Pépite | Appariement de descripteurs évoluant dans le temps : application à la comparaison d'assurance
202
0
0
Texte intégral
Figure

+7

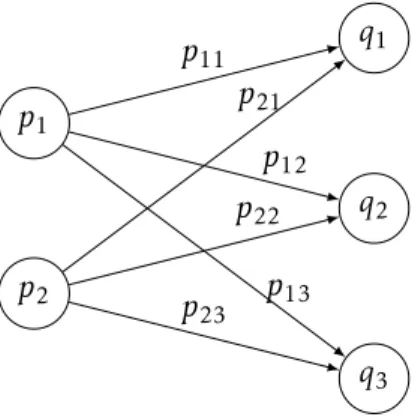


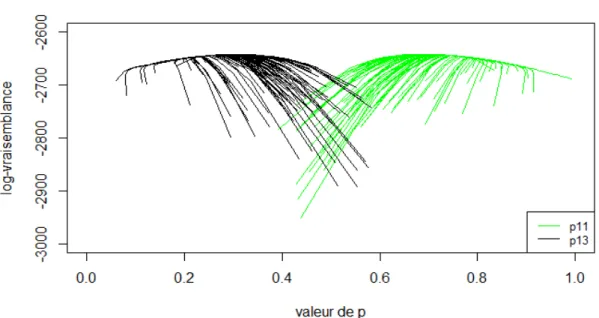
Outline
Problématique et objectif de la thèse
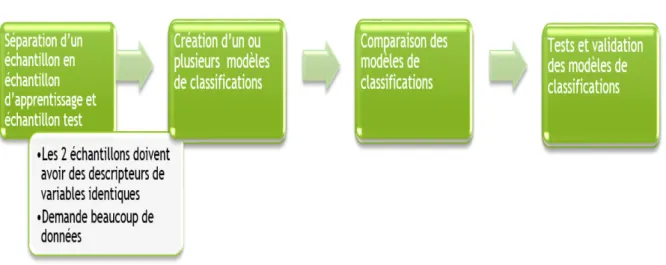
Classification supervisée
Classification évolutive
Rappel de la problématique
Proposition d’une méthodologie pour détecter les modèles non iden-
Méthode de sélection de modèles
Comparaison des critères BIC vs BIL
Méta-heuristiques à base de population de solutions
Algorithme génétique
Analyse de sensibilité des opérateurs
Documents relatifs
Nous croyons oiseux d'insister sur les accidents de péritonite aiguë ou sur ce que l'on a appelé le rhwnatisrrte des parois abdominales : dans ces deux
Cette revue me conduit à identifier cinq éléments clefs à développer dans un et les méthodes pour les caractériser dans le cas spécifique des scénarios d’usages du sol pour
17 La recherche se développera selon trois axes : le premier envisage de contextualiser le « théâtre gestuel » de la compagnie Dos à Deux dans son rapport au mime et à
