Usability aspects of the inside-in approach for ancillary search tasks on the web
20
0
0
Texte intégral
Figure
![Fig. 1. Overview of alternative strategies for finding information; adapted from [23]](https://thumb-eu.123doks.com/thumbv2/123doknet/3236171.92711/4.892.217.691.414.541/fig-overview-alternative-strategies-finding-information-adapted.webp)
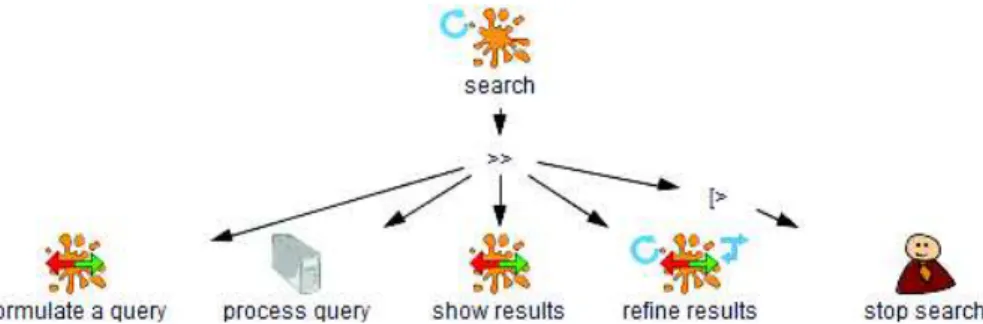
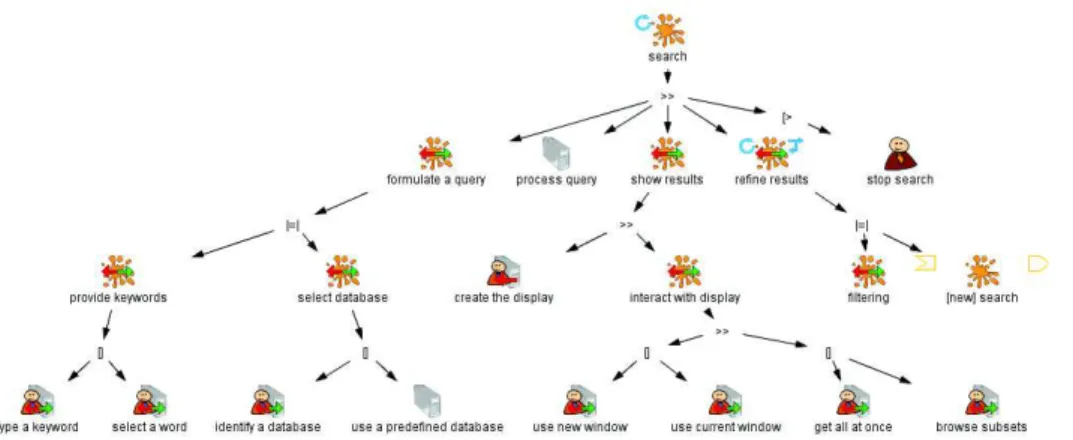
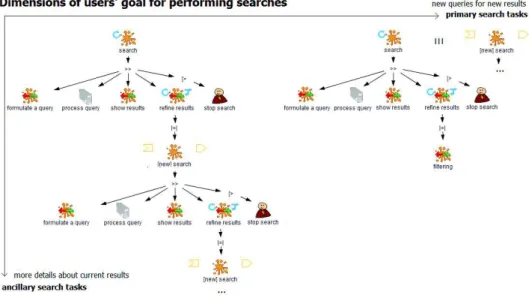
+6
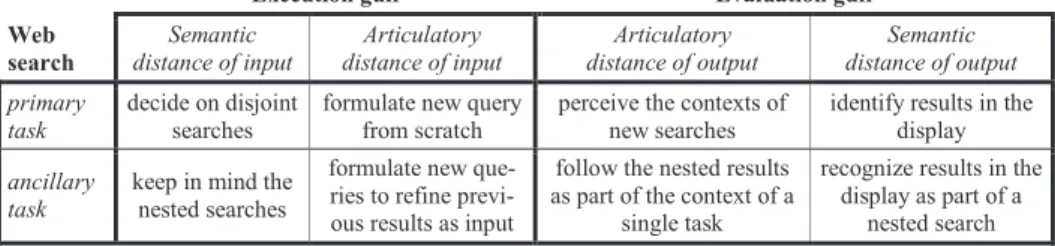
![Fig. 5. Execution and evaluation gulfs in search tasks, adapted from [15].](https://thumb-eu.123doks.com/thumbv2/123doknet/3236171.92711/8.892.268.627.223.600/fig-execution-evaluation-gulfs-search-tasks-adapted.webp)
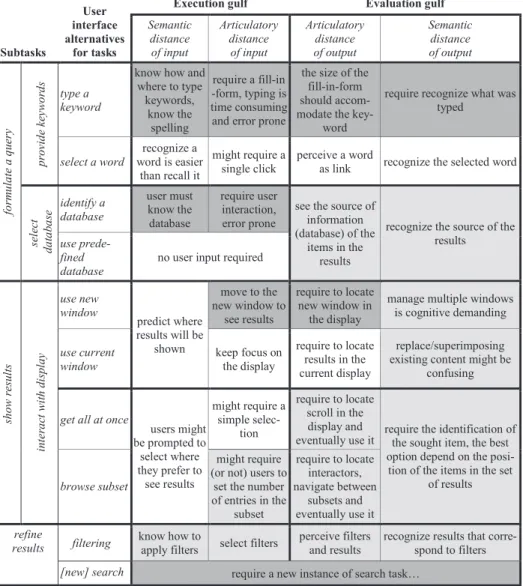
Documents relatifs