Adaptive Markov random fields for joint unmixing and segmentation of hyperspectral image
13
0
0
Texte intégral
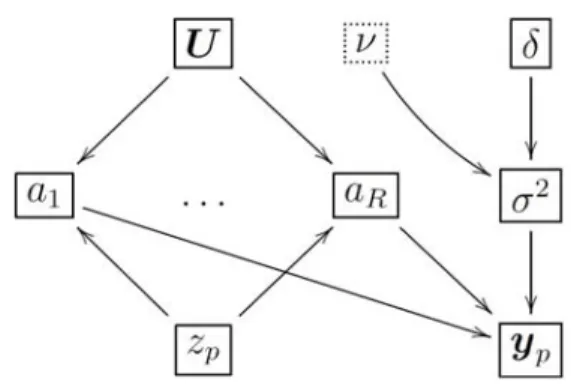
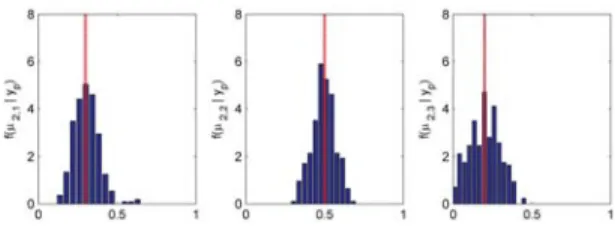
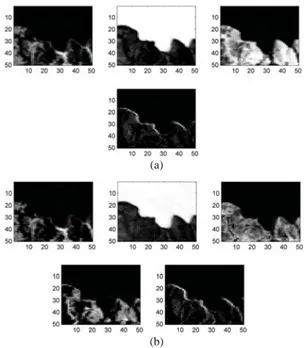
Figure


+3

Documents relatifs