Génération automatique de mélodie par la programmation par contraintes
85
0
0
Texte intégral
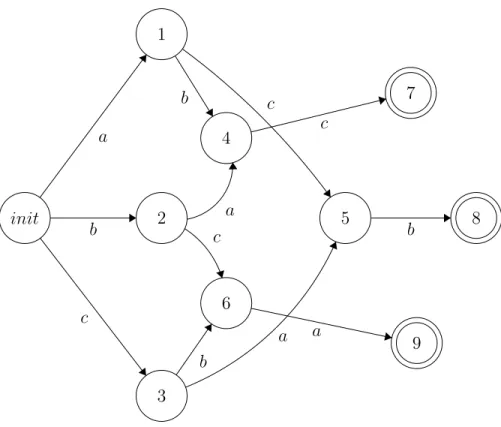
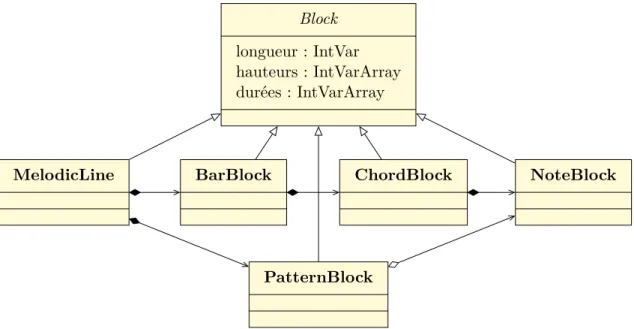
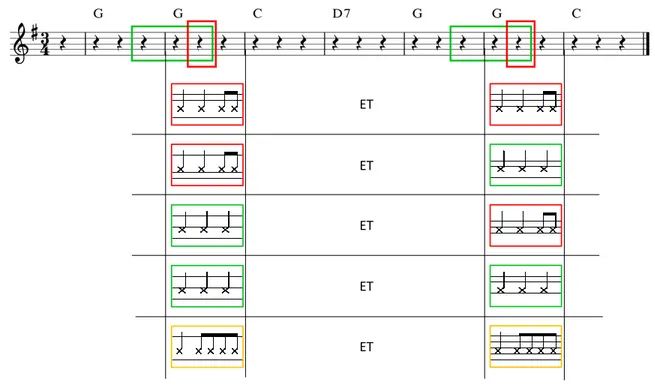
Figure



+7




Documents relatifs