Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat
Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
FACULT
THÈSE DE DOCTORAT D’
Discipline
Spécialité
Modèles de Machines Virtuelles
Basées sur des Systèmes Distribués Multi
Conception,
Devant le jury :
Président :
Youssef BELQASMIExaminateurs :
Ahmed HAMMOUCH Abdelaziz MARZAK El Hossein ILLOUSSAMEN Mohammed OUADI BENSALAH Omar BOUATTANEFaculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat
Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
FACULTTÉ DES SCIENCES
Rabat
SE DE DOCTORAT D’ÉTAT
Présentée par :
Mohamed YOUSSFI
Discipline : Sciences de l’ingénieur
Spécialité : Systèmes Parallèles et Distribués
Modèles de Machines Virtuelles Massivement Parallèles
Basées sur des Systèmes Distribués
Multi-onception, Implémentation et Applications
Soutenue Le 22 Juillet 2015
BELQASMI : PES, Secrétaire Général
MMOUCH : PES, ENSET, CNRST, UM5,
MARZAK : PES, FS Ben M'Sik, UH2, Casablanca
ILLOUSSAMEN : PES, ENSETM, UH2, Casablanca
OUADI BENSALAH : PES, FS de Rabat, UM5, R
BOUATTANE : PES, ENSETM, UH2, Casablanca
Faculté des Sciences, 4 Avenue Ibn Battouta B.P. 1014 RP, Rabat – Maroc Tel +212 (0) 37 77 18 34/35/38, Fax : +212 (0) 37 77 42 61, http://www.fsr.ac.ma
N° d’ordre : 2780
TAT
Massivement Parallèles
-Agents
pplications
ecrétaire Général du MENFP
: PES, ENSET, CNRST, UM5, Rabat , UH2, Casablanca , UH2, Casablanca
, UM5, Rabat , Casablanca
A Mon très cher père,
Que dieu repose son âme en paix, et l’accueille au paradis
A ma très chère mère,
Puisse Dieu tout puissant te donner santé, bonheur et longue vie
A ma très chère femme Hanane,
Merci pour tout le soutien que tu m’as accordé durant toute la durée de
cette thèse de longue durée. Je prie dieu pour te préserver ta bonne santé
et je te souaite tout le bonheur du monde ma chérie.
A mes très chères filles Malak et Ines,
Vous êtes les plus beaux cadeaux de ma vie avec votre mère. Je prie dieu
pour vous protéger et vous préserver votre bonne santé et un grand
merci à maman qui a su vous donner son amour et une meilleure
éducation. Je vous aime très fort.
A tous Mes chers frères et sœurs
A
VANT
P
ROPOS
Les travaux de recherche effectués dans le cadre de ce doctorat d’état ont été effectués sous direction du professeur Mohammed OUADI BENSALAH, Laboratoire de Mécanique et Matériaux, Faculté des Sciences de Rabat, Université Mohammed V de Rabat et la codirection du professeur Omar BOUATTANE directeur du laboratoire Signaux, Systèmes Distribués et Intelligence Artificielle (SSDIA), ENSET Mohammedia, Université Hassan II de Casablanca.
Je tiens à exprimer mes sincères remerciements :
Au professeur Mohammed OUADI BENSALAH d’avoir accepté de diriger les travaux de recherche de cette thèse et pour son dynamisme, ses compétences scientifiques qu’il a mis à notre service pendant la préparation de cette thèse et ses grandes qualités humaines. Qu’il trouve ici le témoignage de mon estime et ma profonde connaissance pour ses conseils pertinents, ses recommandations précieuses et son suivi rigoureux qui m’ont permis de mener à bien les travaux de cette thèse.
Au professeur Omar BOUATTANE, co-directeur de cette thèse pour son encadrement, son suivi rigoureux, ses recommandations précieuses, sa patience et ses grandes qualités humaines et également pour sa disponibilité tout au long de la réalisation de ce travail. Qu’il trouve ici le témoignage de mon estime et ma profonde connaissance pour ses conseils pertinents, ses recommandations précieuses, son suivi rigoureux, et ses compétences scientifiques qu’il a mis à ma disposition pour mener à bien ces travaux de recherches.
Au professeur Youssef BELQASMI, PES, secrétaire général du Ministère de l’Education Nationale et de la Formation Professionnelle, qui nous a fait l’honneur de présider le jury de cette thèse. Qu’il trouve ici le témoignage de mon estime et ma profonde reconnaissance pour ses grandes qualités scientifiques, de son dynamisme et pour les efforts qu’il déploie pour favoriser le développement de l’enseignement et de la recherche scientifique dans notre pays.
Au professeur Ahmed HAMMOUCH, PES à l’ENSET de Rabat, Université Mohammed V, Chef de Département des Affaires Scientifiques et Techniques du CNRST, pour le temps précieux qu’il a consacré pour juger ce travail, d’en être rapporteur et qui m’a fait l’honneur
d’être parmi les membres de ce jury. Qu’il trouve ici le témoignage de mon estime et ma profonde reconnaissance.
Au professeur Abdelaziz MARZAK, PES à la faculté des sciences Ben M'Sik, Université Hassan II de Casablanca, pour le temps précieux qu’il a consacré pour juger ce travail, d’en être rapporteur et qui m’a fait l’honneur d’être parmi les membres de ce jury. Qu’il trouve ici le témoignage de mon estime et ma profonde reconnaissance.
Au professeur El Hossein ILLOUSSAMEN, PES à l’ENSET Mohammedia, Université Hassan II de Casablanca, pour le temps précieux qu’il a consacré pour examiner ce travail, d’en être rapporteur et qui m’a fait l’honneur de faire parti des membres de ce jury. Qu’il trouve ici le témoignage de mon estime et ma profonde reconnaissance.
Un grand remerciement également pour Le professeur Mohammed LFERDE, Directeur du CEDoc de la faculté des sciences de Rabat, pour ses attitudes positives et encourageantes qui ont permis de faciliter le déroulement de ces travaux de recherches. Qu’il trouve ici le témoignage de mon estime et ma profonde reconnaissance.
Enfin merci à tous ceux que je n’ai pas pu citer mais qui ont toutes mes amitiés et ma reconnaissance.
R
ESUME
Dans cette thèse, nous présentons des modèles de machines virtuelles massivement parallèles destinées au calcul de hautes performances. Un premier volet de ce travail a été consacré à la présentation d’un modèle d’émulation de machines massivement parallèles. Cet émulateur permet d’implémenter et de tester des algorithmes parallèles avec différentes topologies. En utilisant l’approche orientée composants et le multi threading, nous avons conçu et développé un noyau extensible dans lequel, nous avons traduit les caractéristiques physiques de tous les composants d’une machine massivement parallèle. Basé sur une couche abstraite, fermée à la modification et ouverte à l’extension, le modèle donne la possibilité aux autres développeurs de créer leurs propres implémentations de machines virtuelles massivement parallèles polymorphiques adaptées à la nature des problèmes parallèles à résoudre. Un langage de programmation parallèle basée sur la technologie XML ainsi que son compilateur ont été également développés. Le deuxième volet de cette thèse est consacré à la parallèlisation des algorithmes de classification des données appliqués à la segmentation des IRM cérébrales. L'utilisation de l'architecture parallèle est introduite afin d'améliorer la complexité des algorithmes correspondants. Les algorithmes parallèles proposés sont assignés à être implémentés sur une machine massivement parallèle qui est la maille connexe reconfigurable (MCR).
Dans ce travail de recherche, nous présentons également un autre modèle de machine virtuelle massivement parallèle basée sur des agents mobiles, conçu pour le calcul parallèle de hautes performances dans des systèmes distribués. Ce modèle est construit à base d’agents mobiles représentants des unités de traitement virtuelles appelées VPUs. Ces processeurs virtuels sont déployés dans des machines physiques hétérogènes du système distribué selon un système d’équilibrage de charges élaboré. Tous les composants de ce modèle sont orchestrés par un agent spécial qui représente un Host virtuel (VHA). L’objectif de cette machine virtuelle parallèle, basée sur des systèmes multi-agents, est de permettre, à l’utilisateur, de construire différents types d’architectures parallèles virtuelles, adaptées à la résolution des problèmes parallèles qui nécessitent des calculs intensifs ou à forte masse de données, en s’appuyant sur des systèmes distribués hétérogènes. Deux systèmes d’équilibrage de charges ont été développés dans ce travail. Le premier est basé sur le principe de migration dynamique des agents VPUs en vue de maintenir le système distribué équilibré. Le deuxième modèle est basé sur l’approche orientée aspect qui consiste à séparer la préoccupation de l’équilibrage de
charges du module de distribution de tâches du middleware. Pour valider nos modèles, des exemples d’applications parallèles, ont été mis en œuvre pour démontrer l'efficacité des modèles proposés.
Mots-clefs : Systèmes Parallèles, Systèmes Distribués, Calcul de hautes performances,
A
BSTRACT
In this thesis, we present a computational model of massively parallel virtual machine assigned for high performance computing. The first part of this work has been devoted to design and develop an emulation model of massively parallel machines. This emulator allows us to implement and test the parallel algorithms using different topologies. Due to the constraints of unavailability of some real massively parallel machines, this emulator allows making more popular the parallel programming techniques. Using the component oriented approach and the multi threading, we developed an extensible core wherein we translated all the physical characteristics and all the components of a physical parallel machine. Basing on an abstract layer which is closed to any modification and open to extensions, it provides an opportunity for other programmers to create their own implementations adapted to the nature of parallel problems in query. In this context, we present a particular implementation that emulates the reconfigurable parallel machine named "Mesh 2D" which is a SIMD structure parallel computing. A parallel programming language based on XML technology and its compiler was also developed.
The second part of this thesis is devoted to some parallel applications that are implemented and tested on the proposed emulator. Among these applications, we propose two parallel algorithms for data classification, and their application to the magnetic resonance images (MRI) segmentation. The use of parallel architecture in the classification field is introduced to improve the complexity of the corresponding algorithms. The proposed algorithms are assigned to be implemented on a parallel machine which is the reconfigurable mesh computer (RMC).
To extend this research work, we present another massively parallel computational model based on mobile agents and assigned to be implemented on distributed systems. This model is built around a virtual CPU called VPU. Each VPU is modeled by a mobile agent deployed in heterogeneous physical processing representing a node of the distributed system. The VPUs are designed to communicate with each other asynchronously to exchange, locally or remotely, ACL messages (Agent Communication Language) containing data, instructions or tasks. In this model, we designed a special agent to represent the virtual host of the parallel machine. It manages the life cycle of the all components of the parallel machine such as: VPUs, load balancing system and associated components of parallel programs. In this model,
the VPUs can also use a virtual shared memory represented by a hierarchy of mobile agents. The aim of this computational model based on multi-agent system, is to allow the user to build an adapted parallel virtual architectures to the problem taking into account the kind of the required intensive computations and the large amount of data. Two load balancing systems for distributed multi-agent systems have been developed in this work. The first system is based on the principle of dynamic migration of worker agents to maintain the distributed system in a balanced state. In the second system, we proposed a model based on an aspect-oriented approach in order to separate the load balancing concern from the task distribution middleware. To validate our models, some parallel application examples, have been implemented to demonstrate the effectiveness of the proposed models.
Keywords: Parallel Systems, Distributed Systems, High performance computing, Mobile
S
OMMAIRE
:
Résumé ... 2
Abstract ... 4
Avant Propos ... 6
Sommaire : ... 8
Liste des figures ... 11
Liste des tableaux ... 14
Introduction générale ... 16
Chapitre 1 ... 23
Systèmes Parallèles et Distribués ... 23
I.1. Introduction ... 23
I.2. Architectures parallèles ... 24
I.2.1. Classification des architectures parallèles ... 24
I.2.2. Parallélisme de données et de traitements ... 28
I.3. Architectures Massivement Parallèles ... 29
I.3.1.Maille Connexe Reconfigurable (MCR) ... 29
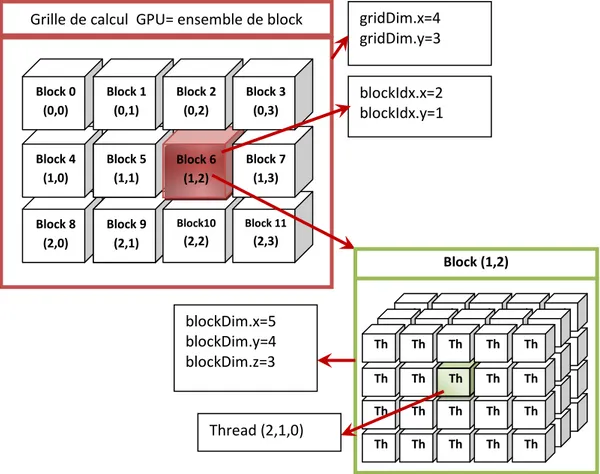
I.3.2.Architecture à base d’unités de traitement graphique GPU (Graphical Processing Unit) .... 34
I.4. Systèmes Distribués ... 40
I.4.1. Présentation des systèmes distribués ... 40
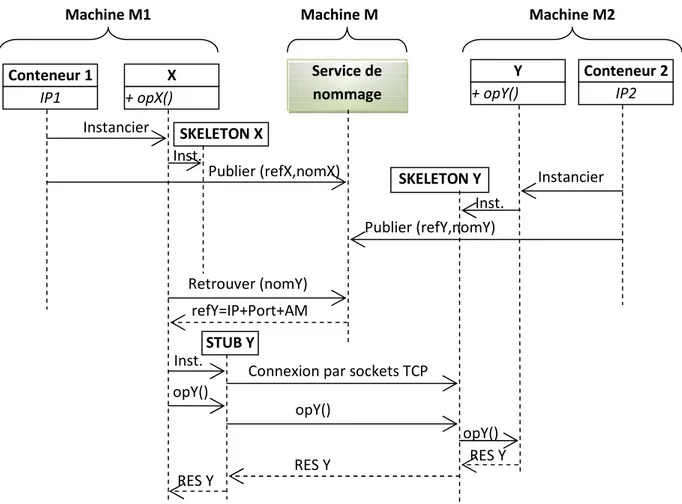
I.4.2. Middlewares ... 42
I.5. Conclusion ... 49
Chapitre 2 ... 50
Machine Massivement Parallèle : ... 50
Emulation basée sur le multi threading ... 50
II.1. Introduction ... 50
II.2.1 Présentation ... 51
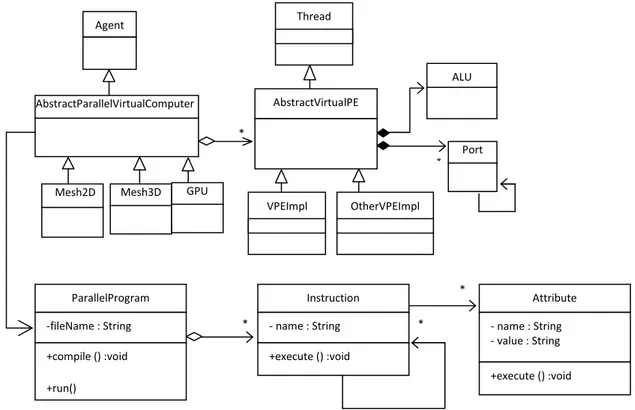
II.2.2. Modèle du processeur élémentaire PE ... 52
II.2.3. Architecture et conception du modèle proposé ... 56
II.3. Exemple d’application. ... 57
II.3.1. Présentation. ... 57
II.3.2. Description et fonctionnement du programme parallèle ... 58
II.4. Conclusion ... 61
Chapitre 3 ... 62
Classification parallèle de données ... 62
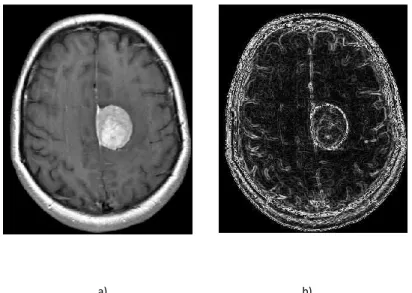
Application à la segmentation des IRM cérébrales ... 62
III.1. Présentation ... 62
III.2. Parallélisation de l’algorithme de classification C-MEANS ... 66
III.2.1 Introduction ... 66
III.2.2 Algorithme « c-means » Standard ... 66
III-2.3. Algorithme Parallèle « c-means » sur une architecture MCR ... 68
III.2.4. Analyse de la complexité ... 72
III.2.5. Implémentations et résultats ... 75
III-2.6- Conclusion ... 82
III.3. Parallélisation de l’algorithme de classification FUZZY C-MEAN ... 83
III.3.1. Introduction ... 83
III.3.2. Algorithme de classification Fuzzy C-MEAN Standard (FCM) ... 83
III.3.4. Parallélisation de l’algorithme de classification Fuzzy C-MEAN (PFCM) ... 85
III.3.3. Résultats de la segmentation: ... 91
III.3.3. Analyse de la complexité ... 98
III.3.4. Conclusion ... 99
Chapitre 4 ... 100
machine virtuelle parallèle à basé des agents mobiles ... 100
IV-1.Introduction ... 100
IV-2.Architecture de la Machine Virtuelle Parallèle ... 102
IV.3. Composants de la machine virtuelle parallèle ... 105
IV.3.1. Unité Virtuelle de Traitement (VPU). ... 105
IV.3.3. Modèle de la machine virtuelle parallèle ... 110
IV.4. Application : Classification distribuée d’une image de grande taille ... 114
IV.5. Conclusion ... 116
Chapitre 5 ... 118
Système d’équilibrage de charges de la Machine Virtuelle Massivement Parallèle ... 118
V.1. Introduction ... 118
V.2. Notations et hypothèses ... 120
V.3. Système d’équilibrage de charges proposé ... 123
V.3. 1 Détermination de l’indice de performance des nœuds ... 123
V.3.2. Estimation de la distribution de charges pour une tâche quelconque ... 125
V.3. 3. Rééquilibrage de charges par mobilité des agents VPU. ... 128
V.4. Application : Traitement distribué d’un flux d’images ... 131
V.4.1 Initialisation du système d’équilibrage de charges. ... 131
V.4.2. Rééquilibrage de charges. ... 137
V.5. Conclusion ... 140
Chapitre 6 ... 142
Model d’équilibrage de charges basé sur l’approche orientée aspect ... 142
VI.1. Introduction ... 142
VI.2. Architecture du système de distribution de tâches ... 143
VI.3. approche proposée ... 145
VI.3.1.Indice de performances de l’agent travailleur ... 147
VI.3.2. Détermination de la distribution de charges ... 149
VI.4. Application et résultats ... 151
VI.4. Conclusion ... 155
Conclusion Générale ... 161
Références ... 165
L
ISTE DES FIGURES- Figure I.1. Architecture SISD.
- Figure I.2. Architecture SIMD.
- Figure I.3. Architecture MISD.
- Figure I.4. Architecture MISD.
- Figure I.5. Les deux modèles d'une MCR de taille 8 x 8.
- Figure I.6. Matrice de connexion des différentes commutations.
- Figure I.7. Comment GPU accélère l’exécution des applications.
- Figure I.8. Architecture d’un GPU montant le regroupent des threads en blocks.
- Figure I.9. Unité d’exécution de contrôle des threads.
- Figure I.10. Architecture d’un exemple de système distribué.
- Figure I.11. Architecture d’une plateforme multi-agents selon FIPA.
- Figure I.12. Exemple de modèle de communication synchrone.
- Figure I.13. Exemple de modèle de communication asynchrone.
- Figure I.14. Exemple de modèle de communication synchrone avec service de
nommage.
- Figure II.1. Exemple de maille reconfigurable 3D de taille 3 x 3 x 3.
- Figure II.2. Composants principaux d’un PE Virtuel.
- Figure II.3. Contenu du registre de flags du PE Virtuel.
- Figure II.4. Diagramme UML de classes représentant les composants principaux de la
machine virtuelle.
- Figure II.5. Architecture de la machine virtuelle parallèle reconfigurable.
- Figure II.6. Contenus des registres des 9 PEs après chargement de l’image.
- Figure II.7. Contenus des registres des 9 PEs après échange avec les voisins.
- Figure II.8. Résultat du programme de détection de contour en utilisant la version
parallèle de l’opérateur Sobel.
- Figure III.2.1. Résultats de segmentation.
- Figure III.2.2. Changements dynamiques des différents paramètres de classification
partant des centres (c1, c2, c3) = (1, 2, 3). a) Centres de classes, b) Cardinal de chaque classe, c) Valeur absolue de l’erreur sur la fonction coût.
- Figure III.2.3. Changements dynamiques des différents paramètres de classification
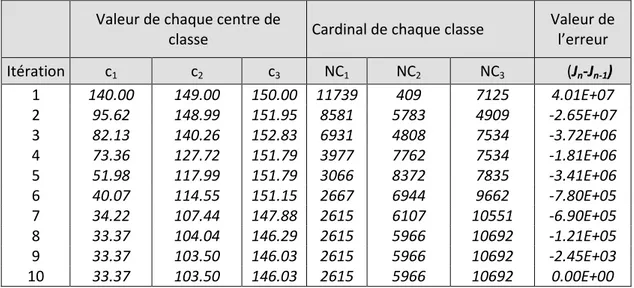
partant des centres (c1, c2, c3) = (1, 30, 255). a) Centres de classes, b) Cardinal de chaque classe, c) Valeur de l’erreur sur la fonction coût.
- Figure III.2. 4. Variations dynamiques des différents paramètres de classification
partant des centres (c1, c2, c3) = (140, 149, 150). a) Centres de classes, b) Cardinal de chaque classe, c) Valeur de l’erreur sur la fonction coût.
- Figure III.3.1. Segmentation PFCM de l’image IRM cérébrale.
- Figure III.3.4. Cas 1: Evolution dynamique des centres de classes en commençant par
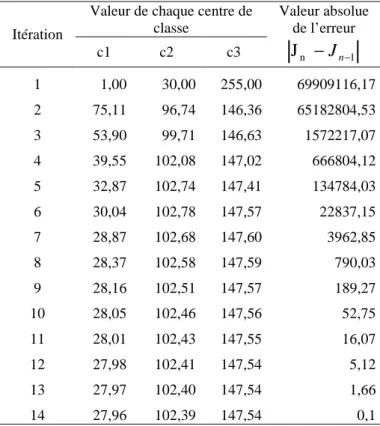
(c1,c2, c3) = (1, 30, 255).
- Figure III.3.5. Cas 2: Evolution dynamique des centres de classes en commençant par
(c1,c2, c3) = (1, 2, 3) .
- Figure III.3.6. Cas 3: Evolution dynamique des centres de classes en commençant par
(c1, c2, c3) = (140,149, 150).
- Figure III.3.7. Cas 4: Evolution dynamique des centres de classes en commençant par
(c1, c2, c3) = (23, 102,150).
- Figure III.3.8. Evolution dynamique des centres de classes pour les différents cas
d’initialisation pour les deux algorithmes PFCM and PCM. - Figure IV.1. Système distribué à 4 noeuds et 24 VPUs distribués.
- Figure IV.2. Exemple de machine parallèle virtuelle de topologie « Mesh 2D ».
- Figure IV.4. Composants principaux d’un VPU.
- Figure IV.5. Diagramme UML de classes représentant la structure logique d’un VPU.
- Figure IV.6. Structure de l’agent Mémoire Partagée Virtuelle.
- Figure IV.7. Diagramme de classes de notre machine virtuelle parallèle.
- Figure IV.8. Résultat de l’algorithme parallèle distribué de segmentation.
- Figure IV.9. Durée de classification dans chaque nœud pour deux itérations
successives.
- Figure V.1. Structure d’un exemple d’application parallèle.
- Figure V.2. Diagramme de séquence de la détermination des indices de performance
de référence.
- Figure V.3. Durées d’exécution dans chaque noeud.
- Figure V.4. Distributions de charges obtenues en utilisant la tâche de référence T0 et les métadonnées de la tâche T.
- Figure VI.5. Durée de calcul, Latence de communication et la durée totale
d’exécution de la tâche T0.
- Figure V.6. Durée de calcul, Latence de communication et la durée totale d’exécution
- Figure V.7. Différence entre les distributions de charges pour les itérations
successives t et t-1.
- Figure V.8. Comparaison entre les durées d’exécution avant et après le rééquilibrage
de charges.
- Figure V.9. Durées d’exécution des deux systèmes : équilibré et non équilibré en
fonction du nombre de nœuds.
- Figure V.10. Gain de temps entre les deux systèmes équilibré et non équilibré.
- Figure VI.1. Modèle de distribution de tâches.
- Figure VI.2. Modèle de distribution de tâches sans aspect d’équilibrage de charge.
- Figure VI.3. Modèle de distribution de tâches avec l’aspect d’équilibrage de charges.
- Figure VI.4. Indice de performance de chaque nœud.
- Figure VI.5. La charge attribuée à chaque nœud.
- Figure VI.6. Durée d’exécution dans chaque nœud pour la tâche de référence T0. - Figure VI.7. Durée d’exécution dans chaque nœud pour la tâche Ti.
L
ISTE DES TABLEAUX- Table I.1. Classification des architectures parallèles.
- Table III.2.1. Les différents registres utilisés par un PE dans l’algorithme parallèle
PCM.
- Table III.2.2. Complexités de chacune des étapes d’algorithme parallèle proposé.
- Table III.2.3. Résultats de comparaison des complexités pour la classification
parallèle.
- Table III.2.4. Etats de la classification partant des centres de classes (c1, c2, c3) =
(1,2, 3).
- Table III.2.5. Différents états de l’algorithme de classification partant des centres
(c1,c2, c3) = (1, 30, 255).
- Table III.2.6. Différents états de l’algorithme de classification partant des centres
(c1,c2, c3) = ((140, 149, 150).
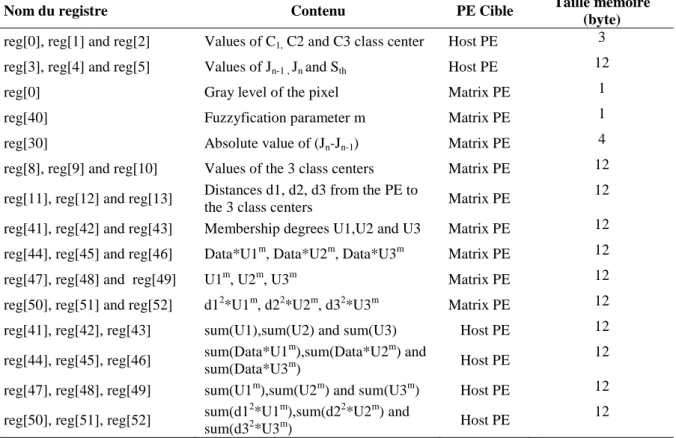
- Table III.3.1. Registres requis par la RMC Durant l’exécution du programme
parallèle PFCM.
- Table III.3.2. Différents états de l’algorithme de classification floue parallèle avec des
les valeurs initiales des centres de classes (c1, c2, c3) = (1, 30, 255).
- Table III.3.3. Différents états de l’algorithme de classification floue parallèle avec des
les valeurs initiales des centres de classes (c1, c2, c3) = (1, 2, 3).
- Table III.3.4. Différents états de l’algorithme de classification floue parallèle avec des
les valeurs initiales des centres de classes (c1, c2, c3) = (140, 149, 150).
- Table III.3.5. Différents états de l’algorithme de classification floue parallèle avec des
les valeurs initiales des centres de classes (c1, c2, c3) = (23, 102, 150).
- Table III.3.5. Différents états de l’algorithme de classification floue parallèle avec des
les valeurs initiales des centres de classes (c1, c2, c3) = (23, 102, 150).
- Table III.3.6. Les complexités de chaque étape de l’algorithme parallèle proposé:
- Table III.3.7. Comparaison des complexités des algorithmes parallèles c-means et
fuzzy-c-means.
- Table V.1. Données utilisées dans le test de diagnostique de référence.
- Table V.2. Résultats de test de diagnostique de référence.
- Table V.3. Métadonnées de la tâche T.
- Table V.4. Résultats d’exécution de la tâche T dans le Système Distribué.
- Table V.6. Migrations requises pour le rééquilibrage de charges.
- Figure V.7. Différence entre les distributions de charges pour les itérations
successives t et t-1.
- Table VI.1. Résultats du test de diagnostique de référence.
- Table VI.2. Résultats théoriques et expérimentaux obtenus lors de l’exécution de la
I
NTRODUCTION GENERALEDans le domaine du calcul de hautes performances, les applications à calcul intensif et à forte masses de données exigent d’énormes puissances de calcul et de stockage de données. L’évolution technologique pour l’amélioration des fréquences de microprocesseurs a marqué le pas depuis quelques années pour des raisons de limites technologiques. La multiplication des processeurs dans une architecture est donc perçue comme la solution pour améliorer les performances des applications. Par conséquent le calcul parallèle et distribué s’impose donc plus que jamais. De nouvelles architectures massivement parallèles ont vu le jour et sont actuellement très exploitées. C’est le cas des architectures GPU [1] qui sont exploitées pour accélérer aussi bien les applications graphiques que d’autres applications à calcul parallèle relatives des domaines scientifiques diverses. Toutefois, les performances de ces architectures restent limitées. Il est donc important d’associer les performances de plusieurs unités de traitement dans des systèmes distribués. De temps plus que les technologies réseaux et télécommunications ne cessent de s’améliorer pour réduire de plus en plus la latence de communication entre les machines. Le développement des systèmes mobiles géo localisés comme les smart phones et les systèmes embarqués miniaturisés tels que Raspberry [2] et Ardouino [3] a ouvert une nouvelle aire qui permet d’interconnecter les objets de notre univers aux applications scientifiques. Le Web 3.0 est entrain de se concrétiser et l’internet des objets « Internet Of Things (IOT)» est devenu une réalité que les systèmes de calcul de hautes performances doivent prendre en considération. En effet les objets de notre environnement peuvent être équipés d’unités de traitement capable d’effectuer des traitements, prendre des décisions tout en étant connectés en permanence à internet et permettant ainsi de doter les applications de fonctionnalités qui permettent d’exploiter l’intelligence massivement collective.
Historiquement, l’amélioration des performances des applications informatiques a été et reste toujours un défit majeur pour les entreprises. En effet Les applications traditionnelles à calcul intensif comme les prévisions météo, les prévisions financières, ou la simulation scientifique des problèmes mécaniques, aérodynamiques, électriques, biologie moléculaires ainsi que les applications à forte masse de données comme le traitement d’image, le multimédia et les jeux vidéo, ont besoin de plus de puissance de traitement et de disponibilité des ressources de stockage et de calcul. Récemment, les outils d’analyse, les méthodes de calcul et leurs modèles physiques de calcul, ont connu une évolution importante. Ce progrès a orienté les
scientifiques vers de nouvelles stratégies de calcul basées sur le parallélisme. Vue le grand volume de données à traiter et l’intensité des calculs nécessaires pour résoudre un problème donnée, l’idée de base étant de subdiviser les données et les taches de façon à ce qu’on l’on puisse, facilement, exécuter leurs algorithmes correspondants d’une manière concurrente dans des unités physiques de calcul différentes. Naturellement, l’utilisation de l’approche parallèle, implique une grande quantité de données à échanger entre les différentes unités de calcul. Cela engendre de nouveaux problèmes d’échange de données et de communications. Pour optimiser ces communications, il est important d’examiner comment ces données en question sont organisées. Actuellement, nous distinguons plusieurs types d’architectures. Commençant par le modèle d’ordinateur à processeur unique, allant jusqu’aux architectures massivement parallèles à grain fin ayant une grande quantité de processeurs élémentaires interconnectés selon différentes topologies. En effet, l'analyse de l'amélioration des performances en termes de puissance de traitement doit prendre en compte aussi bien la vitesse des unités de calcul et le problème de gestion de l'adressage des données à traiter. Par rapport à ce dernier problème, il semble que le modèle classique de VON NEUMANN n’est pas capable de répondre à toutes les contraintes citées. La nécessité de nouvelles architectures et l'amélioration de l'efficacité des processeurs a été excitée et encouragée par le développement de la technologie VLSI. En conséquence, nous avons vu la naissance de nouvelles technologies des processeurs comme Reduced Instruction Set Computer (RISC), Transputer, Digital Signal Processor (DSP), Cellular Automata etc. Les architectures massivement parallèles à grain fin qui ont été largement étudiées dans la littérature et pour laquelle plusieurs algorithmes parallèles pour le calcul scientifique ont été mis au point. Du point de vue théorique, chaque modèle de calcul a ses propres motivations. Du point de vue pratique, certains modèles ont été technologiquement réalisés et ont été exploités réellement comme architectures physique de calcul parallèle, mais d’autres modèles sont restés dans leurs états théoriques et par conséquent n’ont pas pu être réalisés pour cause de leurs complexités technologiques et leurs prix de fabrication trop élevé. Le modèle d’architecture parallèle ciblé par nos études a connu, historiquement, d’énormes progrès technologiques. Au début, il a été présenté comme une simple grille d’automates cellulaires. Après quelques améliorations technologiques, l’automate cellulaire devient un processeur élémentaire à grain fin et la grille résultat devient « The Mesh Connected Computer » MCC [4]. En utilisant quelques bus de communication additionnels, le MCC devient une Maille avec des « Broadcast » multiples [5] et tore polymorphique [6] pour devenir, par la suite, « The Reconfigurable Mesh Computer » (RMC) qui intègre un réseau de configuration pour chaque processeur élémentaire [7,8].
Du point de vue algorithmique, plusieurs auteurs ont développé de nouveau algorithmes parallèles pour le traitement de données et pour le calcul scientifique. Ces algorithmes sont conçus pour être implémentés dans des architectures parallèles mentionnées précédemment dont le but de réduire leurs complexités en termes de temps d’exécution.
Les constructeurs ont beaucoup innové dans la création des machines parallèles en exploitant ces différents modèles d’architectures et en cherchant toujours à créer l’ordinateur le plus rapide du monde. Mais l’expérience a montré que ces performances sont vite dépassées par les besoins gourmands incessants des applications en termes de traitement et de masses de données manipulées. Les théoriciens ont aussi beaucoup innovés dans l’imagination de nouvelles machines parallèles avec des topologies bien adaptées aux types de problèmes spécifiques. Ceci a donné naissance à de nouveaux algorithmes de calcul théoriques très performants destinés à être exécuté dans de telles architectures. Cependant la technologie ne peut pas créer tout ce que l’on peut imaginer. Vue l’indisponibilité ou coût élevé de ce genre de machines parallèles, la création des émulateurs pour ces architectures représente une solution alternative pour tester et valider de tels algorithmes parallèles sur des machines séquentielles quelconques. Des solutions basées sur l’émulation ont été proposées dans la littérature pour élaborer des systèmes virtuels afin d’exécuter ces algorithmes dans n’importe quel type d’ordinateur. Ces systèmes d’émulation peuvent être spécifiques comme dans [11,12] ou à comportement général comme dans le cas de [9,10].
Dans ce sens, nous avons eu l’occasion de développer un émulateur de machines massivement parallèles. Cet outil permet au programmeur l’implémentation et le test de ces algorithmes parallèles, même s’il ne dispose pas de réelles machines parallèles qui supportent ces algorithmes. Dans ce contexte, nous présenterons, dans cette thèse, un outil virtuel qui permet d’émuler une MCR dans lequel nous pourrons facilement implémenter des algorithmes parallèles de type SIMD. Il s’agit d’une plateforme MCR virtuelle de taille (n x m) processeurs élémentaires (PE) dans laquelle n et m représentent respectivement le nombre de lignes et de colonnes de la matrice. Dans le cas où n=m, nous parlerons d’une matrice carré de n2 PE’s. Cet émulateur permet aux scientifiques de dépasser le problème de disponibilités de RMC réelles. Avec cet émulateur, nous offrons un modèle de RMC virtuel étendu qui traduit les fonctionnalités physiques d’une vraie machine massivement parallèle. Ce modèle peut être facilement étendu pour intégrer de nouvelles fonctionnalités requises par la multiplicité de techniques algorithmiques élaborées. Toutefois, le fait d’émuler une machine massivement parallèle au sein d’une machine monoprocesseur, ne présente pas d’effets significatifs en
termes de performances au moment de l’exécution. Il est donc nécessaire de chercher un autre moyen qui permet d’exécuter ces applications émulées dans un environnement qui met en évidence ces performances. La virtualisation des architectures parallèles en utilisant des systèmes distribués, est une solution intéressante pour palier aux limites matérielles. En effet, elle permet d’associer les performances de plusieurs unités de traitements hétérogènes en vue de créer un environnement d’exécution plus performant. Les architectures parallèles et distribuées sont donc des concepts qui s’imposent dans la résolution des problèmes de calcul de hautes performances. Elles offrent aux applications le gain de performances, de rentabilité grâce à sa flexibilité et son extensibilité. Elles se présentent également comme étant une solution adéquate aux problèmes de traitements « temps réel » et de tolérances aux panes. Les technologies des microprocesseurs, de stockage de données ainsi les technologies réseaux et télécommunications ne cessent d’évoluer. Ceci permet d’un coté d’avoir des machines de calcul de plus en plus rapides avec des capacités de stockage de plus en plus grandes et d’un autre coté la possibilité de connecter ces machines dans des réseaux performants de très hauts débits. Ce qui rend ainsi les systèmes distribués, physiquement, plus performants. Ainsi, les grilles de calcul se sont apparues comme étant une solution physique permettant d’associer les unités de traitement et de stockage de plusieurs ordinateurs reliés par un réseau haut débit en vue de paralléliser et distribuer les tâches et les données d’un programme parallèle. En 1998, Ian Foster & Karl Kesselman ont posé le paradigme de la grille informatique dans leur ouvrage: « The Grid: Blueprint for a New Computing Infrastructure » [13]. L'accès aux services informatiques devrait être comparable en coût et facilité au branchement d'appareils sur le réseau électrique. Cet accès devrait être aisé et transparent quels que soient la puissance nécessaire, la complexité des équipements matériels et les logiciels mis en œuvre par les fournisseurs des services. Il peut être intéressant de chercher à exécuter une application parallèle sur une grille dans le cas où les ressources locales, cluster de laboratoire et centre de calcul ne suffisent plus. Toutefois des problèmes plus aisément solubles sur des machines parallèles resurgissent, comme l’équilibrage de charge et la tolérance aux pannes. C’est pourquoi, lorsqu’on exécute un code parallèle sur une grille de calcul, les performances sont très éloignées de ce que l’on pourrait obtenir sur une machine massivement parallèle, en raison de la latence des réseaux et de l’hétérogénéité des unités de traitement utilisées. La mise en œuvre une grille de calcul, nécessite un outil « Middleware » qui permet la synchronisation et la distribution du flux de données et du code programme à exécuter à travers les différents nœuds de la grille. La qualité et les performances d’une grille de calcul ne dépendent pas seulement des performances des machines qui la constituent, mais surtout
du middleware utilisé pour la gestion des flux de données et d’instructions, la synchronisation des tâches parallèles et séquentielles de l’application, la gestion des problèmes d’équilibrage de charge et de tolérances aux panes ainsi que les outils de diagnostique, d’audit et de surveillance des différents nœuds de la grille.
Les travaux de recherches s’intensifient pour développer de nouveaux « middlewares » très performants et dotés de nouvelles fonctionnalités innovantes en vue d’améliorer les performances des machines virtuelles parallèles qui reposent sur les systèmes distribués. Quant à l’aspect équilibrage de charges, plusieurs algorithmes ont été conçus pour les systèmes distribués [15] [16], sachant que dans les systèmes distribués, l’évolution des tâches est vue comme étant un processus dynamique et imprévisible. Cela signifie que l’état de la charge dans chaque nœud ne peut être statique, d’où la nécessité d’un processus dynamique de distribution de charges. Dans ce sens, comme exemple, l’algorithme de diffusion [17] est basé sur la collection des informations sur les différents nœuds du système distribué. La politique de communication, utilisée dans la procédure de collection montre un impact négatif sur la vitesse de convergence de l’algorithme d’équilibrage de charges. Dans l’algorithme de diffusion [18, 19], les auteurs ont utilisé une méthode qui introduit la notion de collection des informations par domaine représentant un groupe de nœuds. Cette méthode tente d’équilibrer la charge dans chaque domaine. Elle agit naturellement par le fait que l’excédent de charge doit être transféré vers les nœuds moins chargés dans leurs domaines respectifs, pour réduire le coût de communication. Pour déplacer la charge des nœuds surchargés vers les nœuds moins chargés, les auteurs ont utilisé, dans [19,20], un agent mobile qui permet de migrer la charge des nœuds surchargés vers ceux qui le sont moins, tout en considérant que tous les nœuds du système distribué sont homogènes.
Les travaux de recherche qui ont été mené dans le cadre de cette thèse, représentent une contribution à une réponse des théoriciens qui démontrent que pour chaque type de problème, il existe un algorithme et une architecture parallèle optimale et idéale pour sa résolution. Pour se faire, nous nous somme parti d’une idée principale se basant sur l’inversion de la vision et des pratiques courantes d’un programmeur à savoir : Au lieu d’adapter les algorithmes aux architectures physiques existantes, nous cherchons à adapter l’architecture à l’algorithme optimal. La création de machines virtuelles parallèles est bien la solution qui permet de concrétiser cette philosophie. Dans ce cadre, nous avons conçu, développé et mis-en en œuvre un nouveau modèle de machine virtuelle massivement parallèle (MVMP) basée sur des agents
mobiles, destinée au calcul de hautes performances. Cette machine permet d’exécuter des applications massivement parallèles en associant les performances des ressources locales et distantes à travers des réseaux locaux, VPN ou Internet sous forme d’une grille de calcul qui matérialise une architecture massivement parallèle. Chaque ressource de cette machine, possède ses propres unités de traitements et de stockage et met à la disposition toutes ses performances pour participer à l’exécution d’autres applications lancées à partir d’autres machines de la grille. Nous avons ainsi développé pour cette machine un middleware doté d’un système d’équilibrage de charge qui s’appuie sur un nouveau concept de virtualisation d’un CPU par un VPU (Virtual Processing Unit). Chaque VPU est représenté par un agent mobile qui est capable de migrer d’un nœud surchargé du système distribué vers un autre moins chargé pour favoriser l’équilibrage de charge. Avec cette plateforme, chaque développeur a la possibilité de créer sa propre architecture parallèle en définissant sa taille (nombre de VPUs) et sa topologie pour chaque type de problème à résoudre. Pour répondre à tous ces aspects, le contenu de ce mémoire sera organisé comme suit :
o La première partie est consacrée à une présentation de l’état de l’art des systèmes parallèles et distribuées. Dans cette partie, nous présenterons les différentes architectures parallèles utilisées dans le domaine du calcul parallèle de haute performance. Un aperçu sur les systèmes distribués sera également présenté en mettant en évidence, de manière particulière, le rôle des middlewares dans le domaine du calcul distribué.
o La deuxième partie est réservée à la description du modèle d’émulateur de machines massivement parallèles, conçu et développé. Dans cette partie, nous présenterons l’architecture des composants logiciels conçue et développé pour cet émulateur ainsi que la structure du langage de programmation parallèle développé pour cet émulateur. o Dans la troisième partie, nous présenterons quelques applications massivement
parallèles que nous avons implémentées en utilisant cet émulateur. Nous nous intéresserons particulièrement à la parallélisation des algorithmes de classification c-mean et Fuzzy c-c-mean pour la segmentation des images IRM cérébrales.
o Dans la quatrième partie de ce rapport nous décrivons le modèle de machine virtuelle massivement parallèle basé sur des agents mobiles et basé sur le principe de virtualisation d’une unité de calcul par un agent mobile VPU. Dans cette partie nous présenterons tout d’abord l’architecture des différents composants du modèle proposé.
Ensuite, pour valider la consistance du modèle, nous présenterons un exemple d’application parallèle et distribuée, implémenté dans cette machine virtuelle parallèle. o Le cinquième chapitre de cette thèse sera consacré à la présentation d’une nouvelle approche d’équilibrage de charges pour les systèmes distribués. Elle se base sur le principe de migration dynamique des agents VPUs en vue de maintenir le système distribué dans un état d’équilibrage de charges. Pour valider ce système d’équilibrage de charge un exemple d’application sera présenté.
o Le sixième chapitre de ce travail de recherche sera consacré à la présentation d’un autre système d’équilibrage de charges basée sur l’approche orientée aspect pour les systèmes distribués multi agents. Nous montrerons comment la préoccupation du système d’équilibrage de charges peut être séparée, sous forme d’un aspect, du reste du middleware de distribution de tâches. Dans cette partie un exemple d’application sera également présenté pour montrer les performances de ce modèle.
o La dernière partie présente une conclusion générale et les perspectives de ce travail de recherche.
C
HAPITRE
1
S
YSTEMES
P
ARALLELES ET
D
ISTRIBUES
I.1.INTRODUCTION
Les systèmes parallèles et distribués sont devenus, depuis plusieurs années, incontournables dans le domaine du calcul de hautes performances. Dans ce chapitre, dédié aux généralités sur les systèmes parallèles et distribués, nous présenterons les concepts nécessaires, relatifs au domaine du calcul parallèle et distribué et aux infrastructures mises en jeu. La première partie de ce chapitre sera consacrée à la présentation des architectures parallèles. Après avoir présenté la classification des architectures parallèles, nous aborderons les concepts fondamentaux liés au parallélisme de données et de traitements. Ensuite nous présenterons quelques détails sur une architecture massivement parallèle à savoir la Maille Connexe Reconfigurable (RMC) et l’architecture similaire basée sur les unités de traitement graphique (Gneneral Purpose Graphical Processing Unit : GPGPU). Dans la deuxième partie de ce chapitre, nous présenterons les concepts fondamentaux et la problématique des systèmes distribués ainsi que les middlewares utilisés dans le domaine du calcul distribués.
I.2.ARCHITECTURES PARALLELES
I.2.1. Classification des architectures parallèles
Les architectures parallèles ont connu un essor considérable ces dernières décennies, elles sont très variées du point de vue topologique et apparaissent sous formes de réseaux à savoir : linéaires, bi-dimensionels, pyramidales, cubiques, hyper-cubiques etc. Cette multitude de structures requiert une classification adéquate du point de vue taille, autonomie d'adressage et de connexion, type de données utilisées etc. Tout cela pour faciliter le choix de la machine dans laquelle l'algorithme doit être implanté.
De très nombreuses propositions de classification sont décrites dans la littérature. La diversité des solutions architecturales rend difficile l'établissement d'une taxonomie générale.
La classification la plus connue est celle de Flynn, [21]. Elle est fondée sur la multiplicité des flots d'instructions et de données. Le processus fondamental est l'exécution d'une suite d'instructions sur un ensemble de données. L'organisation des systèmes est caractérisée par la diversité des réalisations matérielles assurant la distribution du flot de données et d'instructions. Flynn développe quatre types d'organisation pour une machine de donnée. On distingue alors les architectures suivantes :
• S.I.S.D. : Single Instruction Single Data :
Ce type correspond au mode de fonctionnement des architectures séquentielles conventionnelles dans lesquelles un module du microprocesseur est actif à un instant donné.
Figure I.1. Architecture SISD Données
Unité de calcul Processeur
Instruction
• S.I.M.D. : Single Instruction Multiple Data :
Le module de traitement est dupliqué, et la mémoire de données est partagée en blocs disjoints, chaque bloc étant associé à un module de traitement. Tous les modules de traitement reçoivent la même instruction.
Figure I.2. Architecture SIMD
• M.I.S.D. : Multiple Instruction Single Data :
Cette classe fait apparaître une duplication des unités de séquencement et des unités de traitement associées. Celles-ci exécutent simultanément une séquence d'instructions sur un ensemble de données.
Figure I.3. Architecture MISD Données Unité de calcul Processeur Instruction Résultat Données Unité de calcul Processeur Résultat Données Unité de calcul Processeur Instruction Résultat Unité de calcul Processeur Résultat Instruction
• M.I.M.D. : Multiple Instruction Multiple Data :
La plus part des systèmes récents peuvent entrer dans cette catégorie. On constate que cette architecture ressemble à une réplique d'ordre n de la structure S.I.S.D. En fait, une analyse plus fine montre qu'il existe une interaction entre les n systèmes au niveau de la mémoire partagée. Ce couplage peut être faible, auquel cas la structure est équivalente à n structures SISD indépendantes, ou bien elle peut être forte et dans ce cas on parle de structure MIMD intrinsèque.
Figure I.4. Architecture MISD
On peut préciser que cette catégorie MIMD peut être découpée en deux sous-catégories :
• SPMD (Single Program Multiple Data) : Consiste à exécuter un seul programme sur plusieurs données à la fois.
• MPMD (Multiple Program Multiple Data) : Consiste à exécuter des programmes en parallèle sur des données différentes.
Si l'on observe de près l'éventail des architectures proposées au cours des dernières années, on peut faire quelques constatations :
la classification de Flynn n'intègre pas certaines structures comme le flot de données, Il n'existe pas de composant performant de type MISD sur le marché,
Données Unité de calcul Processeur Instruction Résultat Unité de calcul Processeur Résultat Instruction Données
La plus part des architectures rentrent dans la catégorie MIMD.
Fountain [22] a présenté une nouvelle approche de répartition des architectures parallèles, en se basant sur le principe de l'autonomie de processeur, la topologie du réseau d'interconnexion et la largeur du mot de donnée.
Maresca et al. [23] ont raffiné le modèle en introduisant une subdivision supplémentaire au niveau de l'autonomie, et en créant trois sous classes : l'autonomie d'opération, de connexion et d'adressage. Le tableau ci dessous résume les résultats de ce classement. Nous observons cependant, que cette notion d'autonomie n'affecte qu'une partie des structures existantes (la structure SIMD). Il existe d'autres classifications dans la littérature mais jusqu'à ce jour aucune ne s'est imposée.
Le tableau I.1 présente une synthèse de la classification plus élargie des architectures parallèles selon la taxonomie de FLYN.
Dans cette classification, la machine qui sera explorée, dans ce travail, correspond à un model SIMD ayant une autonomie d’adressage dans laquelle la matrice de ses processeurs qui sont disposés en grille. Ces processeurs utilisent des données en format entier ou réel. C’est le cas de la machine nommé « ILLIAC IV ». Notre machine peut également avoir une autonomie de connexion où les processeurs sont connectés en grille torique et pouvant communiquer de manière série ou parallèle c’est le cas de la machine appelée « YUPPIE ». Notre système va alors réaliser un émulateur de ces deux types de machines précitées.
Taxonomie de FLYN Type d'autonomie Topologie du Réseau Format des Données Exemples de machines parallèles existantes MIMD
Multi-étages Flottant PASM
IUA
Hupercube Flottant NCUBE
iPSC
Bus Mixte DATACUBE
Linéaire Flottant WARP
Anneau Entier ZMOB
Grille Flottant TRANSPUTER
MISD Linéaire Bit-série CYTOCOMPUTER
Entier PIPE SIMD Non autonome Grille Bit-série CLIP4 MPP DAP AAP GRID
Arbre Entier NON VON
Cube 3-D Bit-série HUGHES WAFER STACK
Autonomie d'adressage
Grille Entier ILLIAC IV
Linéaire Entier CLIP 7
Multi-étages Flottant GF11
PASM Autonomie de
connexion
n-cube Bit-série CONNECTION MACHINE Tore Bit-série YUPPIE
Autonomie d'opération
Pyramide Bit-série PAPIA
Linéaire Entier CLIP 7
Tableau I.1. Classification des architectures parallèles
I.2.2. Parallélisme de données et de traitements
I.2.2.1.Parallélisme des traitements:
Le premier concept de parallélisation, le plus évident, consiste simplement à exécuter des calculs indépendants en parallèle. Pour cela, il suffit de découper le programme en plusieurs sous-programmes indépendants à exécuter en parallèle. Ces sous-programmes indépendants s’appellent Threads, où chacun correspond à un morceau de programme, constitué d'une suite d'instructions à exécuter en série, et qui devra utiliser un processeur. Il suffit de faire exécuter chaque Thread sur un processeur séparé pour pouvoir paralléliser le programme. Les architectures permettant d’exécuter des threads en parallèle sont donc des architectures multiprocesseurs ou multi cœurs, ainsi que d’autres processeurs spéciaux. Avec ce genre de
parallélisme, le découpage d'un programme en threads reste un problème logiciel. Ce découpage est donc du ressort du compilateur ou du programmeur. Les langages de programmation disposent souvent de mécanismes permettant de découper les programmes en threads, exécutables en parallèle si le matériel le permet. Dans certains cas, le compilateur peut s'en charger tout seul, en utilisation des indications fournies par le programme lui-même.
I.2.2.2.Parallélisme de données :
Un autre concept de parallélisme est celui des applications qui consistent à exécuter un même programme sur des données différentes et indépendantes. Cela permet de traiter un grand volume de données à répartir sur les processeurs et à traiter en même temps. Tous les processeurs exécutent un seul et unique programme ou une suite d'instructions, mais chacun va travailler sur une donnée différente. Le parallélisme de données est aussi largement utilisé dans les cartes graphiques, qui sont des composants capable d’exécuter les mêmes instructions sur un grand nombre de données. A titre d’exemple, dans le cas du traitement parallèle d’images, chaque calcul sur un pixel est plus ou moins indépendant des transformations locales qu'on effectue sur ses voisins.
I.3.ARCHITECTURES MASSIVEMENT PARALLELES
Dans le domaine de traitement massivement parallèle de données, les techniques algorithmiques sont fortement liées aux architectures d'implantation. Généralement l'élaboration d'un algorithme s'accompagne par des propositions sur les modifications ou des améliorations matérielles au niveau des processeurs élémentaires de la machine. Une telle amélioration entraîne de sa part le développement des techniques algorithmiques. En effet un algorithme développé pour une architecture donnée, peut s'écrire d'une autre manière sur une même machine ayant subit des améliorations technologiques ; tout en offrant une complexité meilleure. C'est dans ce contexte que s'inscrit l'architecture parallèle utilisée comme support d'implantation des algorithmes à élaborer. Dans cette partie, nous présenterons deux exemples d’architectures massivement parallèles à savoir la Maille Connexe Reconfigurable (MCR) et l’architecture GPGPU
I.3.1.Maille Connexe Reconfigurable (MCR)
A l'origine elle était une maille connexe appelée « Mesh Connected Computer ». Moyennant l'introduction des réseaux de commutation dans chaque processeur, cette maille
est devenue reconfigurable, capable d'offrir de grandes performances par le biais d'un jeu d'instructions de reconfiguration, supporté par ses processeurs.
I.3.1.1. Structure générale
Une Maille Connexe Reconfigurable (MCR) de taille n x n, est une machine parallèle ayant n2 PE rangés sous forme d’une matrice carrée (figure I.5), c’est une structure "Simple Instruction Multiple Data computer (SIMD)", dans laquelle chaque PE(i, j) est localisé dans la ligne i et la colonne j. Il peut être caractérisé par son identificateur défini par ID = n.i + j.
Chaque PE de la maille est connecté à ses quatre voisins s’ils existent par des canaux de communication. Il possède un nombre fini de registres de longueur (log2 n) bits, dans lesquels il stocke des données entre lesquelles il peut effectuer des opérations arithmétiques et logiques. Tous les PE peuvent exécuter aussi des opérations de reconfiguration pour échanger des informations avec les PE de la maille.
Les réseaux reconfigurables qui se présentent sous forme de matrice de processeurs ont été considérablement approuvés ces dernières années. En effet de nombreux travaux ont été apparus dans la littérature du point de vue théorique et pratique vue la multitude des implémentations qui mettent en jeu leur aspect matériel [25, 27, 29]. Plus particulièrement les travaux dans [24, 26, 28, 30, 31] proposaient des nouveaux modèles de reconfiguration.
Ces réseaux de reconfiguration se basent sur un changement dynamique de la forme de la maille. Cette dernière est considérée alors comme une grille polymorphique de processeurs. Ces architectures sont munies d'un jeu d'instructions de reconfiguration de telle sorte qu'elles présentent plusieurs topologies en fonction du problème à résoudre. Elles se présentent typiquement sous forme d'un réseau multidimensionnelle de processeurs élémentaires connectés à un bus de communication ayant un nombre fixe de ports d'Entrée/Sortie. Lorsque ce bus est réduit à un seul bit on parle de machine "bit-model", alors que pour une maille de taille n x n ayant un bus de largeur log2 n bits, on parle de machine "Word-model". La figure I-5, montre une représentation schématique de ces deux modèles.
La reconfiguration est assurée localement en ajustant des commutateurs du bus au niveau de chaque PE. Le contrôle de ces commutateurs prévoit une autonomie de connexion, dans le sens que différents PE peuvent simultanément sélectionner différents commutateurs pour accomplir une configuration. Ceci est basé sur des décisions locales prises par chaque
PE. Il permet aussi d'effectuer des opérations de configuration inconditionnelles dans les quelles tous les PE exécutent des instructions qui activent les mêmes commutateurs.
Figure I.5. Les deux modèles d'une MCR de taille 8 x 8.
Des opérations arithmétiques non triviales sur des machines "bit-model". [26, 32, 29] ont été développées en utilisant des systèmes de codage spéciaux pour augmenter les performances de la machine à savoir la vitesse d'exécution et le contrôle de ces opérations.
I.3.1.2.Réseaux de commutation
Une maille reconfigurable est une matrice dans laquelle chaque PE possède un ensemble de commutateurs avec les quels il peut établir des liaisons entre ses différents PORTS.
Soient : P1, P2... Pk, les k ports d'un PE (dans la pratique k = 4, {N, S, E, W }) Soit : Pi(r) le bit de rang r du port Pi, avec 0 ≤ r ≤ w-1
w : étant la largeur du bus, c'est le nombre total de bit d'un port.
A l'aide d'un réseau de commutateur associé à chaque PE on peut mettre en évidence les opérations suivantes :
• Commutation directe
En commutation directe Les connexions locales des k ports d'un PE sont décrites par une matrice Booléenne symétrique C (k x k). On a :
Cij = 0 ailleurs.
Ce type de connexion préserve l'ordre des bits, c'est à dire : Si Cij = 1 alors Pi [r] est connecté à Pj [r]. 0 ≤≤≤≤ r ≤≤≤≤ w-1.
• Commutation décalée
D'une manière générale la commutation décalée des k ports d'un PE est décrite par une matrice S(k x k) telle que :
Sij = φφφφ si Pi et Pj sont non connectés
Sij = q 0 ≤ q ≤ w-1 si Pi [r] est connecté à Pj [(r + q) mod w]
Pour q = 0 on retrouve la commutation directe. Remarque :
Si Pi [r] est connecté à Pj [(r + q) mod w] alors Pj[r] est connecté à Pi[(r +w -q) mod w].
La figure I-6, donne des exemples de ces différentes commutations, avec les matrices associées. Ces matrices seront mises en œuvre chaque fois qu'il y a lieu de configurer la maille. Chaque PE réalisera une mise à jour de sa matrice conformément à la configuration imposée par tout algorithme de traitement de données.
• Permutation
Un autre modèle de commutation décalé a été introduit en [28,29]. Dans ce modèle on peut réaliser une commutation par valeur q puissance de 2.
Ce type de commutation a été utilisé pour résoudre les problèmes d'addition et de multiplication des matrices. Le modèle utilisé a un nombre de commutateurs de tailles variables. Cependant ces tailles doivent être définies dans une base de nombres premiers.
I.2.1.3. Opérations de base d'un PE
A. Opérations arithmétiques
Comme tout processeur, les PE de la MCR possèdent un jeu d'instructions relatif aux opérations arithmétiques et logiques. Les opérandes concernés peuvent être des données locales d'un PE ou des données se présentant sur ses canaux de communication lors des opérations inter-PE. Pour les PE du type "bit-model" le calcul s'effectue bit par bit, alors que pour les types "word-model", les calculs se font sur des mots de taille ( log2 n bits), où n est la
largeur du bus de communication du PE.
B. Opérations de configuration
a- Pont Simple (Simple Bridge, SB)
Un PE de la MCR est en état de SB s’il établit des liaisons entre deux de ses canaux de communication. Ce PE peut se connecter à chacun de ses bits de ses canaux, soit en mode émetteur, soit en mode récepteur, comme il peut s’isoler de certains de ses bits (i.e. ni émetteur, ni récepteur). Les différents cas de figures du SB sont réalisés par commutation directe et décrit par les formats suivants :
{{{{EW, S, N }}}}, {{{{E, W, SN }}}}, {{{{ES, W, N }}}},{{{{NW, S, E }}}}, {{{{NE, S, W }}}}et {{{{WS, E, N }}}}.
E, W, N et S désignent respectivement les Ports : Est, Ouest, Nord et Sud d'un PE.
b- Pont Double (Double bridge, DB) :
Un PE est en état de DB lorsqu'il réalise une configuration ayant deux bus indépendants. Les différentes configurations possibles sont :
c- Pont Croisé (Crossed Bridge, CB) :
Un PE se met en CB s’il connecte tous ses canaux de communication actifs en un seul ; chaque bit avec son correspondant. Cette opération est utilisée généralement lorsqu’on veut transmettre une information à un ensemble de PE en même temps.
Le CB est définit par la configuration : {{{{NESW }}}}
Ces différents ponts sont applicables pour les deux types de machines "bit-model" et "word-model". Leurs implantations nécessitent la mise en œuvre de la matrice de connexion C.
d- Opération d’émission directe (direct broadcasting)
L'opération de " direct broadcasting" consiste à transmettre une information de la part d’un PE vers un ensemble de PE et ce en même temps (i.e. en θ(1) itération). Les opérations nécessaires sont :
- Tous les PE se mettent en CB, et se couplent en mode récepteur sur leurs bridges sauf le PE qui va émettre l’information, il doit se coupler en mode émetteur.
- Le PE émetteur transmet l’information sur son bridge ; ainsi tous les PE récepteurs auront en même temps la même information sur leurs bus.
I.3.2.Architecture à base d’unités de traitement graphique GPU (Graphical Processing Unit)
Parallèlement au développement des multi-cœurs, on constate l’émergence des processeurs graphiques (GPU) dédiés au rendu d’images de synthèse. Conçus à l’origine comme des accélérateurs spécialisés, ils sont devenus des architectures parallèles à grain fin entièrement programmables. Leur rôle est complémentaire à celui des processeurs généralistes. Alors que les super-scalaires multi-cœurs sont optimisés pour minimiser la latence de traitement d’un faible nombre de tâches séquentielles, les GPU sont conçus pour maximiser le débit d’exécution d’applications présentant un parallélisme massif. Dans [33], l’auteur a présenté les enjeux de conception des architectures GPGPU (General Purpose GPU): unités de traitement spécialisées pour des exploitations de forte granularité. Le marché de masse que constitue le jeu vidéo a permis de concevoir et de produire en volume des GPU dont la puissance de calcul est nettement supérieure à celle des processeurs multi-cœurs [34]. Cette puissance disponible à faible coût a suscité l’intérêt de la communauté scientifique qui y a vu l’occasion d’exploiter le potentiel des GPU pour d’autres tâches que le rendu graphique. Ainsi, les GPU ont été proposés pour accélérer des applications de calcul scientifique de hautes performances, telles
que des simulations physiques, ou des applications multimédia de type traitement d’image et de vidéo [35]. Les constructeurs de GPU ont vu dans les travaux académiques une opportunité de s’ouvrir au marché du calcul scientifique, et ont commencé à intégrer des fonctionnalités matérielles non liées au rendu graphique dans leurs processeurs respectifs [36, 37].
De nombreux aspects des GPU actuels sont hérités des architectures SIMD [38]. On peut notamment retrouver des similarités dans la façon dont est conçue l’architecture, dans les langages et environnements de programmation utilisés, ainsi que dans les algorithmes parallèles suivis. En plus ces fonctionnalités classiques, les GPU ont aussi adopté des éléments issus du rendu graphique.
Les différents constructeurs de GPU ont des points de vue différents sur le niveau d’abstraction à considérer pour les architectures et les langages de programmation. Par exemple, certains mettent l’accent sur la simplicité et l’efficacité du matériel en déléguant les tâches d’ordonnancement au compilateur, tandis que d’autres fournissent des mécanismes matériels transparents pour masquer la complexité interne. De même, ces constructeurs proposent des environnements de programmation se plaçant à différents niveaux d’abstraction.
Le calcul par GPU consiste à utiliser des processeurs graphiques (GPU) en même temps que le CPU pour accélérer des applications professionnelles de science, d'ingénierie et d'entreprise. Lancé en 2007 par NVIDIA, le calcul par GPU s'est imposé comme un standard de l'industrie. Dans le monde entier, la plupart des centres de données à basse consommation y ont recours, aussi bien dans les laboratoires gouvernementaux et universitaires que dans les petites et moyennes entreprises. Le calcul par GPU permet de paralléliser les tâches et d'offrir un maximum de performances dans de nombreuses applications. Comme le montre la figure I.7, le système GPU accélère les portions de code les plus lourdes en ressources de calcul, le reste de l'application restant affecté au CPU. Les applications des utilisateurs s'exécutent ainsi bien plus rapidement. Pour comprendre les différences fondamentales entre un CPU et un dispositif GPU, il suffit de comparer leur manière de traiter chaque opération. Les CPU incluent un nombre restreint de cœurs optimisés pour le traitement en série, alors que les GPU intègrent des milliers de cœurs conçus pour traiter efficacement de nombreuses tâches simultanées.