Performance Analysis of Peer-to-Peer Storage Systems
Texte intégral
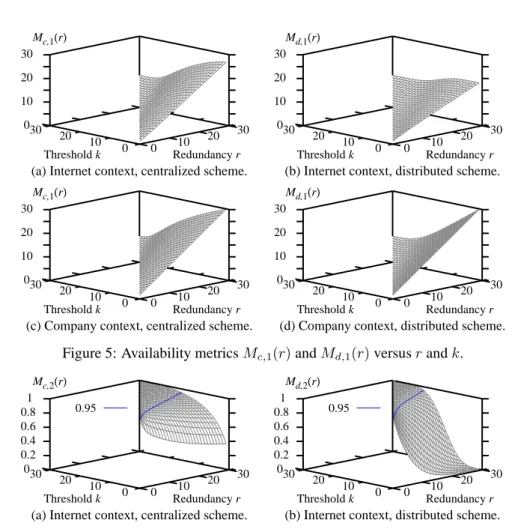
Figure


![Figure 3: Expected lifetime E[T c (r)] and E[T d (r)] (expressed in years) versus r and k.](https://thumb-eu.123doks.com/thumbv2/123doknet/12400592.332004/15.892.188.691.208.653/figure-expected-lifetime-e-t-expressed-years-versus.webp)

Documents relatifs
– A peer that is interior (i.e., non leaf) node of the distribution tree starts uploading the file to k other peers, each rate b/k, soon as it has received the first chunk.. This
– A peer that is interior (i.e., non leaf) node of the distribution tree starts uploading the file to k other peers, each rate b/k, soon as it has received the first chunk.. This
Fabien Mathieu
• handle a request from a Storer that declares it stores a fragment for a file (lines 9–10): the request is received line 9 and processed line 10 by getting the current
The simulator takes as input a configu- ration file that describes the simulation environment, i.e., information about: the number of peers in the simulated network; the number
Data Availability Both blockchain and content-addressable distributed le system are based on the peer-to-peer network. Users of EthDrive are in the Ethereum blockchain network and
In prac- tice, load balance depends also on the distribution of objects on the peers, the object size, and the storage, processing, and communication capacity of the peers..
In this work, we propose the organization of document storage and retrieval in a Corporate Semantic Web (CSW), based on two procedures: First, we solve content location and built
