SyllabO + : la première base de données
sous-lexicale du français québécois oral
Mémoire
Pascale Bédard
Maîtrise en médecine expérimentale
Maître ès sciences (M.Sc.)
Québec, Canada
SyllabO + : la première base de données
sous-lexicale du français québécois oral
Mémoire
Pascale Bédard
Sous la direction de :
Résumé
Les unités linguistiques sous-lexicales (p.ex., la syllabe, le phonème ou le phone) jouent un rôle crucial dans le traitement langagier. En particulier, le traitement langagier est profondément influencé par la distribution de ces unités. Par exemple, les syllabes les plus fréquentes sont articulées plus rapidement. Il est donc important d’avoir accès à des outils permettant de créer du matériel expérimental ou clinique pour l’étude du langage normal ou pathologique qui soit représentatif de l’utilisation des syllabes et des phones dans la langue orale. L’accès à ce type d’outil permet également de comparer des stimuli langagiers en fonction de leurs statistiques distributionnelles, ou encore d’étudier l’impact de ces statistiques sur le traitement langagier dans différentes populations. Pourtant, jusqu’à ce jour, aucun outil n’était disponible sur l’utilisation des unités linguistiques sous-lexicales du français oral québécois. Afin de combler cette lacune, un vaste corpus du français québécois oral spontané a été élaboré à partir d’enregistrements de 184 locuteurs québécois. Une base de données de syllabes et une base de données de phones ont ensuite été construites à partir de ce corpus, offrant une foule d’informations sur la structure des unités et sur leurs statistiques distributionnelles. Le fruit de ce projet, intitulé SyllabO +, sera rendu disponible en ligne en accès libre via le site web
http://speechneurolab.ca/fr/syllabo dès la publication de l’article le décrivant. Cet
outil incomparable sera d’une grande utilité dans plusieurs domaines, tels que les neurosciences cognitives, la psycholinguistique, la psychologie expérimentale, la phonétique, la phonologie, l’orthophonie et l’étude de l’acquisition des langues.
Abstract
Linguistic sublexical units (e.g., syllables, phonemes or phones) have a crucial role in language processing. More specifically, language processing is greatly influenced by the distribution of these units in a language. For example, frequent syllables are produced more rapidly. It is thus important to have access to tools enabling the creation of experimental or clinical material that is representative of syllable and phoneme/phone use in language. Access to such tools also allows the comparison of language stimuli according to their distributional statistics, as well as the study of the impact of these statistics on language processing in different populations. However, to this day, there was no tool available on syllable and phone use for Quebec oral French. To circumvent this problem, a vast corpus of oral spontaneous French was elaborated from the recordings of 184 Quebec speakers. A syllable database and a phone database were then built from this corpus, offering a wealth of information on the structure and distributional statistics of syllables and phones. The project, named SyllabO +, will be made available online (open-access), via this website: http://speechneurolab.ca/en/syllabo as soon as the article describing it is published. We believe SyllabO + will prove immensely useful in many fields, such as cognitive neurosciences, psycholinguistics, experimental psychology, phonetics, phonology, speech therapy and the study of language acquisition.
Table des matières
Résumé ... III Abstract ... IV Table des matières ... V Liste des tableaux ... VII Liste des figures ... VIII Liste des abréviations et des sigles ... IX Remerciements ... X Avant-propos ... XI
1 – Introduction et problématique ... 1
1.1 Unités sous-‐lexicales et statistiques distributionnelles ... 2
1.2 Rôle des unités sous-‐lexicales et des statistiques distributionnelles dans le langage oral ... 5
1.3 Notation du langage oral : Alphabet Phonétique International (API) ... 8
1.4 Bases de données linguistiques ... 11
1.5 Conclusions et objectifs du mémoire ... 26
2 – Article : base de données syllabique ... 27
2.1 Introduction ... 29 2.2 Method ... 32 2.3 General description ... 37 2.4 Conclusion ... 47 2.5 References ... 51 2.6 Supplemental material ... 55
3 – Base de données de phones ... 73
3.1 Objectifs et élaboration ... 73
3.2 Description générale de la base de données phonétique ... 74
4 – Discussion et conclusion ... 80
4.1 Utilité de SyllabO + ... 80
4.2 Forces et limites ... 86
4.3 Perspectives ... 87
4.4 Conclusion ... 88
Bibliographie ... 89
Liste des tableaux
Tableau 1. Liste de bases de données ... 25
Tableau 2. Number of syllables transcribed and number of speakers (n) according to age,
sex and communication context (formal, informal) ... 33
Tableau 3. List of all syllabic structures from the 5% most frequent syllables, with
associated total frequency in the corpus (absolute and percentage) and number of
different syllables (with frequency in percentage) (i.e., prolificacy) ... 41
Tableau 4. List of all 52 syllabic structures of spoken Quebec French (extracted from the
complete database), with associated total frequency in the corpus (absolute and percentage) and number of different syllables (with frequency in percentage) (i.e.,
prolificacy) ... 42
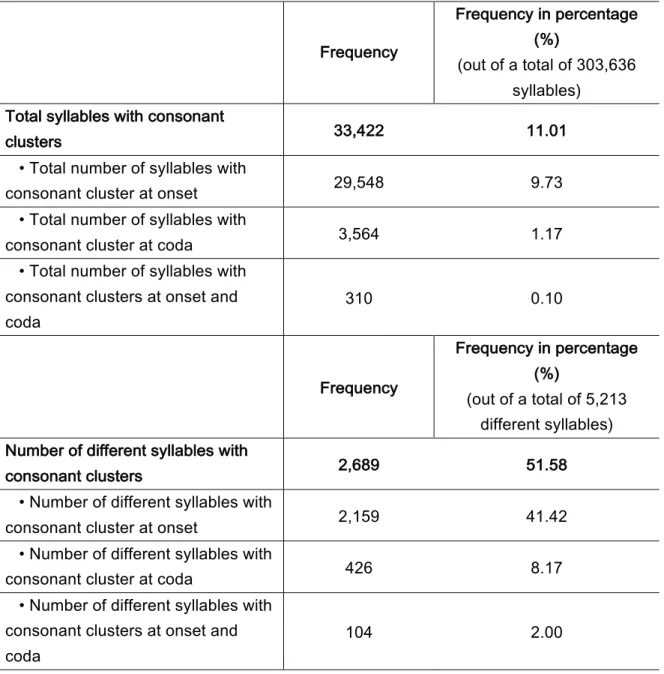
Tableau 5. Overview of the syllabic structures including consonant clusters, with
associated total frequency in the corpus (absolute and percentage) and number of
different syllables (with frequency in percentage) (i.e., prolificacy) ... 44
Tableau 6. List of all syllabic structures including a consonant cluster (c.c.) at onset, with
associated total frequency in the corpus (absolute and percentage) and number of
different syllables (with frequency in percentage) (i.e., prolificacy) ... 45
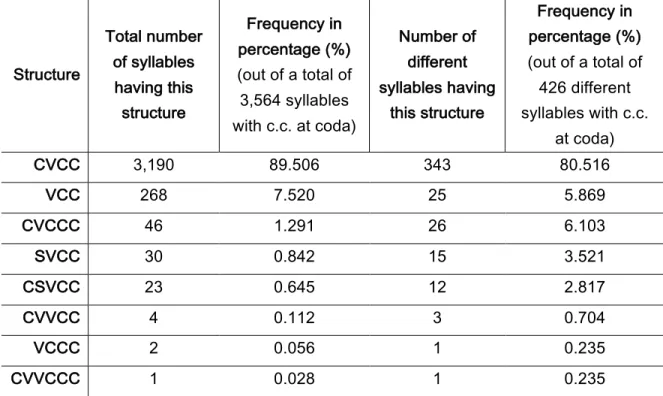
Tableau 7. List of all syllabic structures including a consonant cluster (c.c.) at coda, with
associated total frequency in the corpus (absolute and percentage) and number of
different syllables (with frequency in percentage) (i.e., prolificacy) ... 46
Tableau 8. List of all syllabic structures including consonant clusters (c.c.) at onset and
coda, with associated total frequency in the corpus (absolute and percentage) and number of different syllables (with frequency in percentage) (i.e., prolificacy) ... 46
Tableau 9. Liste de tous les phones avec leur structure, leur fréquence (absolue et
Liste des figures
Figure 1. Alphabet phonétique international ... 10
Figure 2. Relationship between syllable absolute frequency and rank ... 38
Liste des abréviations et des sigles
API Alphabet phonétique international
IPA International phonetic alphabet
C Consonne
V Voyelle
S Semi-voyelle
Remerciements
Ce mémoire est le fruit d’un travail de recherche de près de deux ans. Je tiens donc à exprimer ma reconnaissance envers toutes les personnes qui m’ont aidé de près ou de loin au cours du projet et de la rédaction de ce mémoire.
Je remercie tout d’abord ma directrice de recherche, Pascale Tremblay, pour le temps qu’elle m’a consacré, pour son écoute et ses conseils indispensables, pour son dynamisme et pour son souci du travail de qualité. L’enthousiasme qu’elle démontre pour la recherche est inspirant et éveille la motivation.
J’adresse également mes remerciements à mes collègues de laboratoire et aux professeurs avec qui j’ai pu discuter du projet et échanger des idées. Un merci particulier à Patrick Drouin pour ses « lumières » informatiques, ainsi qu’à Anne-Marie Audet qui a veillé sur mon équilibre mental lors de nos longues heures d’écoute et de transcription.
Je remercie le Conseil de recherches en sciences naturelles et génie du Canada (CRSNG), ainsi que la Faculté de médecine de L’Université Laval, qui ont soutenu mon projet par des bourses d’études.
Je tiens à remercier ma famille : mes parents, Paulin et Claire, ainsi que Daniel et Jessica, qui m’ont toujours encouragée à me lancer dans des projets et à relever des défis. La réussite de cette maîtrise repose en grande partie sur leur dévouement et leur soutien inconditionnel. Je remercie aussi mes extraordinaires amis pour leurs précieux encouragements et leur patience quand je tentais d’expliquer « brièvement » mon projet. Enfin, un immense merci à Alexis, mon complice de tous les jours, qui m’a épaulée et encouragée à chaque moment. Son amour, son appui et sa bonne humeur contagieuse m’ont aidé à persévérer et à garder le sourire.
Avant-propos
Le projet présenté dans ce mémoire est rapporté sous forme d’article scientifique ayant été soumis pour publication. L’article est inséré au chapitre 2 de ce mémoire. L’article est présenté tel que soumis au périodique Behavior Research Methods (présentément sous révision). Cependant, une partie du matériel supplémentaire n’a pas été inclus dans le chapitre afin de respecter les normes de nombre de pages maximum ; ce matériel supplémentaire est toutefois disponible en ligne sur le site internet du laboratoire www.speechneurolab.ca/syllabo. L’article a été rédigé par Pascale Bédard (première auteure). Les coauteurs de l’article sont : Anne-Marie Audet (AMA), Patrick Drouin (PD), Johanna-Pascale Roy (JPR), Julie Rivard (JR) et Pascale Tremblay (PT). PB, AMA, JPR et PT ont participé à l’élaboration du protocole. PB, AMA et JR ont effectué le recrutement des participants, les enregistrements audio et les transcriptions phonétiques sous la supervision de PT. PD a élaboré la structure des fichiers XML et aidé dans les aspects informatiques. PB a mis sur pied les bases de données syllabique et phonétique (incluant la création des algorithmes, l’extraction d’informations et calculs statistiques via programme informatique). Pascale Tremblay, directrice de la maîtrise, a corrigé, révisé et bonifié les différentes versions de l’article et du mémoire. Le projet a été financé par une subvention du CRSH obtenue par la Dre Tremblay.
Nota bene
Dans le présent document, le genre masculin est utilisé comme générique dans le seul but d’alléger le texte.
1 – Introduction et problématique
Les unités linguistiques sous-lexicales, telles que les syllabes, jouent un rôle crucial dans le traitement langagier, tant sur les plans expressifs que réceptifs, comportemental que neural. De nombreuses études (p. ex., Carreiras, Mechelli, & Price, 2006; Cholin, Levelt, & Schiller, 2006; Deschamps, Hasson, & Tremblay, 2016; Pelucchi, Hay, & Saffran, 2009b; Tremblay, Deschamps, Baroni, & Hasson, 2016), incluant plusieurs de notre équipe, s’intéressent à la distribution de ces unités dans le langage courant (que ce soit en français Québécois, dans une autre variété de français ou dans d’autres langues), et visent à déterminer les facteurs qui influencent cette distribution, tels que l’âge ou le sexe des locuteurs, ou encore cherchent à déterminer quelle est l’influence des statistiques de cette distribution sur la production et la perception du langage. Ce type d’étude nécessite un accès à des outils représentatifs de la langue étudiée permettant de calculer la distribution des unités dans une langue. Or, à ce jour, il n’existait aucun corpus, ni aucune base de données, disponible pour le français québécois oral, permettant le calcul des statistiques distributionnelles des unités de la langue orale. L’objectif de ce projet de maîtrise était donc de contribuer à la création d’un corpus du langage oral en français québécois et de développer, à partir de celui-ci, une base de données de syllabes et une base de données de phones. Le mémoire contient quatre chapitres qui permettront de présenter tous les aspects du projet : le premier chapitre consiste en l’introduction, le deuxième chapitre présente l’élaboration du corpus et de la base de données de syllabes, le troisième chapitre décrit la base de données de phones et, finalement, le quatrième chapitre inclut la discussion et la conclusion.
Dans les prochaines sections de l’introduction, nous effectuerons d’abord un survol du rôle des unités sous-lexicales dans le langage. Nous introduirons ensuite la
notion de statistique distributionnelle. De plus, puisque tout au long de ce mémoire il sera question de langage oral, une courte section présentera le système de notation des sons parlés. Nous discuterons ensuite de la création de bases de données linguistiques. Finalement, une analyse des bases de données existantes sera présentée (section 1.7), révélant le besoin de bases de données pour le français oral québécois.
1.1 Unités sous-lexicales et statistiques distributionnelles
Les unités sous-lexicales du langage oral correspondent aux unités linguistiques qui sont plus « petites » que les mots, c’est-à-dire qui composent ceux-ci. En français, les principales unités sous-lexicales d’intérêt sont les syllabes et les phonèmes (Cutler, Mehler, Norris, & Segui, 1986; Healy & Cutting, 1976; Mehler, Dommergues, Frauenfelder, & Segui, 1981; Schouten, 1992), ou les phones. (À noter que d’autres unités sous-lexicales sont de grande importance dans plusieurs langues, par exemple les tons en mandarin). En français, les phonèmes sont les plus petites unités distinctives (Brousseau & Nikiema, 2001), c’est-à-dire qui permettent de distinguer un mot par rapport à d’autres. Par exemple, lorsque l’on entend le mot roi, il est facile de le différencier de moi ou loi, des mots qui ne diffèrent que par un phonème (paire minimale), parce que ce phonème, /r/, est distinct de /m/ et de /l/. Il est important de savoir qu’un phonème peut être prononcé de manières différentes selon le locuteur : des phones (sons) différents peuvent correspondre au même phonème. Par exemple, en français, le phonème /r/ peut être réalisé avec l’arrière de la langue (dans le fond de la gorge) ou avec le bout de la langue (« roulé » près des dents), sans changer le sens du mot. Bien que ce soit deux sons (phones) distincts, ils correspondent tous deux au même phonème.
La syllabe est une composition de sons, comprenant une voyelle (V) comme noyau. Cette voyelle peut être précédée ou suivie d’une ou de plusieurs consonnes (C), formant l’attaque (début) et/ou la coda (fin) de la syllabe (Blevins, 1995; Martin, 1996). Par exemple, la prononciation du mot bateau implique deux syllabes : « ba » et « to » (ba - teau à l’écrit), toutes deux de structure CV. Le mot vrac, lui, possède une seule syllabe, dont la structure est CCVC. Dans ce mémoire, nous définirons comme simples les syllabes comprenant une seule consonne (ou aucune, c.-à-d. V ou CV) et comme complexes les syllabes comprenant plus d’une consonne. Il est important de noter que les syllabes prononcées dans le langage oral ne correspondent pas nécessairement aux syllabes orthographiques.
Chaque langue possède des règles phonotactiques, c’est-à-dire des régularités qui dressent un portrait des suites de sons ou de syllabes qui sont permises dans la langue (ou de celles qui sont plus ou moins probables). La structure combinatoire des sons de la parole (en d’autres mots, l’ensemble des règles phonotactiques) est spécifique à chaque langue et est utilisée par les locuteurs pour le traitement perceptuel de la parole (McQueen, 1998; Scott, 2009). Cette connaissance phonotactique des locuteurs se développe de manière inconsciente au cours du développement langagier. En effet, le cerveau possède une sensibilité aux régularités statistiques (p. ex., distribution des probabilités, structure séquentielle) : il emmagasine donc des informations sur les séquences de sons entendus et établit des généralisations à partir des statistiques de ces séquences (Aslin, Saffran, & Newport, 1999; Curtin & Hufnagle, 2009; Lany & Saffran, 2013; Mattys & Jusczyk, 2001).
Les statistiques distributionnelles correspondent aux mesures relatives à la distribution des unités dans une langue et sont le reflet des régularités
phonotactiques de la langue. Ces statistiques sont établies à partir d’un corpus de la langue cible. Les statistiques les plus fréquemment utilisées sont la fréquence (pour les unités seules ou les cooccurrences) et les probabilités de transition (Grinstead & Snell, 2012) (pour les cooccurrences). La fréquence – brute ou en pourcentage – des unités est une mesure permettant de savoir quelle portion du corpus est représentée par chacune des unités et quelle est la probabilité de retrouver une unité en particulier. (P. ex., une syllabe qui a une fréquence de 218 sur un total de 34 760 syllabes, soit 0,627 % du corpus, a une probabilité de 0,00627). Les statistiques distributionnelles peuvent être calculées non seulement sur les unités seules, mais sur les groupes d’unités trouvés dans le corpus, c’est-à-dire les cooccurrences (p. ex., les paires d’unités). En plus d’observer la fréquence des cooccurrences, il est possible de déterminer dans quelle mesure les unités formant le groupe s’agencent les unes avec les autres. Pour ce faire, on a recours à des calculs tels que la probabilité de transition. Celle-ci mesure la probabilité qu’une syllabe y (ou toute autre unité) suive – ou précède – une syllabe x étant donné la fréquence de la paire x y par rapport à la fréquence de x. Les calculs se notent ainsi :
• Probabilité de transition avant (forward transition probability) – probabilité que la première syllabe d’une paire soit suivie de la deuxième syllabe
Calcul : (fréquence de la paire / fréquence de la première syllabe) * 100 • Probabilité de transition arrière (backward transition probability) – probabilité que la deuxième syllabe d’une paire soit précédée de la première syllabe
Calcul : (fréquence de la paire / fréquence de la deuxième syllabe) * 100 D’autres mesures d’association, telles que l’information mutuelle (mutual information), peuvent aussi fournir des données utiles quant aux groupes d’unités.
En effet, ce sont des mesures qui permettent de déterminer la dépendance mutuelle entre des valeurs. Le score d’association pointwise mutual information (PMI) permet de mesurer l’information commune (association) entre deux valeurs particulières des distributions. Le calcul est représenté ainsi :
pmi(x; y) = log
2p(x, y)
p(x)p(y)
Le MI-like est une variante du calcul de l’information mutuelle. Il permet également de mesurer l’information commune (association) entre deux valeurs, tout en accordant une moins grande importance aux événements rares (contrairement au PMI, qui calculera un score élevé pour les éléments rares). Le MI-like correspond à l’information mutuelle avec le numérateur au cube. Le calcul est représenté ainsi :
mi _ like(x; y) =
( p(x, y))
3p(x)p(y)
Toutes ces mesures statistiques différentes fournissent donc des informations pouvant s’avérer utile à l’analyse de la structure phonotactique d’une langue.
1.2 Rôle des unités sous-lexicales et des statistiques distributionnelles
dans le langage oral
Les propriétés statistiques (p. ex. : fréquence de cooccurrence, probabilités de transition), de même que la complexité phonologique des unités sous-lexicales du langage influencent le développement langagier ainsi que la production et la perception du langage tout au long de la vie. La syllabe – qui est souvent considérée
comme l'unité de base en perception et en production de la parole (Levelt, 1999) – joue un rôle fondamental dans le développement langagier chez l’enfant. Des chercheurs ont montré que les syllabes complexes (contenant un groupe de consonnes) se développent plus tardivement que les syllabes simples (structure syllabique CV). (Levelt, Schiller, & Levelt, 2000; Lleó & Prinz, 1996; McLeod, van Doorn, & Reed, 2001).
Sur le plan statistique, il a été proposé que les enfants utilisent les statistiques distributionnelles (notamment les probabilités de transition) pour apprendre les mots, en l’absence de pauses délimitant les mots dans le discours oral (contrairement au langage écrit), puisque les syllabes qui cooccurrent fréquemment ont tendance à former des mots. En effet, les enfants démontrent une sensibilité aux statistiques distributionnelles des syllabes (Goyet, Nishibayashi, & Nazzi, 2013; Teinonen, Fellman, Näätänen, Alku, & Huotilainen, 2009) et ils utilisent les probabilités de transition des syllabes pour apprendre à segmenter les sons dans le flot continu de la parole. C’est ce qu’ont mis en évidence des études conduites dans divers contextes expérimentaux, soit lorsque des jeunes enfants sont exposés à une langue nouvelle (Pelucchi, Hay, & Saffran, 2009a; Pelucchi et al., 2009b), ou encore à un « langage » de non-mots généré par synthèse vocale (Saffran, Aslin, & Newport, 1996). Les adultes sont également sensibles aux statistiques distributionnelles des unités linguistiques, comme l’ont montré des études utilisant divers stimuli, notamment des séries de séquences trisyllabiques (syllabes CV) énoncées par un système de synthèse vocale (Newport & Aslin, 2004; Peña, Bonatti, Nespor, & Mehler, 2002), ou encore des mots et des non-mots dont les phonèmes variaient selon des probabilités phonotactiques, (p. ex., des probabilités plus ou moins élevées de fréquence de diphone et de fréquence positionnelle du phonème dans le mot (Vitevitch, 2003; Vitevitch & Luce, 1998; Vitevitch, Luce, Charles-Luce,
& Kemmerer, 1997; Vitevitch, Luce, Pisoni, & Auer, 1999). Il est intéressant de noter que ces mécanismes d’apprentissage statistique ne se limitent pas aux unités linguistiques mais peuvent aussi s’appliquer à des stimuli non-linguistiques, comme l’a mis en évidence une étude manipulant l’information statistique tonale (Saffran, Johnson, Aslin, & Newport, 1999).
Outre les probabilités de transition, d’autres statistiques sont associées à des processus de traitement du langage. Notamment, un effet facilitateur de la fréquence syllabique sur la production du langage a été démontré chez des adultes en santé, les syllabes plus fréquentes étant produites plus rapidement et avec moins d’erreurs (Cholin et al., 2006; Levelt, 1999).
De plus, de récentes études en neuroimagerie, dont plusieurs de notre équipe, ont mis en évidence la sensibilité de plusieurs régions du cerveau (p. ex. le gyrus frontal inférieur, le cortex supratemporal, le cortex prémoteur ventral) aux propriétés statistiques de la parole. Ces études montrent un effet facilitateur des syllabes fréquentes dans la planification articulatoire (Carreiras et al., 2006; Carreiras & Perea, 2004) et une sensibilité à la variation de la structure statistique des séquences syllabiques (p. ex., selon des probabilités de transition), que ce soit avec des mots (Deschamps et al., 2016) ou des non-mots (Karuza et al., 2013). Une modulation des réponses neurales a également été observée selon une variation des probabilités de transition pour des séquences de phonèmes (formant des mots ou des non-mots) (Leonard, Bouchard, Tang, & Chang, 2015), ou encore selon une variation de fréquence phonotactique (c.-à-d. de fréquence de cooccurrence) des phonèmes (Vaden, Kuchinsky, et al., 2011; Vaden, Piquado, & Hickok, 2011). D’autres études ont révélé des réseaux corticaux impliqués dans les processus séquentiels sous-lexicaux (Peeva et al., 2010), ou ont montré la manière dont la
structure statistique de séquences de syllabes – non-mots – (p. ex., variant en fréquence syllabique, en information mutuelle ou en mesure de non-prédictibilité) module la perception et la production de la parole (Tremblay et al., 2016; Tremblay, Baroni, & Hasson, 2012). Finalement, des recherches ont rapporté une sensibilité du cerveau à la complexité de la structure syllabique (c.-à-d. variant en composition de C et V, p. ex. avec ou sans groupe consonantique), que ce soit en perception (Deschamps & Tremblay, 2014) ou en production de la parole (Tremblay & Small, 2011). Ces effets de structure syllabique entrent également en interaction avec la fréquence syllabique et la complexité séquentielle des stimuli (Bohland, Bullock, & Guenther, 2009; Bohland & Guenther, 2006; Brendel et al., 2011). En conclusion, bien que de nombreuses questions demeurent quant au rôle que jouent les statistiques distributionnelles et les structures syllabiques chez l’adulte, il est clair que celles-ci influencent le comportement et l’activité du cerveau tout au long de la vie.
1.3 Notation du langage oral : Alphabet Phonétique International (API)
Dans les prochaines sections et les prochains chapitres, la notation phonétique sera régulièrement employée pour représenter les sons parlés. Par souci de clarté, ce système de notation sera présenté dès maintenant.Afin d’être en mesure de consigner par écrit des sons du langage oral, en représentant fidèlement la prononciation des locuteurs, une notation spécifique a été mise au point et est utilisée systématiquement. Il s’agit de l’alphabet phonétique international (API). Ce système de notation permet d’établir une correspondance entre un seul son prononcé et un seul symbole. En effet, l’écriture orthographique régulière ne permet pas cette précision, puisque plusieurs sons peuvent avoir la
même graphie et plusieurs graphies peuvent représenter un seul son. De plus, les symboles (caractères) utilisés varient d’une langue à l’autre et ne représentent pas nécessairement les mêmes sons, même lorsque identiques.
L’API permet de transcrire la parole de manière précise et fidèle, avec un alphabet standardisé. Cet alphabet inclut des lettres, ainsi que des symboles diacritiques et prosodiques qui ajoutent des précisions sur la production de ces sons. Par convention, les caractères API sont notés entre crochets [ ] lorsqu’ils représentent des phones (sons prononcés) et entre barres obliques / / lorsqu’ils représentent des phonèmes. Cette notation est respectée dans l’ensemble de ce manuscrit.
La Figure 1 (page suivante) présente l’ensemble des symboles de l’API1
(International Phonetic Association, 2015).
1 IPA Chart, http://www.internationalphoneticassociation.org/content/ipa-chart, available under a Creative Commons Attribution-Sharealike 3.0 Unported License. Copyright © 2015 International Phonetic Association
Figure 1. Alphabet phonétique international
CONSONANTS (PULMONIC) © 2015 IPA Bilabial Labiodental Dental Alveolar Postalveolar Retroflex Palatal Velar Uvular Pharyngeal Glottal Plosive Nasal Trill Tap or Flap Fricative Lateral fricative Approximant Lateral approximant Symbols to the right in a cell are voiced, to the left are voiceless. Shaded areas denote articulations judged impossible. CONSONANTS (NON-PULMONIC)
Clicks Voiced implosives Ejectives
Bilabial Bilabial Examples: Dental Dental/alveolar Bilabial (Post)alveolar Palatal Dental/alveolar Palatoalveolar Velar Velar Alveolar lateral Uvular Alveolar fricative
VOWELS
Front Central Back Close Close-mid Open-mid Open
Where symbols appear in pairs, the one to the right represents a rounded vowel. OTHER SYMBOLS
Voiceless labial-velar fricative Alveolo-palatal fricatives Voiced labial-velar approximant Voiced alveolar lateral flap Voiced labial-palatal approximant Simultaneous and Voiceless epiglottal fricative
Affricates and double articulations can be represented by two symbols joined by a tie bar if necessary. Voiced epiglottal fricative
Epiglottal plosive SUPRASEGMENTALS Primary stress Secondary stress Long Half-long Extra-short Minor (foot) group Major (intonation) group Syllable break
Linking (absence of a break) DIACRITICS Some diacritics may be placed above a symbol with a descender, e.g.
Voiceless Breathy voiced Dental Voiced Creaky voiced Apical Aspirated Linguolabial Laminal More rounded Labialized Nasalized Less rounded Palatalized Nasal release
Advanced Velarized Lateral release
Retracted Pharyngealized No audible release Centralized Velarized or pharyngealized
Mid-centralized Raised ( = voiced alveolar fricative) Syllabic Lowered ( = voiced bilabial approximant) Non-syllabic Advanced Tongue Root
Rhoticity Retracted Tongue Root
TONES AND WORD ACCENTS
LEVEL CONTOUR or Extra high or Rising
High Falling
Mid Highrising
Low Lowrising
Extra Rising-low falling Downstep Global rise Upstep Global fall THE INTERNATIONAL PHONETIC ALPHABET (revised to 2015)
1.4 Bases de données linguistiques
Importance dans les études sur le langage et aspects à considérer
Développées à partir de corpus, les bases de données lexicales et sous-lexicales offrent des informations précieuses sur l’utilisation d’une langue et sont d’une grande utilité aux chercheurs s’intéressant à la parole et au langage, notamment à ceux qui, comme nous, s’intéressent à la distribution des unités dans la langue. Ce sont des outils caractérisant la langue selon des paramètres spécifiques qui permettent aux chercheurs et aux cliniciens d’avoir une référence représentative pour élaborer des devis expérimentaux précis ou des tâches écologiques. En effet, au sein des neurosciences cognitives, de la psychologie expérimentale ou de la psycholinguistique, des stimuli langagiers sont souvent élaborés afin d’étudier en contexte expérimental le traitement ou la production du langage. Dans ce contexte, il s’avère utile de connaître les fréquences lexicales, syllabiques ou phonétiques selon les unités linguistiques sélectionnées, de même que leur structure ou encore les mesure d’associations qui les lient entre elles, puisque, tel que discuté aux sections 1.1 et 1.2, les statistiques distributionnelles des syllabes et des mots influencent le traitement et la production de ces unités. Les informations fournies par les bases de données permettent ainsi aux chercheurs de valider la qualité ou la représentativité de leur stimuli.
Par exemple, il serait possible de créer pour une expérience des stimuli lexicaux qui soient équilibrés à différents niveaux : les mots auraient tous une fréquence élevée et un nombre de syllabes identique. De plus, les syllabes les composant seraient aussi elles-mêmes équilibrées en termes de fréquence et de structure (composition de consonnes et de voyelles). Ainsi, l’effet de la fréquence lexicale et syllabique pourrait être annulé et ne viendrait pas confondre l’étude des variables manipulées
(p. e.x. la catégorie grammaticale ou le contenu sémantique des mots). Dans d’autres contextes, on voudra plutôt comparer la production de syllabes fréquentes à la production de syllabes rares pour comprendre l’impact de la fréquence syllabique sur le contrôle moteur de la parole ou encore l’accès lexical. Ces types de contrôle (exemple 1) et de manipulations expérimentales (exemple 2) ne sont possibles que grâce aux données recueillies et exposées dans des outils de référence permettant le calcul des statistiques distributionnelles.
Les bases de données linguistiques peuvent également jouer un rôle précieux dans d’autres domaines, incluant la phonétique et la phonologie, l’orthophonie, l’étude de l’acquisition des langues, ainsi que le développement d’outils informatiques de traitement automatique du langage. Les applications de ce genre d’outils sont riches et diversifiées. Une discussion plus élaborée est présentée au chapitre 4.
Ainsi, plusieurs éléments méthodologiques devraient être pris en considération lors du choix ou de l’élaboration d’une base de données visant l’étude de la distribution des unités sous-lexicales dans le langage oral. Les sections suivantes sont dédiées aux principaux aspects d’intérêt dans le cadre de ce mémoire (spécificité de la langue et de la modalité, variation selon le contexte de communication, spécificité de la population, objectifs de normativité et ampleur du corpus).
Spécificité de la langue
Les unités linguistiques qui constituent la langue (mots, syllabes, phonèmes ou phones) ainsi que les statistiques qui y sont associées varient énormément et sont spécifiques à chaque langue. Évidemment, les mots utilisés sont différents d’une langue à l’autre, mais également les structures syllabiques et l’inventaire phonémique et phonétique. En effet, certains phonèmes sont présents dans une
langue, alors qu’ils ne le sont pas dans d’autres (ou encore, certains sons (phones) peuvent être distinctifs dans une langue et non distinctifs dans une autre). Par exemple, on retrouve en anglais la consonne /θ/ (« th »), qui n’est pas utilisée en français, et inversement, la voyelle /ɛ̃/ (« in ») se trouve en français mais pas en anglais. De plus, certaines structures syllabiques complexes sont permises dans des langues, comme CCVC en français, alors qu’elles sont illégales dans d’autres langues comme le japonais, qui ne permet pas de groupe consonantique à l’attaque de la syllabe (Tsujimura, 2013).
Bien que de nombreuses unités linguistiques puissent être partagées à travers différentes langues, les statistiques distributionnelles sous-lexicales sont uniques à chaque langue. La fréquence de chaque syllabe ou de chaque phonème diffère, ainsi que les cooccurrences et le degré d’association entre les éléments.
De plus, même à l’intérieur d’une langue, des variétés régionales significativement différentes peuvent exister, chacune d’elles ayant un inventaire phonémique et un vocabulaire particuliers influençant les statistiques distributionnelles sous-lexicales. On parle alors de variantes diatopiques (Moreau, 1997) (ou géographiques) d'une langue (p. ex. français de France, du Québec, du Manitoba, du Nouveau-Brunswick). Par exemple, la fréquence d’utilisation du mot char en français québécois et en français de France diffère radicalement puisque le mot char en français de France ne s’applique qu’au contexte très spécifique du char d’assaut alors que le mot char au Québec est employé très couramment en contexte informel pour faire référence à une voiture (Mercier, 2002). Ainsi, les syllabes et les mots ont des fréquences d’utilisation et, par conséquent, des statistiques distributionnelles pouvant différer vastement d’une variété géographique de langue à une autre. Les recherches sur le langage doivent prendre en compte les spécificités du système linguistique de la
langue étudiée. II est important de bien définir la variante à l’étude, qu’elle soit celle d’une langue en particulier, d’une région ou d’une sous-région. Ici, la variété nous intéressant est le français du Québec (et non celui de ses sous-régions). Les outils de référence utilisés dans le cadre de ces recherches devraient donc être spécifiques à la variante d’intérêt et refléter fidèlement l’objet d’étude (Podesva & Sharma, 2014).
Spécificité de la modalité
Un second aspect important à considérer est que chaque modalité (orale, écrite) comporte des idiosyncrasies, à l’intérieur même d’une langue. Le langage oral diffère du langage écrit sous plusieurs angles (Biber, 1991). D’abord, le vocabulaire employé à l’oral ne concorde pas entièrement avec celui de l’écrit. Par exemple, au Québec, les locuteurs diront régulièrement auto ou char à l’oral, alors qu’à l’écrit, la même réalité sera souvent décrite par automobile ou voiture. La prévalence de certains mots influencera non seulement la composition de l’inventaire lexical, mais également la fréquence des syllabes et des phonèmes.
D’autre part, un phénomène propre à l’oral est celui des liaisons. Le langage parlé est en effet un flot continu de sons. Il n’y a pas systématiquement de silences entre les mots ou les syllabes, contrairement à l’écrit où les unités sont séparées par des espaces blancs (Kuhl, 2004). Ceci donne lieu à de nombreuses liaisons entre les mots prononcés. Par exemple, les étudiants serait prononcé [lɛ zetydjɑ̃] (les zétudiants). Dans ce cas-ci, la première syllabe du mot étudiant ne serait donc pas [e] (« é »), mais plutôt [ze] (« zé »), telle que prononcée par le locuteur. Outre les liaisons, d’autres phonèmes sont parfois ajoutés (épenthèse) ou retirés (élision) lors de la réalisation de discours oral. Dans le langage parlé, on observe une grande variabilité entre les productions des différents locuteurs. Par exemple, à l’écrit, le
mot cœur aura toujours la même orthographe alors qu’à l’oral, un [ә] (« e ») épenthétique peut être réalisé, changeant ce mot monosyllabique en un mot bisyllabique : [kœ ʁə] (« cœu - re ») par rapport à [kœʁ] (« cœur »). De même, le [ә] (« e ») du mot petit peut être élidé par certains locuteurs, créant une différence notable (nombre de phonèmes et nombre de syllabes) entre [pti] (« p’tit ») et [pə ti]. Ces exemples illustrent l’importance de la modalité (orale, écrite) de la langue faisant l’objet de recherches lors du choix de corpus et de bases de données de référence. Variation selon le contexte de communication (registre)
Une particularité du langage, qu’il soit oral ou écrit, est de varier en fonction des contextes de communication incluant l’auditoire, un phénomène appelé « registre de langue » (Schiffrin, Tannen, & Hamilton, 2008). La manière de s’exprimer en contexte formel se distingue nettement de la manière de s’exprimer en contexte courant ou informel (Biber, 1993). Par exemple, en entrevue ou en conférence, on utilisera un vocabulaire et une syntaxe différents – voire même une prononciation différente – que lors d’une discussion entre amis.
Il convient donc de cibler le ou les contextes d’intérêt et de prendre en considération cet aspect lors du choix d’outils de référence ou lors de l’élaboration de corpus et de bases de données (Podesva & Sharma, 2014). Une base de données issue d’un corpus de discours formel ne saurait rendre compte de toutes les spécificités de la langue familière et vice-versa.
Autres considérations
Spécificité selon la population. Une autre distinction importante est manifeste entre le langage adulte et le langage enfant. Puisque le langage des enfants est en développement, ses productions sont différentes de celles d’un adulte, tant pour la
syntaxe et le vocabulaire que pour la prononciation, incluant sur le plan de la complexité phonologique de la structure des syllabes produites. (Levelt et al., 2000; Lleó & Prinz, 1996; McLeod et al., 2001) De nombreux processus linguistiques particuliers entrent en jeu dans le langage de l’enfant (Hoff & Shatz, 2009). Les études sur le langage chez les enfants gagneraient à avoir des stimuli créés à partir d’une base de données représentative de la population étudiée, tout comme des études sur le vieillissement du langage devraient également se référer à des outils qui représentent fidèlement les productions langagières des personnes âgées. En effet, même au cours de l’âge adulte, le langage oral évolue, comme le montrent des études sur le vieillissement, dont plusieurs de notre équipe (Bilodeau-Mercure et al., 2015; Bilodeau-Mercure & Tremblay, Accepted; Dromey, Boyce, & Channell, 2014; Sadagopan & Smith, 2013; Tremblay & Deschamps, 2015).
Normativité. Parmi les outils de référence, certains ont une visée plutôt prescriptive (ou normative, c.-à-d. dicter une norme particulière), alors que d’autres sont descriptifs (non normatifs), c’est-à-dire qu’ils visent simplement à décrire les phénomènes linguistiques tels qu’ils se produisent, sans poser de jugement sur leur acceptabilité par rapport à une norme établie. D’autres outils peuvent encore se situer à mi-chemin. Le choix d’une intention de mise en pratique de l’outil (normatif ou non) modifiera les caractéristiques du corpus et de la base de données lors de leur élaboration. Par exemple, doit-on englober toutes les variations d’un même élément en les normalisant vers une seule représentation? Par exemple, les réalisations différentes d’un même mot (p. ex., [ɑ̃sɛɲmɑ̃] vs [ɑ̃sɛɲəmɑ̃] pour enseignement) ou d’un même syntagme (p. ex., [le ɡro tarbr] vs [lɛ gro zarbrə] pour les gros arbres) devraient-elles être notées telles quelles ou « rectifiées » sous une notation standardisée, « corrigée »? En ce qui concerne la syllabe dans le langage oral, il est pertinent de tenir compte de la variabilité des prononciations (liaisons,
élisions, épenthèses) puisque celle-ci est inhérente à la langue orale (Greenberg, 1999). De plus, cette même variabilité influence la composition des syllabes puisque des sons ajoutés ou élidés modifient la structure des syllabes, tant pour la simplifier que pour la complexifier.
Ampleur du corpus. Enfin, l’ampleur du corpus utilisé pour construire une base de données linguistique doit également être considérée. Le nombre d’unités à recenser pour former une base de données varie selon les besoins et les aspects mentionnés précédemment. Manifestement, pour avoir une base de données représentative, il faut viser d’avoir un corpus le plus vaste possible; cependant, ce n’est pas l’ampleur du corpus seule qui détermine la validité d’un corpus car bon nombre de petits corpus fournissent des informations précieuses (Lüdeling & Kytö, 2008). Il faut tenir compte des spécificités de chaque projet pour établir des objectifs. Si la base de données est construite à partir de l’écrit, il est beaucoup plus facile de recueillir des millions d’occurrences de mots ou de syllabes, et ce, de manière automatisée. Par contre, avec une base de données de l’oral, le temps de travail exigé pour extraire les informations « manuellement » à partir d’un enregistrement audio peut restreindre l’ampleur qu’aura le corpus (Wynne, 2005) (à moins d’avoir des ressources quasi illimitées).
De plus, la population de locuteurs ciblée peut également changer les objectifs. Par exemple, pour décrire et répertorier les productions langagières de jeunes enfants, il faut prévoir un processus plus compliqué (démarches éthiques, approbation parentale) que pour un échantillon d’adultes. Il en va de même pour un groupe de personnes très âgées, lesquelles ont parfois plus de restrictions physiques et/ou cognitives à participer à ce genre de projet. L’élaboration d’un corpus (puis d’une
base de données à partir de celui-ci) doit à la fois s’avérer réalisable, sans toutefois compromettre la représentativité.
En résumé, les principaux éléments qui devraient être considérés afin de choisir ou d’établir une base de données sont les suivants : la spécificité de la langue – c.-à-d. l’unicité de chaque langue ou de chaque variété de langue, notamment concernant la composition de ses unités linguistiques et de ses statistiques distributionnelles –, la spécificité de la modalité – c.-à-d. la distinction entre les propriétés du langage oral et du langage écrit –, ainsi que la variation selon le contexte de communication – c.-à-d. les caractéristiques propres à chaque registre de langue. Il est également utile de tenir compte de la spécificité du langage selon l’âge de la population étudiée, des objectifs de normativité (prescriptifs ou descriptifs) du projet et de l'ampleur du corpus recueilli.
Bases de données existantes
Les différentes bases de données sélectionnées et présentées dans les prochaines sections correspondent aux exemples les plus pertinents pour notre sujet, soit la distribution des unités sous-lexicales dans le langage oral, plus spécifiquement dans le français québécois contemporain. Après avoir exposé les applications de chaque base de données et leurs limitations, la validité de ces outils pour les recherches expérimentales sur le français québécois oral (particulièrement la syllabe) sera évaluée brièvement.
Lexique 3
La base de données Lexique 32 (New, 2006) a été construite à partir de deux
corpus : un corpus de textes (Frantext) et un corpus de sous-titres. Le premier est composé de 218 textes littéraires publiés entre 1950 et 2000, représentant un corpus de 14,7 millions de mots. Le deuxième contient 50 millions de mots extraits de dialogues de films et de séries télévisées se divisant en quatre catégories : les sous-titres de films français (1,9 millions de mots), les sous-sous-titres de films anglo-saxons (26,5 millions de mots), les sous-titres de séries anglo-saxonnes (19,5 millions de mots) et les sous-titres de films européens non anglo-saxons : (2,5 millions de mots). La base de données Lexique 3 fournit dans des tableaux de nombreuses informations utiles telles que : les formes phonologiques du mot, les lemmes3 du
mot, les catégories grammaticales du mot, la fréquence du lemme et la fréquence du mot selon le corpus de sous-titres (par million d’occurrences), la fréquence du lemme et la fréquence du mot selon le corpus de livres (par million d’occurrences), le nombre de phonèmes, la structure orthographique, la structure phonologique, la forme phonologique syllabée, le nombre de syllabes, la structure phonologique syllabée et plusieurs autres.
Bien que Lexique 3 propose une vaste base de données où sont organisés une foule de renseignements pertinents liés à l’utilisation de mots, certaines caractéristiques limitent son application pour l’étude du français québécois oral. D’abord, le ensemble du corpus qui s’approche le plus du langage oral est la section des sous-titres de films. Même s’ils représentent des discours oraux, les sous-sous-titres ne peuvent toutefois pas rendre compte de toutes les particularités du langage oral puisqu’ils sont consignés à l’écrit et qu’ils ne représentent généralement pas une
3 Le lemme est la forme canonique d’un mot, c’est-à-dire qu’il est un « représentant » englobant toutes les formes que peut prendre un mot (p.ex., variation en genre et en nombre, conjugaison). En effet, le lemme manger représente toutes les formes possibles du verbe (p.ex., mangeais, mangerez) et le lemme petit représente toutes les formes possibles de l’adjectif (p.ex., petite, petits).
transcription exacte de ce qui a été énoncé à l’oral. De plus, la partie française de ce corpus (1,9 millions) est beaucoup plus restreinte que ses contreparties anglaises (46 millions) et il s’agit d’une variété de français spécifique à la France, qui ne peut donc pas caractériser fidèlement les phénomènes linguistiques inhérents au français québécois. Finalement, la base de données est d’abord lexicale et les informations syllabiques fournies sont subordonnées aux mots (c’est-à-dire qu’on ne peut y accéder que par des recherches lexicales et on ne peut obtenir aucun total sur les données syllabiques).
Diphones-fr
La base de données Diphones-fr4 (New & Spinelli, 2013) a été élaborée à partir des données de Lexique 3 (voir section précédente). Les unités répertoriées sont les diphones, c’est-à-dire les paires de phonèmes observées parmi tous les mots du corpus (p. ex. : /ka/, /as/ et /sk/ pour le mot casque /kask/). Tous les diphones sont notés avec leurs fréquences positionnelles intra-mots et inter-mots : à l’intérieur des mots (fréquence du diphone en position début de mot, en position fin de mot, etc.) et entre les mots des phrases des dialogues sous-titrés (p. ex. : la fréquence du diphone /ap/ entre les mots de segments tels que la porte /la pɔʁt/).
Outre les autres restrictions déjà mentionnées pour Lexique 3, la limite de cette approche est qu’au lieu de s’appuyer sur un corpus de l’oral, les données « orales » sont reconstruites à partir d’un corpus écrit de sous-titres. Il est ainsi impossible de connaître les véritables réalisations du discours, avec notamment les liaisons, les élisions et les épenthèses prononcées par les locuteurs.
InfoSyll
La base de données InfoSyll5 consiste en un syllabaire, élaboré à partir de Lexique 2 (New, Pallier, Brysbaert, & Ferrand, 2004), comprenant l’information de syllabes phonologiques6 du français et de leurs syllabes orthographiques correspondantes.
La fréquence, la longueur et la structure de chaque syllabe sont également extraites et notées. Les mots phonologiques syllabés correspondent aux lemmes de la base de données Lexique 2, de laquelle les entrées composées, les abréviations et les onomatopées ont été retirées. InfoSyll vise à faciliter la construction de matériel dans les études psycholinguistiques en permettant un contrôle précis des variables se rapportant à la syllabe.
Les applications de cet outil se rapprochent donc étroitement du sujet d’intérêt de ce mémoire, c’est-à-dire la description des syllabes du français afin de faire bénéficier les chercheurs d’un outil pour les études expérimentales sur le langage. Cependant, comme pour Lexique 3 et Diphone-fr, un corpus issu de l’écrit ne peut représenter les spécificités du langage oral et le français de France ne rend pas compte des phénomènes linguistiques propres à l’utilisation du français au Québec. Texto4Science
Le corpus Texto4Science7 (Langlais & Drouin, 2012) est composé de messages SMS (Short Message Service) – communément appelés textos – d’utilisateurs québécois. Au-delà de 7000 textos, envoyés par 360 personnes différentes, ont été recueillis et normalisés, chaque texto étant enregistré sous sa forme originale,
5 Disponible à l’adresse suivante : http://crcn.ulb.ac.be/lcld_posts/infosyll/
6 Il s’agit ici de syllabes transcrites en API, mais qui représentent les phonèmes de la prononciation
« attendue » du mot et non pas les sons concrètement prononcés par un locuteur.
annotée et normalisée8. Voici un exemple concret, tiré de Langlais & Drouin, 2012
(les balises XML et les annotations ont été mises en couleur dans ce texte pour plus de lisibilité) :
<texto ID="2009120927" date="2009-12-09"> <user_id>user_111250</user_id> <orig>
Salut Florent, je sais pas ou tu es, mais si tu peux connecte toi sur Skype, j y serai une partie de la soiree! Ciao
</orig> <transcrip>
Salut <prenom sexe="masc">Florent</prenom>, je<negat
forme="ne"/> sais pas <ortho forme="où">ou</ortho> tu es, mais si
tu peux <ponc forme=","/><typog forme="connecte-toi">connecte
toi</typog> sur Skype, <typog forme="j’y">j y</typog> serai une
partie de la<ortho forme="soirée">soiree</ortho>! Ciao<ponc forme="."/>
</transcrip> <norm>
Salut Florent, je ne sais pas où tu es, mais si tu peux, connecte-toi sur Skype, j’y serai une partie de la soirée! Ciao.
</norm> </texto>
8 La normalisation réfère au processus de corriger les fautes d’accord, de ponctuation et
d’orthographe, notamment en ramenant vers une seule forme standard les différentes formes d’un même terme. Par exemple, les différents items avec, ak, aek et ac seraient regroupés et comptabilisés sous une seule forme normalisée : avec. Les annotations contiennent des informations sur le type de faute ainsi que d’autres métadonnées linguistiques.
Un total de 90 298 items (« mots ») a été recensé et 104 268 après normalisation. Les textos, leurs annotations et leurs versions normalisées sont sauvegardés et structurés dans des fichiers balisés. Les fréquences calculées pour tous les items (items originaux et items normalisés) sont présentées dans des tableaux résultats. Texto4Science est un outil sur l’utilisation du français au Québec. Il est intéressant de noter que le langage de textos se rapproche un peu plus de l’oral que d’autres formes de langage écrit (Soffer, 2010), mais la différence significative mentionnée pour les bases de données précédentes (c’est-à-dire pas de représentation des phénomènes de prononciation) est toujours présente. D’autre part, il s’agit d’une base de données entièrement consacrée aux unités lexicales.
QUÉBÉTEXT
La base de données QUÉBÉTEXT9 (Trésor de la langue française au Québec, n.d.) est composée de quatre corpus écrits du français québécois, soit : Littérature québécoise (1837-1919), Textes sur l’anglicisme (1826-1930), Témoignages des voyageurs (1651-1899) et Préfaces de répertoires lexicaux (1841-1957). Pour chaque corpus, il est possible d’interroger la base de données afin d’obtenir les occurrences d’unités lexicales précises et leur contexte linguistique (mots ou phrases suivant ou précédant l’unité d’intérêt).
Cet outil représente donc le français québécois écrit, selon des sujets particuliers et des dates précises. Encore une fois, une base de données lexicale écrite ne pourrait constituer une référence sur le langage oral et ses unités sous-lexicales.
Phonologie du français contemporain
La base de données Phonologie du français contemporain (PFC)10 porte sur le français à travers la francophonie et fourni du matériel oral (enregistrements et transcriptions) de locuteurs11 de différents pays et différentes régions.
La base de données PFC se veut utile notamment dans les domaines de l’enseignement des langues et de la recherche en linguistique (phonétique, phonologie, syntaxe, pragmatique, sociolinguistique, analyse conversationnelle). Il s’agit donc d’une source remarquable de données sur le français oral. Toutefois, le nombre de locuteurs du français québécois inclus dans ce projet demeure limité12 et la base de données PFC n’inclut pas d’outil pour calculer les statistiques de la distribution (p. ex., fréquence) des unités lexicales ou sous-lexicales contenues dans l’ensemble des enregistrements.
Autres bases de données – sommaire
Il existe de nombreuses autres bases de données linguistiques sur l’utilisation de mots, de syllabes ou de phonèmes. Un sommaire des outils pour le français est présenté dans le Tableau 1 (une liste incluant les bases de données de toutes les langues est également disponible en Annexe 2). Cependant, ces outils répertoriés ne sont pas utiles pour la recherche sur les syllabes du français québécois oral parce qu’ils diffèrent soit par leur langue (ou variété régionale d’une langue), soit par leur modalité (écrite plutôt qu’orale), ou encore par les unités linguistiques répertoriées.
10 Disponible à l’adresse suivante : http://www.projet-pfc.net/
11 En date du 4 juillet 2016, la base de données contenait un nombre total de locuteurs de 418. 12 En date du 4 juillet 2016, la base de données contenait un nombre de locuteurs québécois de 19.
Tableau 1. Liste de bases de données en français
Base de
données Langue Modalité Unités Référence
Lexique 3 Français (France) Écrit (sous-titres et textes) Mots (New, 2006) Diphones-fr Français (France) Écrit (à partir de Lexique 3) Diphones
(New & Spinelli, 2013)
InfoSyll Français
(France)
Écrit (à partir
de Lexique 2) Syllabes
(Chetail & Mathey, 2010)
QUÉBÉTEXT Français
(Québec) Écrit
Mots (et contexte linguistique) (Trésor de la langue française au Québec, n.d.) PFC Français (toute la francophonie) Oral Enregistrements et
transcriptions annotées N/A
Texto4Science Français
(Québec) Écrit (textos) Mots
(Langlais & Drouin, 2012)
BRULEX Français
(France) Écrit Mots
(Content, Mousty, & Radeau, 1990) LEXOP Français (France) Écrit Mots (monosyllabiques) et correspondance orthographe - phonologie (Peereman & Content, 1999)
1.5 Conclusions et objectifs du mémoire
La revue des bases de données présentée dans la section précédente met en évidence la problématique énoncée plus haut : aucun outil représentatif n’est disponible pour l’étude des unités sous-lexicales en français oral québécois.
L’objectif principal de ce projet de maîtrise était donc de contribuer à l’élaboration d’un corpus et de développer, à partir de ce corpus, deux bases de données (syllabes, phones), puis de les intégrer à une plateforme web (SyllabO +). Ce mémoire décrit chacune des étapes du projet – construction du corpus, calcul des statistiques distributionnelles, élaboration des bases de données (syllabes, phones) intégration des bases de données dans une application web – et offre un aperçu des données extraites de SyllabO +.
Les prochains chapitres décriront en détail la base de données syllabique, sous forme d’article (chapitre 2), ainsi que la base de données de phones (chapitre 3). Suivront une discussion et une conclusion sur l’ensemble du projet (chapitre 4). À noter qu’une grande partie du projet a été consacrée à l’élaboration du corpus et de la base de données de syllabes. La base de données de phones, plus simple, a ensuite découlé du même projet, sans toutefois représenter une aussi grande part de travail. Le mémoire sera donc un reflet de ce travail, où le corpus et la base de données syllabique seront d’abord présenté (sous le nom de projet SyllabO, dans l’article), puis viendra s’ajouter la base de données phonétique (qui par son ajout, a mené au nom de projet SyllabO +).
2 – Article : base de données syllabique
SyllabO : a sublexical database of spoken Quebec French
Pascale Bédard1,2, Anne-Marie Audet1,2, Patrick Drouin3, Johanna-Pascale Roy1,4, Julie Rivard1,2, and Pascale Tremblay1,2
1. Université Laval, Département de réadaptation, Québec, QC, Canada
2. Centre de recherche de l’Institut universitaire en santé mentale de Québec (CRIUSMQ), Québec, QC, Canada
3. Observatoire de linguistique Sens-Texte (OLST), Montréal, QC, Canada
4. Université Laval, Département de langues, linguistique et traduction, Québec, QC, Canada
Référence complète :
Bédard, P., Audet, A.-M., Drouin, P., Roy, J.-P., Rivard, J. & Tremblay, P. (Under review). SyllabO: a sublexical database of spoken Quebec French. Behevior Research Methods.
Résumé
Les régularités phonotactiques du langage influencent le développement langagier, ainsi que le traitement et la production du langage au cours de la vie. Pour étudier les effets des régularités phonotactiques sur les fonctions langagières (niveaux comportemental/neural), il est essentiel d’avoir accès à des corpus de langue écrite et orale. Cet article présente le premier corpus et base de données des syllabes orales du français québécois, SyllabO. Celui-ci contient les transcriptions phonétiques de plus de 300 000 syllabes, extraites d’enregistrements audio de 184 locuteurs français québécois (adultes en santé, 20-97 ans). Les enregistrements ont été faits en contextes de communication familiers et formels pour assurer la représentativité. Les statistiques distributionnelles phonotactiques ont été calculées (p.ex., fréquences (syllabes/cooccurrences), pourcentage, probabilités de transition, information mutuelle). Une application web est disponible via www.speechneurolab.ca/syllabo (accès libre). L’article présente SyllabO et ses applications dans divers domaines : neurosciences cognitives, psycholinguistique, neurolinguistique, psychologie expérimentale, phonétique, phonologie et orthophonie.
Abstract
Phonotactic regularities in language have impacts on language development, as well as language processing and production throughout lifetime. To study the effects of phonotactic regularities on speech and language functions (behavioral and neural levels), it is essential to have access to written and oral language corpora. This article presents the first corpus and database of spoken Quebec French syllables: SyllabO. It contains phonetic transcriptions of over 300,000 syllables extracted from the recordings of 184 healthy adult native Quebec French speakers (age: 20 to 97 years). Recordings were made in formal and familiar communication contexts, ensuring corpus representativeness. Phonotactic distributional statistics (e.g., syllable and co-occurrence frequencies, percentage, transition probabilities, pointwise mutual information) were computed from the corpus. An open-access online application is available at www.speechneurolab.ca/syllabo. This article presents
SyllabO and its practical applications in various fields (research or clinical), including cognitive
neuroscience, psycholinguistics, neurolinguistics, experimental psychology, phonetics, phonology, and speech-language pathology.
2.1 Introduction
Sublexical units of language, such as syllables, consonant clusters, and phonemes, have distributional properties, such as co-occurrence frequency and transition probabilities, which influence language development, as well as language processing and production throughout the entire lifespan (Newport & Aslin, 2004; Pelucchi et al., 2009a, 2009b; Peña et al., 2002; Saffran et al., 1996, 1999). Moreover, recent brain imaging studies have shown that several cortical regions, including the inferior frontal gyrus and the supratemporal cortex, are sensitive to the distributional properties of syllables (Carreiras et al., 2006; Carreiras & Perea, 2004; Cibelli, Leonard, Johnson, & Chang, 2015; Deschamps, Hasson, & Tremblay, 2016; Ettinger, Linzen, & Marantz, 2014; Karuza et al., 2013; Leonard et al., 2015; Tremblay et al., 2012; Tremblay, Deschamps, Baroni, & Hasson, 2016; Vaden, Kuchinsky, et al., 2011; Vaden, Piquado, et al., 2011; Vitevitch, 2003; Vitevitch & Luce, 1998; Vitevitch et al., 1997, 1999).
Though distributional properties are universal, each language is composed of a different set of sublexical units that are organized according to a number of language-specific phonotactic and syntactic rules that determine the permissible combinations of phonemes and syllables; therefore the actual distributional properties associated to any given sublexical unit, such as syllables, are language-specific, even though the same syllables may actually occur in several languages. For example, the syllable [das] is present in German and in Italian, but its distributional statistics are different, notably in terms of frequency (in percentage):
while the German syllable frequency13 is 1.6247%, the Italian syllable frequency14 is much lower, with only 0.0023%.
Moreover, even within a language, there often exist regional varieties that can differ significantly, both in terms of phonetic inventory and vocabulary use, which has a strong impact on sublexical distributional statistics. For example, the phoneme [œ̃] is now hardly ever used by French speakers from France, who favor [ɛ̃], whereas it is still frequently used by French speakers in Quebec (Akamatsu, 1967; Canepari, 2005; Martin, Beaudoin-Begin, Goulet, & Roy, 2001; Vajta, 2012).
Another important factor when studying distributional statistics is within-language modality effects. Indeed, spoken and written language modalities have specific characteristics that have strong impacts on distributional statistics. Certain words are favored in the written language, while other words are favored in the oral form. Therefore, the oral lexicon is not identical to the written lexicon. Moreover, while written language has units that are separated by a blank, spoken language, in contrast, is a continuous flow of sounds, without silences between words or syllables (Kuhl, 2004). This results in the presence of certain phenomena such as liaisons between the pronounced words, epenthesis (adding phoneme(s)), and elision (removing phoneme(s)) during oral discourse, which account for a large amount of the variability between different speakers’ productions and result in syllables with different structures. For example, the schwa [ә] in the French word petit ('small') is typically removed in familiar contexts, resulting in distinct syllables for informal oral (CCV: [pti] ('p’tit')), compared to formal oral or written (CVCV: [pә - ti] ('petit')) French. Since sublexical units and their distributional properties are specific––at least in part– –to each language and each modality, it is necessary to have access to
13 Retrieved from BAStat database (Schiel, 2010)
specific and modality-specific corpora to be able to fully characterize distributional statistics and to study their impacts on spoken language use. Yet, spoken language corpora remain relatively scarce, particularly sublexical oral corpora, probably because of the considerable challenges that they present in terms of truthfully representing features of spoken language.
The objective of this project was therefore to constitute a corpus of oral syllables (SyllabO) from French speakers in Quebec, where 6,231,600 individuals––80% of the population––(Statistique Canada, 2011) are native speakers of French, in order to facilitate experimental and descriptive research in this population.
To the best of our knowledge (see supplemental material 1), there currently exists no database of spoken Quebec French syllables. A few databases or corpora exist for the French language, notably: Lexique 3 (New, 2006), Diphones-fr (New & Spinelli, 2013), InfoSyll (Chetail & Mathey, 2010), Texto4Science (Langlais & Drouin, 2012), QUÉBÉTEXT (Trésor de la langue française au Québec, n.d.) and Phonologie du français contemporain (PFC). The first three databases were created from the same corpus of French texts and film subtitles (France). They respectively offer information on lexical units and their components, pairs of phonemes, and syllables. The fourth database, Texto4Science is a corpus of text messages (SMS) of French speakers in Quebec, from which all word forms were extracted, as well as their distributional statistics. Although it portrays Quebec French use, Texto4Science is dedicated to the study of written lexical units occurring in the specific context of text messages. QUÉBÉTEXT is composed of four different written Quebec French corpora, providing no information on spoken Quebec French. The last database, PFC, provides recordings and transcriptions (as well as liaison and schwa
information) of oral discourse from French speakers worldwide (only a very small subset being Quebec French speakers).
Thus, in order to facilitate research on spoken language comprehension and production in Quebec, we created a corpus of contemporary spoken Quebec French, extracted over 300,000 syllables from it, and computed a large number distributional statistics. The resulting database is called SyllabO. In this article, we present the elaboration of the corpus and database, and describe the web application that provides access to it. We also present an overview of the corpus data extracted from SyllabO.
2.2 Method
Corpus elaborationSpeech samples were collected from 184 different speakers (representing over 300,000 syllables). Samples were either obtained through online public resources (55%) – the recordings were all dated between 2000 and 2014 – or recorded by our team (45%), between the year 2013 and 2014. The ones obtained by our team were mainly recorded in a soundproof room, and a few (7%) were recorded at a lecture or conference, or at a participant’s home. Participants were all native speakers of Quebec French15 (mean age 52 ±19,7 years, range 20-97 years). The speech samples came from 95 male and 89 female speakers, divided into three age groups to ensure a balanced representation throughout all ages (20-45 years (mean 32 ±6,8 years), 46-70 years (mean 55 ±7,6 years, 71-97 years (mean 78 ±6,4 years)). The corpus is described in Table 2.
15 Participants were born in Quebec and reported Quebec French as their native language