Any correspondence concerning this service should be sent
to the repository administrator:
[email protected]
This is an author’s version published in:
http://oatao.univ-toulouse.fr/25022
To cite this version:
Washha, Mahdi and Qaroush, Aziz and
Mezghani, Manel and Sèdes, Florence Unsupervised Collective-based
Framework for Dynamic Retraining of Supervised Real-Time Spam
Tweets Detection Model. (2019) Expert systems with Applications, 135.
129-152. ISSN 0957-4174
Official URL
DOI :
https://doi.org/10.1016/j.eswa.2019.05.052
Open Archive Toulouse Archive Ouverte
OATAO is an open access repository that collects the work of Toulouse
researchers and makes it freely available over the web where possible
Unsupervise
d
collective-base
d
framework
for
dynamic
retraining
of
supervised
real-time
spam
tweets
detection
model
Mahdi
Washha
a, ∗,
Aziz
Qaroush
b,
Manel
Mezghani
a,
Florence
Sedes
aa IRIT, University of Toulouse, CNRS, INPT, UPS, UT1, UT2J, France
b Department of Electrical and Computer Engineering, Birzeit University, Ramallah, Palestine
Keywords: Twitter Real-time Spam Social spammers Twitter stream
a
b
s
t
r
a
c
t
Twitter is one of the most popular social platforms. It has changed the way of communication and in- formation dissemination through its real-time messaging mechanism. Recently, it has been used by re- searchers and industries as a new source of data for various intelligent systems, such as tweet sentiment analysis and recommendation systems, which require high data quality. However, due to its flexibility and popularity, Twitter has become the main target for spamming activities such as phishing legitimate users or spreading malicious software, which introduces new security issues and waste resources. There- fore, researchers have developed various machine-learning algorithms to reveal Twitter spam. However, as spammers have become smarter and more crafty, the characteristics of the spam tweets are varying over time making these methods inefficient to detect new spammers tricks and strategies. In addition, some of the employed methods (e.g. blacklisting) or spammer features (e.g. graph-based features) are extremely time-consuming, which hinders the ability to detect spammer activities in real-time. In this paper, we introduce a framework to deal with the volatility of the spam contents and new spamming patterns, called the spam drift. The framework combines the strength of unsupervised machine learning approach, which learns from unlabeled tweets, to retrain a real-time supervised tweet-level spam detec- tion model in a batch mode. A set of experiments on a large-scale data set show the effectiveness of the proposed online unsupervised method in adaptively discovers and learns the patterns of new spam activities and achieve stable recall values reaching more than 95%. Although the average spam precision of our method is around 60%, the high spam recall values show the ability of our proposed method in reducing spam drift problems compared to traditional machine learning algorithms.
1. Introduction
The newgreatcharacteristics ofSocial Webthat involveusers asinformationproducershaveexposeddifferentinformation qual-ity (IQ) problems (Agarwal & Yiliyasi, 2010). For example, Twit-ter,whichisthemostpopularmicrobloggingsites,hasareal-time messagingmechanismthatmakesitmorepopularandsuitablefor handlingreal-time publicevents andupdates. In addition,dueto its popularity, social-basedresearchers adoptit asa main source of information in performing their experiments on related re-searchareas(Abascal-Mena,Lema,&Sèdes,2015;Hoang&Mothe, 2016; Mezghani et al., 2015; Mezghani, Zayani, Amous, Péninou, & Sèdes, 2014; Zubiaga, Spina, Amigó,& Gonzalo,2012; Zubiaga, Spina, Fresno, & Martínez-Unanue,2011). However, thesimplicity
∗ Corresponding author.
andflexibilityofusingthesesites,andtheabsenceofanyeffective restrictions on content posting action might be viewed as addi-tionalchallengesforhavingIQissues.Indeed,socialspamcontent, which ispublishedby awell-known kindofill-intentionedusers, so-called social spammers, is one of the most common noises appearing on online social media (OSM) sites and is categorized under IQ problems.Social spammers intensivelypost nonsensical contentssuchasadvertisements,pornmaterials,viruses,malware, andphishingwebsitesindifferentcontexts (e.g.,topics)andinan automated andsystematicway(Benevenuto,Magno,Rodrigues,& Almeida,2010;Washha,Qaroush,&Sèdes,2016).Moreover,Social spammers exploit trending topics and available services or APIs to lunchtheir spammycontentinshortperiods (e.g.,one day)to maximizetheirmonetaryprofitsandspeeduptheirspamming be-havior.Forexample,onTwitter,socialspammersleveragedifferent setofprovidedservicestolaunchtheirspamattacksthrough:URL, Hashtag,andMentionservices.Besidestheseservices,Twitter pro-vides APIsfordevelopers tobe used intheir third-party
applica-E-mail addresses: [email protected] (M. Washha), [email protected] (A. Qaroush), [email protected] (F. Sedes).
tions.Socialspammersexploitthisdistinctiveserviceasan oppor-tunitytoautomatetheirspammingbehavior.
Social spammightbedefinedasa pieceofirrelevant informa-tion; however, this interpretation is quite not accurate. We jus-tifythismisinterpretationthroughthedefinitionofinformation re-trieval(IR)systems(Manning,Raghavan,&Schütze,2008)inwhich the relevancyoftheretrieveddocumentsintheIRsystemsis de-pendent on the input search query. Thus, irrelevant documents with respectto aninput queryare “not” necessary tobe a spam content. Hence, asan additionaldefinition,social spammight be viewed asirrelevant informationthat doesn’t havean interpreta-tioninanycontextaslongastheinputqueryisnotaspam con-tent.SincesocialspamisapureIQproblem,weprojectthe prob-lem onfive IQ dimensionsincludingaccuracy,believability, repu-tation, value-added,andrelevancy.Indeed,spamcontentdoesnot represent real-world data,andthus it has a low degree in accu-racy andbelievabilitydimensions.Also, thereputationofspamis alsolowbecausenormaluserstendtocirculateaccurate informa-tion ingeneral. Finally,spam content doesn’t deliver anybenefit forthe OSMusersinterms ofvalue-addedandrelevancy dimen-sions.AlthoughprojectingsocialspamproblemsonIQ world pro-videsmoreinsightsregardinghandlingtheproblemefficiently; so-cialspammers spendgreateffortstoincreasethedegreeofIQ di-mensions.Therefore,understandingandknowingfactsaboutsocial spammersandtheirbehaviorscancontributetoprovidingeffective solutionsforthesocialspamproblem.Theworkofspamdetection is veryimportant toboth industriesandacademia becausesocial spamisalsoverycriticalinothersocialmediaplatforms.
Social media platforms, including Twitter, has recently been usedasanewdatasourcebyresearcherswhichpotentiallycould havemanyapplicationswithinemergencymanagementandcrisis coordination, makingthe streamingofhigh-quality tweetsa seri-ouschallengewiththecontinuouspresenceofill-intentioned indi-viduals (Imran,Castillo, Diaz,& Vieweg,2015). Amongthese plat-forms,TwitterAPIismoreopenandaccessible,whichmakes Twit-ter more favorabletodevelopers tobuilding toolstoaccess data. In addition,Twitterdatacancontain valuablemetadataincluding geospatial data.Researchandapplicationson Twitterdataranges fromsentimentanalysis, time seriesanalysis,andNetwork analy-sis which canbe exploitedin relatingintelligent systemsapplied in industry, government, and universities (Giachanou & Crestani, 2016). For example,Twitter uses artificialintelligence techniques to determine what tweet recommendations to suggest on users timelines. Also, severalcompanies useTwitterSentimentAnalysis todeveloptheirbusinessstrategies,tofindoutcustomersfeelings towardsproductsorbrand,andtopredictthestockmarket move-ments(Mittal,2011).
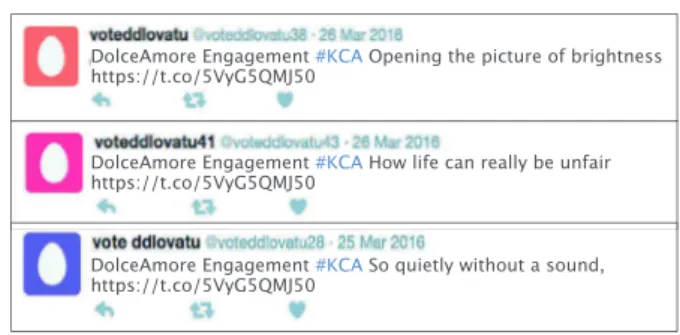
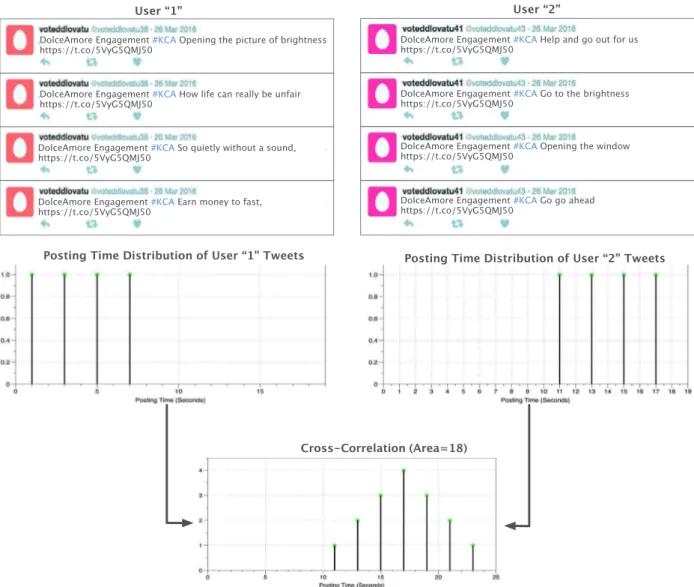
Several methodswere presented in therecent research litera-turefordetecting spammingactivities onTwitter.However, these methods haveseveralweaknessesthat makethem belowthe de-sired level of efficiency indetecting dynamic spammer activities in real-time. These weaknesses could be summarized asfollows: (i) mostofthesemethodsarebasedonsupervisedmachine learn-ingapproachwhichistrainedonstatic,human-annotateddatasets which is very human-labor cost, (ii) reliance on smalland static annotateddatasetstobuildamodeltofollow-upsocialspammers’ patternsandtheirtricks,isnotanefficientsolutionbecauseofthe lack of information in the tweet object itself, information fabri-cation problem, and the variation in social spammers’ behaviors (Chen,Zhang,Xiang, Zhou,&Oliver, 2016;Grier,Thomas, Paxson, &Zhang,2010).Forexample,Fig.1showsasequenceofstreamed spam tweets that attacked the “KCA” event by three correlated spamaccounts(socialspammers).Fromthisexample,various pat-terns might be elicited: (1) same URL used in posting tweets; (2) the sameprefixwas exploitedinfillingscreen-name attribute “voteddlovatu”; and (3) there was a high similarity in the
user-Fig. 1. An example of three correlated spam tweets posted in a consecutive way by three different spam accounts.
nameattributeamongthethreeaccounts,and(iii)previousstudies didn’t provide sufficient analysis and formulations regarding the featuresusedbythespamdetectionmodeltoworkinreal-time.
Inspite of thevolatility of the spamcontent and new spam-ming patterns,we can exploit thehigh correlationamong spam-mers’behaviorwhentheylaunchtheirspamcampaignsfor aggre-gatingandanalyzingcontinuously-streamedtweetsusing unsuper-vised methods to produce annotateddatasets oftweets that can be used for repetitively retraining and updating spam classifica-tionmodels.Inthispaper,weintroduceandexperimenta frame-work that leverages an unsupervised method inproviding, auto-maticallyand periodically, an annotated datasetfor updating su-pervised real-time spam tweet detection model. More precisely, ourframework is mainly composed oftwo main modules:(i) an onlinecollective-basedunsupervisedspamtweetmodel;and(ii)a supervisedreal-timespam tweetdetection model.Thefirst mod-ulecollectsandstoresstreamedtweets.Then,itappliesclustering methods on the storedtweets, followed by a rule-based method that labels each cluster of tweets to provide annotated tweets. The second module is responsible for classifying instantly every streamedtweetintospamornon-spam,withperiodically leverag-ingtheannotateddatasetsthatcomefromthefirstmoduleto re-trainandupdatethecurrentclassificationmodel.Wedemonstrate the effectiveness of the proposed framework through a series of intensive experiments conductedon a dataset streamed from 50 differentTwittertrendingtopicsconsistingofmorethan2million tweets.Comparedto two known methods designedforreal-time spamtweetsdetection,theexperimentalevaluationshowsthe ef-ficiencyof the proposed framework in detecting spam tweets in terms of precision, recall, andF-measure performance measures. Also, it provides the ability to have control of the target quality ofthetweets.Insummary,themaincontributionsofthework in-troducedin thispaper are: (i) providean up-to-date survey and analysisregardingrelatedstudiesorganizedinahierarchyway,(ii) we have collected andlabeled a large Twitter dataset ofaround 2 million Tweets from50 differentTwitter trending topicsto be used in data analysis and experimental evaluation we will also makethisdatasetavailableforothersresearcherstouse,(iii) pro-viding a complete framework based on an online unsupervised learning method to deal withspamdrift problems, by automati-callyandperiodicallypreparingannotatedtrainingdatasetsto re-trainasupervisedtweet-levelspamdetectionmodel,(iv)the pro-posed tweet-level classification model didn’t require pre-training onthepreparedannotateddatasets.Additionally,nohuman inter-ventionisrequired;whichsaves time,cost,andresources.(v) in-troducingan optimized setofdiscriminative,hardly manipulated, andlightweightfeaturesextractedonlyfromthestreamedtweets, withoutrequiringanyexternalinformationfromTwitter’sservers, (vi) compared to the state-of-the-art methods, the experimental evaluationshowstheefficiencyoftheproposed framework in re-ducingtheimpactofspamdriftproblems.
Fig. 2. A taxonomy for Social spam detection methods in Twitter ( Kabakus & Kara, 2017; Washha, Shilleh et al., 2017; Wu, Wen et al., 2017 ).
2. Relatedwork
Twittergivesitsuserstheopportunitytoreportspamaccounts through clicking ”Report: they are posting spam” option that is availableinallaccounts.Whenanaccountisbeingreported, Twit-ter’sadministrators manually review anddeeply analyzethat ac-count tomakelatersuspension decision.However, suchreporting mechanism isinefficient forfighting social spammers, because it needssignificanteffortsfrombothusersandadministratorswhen considering billionsof users. Moreover, many users may provide fakereportsandthusnotallreportsarenecessarytrue.Asan ad-ditionalattemptto address thesocial spamproblem, Twitterhas asetofruleswithpermanentlysuspendingtheaccountsthat vio-latethoserules(Twitter,2016).Unfortunately,socialspammersare smartenoughtobypassTwitter’srules.Forinstance,social spam-mersmaycoordinatemultipleaccountsbydistributingthedesired workload among these accounts to mislead the detection. Con-sequently, Twitter’sapproaches are ineffectivefor reducing spam driftinreal-timespamfiltering.
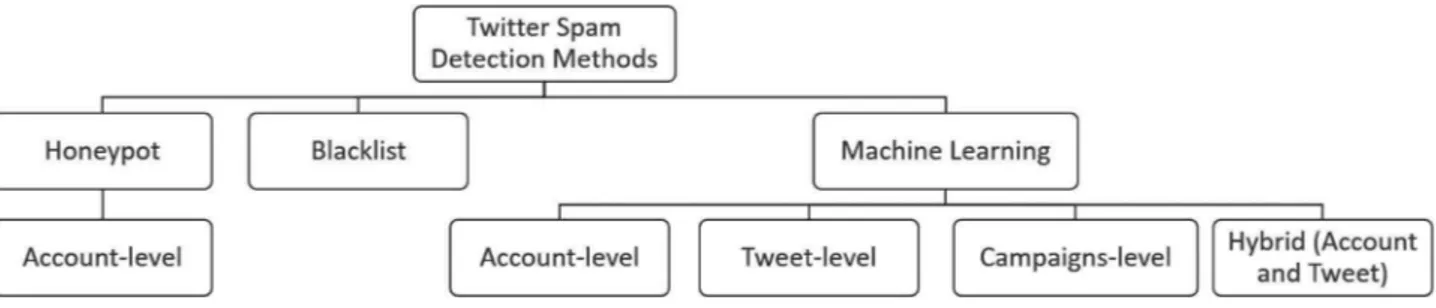
Theshortcomings inTwitter’santi-spammechanismhave mo-tivated researcherstointroduce morerobust methodsto increase dataqualityfortheapplicationsthatuseTwitterasamainsource ofinformation.Afteradeeplookintoawiderangeofscientific re-searchrelatedtothespamdetectionmethodsonTwitter,webuild adetailedtaxonomyforthesemethodsasshowninFig.2,whichis basedondifferentcriteria,including:(i)type ofthedetection ap-proach (Honeypot, Blacklist,and Machine Learning) and(ii) level ofdetection(Tweet,Account,andCampaign) exploitedinthe de-tection methods(Kabakus& Kara,2017;Wu, Wen,Xiang,&Zhou, 2017).
2.1. Honeypotapproach
Traditional supervisedlearning methods requirean initial hu-man labeled dataset which cannot work efficiently with spam driftissues.Alternatively,somespamdiscoveryapproachesrelyon communityreportingmechanismby usingSocialhoneypot. A so-cial honeypot is viewed as an information system resource that can monitor social spammers’ behavior throughlogging their in-formationsuchastheinformationoftheiraccountsandany avail-able content (Lee, Caverlee, & Webb, 2010). Social honeypots are valuabletoolforgatheringandunderstandingspammingactivities, specifically community-based online activities. However, there is no significant difference betweenTwitter’santi-spam mechanism andthesocialhoneypotapproach.Bothofthemneed administra-tive control to make a decisionregardingthe accountsthat have beenfallenintothehoneypottraptoreducethefalsepositiverate, which in turns is time-consuming. Lee et al. (2010) deployed a set ofhoneypots forMySpace andTwitterand they used an up-dated trained classifier to identify spammers. Stringhini, Kruegel, andVigna (2010) deployed 900honeypots inFacebook, MySpace, and Twitterandthey manually identified spammers from all re-quests.
2.2. Blacklistapproach
Mostspammerspromotetheir services/productsbyembedding URL linksinthespamtweet. Therefore,aneffectivewayofspam detectionistodetecttweetscontaining spamlinkswhichrelyon the third party blacklisting techniques. Forexample, Twitter em-ployedGooglesSafeBrowsingAPItopreventmaliciouslinks(Grier et al., 2010). In fact, blacklist methods detect spamby searching the list andit can be applied fordomain level rather than spe-cific URL.Blacklisting techniques are commonlydeployed in web filtering services such as Twitter spam detection or for dataset labeling. In addition, it provides a lightweight approach with a lower cost than existing classifiers (Ma, Saul, Savage, & Voelker, 2011).However,itcannotdealwiththedynamicbehaviorof spam-ming activities and thus it’s not appropriate for real-time detec-tionbecauseinaverageittakes4daysfortheblacklisttoinclude the new spamURLs. In addition,many spammers try to embed-dedshortenedURLs,whichdisabletheperformanceofblacklisting techniques(Wu,Wenetal.,2017).Moreover,someURLsdetection techniques are based on the correlations between the extracted URLs fromseveral tweetsinwhich requiremoretime to retrieve tweetsfromTwitterservers(Lee&Kim,2013).
2.3. Machinelearningapproach
To automate the task ofspam detection, most of the Twitter spammingdetectionmethodsarebasedonmachinelearning tech-niques.However,themaindifferencebetweenthesemethodsisin theselectedfeaturesalongwiththeirformulations.Infact,almost everypaperinthesemethodsintroduceagroupofdistinctfeatures andapplyasetofwell-knownmachinelearningmethodstodetect spamming activities. Features used by machine learning methods forTwitterspamdetectionarevaryinganddifferintermsoftheir level (e.g account, tweet, andcampaign), formulations, powerful-ness,easeofmanipulation,andtheirsuitabilityforreal-time detec-tion.AuthorsinSedhaiandSun(2017a)andYang,Harkreader,and Gu (2013) provide a comprehensivestudy andanalysisregarding hashtag,tweet,account,graph,andtimingfeatureswithrespectto theirperformanceinTwitterspamdetection.
Selection ofthemachinelearning method(e.g.supervised, un-supervised,orsemi-supervised)ismainlybasedontheavailability of annotated dataset. In fact, mostof the spam detection meth-odshaveemployedsupervisedmachinelearningalgorithms,which are trained on one or more types of spam features, that are distributedbetweentweet-basedfeatures, account-basedfeatures, and campaign-based features. Account-based methods are based on the features extracted from a Twitter account such as user name, creation date, location, number of followings, number of tweets,numberofmentions,numberofmoments,numberoflikes, andnumberofretweets.TheworksintroducedinBenevenutoetal. (2010), Washha et al. (2016), Wu, Liu, Zhang, and Xiang (2017), Wang (2010), McCord andChuah (2011), Stringhini et al.(2010), Medaetal.(2016),Bara,Fung,andDinh(2015),Hu,Tang,andLiu
(2014) andHu,Tang,Zhang,andLiu(2013)havebeenfocusedon extractingfeatures(e.g.,thenumberoffriends,numberof follow-ers, similarity betweentweets,andratioofURLs intweets) from users’ accounts. In more dedicated studies, the works presented in Cao andCaverlee (2015) and Wang andPu (2015) have iden-tified the spam URLs throughanalyzing the behavior of shorten-ing URLssuchasthenumberofclicksandthelengthofthe redi-rectionchain.FeaturesextractedfromasingleTwitteraccountare simple andlightweight. However, they are easily manipulated by social spammers usinga group ofbots.In addition,account-level detectionislesseffectiveforspammerswhomayactaslegitimate users by posting nonspamcontent regularly. Thisbehavior moti-vated researchers to leverage graphtheory to extract more com-plexfeaturesfromasetofTwitteraccounts.Forinstance,the stud-iespresentedinYang,Harkreader,andGu(2011),Yang,Harkreader, Zhang, Shin,andGu(2012) andAlmaatouqetal.(2016) have ex-amined therelationamong usersthrough usingsome graph the-ories andmetrics to measure three features, including node be-tweenness,localclustering,andbi-directionalrelationratio. Lever-aging such complex features gives highspam accounts detection rate;however,theyarenotsuitableforreal-timeTwitter-based ap-plications, because ofthe huge volume of data that must be re-trievedfromTwitter’sserversaswellasgraphoperations,that re-quireexponentialtime.
Tweet-level spam detection is a lightweight method that re-quires instant analysis and they are based on the features ex-tracted from tweets such as tweet contents (e.g.text and links), sender, mentions,hashtags, links,number ofretweets,numberof replays, send dates, location (Kabakus & Kara, 2017; Wu, Wen etal.,2017).Tweet-levelspamdetectionisessentialtofightagainst spamming activities at a more fine-grained level. Most of these methodsarebasedonusinglanguagemodels(e.gTF-IDFand bag-of-words) to compute the similarity between a tweet and other tweetsinthesametrendingtopic,orbasedondetectingmalicious URLs embedded inthe tweets(Lee& Kim, 2012; Martinez-Romo & Araujo, 2013;Thomas, Grier, Ma, Paxson,& Song, 2011). How-ever,thesemethodsmaynotbesuitableforreal-timefiltering be-causeitneedsthetweetsthathavebeenpostedonthesametopic fromTwitter’sservers.Moreover,thetraditionalwaystofilterURLs are basedonblacklisting andHTMLparsingwhichcannot handle shortenedURLs,andtakesignificanttimetoupdateblacklist.Other tweet features like sender, mentions, hashtags, links, number of retweets, numberof replays, send dates, andlocation are simple andlightweight.
In campaign-level, researchers treated spam problem from a collective perspective view. Therefore, instead of detecting spam tweets one by one, they clustered spaminto a set ofgroups ac-cording to their similarity on tweet contents or URLs (Wu, Wen et al., 2017). Chu, Widjaja, and Wang (2012) clustered a set of desired accounts according to the URLs available in the posted tweets. Then, a defined set of features from the accounts clus-teredisdesignedtobuilda binaryclassificationmodelusing ma-chine learning algorithms to identify spamcampaign. Chu, Gian-vecchio, Wang, and Jajodia (2012) have proposed a classification model tocapturethedifference betweenbot,human,andcyborg with taking into consideration the content of tweets and spam-ming behavior. Campaign-based methods are not appropriate for real-time filtering due tothe high volume ofdata required from Twitter’sservers.Inaddition,some campaignsareclassified man-ually whichisextremely time-consuming(Thomas, Grier,Song,& Paxson, 2011). Finally, in hybrid-based methods, researchers use a combination of features extracted from Twitter accounts and tweets contents in order to provide more robust spam detection method (Chen, Zhang,Chen, Xiang, & Zhou, 2015;Chu, Gianvec-chio,Wang,&Jajodia,2010;Inuwa-Dutse,Liptrott,&Korkontzelos, 2018;Wang,Zubiaga,Liakata,&Procter,2015).However,using
hy-bridfeatures, requirescarefulfeatures selection to makea trade-off between detection rate anddetection time, in addition to the neededinformationfromTwitterserverstocomputefeatures.
In general, supervised machine learning methods that have beenusedtodetectspamtweetsinreal-timerequireasetof dis-criminative,lightweight,andnoteasymanipulatedfeatures,in ad-dition to the existence ofan annotated datasets for the training phase(Benevenutoetal.,2010;Chen,Zhang,Xieetal.,2015).Since tweetobjecthasalimitedamountofcontentorinformation,afew numbersofthefeaturesdescribed inTable1areadoptedin real-timespamtweet detection.Moreover,themajor drawbackofthis approach is in the process of training classifiers, which is based onstaticdatasetsthat reflectcurrentspammerstrategies without payingattentiontothe spamdriftissues.Toovercomethis prob-lem, we need to retrain classifiers periodically based on up-to-datedatasetsthatcatchthenewspammingstrategies(Chenetal., 2017). Authors in Chen,Zhang, Xiang, andZhou (2015) proposed asymmetric self-learningmethodto update classifier periodically. Theyaddedthe incomingclassifiedtweets,which were classified usingan initial trainedmodel tothe training dataset.Then, after adefinedperiod(e.g.,1dayor2days),theclassificationmodelis retrainedusingtheoldtrainingtweetsalongwiththerecent clas-sifiedtweets.However, thisapproachiscompletelydependenton theinitialtrainedmodel,andthereisnoguaranteeaboutits per-formance in effectivelydetecting newsocial spammers’ patterns. Similar approach are proposed in Lee et al. (2010). The authors employed honeypots as an information resource to monitor and collect spammers behaviorsand logtheir information.Theypass detectedcandidatespamprofilestothetrainedclassifierandthen returnback profiles that are classifiedas a spammer to periodi-callyupdateclassifiers.However,theinitialdatasetusedfor train-ing classifier is small. In addition, the approach includes human inspectorsforvalidatingthequality ofthe extractedspam candi-dates.SurendraandAixin(Sedhai&Sun,2017b)proposeda semi-supervisedspam detection methodconsisting oftwo main mod-ules:four-level spam tweet-based detection module which oper-ates in real-time mode andan updating module which operates in batch mode. After finding the confidently labeled tweets, the detectionmoduleincludingblacklisted,near-duplicate,hamtweet detector,andtweetclassification modelsare updated accordingly. The proposed detectoruses tweet-based features which are suit-ableforreal-timedetection.However,somediscriminativefeatures thatcanbederivedfromtheuseraccountandhistoricaltweetsof theusersaremissing.Inaddition,amongfourdetectors,the classi-ficationmodelcontributesto87%oftweetslabeling,forwhichthe performanceisdependentontheinitialdataset.Chaoet.al.(Chen et al., 2017) proposed a scheme called Lfun that can automati-callydetectchangedspamtweetsfromnewunlabeledtweetsand incorporatetheminto classifiersretraining process.The proposed method employed 12 lightweight features and uses two compo-nents to extract changed spam tweets including learn from de-tectedspamtweetsandlearn fromhumanlabeling.However, the performanceoftheschemeismainlydependentonthefirst com-ponentwhichtrainedonaninitializedlabeleddataset.Inaddition, humanlabelingistimeconsuming.
Tosumup,theabovestudieshavethefollowingweaknesses:(i) theyassumethatallpre-information(e.g.,ablacklistofspamming domainsandannotateddatasetortrainedclassificationmodels)to labeltweetsexist,(ii)mostofthemarebasedonupdatingdataset using the output of the classifier which can’t guarantee to learn newspammingactivities,sincetheclassifieristrainedonaninitial dataset,and(iii)someofthemare missingimportantlightweight account-level features, and(iv) some of them requirehuman in-spectors for validating the quality of the detector. Unlike these studies,our proposed framework havethe followingstrengthens: (i) it didn’t requirepre-informationlike e.g., a blacklistof
spam-Table 1
A description of content and user features exploited in spam tweets detection, with classifying them based on their suitability for real-time filtering.
Feature Name Description Real-Time Suitability
Content Features
Number of Hashtags The number of words that begin by “#” symbol ( Benevenuto et al., 2010; Chen, Zhang, Xiang et al., 2015; Chen, Zhang, Xie et al., 2015; Martinez-Romo & Araujo, 2013 ).
√ Number of URLs The number of links, including shorten links ( Benevenuto et al., 2010; Chen, Zhang, Xiang et al., 2015;
Chen, Zhang, Xie et al., 2015; Martinez-Romo & Araujo, 2013 ).
√ Number of Words The number of words written in tweet where white-space is used a separator among words
( Benevenuto et al., 2010; Chen, Zhang, Xiang et al., 2015; Chen, Zhang, Xie et al., 2015; Martinez-Romo & Araujo, 2013 ).
√
Number of Characters The number of characters used in creating the tweet, including numbers and symbols ( Benevenuto et al., 2010; Chen, Zhang, Xiang et al., 2015; Chen, Zhang, Xie et al., 2015; Martinez-Romo & Araujo, 2013 ).
√
Number of Mentions The number of accounts mentioned in the tweet through looking for words starting by “@”
( Benevenuto et al., 2010; Chen, Zhang, Xiang et al., 2015; Chen, Zhang, Xie et al., 2015; Martinez-Romo & Araujo, 2013 ).
√
Number of Retweets The number of retweets that the tweet has gained ( Benevenuto et al., 2010 ). √ Number of Spam Words The number of spam words that exist in the tweet according to a define list of spam words
( Benevenuto et al., 2010; Martinez-Romo & Araujo, 2013 ).
√ Number of Trending Topics The number of words that represent trending topics circulated in Twitter ( Benevenuto et al., 2010;
Martinez-Romo & Araujo, 2013 ).
√ Number of hashtags per words The ratio of the number of hashtags to the number of words in the tweet ( Benevenuto et al., 2010 ). √ Number of URLs per Words The ratio of the number of URLs to the number of words in the tweet ( Benevenuto et al., 2010 ). √ Number of Numeric Characters The number of numeric digits in the tweet ( Benevenuto et al., 2010; Chen, Zhang, Xiang et al., 2015;
Chen, Zhang, Xie et al., 2015; Martinez-Romo & Araujo, 2013 ).
√ Number of Replies The number of times that the tweet has been replied by other users ( Benevenuto et al., 2010;
Martinez-Romo & Araujo, 2013 ).
√ Number of Favourites The number of accounts/users that have favorited the tweet ( Chen, Zhang, Xiang et al., 2015; Chen,
Zhang, Xie et al., 2015 ).
√ Tweet and URL Page Title Divergence The Kullback Leibler Divergence value computed between the text of the tweet and the title of the
URL website, if any ( Martinez-Romo & Araujo, 2013 ).
✗
Tweet and Topic Content Divergence The average value of the Kullback Leibler Divergence values computed between each tweet of the considered tweet topic and the text of the considered tweet, if any ( Martinez-Romo & Araujo, 2013 ).
✗
Tweet and User’s Tweets Divergence The average value of the Kullback Leibler Divergence values computed between each tweet posted by the tweet user and the considered tweet content ( Martinez-Romo & Araujo, 2013 ).
✗
User Features
Number of Followings The number of accounts/users that the user of the tweet follows ( Chen, Zhang, Xiang et al., 2015; Chen, Zhang, Xie et al., 2015 ).
√ Number of Lists The number of accounts/users that has listed the user of the tweet ( Chen, Zhang, Xiang et al., 2015;
Chen, Zhang, Xie et al., 2015 ).
√ Number of Followers The number of accounts/users that follow the user of the tweet ( Chen, Zhang, Xiang et al., 2015; Chen,
Zhang, Xie et al., 2015 ).
√ Account Age The number of milliseconds spent since the creation date of the account of the tweet ( Chen, Zhang,
Xiang et al., 2015; Chen, Zhang, Xie et al., 2015 ).
√ Number of Tweets The number of tweets that the user of the tweet has tweeted ( Chen, Zhang, Xiang et al., 2015; Chen,
Zhang, Xie et al., 2015 ).
√
ming domains andtrainedclassifier, (ii)our proposed framework is capable of continuously updating itself by using unsupervised learningmethod,whichisbasedonasetofdiscriminativeaccount andtweet-levelfeatureswithoutanyhumanintervention,and(iii) introducinganoptimizedsetofdiscriminative,andlightweight ac-count and tweet-level features extractedfrom only thestreamed tweets,withoutrequiringanyexternalinformationfromTwitter’s servers.
3. Problemdefinitionandformalization
AnyTwitterstreamcanberepresentedasafinitesetof chrono-logicallysortedtweets,definedasSt=
{
T1 ,T2 ,...,Tt−1,Tt}
, where t∈N+ representsthenumberofsecondssincestartingthe stream-ing process, and T1 and Tt are the first and latest tweets thathasbeenstreamed.Indeed,theTweetobjectcontainsdifferent at-tributes related to the tweet content andits user. Therefore, we represent the tweet element T• by a 6-tuple of attributes, T•=
(
User,#Retweets,#Replies,#Favourites,Text,Time),where#Retweetsrepresents the number of retweets that the tweet has gained, #Replies is the number of comments performed as a reply on the tweet, #Favourites isthe numberof likes that thetweet has,
Time∈Z≥0 is theposting date ofthe tweet in secondstime unit
computedsinceJanuary1,1970,00:00:00GMT,whiletheTextand
Userattributesaredefinedasfollows:
• Text:Thetextualcontentofthetweetisrepresentedasafinite
set oforderedwords, Text=
{
w1 ,w2 ,...}
.This setofwords is extracted by segmenting the tweet content usingthe whites-paceseparator.Thewordelementw•mightbeahashtag,URL,user’saccountmentioned,andmore.
• User: Twitter provides simple meta-data about the user who
posted a tweet. Hence, we further represent the user object by7-tuple ofattributesdefinedas,User=
(
SN,UN,UA,#Tweets, #Followers,#Followees,#Lists),where#Tweetsisthenumberof tweets that the userhas posted on his account, #Followersis thenumberofaccountsthat followtheuser,#Followeesisthe numberofaccountsthattheuserfollows,#Listsisthenumber ofaccountsthatlisttheuser.Therestoftheattributes,SN,UN, UA,arefurtherdefinedasfollows:– Username (UN): Twitter allows users to name their ac-countswithamaximumlength of20characters. Userscan use whitespace, symbols, special characters, and numeric numbersinfillingtheirusernameattribute.Thisfieldisnot necessary for being unique and thus the users can name their accounts by already used names. We represent this
attribute as a set of ordered characters, defined as UN=
{
d1 ,...,di}
,whered•∈{PrintableCharacters}1 isthecharac-terandi∈Z≥0 isthepositioninsidetheusernamestring. – ScreenName (SN):Thisattribute isa mandatory field and
itmustbe filledatthecreation timeofthe account.Users must choose a unique name that hasn’t been used previ-ously by other users, witha maximum length of 16 char-acters. Twitter also restricts the space of allowed charac-ters to includeonly the alphabetical letters, numbers, and “_” character. Similar to the username attribute, we rep-resent this field as an ordered set of characters, defined asUN=
{
d1 ,...,di}
,where d–∈{PrintableCharacters} is thecharacter and i∈Z≥0 is the position inside the username string.
– UserAge(UA):Whenausercreatesan accountonTwitter, the creation date ofthe account isregistered on Twitter’s servers without providing any permissionsto modify it in thefuture.Weexploitthecreationdate,asanaccessibleand available propertyin theuser’sobject,to compute theage oftheaccount.Formally,we calculatetheageindaystime unitthroughsubtractingthecurrenttimefromthecreation dateoftheaccount,defineasUA=Timenow−T imecreation
864 ∗10 5 ,where Timenow,Timecreation∈Z≥0 arenumberofmilliseconds
com-putedsinceJanuary1,1970,00:00:00GMT.
According to this representation, the problem of real-time tweet-level spam detection can be defined as follows; Given a tweetstreamedattimet,Tt,andasetofalreadystreamedtweets, St−1,ourproblemistopredictwhetherthetweetTtisaspamor
non-spam, withleveragingonlythe available informationinboth
TtandthesetofalreadystreamedtweetsSt−1.Moreformally,we
aimatdesigningamodel,F:x→
{
spam,non− Spam}
,whichtakes afeaturevectorofthestreamedtweetT•asaninputandpredictsitsclasslabelasanoutput.
4. Datasetdescriptionandgroundtruth
A dataset with ground-truth is required to train and evalu-ate a supervised machine learning spam detection methods. In fact, most ofthe researchers use their own dataset andsome of them didn’t make it publicly available (Benevenuto et al., 2010; Martinez-Romo & Araujo, 2013). In addition, forprivacy reasons, when social-network-based researchers publish a dataset, they only provide the target object IDs(e.g., tweets and accounts) to retrievethemfromserversofthedesiredsocialnetwork.However, providing the IDs ofthe spam tweetsor accountsis not enough because Twittermightalreadyhavesuspended thecorresponding accountsandthusnothingtoretrievefromtheservers.
Themostchallenging taskincreatingalargedatasetisthe an-notationprocess.Currently,researchersareusingfourwaysto gen-erate groundtruth, including: manual inspection, blacklists, sus-pended accounts, andclustering (Chen, Zhang,Chen etal., 2015; Hu et al., 2014; Hu et al., 2013; Sedhai & Sun, 2017a; Thomas, Grier,Songetal.,2011;Wu,Liuetal.,2017).Manualinspectionis costly, time-consuming,andsome timessubjective.Blacklists(e.g. googlesafebrowsing)areaneffectiveautomatedmethod.However, notallspamtweetscontainURLsandalsosomespamtweets con-tain URLs that maydirectto legitimatecontent. Therefore, Black-list canbe appliedonlyfortweetscontaining URLs.On theother hand, suspended accounts are also automated methodand work by labelingallofthesuspendedaccountstweetsasspam.Infact, Twitterdecidestosuspendanaccountifitengagingspamming ac-tivitiesincludingpostingmisleading,deceptive,ormaliciouslinks.2
1http://web.itu.edu.tr/sgunduz/courses/mikroisl/ascii.html . 2https://help.twitter.com/en/rules- and- policies/twitter- rules .
However, sometimes,suspended accountsmay contain non-spam tweets.Finally,inclusteringmethods (e.g.near-duplicate and ex-pectationmaximization),alltweetsinthesameclusterwillbe an-notatedwiththesamelabel. Upto ourknowledge,therearetwo publiclyavailable datasetssuitable fortweet-level spamdetection (Chen, Zhang, Chen et al., 2015; Sedhai & Sun, 2015). In Chen, Zhang, Chen etal. (2015) the authors used the blacklist method toannotate collectedtweets,andthustheyareconcernedonlyon tweetscontainingURLs.Ontheotherhand,authorsinSedhaiand Sun(2015)usedfourmainstagesintheannotationprocess. How-ever,duetothewaythetweetswerecollected,thecollectiondoes notcontainfulluserprofiles,whichlimitsextractingaccount-level features. In addition, the data set was collected based on popu-larhashtags,notonuserbasis, whichdoesnot guaranteeto con-tain all tweetsof anyuser. Therefore,since ourmethodology: (i) useshybridfeatures(tweet-levelandaccount-level)totraina real-time spam detection model, (ii) deals with all tweets not only the tweetshaving URLs, and (iii)uses tweets writingstyle simi-larityandtweetspostingbehaviorsimilarityfeaturestolabelnew streamedtweetwhichrequireretrievingusertweets,bothdatasets arenotsuitableforourproposedapproach.Asaresult,wedecided tocollectourowndatasetandgenerateground-truth.
Building large tweet dataset consists of two main stages, the collectionstage,andtheannotationstage.Forthecollectionstage, we have developed a crawler that uses the Twitter Streaming APIs. Actually, real-time spam detection methods are applied on astreamoftweetsrelatedtoone ormoreentities(hashtag, user-name,andURL).Therefore,tosimulateandinvestigatesuchcases, we havechosen the hashtag asa target entitysince mostof the researches and applications stream the tweets from a particular hashtag ortopic(Chellal, Boughanem, & Dousset, 2016;Hoang& Mothe,2016;Sedhai& Sun,2015; Zubiaga etal., 2012). We have launched our crawler for four months, started since 1/Jan/2015, where 2.1 million of relevant tweets from 50 trending hashtags havebeencollectedandalsostoredbasedontheirpostingtime.In theannotationstage,sincemanuallabelingisexpensiveand black-listsareused onlyfortweetscontaining URLs,we haveleveraged the suspended accounts method which is widely used in social spamdetectiontoannotate ourcollected tweets(Huetal., 2014; Huetal.,2013;Thomas,Grier,Songetal.,2011;Washha,Qaroush, Mezghani,&Sèdes,2017a;Wu,Liuetal.,2017).Theprocesschecks whethertheuserofeachtweetwassuspendedbyTwitter.Incase ofsuspension, boththe userandhis tweetsarelabeled asspam. We have performed this process for one year after crawling the tweetsin orderto have a large numberof spamusers andtheir tweets.
In total, asreported in Table 2, we havefound about 78,000 users(accounts)labeledassocialspammer,and881,000legitimate users. Also, the number of spam tweets existing in our dataset is more than 208,000 tweets, forming about 10% of 2.1 million tweets.Thenumberoftweetspostedisobviouslygreaterthanthe number of tweets retrieved since the former number represents the tweets that have been streamed into the hashtags selected, while thelatter numbercorresponds tothe ultimate tweetsthat havebeenpostedsincethecreationoftheaccounts.Asthedataset isnotbalancedattheclasslevel,wecomputethenormalized ver-sionof the statistics per 100 usersto have a morefair compari-son between social spammers and legitimate users. The normal-izedversionofthenumberofURLsshowsanobviousmisusingof URLs inspreadingsocial spammers’ content,compared tothe le-gitimateusers.Itis expectedthat thenumberofverifiedusers is zerosince having a verifiedaccount requires to contactTwitter’s administrators;thusthespamaccountsaretoodifficulttobe veri-fied.Anotherinterestingpossibleconclusionisthatthedistribution ofspamtweetsisnotnecessarytobeuniform,meaningthatsocial spammersmayhavesome hiddenpreferencesforselecting
hash-Table 2
Distribution of different statistics for social spammers (spam accounts) and legitimate users (non-spam accounts) existing in our dataset.
Social spammers Legitimate users
Statistic Name Number Percentage Number (per 100 users) Percentage Number Percentage Number (per 100 users) Percentage
Number of users 78,074 8.1% – – 881,207 91.9% – –
Number of geo-enabled users 5986 1.8% 8 18.2% 316,617 98.2% 36 81.8%
Number of verified users 0 0.0% 0 0.0% 2978 100% 1 100%
Number of users’ followers 78,143,567 2.9% 100,089 25.8% 2,526,736,521 97.1% 286,735 74.2%
Number of users’ followees 50,839,084 3.6% 651,165 81.5% 1,302,269,081 96.4% 147,782 18.5%
Number of tweets posted 944,566,070 5.4% 1,209,834 39.1% 16,604,525,699 94.6% 1,884,293 60.9%
Number of tweets retrieved 208,546 10.1% 267 55.8% 1,857,479 89.9% 211 44.1%
Number of retweeted tweets 80,773 9.1% 104 53.3% 808,263 90.9% 92 46.6%
Number of replied tweets 855 2.4% 1 33.3% 24,895 97.6% 3 66.6%
Number of URLs 127,655 1.9% 163 55.1% 1,166,666 98.1% 133 44.9%
Table 3
Distribution of 50,0 0 0 spam and non-spam tweets streamed into the top 20 hashtags existing in our dataset, showing an obvious variation in the number of spam tweets of 20 hashtags.
Non-spam tweets Spam tweets Non-spam tweets Spam tweets
Topic name Number Percentage Number Percentage Topic name Number Percentage Number Percentage
#iHeartAwards 39,478 78.9% 10,522 21.1% #Harmonizers 38,844 77.7% 11,156 22.3% #KCA 38,992 77.9% 11,008 22.1% #quote 46,076 92.2% 3924 7.8% #BestFanArmy 40,982 81.2% 9018 18.8% #NowPlaying 47,841 95.7% 2159 4.3% #TreCru 49,541 99.1% 459 0.9% #BTS 48,798 97.6% 1202 2.4% #Periscope 48,831 97.7% 1169 2.3% #VoteMaineFPP 47,756 95.5% 2244 4.5% #SoundCloud 46,709 93.4% 3291 6.6% #gameinsight 45,492 90.9% 4508 9.1% #np 47,150 94.3% 2850 6.7% #VoteKathrynFPP 47,427 94.8% 2573 5.2% #RT 36,922 73.8% 13,078 26.2% #android 46,162 92.3% 3838 7.7% #5SOSFam 41,476 82.9% 8524 17.2% #love 46,802 93.6% 3198 6.4% #Directioners 44,704 89.4% 5296 10.6% #giveaway 47,602 95.2% 2398 4.8%
tags. Moreprecisely, Table3 reportsthedistribution ofthespam andnon-spamtweetsstreamedintotop20hashtagsandshowsa clearvariationinthenumberofspamtweets.Thestreamofsome hashtags such as#RT hasbeenintensively polluted withan esti-mated ratio of1 spamtweet to 3non-spam tweets,while there arehashtagsthathaven’tbeenpollutedtoomuchlike#TreCru. In-deed,thereisnoclearinterpretationbehindthishighvariationin the distribution of spamtweets; however,the importance of the hashtag,andhowlongtimethehashtaghasbeentrendingarethe mostpossiblereasons.
5. Unsupervisedcollective-basedandreal-timespamfiltering model
5.1. Modeldesign:anoverview
Supervisedlearningmethodsaretheclassicalapproachadopted in literature forbuildingspamtweets detectionmodels. As com-monlyknowninthemachine learningfield,applyingthese meth-ods need an annotated dataset. Unfortunately, having such data is often very expensive in terms of annotation time, and/or hu-man resources. In addition, social spamclassification models re-quirecontinuous adaptionusingnew training datasets to follow-up newsocialspammers’ patternsandbehaviors. Thus,obtaining astatictrainingdatasettotrainaclassificationmodelisnotan ef-ficientsolutionatall.
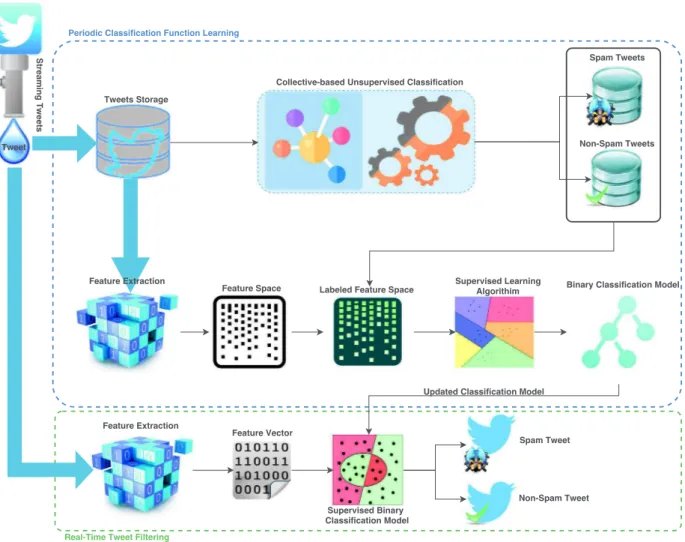
Therefore, we propose a design of an online collective-based spamtweetsclassificationframeworkthat utilizesthegreat bene-fitsofunsupervisedmachinelearningmethods,toperiodicallyand automaticallyprovidean annotateddatasetbywhichupdated su-pervised classification models can be produced. The model em-ploys thecorrelation betweensocial spammers’tweetsin ashort period to predictspamming behavior. As described inFig. 3,our frameworkconsistsoftwomainmodules:(i)real-timetweet filter-ingmodel;and(ii)periodicclassificationmodellearning.Thefirst modulepreparesafeaturevectorforastreamedtweetthrough
ex-tractingasetofpredefinedlightfeaturesandthenpassesthe vec-tor toan alreadylearnedclassification modeltopredict theclass labelofthestreamedtweet.Thesecondmodule,whichisthecore of the framework, stores incrementally thestreamed tweetsin a storage component (e.g., database) andthen frequently creates a newlylabeledtrainingdatasetusingunsupervisedmethodsoncea certainnumberofnewtweetsisstoredinthestoragecomponent. Upon satisfying thecondition of streamed tweets,a newfeature spaceispreparedusingallannotatedtweetsinthestorage compo-nent.Finally,aclassicalsupervisedlearningmethod(e.g.,Random Forest, SVM, J48) is applied to the new labeled feature spaceto build abinaryclassificationmodeltoreplacethecurrentclassifier model.
5.2. Collective-basedunsupervisedpredictivemodel
Leveraging Twitter REST APIs to retrieve more information about users of the streamed tweets is the best solution to pre-ciselylabeleach tweetasspamornot.However,theimpractically ofthisapproachintermsoftime bringsseriouschallengesto de-signanefficientmethodsuitableforprocessinglargescale (some-timesendless)ofstreamedtweets.Therefore,insteadofinspecting eachtweetindividually,weovercomethisshortcomingby propos-ing an automatic approach that inspects the correlation between spamaccountsandtheirtweetsatdifferentlevelsusing unsuper-vised clustering methods. The design of the proposed approach comesinfive-stagesasillustratedthroughanexampleinFig.4.For a givenset ofstreamed tweets,the first stage extracts the users who posted the tweets streamed. The second stage clusters the userssetbasedontheageofeachuser’saccount.Inthenextstage, foreachgeneratedcluster,adefinednumberofcommunitiesis de-tectedthroughanoptimizationprocess.Inthefourthstage,we ex-tracthand-designedfeaturesforeachcommunityusingonlyusers’ tweetsandaccountsinformation.Thelast stage makesa decision abouteachcommunityusingasimplediscriminativefeature-based
Fig. 3. A diagram showing the flow and the steps of the two main components in our framework: (i) periodic classification function learning; (ii) and real-time tweet detection or filtering.
Fig. 4. An example describing the functionality of the 5-stage unsupervised classification: (i) user set extraction; (ii) account age clustering; (iii) community detection; (iv) community-based features extraction; (v) and community-based classification.
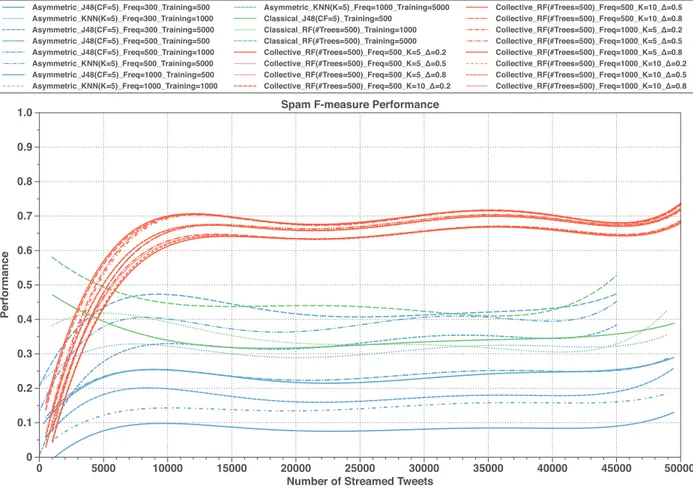
Fig. 5. CDF of 12 tweet features drawn for a randomly selected 10 days of streaming spam and non-spam tweets.
classificationmodelthatlabelseachtweetofspamcommunitiesas spamtweets.
Stage1:UsersSetExtraction.Wedesigntheclusteringandthe communitydetection stagesbasedon leveragingthe users’ infor-mation that isavailable inthestreamed tweets.Formally,forthe lateststreamedtweetsset,St,theuniquesetofusersisdefinedas Users=
{
T.User|
T∈St}
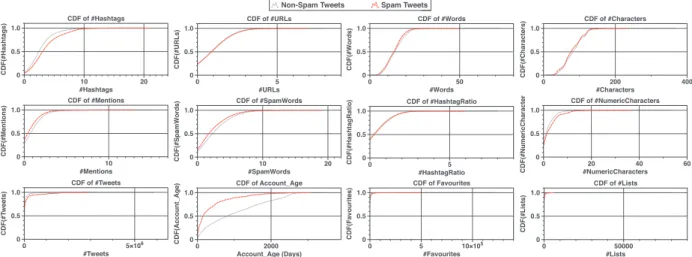
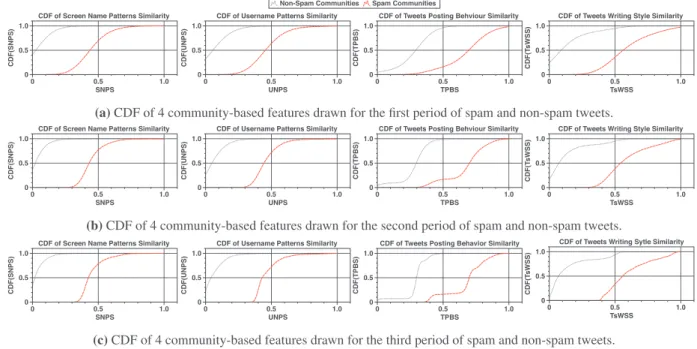
where|Users|≤ |St|.Stage2:UserAge-basedClustering.Socialspammershavethe abilitytocreatehundredsorthousandsoftheTwitteraccountsin a short period not exceeding few days,for launching their spam campaigns(Benevenutoetal.,2010;Washhaetal.,2016).Also,the impactofthecreationtime hasshownitseffectivenessin detect-ing spam accountsso that when a set of accounts have a close andrecentcreationdate,theprobabilityofbeingaspamaccounts increased. Fig.5show theCumulativeDistributionFunction(CDF) of12tweet-levelfeatureswhichextractedforspamandnon-spam tweets.TheseCDFsarecomputedforarandomlyselected10days oftweetstreamingtostudythestrengthofthesefeatures.TheCDF ofthefeaturesshowsthatsocialspammerstendtobehaveexactly aslegitimateusers toavoiddetection. Aninteresting pointworth tomentionisthattheCDFofaccountagefeatureisthemost ro-bust one compared to therest ofthe features since the creation dateofaccountsisnon-editablebyusers.
Thus, the creation date of Twitter accounts can be an effec-tivemeansforgroupingthespamaccountsthatmighthavea cor-relation between them. According to that, the Users set is clus-tered based on the user age (UA) attribute. In a formal way, let
CaAge=
{
u|
u∈Users,u.UA=a}
beaday-clustercontainingtheuserswhohaveanaccountageequalinga∈Ages,whereAges=
{
u.UA|
u∈ Users}
isasetofdistinctusersages.Obviously,thenumberofday clusters is dynamically determined, which exactly equals to the sizeoftheAgesset(i.e.,|Ages|).Stage3:Community Detection.Socialspammers mightcreate uncorrelated spam campaignsatthe sametime (Stringhiniet al., 2010;Wang&Pu,2015;Washha,Shilleh,Ghawadrah,Jazi,&Sèdes, 2017). In other words, we might have an age cluster containing spamaccountsbelongingtodifferentspamcampaigns.Also,many non-spam users join Twitter daily, which increase the probabil-ity of having non-spam users created on the same day as the spam ones. Therefore, to distinguish between different uncorre-latedspam campaignsandnon-spam accounts, acommunity de-tection stage isperformed oneach cluster resultedby age-based clusteringstage. Wedefine each spamcampaignasacommunity having a high correlation between its users, where the
correla-tioninagivencommunitycanbemeasuredovernamingaccounts level,duplicatedtweetscontent,orsimilarpostingbehavior.
In thispaper, we adoptthe Non-negativeMatrix Factorization (NMF) as an unsupervised method, to infer communities’ struc-turebecauseofitsoutstandingperformanceinclusteringproblems (Yang&Leskovec,2013).NMFhasturnedintooneofthepreferable tools for decomposing data into low-rank factorizing matricesto yield a parts-basedrepresentation. Ithasdistinct features of pre-serving the structure ofthe original input data and keepingthe non-negativityinbothweightandbasis.Thelatentsemanticspace oftheNMFmethodhasaveryintuitiveexplanationinsome clus-teringproblems.Forinstance,inNMFbaseddocumentclustering, each axisof the latentsemantic space standsforthe basic topic ofaparticularclusterwhereeachdocumentisrepresentedbythe additivecombinationofthebasictopics.
For the given community detection problem, NMF works throughpartitioningorfactorizingoneormoreinformation matri-cesintohiddenfactormatricesforanagingcluster,Ca,a∈Ages,of
users.Formally,thefactorizationofinformationmatricesis mathe-maticallydefinedasanoptimizationminimizationproblemas:
min H≥0
||
X− HH T||
2 F =min H≥0
v
u
u
t
| CAge a | X i=1 | CAge a | X j=1|
xi j− hihTj|
2
2 =min H≥0 | CaAge| X i=1 | CaAge| X j=1|
xi j− hihTj|
2 (1)where ||•||F is the Frobeniusnorm of the considered matrix,X∈
R|CaAge|×|CaAge| isan informationmatrix representingthe strengthof
the social connections (i.e., similarityamong a pairof users) be-tween users,H=[h1 ...hK]∈R| C
Age
a |×K isthecommunitystructure
hidden factor matrix of K communities, and the jth row vector
hj=[hj1,...,hjK]∈R1 ×K .The entryxij reflectsthestrengthofthe
socialconnectionbetweentheui∈CaAgeuseranduj∈CaAgeuser.The
entryhijinthehiddenfactormatrixcanbeinterpretedasthe
con-fidencedegree ofuserui∈CaAge belongingtothejthcommunity.It
isimportanttomentionthateachuserbelongstoonecommunity only,notmorethanone.
Obviously,inferringthehiddenmatrixHrequiresaformal def-inition ofthe informationmatrix X. Forexample,X might be an adjacency matrixrepresentingthe socialconnections orthe links among users of a givenage cluster CAgea . However, obtaining the
adjacency matrix in our case is not possible since the available information aboutusers is limited to simple meta-data that de-scribeaccounts,whichdidnotgiveenoughinformationaboutthe
followersandthefollowees.Hence,inthispaper,weleveragethe availableandaccessibleinformationtoestimatesocialconnections betweenusersthroughproposingthreedefinitionsofthe informa-tionmatrixXdenotedasXSN,XUN,andXWS whereeachofwhich isformallydefinedasfollows:
• ScreenNameSimilarity(XSN):Sincethescreennamefieldmust
be unique, social spammers tend to adopt a particular fixed patternwhencreatingmultipleaccountsactingasaspam cam-paign. For example, in Fig. 1, the spammer has adopted the name“voteddlovatu” asa fixedpatternandrepeatedit in fill-ingthescreennamefield.Intuitively,thehighmatchinginthe screennamebetweenusers(or accounts)increasesthe proba-bilityoftheuserstobelongtothesamecommunity.Therefore, wedefinetheinformationmatrixXSNtomeasurethedegreeof matching between the screen name attribute. More precisely, foreach two usersui,uj∈CaAge, a∈Ages,thedegree of
match-ingforaparticularentryinthematrixXSNisdefinedas:
xSN i j =
max
{|
m|
:m∈N− gram(
ui.SN)
∩N− gram(
uj.SN)
,N∈{
1,...,min(
|
ui.SN|
,|
uj.SN|
)
}}
min
(
|
ui.SN|
,|
uj.SN|
)
(2)
where|•| isthe cardinalityofthe consideredset,N− gram
(
•)
isafunctionthatreturnsasetofcontiguoussequenceof char-acters for a given name (set of ordered characters) based on the value of N. For better understanding, the 3-gram (or tri-gram (Cavnar & Trenkle, 1994)) of the screen name “vote” is {“vot”,“ote”}.Theabovedefinitioncandetectthematched pat-ternwherever itappearsinthe screennameattribute. For in-stance,let “vote12” and“tovote” bescreennamesfortwo dif-ferent spam users, the degree of matching according to Eq. (2)isaround
(
4 6)
66.6%,whichresultedfromtheuseofpattern “vote”,regardlessthepositionofthepattern.• User Name Similarity (XUN): Conversely the screen name
at-tribute, spammers mayduplicate username attribute asmany astheywish.Infact,theyaimtouseastructuredand represen-tative(notrandom)namestoattractlegitimateusers(Washha, Qaroush,Mezghani,&Sèdes,2017b).Therefore,fullyorpartially matchingamongusersbasedonsuchanattributeincreasesthe probability of being inthe same community. Thus, we define theinformationmatrixXUN tomeasurethedegreeofsimilarity amongusersbasedontheusernameattribute.Formally,given twousersui,uj∈CageAge,thedegreeofsimilarityisdefinedas:
xUNi j =max
{|
m|
:m∈N− gram(
ui.UN)
∩minN− gram(
(
uj.UN)
,N∈{
1,...,min(
|
ui.UN|
,|
uj.UN|
)
}}
|
ui.UN|
,|
uj.UN|
)
(3) • Names Writing Style Similarity (XWS): Based on our
observa-tions, social spammers mayfollow a particular style in writ-ing theusername andscreennameattributes.Forinstance,in these two real spam accounts (u1=
{
SN=“v
ote5soss33′′,US=“
v
ote5sos′′}
,andu2 ={
SN=“sav
ed028′′,US=“sav
ed′′}
),theso-cial spammer has used the username attribute in filling the screen-name attributewithputtingtheusername valueinthe beginning. Hence, as these two accounts belong to the same spam campaign, modeling such behavior can efficiently con-tributetoidentifyingspamcommunities.Inordertomodelthis
similaritybetweenapairofusers,wefirstlydefinea function,
Pos(Str1 , Str2 ), that takes two strings as an input andthen it finds the location (Start,Inside, End)of thestring Str2 in the stringStr1,writtenas:
Pos
(
Str1 ,Str2)
=
SE|
Str1 ∩Str2|
=|
Str2|
=|
Str1|
S|
Str1∩Str2|
=|
Str2|
and•1∈Str1∩Str2 E|
Str1 ∩Str2|
=|
Str2|
and•| Str1|∈ Str1 ∩Str2 I|
Str1 ∩Str2|
=|
Str2|
and•1 ∈/Str1 ∩Str2 and•| Str1| ∈/Str1 ∩Str2 (4)where the two strings are represented as a finite set of or-dered characters Str•=
{
d1 ,d2 ,...}
, d•∈{PrintableCharacters},the symbol •1 representsany character written at the begin-ningofagivenstring,while •|Str
1| correspondstothecharacter
writtenattheendofthestringStr1 .
Therefore,forapairofusersui,uj∈CaAge,a∈Ages,belongingto
an agecluster,we defineawritingstylesimilaritymatrixXWS
basedontheequalityofthepairinthePosfunctionvalue.For a particularentryin thematrixXWS, thesimilarity isdefined as: xWS i j =
½
1 Pos(
ui.SN,ui.UN)
=Pos(
uj.SN,uj.UN)
0 otherwise (5)where here 1 means that the pair of users has same writing style, while 0 represents dissimilar writing style. For better understanding, when applying the Pos func-tion on the given example of a pair of spam accounts (users), (u1=
{
SN=“v
ote5soss33′′,US=“v
ote5sos′′}
, andu2 =
{
SN=“sav
ed028′′,US=′′sav
ed′′}
), the “S” location isre-turned fortheboth users(i.e.,Pos
(
“v
ote5soss33′′,“v
ote5sos′′)
=S,Pos
(
“sav
ed028′′ ,“sav
ed′′)
=S) since the username “vote5sos”appears inthebeginning ofscreenname“vote5soss33” of the user u1 ,andsimilar for the“saved” username of the useru2 . Thus,thewritingstylesimilarityequalsto1.
Non-negative matrix factorization method allows to integrate these three information matrices together in the same objective function.Accordingtothis,theobjectivefunctionisdefinedas:
min H≥0
||
X SN − HHT||
2 F+||
X UN − HHT||
2 F+||
X WS − HHT||
2 F (6)Obviously, the objective function in Eq. (6) infers the hidden factormatrixHtorepresentconsistentcommunitystructureof re-latedusers.Indeed,thisobjectivefunctionisnotjointlyconvexand hasnoclosedformsolution exists.Hence,we proposethe useof a gradient descent approximation method asan alternative opti-mizationapproach.Sincewehaveonematrixfreevariable(H),the gradient descent method updates it iteratively until the variable
converge. Formally,let L
(
H)
denotesthe objectivefunction given inEq.(6).So,atiterationτ
,updatingEq.(6)isgivenby:Hτ=Hτ−1 −
η
.∂
L(
H τ−1)
∂
(
H)
=H τ−1 − 2η
¡
6Hτ−1(
Hτ−1)
THτ−1 −(
XSN+XUN+XWS)
Hτ−1 −((
XSN)
T+(
XUN)
T+(
XWS)
T)
Hτ−1¢
(7)wherethe parameter
η
denotes thegradient descent step in up-dating the matrix H. We assign the value ofη
to a smallcon-stantvalue (i.e. 0.05).Also, since the gradient descent methodis an iterative process, a stop condition is required in such a case. For this, we used two stop conditions: (i) the number of itera-tions, denoted as M; and (ii) the absolutechange in the H ma-trixfortwoconsecutiveiterationstobelessthanathreshold,i.e.,
|
(
||
Hτ||
F−
||
Hτ−1||
F)
|
≤ǫ
.One might view that the proposed information matrices and theage-clusteringstagecanbeeasilymanipulatedbysocial spam-mers to evade the detection. Indeed, this view could be correct whenasocialspammercreatesverysmallspambotconsistingof nomorethan5spamaccounts.Also,socialspammersdidnot pre-fer tousearandom functiontogeneratescreennamesand user-names sincethemain objectiveofthesocialspammers istolure legitimate users. Thus, social spammers haveto usenames suit-able for the target that they want to achieve. For instance, if a social spammer wants topromote fora product ”X” through de-voting large spam bots, he must name the spam accountsusing keywords relatedto the intended product.Social spammers have theoptiontocreatetheaccountsbeforetheattack;however,they couldn’tchangethecreationdateattribute.Moreover,thepurpose ofusingtheagefeatureistoincreasethedifficultyinfrontofthe socialspammerstocreatethousandsofaccountsinshortaperiod so thatsocial spammers needto spendmonths tocreatea thou-sand ofspamaccounts. As the purposeof launchingspambots is a monetary benefit,socialspammers could notwait forthislong time in creating their accountsas well as leaving them inactive maysubjectthemforsuspensionfromTwitteritself.
Stage 4: Community-Based Feature Extraction. In order to predict the class (spam or non-Spam) of each community, one or more features must be extracted from each community such thatthesefeaturescaneffectivelydiscriminatebetweenspamand non-spam communities. Since social spammers may follow com-plex and differentspamming strategies,no singlefeature can ef-fectively discriminatebetweenspamandnon-spam communities. In addition, the design of such features must rely only on the availableinformationineachcommunitytoavoidusingRESTAPIs. Thus,weintroduceadesignoffourcommunity-basedfeaturesthat take intoaccount thecommunity’susersalong withtheirtweets. The four introduced features are distributed between account-based and tweet-based features. The username patterns similar-ity (UNPS), and the screen name patterns similarity (SNPS) are twofeaturesextractedusingtheusernameandscreennameofthe user attributes. Onthe other hand, Tweets writingstyle similar-ity(TsWSS), andTweetspostingbehaviorcorrelation (TsPBC), are tweet-based featureswhichonlyleveragetheavailable contentin thetweetsofa community.Itisimportantto mentionthat there isastrongintuitionbehindthedesignofeach feature,whichwill be illustrated statistically through different graphs of cumulative densityfunction(CDF).
The totalnumberofformedcommunitiesisdependent onthe number ofage clusters (|Ages|)beside the number ofpredefined communitiesK.Therefore,theultimatenumberofcommunitiesis |Ages|× K,wherethecommunitydetectionstageisappliedtoeach agecluster.Werepresentthejthinferredcommunityinthehidden matrix,H,by 7-tupleofattributesCj=
(
Users,Tweets,UNPS,SNPS, TsWSS, TsPBC, Label) where Users is a finite set of the users be-longingtotheinferredcommunity,Tweets⊆Stisalltweetsthatareposted by the users of the community, and Lable∈
{
spam,non−spam
}
istheclasslabelofthecommunity.Theremainingattributes aredefinedandformulatedasfollows:• UsernamePatternsSimilarity (UNPS)andScreen Name
Pat-ternsSimilarity(SNPS):Socialspammers mayadopta partic-ularpattern(e.g.,“voteddlovatu”)in creatingtheir spam cam-paigns andtherefore the probability ofhaving spam commu-nities biased toward a particular pattern used increating
ac-countsis relatively high.Since there isno obviouscorrelation amongcommunitiesatthepatternlevel,norapriorknowledge aboutthelengthandthenameofthepatterns,wemusthavea generic andindependentwayto determinewhetherthe com-munity has a spammy pattern. Thus, we rely on an intuitive andgeneralizedfactwhichstatesthattheprobability distribu-tion ofthe patterns innon-spam communities isclose tothe uniformdistribution,whilethespamcommunitieshavethe op-positebehavior.Moreprecisely,wemeasurethedegreeof simi-laritybetweenstringpatternsprobabilitydistributionextracted fromusersofaparticularcommunitywiththeuniform proba-bilitydistributionofthepatterns.
Formally, let PTUN and PTSN be two finite sets of string
pat-terns extracted from the username and the screen name attributes for users of the jth community, C
j. Also, let PDUN
and PSN
D be the corresponding probability distributions of
the username and the screen name patterns, respectively. For the uniform distribution, let PUN
uni, PuniSN be the
corre-sponding uniform distributions of username and screen name patterns, respectively. For instance, for a particu-lar community, let PTSN=
{
“mischie f′′,“isch′′,“_12”,“_14”}
and PSN
D =
{
(
“mischie f′′ ,0.7)
,(
“_15”,0.1)
,(
“_14”,0.1)
,(
“_12”, 0.1)} be a set of screen name patterns along with its probability distribution, and {(“mischief′′, 0.25
)
,(
“_15”,0.25)
,(
“_14”,0.25)
,(
“_12”,0.25)
}
be the uni-form probability distribution of these patterns. To extract and catch all string patterns, the N-gram method is applied since social spammers may define patterns varying in their length andposition.Toperformthe N-grammethod,different valuesofN ranging fromthree tothe lengthof thestringare used,withignoring low N values(oneandtwo) becausethey provide meaningless patterns. For the jth community’s users, represented as Cj, we extract the string patterns used in theusernameandscreenattributesasfollows:
PTUN = [ u∈ Cj·Users [ N∈{ 3 , ... , | u.UN|} N− gram
(
u.UN)
PTSN = [ u∈ Cj·Users [ N∈{ 3 , ... , | u.SN|} N− gram(
u.SN)
(8)The doubleunification (S S)can be viewedasadouble “for” loopswhere theinner unification isresponsible about return-ingallpatterns,asafinitesetofstrings,thatasingleuserhas, whiletheouter unification unifiesallsets ofusers’string pat-terns tohaveonly one singlesetofthe stringpatterns repre-sentingthecommunityitself.
Sincethepatternisacategoricalrandomvariableinwhichthe string has not a meaningful order of magnitudes, we adopt theKullback–Leibler divergence(Kullback& Leibler,1951)(KL) method as a suitable and a fast way to measure the similar-itybetweenanytwoprobabilitydistributionsofcategorical ran-domvariables.However,theclassicalversionofKLmethod can-notbe directlyexploitedincomputingsimilarityamong(PTUN D
and PTUN
uni) or(PTDSN andPTuniSN) since the∞ and 0values
cor-respond to dissimilar, and similar distributions, respectively. Hence,we performafewmodificationsonthecurrentversion ofKLmethodtoinversethesemanticmeaningofKLvalues(i.e., 0⇒dissimilarand1⇒similar)andtakingintoaccount bound-ing its values. Thus, for the jth community, the value of the UNPSandSNPSfeaturesarecomputedusingthecustomizedKL
equationasfollows: Cj .UNPS= log