On the data delivery delay taken by random walks in wireless sensor networks
Texte intégral
Figure
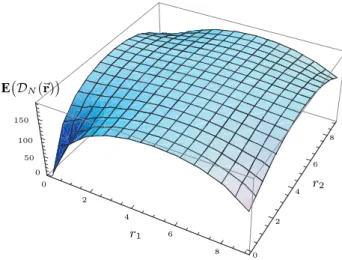
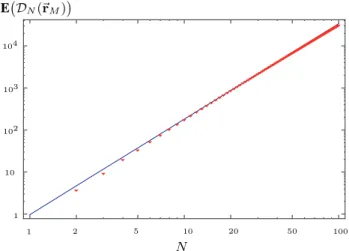
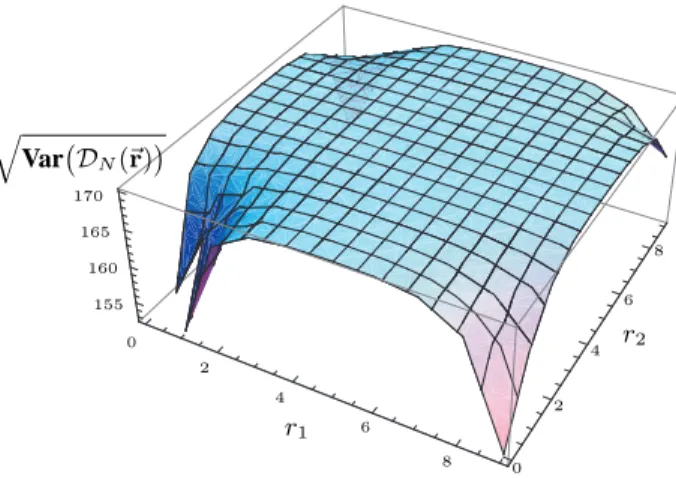
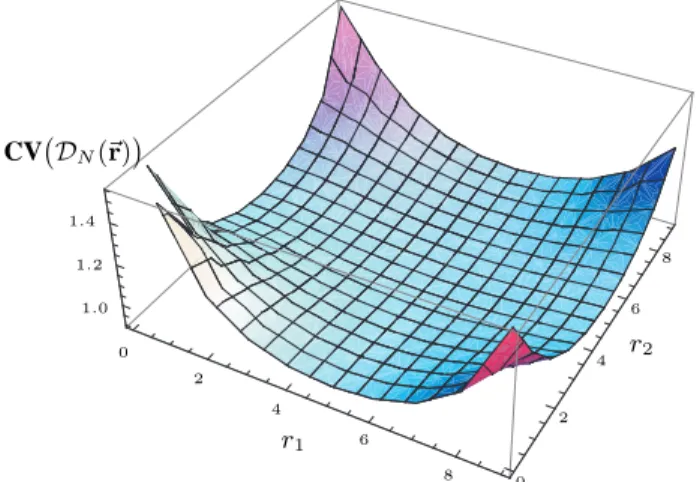
Documents relatifs
Our coloring algorithm contributes to maximize network lifetime by reducing the activity period as well as allowing any node to sleep in this period (in the slots that are not
This is explained by the fact that if the priority is given by the number of descendants, nodes close to the sink have the highest priority, and hence the probability that the
1) Where to aggregate is the objective of aggregation structure. This category defines how the aggregated data is routed towards the sink by using or creating a network structure,
Ce réservoir est constitué d'un cône surmonté d'un cylindre, comme le montre le dessin ci- contre. Le diamètre du réservoir est de 6 m , le cylindre mesure 35 m de hauteur et le
Directed diffusion (DD) was proposed as a robust data- centric dissemination protocol for WSNs in [5]; data generated by sensors are named by attribute-value pairs and all nodes
To send data to the base station, each sensor node may use a single-hop long distance link, which leads to the single hop network architecture, as shown in Figure 3.a).. 9
Then, two modulation schemes by which High Data Rate can be achieved are compared : Multi carrier approaches, represented by the popular Orthogonal Frequency Division
In this Section we present in detail the proposed approach which is based on an energy efficient video compression scheme and an Energy and Queue Buffer Size Aware routing
