Domain-specific question answering system : an application to the construction sector
Texte intégral
Figure
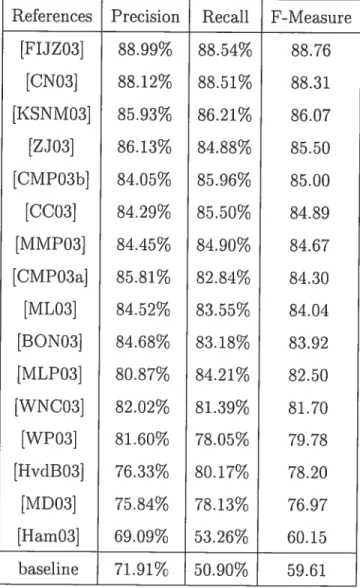
![Table 2.1: Maximum resuits reported in MUC-3 through MUC-7 by task [MUCO3].](https://thumb-eu.123doks.com/thumbv2/123doknet/7698636.245214/31.918.156.800.101.401/table-maximum-resuits-reported-muc-muc-task-muco.webp)

![Figure 2.4: Question, paragraph and processing in FALCON [HMMOO]](https://thumb-eu.123doks.com/thumbv2/123doknet/7698636.245214/49.918.190.774.107.497/figure-question-paragraph-processing-falcon-hmmoo.webp)
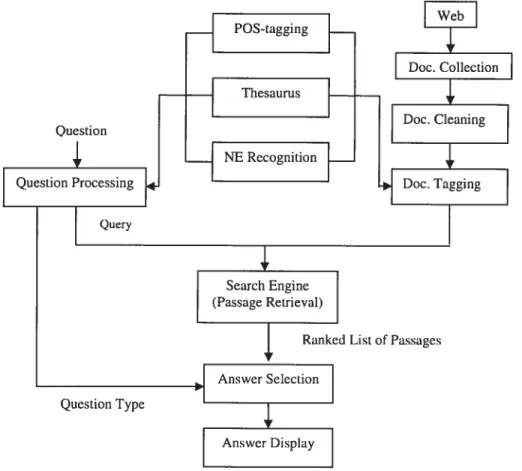

Documents relatifs
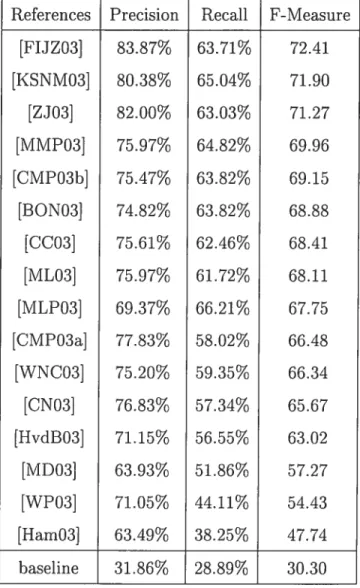
We expected NII1 or NII5 to have the best scores before the evaluation since we expected the Sentence Extractor to remove noise in the documents and contribute to accuracy of
This paper introduces an Xception-GRU model for Image- CLEF 2019 Medical Domain Visual Question Answering (VQA-Med) Task.. First, we enhance the images and remove extraneous words
In this section, we propose a method for a question answering system based on the construction of a temporal resource for the resolution of temporal inference
[4] classified the questions asked on Community Question Answering systems into 3 categories according to their user intent as, subjective, objective, and social.. [17]
The Query Formulation Module transforms the ques- tion into a query in 3 seconds, the Document Re- trieval Module and the Candidate Answer Extrac- tion Module together take 8 seconds
Question Answering Sys- tem for QA4MRE@CLEF 2012, Workshop on Ques- tion Answering For Machine Reading Evaluation (QA4MRE), CLEF 2012 Labs and Workshop Pinaki Bhaskar, Somnath
– Answer Production generates a set of candidate answers based on the question, typically by performing a Primary Search in the knowledge bases according to the question clues
I submitted results for all five batches of test questions for task 3b: (a) phase A, i.e., concept mapping and document and passage retrieval, and (b) phase B, i.e., exact and
