A New Experimental Approach for Urban Soundscape Characterization Based on Sound Manipulation : A Pilot Study
Texte intégral
Figure
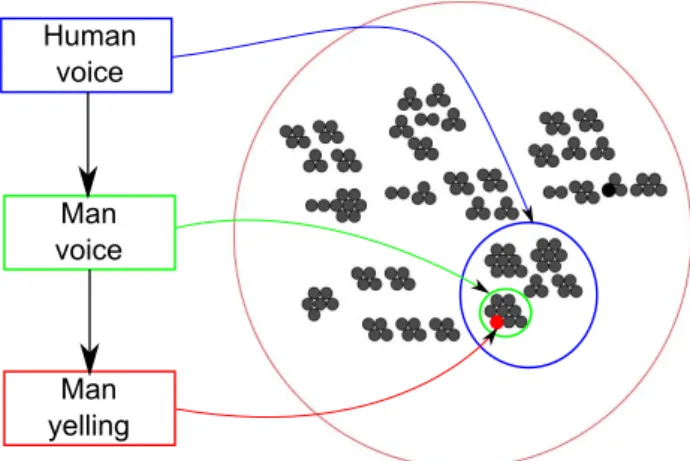
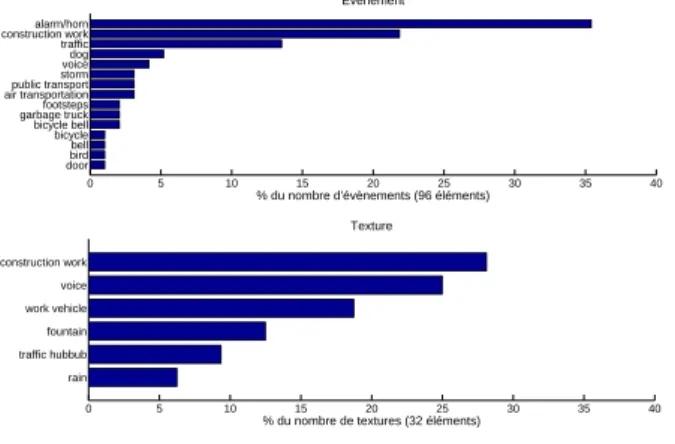
Documents relatifs
Using delay data collected over the Internet, it was shown that the optimal monitoring policy enables to obtain a routing performance almost as good as the one obtained when all
Make the six digit number N by writing your three digit number twice. Try
the same number of 1’s as 2’s and the same number of 0’s as 3’s, and thus there is only one abelian equivalence class.. Before giving the proof, we prove a corollary. The
We describe below first the learning mode, necessary to build the hierarchical gesture models from templates recorded by the user, and second, the performance mode, where the
69 Arguably, if seen in the light of the systematic link between Article 3 ECSC (objectives of the Community) and Articles 5/15 ECSC (duty to give reasons), the public
1 We present a framework (abstract model) for categorizing knowledge-creating learning processes based on process modeling and Nonaka’s (SECI spiral) theory of knowledge
MDS codes with the Simplex code was considered (note that a 51 distance-3 MDS code, even non-linear, is always completely 52 regular [12, Cor. 6]); the result is a two-weight
1 Hundreds of thousands of wholesalers come to buy their goods in Yiwu (China), which is the largest wholesale market in the world and specializes in small commodities.. The broad
