Automatic reconstruction and analysis of security policies from deployed security components
Texte intégral
Figure


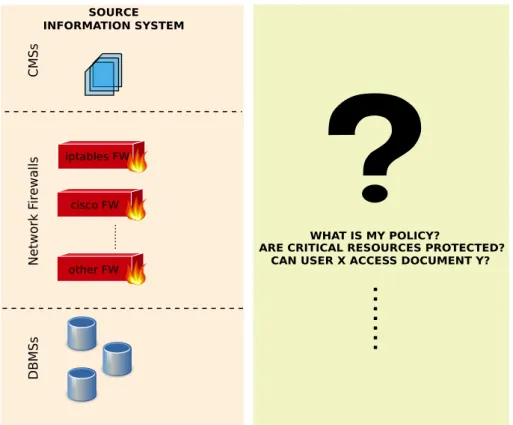


![Figure 2.7: Model transformation [35]](https://thumb-eu.123doks.com/thumbv2/123doknet/7945760.266185/28.892.212.771.712.908/figure-model-transformation.webp)
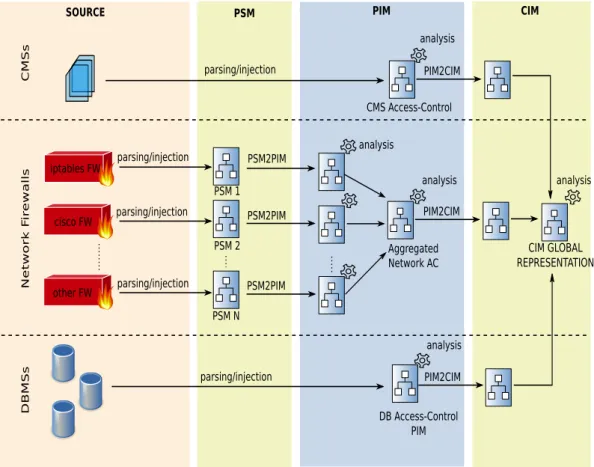
![Figure 2.8: Bridging technological spaces [29]](https://thumb-eu.123doks.com/thumbv2/123doknet/7945760.266185/29.892.140.661.375.685/figure-bridging-technological-spaces.webp)
Documents relatifs
Our work is contextualized in the field of automatic code generation for security analysis on communicating em- bedded systems. The choice of this type of system is justified on the
To model this behaviour, the Delivery Guy and the Smart Lock have two execution branches, one called the normal behaviour, when the Attacker does not interfere and a second one,
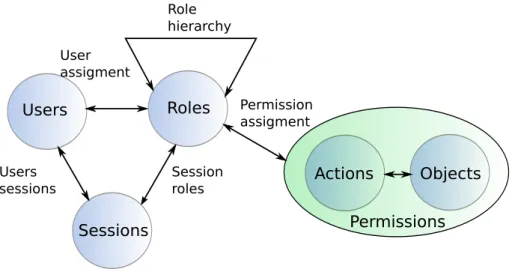
RBAC policies Prerequisite constraint Cardinality constraint Precedence and dependency constraint Role hierarchy constraint Separation of duty constraint (SoD) Binding of duty
1/ Les contenus accessibles sur le site Gallica sont pour la plupart des reproductions numériques d'oeuvres tombées dans le domaine public provenant des collections de la
To generate executable test cases from misuse case specifications we employ some concepts of natural language programming, a term which refers to approaches automatically
They are collected, specified as reusable aspect models (RAM) [7] to form a coherent system of them. While not only specifying security patterns at the abstract level like in
Towards the third main contribution, we have been working on a Mds approach based on a library-like System of generic aspect-oriented Security design Patterns in which security
In this paper, we introduce a framework composed of a syn- tax and its compositional Petri net semantics, for the specification and verification of properties (like authentication)
