Apprentissage et fouille de données par les algorithmes bio-inspirés : application à la reconnaissance de caractères arabes manuscrits
Texte intégral
Figure
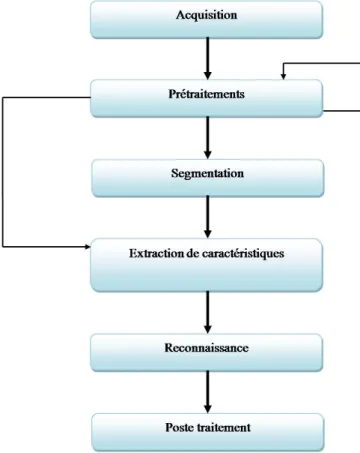
![Fig. 1.1 – Sch´ ema d’un processus de fouille de donn´ ees [1]](https://thumb-eu.123doks.com/thumbv2/123doknet/2945962.79697/16.892.129.772.319.692/fig-sch-ema-processus-fouille-donn-ees.webp)
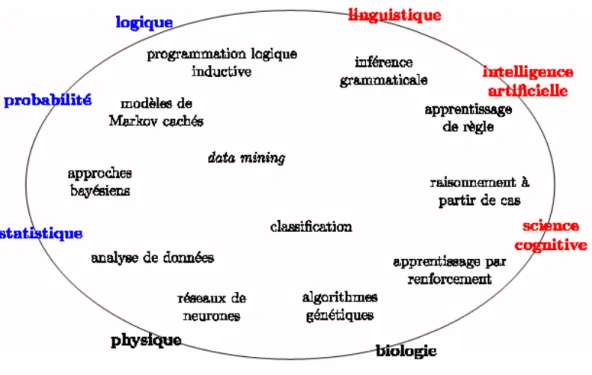
![Fig. 1.2 – M´ ethodes de fouilles de donn´ ees [1]](https://thumb-eu.123doks.com/thumbv2/123doknet/2945962.79697/17.892.132.771.462.898/fig-m-ethodes-de-fouilles-de-donn-ees.webp)

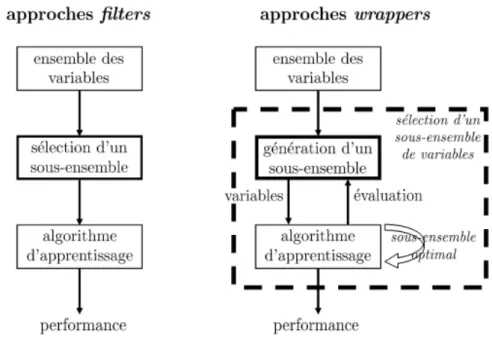
![Fig. 1.4 – Proc´ edure de recherche d’un sous-ensemble de variables [9]](https://thumb-eu.123doks.com/thumbv2/123doknet/2945962.79697/22.892.191.704.711.911/fig-proc-edure-recherche-variables.webp)
![Tab. 2.1 – L’alphabet arabe et les diff´ erentes formes [24]](https://thumb-eu.123doks.com/thumbv2/123doknet/2945962.79697/34.892.207.685.206.771/tab-l-alphabet-arabe-les-diff-erentes-formes.webp)
![Fig. 2.2 – Caract´ eristiques de l’´ ecriture arabe [33]](https://thumb-eu.123doks.com/thumbv2/123doknet/2945962.79697/35.892.187.701.268.511/fig-caract-eristiques-l-ecriture-arabe.webp)
![Tab. 2.2 – Liste des diacritiques [34]](https://thumb-eu.123doks.com/thumbv2/123doknet/2945962.79697/36.892.154.740.373.633/tab-liste-des-diacritiques.webp)
Documents relatifs
Dans le cas où les caractéristiques ne sont pas détectées à cause de la variabilité du manuscrit ou de leur absence dans certaines lettres arabes, deux
:ةيعرفلا تايضرفلا ةيضرفلا ىلولأا : ةيجمربلا يكمل ةي ةاقولا PMB فل ة بطملا وال لا ةيلكل ةي ماجلا ةبلكملا و ةاايراجللا واال لاو ةيدااادلصتا لا واال لا
Le but de cette étape est la partition de l’image d’un mot en une suite de segments (graphèmes) par l’identification des positions de points de segmentation. A cet effet, nous
Soit par la recherche du modèle discriminant dans le cas d’un modèle par classe. Cette suite est appelée la suite d’états de Viterbi. Pour résoudre ce
When the number of points to be covered is large, we show how the DRN algorithm can be used with an active-set strategy (where the active-set strategy is
The first proposals apply first- and second- order polynomial regression models as surrogates for the true limit state function, as applied in the example of cumulative
Cette technique de base peut être appliquée pour générer des données d’apprentissage suffisantes pour les modèles de classification qui nécessitent un nombre minimal
Si l'on considère les prix Pqt d'un même produit dont on peut avoir la disposition à di vers moments dans le temps on appelle facteur d'escompte propre fJ qt pour la date t le
