Comparaison de méthodes d’indexation des versions
Khaled JOUINI Geneviève JOMIERUniversité Paris Dauphine, LAMSADE Place du Mal de Lattre de Tassigny
75775 Paris Cedex 16, France
{khaled.jouini, genevieve.jomier}@dauphine.fr
Résumé. De nombreuses structures d’indexation prenant en compte les spécificités des bases de données
temporelles et des bases de données multiversions ont été proposées. La grande diversité de propositions rend difficile de déceler leurs potentiels et limites respectifs. Cet article définit un cadre permettant d’analyser des structures d’indexation de versions d’entité et propose une nouvelle structure d’indexation pour bases de données multiversions, le B+V arbre. L’article caractérise les types de requêtes dans une base de données multiversions et propose une classification des structures d’indexation liée au type de requêtes qu’elles favorisent a priori. Le travail présente également un modèle pour l’évaluation analytique des performances des différentes structures d’indexation. Cette évaluation est validée par une étude expérimentale.
Abstract. Many access methods taking into account the specificities of temporal and multiversion
databases have been proposed. The variety of proposals makes it difficult to identify their respective potentials and limits. The present paper defines a framework for understanding the versionned data indexing related issues. It identifies the main types of queries in a multiversion database and classifies data access methods according to the queries they more efficiently support. This work also presents a model for an analytical evaluation of the efficiency achieved by the different indexation methods. This evaluation is validated by an experimental study.
Mots-clés : Indexation de versions, analyse de performances, comparaison de performances d’index Keywords : Index for versions, performance analysis, comparison of index for versionned data
1 Introduction
La diffusion des bases de données temporelles [ST99] et multiversions [CJ90, BM03, JSL+04] a conduit à élaborer des structures d’index destinées à optimiser les requêtes à ces bases [TPZ02]. Le but de cet article est de déceler leurs potentiels et limites respectifs en terme qualitatif et quantitatif.
Ces structures d’index tiennent compte de la spécificité de ces bases qui rendent simultanément persistantes les représentations de plusieurs états du monde réel modélisé, dits Versions de Base de Données (DataBase Versions [CJ90, JSL+04]) ou VBD. Le concept de version de base de données, essentiel pour l’élaboration de ces structures d’index, est analogue pour les bases de données temporelles et les bases de données qui implantent les versions pour des besoins autres que la gestion du temps.
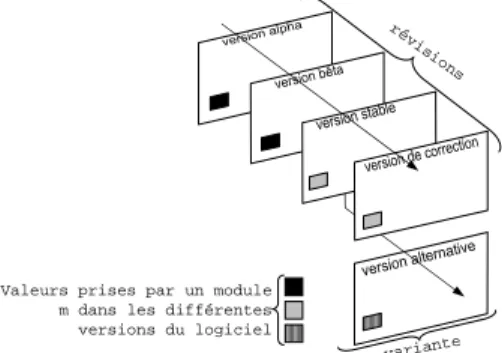
Par exemple, dans les applications de génie logiciel les concepteurs gardent une trace de leur travail, en créant successivement, à chaque étape, une nouvelle version du logiciel à concevoir, dite révision. Parvenu à une étape importante, la version stable de la figure 1, le développement continue sur deux branches : la branche de développement prépare la version majeure suivante, dite variante, et la branche de maintenance gère les mises-à-jour corrigeant la version stable. Des outils comme
Oracle Workspace Manager [BM03], subVersion
[CS02] ou CVS [Mor96], assistent les concepteurs dans la gestion des versions.
Valeurs prises par un module m dans les différentes versions du logiciel ré vi sion s variante
Figure 1: Arbre des versions d’un logiciel
Dans la suite de cet article le terme bases de
données multiversions utilisé seul inclut les bases
de données temporelles. Concrètement, dans le cas temporel, une VBD représente un état du monde réel modélisé par la base à un instant t, d’où le nom de slice [JSL+04] en anglais, symbolisant le fait qu’on prend une tranche de la base. Cet instant
t est mémorisé dans l’estampille temporelle utilisée
pour l’identification de la VBD. Dans le cas général
d’une base de données multiversions, une VBD est identifiée par une estampille de version v dont la sémantique est associée à l’application pour laquelle la base est construite. Lorsqu’aucune confusion n’est possible nous ne distinguerons pas une VBD de l’estampille v qui l’identifie. Le terme entité de la base désigne un élément persistant : n-uplet, objet,... Si E est l’ensemble des entités e de la base, alors la VBD v est composée de l’ensemble des (e,v ), versions d’entité estampillées par v :
VBD v ={(e,v ), pour tout e∈ E}.
Dans cet article nous nous intéressons à la structure de l’ensemble des estampilles V={v }, mais pas à sa sémantique. Celle-ci peut représenter un temps linéaire [LS90, BGO+96, TML99], et V est un ensemble ordonné, ou un temps arborescent [JSLB00, JSLB03, JSL+04], V a alors une structure d’arbre. Dans le cas général, l’ensemble V des estampilles est structuré en arbre. La relation liant deux nœuds successifs v et v’ de V, est la dérivation de VBD. En effet, classiquement une VBD v’ est créée par dérivation, c’est-à-dire copie matérialisée ou non, à partir d’une VBD v préexistante et persistante. Une fois la VBD v’ créée, des modifications peuvent être portées à ses versions d’entité (e,v’ ).
Les deux modes primitifs de requête aux bases de données multiversions [AJ97], consistent pour le couple (e,v ) à :
1. fixer v et faire varier e : l’interrogation est interne à la VBD v (version slice query [JSL+04]).
2. fixer e et faire varier v : il s’agit de suivre l’évolution de l’entité e à travers un ensemble de VBD. Si v est une estampille temporelle linéaire, ce type de requête suivra la série chronologique des valeurs prises par l’entité e au fil du temps.
La composition des deux types primitifs de requêtes aux bases de données multiversions, présentés ci-dessus, permet de poser des requêtes mêlant des recherches de données à l’intérieur d’une VBD et le suivi d’entités à travers un ensemble de VBD. Ainsi, dans une base de données temporelles décrivant une partie du système éducatif on pourrait poser une requête comme : "Combien y avait-il d’élèves dans les classes de cours préparatoire fréquentées dans leur enfance par les lauréats du Concours Général de 2006 ?".
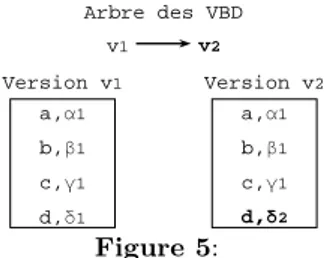
a,α1 d,δ1 Version v1 Figure 2: VBD initiale v1 Arbre des VBD v1 v2 a,α1 d,δ1 Version v1 a,α1 d,δ2 Version v2
Figure 3: Deux VBD, v1 et v2 vues
par les utilisateurs
(a,v1,α1) (d,v1,δ1) (d,v2,δ2) Arbre des VBD
v1 v2
Figure 4: Versions d’entité stockées dans la base
L’évaluation de cette requête se fait en plusieurs étapes :
1. identification des lauréats du concours général dans la VBD correspondant à 2006.
2. pour chaque lauréat :
(a) remonter dans son histoire, donc à travers un ensemble de VBD, jusqu’à trouver la VBD v de l’année où il était en cours préparatoire.
(b) dans cette VBD v, extraire le
nombre d’élèves de sa classe de cours préparatoire.
L’optimisation de ces différents types de requête a amené la proposition de différentes structures d’index [BGO+96, TML99, JSLB00, JSL+04]. L’optimisation des requêtes dans une VBD amène à regrouper les (e,v ) selon les valeurs de v. En revanche, l’optimisation des requêtes de type suivi
de versions de l’entité e à travers un ensemble de VBD amène à regrouper les (e,v ) selon les valeurs
de e, donc par entité.
Ce dernier type de regroupement des versions par entité est très naturel dans les bases de données structurées (relationnelles ou objets) multiversions. En effet, le concept de version est intéressant quand, d’une VBD à la suivante dans l’ordre de dérivation, seule une faible proportion des versions d’entité est modifiée. Par conséquent, des mécanismes de partage de valeur entre deux ou plusieurs versions d’entité sont mis en œuvre. Le principe du partage implicite [CJ90] est le suivant :
"lorsque la valeur d’une version d’entité (e,v ) n’est pas explicitement stockée dans la base, elle est la même que celle de (e,v’ ), où v’ est le plus proche ancêtre de v (au sens de la dérivation des VBD dans V) dont la valeur est explicitement stockée dans la base" [CJ90].
La valeur de la version d’entité (e,v’ ) est dite alors
valide par rapport à v.
Ceci est illustré par les figures 2, 3 et 4, où sont appliquées, comme dans la suite de l’article, les conventions d’écriture suivantes :
· les identificateurs d’entité sont des minuscules
latines du début de l’alphabet.
· les valeurs de versions d’entité sont des minuscules
grecques du début de l’alphabet. Dans le
cas relationnel une entité est un n-uplet et l’identificateur la clé primaire de la relation
· les estampilles sont des vi.
· les changements dans une figure par rapport à celle
qui la précède dans un exemple sont marqués en gras.
La figure 2 montre les versions d’entité composant la VBD v1 : (a,v1) a pour valeur α1 et (d,v1), δ1. À la figure 3 une deuxième VBD v2 est dérivée de v1. Dans v2, l’entité d a une nouvelle valeur δ2et l’entité
a garde la même valeur que dans v1. La figure 4
représente le contenu effectivement stocké de la base. La valeur de (a,v2) n’est pas explicitement stockée. Le principe du partage implicite permet de déduire, en utilisant l’arbre des versions, que (a,v2) partage sa valeur α1 avec (a,v1).
Dans la suite de l’article, la section 2 présente trois types d’index pour bases de données multiversions. La section 3 analyse théoriquement les performances des différentes familles d’index. La section 4 compare expérimentalement les performances des différentes familles d’index. Suit la conclusion.
2 Indexation des bases de données multiversions
Les index destinés à optimiser les requêtes aux bases de données multiversions sont de deux sortes selon qu’à partir de la valeur d’attribut on retrouve des identificateurs de versions d’entité (e,v ) ou qu’à partir des identificateurs de versions d’entité (e,v ) on retrouve les valeurs des attributs de (e,v ). Dans la suite nous ne nous intéressons qu’aux index permettant, à partir de (e,v ), de retrouver la
valeur de cette version d’entité. Pour préciser, dans une base de données relationnelles multiversions on indexerait les n-uplets par relation. L’identificateur
e d’entité serait une clé de la relation (établi
classiquement sans tenir compte des versions) et (e,v ) identifierait un n-uplet de la relation supposée contenir des n-uplets relevant de différentes VBD. L’usage du partage implicite de valeurs de version d’entité, ainsi que le suivi des versions d’entité sur des intervalles d’estampille expliquent que, comme nous l’avons constaté, les structures d’index de versions d’entité proposées dans la littérature n’utilisent pas le hachage, mais sont dérivées de l’arbre B+ qui utilise la relation d’ordre pour organiser l’accès aux données.
a,α1 b,β1 c,γ1 d,δ1 Version v1 a,α1 b,β1 c,γ1 d,δ2 Version v2 Arbre des VBD v1 v2 Figure 5:
Dans la suite de l’article, notre base de données exemple de référence est à la figure 5. Elle comporte deux VBD v1 et v2 et quatre entités a, b, c et
d. Seule la valeur de l’entité d est modifiée dans v2. Comme les index présentés dans cette section sont des arbres, dans la suite, pour simplifier les exemples, nous supposons qu’un nœud d’un index contient, au maximum, trois entrées. Un nœud interne est noté Ii et un nœud feuille, contenant les
données, Di.
Dans cette section trois types de structures d’index de versions d’entité sont présentées. La première structure d’index, l’arbre B+V, regroupe les versions par entité. Il favorise donc les requêtes de suivi des versions d’entité. La deuxième structure d’index, le chevauchement d’arbres B+ [TML99], regroupe les versions par VBD et favorise les requêtes dans une VBD. Une troisième structure, que nous qualifierons d’hybride, apparaît comme un compromis entre l’arbre B+V et le chevauchement d’arbres B+. L’approche hybride a plusieurs variantes présentées dans [Eas86, LS90, BGO+96, VV97, JSLB00, JSLB03, JSL+04].
2.1 Arbre B+V
Contrairement à d’autres structures d’index, l’arbre B+V autorise toutes les VBD de la base multiversion indexée à évoluer par insertion,
mise-à-jour et suppression de versions d’entité, par création ou suppression d’entité et par dérivation de nouvelles VBD. Ces mécanismes d’évolution ont été largement expliqués dans [CJ90, GJ95] et il n’y a pas lieu d’y revenir ici.
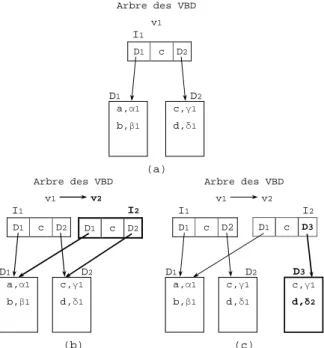
L’arbre B+V est un arbre B+ modifié, indexant les versions d’entité sur le couple (e,v ). Au lieu de stocker tous les (e,v ) de la base pour retrouver leurs valeurs, il utilise le partage implicite. Par conséquent, il ne stocke que les (e,v’ ), telles que : (1) l’entité e a été modifiée dans la VBD v’ et (2) la valeur de (e,v’ ) n’est pas partagée avec (e,v ), où v est l’estampille de la version parente de v’ au sens de l’arbre des VBD. La taille de l’arbre B+V croît donc lentement en fonction des insertions et mises à jour de versions d’entité et est inchangée en cas de dérivation de nouvelle VBD. a,v1,α1 b,v1,β1 I1 D1 c,v1 D2 D1 D2 c,v1,γ1 d,v1,δ1 a,v1,α1 b,v1,β1 I1 D1 c,v1 D2 D1 D2 c,v1,γ1 d,v1,δ1 d,v2,δ2 (a) (b) Arbre des VBD v1 v2 Arbre des VBD v1
Figure 6: Exemple d’arbre B+V
Ceci est illustré par les figures 6.a et 6.b qui représentent l’arbre B+V avant et après la mise-à-jour de l’entité d dans la VBD v2 de la figure 5. L’idée d’utiliser un arbre B+ pour indexer les versions d’entité a été utilisée dans [Nor99] pour indexer des versions d’objet dans une base de données historique où le temps est linéaire. Le passage au cas arborescent introduit deux problèmes liés à l’absence d’un ordre total entre les VBD :
1. l’arbre B+V indexe les (e,v ). Il faut donc que l’ensemble des identificateurs d’entité e soit muni d’un ordre total; ceci a priori
ne pose pas de problèmes. Il en est
de même pour l’ensemble des estampilles de VBD v. Lorsque le versionnement est linéaire, l’ordre total des estampilles permet l’utilisation de l’arbre B+V. Dans le cas général du versionnement arborescent, les estampilles doivent être construites en tenant compte de l’évolution de l’arbre des VBD, puisqu’une nouvelle VBD peut être dérivée à chaque instant de chaque VBD existante. 2. l’algorithme de recherche de la valeur de
à chercher l’ancêtre le plus proche de v’ (au sens de la dérivation dans l’arbre des VBD) parmi les (e’,v ) de l’arbre B+V. Lorsque le versionnement est linéaire la détermination des ancêtres de v’ est triviale. Dans le cas arborescent, pour des raisons de performances, il est préférable que les estampilles soient construites de manière que la connaissance de v’ implique celle de tous ses ancêtres.
En réponse à ces besoins, l’arbre B+V peut utiliser un estampillage généalogique des VBD. Il peut se baser sur des techniques différentes d’énumération d’arbre comme celle de [CJ90] ou de [KU95]. Ainsi, dans [CJ90] le peme fils d’un nœud s est identifié
par s.p. Cette technique est bien adapté aux cas où l’arbre des VBD est large et peu profond comme dans la gestion de configurations.
Dans [KU95] le premier fils du nœud s est identifié par s+1 et le p+1eme fils par s.p.1. Par exemple,
dans l’arbre des VBD de la figure 6, le premier fils de
v2 est identifié par v3, son deuxième fils par v2.1.1 et s’il avait un troisième fils il serait identifié par v2.2.1. De même, le premier fils de v2.1.1 est estampillé par v2.1.2. Cette technique d’estampillage est bien adapté aux cas où l’arbre des VBD est profond et peu large, comme il est classiquement le cas des applications de conception.
Dans la suite de cet article nous considérons que l’estampillage utilisé est généalogique.
L’équilibre d’un arbre B+ classique est dû au fait que tout nœud interne ou feuille, excepté la racine, est maintenu au moins à moitié plein au fur et à mesure des éclatements et fusions de nœuds dûs aux insertions et suppressions de données.
Pour l’arbre B+V on applique un principe analogue pour maintenir l’équilibre de l’arbre en modifiant légèrement le critère de répartition des données lors de l’éclatement d’une feuille suite à l’insertion d’une version (e,v ). En effet, pour optimiser la recherche de la valeur d’une version (e,v ), il est pertinent de maintenir, autant que possible, toutes les versions de e dans un même nœud feuille de l’arbre B+V. Par conséquent, tant qu’un nœud feuille Di contient des
versions de plusieurs entités lors de son éclatement en Di et Di+1, la répartition des données entre Di et
Di+1, ne sépare pas sur les deux feuilles les versions
d’une même entité e.
Il peut cependant se produire qu’il soit nécessaire d’éclater une feuille Dine contenant que les versions
d’une seule entité e’. Dans ce cas on choisira d’effectuer la répartition des versions de l’entité
e’ entre Di et Di+1 de manière que lors, d’une
recherche de (e’,v’ ), trouver la valeur de cette version ne nécessite l’accès qu’à une seule feuille. Pour cela on considère V’ l’ensemble ordonné des estampilles de l’entité e’ figurant dans l’arbre B+V.
V’ ⊆V, ensemble de toutes les estampilles de VBD
de la base. Il faut scinder V’ en deux sous-ensembles ordonnés successifs, V’i, V’i+1. Le premier regroupe
les estampilles des versions d’entité (e’,v’ ) destinées à Diet le second les estampilles des versions d’entité (e’,v’ ) destinées à Di+1. La plus petite estampille
de V’i+1figurant dans Di+1 est la racine d’un
sous-arbre A de V. Par ce biais, la valeur de toute version (e’,v’ ), telle que v’ ⊂A, peut être trouvée dans Di+1,
en utilisant ou non le partage implicite de valeurs de versions d’entité. De manière analogue, la valeur de toute version d’entité (e’,v’ ), telle que v’ ⊂V-A, peut être trouvée dans Di.
a,v1,α1 a,v2.1.1,α2 a,v4,α4 I1 D1 d,v1 D2 D1 D2 d,v1,δ1 d,v3,δ3 d,v2.1.1,δ5 (a) (b) v1 v2 v4 v2.1.1 v2.1.2 v3 a,v1,α1 a,v2.1.1,α2 a,v4,α4 I1 D1 d,v1 D2 d,v3 D3 D1 D2 d,v1,δ1 d,v2.1.1,δ5 D3 d,v3,δ3 d,v4,δ4 Arbre des VBD Arbre des VBD v1 v2 v3 v2.1.1 v2.1.2
Figure 7: Insertion avec éclatement dans l’arbre B+V
Considérons à titre d’exemple les figures 7.a et 7.b (les estampilles sont construites comme décrit précédemment). La situation initiale est donnée dans la figure 7.a. : la feuille D1contient uniquement des versions de a et D2 uniquement des versions de
d. Dans la figure 7.b une nouvelle VBD v4 est dérivée de v3. Dans v4 l’entité d est mise-à-jour. Cette mise à jour provoque l’éclatement de D2 et la création de D3. La répartition des versions de l’entité d entre D2 et D3 se fait selon l’estampille
v3 : les versions de l’entité d dont l’identificateur de VBD est un descendant de v3, ((d,v3),δ3) et ((d,v4),δ4), sont déplacées dans D3.
La granularité de version de l’arbre B+V est la version d’entité. L’arbre B+V est donc un index d’une base de données multiversions au stockage extrêmement compact. Il est particulièrement performant pour les requêtes de suivi des versions
d’entité à travers les VBD.
2.2 Chevauchement d’arbres B+
Le chevauchement d’arbres B+ (Overlapping
B-Trees) [MK90, TML99], a été proposé pour les
bases de données historiques, c’est-à-dire que les estampilles de VBD sont associées au temps linéaire. Il peut être facilement étendu au temps arborescent. Comme "on ne re-écrit pas l’histoire" seule la dernière VBD peut être mise-à-jour, toutes les VBD précédentes sont gelées.
L’objectif du chevauchement est de favoriser l’accès aux versions (e,v ) par VBD. Pour cette raison, un arbre B+, noté O+(v) est créé pour chaque VBD
v. Ces arbres sont des versions d’arbre B+. Par
conséquent dans O+(v) les données sont ordonnées selon les identificateurs d’entité e. Pour réduire le coût du stockage, les nœuds inchangés entre deux versions d’arbre successives sont partagés.
D1 c D2 I2 D1 c D2 D1 D2 a,α1 b,β1 c,γ1 d,δ1 I1 (b) Arbre des VBD v1 v2 D1 c D3 I2 D1 c D2 D1 D2 a,α1 b,β1 c,γ1 d,δ1 I1 D3 c,γ1 d,δ2 (c) Arbre des VBD v1 v2 D1 c D2 D1 D2 a,α1 b,β1 c,γ1 d,δ1 I1 (a) Arbre des VBD v1
Figure 8: Chevauchement de deux versions d’arbre
Dans l’exemple de la figure 8.a l’arbre O+(v1) de la VBD initiale v1 contient les versions (e,v1) de toutes les entités e de la base. Lorsqu’une nouvelle VBD v’ est dérivée de v, O+(v’) est créé à partir de
O+(v). Une nouvelle racine est créée pour O+(v’).
Initialement le contenu de la racine de O+(v’) est une copie de celle de O+(v). O+(v) et O+(v’)
partagent donc tous leurs nœuds, excepté le nœud racine. Ceci est illustré dans la figure 8.b, où, suite à la dérivation de v2, I2 est créé et son contenu est une copie de I1, la racine de O+(v1).
Soit Di et Ij deux nœuds partagés par O+(v) et
O+(v’), tels que Di est un nœud feuille et Ij le père
de Di. La première modification du contenu de Di
dans v’, par mise-à-jour ou insertion d’une version d’entité ((e,v’ ),val), entraîne la rupture du partage de Di entre O+(v) et O+(v’). Celle-ci se fait par
la création dans O+(v’) d’un nouveau nœud Di+1 copie de Di; suit la prise en compte de la mise-à-jour
de (e,v’ ).
Ainsi, dans la figure 8.c, lors de la rupture du partage de D2, suite à la mise-à-jour de d, le contenu de D2 est copié dans D3. Après la copie, d est mis-à-jour.
Le remplacement de Di par Di+1 dans O+(v’) modifie le contenu de son nœud père Ijdans O+(v’),
puisqu’il doit pointer vers Di+1et non plus vers Di.
Le partage de Ij doit donc être rompu. Un nœud
Ij+1 est créé et remplace Ij dans v’. La rupture
du partage des nœuds entre O+(v) et O+(v’) se poursuit ainsi dans O+(v’) jusqu’à la mise-à-jour de la racine de O+(v’).
Dans la figure 8.c, suite à la rupture du partage de D2, I2 est modifiée pour pointer vers D3.
a,α1 b,β1 D1 c D3 I2 D1 c D2 D1 D2 c,γ1 d,δ1 I1 D3 c,γ1 d,δ2 v1 I1 v2 I2
Index des racines des versions d’arbre
Versions d’arbre
Figure 9: Indexation par le chevauchement d’arbres B+
L’accès aux racines des O+(v) n’est pas précisé dans [MK90, TML99]. Cependant un index devient nécessaire dès qu’il y a un grand nombre de VBD. La structure de l’index permettant l’accès aux racines des O+(v) peut être un arbre B+. L’accès à une version d’entité identifiée par (e,v ) se fait alors en deux étapes. Un premier accès par identificateur de VBD v permet de localiser la racine de O+(v). Ensuite, un second accès par identificateur d’entité
e est effectué dans O+(v) pour trouver la valeur de
l’entité (e,v ).
Par rapport à l’arbre B+V on notera que dans le chevauchement d’arbres B+ la granularité de version est le nœud feuille. Par conséquent, une mise-à-jour d’une version d’entité (e,v ) entraîne la création de h nœuds, si h est la hauteur de O+(v). Le taux de redondance introduit par ce biais est
fonction de la taille des nœuds.
2.3 Approche hybride
Nous appellerons hybride l’approche proposée dans [BGO+96, VV97, JSLB00, JSLB03, JSL+04] car elle a pour objectif de favoriser l’accès aux données par VBD tout en utilisant le partage implicite. De temps en temps elle duplique des versions d’entité valides pour accélérer la recherche de valeurs de versions d’entité.
L’approche hybride a été implantée de différentes manières dans le modèle de versionnement linéaire [BGO+96, VV97] et plus récemment dans le modèle arborescent [JSLB00, JSLB03, JSL+04]. Dans tous les cas la mise-à-jour d’une VBD non feuille dans l’arbre des VBD est impossible.
Ici, le BT-Tree [JSLB00, JSL+04] est pris comme exemple de l’approche hybride et il est décrit tel que présenté dans [JSL+04].
Préalablement à la description du BT-Tree, la notion de sous-ensemble connexe de VBD, essentielle dans l’approche hybride, est explicitée.
2.3.1 Sous-ensemble connexe de VBD
Un sous-ensemble connexe de VBD est un ensemble de VBD situées dans une partie connexe de l’arbre des VBD. Un sous-ensemble connexe a donc une structure d’arbre. v1 v2 v4 v3 v5 C1 v6 (a) Arbre des VBD v1 v2 v4 v3 v5 C2 v6 (b) Arbre des VBD
Figure 10: Exemple de deux sous-ensembles connexes. C1
est représenté par (v2,{v5,v6}) et C2 par (v2,Ø). Les auteurs de [JSL+04] représentent un sous-ensemble connexe C par un couple (vin,vout), où vin
est la VBD racine de l’arbre correspondant à C et
vout un ensemble de VBD. Chaque VBD figurant
dans vout est une VBD n’appartenant pas à C, mais
dont le père dans l’arbre des VBD appartient à C. Ceci est illustré dans la figure 10.a où vout={v5, v6} et dans la figure 10.b où vout=Ø : ceci signifie que
C2 n’est pas complètement déterminé et qu’il peut encore recevoir des nouvelles VBD pas encore créées. 2.3.2 BT-Tree (Branched and Temporal Tree)
Le BT-Tree [JSLB00, JSL+04] est une variante de l’arbre R [Gut84], indexant les versions d’entité sur
le couple (e,v ).
La figure 11.a représente le BT-tree indexant la VBD initiale v1. Les nœuds internes (ici seulement la racine I1) partitionnent l’espace bi-dimensionnel identificateur d’entité, identificateur de VBD. À chaque nœud de l’arbre correspond un intervalle d’identificateurs d’entité, noté (emin,emax), et un
sous-ensemble connexe de VBD (vin,vout). Une entrée d’un nœud interne est donc un triplet ((emin,emax),(vin,vout),ref ), où ref est la référence
d’un nœud Ij. Une entrée de cette forme indique que les feuilles du sous-arbre dont Ij est la racine,
stockent les versions d’entité définies comme suit :
{(e,v ), tels que emin ≤ e < emax et v ∈ (vin,vout)}.
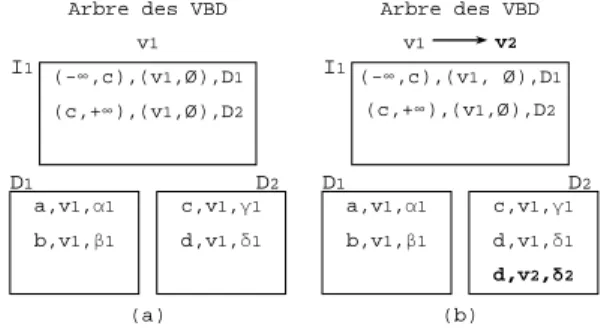
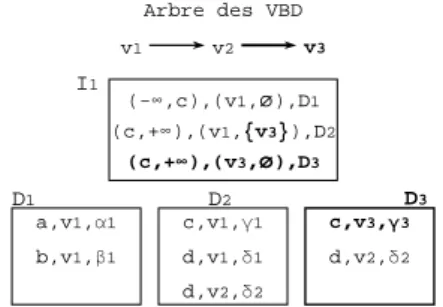
a,v1,α1 b,v1,β1 D1 D2 c,v1,γ1 d,v1,δ1 d,v2,δ2 I1 (-∞,c),(v1, Ø),D1 (c,+∞),(v1,Ø),D2 (b) Arbre des VBD v1 v2 a,v1,α1 b,v1,β1 D1 D2 c,v1,γ1 d,v1,δ1 (-∞,c),(v1,Ø),D1 (c,+∞),(v1,Ø),D2 I1 (a) Arbre des VBD v1
Figure 11: Insertion dans un nœud non saturé
Dans l’entrée correspondant à D1 dans le nœud I1 de la figure 11.a, −∞ correspond à emin, c à emax,
v1 à vin et Ø à vout. Dans l’entrée correspondant à
D2, c correspond à emin et+∞à emax.
Un nœud Di du BT-Tree est dit valide par rapport
à une VBD v, si v appartient au sous-ensemble connexe (vin,vout) correspondant à Di.
Tant qu’un nœud feuille Di n’est pas saturé, il
est possible d’y stocker des versions d’entité (e,v ), telles que v appartient au (vin,vout) correspondant
à Di et e au (emin,emax) correspondant à Di. Par
exemple, dans la figure 11.b, comme D2 dispose encore d’espace libre, (d,v2) y est insérée.
Le partage implicite de valeur est utilisé pour retrouver les valeurs des versions d’entité qui ne sont pas explicitement stockées. Dans la figure 11.b, la valeur de (c,v2) n’est pas explicitement stockée. Par le principe du partage implicite, on déduit qu’elle a la même valeur γ2 que (c,v1).
Lorsque Di est saturé, l’insertion d’une nouvelle version d’entité (e,v ) provoque la création d’un nouveau nœud feuille Di+1. Les versions d’entité
pour certaines dupliquées. Le but de la répartition des versions d’entité entre Di et Di+1est d’accélérer
les accès aux données par VBD, au prix de redondance. Plus précisément, il s’agit d’éviter d’accéder à Di lors de la recherche de valeurs de
versions d’entité appartenant à v, la VBD qui a provoqué la répartition/duplication.
Pour cette raison, les versions d’entité stockées dans Di et valides par rapport à v sont dupliquées
dans Di+1. L’opération de duplication des versions
d’entité valides par rapport à v est appelée scission
par la VBD v (version-split [JSL+04]). Lorsqu’un
nœud Di subit une scission par v donnant lieu à un
nœud Di+1, v représente le vin du sous-ensemble connexe pour lequel Di+1 est valide et un des
éléments du vout du sous-ensemble connexe pour
lequel Di est valide.
a,v1,α1 b,v1,β1 D1 D2 c,v1,γ1 d,v1,δ1 d,v2,δ2 D3 c,v3,γ3 d,v2,δ2 Arbre des VBD v1 v2 v3 (-∞,c),(v1,ø),D1 (c,+∞),(v1,{v3}),D2 (c,+∞),(v3,ø),D3 I1
Figure 12: Insertion dans un nœud saturé
Considérons à titre d’exemple la figure 12 où une VBD v3est dérivée à partir de v2. Dans v3, l’entité c est mise-à-jour et a pour nouvelle valeur γ3. Ceci se matérialise par l’insertion de ((c,v3),γ3) et provoque la scission de D2 et la création de D3. La version d’entité ((d,v2),δ2) valide à la fois par rapport à v2 et v3 est dupliquée dans D3. Ceci évite de visiter
D2 lors de la recherche des valeurs des versions d’entité composant v3 et ayant un identificateur d’entité supérieur à c. ((d,v2),δ2) est dupliquée et non déplacée, pour éviter de visiter D3 lors de la recherche des versions d’entité appartenant à v2 et ayant un identificateur d’entité supérieur à c. Après la scission D2 devient valide par rapport au sous-ensemble connexe (v1,{v3}) alors que D3 l’est par rapport au sous-ensemble connexe (v3,Ø).
Le nombre de versions d’entité dupliquées lors d’une scission par v d’un nœud feuille Di, correspond
au nombre d’identificateurs d’entité différents apparaissant dans Di, puisque chacune de ces entités
a exactement une version valide par rapport à
v. Ainsi, plus le nombre d’identificateurs d’entité
différents est élevé dans un nœud sujet à scission, plus la redondance est grande. Pour éviter le cas où, dès sa création suite à une scission, un
nœud Di+1contiendrait un nombre d’identificateurs
d’entité différents trop important par rapport à la redondance jugée tolérable, la règle suivante est imposée. Si la proportion des versions d’entité dupliquées dans Di+1 par rapport à la capacité
de Di+1, en nombre de versions d’entité qu’il peut stocker, dépasse un seuil u, la scission est suivie par la création d’un nouveau nœud Di+2. Les versions
d’entité initialement dupliquées dans Di+1 sont réparties entre Di+1et Di+2selon les identificateurs
d’entité. Cette opération est nommée éclatement. Alors que la scission détermine le sous-ensemble connexe pour lequel un nœud Di est valide,
l’éclatement détermine les identificateurs d’entités apparaissant dans Di.
Le traitement de la saturation d’un nœud interne
Ij dans une VBD v suit les mêmes mécanismes
que pour un nœud feuille : les entrées de Ij où
apparaît un (vin,vout), tel que v ∈(vin,vout), sont dupliquées dans un nouveau nœud Ij+1 (scission).
Si la proportion d’entrées dupliquées dépasse u, un nouveau nœud Ij+2 est créé et les entrées sont
réparties entre Ij+1 et Ij+2 selon les intervalles
d’identificateurs d’entité (éclatement).
En conclusion on peut dire que la conjugaison dans le BT-Tree du partage implicite et de la duplication de versions d’entité, le rend potentiellement intéressant à la fois pour les requêtes à travers un ensemble de VBD et à l’intérieur d’une VBD.
2.4 Conclusion
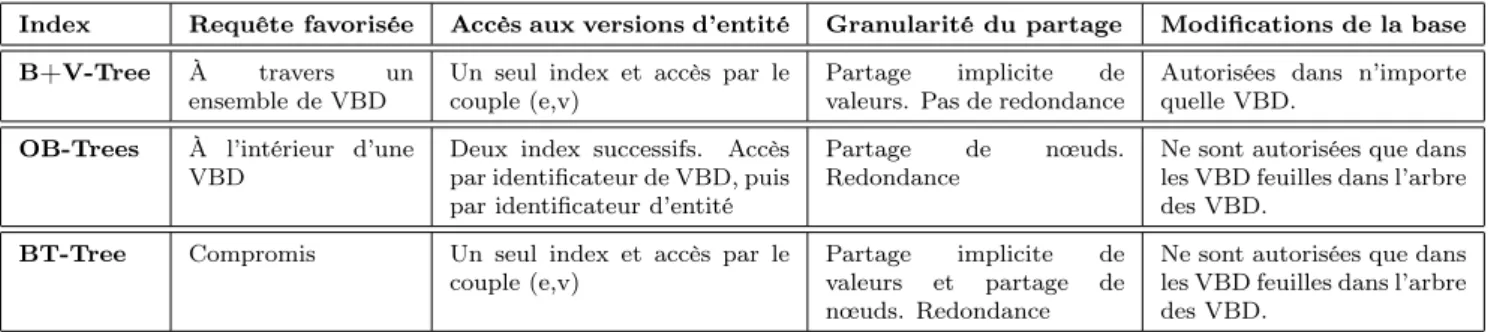
Les mécanismes de partage des valeurs des versions d’entité, la granularité de l’information partagée et le regroupement des versions d’entité, sont autant de critères qui différencient les approches d’indexation. Le tableau de la figure 13 synthétise les différences entre les approches d’indexation.
3 Analyse et comparaison des index
Cette section compare les performances de l’arbre
B+V à celles de l’OB-Trees et du BT-Tree. Cette
comparaison vise à évaluer la taille de chaque index, le nombre de nœuds visités suite à une requête et de déterminer, en fonction du type de requête et de la taille du stockage, dans quels cas il convient d’utiliser un index plutôt qu’un autre.
L’analyse des index conçus pour les bases de données multiversions implique un nombre important de paramètres. Comme le montrent les
Index Requête favorisée Accès aux versions d’entité Granularité du partage Modifications de la base B+V-Tree À travers un
ensemble de VBD
Un seul index et accès par le couple (e,v)
Partage implicite de valeurs. Pas de redondance
Autorisées dans n’importe quelle VBD.
OB-Trees À l’intérieur d’une VBD
Deux index successifs. Accès par identificateur de VBD, puis par identificateur d’entité
Partage de nœuds. Redondance
Ne sont autorisées que dans les VBD feuilles dans l’arbre des VBD.
BT-Tree Compromis Un seul index et accès par le couple (e,v)
Partage implicite de valeurs et partage de nœuds. Redondance
Ne sont autorisées que dans les VBD feuilles dans l’arbre des VBD.
Figure 13: Différences entre les approches d’indexation
analyses faites dans [LS90] et [TPZ02], considérer l’ensemble de ces paramètres conduit à une explosion du nombre de cas à traiter. Inversement,
une analyse simpliste telle que l’analyse
asymptotique [ST99], ne permet pas une distinction fine des performances des index. Cette section définit une méthode d’analyse, appelée analyse
en régime permanent. Cette analyse, inspirée du
modèle de coût proposé dans [TPZ02], se concentre sur les paramètres prépondérants pour obtenir des résultats simples et fins.
La suite de cette section est organisée comme suit. La sous-section 3.1 introduit l’analyse en régime permanent. Dans 3.2 les éléments de comparaison considérés dans l’analyse sont présentés. Les sous-sections 3.3, 3.4 et 3.5 appliquent l’analyse, respectivement, à l’arbre B+V, à l’OB-Tree et
au BT-Tree. Ensuite, une comparaison des
performances de ces index est faite dans 3.6. Enfin, la sous-section 3.7 situe l’analyse en régime permanent par rapport à d’autres analyses.
3.1 Analyse en régime permanent
Après un régime transitoire, une base de données multiversions est dite en régime permanent, si :
· le nombre d’entités qui la composent n’évolue plus · la proportion de versions d’entité mises-à-jour
dans une VBD est stable.
L’analyse en régime permanent est inspirée du modèle de coût de [TPZ02]. Ce modèle est présenté brièvement dans la sous-section 3.1.1. Suit la présentation de l’analyse en régime permanent.
3.1.1 Modèle de coût de [TPZ02]
Le modèle de coût de [TPZ02] s’intéresse aux performances des index permettant à partir de la valeur d’un attribut de retrouver des versions d’entité. Il se place dans le cas d’une base de données multiversions en régime permanent et vise à comparer le comportement de l’OB-Trees et du
MultiVersion B-Tree [BGO+96] (une variante de
l’approche hybride) pour ce type d’indexation. Le modèle considère que les valeurs d’un attribut sont indexées par l’OTrees et le MultiVersion
B-Tree. Les coûts d’une requête et du stockage sont
alors évalués pour chaque index. Les résultats des simulations figurant dans [TPZ02] sont cohérents avec ce modèle.
Le modèle de [TPZ02] fournit des évaluations trop complexes pour mettre en évidence le rôle primordial de certains paramètres comme le rôle du seuil pour un index de l’approche hybride. La complexité des évaluations de [TPZ02] nécessite le recours aux simulations pour comprendre le comportement des index. Ceci rend les conclusions de [TPZ02] dépendantes des valeurs des paramètres que les auteurs ont choisi de fixer.
Les conclusions de [TPZ02] ne se transposent pas directement aux index où à partir d’identificateurs de versions d’entité on cherche leurs valeurs, ce qui est l’objet de cet article. Ceci s’explique par le fait que la gestion du partage implicite diffère selon que l’index est construit sur les valeurs d’un attribut ou sur les identificateurs de version d’entité.
3.1.2 Principe de l’analyse en régime
permanent
L’analyse en régime permanent s’intéresse aux index contrôlant le regroupement des versions d’entité sur le disque et permettant à partir des identificateurs de versions d’entité (e,v ) de retrouver leurs valeurs. L’analyse suppose qu’il existe E entités et V VBD. Chaque entité est représentée par une version dans la VBD initiale v1. À partir de v1 il n’y a plus de création d’entité, mais seulement des mises-à-jour d’entités dans la dernière VBD créée. La proportion des entités mises-à-jour dans chaque VBD est supposée constante et est égale à a, l’agilité
des données dans [TPZ02]. Si E est le nombre total
de versions d’entité, alors:
E = E + aE(V-1). (3.1.1)
Dans cette équation, E est le nombre de versions d’entité insérées dans v1 et aE (V-1 ) le nombre de versions d’entité insérées dans les V-1 autres VBD. Pour pouvoir comparer les conclusions de l’analyse en régime permanent à celles de [TPZ02], l’analyse se place dans le cas des bases de données historiques, telles que le versionnement est linéaire. Comme [TPZ02], l’analyse en régime permanent prend l’hypothèse classique de l’uniformité de la distribution des données, c’est-à-dire qu’elle suppose que, dans chaque VBD, toutes les entités ont une même probabilité, égale à a, de subir une mise-à-jour et qu’en moyenne chaque entité possède
1 +a(V-1 ) versions différentes.
Pour éviter des évaluations trop complexes,
l’analyse en régime permanent évalue les
performances des index d’une manière plus simple et plus intuitive que le modèle de [TPZ02].
Classiquement les nœuds internes des index basés sur l’arbre B+ ont des centaines nœuds fils et de ce fait, plus de 99% des nœuds sont des feuilles. Pour simplifier les calculs, l’analyse en régime permanent se focalise sur les nœuds feuilles des index.
3.2 Éléments de comparaison
Deux éléments de comparaison sont considérés : le coût d’une requête et le coût du stockage.
3.2.1 Coût d’une requête
Dans un environnement base de données le coût d’une requête q se mesure en nombre de nœuds visités (= pages chargées en mémoire). Deux paramètres influent sur ce nombre. Le premier est le nombre de nœuds internes à visiter avant d’atteindre les nœuds feuilles. Ce nombre, noté
H dans la suite, correspond dans les structures
arborescentes à la hauteur. Le second paramètre est le nombre de nœuds feuilles à visiter, noté P.
• Évaluation de H
Pour l’arbre B+V et le BT-Tree, H représente la hauteur de l’arbre final qui résulte de l’insertion de E versions d’entité. H est décomposé en deux parties
h et h’. h est la hauteur de l’arbre initial construit
à partir de la VBD initiale v1 (indexant E versions
d’entité). h’ est le nombre de niveaux créés au delà du niveau h, suite à l’insertion de aE (V-1 ) versions d’entité. Pour l’OB-Trees, h est la hauteur moyenne d’une version d’arbre O+(v) et h’ la hauteur de l’index des racines des O+(v), qu’il faut consulter pour accéder à une version d’arbre.
• Évaluation de P
P, le nombre de nœuds feuilles à visiter pour
répondre à une requête q, dépend de la taille de la réponse, c’est-à-dire le nombre de versions d’entité à extraire, et de la répartition de ces versions d’entité dans les nœuds feuilles. Pour prendre en compte les différents type de requêtes, nous considérons le cas du suivi de l’évolution de qe entités à travers
qv VBD successives. Une requête q est représentée
dans la suite par le couple (qe,qv). Les requêtes dans
une VBD sont un cas particulier de q, où qv=1. Le
suivi de l’évolution d’une version d’entité est un cas particulier de q, où qe=1.
3.2.2 Coût du stockage
Dans l’OB-Trees et le BT-Tree, à cause de la duplication des versions d’entité, le nombre de versions d’entité stockées, noté Er, est supérieur
au nombre de versions d’entité E. L’évaluation du coût de stockage est faite selon le nombre des versions d’entité dupliquées, mesuré par le facteur de redondance R ;
R=Er
E (3.2.1)
L’évaluation du coût d’une requête et du coût du stockage nécessite l’évaluation du nombre de nœuds de niveau i dans l’index, noté Ni. Pour l’OB-Trees,
Ni est le nombre de nœuds créés au niveau i des V
versions d’arbre O+(v).
Considérons l’arbre B+V et le BT-Tree. Si ni est
(avec, 1 ≤ i ≤ h) le nombre moyen de nœuds créés au niveau i de l’arbre initial et mile nombre moyen de nouveaux nœuds créés à ce niveau lors de la prise en compte d’une VBD v, alors :
Ni= ni+ mi(V − 1) (avec, 1 ≤ i ≤ h). (3.2.2)
Pour l’OB-Trees ni correspond au nombre moyen
de nœuds créés au niveau i de la première version d’arbre et mi au nombre moyen de nouveaux nœuds créés à ce niveau dans chacune des (V-1 ) autres versions d’arbre. Le tableau de la figure 14 récapitule les symboles utilisés dans l’analyse.
a Agilité des données, c’est-à-dire la proportion des entités qui subissent une mise-à-jour à chaque VBD. V =card(V) Nombre total de VBD.
E =card(E) Nombre total d’entités représentées dans la base.
E Nombre total de versions d’entité sans duplication. E=E +aE (V-1 ).
Er Nombre total de versions d’entité stockées. S’il n’y a pas de duplication Er=E.
R Facteur de redondance. R=Er E.
h Pour l’arbre B+V et le BT-Tree, h est à la hauteur de l’arbre initial. Pour l’OB-Trees, h est la hauteur moyenne d’une version d’arbre.
h’ Pour l’arbre B+V et le BT-Tree, h’ est le nombre de niveaux créés dans l’arbre, au delà du niveau h, suite à la création de V-1 VBD. Pour l’OB-Trees, h’ est la hauteur de l’index des VBD.
H Nombre de nœuds internes à visiter avant d’atteindre les nœuds feuilles. Pour l’arbre B+V et le BT-Tree, H est la hauteur de l’arbre final. H=h+h’.
q(qe, qv) La requête q consiste à chercher les valeurs de qeentités dans qvVBD.
P Nombre de nœuds feuilles à visiter pour répondre à la requête q.
ni (1≤ i ≤h) Nombre moyen de nœuds créés au niveau i de l’index dans la VBD initiale v1.
mi (1≤ i ≤h) Nombre moyen de nouveaux nœuds créés au niveau i de l’index dans chacune des VBD créées après v1. Ni (1≤ i ≤h) Nombre moyen de nœuds créés au niveau i de la l’index après la création de V VBD. Ni= ni+ mi(V − 1).
Ai (1≤ i ≤h) Pour l’OB-Trees, Ai est la probabilité pour que le partage d’un nœud se trouvant à un niveau i soit rompu entre deux versions d’arbre successives. Pour le BT-Tree, Ai est la probabilité pour qu’un nœud au niveau i subisse une scission lors de la prise en compte d’une VBD. Ai=mni
i.
B Taille d’un nœud feuille en nombre de valeurs de versions d’entité qu’il peut stocker. F Taille d’un nœud interne en nombre d’entrées qu’il peut stocker.
b Nombre moyen de versions d’entité stockées dans un nœud feuille. Pour le B+V arbre et l’OB-Trees, b≈ B ln 2. f Nombre moyen d’entrées stockées dans un nœud interne. Pour le B+V arbre et l’OB-Trees, f≈ F ln 2.
b’ Nombre moyen d’identificateurs d’entité différents apparaissant dans un nœud feuille du BT-Tree. b’≈ uB ln 2. f ’ Soit Ij un nœud interne du BT-Tree. f ’ est le nombre moyen d’entrées de Ij, valides par rapport aux VBD
appartenant au sous-ensemble connexe (vin,vout) correspondant à Ij. f ’≈ uF ln 2.
u Dans le BT-Tree si le nombre de versions d’entité (respectivement le nombre d’entrées) à dupliquer lors d’une scission dépasse uB (respectivement uF ), la scission est suivi par un éclatement.
Figure 14: Liste des symboles utilisés
3.3 Arbre B+V
3.3.1 Évaluation de H
• Évaluation de h, hauteur du B+V arbre initial
Soit B le nombre de versions d’entité qu’un nœud feuille peut contenir, b le nombre moyen de versions d’entité stockées dans un nœud feuille, F le nombre d’entrées qu’un nœud interne peut contenir et f le nombre moyen d’entrées stockées dans un nœud interne. Les valeurs admises pour b et f sont :
b≈ B ln 2 et f≈ F ln 2 [Yao77].
L’arbre B+V initial indexe E versions d’entité. Dans cet arbre il existe donc, en moyenne, n1 = Eb nœuds au niveau 1 (niveau des nœuds feuilles),
n2= bfE nœuds au niveau 2, etc.. En généralisant à l’ensemble des niveaux de l’arbre, nous obtenons :
ni = bfEi−1 (avec, 1 ≤ i ≤ h). (3.3.1)
Au niveau h du B+V arbre initial, niveau de la racine, il existe nh= bfEh−1=1 nœud, d’où :
h=1+logf E
b. (3.3.2)
• Évaluation de h’
h’ est fonction de Nh, le nombre de nœuds créés
au niveau h du B+V arbre final. En adoptant le même principe de calcul que pour h, on a :
h’=logfNh = logf(nh + mh(V − 1)), avec nh, le
nombre moyen de nœuds créés au niveau h dans le
B+V arbre initial (nh = E
bfh−1=1) et mh, le nombre
moyen de nouveaux nœuds créés au niveau h du
B+V arbre à chaque prise en compte d’une VBD.
À la prise en compte de chaque nouvelle VBD, aE versions d’entité sont insérées dans le B+V arbre. D’où : mi = bfaEi−1 (avec, 1 ≤ i ≤ h). Comme
E
bfh−1 = 1, mh= a et
h’=logf1 + a(V − 1). (3.3.3)
• Évaluation de H=h+h’
Les équations (3.3.2) et (3.3.3) impliquent :
H = h + h0 = 1 + logf Eb.
3.3.2 Évaluation de P
P représente le nombre moyen de nœuds feuilles
à visiter pour répondre à une requête q(qe,qv).
L’évaluation de P pour l’arbre B+V diffère selon que les versions d’une même entité tiennent dans un seul nœud feuille, ou non. Chaque entité possède en moyenne 1+a(V -1) versions. Si les versions d’une entité ne tiennent pas dans une seule feuille, alors 1+a(V -1)>B ⇔ a>B−1V −1. Inversement, lorsque toutes les versions d’une entité tiennent dans un même nœud feuille, a≤ B−1
V −1.
1. cas a > B−1V −1 : pour qv VBD, chaque entité
possède en moyenne 1+a(qv-1) versions. Pour
il faut visiter en moyenne d1+a(qv−1)
b e nœuds
feuilles. Pour qe entités, P=qed1+a(qbv−1)e.
2. cas a < B−1V −1 : dans ce cas, qv n’a
aucune incidence sur P, puisque chercher une ou toutes les versions d’une entité, revient à visiter un seul nœud feuille. Les qe
entités concernées par la requête q, possèdent en moyenne qe(1+a(V -1)) versions. Pour
extraire qe(1+a(V -1)) versions d’entité, le
nombre moyen de nœuds feuilles à visiter est égal à P= dqe
b (1 + a(V − 1))e.
3.3.3 Évaluation du coût de stockage Comme il n’y a pas de duplication, R=1.
3.4 Overlapping B-Trees
3.4.1 Observations générales
La considération du régime permanent d’une base multiversions indexée par l’OB-Trees, amène à l’observation suivante : toutes les versions d’arbre ont un même nombre de nœuds au niveau i. Ce nombre est égal au nombre moyen de nœuds créés au niveau i de la version d’arbre initiale :
ni = bfEi−1 (avec, 1 ≤ i ≤ h). (3.4.1)
Ceci s’explique comme suit. La modification d’un nœud feuille Dj, partagé entre deux versions d’arbre
successives O+(v) et O+(v’), entraîne la création dans O+(v’) d’un nouvelle feuille D’j, copie de Dj.
Si la modification est une mise-à-jour d’une entité
e, ((e,v’ ),val’ ), remplace ((e,v ),val) dans D’j. En
conséquence, D’j, même saturé, n’est pas éclaté
et O+(v) et O+(v’) gardent un même nombre de nœuds. Dans un régime permanent seules les modifications de type mises-à-jour sont considérées.
3.4.2 Évaluation de H
• Évaluation de h
L’équation (3.4.1) implique : h=1+logf Eb.
• Évaluation de h’
h’ est la hauteur de l’arbre B+ utilisé comme index
des racines des V versions d’arbres : ⇒h’=logfV. • Évaluation de H=h+h’
H=h+h’=1+logf V E
b .
3.4.3 Évaluation de P
P représente le nombre moyen de nœuds feuilles
à visiter pour répondre à une requête q(qe,qv).
L’évaluation de P, nécessite au préalable celle de
A1, la probabilité que le partage d’une feuille soit rompu entre deux versions d’arbre successives.
• Évaluation de A1
A1 est le rapport de m1 à n1, où m1 est le nombre de nouvelles feuilles créées dans une version d’arbre
O+(v) et n1 le nombre total de nœuds feuilles de
O+(v). D’où :
A1 = mn1 1
(3.4.2) D’après l’équation (3.4.1), n1 = Eb. L’évaluation de m1 diffère selon que l’OB-Trees dégénère ou non en un ensemble d’arbres indépendants. En prenant l’hypothèse de l’uniformité de distribution des données, l’OB-Trees ne dégénère lorsque aE, le nombre d’entités mises-à-jour dans une VBD v, ne dépasse pas n1, le nombre de feuilles de O+(v), c’est-à-dire lorsque aE < n1⇔ aE < Eb ⇔ a < 1b.
· Cas a ≥ 1b : dans ce cas m1 = n1 ⇔ A1=1.
· Cas a < 1b : dans ce cas le nombre de feuilles dont
le partage est rompu dans une version d’arbre est égal au nombre d’entités mises-à-jour :
m1 = aE ⇒ A1 = aEE b
= ab.
• Évaluation de P
La requête q(qe,qv) consiste à chercher les valeurs
que possèdent qe entités dans qv VBD successives.
Soit v et v’ deux VBD successives concernées par q. Le nombre moyen de nœuds feuilles à visiter dans
O+(v), pour trouver les valeurs de qe entités, est
égal à dqe
b e. Une partie des nœuds feuilles visités
dans O+(v), est partagée avec O+(v’). Dans O+(v’) ne sont visités que les nœuds non partagés avec
v. La proportion des feuilles non partagées entre
O+(v) et O+(v’) est A1, proportion des feuilles
dont le partage est rompu lors de la prise en compte de v’. Le nombre moyen de nœuds feuilles à visiter dans O+(v’) est donc égal à A1dqe
be. En généralisant
à l’ensemble des versions d’arbre concernées par la requête q, nous obtenons : P=dqe
be(1 + A1(qv− 1)).
Si l’OB-Trees ne dégénère pas, A1 = ab et
P=dqe
b e(1 + ab(qv− 1)).
Sinon, A1=1 et P=dqe
3.4.4 Évaluation du coût de stockage
• Évaluation de Er
Er est le nombre total de versions d’entité stockées.
Chaque nœud feuille stocke en moyenne b versions d’entité : ⇒ Er=bN1=b(n1+m1(V-1 )).
Si l’OB-Trees ne dégénère pas, on a : n1=E
b, m1=aE
et donc Er= E(1 + ab(V − 1)).
Sinon : m1=n1=Eb et Er= b(Eb +Eb(V − 1))=VE.
• Évaluation de R, le facteur de redondance R=Er
E=
1+ab(V −1)
1+a(V −1). Pour V assez grand, tel que 1 ¿ a(V-1), R≈ ab(V −1)a(V −1) =b. Intuitivement ceci s’explique comme suit. Chaque nœud feuille
Di stocke b versions d’entité. L’hypothèse de l’uniformité de distribution des données suppose qu’une entité e ayant une version stockée dans Di,
subit une mise-à-jour une fois sur b. Or, à chaque fois qu’une entité e’ dont l’identificateur apparaît dans Di et telle que e’ 6=e, subit une mise-à-jour,
la version de e est dupliquée, puisqu’une copie du nœud Di est créée. Ainsi, la version de e stockée
dans Di est dupliquée, en moyenne, b fois.
Si l’OB-Trees dégénère, R=Er
E=1+a(V −1)V . Pour V assez grand, tel que 1 ¿ a(V-1), R≈ 1a.
3.5 Approche hybride : BT-Tree
3.5.1 Observations générales
Rappelons que dans le BT-Tree, à un nœud feuille Di, correspond un intervalle d’identificateurs
d’entités (emin,emax) et un sous-ensemble connexe
(vin,vout). Ceci signifie que Di stocke les valeurs
des versions d’entité valides par rapport aux VBD appartenant à (vin,vout) et ayant des identificateurs
d’entité appartenant à (emin,emax). Soit v une VBD
appartenant à (vin,vout) (Di est valide par rapport
à v ). Lorsqu’une base de données multiversions indexée par le BT-Tree est en régime permanent, le nombre de versions d’entité stockées dans Di
et valides par rapport à v correspond au nombre d’identificateurs d’entité différents apparaissant dans Di (puisque chacune de ces entités possède exactement une version valide par rapport à v ). Le nombre moyen d’identificateurs d’entité différents apparaissant dans un nœud feuille est noté b’. Rappelons également que lors de la scission d’un nœud feuille Di par une VBD v, si le nombre de versions d’entité à dupliquer dépasse un seuil égal à
uB, la scission est suivie par un éclatement selon un
identificateur d’entité. Lorsqu’une base de données
multiversions est en régime permanent, la valeur admise pour b’ est ≈ uB ln 2 [LS90]. Comme la scission et l’éclatement des nœuds internes suivent les mêmes principes que les nœuds feuilles, dans la suite nous prenons l’hypothèse qu’un nœud interne
Ij contient en moyenne f’≈ uF ln 2 entrées valides par rapport aux VBD appartenant au sous-ensemble connexe (vin,vout) correspondant à Ij.
La considération du régime permanent d’une base multiversions indexée par le BT-Tree amène à trois observations :
· Observation 1 : après la création de la VBD
initiale, il n’y a que des scissions dans le BT-Tree. Ceci s’explique comme suit. En régime permanent il n’y a que des mises-à-jour d’entités. Le nombre d’identificateurs d’entités apparaissant dans un nœud feuille Diest donc le même lors de la création
de Disuite à une scission, que lorsque Disubit une
scission. Le nombre d’identificateurs apparaissant dans Dilors de sa création est inférieur au seuil uB.
Par suite, lors de la scission de Di, le nombre de
versions d’entité à dupliquer est inférieur à uB. La scission n’est donc pas suivie par un éclatement.
· Observation 2 : Soit v et v’ deux VBD successives
et i un niveau du BT-Tree, tel que 1≤i≤h. Le nombre de nœuds se trouvant au niveau i et valides par rapport à v’ est égal au nombre de nœuds du même niveau, valides par rapport à v.
Cette observation est une conséquence directe de l’Observation 1. La prise en compte d’une VBD v’ se passe en deux étapes : dérivation de v’ à partir de v, puis, mise-à-jour d’entités dans v’. Lors de la création de v’, les nœuds feuilles valides par rapport à v, le sont également pour v’. Lors des mises-à-jour d’entités dans v’, si un nœud feuille Di
subit une scission, une seule feuille Di+1 est créée
dans le BT-Tree, puisqu’en régime permanent il n’y a pas d’éclatement. Suite à la scission, Di n’est
plus valide par rapport à v, alors que D’i l’est. Le
nombre de nœuds feuilles valides par rapport à v’ reste donc égal au nombre de nœuds feuilles valides par rapport à v.
· Observation 3 : le nombre de nœuds du niveau i valides par rapport à une VBD v est égal au
nombre de nœuds créés à ce niveau dans le
BT-Tree initial, soit :
ni = b0fE0i−1 (avec, 1≤i≤h). (3.5.1)
Ceci est une conséquence directe de
3.5.2 Évaluation de H
• Évaluation de h
Dans le BT-Tree initial il existe un seul nœud au niveau h, le nœud racine, d’où,
nh= E
b0f0h−1 = 1⇔ h=1+logf0 Eb0. • Évaluation de h’
h’ est fonction de Nh, le nombre de nœuds créés au
niveau h du BT-Tree final : h’=logfNh. Comme
Nh = nh+ mh(V − 1),
h’=logf0nh+ mh(V − 1) (3.5.2)
L’évaluation de nh est donnée dans l’équation (3.5.1). mh est évalué dans le paragraphe suivant.
Un nœud feuille contient en moyenne b’ versions d’entité lors de sa création. Il subit donc une scission après B-b’ insertions de versions d’entité. Lors de la prise en compte d’une VBD v, aE versions d’entités sont insérées dans le BT-Tree. Le nombre de nœuds feuilles valides par rapport à v est égal à
n1 (Observation 3 ). Chaque nœud feuille valide par rapport à v reçoit donc de cette VBD, aE
n1 versions d’entité, en moyenne. Un nœud feuille créé lors de la prise en compte de v, subit une scission après la prise en compte, à partir de v, de (B−b0)n1
aE VBD.
Ainsi, après la prise en compte de (B−b0)n1
aE VBD,
en moyenne, n1 nouveaux nœuds feuilles sont créés dans le BT-Tree. Il s’ensuit que le nombre moyen de nouvelles feuilles créées à chaque prise en compte d’une VBD est égal à m1 = (B−b0)n1n1
aE
= B−baE0. En
utilisant le même raisonnement, nous obtenons :
mi = (B − b0)(F − faE 0)i−1 (avec, 1≤i≤h). (3.5.3)
Au niveau h, nh = E b0f0h−1 = 1 ⇔ E = b0f0h−1. Comme, b’≈ uB ln 2 et f’≈ uF ln 2, mh = (B−b0)(F −faE 0)h−1 = ab 0f0h−1 (B−b0)(F −f0)h−1, d’où, mh ≈ a(1−u ln 2u ln 2 )h et h0 = log f0nh+ mh(V − 1) ⇔ h0 = log f01 + a(V − 1)(1−u ln 2u ln 2 )h • Évaluation de H=h+h’
H=h+h’=1+logf0 Eb0(1 + a(V − 1)(1−u ln 2u ln 2 )h).
3.5.3 Évaluation de P
L’évaluation de P pour le BT-Tree suit le même raisonnement que pour le OB-Trees. Soit A1 la probabilité pour qu’un nœud feuille subisse une scission lors de la prise en compte d’une VBD v.
A1 est évalué par : A1=mn11. Les équations (3.5.3) et (3.5.1) impliquent :
A1 = ab
0
B − b0 (3.5.4)
Considérons la requête q. Soit v et v’ deux VBD successives concernées par q. Le nombre moyen de nœuds feuilles à visiter pour trouver les valeurs que possèdent qe entités dans v est égal à dqbe0e. Lors de
la recherche des valeurs des qe entités dans v’, ne
sont visitées que les feuilles valides par rapport à v’ et non valides par rapport à v. La proportion des feuilles valides uniquement par rapport à v’ est A1, proportion des feuilles subissant une scission dans
v’. Le nombre moyen de nœuds feuilles à visiter
dans v’ est donc égal à A1dqbe0e. L’extension du
raisonnement aux qv VBD concernées par q donne :
P=dqe
b0e(1+A1(qv-1)).
En remplaçant A1 par sa valeur, il résulte :
P=dqe b0e(1+ ab 0 B−b0(qv-1)). Comme b’≈ uB ln 2, P≈d qe uB ln 2e(1+1−u ln 2au ln 2 (qv-1)).
Il est à noter le rôle primordial du seuil u dans les performances d’un index de l’approche hybride. Pour les requêtes dans une VBD (qv=1), plus
la valeur du seuil u est grande, plus petit est
P≈d qe
uB ln 2e et donc meilleures sont les performances
de l’index. Inversement, plus la valeur de u est petite, plus petit est au ln 2
1−u ln 2(qv-1) et donc meilleures sont les performances de l’index pour les requêtes de type suivi de l’évolution. Intuitivement ceci s’explique par le fait que plus u est grand et plus le nombre d’identificateurs d’entité différents apparaissant dans un nœud Di est grand. Or, plus
ce nombre est grand, moins les requêtes à travers plusieurs VBD sont efficaces, puisque Di stocke
moins de versions par entité, et inversement plus les requêtes dans une VBD sont efficaces.
3.5.4 Évaluation du coût de stockage
• Évaluation de Er
Chaque fois qu’un nœud feuille subit une scission, en moyenne b’ versions d’entité sont dupliquées. Le nombre total de scissions au niveau des nœuds feuilles correspond au nombre total de nœuds feuilles créées après la VBD initiale, c’est-à-dire,
m1(V -1). En conséquence,
Er = E + b0m
1(V − 1), où E est le nombre total de versions d’entité sans duplication et b0m
1(V − 1) le nombre total de versions d’entité dupliquées.
Comme m1= aE
B−b0 (équation 3.5.3), Er = E +aEb
0(V −1)
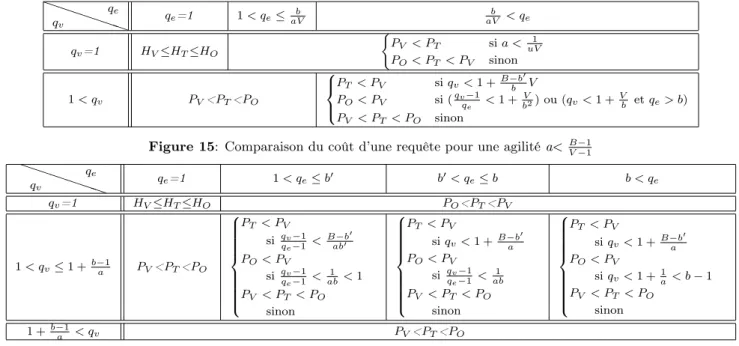
PPP PPP qv qe q e=1 1 < qe≤ aVb aVb < qe qv=1 HV≤HT≤HO ( PV < PT si a < uV1 PO< PT < PV sinon 1 < qv PV<PT<PO 8 > < > : PT< PV si qv< 1 +B−b 0 b V PO< PV si (qvq−1e < 1 + V b2) ou (qv< 1 +Vb et qe> b) PV < PT< PO sinon
Figure 15: Comparaison du coût d’une requête pour une agilité a< B−1 V −1 PPP PPP qv qe q e=1 1 < qe≤ b0 b0< qe≤ b b < qe qv=1 HV≤HT≤HO PO<PT<PV 1 < qv≤ 1 +b−1a PV<PT<PO 8 > > > > > > > > < > > > > > > > > : PT< PV si qv−1 qe−1 < B−b0 ab0 PO< PV si qv−1 qe−1 < 1 ab< 1 PV < PT < PO sinon 8 > > > > > > > > < > > > > > > > > : PT< PV si qv< 1 +B−b 0 a PO< PV si qv−1 qe−1 < 1 ab PV < PT < PO sinon 8 > > > > > > > > < > > > > > > > > : PT< PV si qv< 1 +B−b 0 a PO< PV si qv< 1 +1a< b − 1 PV < PT < PO sinon 1 +b−1 a < qv PV<PT<PO
Figure 16: Comparaison du coût d’une requête pour une agilité a≥ B−1 V −1. • Évaluation du facteur de redondance R
R= Er
E ⇒ R= 1 +
ab0(V −1)
(B−b0)(1+a(V −1)). Pour V assez
grand, tel que 1 ¿ a(V-1), le facteur de redondance du BT-Tree est égal à R= 1 + b0
(B−b0). Comme
b’≈ uB ln 2, R≈ (1−u ln 2)1 . Dans [LS90, JSLB00,
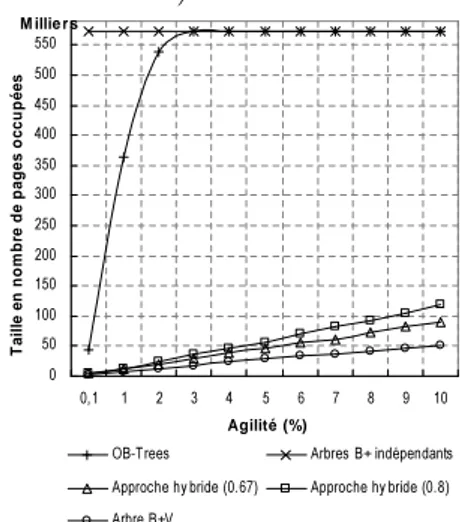
JSLB03, JSL+04] le seuil u est fixé à 0,67. Pour cette valeur R≈1,9. Dans [BGO+96, VV97, TPZ02] le seuil u est fixé à 0,8. Pour cette valeur R≈2,2. Lorsqu’une base de données multiversions est indexée par un ensemble d’arbres B+ indépendants son facteur de redondance est égal à ≈ 1
a (cf.
sous-section 3.4.4). Une base de données multiversions indexée par le BT-Tree occupe donc plus d’espace que si elle est indexée par un ensemble d’arbres B+ indépendants lorsque son facteur de redondance
R> 1a, c’est-à-dire, (1−u ln 2)1 ≥ 1a ⇔ 1 − u ln 2 ≤a. R≈ (1−u ln 2)1 croît avec l’augmentation de la valeur du seuil. Intuitivement ceci s’explique par le fait que plus u est grand et plus le nombre d’identificateurs d’entité différents apparaissant dans un nœud est grand et donc plus grand est le nombre de versions d’entité à dupliquer lors d’une scission.
3.6 Comparaisons
Cette section compare l’arbre B+V à l’OB-Trees et au BT-Tree.
3.6.1 Coût d’une requête
La comparaison du coût d’une requête q(qe,qv) est
faite selon P, le nombre de nœuds feuilles à visiter pour répondre à q.
Le calcul de P pour les différents index amène à considérer plusieurs cas selon les valeurs prises par
qe, qv et l’agilité a. Ces cas sont résumés dans
les tableaux 15 et 16, où la comparaison est faite respectivement pour une agilité a< B−1V −1 et une agilité a≥ B−1V −1. Dans ces tableaux PV, PT et
PO correspondent respectivement à P pour l’arbre
B+V, le BT-Tree et l’OB-Trees. Dans le cas où
qe=qv=1, P ne permet pas de départager les index
(PV=PT=PO=1). Dans ce cas H, nombre moyen de
nœuds internes à visiter avant d’atteindre les nœuds feuilles, est considéré. Dans les tableaux 15 et 16,
HV, HT et HO correspondent respectivement à H
pour l’arbre B+V, le BT-Tree et l’OB-Trees. Pour la recherche de la valeur d’une version d’entité, la considération de H permet de conclure que l’arbre
B+V est plus performant que le BT-Tree et l’OB-Trees.
Pour les requêtes dans une VBD (qv=1), le
l’OB-Trees est bien sûr plus performant que l’arbre B+V
et le BT-Tree. En règle générale, le BT-Tree est plus performante que l’arbre B+V pour ce type de requêtes. La seule exception à cette règle est lorsque l’agilité est très faible : a< 1
uV (tableau 15).
Pour les requêtes de suivi de l’évolution d’une entité (qe=1) l’arbre B+V est plus performant que le
BT-Tree, plus performante elle-même que l’OB-Trees.
Lorsque qe>1 et qv>1, en règle générale l’arbre B+V