Prédisposition à ignorer la corrélation en situation
d'investissement : une étude expérimentale
Mémoire
Mélissa Rochette
Maîtrise en économique - avec mémoire
Maître ès arts (M.A.)
Prédisposition à ignorer la corrélation
en situation d’investissement :
une étude expérimentale
Mémoire
Mélissa Rochette
Sous la direction de :
Charles Bellemare, directeur de recherche
Sabine Kröger, codirectrice de recherche
Résumé
Ce mémoire étudie la Prédisposition à Ignorer la Corrélation (PIC) dans la prise de décision à investir. La PIC est un biais comportemental d’importance et a des effets néfastes sur les finances personnelles. Sous ce biais, l’investisseur simplifie son processus de décision en ignorant la corrélation entre les actifs de son portefeuille. L’objectif principal de ce projet est de développer les connaissances sur la PIC. Plus précisément, quatre objectifs spécifiques sont fixés : 1) évaluer l’existence de la PIC, 2) déterminer les sous-groupes de la population les plus à risque de la PIC, 3) développer une mesure simple de la PIC pour des questionnaires et 4) proposer des pistes de solution à ce biais.
Pour ce faire, nous réalisons une expérience en laboratoire auprès d’étudiants et de travailleurs. À plusieurs reprises, les répondants complètent un portefeuille financier en sélectionnant un de deux fonds proposés. La corrélation entre les fonds varie d’une fois à l’autre. Ces décisions expérimentales détectent le niveau de PIC du répondant. Par ailleurs, nous mesurons l’effet du format de présentation et du niveau d’information financière sur la présence du biais. Ensuite, le répondant remplit un questionnaire sur la diversification de portefeuille et sur ses informations socio-économiques.
D’après nos résultats, la PIC existe réellement et à différents niveaux dans la population des répondants. Nous identifions trois questions à choix multiples qui peuvent facilement mesurer la PIC. D’autre part, nous trouvons que certains groupes d’investisseurs sont plus à risque du biais de la PIC, soit les femmes et ceux n’ayant pas d’études en finance. Également, nous suggérons des pistes de solution qui peuvent améliorer les décisions financières des répondants. La surcharge d’information devrait être évitée et certaines informations devraient être mises en évidence.
Abstract
This thesis studies Correlation Neglect (CN) in investment decisions. CN is a significant behavioral bias that has negative effects on personal finances. Under this bias, the investor simplifies his decision-making process by ignoring correlation between his portfolio’s assets.
The main objective of this project is to develop an understanding of CN. We have fixed four specific objectives : 1) evaluate the existence of CN, 2) determine the subgroups of the population that are the most affected by CN, 3) develop a simple measure of CN that could be used in questionnaires, and 4) propose solutions to the CN bias.
To meet these objectives, we realize a laboratory experiment with students and workers. Repeatedly, respondents complete a financial portfolio by selecting one of two proposed funds. The correlation between the funds varies each time. These experimental decisions detect the respondent’s CN. During this experiment, we also measure the effect of the presentation format and the level of financial information on the presence of the bias. Then, the respondent completes a multiple choice questionnaire on portfolio diversification and on his socioeconomic status.
Our results suggest that CN does exist, and that there are different levels of CN within the population of respondents. We identify three multiple choice questions that can easily measure CN. These questions evaluate the respondent’s awareness of correlation when choosing a financial portfolio. Also, we find that different groups are more at risk of CN, mainly those who did not study finance and women. However, we find potential solutions that could improve the financial decisions of respondents. Information overload should be avoided, and some information should be highlighted.
Table des matières
Résumé ... ii
Abstract ... iii
Table des matières... iv
Liste des tableaux ... vi
Liste des figures ... vii
Liste des sigles ... viii
Remerciements ... ix
Introduction ... 1
Chapitre 1 Revue de littérature ... 3
1.1. La littératie financière ... 3
1.2. La Prédisposition à Ignorer la Corrélation (PIC) ... 3
1.3. La réduction du biais de la PIC ... 6
1.4. Le résumé... 7
Chapitre 2 Cadre théorique ... 9
2.1. La théorie moderne du portefeuille ... 9
2.2. Les effets de la PIC sur les choix de portefeuille ... 10
2.2.1. Le cas général ... 10
2.2.2. Le cas particulier ... 11
2.3. La mesure expérimentale de la PIC ... 13
2.3.1. La mesure du niveau de PIC pour les séquences monotones ... 16
2.3.2. La mesure du niveau de PIC pour les séquences non-monotones ... 16
2.3.3. L’évaluation de l’intensité de la monotonie ... 17
2.3.4. Un exemple de calcul de niveau de PIC et d’intensité de la monotonie ... 18
Chapitre 3 Expérience ... 20
3.1. Les mises en situation expérimentale ... 20
3.1.2. La structure des traitements ... 20
3.2. Le questionnaire ... 24
3.2.1. Le questionnaire sur les motivations des décisions ... 25
3.2.2. Le test de connaissances sur la diversification de portefeuille ... 25
3.2.3. Le test des habiletés de calcul du Berlin Numeracy Test ... 25
3.2.4. Les questions générales ... 25
3.3. Le protocole expérimental ... 26
3.4. Les statistiques descriptives ... 27
3.4.1. L’échantillon ... 27
3.4.3. Les motivations et le temps de réponse des participants ... 32
Chapitre 4 Résultats ... 35
4.1. Les niveaux de PIC de l’échantillon ... 35
4.1.1. La distribution des niveaux de PIC ... 35
4.1.2. L’évaluation de l’intensité de la monotonie ... 37
4.2. Le modèle empirique ... 39
4.2.1. Les variables incluses dans le modèle ... 42
4.2.2. L’estimation des paramètres et des effets marginaux ... 42
4.3. La mesure de la PIC en sondage ... 45
4.4. Les solutions pour atténuer la PIC... 49
Conclusion ... 54
Bibliographie ... 56
Annexe A La collecte des données ... 59
A.1. La liste des modifications à l’expérience entre la première et la deuxième période de collecte ... 59
A.2. La répartition des séances et des participants selon la date ... 60
A.3. Les noms des personnes fictives à qui les participants recommandent des fonds ... 60
A.4. Les statistiques descriptives de l’échantillon de l’automne 2019 ... 61
Annexe B Les variables explicatives ... 62
Annexe C L’expérience ... 65
Annexe D Les régressions du modèle empirique principale ... 73
Annexe E Les régressions supplémentaires ... 79
E.1. Les modèles pour deux catégories de raisons principales des choix ... 79
E.2. Les modèles de la mesure de la PIC en sondage sur la mesure expérimentale de la PIC ... 82
Liste des tableaux
Tableau 1. Statistiques descriptives des huit situations ... 13
Tableau 2. Seuil de renversement des huit situations ... 14
Tableau 3. Choix de portefeuilles entre P1D et P2D selon le paramètre de PIC 𝛥𝛥 ... 14
Tableau 4. Seuil de renversement des huit situations selon les trois types de données ... 15
Tableau 5. Le plan expérimental ... 21
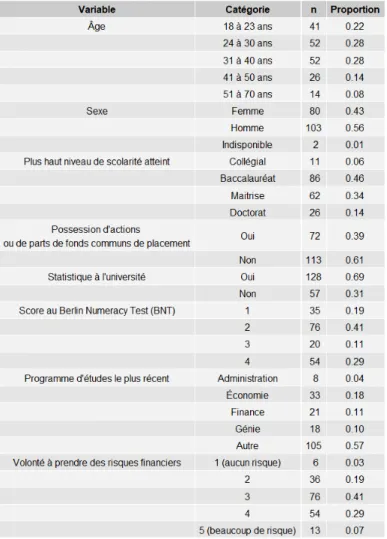
Tableau 6. Statistique descriptive de l'échantillon (185 participants) ... 27
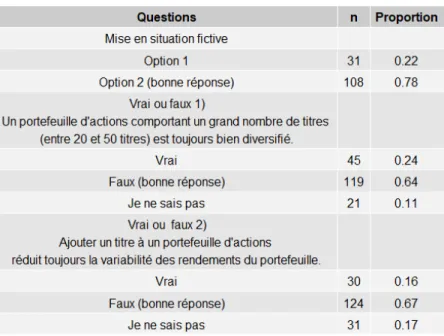
Tableau 7. Statistique descriptive des réponses au test de connaissances : mise en situation fictive (139 participants) et « vrai ou faux » (185 participants) ... 28
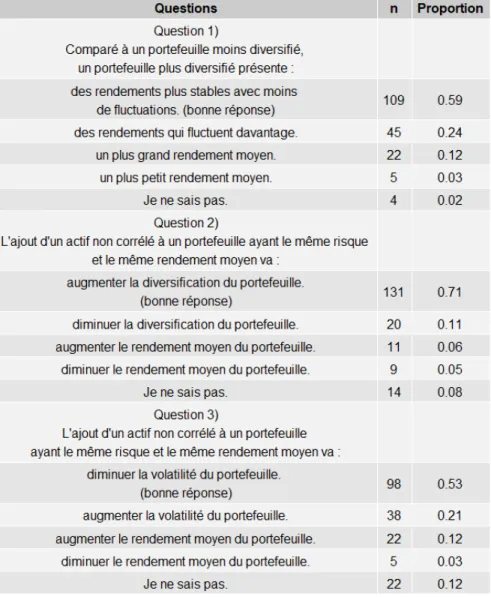
Tableau 8. Statistique descriptive des réponses au test de connaissances : Questions tirées de Reinholtz et coll. (2018) (185 participants) ... 29
Tableau 9. Taux de succès par traitement (format de présentation et niveau d’information) (185 participants) 30 Tableau 10. Taux de succès par traitement (format de présentation, niveau d’information et nombre de décimales) (139 participants) ... 31
Tableau 11. Taux de succès par traitement (niveau d’information et ordre d’apparition des niveaux) (185 participants) ... 31
Tableau 12. Taux de succès par traitement (numéro de situation et niveau d’information) (139 participants) . 32 Tableau 13. Statistique descriptive des motivations des décisions (185 participants) ... 33
Tableau 14. Temps de réponse des participants (en minutes) ... 34
Tableau 15. Description abrégée des modèles ... 43
Tableau 16. Mesure de la PIC : test à trois questions ... 46
Tableau 17. Statistique descriptive des résultats à l’expérience selon le score au test à trois questions (139 participants) ... 47
Tableau 18. Effets marginaux du niveau de PIC mesuré expérimentalement sur deux mesures de la PIC en sondage ((1) obtenir un score de 2 ou 3 au test à trois questions et (2) obtenir la bonne réponse à la mise en situation fictive) pour chacun des niveaux d’information (format abrégé) ... 48
Tableau 19. Répartition des séances et des participants selon la période de temps ... 60
Tableau 20. Noms des personnes fictives par situation et par niveau d'information ... 60
Tableau 21. Statistique descriptive de l'échantillon (139 participants) ... 61
Tableau 22. Résultat des régressions du modèle empirique ... 73
Tableau 23. Estimation des effets marginaux des modèles du Tableau 22 ... 76
Tableau 24. Résultat des régressions pour deux sous-groupes de participants selon la raison principale des choix ... 79
Tableau 25. Résultat des régressions probit de deux mesures de la PIC en sondage ((1) obtenir un score de 2 ou 3 au test à trois questions et (2) obtenir une bonne réponse à la mise en situation fictive) sur le niveau de PIC expérimentalement estimé et la mesure d’intensité de la monotonie pour chacun des niveaux d’information (format long) ... 83
Tableau 26. Résultat de la régression probit du score au test à trois questions (0 ou 1 (codé par 0) versus 2 ou 3 (codé par 1)) sur les traitements à l'expérience et les caractéristiques individuelles ... 85
Liste des figures
Figure 1. Schéma des paramètres δ et 𝛥𝛥 ... 12
Figure 2. Processus de développement de la mesure de l’intensité des séquences non-monotones ... 19
Figure 3. Les formats de présentation ... 22
Figure 4. Les niveaux d'information. ... 24
Figure 5. Histogramme de la PIC pour les réponses provenant de séquences monotones (gauche) et pour les réponses de tous les répondants (droite) ... 35
Figure 6. Histogramme de la PIC pour les séquences monotones (gauche) et pour les réponses de toutes les séquences (droite) par niveau d’information (A-B-C) ... 36
Figure 7. Histogramme de la distribution des pointages d’intensité de la monotonie des données simulées ... 37
Figure 8. Histogramme des pointages de l’intensité de la monotonie par traitement pour les données réelles (139 participants) et pour les données simulées ... 38
Liste des sigles
BNT : Berlin Numeracy Test
CIRANO : Centre interuniversitaire de recherche en analyse des organisations LEEL : Laboratoire d’économie expérimentale de l’Université Laval
Remerciements
Tout d’abord, je souhaite remercier mon directeur de mémoire, M. Charles Bellemare, de m’avoir accordé sa confiance à me joindre à la grande équipe de ce projet de recherche. Merci pour votre apport à ce projet et pour vos commentaires et propositions.
Je suis également très reconnaissante envers ma codirectrice, Mme Sabine Kröger. Je tiens à souligner sa disponibilité, les responsabilités importantes que j’ai eu la chance qu’elle m’accorde et les opportunités offertes. Merci pour les nombreux commentaires et suggestions que vous m’avez faits.
Je remercie M. Stéphane Chrétien pour sa contribution au projet et pour ces commentaires sur plusieurs aspects. Merci pour les apprentissages en finance que vous m’avez inculqués.
Je tiens à remercier Gabriel Amiot et Nicolas Cadelis qui ont énormément travaillé sur l’expérience du projet. Merci pour votre accueil lorsque je me suis jointe à l’équipe, pour toutes les connaissances financières que vous m’avez apprises et pour le temps que vous avez mis à ce projet.
Je remercie également l’Autorité des marchés financiers pour le financement de ce projet. Je remercie également le CRREP de m’avoir accordé une bourse d’excellence dans le cadre de cette recherche.
Je remercie les membres de l’équipe du CSTIP qui contribue fortement à l’opérationnalisation du Laboratoire d’économie expérimentale de l’Université Laval, ainsi que l’équipe du Laboratoire d’économie expérimentale du CIRANO.
Je remercie mon amoureux Simon-Olivier d’avoir investi plusieurs heures à m’aider à la réalisation de ce mémoire. Merci sincèrement pour tous les commentaires et les propositions.
Finalement, je tiens à remercier mes parents pour leurs valeurs de vaillance et de persévérance. Merci de m’avoir soutenue et d’avoir été à l’écoute dans les moments les plus difficiles. Merci pour la fierté que vous avez à mon égard.
Introduction
La littératie financière est la possession de suffisamment de connaissances, de compétences et de confiance pour prendre des décisions financières responsables. Avant les années 2000, les modèles théoriques de prise de décisions financières incluaient très peu le niveau de littératie financière des individus (Lusardi et Mitchell (2011)). Toutefois, il se trouve un grand nombre de recherches sur la relation entre la littératie financière et le comportement financier dans la littérature (Lusardi et Mitchell (2014)). Les chercheurs observent que de meilleures connaissances impliquent de meilleures décisions (Boisclair et coll. (2017), Van Roji et coll. (2011) et Lusardi et Mitchell (2011)).
La diversification est primordiale pour choisir des portefeuilles optimaux (Markowitz (1952)). Un des éléments principaux à prendre en compte lors de la diversification d’un portefeuille est la corrélation entre les actifs, sinon même un portefeuille avec un grand nombre d’actifs peut être inefficace. Par exemple, un portefeuille peut ne pas être suffisamment diversifié si la majorité des actifs sont dans le même secteur économique ou de même type. La mesure de la corrélation permet de détecter ce type de problème et d’analyser le degré d’interaction entre les actifs.
Le niveau de corrélation a d’énormes implications sur le risque d’un portefeuille financier. Pour deux actifs donnés, la corrélation peut être positive, négative ou nulle. Une corrélation positive entre deux actifs signifie que, lorsqu’un actif est à la hausse, l’autre augmente généralement aussi. Cependant, lorsqu’un se porte à la baisse, le second se porte également mal. Cette relation positive entre des actifs d’un portefeuille est néfaste. Elle occasionne plus de volatilité dans les rendements que si les actifs étaient corrélés négativement. Effectivement, une corrélation négative entre deux actifs signifie que ces derniers vont généralement dans des sens opposés, c’est-à-dire si un est en croissance, l’autre est en décroissance. La décroissance de l’un est compensée par la croissance de l’autre. Ceci assure une stabilité dans les rendements. Ainsi, les rendements d’un portefeuille avec des actifs corrélés négativement sont moins variables que ceux corrélés positivement. En d’autres mots, plus la corrélation est faible entre les actifs, plus la volatilité du portefeuille est faible, et donc moins il est risqué. Le portefeuille est ainsi mieux diversifié toute chose étant égale par ailleurs.
Bien qu’il semble simple de comprendre les implications de la corrélation en choix de portefeuille, des investisseurs semblent l’oublier quand ils doivent faire leurs choix (Kroll et coll. (1988)). Cette absence d’attention envers la corrélation est un biais comportemental nommé « Correlation Neglect », ou en français, la « Prédisposition à Ignorer la Corrélation (PIC) ». La PIC est une simplification du processus de décision. Effectivement, l’individu prendra une décision plus rapide et moins réfléchie puisqu’il ignore la corrélation entre les différents actifs de son portefeuille. Ce biais occasionne des risques inutiles et des effets indésirables sur
L'objectif de ce mémoire est de développer les connaissances sur la PIC dans la prise de décision à investir. Pour y arriver, les quatre objectifs spécifiques sont : 1) évaluer l’existence de la PIC, 2) analyser les déterminants de la PIC, 3) valider une mesure de la PIC simple et 4) proposer des solutions pour atténuer la PIC. L’ensemble de ces objectifs n’a jamais été poursuivi à notre connaissance dans la littérature bien que la PIC puisse avoir de graves conséquences sur les finances personnelles.
Dans le cadre du premier objectif spécifique, nous réalisons une expérience en laboratoire qui permet d’évaluer la PIC chez le répondant. Pour le deuxième objectif spécifique, nous déterminons les sous-groupes de la population les plus à risque de la PIC, soit les caractéristiques des individus présentant le plus de difficulté lors de l’expérience. Pour le troisième objectif spécifique, nous analysons la relation entre le résultat à l’expérience et des questions simples à choix multiple mesurant la PIC. Finalement, dans le cadre du dernier objectif spécifique, nous évaluons des solutions pour atténuer la PIC. Nous analysons différents formats de présentation et niveaux d’information financière. Puis, nous observons si certains réduisent la PIC.
Ce document est divisé de la manière suivante. Tout d’abord, le chapitre 2 présente une revue de la littérature. Ensuite, les chapitres 3 et 4 contiennent le cadre théorique et l’expérience. Finalement, le chapitre 5 comporte les résultats.
Chapitre 1
Revue de littérature
Ce chapitre présente l’état des connaissances actuel sur la prédisposition à ignorer la corrélation (PIC). Tout d’abord, nous présentons brièvement les connaissances sur la littératie financière, puis nous décrivons la PIC et des expériences en laboratoire réalisées sur ce biais. Nous exposons également les pistes de réduction actuelles de ce biais.
1.1. La littératie financière
Plusieurs études ont été faites sur les effets de la littératie financière sur le comportement financier. Des connaissances plus avancées en finance impliquent de meilleures décisions (Boisclair et coll. (2017), Van Roji et coll. (2011) et Lusardi et Mitchell (2011)). Malheureusement, le niveau de littératie financière des Canadiens est faible (Boisclair et coll. (2017)). Boisclair et coll. (2016) trouvent des résultats concernant les caractéristiques démographiques des Canadiens qui concordent avec ceux d’autres pays (Lusardi et Mitchell (2011)). Il existe une relation en forme de U inversé entre l’âge et le niveau de littératie financière. Les jeunes et les personnes âgées ont un niveau de connaissances financières plus faible que ceux d’âge moyen, et les personnes de moins de 35 ans performent encore moins bien que les aînés. De plus, les femmes ont moins de connaissances financières que les hommes, et les personnes avec des niveaux d’éducation plus faibles ont moins de connaissances financières que ceux à plus haut niveau. Il s’agit de résultats sur la relation entre les caractéristiques individuelles et le niveau de littératie financière. Les groupes d’individus mentionnés sont donc plus ou moins à risque de prendre de mauvaises décisions financières.
1.2. La Prédisposition à Ignorer la Corrélation (PIC)
Dans ce mémoire, nous nous intéressons plus précisément à un biais comportemental ayant des effets sur la diversification de portefeuilles financiers. Le biais d’intérêt est la Prédisposition à Ignorer la Corrélation (PIC) en contexte d’investissement. La PIC intervient principalement lorsqu’un investisseur souhaite ajouter des fonds à son portefeuille financier. Pour diversifier son portefeuille de manière optimale, la corrélation entre les fonds détenus et les fonds potentiels doit être prise en compte. En effet, ignorer cette information financière peut mener à des portefeuilles plus risqués. Prenons le cas simple de deux fonds. La corrélation entre ces deux fonds est soit positive, nulle ou négative. Toute chose étant égale par ailleurs, une corrélation négative est souhaitable entre deux fonds. En effet, une corrélation négative provoque moins de fluctuation dans les rendements qu’une corrélation positive. Il est donc primordial de porter attention à la corrélation entre les fonds pour sélectionner le portefeuille optimal. Ignorer l’information sur la corrélation entre les fonds est le biais comportemental sur lequel nous nous penchons.
La PIC mène l’investisseur à simplifier son processus de décision. L’investisseur épargne du temps de réflexion concernant l’interaction entre les actifs, cependant ce gain de temps a des effets néfastes sur ses finances personnelles. Effectivement, la PIC est une entrave directe à une bonne diversification, alors que cette dernière est primordiale en choix de portefeuille (Markowitz (1952)).
Des expériences contrôlées ont permis de constater une absence de la prise en compte des informations sur la corrélation entre les actifs lors de la création de portefeuilles. La première expérience constatant l’existence de ce problème est celle de Kroll et coll. (1988). Leur expérience visait initialement à tester les hypothèses du théorème de séparation et du modèle d’évaluation des actifs financiers, soit le « Capital Asset Pricing Model» en anglais, un modèle prédisant les rendements et les prix des actifs sur le marché financier.
Dans l’expérience de Kroll et coll. (1988), les participants, des étudiants au premier cycle, distribuent leur capital entre trois actifs risqués, A, B et C, lors de 20 jeux avec un maximum de 10 essais chacun. Les participants sont attribués aléatoirement à un des trois groupes de traitement avec un niveau de corrélation différent entre les actifs B et C de soit 0.8, 0 ou -0.8. Toutefois, les proportions d’investissement ne varient pas significativement entre les trois groupes. En d’autres mots, peu importe le niveau de corrélation attribué entre les actifs B et C, les participants choisissent à peu près la même allocation. Ainsi, les participants ignorent la corrélation. Plus d’une décennie plus tard, des chercheurs se penchent directement sur la question de la négligence de la corrélation en situation d’investissement. Entre autres, Kallir et Sonsino (2009) étudient l’effet de la variation de la corrélation entre deux actifs sur l’investissement d’étudiants en administration des affaires de premier et deuxième cycle. Les participants distribuent leur capital entre des actifs A et B. Les rendements de ces actifs ne prennent que deux valeurs, soit un rendement élevé ou un rendement faible. Les participants disposent de la distribution des rendements pour 12 périodes sous forme d’un tableau de fréquences absolues. La distribution marginale de l’actif A est toujours supérieure à celle de B. La seule raison d’allouer des fonds à B est que les rendements de B sont élevés quand ceux de A sont faibles, soit que la corrélation entre A et B est négative. Les participants doivent prendre cinq décisions, soit allouer à cinq reprises une portion de leur montant à investir dans les deux actifs A et B. À chaque décision, Kallir et Sonsino (2009) modifient la corrélation entre les actifs A et B. La corrélation varie entre 2/3, 1/3, 0, -1/3 et -2/3. Les auteurs observent que l’allocation à l’actif B n’augmente pas significativement à mesure que la corrélation entre les actifs A et B diminue, telle que les modèles théoriques le prédiraient. Les individus ont donc ignoré la corrélation entre les actifs A et B pour prendre leur décision d’investissement. Les participants ont plutôt basé leur décision sur le rendement observé précédemment pour les deux actifs que sur la distribution conjointe des rendements. Anderson et Settle (1996) obtiennent aussi, lors d’une expérience, que leurs participants ont de la difficulté à prendre en compte les informations sur le risque des actifs pour la construction d’un portefeuille.
Dans les expériences de Kroll et coll. (1988) et de Kallir et Sonsino (2009), les auteurs varient la corrélation entre les actifs et espèrent une modification significative de l’allocation aux actifs face à la variation. Toutefois, ils observent peu de changements dans les portefeuilles des participants. Eyster et Weizsacker (2011) inversent ce format. Le participant devrait choisir des portefeuilles équivalents dans chacun des problèmes de décisions qui lui sont présentés. Eyster et Weizsacker (2011) soutiennent que les deux approches se complémentent et dressent un portrait complet de la PIC.
Dans l’expérience de Eyster et Weizsacker (2011), 146 étudiants majoritairement au premier cycle font face successivement à huit choix de portefeuille à deux actifs. Les participants disposent du rendement des actifs dans quatre états équiprobables. Ces derniers répartissent une portion de leurs points dans le premier actif et le reste dans le second. Les huit choix peuvent être séparés en quatre problèmes à pair de choix, c’est-à-dire que dans chacun des quatre problèmes, il y a deux décisions à prendre. Pour la première décision, les deux actifs présentés, A et B, ne sont pas corrélés (version non corrélée). Pour la deuxième décision, deux actifs C et D sont proposés où C correspond exactement à A et où D est une combinaison linéaire de A et B (version corrélée). Tous les portefeuilles réalisables dans la version non corrélée peuvent être répliqués dans la version corrélée, et l’inverse est aussi possible. Les auteurs s’attendent à ce que les participants choisissent des portefeuilles équivalents dans les deux décisions d’un problème. Cependant, les participants ne connaissent pas la structure des actifs C et D, c’est-à-dire qu’ils sont reliés aux actifs A et B. Il est donc complexe pour les participants de réaliser des choix qui sont équivalents pour chacun des problèmes. D’ailleurs, 61% des participants ne choisissent pour aucun problème deux allocations équivalentes. Puis, 97% des participants choisissent plus fréquemment des portefeuilles non équivalents qu’équivalents.
Eyster et Weizsacker (2011) considèrent deux théories pour expliquer le comportement des participants : ou bien que l’investisseur est « confus » ou bien qu’il utilise l’heuristique 1/n. L’investisseur confus traite les actifs corrélés comme non corrélés. L’heuristique 1/n est la répartition égale du capital entre les n options proposées. Cette heuristique a été documentée par Bernatzi et Thaler (2001).
Eyster et Weizsacker (2011) réalisent des régressions pour évaluer le pouvoir prédictif de ces deux théories. Ils trouvent que les deux prédisent bien la moyenne des données, mais que le modèle de l’heuristique 1/n a un plus grand pouvoir prédictif. Eyster et Weizsacker (2011) trouvent donc des preuves que les participants ignorent la corrélation en traitant des variables corrélées comme non corrélées. Cependant, leur expérience est compliquée et le manque d’information concernant la structure des actifs dans les versions corrélées peut expliquer la plus grande apparence de l’heuristique 1/n. Effectivement, le participant qui ne remarque pas que le choix qu’il fait est lié au précédent peut répartir également ses points dans les deux actifs en pensant qu’il diversifie bien son portefeuille de cette façon.
Les expériences portant sur la PIC sont toutes effectuées en laboratoire avec l’objectif de déterminer l’existence ou non en contexte d’investissement. Toutefois, nous ne connaissons rien sur les déterminants de la PIC.
1.3. La réduction du biais de la PIC
Étant donné des effets néfastes que peut avoir la PIC sur les finances personnelles, il est pertinent de se questionner sur la façon dont il est possible de réduire ce biais.
Actuellement, les niveaux de connaissances des Canadiens concernant la diversification sont faibles (Boisclair et coll. (2016)). Ainsi, nous pourrions être portés à croire que de créer des programmes d’éducation financière permettrait de réduire la PIC. Toutefois, il semble que ces programmes n’ont pas les effets désirés sur le comportement. Effectivement, Fernandes et coll. (2014) se penchent sur l’impact de programmes éducatifs en finance sur les futurs comportements des participants à ces programmes. Les auteurs réalisent une méta-analyse de plus de 150 articles portant sur l’effet de programmes ayant pour objectif d’améliorer le niveau de connaissances financières. Ils trouvent que l’effet sur le comportement est significatif, mais faible, et encore plus faible lors de l’utilisation de variables instrumentales. Ainsi, les programmes d’éducation financière n’ont pas un impact significatif sur le long terme. Une des explications mises de l’avant est que les connaissances financières apprises se détériorent à travers le temps et les individus oublient leurs apprentissages financiers avant de les mettre en application. Fernandes et coll. (2014) suggèrent qu’il faudrait intervenir juste avant l’action que le programme est destiné à changer. Toutefois, l’éducation nécessite du temps et ce n’est pas nécessairement toutes les cohortes qui ont accès au programme. Ainsi, ces programmes ne semblent pas être une solution efficace pour modifier les comportements financiers des individus jusqu’à présent.
Une alternative à l’éducation est de modifier la présentation des choix (Fernandes et coll. (2014)). La modification à l’architecture du choix serait une solution pour guider et aider les agents à prendre de meilleures décisions. En effet, la façon dont est présentée l’information peut améliorer le comportement de l’individu (Hoffrage et coll. (2000) et Thaler et Sunstein (2009)). Les études de Kallir et Sonsino (2009) et de Eyster et Weizsacker (2011) incluent une partie sur la modification de la présentation pour mesurer son effet sur la présence de la PIC chez les participants.
Tout d’abord, Kallir et Sonsino (2009) refont l’étude mentionnée plus tôt dans laquelle les participants répartissent leur capital entre deux actifs A et B. Cependant, cette fois, il y a deux niveaux de corrélation plutôt que cinq, et la distribution conjointe des rendements est présentée sous forme de diagramme à secteurs avec pourcentage plutôt que sous forme de tableau de fréquences. Les résultats sont similaires à la première expérience en ce qui concerne la modification de l’allocation vis-à-vis de la variation de la corrélation entre les actifs. Ainsi, le changement de mode de présentation n’a pas modifié le comportement des participants, et la
PIC apparait toujours. Toutefois, Hoffrage et coll. (2000) trouvent que l’information présentée en pourcentage est plus complexe que celle en fréquence. L’expérience de Kallir et Sonsino (2009) est donc complexifiée par l’affichage des fréquences (fréquence à pourcentage), puis elle est simplifiée en termes du nombre de décisions à prendre (cinq à deux décisions) et en termes du format de présentation (tableau à diagramme en secteurs). Il est donc difficile d’évaluer avec ses nombreux changements si l’expérience est complexifiée ou simplifiée. D’autre part, Eyster et Weizsacker (2011) font une nouvelle expérience présentée de deux façons à deux groupes de participants différents et ils obtiennent un changement significatif entre les deux groupes. Dans l’expérience, deux portefeuilles sont proposés. Lorsque la corrélation est ignorée, le premier portefeuille semble dominer le second. Le premier groupe observe deux portefeuilles qui sont chacun composés de deux actifs U et V. Le portefeuille 1 investit 52 points dans U et 8 dans V et le portefeuille 2 investit 26 points dans U et 34 dans V. Presque l’ensemble des participants choisit le premier portefeuille qui semble dominer le second. Le second groupe observe plutôt deux portefeuilles comportant chacun un seul actif U’ ou V’, tels que 𝑈𝑈’ =5260∗ 𝑈𝑈 +608 ∗ 𝑉𝑉 et 𝑉𝑉’ =2660∗ 𝑈𝑈 +3460∗ 𝑉𝑉. Ces portefeuilles ont exactement le même rendement espéré que ceux présentés au premier groupe. Toutefois, les participants du deuxième groupe ont un calcul de moins à faire par rapport à ceux du premier groupe. Pour eux, le portefeuille global est déjà affiché. Dans le second groupe, près de la moitié des participants sélectionnent le deuxième portefeuille. Ainsi, la modification de la présentation a modifié significativement la décision des participants et a diminué le biais de la PIC.
1.4. Le résumé
En somme, plusieurs auteurs ont étudié les effets de la littératie financière sur les comportements financiers. Il est connu que de meilleures connaissances mènent à de meilleurs comportements. Quelques auteurs ont constaté l’existence du biais de la PIC par des expériences, mais aucune mesure simple permettant d’identifier les personnes les plus à risque de ce biais n’a encore été développée. Ce type de mesure existe plus généralement pour la littératie financière (Lusardi et Mitchell (2011)), mais il n’en existe aucune pour la PIC plus précisément.
Pour répondre à cette faille de la littérature actuelle, nous réalisons également une expérience en laboratoire, toutefois la nôtre se distingue par sa simplicité pour le participant. De plus, notre expérience évalue la relation entre les résultats à l’expérience et certaines questions sur les implications de la corrélation en choix de portefeuille et sur la diversification. Des questions fortement reliées avec les résultats à l’expérience seraient une bonne mesure de la PIC et seraient facilement insérables dans un questionnaire. Ce type de validation de mesure existe déjà pour d’autres caractéristiques individuelles telles que l’aversion au risque (Dohmen et coll.
(2011). Nous analysons les déterminants de la PIC et nous comparons nos résultats avec ceux des écrits pour la littératie financière.
De plus, la modification de la présentation de l’information financière semble pouvoir diminuer le biais comportemental de la PIC. Lors de l’expérience de Eyster et Weizsacker (2011), l’évitement d’un calcul aux participants avait amélioré leur décision financière. Notre expérience évalue différents formats de présentation et niveaux d’information financière.
Chapitre 2
Cadre théorique
Ce chapitre présente le cadre théorique du choix de portefeuille optimal, puis les effets de la PIC sur ce choix. Nous développons également une mesure expérimentale de la PIC.
2.1. La théorie moderne du portefeuille
La théorie moderne du choix optimal de portefeuille a été développée par Markowitz (1952). Cette section montre l’approche de l’analyse de l’espérance et de la variance. Nous présentons ici cette approche pour un portefeuille composé de deux actifs.
Pour un portefeuille composé de deux actifs A et B, le rendement espéré du portefeuille, 𝔼𝔼�𝑅𝑅𝑝𝑝�, est :
Équation 1
𝔼𝔼(𝑅𝑅𝑃𝑃) = 𝔼𝔼(𝑎𝑎 ∗ 𝑅𝑅𝐴𝐴+ (1 − 𝑎𝑎) ∗ 𝑅𝑅𝐵𝐵) = 𝑎𝑎 ∗ 𝔼𝔼(𝑅𝑅𝐴𝐴) + (1 − 𝑎𝑎) ∗ 𝔼𝔼(𝑅𝑅𝐵𝐵)
où 𝑎𝑎 La part de l’investissement dans l’actif A, telle que 0 ≤ 𝑎𝑎 ≤ 1 ; 𝔼𝔼(𝑅𝑅𝐴𝐴) L’espérance des rendements de l’actif A ;
𝔼𝔼(𝑅𝑅𝐵𝐵) L’espérance des rendements de l’actif B.
La variance des rendements de ce portefeuille, 𝑉𝑉(𝑅𝑅𝑃𝑃), est :
Équation 2
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) = 𝑉𝑉𝑎𝑎𝑉𝑉(𝑎𝑎 ∗ 𝑅𝑅𝐴𝐴+ (1 − 𝑎𝑎) ∗ 𝑅𝑅𝐵𝐵)
= 𝑎𝑎2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅
𝐴𝐴) + (1 − 𝑎𝑎)2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵) + 2 ∗ 𝑎𝑎 ∗ (1 − 𝑎𝑎) ∗ 𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅𝐴𝐴, 𝑅𝑅𝐵𝐵)
où 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴) La variance des rendements de l’actif A ;
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵) La variance des rendements de l’actif B ;
𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅𝐴𝐴, 𝑅𝑅𝐵𝐵) La covariance des rendements des actifs A et B.
La covariance des rendements des actifs A et B peut être exprimée comme :
Équation 3
𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅𝐴𝐴, 𝑅𝑅𝐵𝐵) = 𝜌𝜌𝐴𝐴,𝐵𝐵∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴) ∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵)
où 𝜌𝜌𝐴𝐴,𝐵𝐵 La corrélation entre les rendements des actifs A et B,
telle que −1 ≤ 𝜌𝜌𝐴𝐴,𝐵𝐵≤ 1.
Équation 4
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) = 𝑎𝑎2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴) + (1 − 𝑎𝑎)2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵) + 2 ∗ 𝑎𝑎 ∗ (1 − 𝑎𝑎) ∗ 𝜌𝜌𝐴𝐴,𝐵𝐵∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴)
∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵).
La méthode de l’analyse de l’espérance et de la variance de Markowitz est de maximiser l’espérance de rendement en ayant la variance minimale. Le portefeuille avec le rendement espéré le plus élevé n’est pas nécessairement celui avec la variance la plus faible. Ainsi, selon cette théorie, l’investisseur va minimiser la variance 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) pour une espérance 𝔼𝔼(𝑅𝑅𝑃𝑃) donnée ou plus, et va maximiser l’espérance 𝔼𝔼(𝑅𝑅𝑃𝑃) pour une
variance 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) donnée ou moins. Par cette approche, les portefeuilles efficaces que Markowitz obtient sont
presque tous diversifiés. Ainsi, les investisseurs rationnels diversifient leur portefeuille pour optimiser leur rendement.
Par ailleurs, il est aisé de remarquer à l’Équation 4 que si la corrélation entre les rendements des actifs A et B diminue, la variance du portefeuille diminue toute chose étant égale par ailleurs. Ceci démontre qu’une corrélation négative entre les actifs est préférable à une corrélation positive ou nulle.
2.2. Les effets de la PIC sur les choix de portefeuille
2.2.1. Le cas général
Le biais comportemental de la PIC mène parfois l’investisseur à des choix différents que ce que la théorie de Markowitz (1952) prédit. Effectivement, ignorer la corrélation entre les rendements signifie que l’investisseur traite comme indépendants deux actifs potentiellement corrélés. Dans ce cas, le troisième terme de l’Équation 4 est nul puisque 𝜌𝜌𝐴𝐴,𝐵𝐵= 0. Ainsi, l’équation de la variance du portefeuille pour un individu ignorant
complètement la corrélation, 𝑉𝑉(𝑅𝑅� , est : 𝑃𝑃)
Équation 5
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅� = 𝑎𝑎𝑃𝑃) 2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴) + (1 − 𝑎𝑎)2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵).
Une alternative possible pour considérer l’inattention à la corrélation dans la variance du portefeuille est en introduisant un paramètre de l’attention envers la corrélation 𝛿𝛿 dans l’Équation 4 de la variance au troisième terme. Ce paramètre prend une valeur entre 0 et 1, soit 𝛿𝛿 ∈ [0,1]. L’Équation 6 présente cette nouvelle équation de la variance.
Équation 6
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅� = 𝑎𝑎𝑃𝑃) 2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴) + (1 − 𝑎𝑎)2∗ 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵) + 𝛿𝛿 ∗ 2 ∗ 𝑎𝑎 ∗ (1 − 𝑎𝑎) ∗ 𝜌𝜌𝐴𝐴,𝐵𝐵∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐴𝐴)
∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐵𝐵).
Ceci permet de considérer différents niveaux d’attention envers la corrélation. Ainsi, 𝛿𝛿 = 0 signifie que la corrélation est complètement ignorée (PIC élevée). 𝛿𝛿 = 0.5 décèle une PIC partielle. 𝛿𝛿 = 1 indique que le répondant porte complètement attention à la corrélation (PIC nulle). Il est possible de constater que si 𝛿𝛿 = 0, alors 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅� = 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) � , et si 𝛿𝛿 = 1, 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) � = 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃) 𝑃𝑃). Le niveau de PIC est donc Δ = 1 −
𝛿𝛿. Δ = 1 signifie une PIC élevée, alors que Δ = 0 signifie une attention totale à la corrélation.
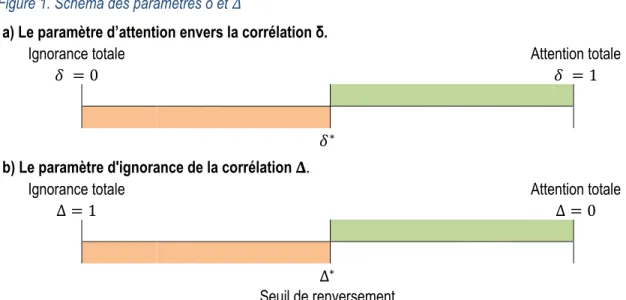
2.2.2. Le cas particulier
Cette section présente un cas particulier qui occupe une place centrale dans l’expérience. Supposons que : (i) Un investisseur avec un niveau de PIC de Δ investit actuellement Z $ dans un fonds détenu D ; (ii) Cet investisseur souhaite investir Z $ supplémentaires dans un fonds potentiel P1 ou P2 ; (iii) L’espérance des rendements des fonds P1 et P2 est la même.
La décision optimale ne dépend que de la variance du portefeuille global 1 combinant les fonds D et P1 (PF1 : P1D) et du portefeuille global 2 combinant les fonds D et P2 (PF2 : P2D). Effectivement, l’investisseur choisit le portefeuille avec la variance minimale des rendements, puisque l’espérance de rendement est la même pour les deux portefeuilles. Alors, l’investisseur choisira le fonds P1 si 𝑉𝑉(𝑅𝑅� < 𝑉𝑉(𝑅𝑅𝑃𝑃1𝐷𝐷) � , c’est-à-dire si : 𝑃𝑃2𝐷𝐷)
Équation 7
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃1) + 𝛿𝛿 ∗ 2 ∗ 𝜌𝜌𝑃𝑃1,𝐷𝐷∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃1) ∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐷𝐷)
< 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃2) + 𝛿𝛿 ∗ 2 ∗ 𝜌𝜌𝑃𝑃2,𝐷𝐷∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃2) ∗ �𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝐷𝐷).
Au contraire, si 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅�𝑃𝑃1𝐷𝐷)> 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅�𝑃𝑃2𝐷𝐷), alors il choisit le fonds P2. Puis, il sera indifférent entre les deux
actifs si 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅�𝑃𝑃1𝐷𝐷)= 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅�𝑃𝑃2𝐷𝐷).
Si nous ne connaissons pas le niveau de PIC d’un investisseur et que nous souhaitons le déterminer, le cas d’indifférence devient particulièrement pertinent. Pour déterminer ce niveau, nous observons les choix que cet investisseur fait dans plusieurs décisions de ce type.
Supposons qu’avec l’attention complète à la corrélation, soit avec un 𝛿𝛿 = 1, le choix optimal est P1. À l’opposé, avec une PIC totale, soit avec 𝛿𝛿 = 0, le choix est plutôt P2. Il existe nécessairement un 𝛿𝛿∗∈ (0,1) où il y a
un changement de choix optimal passant de P1 à P2. Il est possible de trouver ce 𝛿𝛿∗ en isolant 𝛿𝛿 dans l’équation
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅�𝑃𝑃1)= 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅� . Nous obtenons l’expression suivante : 𝑃𝑃2)
Équation 8
𝛿𝛿∗=1
2 ∗
𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃1) − 𝑉𝑉𝑎𝑎𝑉𝑉(𝑅𝑅𝑃𝑃2)
Ainsi, le fonds P1 est choisi par l’investisseur si son 𝛿𝛿 est supérieur à 𝛿𝛿∗, alors que le fonds P2 est choisi si son
𝛿𝛿 est inférieur à 𝛿𝛿∗. De plus, 𝛿𝛿∗ correspond au niveau de PIC : Δ∗= 1 − 𝛿𝛿∗. Nous nommons ce point de
changement, Δ∗, le « seuil de renversement », puisqu’il y a un renversement du choix optimal à ce niveau précis
de PIC. La Figure 1 suivante schématise ces informations.
Figure 1. Schéma des paramètres δ et 𝛥𝛥
a) Le paramètre d’attention envers la corrélation δ.
Ignorance totale Attention totale
𝛿𝛿 = 0 𝛿𝛿 = 1
𝛿𝛿∗
b) Le paramètre d'ignorance de la corrélation 𝚫𝚫.
Ignorance totale Attention totale
Δ = 1 Δ = 0
Δ∗
Seuil de renversement
Dans le cas où l’espérance de rendement est différente pour les deux fonds (relâchement de (iii)), le fonds optimal est déterminé par une variante du ratio de Sharpe. Le ratio de Sharpe (RS) pour un portefeuille (PF) est 𝑅𝑅𝑅𝑅 = 𝔼𝔼(𝑅𝑅𝑃𝑃𝑃𝑃)−𝑟𝑟
�𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝑃𝑃𝑃𝑃) . Nous supposons que 𝑟𝑟, le taux de placement sans risque, est de 0. Puis, nous divisons par la
variance plutôt que par l’écart-type. Ainsi, nous maximisons la division de l’espérance par la variance, soit
𝔼𝔼(𝑅𝑅𝑃𝑃𝑃𝑃)
𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝑃𝑃𝑃𝑃). L’investisseur choisit le portefeuille 1 (P1D) par rapport au portefeuille 2 (P2D) si :
Équation 9
𝔼𝔼(𝑅𝑅𝑃𝑃1𝐷𝐷)
𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝑃𝑃1𝐷𝐷) >
𝔼𝔼(𝑅𝑅𝑃𝑃2𝐷𝐷)
𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝑃𝑃2𝐷𝐷).
Le paramètre 𝛿𝛿∗ de l’Équation 8 devient :
Équation 10
𝛿𝛿𝑅𝑅𝑅𝑅∗ =12 ∗�𝔼𝔼(𝑅𝑅𝑃𝑃1) +�𝔼𝔼𝔼𝔼(𝑅𝑅(𝑅𝑅𝐷𝐷)� ∗ (𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝑃𝑃2) + 𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝐷𝐷) − �𝔼𝔼(𝑅𝑅𝑃𝑃𝑃𝑃2) +𝔼𝔼(𝑅𝑅𝐷𝐷)� ∗ 𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝑃𝑃1) + 𝑉𝑉𝑉𝑉𝑟𝑟(𝑅𝑅𝐷𝐷) 𝑃𝑃2) +𝔼𝔼(𝑅𝑅𝐷𝐷)� ∗ 𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅𝑃𝑃1, 𝑅𝑅𝐷𝐷) − �𝔼𝔼(𝑅𝑅𝑃𝑃1) +𝔼𝔼(𝑅𝑅𝐷𝐷)� ∗ 𝐶𝐶𝐶𝐶𝐶𝐶(𝑅𝑅𝑃𝑃2, 𝑅𝑅𝐷𝐷) .
Théoriquement, nous pouvons donc déterminer si le niveau de PIC de l’investisseur est supérieur ou inférieur au seuil de renversement.
2.3. La mesure expérimentale de la PIC
En observant à plusieurs reprises les décisions d’un investisseur, nous sommes en mesure de déterminer une approximation de son niveau de PIC. Le fondement de notre méthode ressemble à celui de Holt et Laury (2002) qui borne l’aversion au risque d’individus. Holt et Laury (2002) invitent les individus à choisir entre deux loteries à plusieurs reprises. Les paiements de chaque loterie restent les mêmes, mais les probabilités d’obtenir les gains varient à chaque décision. Holt et Laury sont en mesure de borner l’aversion au risque d’un individu selon le changement de sa loterie préférée pour une autre.
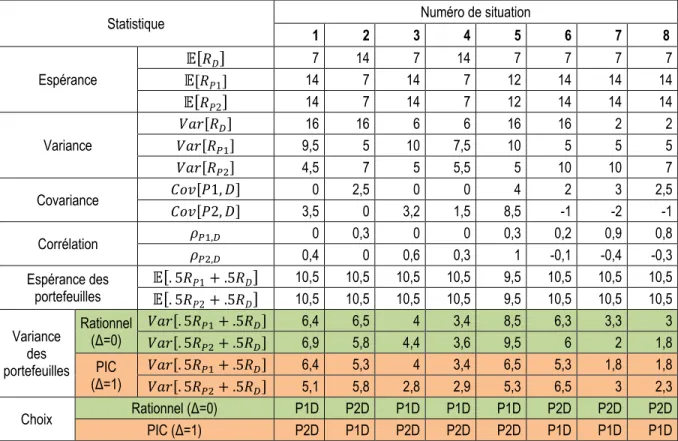
Plutôt que des choix entre deux loteries, nous utilisons des choix entre deux fonds. Plutôt qu’une variation des probabilités de gains entre chaque proposition, nous varions l’espérance, la variance et la corrélation des fonds entre chaque situation. Nous utilisons huit situations différentes de proposition d’ajout d’un fonds potentiel P1 ou P2 à un portefeuille comportant déjà le fonds détenu D. Ceci permet d’attribuer un de neuf niveaux de PIC à un individu. Les caractéristiques de ces situations sont présentées au Tableau 1.
Tableau 1. Statistiques descriptives des huit situations
Statistique Numéro de situation
1 2 3 4 5 6 7 8 Espérance 𝔼𝔼[𝑅𝑅𝐷𝐷] 7 14 7 14 7 7 7 7 𝔼𝔼[𝑅𝑅𝑃𝑃1] 14 7 14 7 12 14 14 14 𝔼𝔼[𝑅𝑅𝑃𝑃2] 14 7 14 7 12 14 14 14 Variance 𝑉𝑉𝑉𝑉𝑟𝑟[𝑅𝑅𝐷𝐷] 16 16 6 6 16 16 2 2 𝑉𝑉𝑉𝑉𝑟𝑟[𝑅𝑅𝑃𝑃1] 9,5 5 10 7,5 10 5 5 5 𝑉𝑉𝑉𝑉𝑟𝑟[𝑅𝑅𝑃𝑃2] 4,5 7 5 5,5 5 10 10 7 Covariance 𝐶𝐶𝐶𝐶𝐶𝐶[𝑃𝑃1, 𝐷𝐷] 0 2,5 0 0 4 2 3 2,5 𝐶𝐶𝐶𝐶𝐶𝐶[𝑃𝑃2, 𝐷𝐷] 3,5 0 3,2 1,5 8,5 -1 -2 -1 Corrélation 𝜌𝜌𝑃𝑃1,𝐷𝐷 0 0,3 0 0 0,3 0,2 0,9 0,8 𝜌𝜌𝑃𝑃2,𝐷𝐷 0,4 0 0,6 0,3 1 -0,1 -0,4 -0,3 Espérance des portefeuilles 𝔼𝔼[𝔼𝔼[. 5𝑅𝑅. 5𝑅𝑅𝑃𝑃1𝑃𝑃2+ .5𝑅𝑅+ .5𝑅𝑅𝐷𝐷𝐷𝐷]] 10,5 10,5 10,5 10,5 10,5 10,5 10,5 10,5 9,5 9,5 10,5 10,5 10,5 10,5 10,5 10,5 Variance des portefeuilles Rationnel (Δ=0) 𝑉𝑉𝑉𝑉𝑟𝑟[. 5𝑅𝑅 𝑉𝑉𝑉𝑉𝑟𝑟[. 5𝑅𝑅𝑃𝑃2𝑃𝑃1+ .5𝑅𝑅+ .5𝑅𝑅𝐷𝐷𝐷𝐷] ] 6,4 6,9 6,5 5,8 4,4 4 3,6 3,4 9,5 8,5 6,3 6 3,3 2 1,8 3 PIC (Δ=1) 𝑉𝑉𝑉𝑉𝑟𝑟[. 5𝑅𝑅 𝑉𝑉𝑉𝑉𝑟𝑟[. 5𝑅𝑅𝑃𝑃1𝑃𝑃2+ .5𝑅𝑅+ .5𝑅𝑅𝐷𝐷𝐷𝐷] ] 6,4 5,1 5,8 5,3 2,8 4 2,9 3,4 5,3 6,5 6,5 5,3 1,8 3 1,8 2,3 Choix Rationnel (Δ=0) P1D P2D P1D P1D P1D P2D P2D P2D PIC (Δ=1) P2D P1D P2D P2D P2D P1D P1D P1D
Note : Le fonds D est le fonds détenu et les fonds P1 et P2 sont les fonds potentiels. Les portefeuilles P1D et P2D sont respectivement le portefeuille potentiel comportant les fonds P1 et D et le portefeuille potentiel comportant les fonds P2 et D.
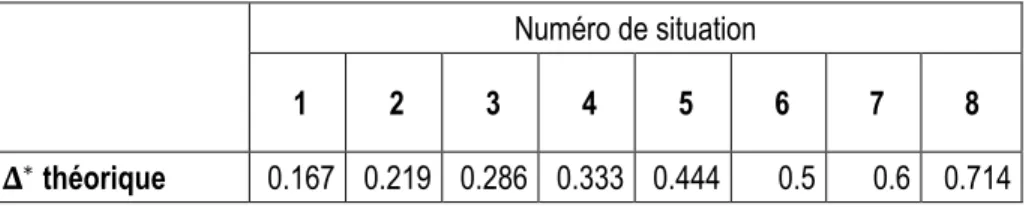
Pour ces huit situations, les seuils de renversements Δ∗ sont présentés au Tableau 2. Pour rappel, il s’agit du
niveau d’ignorance auquel une personne ayant exactement ce niveau de PIC sera indifférente entre les fonds potentiels P1 et P2.
Tableau 2. Seuil de renversement des huit situations
Numéro de situation
1 2 3 4 5 6 7 8
𝚫𝚫∗ théorique 0.167 0.219 0.286 0.333 0.444 0.5 0.6 0.714
Supposons que le niveau de PIC réel d’un individu est de 0.3, soit un niveau modéré de PIC. Il y a trois situations pour lesquels le seuil de renversement est plus faible, soit les situations 1, 2 et 3. Le niveau de PIC de 0.3 se situe dans la zone de mauvaise réponse pour ces questions. Il faut un niveau de PIC plus faible pour répondre adéquatement. À l’opposé, les situations 4 à 8 ont des seuils de renversements plus élevés. Ainsi, le niveau de PIC de 0.3 se situe dans la zone de bonnes réponses pour ces situations. Il aurait fallu que l’individu ait un niveau de PIC plus élevé pour prendre de mauvaises décisions aux situations 4 à 8.
Évidemment, nous n’observons pas le chiffre exact de la PIC d’un individu sinon il faudrait une infinité de situations pour le déterminer. Nous observons plutôt un intervalle dans lequel son niveau de PIC se situe. Le Tableau 3 présente les intervalles possibles selon neuf possibilités de séquence de réponses. Une ligne correspond à une séquence de réponse selon le niveau de PIC affiché dans la première colonne.
Tableau 3. Choix de portefeuilles entre P1D et P2D selon le paramètre de PIC 𝛥𝛥
Intervalles de niveau de PIC Δ Numéro de situation 1 2 3 4 5 6 7 8 Attention totale (Δ=0) P1D P2D P1D P1D P1D P2D P2D P2D Entre 0 et 0.167 P1D P2D P1D P1D P1D P2D P2D P2D Entre 0.167 et 0.219 P2D P2D P1D P1D P1D P2D P2D P2D Entre 0.219 et 0.286 P2D P1D P1D P1D P1D P2D P2D P2D Entre 0.286 et 0.333 P2D P1D P2D P1D P1D P2D P2D P2D Entre 0.333 et 0.444 P2D P1D P2D P2D P1D P2D P2D P2D Entre 0.444 et 0.5 P2D P1D P2D P2D P2D P2D P2D P2D Entre 0.5 et 0.6 P2D P1D P2D P2D P2D P1D P2D P2D Entre 0.6 et 0.714 P2D P1D P2D P2D P2D P1D P1D P2D Entre 0.714 et 1 P2D P1D P2D P2D P2D P1D P1D P1D Ignorance complète (Δ=1) P2D P1D P2D P2D P2D P1D P1D P1D
Les valeurs présentées au Tableau 2 des seuils de renversement sont calculées à partir des données théoriques du Tableau 1. Toutefois, nous présentons un historique de rendement annuel des 10 dernières années à un individu sous la forme d’un diagramme à bandes pour chacun des fonds. Les données affichées sur ce diagramme sont générées à partir d’une loi normale multivariée de paramètres empiriques d’espérance, de variance et de corrélation du Tableau 1. Si nous présentions les données des diagrammes avec l’ensemble des décimales, nous aurions exactement les seuils de renversement présenté au Tableau 2. Il est évidemment impossible de présenter toutes les décimales aux répondants. Nous présentons donc ces données arrondies à une décimale ou à l’entier.
Le seuil de renversement du ratio de Sharpe 𝛿𝛿𝑅𝑅𝑅𝑅∗ est utilisé, car toutes les situations n’avaient pas exactement
la même espérance de rendement pour les deux fonds proposés. Cependant, dans nos situations, les seuils 𝛿𝛿∗
et 𝛿𝛿𝑅𝑅𝑅𝑅∗ ne sont pas très différents. Cela est fait par souci de rigueur. Les seuils obtenus sont présentés au
Tableau 4.
Tableau 4. Seuil de renversement des huit situations selon les trois types de données
Données utilisées pour calculer le seuil de renversement
Numéro de situation
1 2 3 4 5 6 7 8
𝚫𝚫∗ théorique 0.167 0.219 0.286 0.333 0.444 0.500 0.600 0.714
𝚫𝚫∗ calculé à partir des données
non-arrondies 0.167 0.219 0.286 0.333 0.444 0.500 0.600 0.714
𝚫𝚫∗𝑬𝑬 calculé à partir des données
arrondies à l'entier 0.047 0.152 0.281 0.398 0.443 0.511 0.610 0.762
𝚫𝚫∗𝑫𝑫 calculé à partir des données
arrondies à une décimale près 0.183 0.254 0.300 0.342 0.458 0.514 0.636 0.722
Il faut donc modifier un peu les intervalles du Tableau 3 selon les valeurs des seuils de renversement du Tableau 4. Dans le Tableau 3, nous présentons neuf séquences de décisions différentes. Par exemple, la ligne 5 pour les niveaux de PIC entre 0.286 et 0.333 correspond à la séquence de décisions suivante :
{𝑛𝑛𝐶𝐶. 1, 𝑛𝑛𝐶𝐶. 2, 𝑛𝑛𝐶𝐶. 3, 𝑛𝑛𝐶𝐶. 4, 𝑛𝑛𝐶𝐶. 5, 𝑛𝑛𝐶𝐶. 6, 𝑛𝑛𝐶𝐶. 7, 𝑛𝑛𝐶𝐶. 8} = {𝑃𝑃2𝐷𝐷, 𝑃𝑃1𝐷𝐷, 𝑃𝑃2𝐷𝐷, 𝑃𝑃1𝐷𝐷, 𝑃𝑃1𝐷𝐷, 𝑃𝑃2𝐷𝐷, 𝑃𝑃2𝐷𝐷, 𝑃𝑃2𝐷𝐷}. Nous nommons cette séquence et les huit autres du Tableau 3 les séquences monotones. Toutefois, il existe plusieurs autres séquences possibles. En fait, mathématiquement, il y a deux choix possibles pour chaque situation, soit P1D ou P2D, et nous avons huit situations. Ainsi, il y a 28= 256 séquences possibles. Les 247
appliquée pour déterminer le niveau de PIC selon que la séquence de décision soit monotone ou non. Les deux sous-sections suivantes présentent ces deux méthodes.
Avant de faire cette présentation, nous mathématisons un peu les séquences. Nous notons avec 𝑦𝑦𝑖𝑖,𝑡𝑡 le résultat
de la décision de l’individu 𝑖𝑖 à la situation 𝑡𝑡 (𝑡𝑡 ∈ {1,2, … , 8}). La variable 𝑦𝑦𝑖𝑖,𝑡𝑡 prend la valeur 1 si l’individu
choisit le fonds qui minimise le risque, nommé le « bon » fonds, et 0 sinon. Nous regardons pour l’individu 𝑖𝑖 la suite de nombre𝑠𝑠 {𝑦𝑦𝑖𝑖,1, 𝑦𝑦𝑖𝑖,2, 𝑦𝑦𝑖𝑖,3, 𝑦𝑦𝑖𝑖,4, 𝑦𝑦𝑖𝑖,5, 𝑦𝑦𝑖𝑖,6, 𝑦𝑦𝑖𝑖,7, 𝑦𝑦𝑖𝑖,8}. Si la suite de 0 et de 1 dans cet ensemble est
croissante, il s’agit d’une séquence monotone. S’il ne s’agit pas d'une suite croissante, il s’agit plutôt d’une séquence non-monotone.
2.3.1. La mesure du niveau de PIC pour les séquences monotones
Pour les séquences monotones, il est relativement direct de trouver le niveau de PIC d’un individu. En effet, si nous trouvons que le niveau de PIC se trouve dans un des neuf intervalles possibles, nous prenons le point milieu entre les deux bornes de l’intervalle. Nous obtenons donc une estimation de son niveau de PIC.
Par exemple, si la séquence est �𝑦𝑦𝑖𝑖,1, 𝑦𝑦𝑖𝑖,2, 𝑦𝑦𝑖𝑖,3, 𝑦𝑦𝑖𝑖,4, 𝑦𝑦𝑖𝑖,5, 𝑦𝑦𝑖𝑖,6, 𝑦𝑦𝑖𝑖,7, 𝑦𝑦𝑖𝑖,8� = {0,0,0,0,0,1,1,1}, nous accordons
0.477 (=(0.511+0.443)/2) pour les traitements avec données arrondies à l’entier et 0.486 (=(0.514+0.458)/2) pour les traitements avec des données arrondies à une décimale près. À une séquence {0,0,0,0,0,0,0,0}, nous accordons 0.881 et 0.861 respectivement, et à {1,1,1,1,1,1,1,1}, 0.024 et 0.092 respectivement.
2.3.2. La mesure du niveau de PIC pour les séquences non-monotones
Les individus peuvent faire des erreurs supplémentaires ou obtenir de bonnes réponses supplémentaires qui provoquent des séquences de résultats de décisions non-monotones. Par exemple, les séquences {0,0,1,1,0,1,1,1} et {0,0,1,0,0,1,1,1} sont non-monotones. Pour déterminer la PIC des répondants ayant des séquences non-monotones, nous regardons le nombre minimal de substitutions dans une séquence pour la rendre monotone. Une substitution consiste en un changement d’un « 1 » par un « 0 » ou vice versa. La distance de Levenshtein est utilisée pour faire ce calcul (Baillargeon (2020)). À partir de la nouvelle séquence monotone, nous pouvons trouver le niveau de PIC.
Dans certains cas, le nombre minimal de substitutions résulte en plus d’une séquence monotone possible. Nous nommons ces séquences les séquences non-monotones ambiguës. Nous prenons alors la moyenne du niveau de PIC le plus faible et le plus élevé parmi les séquences possibles.
En plus, nous développons une mesure qui indique l’intensité de la monotonie d’une séquence sur une échelle de 0.27 à 1. La valeur 1 signifie qu’il s’agit d’une séquence monotone. Après la présentation de la méthode de calcul de l’intensité, nous donnons quelques exemples.
2.3.3. L’évaluation de l’intensité de la monotonie
La méthode d’évaluation développée est basée sur le principe suivant :
- Si un individu choisit le « mauvais » fonds à la situation numéro T (𝑦𝑦𝑖𝑖,𝑇𝑇= 0), il devrait également
choisir le mauvais fonds à une situation numéro Z < T ;
- Si un individu choisit le « bon » fonds à la situation numéro T (𝑦𝑦𝑖𝑖,𝑇𝑇= 1), il devrait également choisir
le bon fonds à une situation numéro Z > T.
La méthode accorde un « pointage » pour chacune des situations, puis à la séquence. Plus le pointage est élevé, moins l’intensité des infractions à la monotonie est importante. Pour une situation donnée, nous regardons soit les situations d’un numéro inférieur ou d’un numéro supérieur selon qu’une mauvaise ou une bonne réponse ait été obtenue à la situation donnée. Puis, nous évaluons à quel point (hauteur) les réponses obtenues dans les autres situations ciblées concordent avec la réponse obtenue à la situation donnée.
Précisément, la méthode d’évaluation est la suivante :
- Étape 1) Pour chaque individu, nous classons en ordre croissant les situations ainsi que les 𝑦𝑦𝑖𝑖,𝑡𝑡 correspondants de façon à avoir la séquence suivante : �𝑦𝑦𝑖𝑖,1, 𝑦𝑦𝑖𝑖,2, 𝑦𝑦𝑖𝑖,3, 𝑦𝑦𝑖𝑖,4, 𝑦𝑦𝑖𝑖,5, 𝑦𝑦𝑖𝑖,6, 𝑦𝑦𝑖𝑖,7, 𝑦𝑦𝑖𝑖,8�.
- Étape 2) Nous calculons le pointage maximal possible pour chacune des situations selon la réponse d’un répondant à la situation 𝑇𝑇 :
o Si 𝑦𝑦𝑖𝑖,𝑇𝑇 est égale à 0, alors nous regardons les situations avec un numéro inférieur à 𝑇𝑇. Le
pointage maximal est de 𝑇𝑇 − 1.
o Si 𝑦𝑦𝑖𝑖,𝑇𝑇 est égale à 1, alors nous regardons les situations avec un numéro supérieur à 𝑇𝑇. Le
pointage maximal est de 8 − 𝑇𝑇.
- Étape 3) Nous calculons le pointage réalisé pour chacune des situations selon la réponse d’un répondant à la situation 𝑇𝑇 :
o Si 𝑦𝑦𝑖𝑖,𝑇𝑇 est égale à 0, alors nous regardons les situations avec un numéro inférieur à 𝑇𝑇. Pour
les situations numéro 1 à 𝑇𝑇 − 1, nous comptons le nombre de fois qu’il y a un 0 dans les 𝑦𝑦𝑖𝑖,𝑠𝑠 ∀ 𝑠𝑠 ∈ {1, … , 𝑇𝑇 − 1}.
o Si 𝑦𝑦𝑖𝑖,𝑇𝑇 est égale à 1, alors nous regardons les situations avec un numéro supérieur à 𝑇𝑇. Pour
les situations numéro 𝑇𝑇 + 1 à 8, nous comptons le nombre de fois qu’il y a un 1 dans les 𝑦𝑦𝑖𝑖,𝑠𝑠 ∀ 𝑠𝑠 ∈ {𝑇𝑇 + 1, … , 8}.
- Étape 4) Nous prenons la somme des pointages maximaux et la somme des pointages réalisés pour toutes les situations de l’individu 𝑖𝑖. Puis, nous divisons les deux nombres obtenus (pointage réalisé / pointage maximal). Il s’agit du pointage de l’individu 𝑖𝑖 de l’intensité de la monotonie de la séquence de ses résultats.
Le maximum de points possibles est de 1 lorsqu’un individu a répondu de façon monotone croissante à travers les huit situations. Il y a neuf séquences possibles, soit celles précédemment présentées au Tableau 3. Le minimum de points possibles est de 12/44 = 0.27. Cela arrive lorsque la suite
�𝑦𝑦𝑖𝑖,1= 1, 𝑦𝑦𝑖𝑖,2 = 1, 𝑦𝑦𝑖𝑖,3 = 1, 𝑦𝑦𝑖𝑖,4= 1, 𝑦𝑦𝑖𝑖,5= 0, 𝑦𝑦𝑖𝑖,6= 0, 𝑦𝑦𝑖𝑖,7 = 0, 𝑦𝑦𝑖𝑖,8 = 0�
est obtenue. Cette séquence est monotone décroissante plutôt que monotone croissante.
2.3.4. Un exemple de calcul de niveau de PIC et d’intensité de la monotonie
Nous présentons maintenant le calcul du niveau de PIC et de l’intensité de la monotonie pour deux séquences non-monotones, soit {0,0,1,0,0,1,1,1} et {1,0,0,0,0,1,0,1}. La séquence non-monotone {0,0,1,0,0,1,1,1} nécessite une seule substitution pour obtenir une séquence monotone. En effet, comme indiqué en gris, le résultat de la situation 3, un « 1 », est substitué par « 0 » et la séquence {0,0,0,0,0,1,1,1} est obtenue. Nous accorderons le niveau de PIC 0.4771 (0.4862) à cette séquence si les données sont arrondies à l’entier (une
décimale).
Ce n’est pas aussi direct pour les séquences non-monotones ambigües telles que la séquence {1,0,0,0,0,1,0,1}. Cette séquence peut être transformée avec un nombre minimal de deux substitutions en deux séquences monotones possibles. En effet, la séquence {1,0,0,0,0,1,0,1} peut devenir la séquence monotone {0,0,0,0,0,1,1,1} avec un niveau de PIC de 0.477 (0.486) ou bien la séquence {0,0,0,0,0,0,0,1} avec un niveau de PIC de 0.6863 (0.6794). Nous utilisons la moyenne du niveau de PIC le plus élevé (pire cas) et le niveau de
PIC le plus faible (meilleur cas) qui sont possibles avec le nombre minimal de substitutions, soit dans notre exemple, 0.5825 (0.5836).
À la Figure 2, nous présentons le pointage de l’intensité de la monotonie pour ces deux exemples.
Nous pouvons utiliser cette mesure comme indication de la fiabilité du niveau de PIC attribuée à une personne. Pour les séquences {0,0,1,0,0,1,1,1} et {1,0,0,0,0,1,0,1}, les intensités de la monotonie accordées sont 0.75 et 0.52. La première séquence ne nécessitait qu’une seule substitution, alors que pour la deuxième, deux substitutions sont nécessaires.
1 Voir Tableau 4 : (0.443 + 0.511)/2 = 0.477. 2 Voir Tableau 4 : (0.458 + 0.514)/2 = 0.486. 3 Voir Tableau 4 : (0.610 + 0.762)/2 = 0.686. 4 Voir Tableau 4 : (0.636 + 0.722)/2 = 0.679. 5 (0.477 + 0.686)/2 = 0.582. 6 (0.486 + 0.679)/2 = 0.583.
Figure 2. Processus de développement de la mesure de l’intensité des séquences non-monotones
A) Séquence : {0,0,1,0,0,1,1,1} Étape 1) Classer en ordre
croissant les numéros de situations
Étape 2) Calcul du pointage maximal par situation
Étape 3) Calcul du pointage réalisé par situation
Numéro de situation 𝑦𝑦𝑖𝑖,𝑡𝑡 Pointage maximal Pointage réalisé
1 0 0 0 2 0 1 1 3 1 5 3 4 0 3 2 5 0 4 3 6 1 2 2 7 1 1 1 8 1 0 0
Étape 4) Somme de chacun des
pointages et division des deux 16 12 Pointage final 0,75
B) Séquence : {1,0,0,0,0,1,0,1}. Étape 1) Classer en ordre
croissant les numéros de situations
Étape 2) Calcul du pointage maximal par situation
Étape 3) Calcul du pointage réalisé par situation
Numéro de situation 𝑦𝑦𝑖𝑖,𝑡𝑡 Pointage maximal Pointage réalisé
1 1 7 2 2 0 1 0 3 0 2 1 4 0 3 2 5 0 4 3 6 1 2 1 7 0 6 4 8 1 0 0
Étape 4) Somme de chacun des
pointages et division des deux 25 13 Pointage final 0,52
Chapitre 3
Expérience
L’expérience en laboratoire comporte deux parties. Dans la première, les répondants prennent part à des mises en situation expérimentale dans lesquels ils doivent prendre des décisions financières. Dans la deuxième partie, les répondants remplissent un questionnaire de leurs caractéristiques socio-économiques, de connaissances, en stratégies d’investissement ainsi qu’un test de numératie. Ces deux parties sont décrites dans les prochaines lignes. Le protocole expérimental et les statistiques descriptives de l’échantillon concluent ce chapitre.
3.1. Les mises en situation expérimentale
Dans la première partie, les répondants font des recommandations de choix de portefeuille à une personne fictive. Le répondant doit conseiller subséquemment 24 personnes fictives. Chacune de ces personnes possède 10 000 $ dans un fonds détenu D et elle souhaite investir un montant supplémentaire de 10 000 $ dans un autre fonds, soit le fonds potentiel P1 ou le fonds potentiel P2. Le répondant doit recommander lequel des fonds potentiels P1 et P2 va fournir le portefeuille le plus diversifié, et donc le moins risqué. Le répondant conseille un autre individu afin que sa propre aversion au risque affecte moins sa recommandation.
L’espérance de rendement du portefeuille est la même que le répondant choisisse le fonds P1 ou le fonds P2. Cette situation d’investissement est exactement celle considérée dans l’exemple du chapitre précédent.7
Comme expliqué dans ce dernier chapitre, la décision ne devrait dépendre uniquement de la variance des deux portefeuilles. Le portefeuille ayant la variance la plus faible est le mieux diversifié.
Pour prendre cette décision, le répondant a accès à certaines informations concernant les fonds. Il possède l’historique de rendement des fonds, ainsi que certaines informations supplémentaires.
3.1.2. La structure des traitements
L’historique de rendement des fonds est présenté sous trois différentes formes que nous appelons les formats
de présentation. Il y a également trois niveaux d’information supplémentaire que nous appelons les niveaux d’information. Le Tableau 5 résume le plan expérimental des neuf traitements résultants.
Les répondants sont attribués aléatoirement à un de ces trois formats de présentation pour toute l’expérience. Il s’agit donc d’un between subjects design pour le format de présentation. Toutefois, chaque répondant fera
7 Comme expliqué dans le chapitre précédent, il y avait des légères différences au niveau de l’espérance de rendement
dû à l’arrondissement. Ainsi, le ratio de Sharpe est utilisé pour déterminer le portefeuille optimal mathématiquement. Toutefois, dans toutes les situations, le portefeuille à variance minimale et à ratio de Sharpe le plus élevé est le même.
face à tous les niveaux d’information. Nous avons donc un within-subjects design pour le niveau d’information. Le within-subjects design permet de mesurer les résultats des répondants dans chacun des niveaux d’information et donc de mieux évaluer l’effet de chacun des niveaux d’information sur les répondants.
Tableau 5. Le plan expérimental
Niveau d’information A) Base : sans
information supplémentaire.
B) Intermédiaire :
corrélation entre les actifs.
Complet : performance,
niveau de risque et corrélation entre les actifs.
Format de présentation
Séparé 1 2 3
Joint 4 5 6
Global 7 8 9
En bref, un répondant ne fait face qu’à trois des neuf traitements, soit 1 à 3, 4 à 6 ou 7 à 9. Dans chacun des traitements, le répondant doit prendre huit décisions, soit recommander un fonds à huit individus fictifs. Dans les neuf traitements, ce sont les mêmes huit situations. Ces situations sont celles présentées au chapitre précédent. Au total, le répondant doit donc prendre 24 décisions (= 3*8). Les prochaines sections développent davantage chacun des traitements, ainsi que d’autres variations incluses dans l’expérience.
3.1.2.1. Le format de présentation
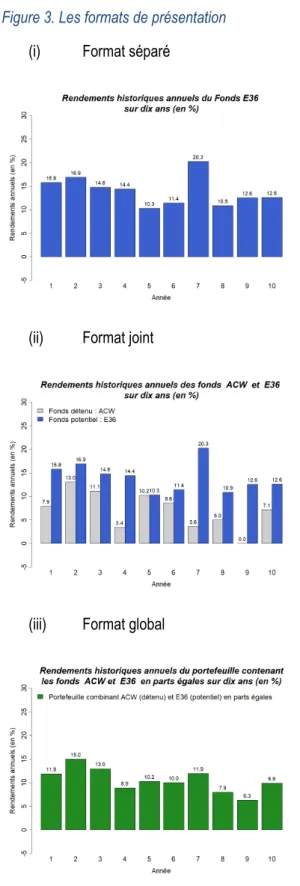
Tout d’abord, le répondant détient l’historique de rendement des trois fonds, soit D, P1 et P2, sur 10 ans sous la forme d’un diagramme à bande. Le diagramme affiche les rendements annuels en fonction de l’année. Pour le diagramme du fonds détenu D, seulement les rendements de ce fonds sont affichés. Pour les fonds potentiels P1 et P2, il y a trois formats de présentation des diagrammes de leurs historiques de rendements ; séparé, joint et global. Le format séparé comporte seulement les rendements annuels du fonds potentiel. Le format joint comporte les rendements du fonds potentiel et ceux du fonds détenu D cote à cote. Le format global présente les rendements du portefeuille combinant le fonds détenu et le fonds potentiel en parts égales. La Figure 3 permet de visualiser ces trois formats de présentation.
Afin que le répondant ne soit pas influencé par une tendance temporelle non-existante, les rendements des deux ou trois dernières années terminent à des niveaux de rendements semblables pour les deux fonds proposés. Nous avons donc permuté certaines données qui ont été obtenues par la génération d’une loi normale multivariée de paramètres empiriques du Tableau 1.
Figure 3. Les formats de présentation
(i) Format séparé
(ii) Format joint
(iii) Format global
Note : Dans ces graphiques, le fonds détenu D correspond au fonds ACW et le fonds potentiel P1 correspond à E36.