Mixture models, latent variables and partitioned importance sampling
17
0
0
Texte intégral
Figure

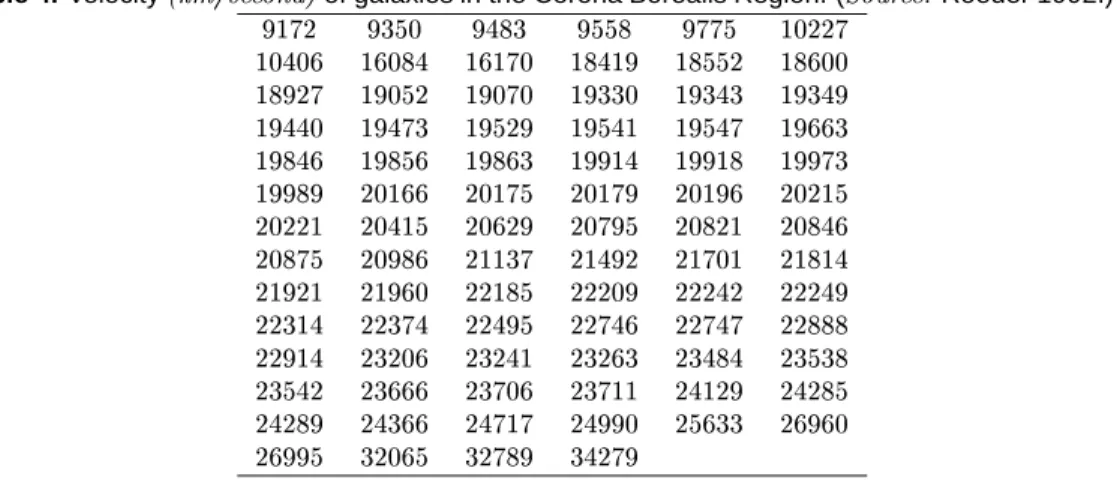
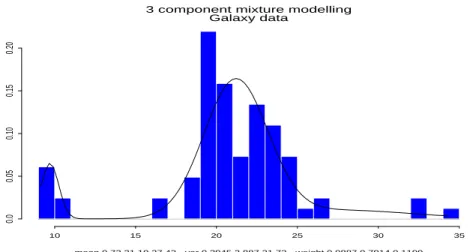
Documents relatifs