonctions complexes de classification et de condi-tionnement seulement au niveau des nœuds de bordures du réseau, et en appliquant des comportements par-saut (PHB) à des agrégats de trafic qui ont été marqués de façon appropriée en utilisant le champ DS dans les en-têtes IPv4 ou IPv6. Les PHB sont définis pour permettre un moyen raisonnablement précis d’allocation des ressources dans chaque nœud pour les flux de trafic concurrents. Grâce à ce mécanisme, les informations sur les flux de chaque application ou l’état de transmission de chaque trafic client, ne doivent pas être maintenues dans le cœur du réseau, ce qui rend DiffServ très adapté à l’implémen-tation à grande échelle. L’architecture de DiffServ et ses différents éléments ainsi que les différents PHB seront décrits en détails dans ce qui reste de cette section.
2.3.1 L’architecture du modèle DiffServ
L’architecture de DiffServ est basée sur un modèle simple où le trafic entrant dans un réseau est classé et éventuellement conditionné au niveau des nœuds de bordures de ce réseau, pour être affecté par la suite aux différents PHB définis dans le réseau. Chaque PHB global est identifié par un seul code DSCP. Dans le cœur du réseau, les paquets sont transmis selon le PHB associé à leur code DSCP. Dans cette sous-section, nous discutons les éléments clés dans une région DiffServ, les fonctions de classification et de conditionnement du trafic, et comment les services différenciés sont assurés grâce à la combinaison des fonctions de conditionnement du trafic et de la retransmission en fonction des PHB.
2.3.1.1 Le domaine DiffServ
Un domaine DiffServ (DS) est un ensemble contigu de nœuds DS qui fonctionnent avec une politique d’approvisionnement de services commune et un ensemble de PHB implémenté dans chaque nœud. Un domaine DS a une limite bien définie constituée par les nœuds de bordures DS qui classifient et éventuellement conditionnent le trafic entrant afin d’assurer que les paquets qui traversent le domaine sont marqués, de manière appropriée, pour être attribués à un PHB à partir des PHB définis dans le domaine. Les nœuds du domaine DS sélectionnent le PHB des paquets à partir de leur code DSCP. Le fait
d’avoir des nœuds qui ne supportent pas DS dans un domaine DS peut entrainer des performances imprévisibles et peut nuire à la capacité de satisfaire les accords de niveau de service (SLA) établis avec le client.
Un domaine DS se compose normalement d’un ou de plusieurs réseaux sous la direction de la même entité d’administration ; par exemple, l’intranet d’une organisation ou le réseau d’un fournisseur d’accès Internet (ISP : Internet Service Provider). L’administration du domaine est chargée de veiller à ce que des ressources adéquates soient provisionnées et / ou réservées pour garantir les SLA offerts par le domaine.
2.3.1.2 Les nœuds de bordure et les nœuds intérieurs dans DiffServ
Un domaine DS se compose des nœuds de bordures et des nœuds intérieurs ou de cœur du réseau. Les nœuds de bordures permettent d’interconnecter le domaine DS à d’autres domaines DS ou non-DS, alors que les nœuds intérieurs peuvent se connecter à d’autres nœuds intérieurs ou à des nœuds de bordure dans le même domaine DS.
Les deux types de nœuds DS de bordure et intérieurs doivent être en mesure d’appli-quer le PHB approprié aux paquets en fonction du code DSCP ; sinon, un comportement imprévisible peut se produire.
En outre, les nœuds de bordure doivent exécuter les fonctions de conditionnement de trafic telles que définies par un accord de conditionnement de trafic (Traffic Conditionning Agreement : TCA) [41]établi avec le client, et qui fait partie du SLA.
Les nœuds intérieurs peuvent parfois être en mesure d’exécuter des fonctions de condi-tionnement de trafic limitées comme le re-marquage des codes DSCP dans les entêtes IP des paquets.
Un hôte dans un réseau contenant un domaine DS peut agir comme un nœud de bordure DS pour le trafic des applications en cours d’exécution sur cet hôte ; nous dirons donc que l’hôte est dans le domaine DS. Si un hôte n’agit pas comme un nœud de bordure, alors le nœud DS le plus proche de cet hôte joue le rôle de nœud de bordure pour le trafic provenant de ce dernier.
2.3.2 La classification et le conditionnement de trafic
La politique de la classification des paquets identifie le sous-ensemble du trafic qui peut bénéficier d’un service différencié en étant conditionné et/ou mis en correspondance avec un ou plusieurs PHB (par re-marquage du code DSCP) dans le domaine DS.
Le conditionnement de trafic consiste à accomplir les opérations de mesure, de régu-lation, de contrôle et/ou de re-marquage pour assurer que le trafic entrant est conforme aux règles définies dans le SLA, conformément à la politique de prestation de services du domaine. L’ampleur du conditionnement du trafic requis dépend des spécificités du
Figure 2.2 – La structure du champ DS [73]
service offert, et peut aller d’un simple re-marquage de code DSCP jusqu’à des opérations complexes de contrôle et de régulation (mise en forme).
2.3.2.1 La classification
Les classificateurs de paquets sont chargés de sélectionner les paquets dans un flux de trafic en se basant sur le contenu d’un certain champ de l’en-tête IP du paquet. Deux types de classificateurs sont définis : Le classificateur BA (Behavior Aggregate) qui classe les paquets en se basant seulement sur les codes DSCP, et le classificateur MF (Multi-Field) qui sélectionne les paquets en fonction de la valeur d’une combinaison d’un ou de plusieurs champs de l’en-tête, comme l’adresse source, l’adresse de destination, le code DSCP, l’ID du protocole, le port source et le numéro de port de destination, ainsi que d’autres informations telles que l’interface d’entrée.
La structure du champ DS de l’entête IP du paquet est présentée dans la figure 2.2. Les classificateurs sont utilisés pour «diriger» les paquets correspondant à une règle déterminée vers un élément du conditionneur de trafic pour un traitement ultérieur. Les classificateurs doivent être configurés par une procédure de gestion conformément au SLA approprié.
2.3.2.2 Les profils de trafic
Un profil de trafic détermine les propriétés temporelles d’un flux de trafic sélectionné par un classificateur. Il fournit des règles permettant de déterminer si un paquet particulier respecte son profil ou non. Par exemple, un profil basé sur le mécanisme du seau à jeton (token bucket) peut être sous la forme suivante : « code DSCP = X, utilisez token-bucket r, b »[44, 45].
Le profil ci-dessus indique que tous les paquets marqués avec le code DSCP X doivent être mesurés par un compteur token-bucket avec un taux r et une taille de rafale b. Dans
cet exemple, les paquets hors-profil sont les paquets qui arrivent quand il ne reste plus suffisamment de jetons dans le seau.
Plusieurs actions de conditionnement peuvent être appliquées sur les paquets respectant le profil et ceux hors-profil.
Les paquets, respectant le profil, peuvent être autorisés à entrer dans le domaine DS sans subir d’autres opérations de conditionnement ; ou bien leur code DSCP peut être modifié. Ceci se produit lorsque le code DSCP n’est pas mis à la valeur par défaut pour la première fois.
Les paquets hors-profil peuvent être mis en attente jusqu’à ce qu’ils respectent le profil (mise-en-forme), rejetés (policing), ou bien marqués par un nouveau code DSCP (re-marquage). Ces paquets peuvent être mis en correspondance avec un ou plusieurs clas-sificateurs BA qui sont "inférieurs" aux performances de transmission du BA auquel les paquets, respectant le profil, sont attribués.
2.3.2.3 Le conditionnement de trafic
Le conditionnement de trafic contient les fonctions suivantes : la mesure (meter), le marquage (marker), la régulation ou la mise en forme (shaper), et le contrôle ou le rejet de paquet (policer/dropper). Un flux de trafic est sélectionné par un classificateur, qui dirige les paquets vers un des éléments du conditionnement de trafic.
Un compteur (meter) est utilisé (le cas échéant) afin de mesurer un flux de trafic et le comparer avec un profil de trafic. L’état du compteur par rapport à un paquet particulier (par exemple, s’il respecte ou non le profil) peut affecter les opérations de marquage, de rejet, ou de mise en forme.
Lorsque les paquets quittent le conditionneur de trafic d’un nœud de bordure, le code DSCP de chaque paquet doit être mis à une valeur appropriée.
La figure 2.3 représente le diagramme de la structure d’un classificateur et d’un condi-tionneur de trafic.
Le compteur (meter)
Les compteurs de trafic mesurent les propriétés temporelles du flux de paquets sélec-tionné par un classificateur et le comparent au profil de trafic spécifié dans le SLA. Un compteur passe les informations d’état à d’autres fonctions de conditionnement pour dé-clencher une action particulière pour chaque paquet qui est, soit conforme au profil ou pas.
Le marqueur (marker)
Les marqueurs de paquets attribuent au champ DS d’un paquet un code DSCP par-ticulier, et ajoutent le paquet marqué à un comportement BA particulier. Le marqueur peut être configuré pour marquer tous les paquets entrants à un seul code DSCP, ou peut être configuré pour marquer un paquet par un code de l’ensemble des codes DSCP utilisés
Figure 2.3 – La structure d’un classificateur et d’un conditionneur de trafic [17]
pour sélectionner un PHB, en fonction de l’état du compteur. Lorsque le marqueur change le code DSCP d’un paquet, on dit qu’il a «re-marqué» le paquet.
Le régulateur (shaper)
Les régulateurs ont pour objectif de retarder certains ou tous les paquets dans un flux de trafic afin de rendre ce flux conforme à un profil de trafic. Un régulateur a généralement un tampon de taille finie, et les paquets peuvent être jetés s’il n’y a pas suffisamment de mémoire tampon pour contenir les paquets retardés.
Le contrôleur (dropper)
Les contrôleurs de trafic permettent de rejeter certains ou tous les paquets dans un flux de trafic en vue de mettre le flux de paquets en conformité avec un profil de trafic. On note qu’un contrôleur peut être mis en œuvre comme un cas particulier d’un régulateur en ajustant la taille de la mémoire tampon de rafales à zéro.
2.3.3 Les comportements-par-saut (PHB)
Un comportement par saut (PHB) est une description du comportement de transmis-sion (forwarding behaviour) visible de l’extérieur d’un nœud DS. Dans ce contexte, un comportement de transmission représente un concept général. Par exemple, dans le cas où un seul ensemble de comportements occupe un lien, le comportement de transmission visible (à savoir, perte, délai, gigue) ne va souvent dépendre que de la charge relative du lien. Les distinctions intéressantes entre les différents comportements sont principale-ment observées lorsque plusieurs ensembles de comporteprincipale-ments sont en compétition pour les ressources de mémoire tampon et de bande passante dans un nœud. Le PHB est le moyen par lequel un nœud alloue les ressources aux ensembles de comportements, et il est le premier moyen utilisé par le mécanisme d’allocation de ressources saut-par-saut utilisé par DiffServ.
Les PHB peuvent être spécifiés en termes de la priorité de leurs ressources (par exemple, un tampon, la bande passante) par rapport aux autres PHB, ou en fonction de leurs caractéristiques de trafic visibles (par exemple, délai, perte). Pour assurer une certaine cohérence, ces PHBs doivent être définis comme un groupe (groupe de PHB). Les groupes de PHB partagent généralement une contrainte commune qui s’applique à chaque PHB au sein du groupe, comme la politique d’ordonnancement de paquets ou de gestion de la mémoire tampon. Ils sont mis en oeuvre dans les nœuds à l’aide des mécanismes de gestion de mémoire tampon et d’ordonnancement de paquets.
Comme nous avons décrit plus haut, un PHB est sélectionné au niveau d’un nœud en faisant correspondre son code DSCP déjà prédéfini au code DSCP du paquet reçu. Les PHBs standardisés ont un code DSCP recommandé. Jusqu’à présent, trois PHBs ont été standardisés : le PHB par défaut, la transmission accélérée (Expedited Forwarding : EF), et la transmission assurée (Assured Forwarding : AF).
2.3.3.1 Le PHB par défaut
Le PHB par défaut, défini dans la RFC 2474, indique qu’un paquet marqué avec la valeur DSCP (recommandé) «000000» sera traité par le nœud DS selon le service best-effort usuel. En outre, si un paquet arrive à un nœud DS et sa valeur DSCP n’est pas mise en correspondance avec l’un des autres PHB, il sera automatiquement mappé vers le PHB par défaut.
2.3.3.2 Le PHB EF
Le PHB Expedited Forwarding (EF) (Transmission Accélérée) , défini dans la RFC 2598 [49], permet de fournir un service avec un taux perte faible, une latence faible, une gigue faible, et une bande passante garantie. EF peut être implémenté en utilisant des files d’attente avec des niveaux de priorité, ainsi que la limitation du débit des classes. Bien que quand le PHB EF est mis en œuvre dans un réseau DiffServ il fournit un service privilégié, il devrait cibler spécifiquement les applications les plus critiques parce qu’en cas de problèmes de congestion, il n’est pas possible de traiter la totalité du trafic avec une priorité élevée. Le PHB EF est particulièrement adapté aux applications (comme la VoIP) qui nécessitent un très faible taux de perte, une bande passante garantie, un faible délai et une faible gigue. La valeur DSCP recommandée pour EF est «101110».
2.3.3.3 Le PHB AF
Le PHB Assured Forwarding (AFxy) (Transmission Assurée), défini dans la RFC 2597 [43], permet de garantir l’acheminement des paquets. Il définit une méthode qui peut donner aux comportements BA plusieurs garanties de transferts différentes. Par exemple,
Drop Precedence Classe 1 Classe 2 Classe 3 Classe 4 Low Drop Precedence (AF11) 001010 (AF21) 010010 (AF31) 011010 (AF41) 100010 Medium Drop Precedence (AF12) 001100 (AF22) 010100 (AF32) 011100 (AF42) 100100 High Drop Precedence (AF13) 001110 (AF23) 010110 (AF33) 011110 (AF43) 100110
Table 2.2 – Les valeurs DSCP des classes AF [43]
le trafic peut être divisé en trois types de classes : or, argent et bronze, 50% de la bande passante disponible du lien sera allouée à la classe or, 30% à la classe argent, et 20 % pour la classe bronze. Le PHB AFxy définit quatre classes AFx : AF1, AF2, AF3 et AF4. A chaque classe, on attribue une certaine quantité d’espace mémoire tampon et de bande passante de l’interface, en fonction du SLA établi avec le fournisseur de services / politique. Dans chaque classe AFx, il est possible de spécifier trois valeurs de priorité d’abandon (drop precedence), représentée par le ‘y’ dans la notation AFxy.
En cas de congestion dans un nœud DS sur un lien spécifique, et si les paquets d’une classe AFx (par exemple AF1) doivent être abandonnés alors les paquets de la classe qui a la valeur la plus élevée du « drop precedence » seront abandonnés en premier. Dans notre exemple les paquets de la classe AF13 seront abandonnés en premier, suivis de ceux de la classe AF12, et en dernier ceux de la classe AF11.
Ce concept de drop precedence peut être utile pour pénaliser les flux au sein d’un BA qui dépassent leur bande passante attribuée. Les paquets de ces flux pourraient être re-marqués par un policer et avoir une valeur « drop precedence » plus élevée. Le tableau 2.2 présente les valeurs DSCP et drop precedence de chaque classe AF.
2.3.4 Les limites du modèle DiffServ
Comme toute autre technologie, le modèle DiffServ présente plusieurs avantages, mais aussi quelques limites. DiffServ présente des points forts concernant la simplicité de son architecture et son implémentation. En outre, l’agrégation de flux de trafic peut constituer un avantage puisque les nœuds DiffServ n’ont pas à garder des informations d’état sur chaque flux. Cependant, il présente aussi un inconvénient, puisque DiffServ traite les paquets de la même classe de façon identique, et alors, il est difficile de fournir une QoS quantitative pour chaque flux. Aussi, l’absence de mécanismes de gestion de réseau, comme les agents de gestion de bande passante, qui aident à assurer un certain contrôle des ressources, peut également constituer une faiblesse de DiffServ. Un autre point dans les limites de DiffServ, il s’agit des SLA qui sont établis entre le client et le FAI et qui définissent les besoins du client et les engagements du FAI, ces SLA ne sont pas changeables, alors que le trafic réseau et la topologie sont de nature dynamique, ce qui peut créer des perturbations concernant la conformité des flux client, et dégrader par la suite le service offert.
Après avoir présenté les deux principaux modèles qui permettent d’assurer la QoS : le modèle IntServ et le modèle DiffServ, l’objectif de la section suivante est de décrire une
![Figure 2.1 – Les éléments de IntServ implémentés dans chaque nœud du réseau [86]](https://thumb-eu.123doks.com/thumbv2/123doknet/2198411.12228/18.892.139.754.110.464/figure-elements-intserv-implementes-noeud-reseau.webp)
![Figure 2.3 – La structure d’un classificateur et d’un conditionneur de trafic [17]](https://thumb-eu.123doks.com/thumbv2/123doknet/2198411.12228/28.892.126.722.105.383/figure-structure-classificateur-conditionneur-trafic.webp)
![Figure 3.2 – Les blocs de l’architecture de pré-calcul de chemins [38]](https://thumb-eu.123doks.com/thumbv2/123doknet/2198411.12228/53.892.223.672.117.398/figure-blocs-l-architecture-pre-calcul-chemins.webp)