Système de tableaux de bord personnalisables pour
l'optimisation et l'aide à la décision
Mémoire
Jean Bouchard
Maîtrise en informatique - avec mémoire
Maître ès sciences (M. Sc.)
Système de tableaux de bord personnalisables pour
l’optimisation et l’aide à la décision.
Mémoire
Jean Bouchard
Sous la direction de:
Jonathan Gaudreault, directeur de recherche Claude-Guy Quimper, codirecteur de recherche
Résumé
La planification des opérations dans un contexte industriel est une tâche complexe. Une bonne solution est difficile à obtenir, puisqu’elle doit respecter bon nombre de contraintes. Trouver la solution optimale est encore plus ardu. Pour ce faire, les entreprises ont recours à toutes sortes de méthodes, dont l’utilisation de modèles mathématiques d’optimisation. Bien que ces modèles fournissent une solution optimale, ils ne sont généralement qu’une approximation de la réalité.
Pour pallier cette situation, nous proposons un système de tableaux de bord personnalisables permettant l’ajout facile et dynamique de préférences de la part du décideur. Comme l’ajout successif de préférences peut mener à la situation où chaque nouvelle préférence efface les précédentes, le décideur peut ne jamais obtenir la solution désirée même si elle existe. Pour contrer cette limitation, nous proposons une méthode permettant d’imposer des préférences pour les modifications futures. Ceci permet donc au décideur de converger rapidement vers la solution désirée. Une série d’expérimentations montre que l’utilisation d’un solveur offrira une plus grande diversité de solutions que l’utilisation de notre méthode si plusieurs préférences sont imposées. Cependant, le temps requis pour trouver des solutions par notre méthode est largement inférieur au temps nécessaire par un solveur.
Le système de tableau de bord que nous avons développé permet uniquement l’utilisation de modèles linéaires, cependant les modèles à nombre entiers sont largement utilisés par les entre-prises. Pour étendre l’utilisation de notre système, nous proposons une extension à l’approche originale qui permet l’utilisation de modèles à nombre entiers avec notre système de tableau de bord.
Table des matières
Résumé iii
Table des matières iv
Liste des figures vi
Remerciements viii
Avant-propos ix
1 Introduction 1
2 Concepts préliminaires 3
2.1 Problèmes d’optimisation . . . 3
2.1.1 Utilisation des modèles en contexte industriel . . . 5
2.2 Systèmes à initiative partagée . . . 6
2.3 Systèmes à initiative partagée pour les modèles linéaires . . . 8
2.3.1 Ajout de seuils de tolérances . . . 13
2.3.2 Limitation des systèmes présentés . . . 14
3 Conception d’un système de tableau de bord générique interactif pour les systèmes à initiative partagée linéaires 16 3.1 Description du système proposé . . . 16
3.1.1 Engin de prétraitement des données . . . 17
3.1.2 Création d’un tableau de bord interactif . . . 18
3.2 Architecture de l’extension. . . 19
3.2.1 Patron Contrôleur . . . 22
3.2.2 Patron Observateur . . . 23
3.2.3 Patron État . . . 24
3.2.4 Patron Null Object . . . 25
3.3 Accélérer le moteur de prétraitement de données . . . 26
3.4 Application industrielle . . . 28
4 Ajout de contraintes pour converger vers la solution désirée 32 4.1 Description de l’algorithme . . . 32
4.1.1 Inconvénient de notre algorithme . . . 37
4.2 Expérimentation . . . 38
4.2.2 Résultats expérimentaux. . . 40
5 Prise en charge des variables entières 43
5.1 Description de la méthode proposée. . . 43
5.1.1 Obtenir les espaces de solutions . . . 45
5.1.2 Obtention d’une nouvelle solution lorsque l’utilisateur émet une
nou-velle préférence . . . 47
5.1.3 Limitation du calcule de plusieurs polytopes. . . 49
5.2 Expérimentations comparant la méthode utilisant plusieurs polytopes à celle
de Hamel . . . 50
5.2.1 Métrique utilisée pour comparer notre méthode à celle de Hamel . . 51
5.2.2 Protocole expérimental. . . 53
6 Conclusion 56
Bibliographie 58
A Modèles mathématiques 60
A.1 Modèle mathématique linéaire du problème de l’usine d’huile . . . 60
A.2 Modèle de l’usine contenant des nombres entiers. . . 61
Liste des figures
2.1 Représentation graphique du modèle de l’équation 2.1 . . . 4
2.2 Processus itératif d’optimisation . . . 6
2.3 Représentation graphique d’une frontière Pareto. . . 7
2.4 Ajout des min/max pour un modèle contenant 10 variables d’intérêts. . . 9
2.5 Une représentation de l’espace solution accessible.. . . 11
2.6 Exemple du fonctionnement de l’heuristique bipolaire. . . 12
2.7 Exemple d’utilisation de l’heuristique triangulaire . . . 12
2.8 Exemple de requête faite par le décideur menant à des solutions sous-optimales. 13 2.9 Application de la méthode par paliers de Chéné. . . 14
2.10 Interface utilisateur proposée par Chéné et al. . . 15
3.1 Représentation schématique de notre système . . . 17
3.2 Exemple d’une feuille Data de notre extension. . . 18
3.3 Exemple d’une modification d’un utilisateur. . . 21
3.4 Dépendances entre les composantes et les librairies de notre extension. . . 21
3.5 Étape exécutée lors de la modification d’une variable. . . 22
3.6 Modélisation du patron de l’Observateur. . . 23
3.7 Diagramme d’état de la feuille représentant la Data. . . 24
3.8 Modélisation du patron du State Pattern. . . 25
3.9 Diagramme d’activité représentant l’algorithme de filtrage.. . . 27
3.10 Résolution en parallèle des optimisations . . . 28
3.11 Exemple d’un réseau représenté par LogiLab. . . 29
3.12 Exemple d’une page d’un tableau de bord . . . 30
3.13 Feuille montrant les variables de transport présentes dans le modèle. . . 31
4.1 Représentation d’un ajout de contrainte . . . 33
4.2 Exemple de recherche d’intersection entre le polytope et l’hyperplan ajouté. . . 34
4.3 Inconvénient de notre algorithme . . . 37
4.4 Représentation de notre métrique . . . 39
4.5 Résultat de nos expérimentations . . . 41
5.1 Application de méthode de Hamel sur un MIP . . . 44
5.2 Calcul d’un espace solution en imposant des valeurs entières aux variables. . . . 45
5.3 Exemple de tous les polytopes trouvés. . . 46
5.4 Utilisation de l’heuristique triangulaire . . . 47
5.5 Changement de polytope lors d’une modification . . . 48
5.6 Solution contenue dans aucun polytope. . . 49
5.8 Représentation 1D des valeurs d’une variable . . . 52
5.9 Calcule de la plage d’une variable . . . 52
5.10 Comparaison des plages de valeurs de notre méthode avec celle de Hamel pour
des problèmes à nombres entiers. . . 54
Remerciements
Je tiens à remercier mon directeur de recherche, Jonathan Gaudreault, ainsi que mon codi-recteur Claude-Guy Quimper qui ont tous les deux fortement contribué à l’élaboration de ce mémoire.
Merci également à toute l’équipe du Consortium de recherche FORAC, en particulier à Phi-lippe Marier et Edith Brotherton qui ont collaboré à ce projet.
Avant-propos
Ce travail de maîtrise a été entrepris avec comme objectif de produire un outil de prise de décision utilisant les plus récentes avancées dans le domaine des systèmes à initiative partagés. Pour ce faire, nous avons implémenté une méthode permettant l’ajout de préférences par l’utilisateur lorsqu’il analyse la solution d’un problème linéaire.
Ce mémoire décrit notre application ainsi que les nouvelles fonctionnalités proposées pour rendre l’expérience plus conviviale. Nous avons testé notre application avec un partenaire du Consortium de recherche FORAC lors de la planification des blocs de coupe de la prochaine année.
Les résultats ont été publiés dans un article de conférence (avec comité de lecture) présenté en annexe (Mixed-initiative system for tactical planning allowing real-time constraint insertions, IFAC2017 World Congress, France, 9-14 Juillet 2017 ). Pour cet article dont je suis le premier auteur, j’ai réalisé toutes les expérimentations. Les coauteurs sont mon directeur, mon codirec-teur, les professionnels de recherche Philippe Marier (qui m’a conseillé pour les fonctionnalités de notre application), Edith Brotherton (qui m’a fourni les données du partenaire industriel) et le stagiaire Nathaniel Simard (qui a implémenté des portions de notre système).
Chapitre 1
Introduction
Dans un contexte industriel complexe, l’optimisation de la chaîne de valeur et la planification des opérations est une tâche ardue. Beaucoup de facteurs sont à considérer et peu de temps est disponible pour élaborer une solution. Ainsi, les industriels ont recours à des méthodes mettant à profit la vitesse de calcul d’un ordinateur pour mener à bien cette tâche. Deux approches sont couramment utilisées. La première est l’utilisation d’outils entièrement automatiques. Avec cette approche, le problème est d’abord décrit avec un modèle mathématique puis il est résolu à l’aide d’un solveur. La deuxième méthode est davantage manuelle. Le décideur cherche à trouver une solution satisfaisante par essai et erreur à l’aide d’un outil plus ou moins automatisé. Les différentes solutions sont analysées en utilisant un logiciel, tel qu’Excel, pour obtenir une rétroaction sur la qualité de la solution.
Ces deux méthodes souffrent de limitations majeures. En effet, la méthode entièrement auto-matique offre peu de rétroaction pour que le décideur puisse aisément comprendre et analyser la solution obtenue. La méthode manuelle, quant à elle, requiert beaucoup de temps et ne garantit pas que la solution retenue sera optimale ou même de bonne qualité. De plus, ces deux approches requièrent le développement d’une application spécialisée à chaque problème pour bien analyser la solution.
Les systèmes à initiative partagée (SIP, ou en anglais Mixed-Initiative Systems) permettent de combiner ces deux approches [2]. Un SIP spécialisé pour les problèmes ayant une structure linéaire fut développé par Hamel et al. [10] et étendu par Chéné et al. [4]. L’utilisation de ce système permet au décideur de facilement visualiser une solution, c’est-à-dire visualiser la valeur des différentes variables ainsi que la valeur minimale et maximale que chaque variable peut prendre. De plus, le système offre la possibilité au décideur de modifier la valeur des variables. Cette modification correspond à l’ajout de préférences. À chaque modification, le système recalcule instantanément une nouvelle solution et la réaffiche à l’utilisateur. Ce sys-tème permet donc l’ajout de préférences de la part d’un décideur lorsqu’il effectue l’analyse de la solution. Cependant, pour effectuer une bonne analyse, le décideur doit disposer d’une
interface graphique suffisamment expressive pour bien comprendre la solution présentée. À l’heure actuelle, une nouvelle interface doit être entièrement développée pour s’adapter aux différents problèmes, ce qui représente une tâche considérable.
Pour faciliter l’adoption du SIP proposé par Hamel et al., nous proposons un système de création de tableaux de bord générique utilisant Excel. Ce système permet au décideur de facilement créer lui-même une interface offrant la meilleure schématisation de la solution per-mettant son analyse. De plus, notre système utilise la méthode de Hamel pour inclure les préférences du décideur et recalculer une nouvelle solution instantanément. Cependant, bien que la méthode de Hamel tente de minimiser les changements entre la solution actuellement visualisée et la nouvelle solution calculée, il peut arriver que certaines modifications ignorent constamment les préférences précédentes. Cet effet peut donc empêcher le décideur d’atteindre la solution qu’il désire visualiser même si cette dernière existe. Pour résoudre ce problème, nous proposons un algorithme qui permet au décideur d’imposer une valeur à une variable pour toutes les solutions qui seront trouvées ultérieurement.
De plus, comme les problèmes industriels possèdent généralement des nombres entiers, la méthode de Hamel ne peut être utilisée puisqu’elle se limite aux problèmes ayant une structure linéaire. Ainsi, cette limitation doit être considérée pour permettre l’adoption d’un tel système en contexte industriel. Pour ce faire, nous avons étendu la méthode proposée par Hamel pour permettre d’utiliser de tels problèmes. Notre nouvelle approche permet donc à notre système de tableau de bord d’utiliser des problèmes contenant des nombres entiers.
Dans un premier temps, les concepts préliminaires seront expliqués. Par la suite, nous dé-taillerons notre système de tableau de bord Excel et nous présenterons une étude de cas avec une entreprise forestière canadienne. Ensuite, nous exposerons notre algorithme permettant d’imposer une valeur à une variable pour toutes les modifications ultérieures ainsi que des expérimentations montrant sa convivialité. Pour terminer, nous présenterons notre nouvelle approche permettant d’utiliser des problèmes contenant des variables entières ainsi que les expérimentations montrant les performances de cette nouvelle méthode.
Chapitre 2
Concepts préliminaires
Ce chapitre présente d’abord ce qu’est l’optimisation de modèles mathématiques ainsi que son utilisation en contexte industriel. Par la suite, nous expliquons ce que sont les Systèmes à initiative partagée (SIP) et leurs principales utilisations. Nous verrons plus en détail les SIP spécialement conçus pour être utilisés dans un contexte d’optimisation linéaire.
2.1
Problèmes d’optimisation
Pour un problème de prise de décision comportant des centaines de milliers de variables, la meilleure solution peut être difficile à trouver. Pour ce faire, les décideurs ont recours à la modélisation mathématique pour représenter leur problème sous la forme d’un système d’équations. Par la suite, un solveur mathématique utilise différents algorithmes pour trouver la solution au problème.
Différents types de modèles mathématiques et techniques de résolution sont possibles. Les plus courants sont les modèles de programmation linéaire (PL) et les modèles de programmation par contraintes (PPC). Dans tous les cas, un modèle est constitué den variables et d’un ensemble dem contraintes prenant la forme d’équations. Les variables représentent les options possibles. Les contraintes représentent des limitations sur les valeurs pouvant être prises par les variables dans sa portée, c’est-à-dire les variables affectées par la contrainte. Le solveur doit affecter aux variables des valeurs valides, c’est-à-dire qu’elles doivent respecter les contraintes. La solution se présente donc sous la forme d’un vecteur de longueur n où la ième composante représente la valeur de la ième variable.
Si l’objectif est uniquement de trouver une solution satisfaisant les contraintes, on parle alors d’un problème de satisfaction de contraintes. Si l’on veut définir un modèle d’optimisation, une fonction-objectif est ajoutée au modèle. Cette fonction sert à évaluer la qualité d’une solution. Le solveur cherche alors à trouver la solution qui maximise ou minimise la valeur de la fonction objectif.
Puisque différents types de modèles existent, différents solveurs sont offerts pour les résoudre. Les différences entre tous ces modèles résident dans les différentes contraintes qu’il est permis de spécifier et l’ensemble des valeurs que les variables peuvent prendre. Dans un modèle li-néaire classique, les variables doivent obligatoirement appartenir à l’ensemble des réels et les contraintes doivent être des équations (ou inéquations) linéaires. Ces restrictions permettent d’obtenir un espace de recherche convexe (un polytope). La solution optimale, s’il en existe une, se trouvera sur un de ses sommets. S’il existe plus d’une solution optimale, les solutions se trouveront sur une face. Ces modèles sont généralement résolus grâce à l’algorithme du Simplex de Dantzig [5]. Les équations 2.1 montrent un exemple de modèle linéaire simple et la figure 2.1est le polytope formant l’espace de recherche.
max 2x + y s.t. x + y ≤ 10 −x + y ≤ 3 x − y ≤ 5 x , y ≥ 0 (2.1)
x + y 10
x + y 3
x y 5
Figure 2.1 – Représentation graphique du modèle de l’équation 2.1
(lorsque toutes les variables doivent être entières), ou programmation linéaire mixte avec nombres entiers (lorsque seulement certaines variables sont des nombres entiers). Ces pro-blèmes sont plus difficiles à résoudre, puisque le problème ne forme plus un espace convexe. Cependant, les contraintes demeurent des équations linéaires. La résolution de ces problèmes utilise aussi l’algorithme du Simplex. Cependant, pour restreindre les solutions à des nombres entiers, la recherche de valeur entière se fait à l’aide de l’algorithme « Branch and Bound » [16]. Lors de l’utilisation de cette technique, le modèle est premièrement résolu comme s’il s’agissait d’un modèle linéaire. Par la suite, le modèle est résolu en ajoutant des contraintes pour obtenir des variables entières.
Le dernier type de modèle couramment utilisé est la programmation par contrainte (PPC). Les variables de ce type de modèle peuvent être des nombres réels ou entiers, ou même prendre des valeurs symboliques. Les contraintes ne sont plus limitées à prendre la forme d’équa-tions linéaires, elles peuvent être constituées d’expressions plus expressives. Par exemple, la contrainte AllDifferent signifie que toutes les variables dans sa portée doivent prendre des valeurs différentes pour que la solution soit valide.
Trouver la solution optimale pour ce type de problème s’effectue généralement en parcourant un arbre de recherche. Chaque noeud représente une affectation d’une valeur à une variable. Ultimement, les feuilles représentent les solutions valides au problème (chaque variable ayant une valeur) si aucune contrainte n’est violée. Ainsi lorsque l’algorithme de recherche parcourt l’arbre, pour chaque noeud il doit affecter une valeur à une variable. C’est ce qui s’appelle faire un branchement dans l’arbre. Pour conclure qu’une solution est optimale, l’arbre doit être exploré dans sa totalité. Cependant, la taille d’un tel arbre croît exponentiellement en fonction du nombre de variables. Il est donc impossible de simplement essayer toutes les combinaisons possibles, car le temps nécessaire serait trop long.
Ainsi, pour résoudre ces problèmes en un temps acceptable, la dimension de l’arbre est réduite à l’aide d’algorithmes de filtrage. Ces algorithmes sont appliqués à chaque branchement dans l’arbre pour retirer les branches qui invalideront à coup sûr la solution. Ces algorithmes se spécialisent pour une contrainte particulière. Pour permettre d’obtenir un résultat rapidement, un algorithme de filtrage met à profit la structure unique de la contrainte qu’il filtre. Ainsi, les variables déjà affectées permettent à l’algorithme de déduire rapidement (sans essayer toutes les combinaisons) les prochaines affectations valides que le solveur pourra essayer.
2.1.1 Utilisation des modèles en contexte industriel
Dans un contexte industriel, plusieurs étapes précèdent l’adoption d’une solution provenant d’un modèle mathématique. Dans un premier temps, le modèle doit être créé. Cette étape demande la transcription de contraintes réelles en équations mathématiques. Une fois le modèle construit, il est résolu à l’aide d’un solveur mathématique.
Une fois une solution trouvée, elle doit être analysée par un décideur pour déterminer si elle pourra être appliquée. Bien que la solution soit optimale pour le solveur, il est possible que certaines contraintes aient été omises. Cette étape est nécessaire, car bien que la solu-tion soit optimale mathématiquement, il est difficile, voire impossible, de modéliser toutes les contraintes d’un problème. Certaines approximations doivent être faites pour résoudre le modèle en un temps raisonnable et certains concepts ne sont connus que par l’humain. Ainsi, le décideur regardera les différentes valeurs des variables pour déterminer si la solution est réalisable en utilisant son expérience. Cette analyse s’effectuera généralement en utilisant un logiciel, tel qu’Excel, pour obtenir une compréhension des valeurs observées. De plus, cer-taines contraintes sont généralement découvertes par le décideur en analysant la solution [12]. Ainsi, pour inclure ces nouvelles contraintes « fantômes », le modèle doit être adapté par l’ajout de nouvelles contraintes ou par la modification de contraintes déjà existantes. Pour obtenir une nouvelle solution, l’optimisation doit être refaite et l’analyse reprend. Ce procédé itératif est représenté par le schéma de la figure 2.2.
Méthode traditionnelle
Préparation du modèle
mathématique. Calcul de la solution. Analyse de la solution.
Oui
Non
Modification du modèle pour répondre aux nouvelles exigences.
Solution satisfaisante?
Figure 2.2 – Processus itératif d’optimisation. Inspiré de Hamel [9]
Ces itérations sont laborieuses puisqu’il est difficile d’intégrer toutes les préférences des déci-deurs dans les modèles. Pour ce faire, un système hybride permettant une interaction entre le décideur et l’ordinateur est tout indiqué pour accélérer le processus. Nous décrivons ce type de système dans la prochaine section.
2.2
Systèmes à initiative partagée
Les Systèmes à initiative partagée (SIP, en anglais Mixed-Initiative systems ou MIS) sont élaborés pour permettre à plusieurs agents de contribuer à la résolution d’un problème [2]. Dans le cas qui nous intéresse, nous référons spécifiquement à l’interaction entre l’homme et l’ordinateur. Lors de l’élaboration d’un SIP, il faut déterminer les tâches effectuées par les différents agents. Ainsi, différents modèles de SIP furent proposés où chacun divise les tâches différemment entre les agents. Dans certains types de SIP, les agents effectueront des tâches différentes en parallèle alors que dans d’autres systèmes, les agents échangeront l’initiative.
L’utilisation de SIP s’est d’abord répandue pour la résolution de problèmes non linéaires tels que la planification de missions sur Mars [1; 3] ou la coordination du trafic aérien [8]. L’implication d’un humain peut servir deux stratégies différentes. Premièrement, le temps de résolution peut-être diminué en permettant à un humain de « guider » l’algorithme vers la solution optimale grâce à son intuition [12]. Deuxièmement, le degré de satisfaction du décideur envers la solution peut-être augmentée en lui permettant d’ajouter dynamiquement des contraintes ou préférences pendant le processus de résolution [3].
Dans le domaine de l’optimisation multi-objectifs, la qualité d’une solution est généralement difficile à évaluer. Le décideur doit analyser un ensemble de solutions mathématiquement équivalentes formant la frontière Pareto. Bien que chaque solution soit différente, elles sont toutes optimales quant à une des fonctions objectifs. Ainsi, la solution retenue dépendra de la fonction sur laquelle le décideur voudra mettre l’emphase. Par exemple, la figure 2.3montre une frontière Pareto pour un problème à deux variables. Toutes les solutions se trouvant sur la courbe sont acceptables, mais les variables prennent des valeurs différentes. Si la solution A est retenue, le décideur obtiendra une solution qui favorise une plus grande valeur pour la variablea. Le même phénomène se produira pour la variable b si la solution B est retenue.
Figure 2.3 – Représentation graphique d’une frontière Pareto.
Comme toutes ces solutions sont intéressantes pour un décideur, certains SIP permettent d’explorer la courbe Pareto à l’aide d’une interface graphique [17;14]. Ces systèmes montrent
bien l’importance d’une interface graphique intuitive pour faciliter la compréhension du déci-deur lors de l’analyse, car uniquement visualiser une solution sous la forme d’un vecteur est complexe et non expressif.
2.3
Systèmes à initiative partagée pour les modèles linéaires
À ce jour, peu de SIP ont été développées pour les problèmes linéaires. Bien que ces problèmes soient plus faciles à résoudre, l’application de telles méthodes pourrait faciliter l’adoption des modèles en contexte industriel. Un premier système à initiative partagée pour la résolution de modèles linéaires fut élaboré par Hamel et al [10;9]. Ce système permet d’ajuster la solution d’un problème linéaire sans en dégrader la qualité. Dans ce contexte, on explore le sous-espace des solutions optimales, mais de manière interactive. Il permet à un décideur de modifier la valeur d’une variable à l’intérieur de sa plage de valeurs possibles. Le système calcule alors en temps réel la nouvelle valeur des autres variables de manière à maintenir l’optimalité de la solution. Ainsi, l’utilisateur peut ajuster la solution de manière interactive en fonction de ses préférences.
Pour répondre aux modifications d’un utilisateur en temps réel, réoptimiser entièrement le modèle est trop coûteux. Pour ce faire, le système se limitera à calculer de nouvelles solutions à partir d’un ensemble de solutions précalculées avant l’interaction avec l’utilisateur. Pour ce faire, des variables d’intérêts doivent être préalablement identifiées par un utilisateur. Ces va-riables sont celles que le décideur risque de vouloir modifier. Cette énumération est nécessaire, puisque le décideur ne s’intéresse qu’à un sous ensemble des milliers de variables présentes dans un modèle.
Pour garantir l’optimalité des nouvelles solutions trouvées, le système trouve les nouvelles solutions en combinant différentes solutions optimales obtenues au préalable. Ce procédé pro-cure de nouvelles solutions optimales puisque la combinaison concave de solutions optimales est aussi une solution optimale [16]. Ainsi, la combinaison de différentes solutions optimales (si) permet d’obtenir une nouvelle solution optimale (s0) à l’aide des équations 2.2.
n X i=0 αisi = s0 n X i=0 αi = 1 ∀αi ∈ [0, 1] (2.2)
Lors de l’utilisation du SIP de Hamel, le décideur modifie une solution en identifiant la variable qu’il souhaite modifier (xj) de même que la valeur désirée (vj0). L’objectif est de trouver une nouvelle solution S0 où la variable modifiée par l’utilisateur prend la valeur demandée (Sj0 =
v0
j). Pour ce faire, le système doit déterminer les différents poids (α) de la combinaison linéaire pour satisfaire la préférence du décideur, c’est-à-dire résoudre le système de l’équation 2.2. Résoudre un tel système peut s’avérer coûteux, surtout s’il contient beaucoup de variables, car plusieurs valeurs de α sont possibles. Il est possible de simplifier la résolution d’un tel problème en se limitant à la combinaison de deux solutions, y et z (équation 2.3). Ainsi, la valeur deα devient triviale à trouver, puisqu’une solution unique existe.
αy + (1− α)z = S0 (2.3)
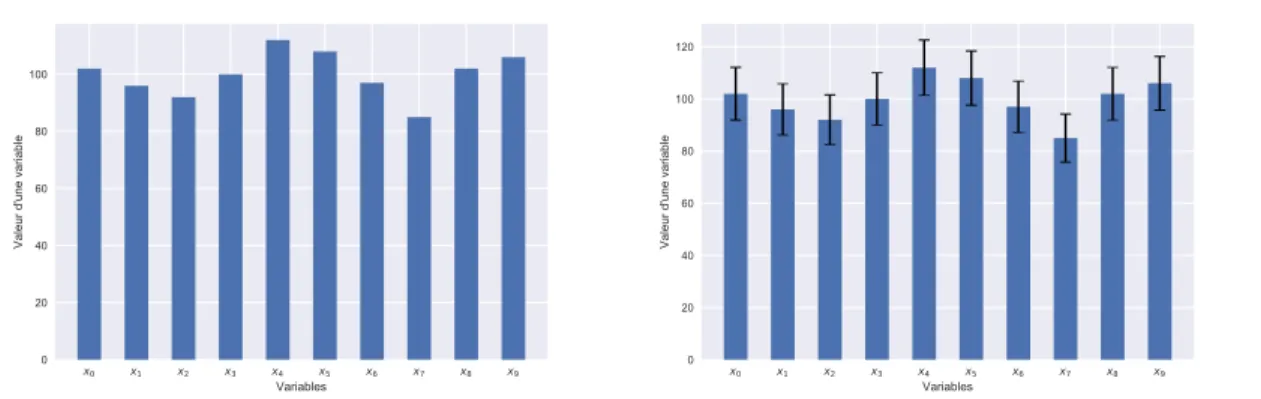
Pour permettre au décideur de visualiser la plage des valeurs disponibles, la solution minimi-sant chaque variable et la solution maximiminimi-sant chaque variable seront calculées. Ces solutions permettent d’indiquer au décideur les valeurs acceptées lors de la modification d’une solution. La figure 2.4montre une représentation d’un modèle contenant 10 variables d’intérêts. Sur la figure de droite, il est possible d’observer les limites que peut prendre chaque variable pour conserver une solution optimale.
x0 x1 x2 x3 x4 x5 x6 x7 x8 x9
(a) Solution unique retournée par le solveur.
x0 x1 x2 x3 x4 x5 x6 x7 x8 x9
(b) La solution augmentée avec les min/max pour toutes les variables.
Figure 2.4 – Ajout des min/max pour un modèle contenant 10 variables d’intérêts. Ces minimums et maximums sont trouvés en optimisant plusieurs fois le modèle sous la contrainte que la valeur de la fonction-objectif demeure optimale. Par exemple, pour le mo-dèle décrit par les équations 2.4 la valeur de la fonction objectif à maximiser est −10. S’il faut trouver le maximum de la variable x, le modèle sera modifié pour former le modèle des équations 2.5. Par la suite, la résolution de ce modèle fournira une solution optimale oùx est à sa valeur maximale. Il faudra donc effectuer au total2n + 1 optimisations où n est le nombre de variables d’intérêts. Toutes ces optimisations forment ainsi un ensemble de 2n solutions qu’il sera possible de combiner pour répondre aux modifications du décideur.
max x− y s.t. x ≥ 10 y ≤ 20 (2.4) max x s.t. x ≥ 10 y ≤ 20 x− y = −10 (2.5)
Ces solutions forment un sous-ensemble de l’ensemble des solutions optimales du modèle. De plus, ce sous-ensemble forme un ensemble convexe, c’est-à-dire que tous les points sont atteignables par une transformation linéaire. La figure 2.5représente graphiquement le sous-ensemble ainsi formé pour un problème (imaginaire) à deux variables. Le point vert sx re-présente la solution minimisant x et le point vert sx représente la solution maximisant x. Similairement, les points orange représentent les solutions minimisant et maximisant la va-riable y. Toutes les solutions se trouvant dans le carré gris sont des solutions optimales et le losange bleu représente les solutions atteignables par la combinaison linéaire des quatre solutions identifiées.
Avec un sous-ensemble de solutions optimales disponible, les différentes solutions de cet en-semble doivent être combinées efficacement pour répondre à la demande du décideur. Deux critères ont été utilisés pour évaluer les méthodes proposées par Hamel et al. : la stabilité et la réactivité. La réactivité correspond au temps nécessaire pour obtenir une nouvelle solution. L’objectif étant de concevoir un système temps réel, l’utilisateur voudra obtenir les nouvelles solutions immédiatement. La stabilité correspond à la similitude entre la solution actuellement disponible et la nouvelle solution calculée. Un utilisateur souhaitera obtenir une solution simi-laire si le changement demandé est petit, c’est-à-dire que l’on veut minimiser le changement des valeurs des autres variables de décision.
Plusieurs méthodes furent proposées par Hamel et al. [10] pour respecter les critères préalable-ment établis. La première méthode détermine la combinaison linéaire qui minimise la distance euclidienne entre la solution courante et la nouvelle solution obtenue. Pour ce faire, un modèle non linéaire doit être résolu à l’aide d’un solveur. Cette méthode procure une bonne stabilité, par contre elle demande beaucoup de temps de calcul. Pour améliorer la réactivité, un modèle linéaire minimisant plutôt le plus grand changement de variable a été testé. Ce modèle est plus rapide à résoudre que le précédent et procure une bonne stabilité. Par contre, bien qu’il y ait une amélioration par rapport au modèle précédent, l’utilisation d’un solveur demeure quand même un facteur pénalisant en termes de réactivité.
Pour améliorer la rapidité du système, toute utilisation d’un solveur doit donc être abandonnée au profit d’heuristiques. Hamel a donc proposé une heuristique dite bipolaire qui combine
X
Y
𝑠
𝑥𝑠
𝑦𝑠
𝑥𝑠
𝑠
𝑦Figure 2.5 – Une représentation de l’espace solution accessible.
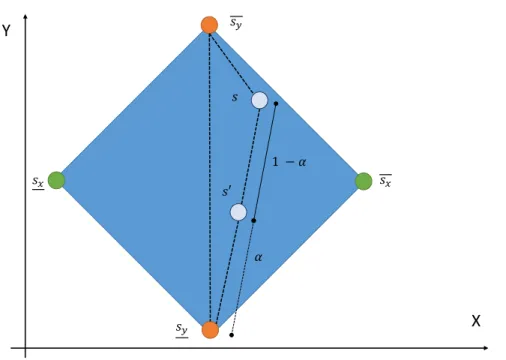
linéairement la solution minimum et la solution maximum de la variable modifiée (xi). Ceci permet d’atteindre tous les points se trouvant sur l’hyperplan formé par ces deux points (voir figure 2.6). Pour trouver cette solution, il suffit de trouver un α tel que S0 = αsi+ (1− α)si. Bien que cette heuristique soit très réactive, la nouvelle solution obtenue est généralement très différente de la solution originale (il y a donc une grande instabilité).
Pour augmenter la stabilité, l’heuristique triangulaire a ensuite été proposée par Hamel. Cette méthode consiste à effectuer une combinaison linéaire entre la solution courante et la solution min ou max de la variable modifiée (dépendamment de si l’utilisateur a demandé une dimi-nution ou une augmentation de la variable). Si l’utilisateur souhaite diminuer la valeur d’une variable (xi), la solution minimisant cette variable sera utilisée dans la combinaison linéaire. Ainsi, la combinaisonS0 = αs + (1− αs
i) déterminera la nouvelle solution. Inversement, si la valeur de la variable xi est augmentée, la solution maximisant xi est utilisée et la combinai-son linéaire S0 = αs + (1− αs
i) déterminera la nouvelle solution. L’utilisation de la solution courante permet de conserver la stabilité désirée lors de la combinaison (voir figure 2.7).
𝑠 𝑠′ 𝑠𝑥 𝑠𝑦 𝑠𝑥 𝑠𝑦
X
Y
Figure 2.6 – Exemple du fonctionnement de l’heuristique bipolaire.
1 − 𝛼 𝛼
X
Y
𝑠𝑥 𝑠𝑦 𝑠𝑥 𝑠𝑦 𝑠 𝑠′2.3.1 Ajout de seuils de tolérances
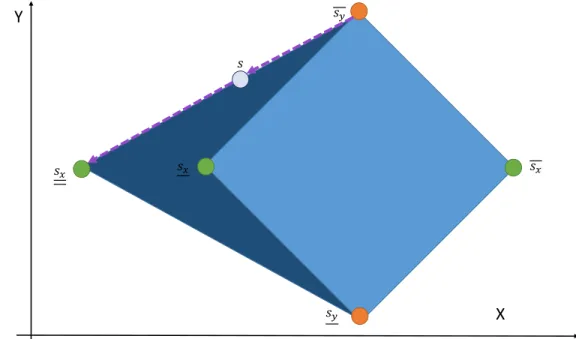
Avec l’approche proposée par Hamel, on visite uniquement des solutions optimales. Par contre, des solutions sous-optimales revêtent parfois un intérêt pour le décideur. Elles peuvent consti-tuer un bon compromis qui permet de respecter la contrainte du décideur (il est parfois impos-sible de modifier une variable en conservant l’optimalité). De plus, étant donné que le modèle et ses données sont parfois des approximations de la réalité, tolérer une sous-optimalité est souvent plus qu’acceptable. Pour rendre ces solutions accessibles, Chéné et al. [4] ont étendu la méthode de Hamel de manière à inclure des seuils de tolérance. Chaque seuil est un pourcen-tage représentant la dégradation de la fonction-objectif. Ainsi, une tolérance de 10% signifie que la qualité des solutions pour ce seuil ne doit pas être inférieure à 90% de la qualité opti-male. Par exemple, si la fonction-objectif a une valeur optimale de200 (en maximisation), les solutions correspondant à une tolérance de 10% auront une valeur supérieure ou égale à 180 (0.9× 200 = 180).
L’heuristique triangulaire peut être modifiée (de manière naïve) de manière à inclure une tolérance sur la fonction objective. Pour ce faire, toutes les solutions formant l’espace solution sont obtenues en appliquant une tolérance sur la fonction objectif. Cependant, cette approche ne fournira pas toujours une solution optimale lors de l’ajout de préférence bien qu’elle serait théoriquement atteignable. Ce phénomène est mis en lumière à la figure 2.8. Les solutions retournées se trouvent sur les limites du polygone lors de modification rapides vers une solution extrême. De plus, ce phénomène se trouve amplifié lorsque la tolérance augmente.
X
Y
𝑠𝑥 𝑠𝑦 𝑠𝑥 𝑠𝑦 𝑠 𝑠𝑥Pour obtenir une solution optimale, s’il en existe une, Chéné et al. ont ajouté des paliers à la méthode de Hamel. L’algorithme combine alors les solutions au degré de tolérances les plus basses lorsque c’est possible. Ceci a donc pour effet de garder les nouvelles solutions à l’intérieur des régions procurant la meilleure optimalité lorsque cela est possible. La figure 2.9
montre que pour le même changement de valeur que la figure 2.8 une solution optimale est trouvée par l’algorithme.
X Y 𝑠𝑥 𝑠𝑦 𝑠𝑥 𝑠𝑦 𝑠 𝑠𝑥
Figure 2.9 – Application de la méthode par paliers de Chéné.
Pour utiliser cet algorithme, plus de temps de calcul est nécessaire que la méthode de Hamel lors du calcul des différentes solutions avant l’interaction avec le décideur. En effet, il faut trouver la solution maximisant chaque variable et la solution minimisant chaque variable pour chaque tolérance utilisée. Ainsi, lorsque le traitement est fait sur un modèle contenant n va-riables etm niveaux de tolérances, un total de 2nm optimisations sont nécessaires. L’approche proposée est intéressante pour un décideur, car elle permet d’explorer plus de solutions que l’utilisation de la méthode de Hamel et elle favorise les meilleures solutions disponibles. De plus, il est possible de connaître et de contrôler précisément la déviation de la fonction-objectif.
2.3.2 Limitation des systèmes présentés
Les méthodes de Hamel et Chéné semblent prometteuses puisqu’elles comblent un besoin cru-cial dans l’utilisation de modèles mathématiques en contexte industriel. Cependant, certains problèmes rendent leurs utilisations moins attrayantes. Dans un premier temps, aucune in-terface utilisateur suffisamment générique n’est disponible. Bien qu’une première inin-terface a été développée par Chéné et al. [4] pour les problèmes de la chaîne d’approvisionnement
(fi-gure 2.10), beaucoup de travail serait nécessaire pour l’adapter à un autre type de problème. Pour permettre une meilleure généralisation, nous proposons au chapitre 3 une interface uti-lisateur générique.
Figure 2.10 – Interface utilisateur proposée par Chéné et al. pour les problèmes de chaîne d’approvisionnement
Avec la méthode de Hamel, une deuxième limitation se présente lors de la modification d’une solution. Bien que l’heuristique triangulaire tente de maximiser la stabilité entre les solutions, certains cas pathogènes peuvent tout de même se produire. Le décideur peut se trouver dans la situation où les modifications précédentes sont continuellement supprimées par un changement ultérieur. À titre d’exemple, imaginons que nous avons deux variables, x1 etx2. Toutes deux ont respectivement une valeur, v1 etv2. Un utilisateur désire modifier la valeur dex1 pourv01. Inévitablement,x2 prendra une nouvelle valeur,v20. Par la suite, si l’utilisateur désire modifier x2, il est possible quex1 reprenne sa valeur originale (v1). Il peut donc être impossible pour le décideur d’atteindre la solution désirée (même si elle existe et qu’elle est optimale), car chaque modification efface continuellement la modification précédente.
À ce jour, aucun moyen ne permet de contrer cet effet de va-et-vient. Ainsi, nous proposerons un algorithme permettant d’imposer une valeur à une variable (« verrouiller » une variable) pour toutes les solutions subséquentes. Notre approche fera l’objet du chapitre 4.
La dernière limitation se trouve dans le type de problèmes pouvant être utilisé avec la méthode de Hamel. Les problèmes doivent absolument être linéaires pour que le théorème supportant l’approche soit valide. Comme bon nombre de problèmes industriels requièrent l’utilisation de variables entières, permettre au décideur d’ajouter ses préférences en temps réel à ces modèles est primordial. Pour ce faire, nous proposons une piste de solution au chapitre 5 mettant à profit la nature linéaire de ces modèles.
Chapitre 3
Conception d’un système de tableau
de bord générique interactif pour les
systèmes à initiative partagée linéaires
Pour permettre l’exploitation facile de la méthode de Hamel et de Chéné par des décideurs, nous avons développé une extension Excel permettant son utilisation au sein de tableaux de bord interactifs. L’utilisation d’Excel procure un avantage grâce à la flexibilité qu’offre ce logiciel pour la création de tableaux de bord. De plus, ce logiciel est largement utilisé et maîtrisé par les entreprises. Cela facilite l’utilisation de notre extension dans leur processus d’affaires.
Dans ce chapitre, nous allons d’abord expliquer le fonctionnement de notre système du point de vue de l’utilisateur. Par la suite, nous allons décrire l’architecture logicielle de l’extension et les différents points importants dans sa conception.
3.1
Description du système proposé
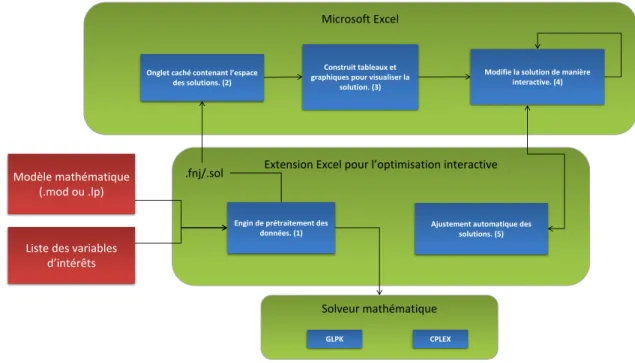
L’utilisation de notre système doit permettre de visualiser une solution avec la plage de valeurs de chaque variable. En plus, le décideur doit être en mesure de modifier la valeur des variables exposées. Pour ce faire, l’espace de solutions (les 2n solutions décrites à la section 2.3) doit être préalablement calculé. Par la suite, le décideur sera en mesure de visualiser et modifier la solution à l’aide d’un tableau de bord interactif qu’il peut modifier comme bon lui semble. Notre système est divisé en deux composantes. La première, l’engin de prétraitement des don-nées, permet d’effectuer les optimisations avant l’utilisation d’Excel. La seconde composante, l’extension Excel, permet d’interagir avec le décideur par le biais d’un tableau de bord inter-actif. Une représentation schématique de notre système est donnée à la figure 3.1.
Microsoft Excel
Onglet caché contenant l’espace des solutions. (2)
Construit tableaux et graphiques pour visualiser la
solution. (3)
Modifie la solution de manière interactive. (4)
Extension Excel pour l’optimisation interactive
Ajustement automatique des solutions. (5) Engin de prétraitement des
données. (1)
Solveur mathématique
GLPK CPLEX
Modèle mathématique (.mod ou .lp)
Liste des variables d’intérêts
.fnj/.sol
Figure 3.1 – Représentation schématique de notre système de tableau de bord interactif. Pour produire son tableau de bord interactif, l’utilisateur doit suivre différentes étapes. Premiè-rement, le modèle mathématique doit être résolu plusieurs fois par notre engin de prétraitement des données pour trouver les différentes solutions (1). Ce processus génère des fichiers qui se-ront par la suite utilisés par Excel (2) pour permettre la création d’un tableau de bord (3). Par la suite, le décideur sera en mesure de modifier la solution tout en demeurant dans Excel (4). Pour chaque modification demandée par le décideur, notre extension recalcule et réaffiche la nouvelle solution (5).
Dans les prochaines sous-sections, nous allons décrire les différentes étapes plus en détail. Dans un premier temps, nous allons décrire l’étape effectuant les différentes optimisations. Par la suite, nous allons expliquer le fonctionnement de notre extension Excel qui permet la création de tableaux de bord.
3.1.1 Engin de prétraitement des données
Le décideur doit d’abord identifier les différentes variables d’intérêts du modèle. Ceci est fait en écrivant leurs noms dans un fichier (.var). Les différentes optimisations du modèle mathématique sont ensuite exécutées. Ces optimisations produiront un fichier .fnj et un fichier .sol. Ces deux fichiers contiennent les solutions qui seront ensuite exploitées automatiquement dans un classeur Excel.
Pour résoudre le modèle, notre module utilise un solveur linéaire. Deux solveurs différents peuvent être utilisés, mais il serait possible d’adapter le module pour prendre en compte
d’autres solveurs. Le premier, GLPK [7], est un solveur « open source » faisant partie du projet GNU. Le deuxième, IBM ILOG CPLEX [11] qui est développé par IBM est un solveur pouvant résoudre des problèmes ardus. Ainsi, nous pouvons offrir notre application sans contrainte de licence grâce à GLPK et nous sommes en mesure de résoudre des problèmes industriels à l’aide de CPLEX.
À la suite de ce procédé, le décideur possède tous les fichiers nécessaires pour l’élaboration de son tableau de bord.
3.1.2 Création d’un tableau de bord interactif
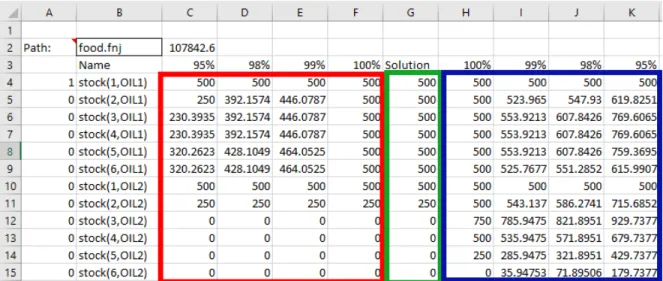
Lors de l’élaboration d’un tableau de bord interactif, la première étape est d’importer les fichiers des solutions obtenues à l’étape précédente. Cette tâche est réalisée de manière entiè-rement automatisée par notre extension. Pour déclencher l’importation, l’utilisateur n’a qu’à indiquer dans une cellule prédéfinie le chemin d’accès vers le fichier .fnj. Lors de l’importa-tion, les valeurs nécessaires sont insérées dans la feuille Data. Il s’agit de l’unique feuille ayant un format standardisé pour être utilisée par notre extension.
La feuille Data affiche à l’utilisateur le nom de chaque variable, leurs valeurs minimum et maximum pour les différentes tolérances ainsi que leur valeur dans la solution courante. Un exemple de cette feuille est disponible à la figure 3.2. Les colonnes encadrées en rouge repré-sentent les solutions minimisant les variables. Les colonnes encadrées en bleureprésentent les solutions maximisant les variables. La colonne centrale, encadrée envert, représente la solution courante. Cette dernière colonne sera continuellement modifiée par l’extension lors de l’ajout de préférences.
Figure 3.2 – Exemple d’une feuille Data de notre extension.
Une fois les solutions importées, l’utilisateur est en mesure de créer son tableau de bord en créant de nouvelles feuilles qui feront référence à la feuille originale. Il peut donc créer
tous les tableaux et les graphiques qui lui sont nécessaires. Une cellule du tableau de bord faisant référence à la feuille de départ affichera la valeur courante de la variable. Cependant, l’utilisateur pourra ensuite aller écraser cette valeur et l’extension Excel mettra ensuite à jour le reste de la solution de manière conséquente. Pour ce faire, le décideur doit sélectionner la cellule/variable dont il désire modifier la valeur (figure 3.3a). Par la suite, il inscrit à même la cellule la nouvelle valeur désirée pour cette variable (figure 3.3b). Ceci donne l’impression que l’utilisateur est en train de supprimer une référence, cependant notre extension entre alors en action.
La nouvelle solution qui satisfait la requête (préférence) de l’utilisateur est calculée et elle sera inscrite dans la colonne de la solution courante de la feuille initiale. Finalement, la référence est remise telle qu’elle était avant la modification (figure 3.3c). Rappelons que l’utilisateur utilise majoritairement des références vers la feuille Data pour construire son tableau de bord. Ainsi, lorsque l’extension modifie des valeurs, l’ensemble du classeur est modifié. Ces étapes sont illustrées par la figure 3.3.
Ce type de design a prouvé sa convivialité, puisqu’il a été possible de l’utiliser pour un problème industriel (voir section 3.4). Le modèle utilisé contenait plus de 60000 variables dont plus de 2000 étaient présentes dans le classeur. Pour permettre la production d’une application stable et fonctionnelle, plusieurs préoccupations et choix architecturaux se sont présentés. Ceci fera l’objet de la section 3.2.
3.2
Architecture de l’extension
Le développement de l’extension Excel a suivi un processus de développement logiciel complet. Il s’agit en fait d’une vraie application et non d’un simple ensemble de macros VBA. L’uti-lisation d’Excel comme interface graphique est un choix pour fournir une interface générique offrant de multiples fonctionnalités. De plus, Excel est une application déjà bien maîtrisée par les entreprises et largement utilisée dans leur processus d’affaires.
Notre extension est une application développée dans le langage C# qui communique avec Excel par l’intermédiaire de la technologie VSTO de Microsoft. Cette technologie rend accessible les fonctionnalités d’Excel via une librairie utilisable en C#. Ainsi, Excel devient une simple librairie d’interface graphique et les principes de génie logiciel peuvent être appliqués pour le développement de notre code. Il est alors possible, conformément aux bonnes pratiques du génie logiciel, de diviser l’application en différentes couches, d’effectuer des tests unitaires et éventuellement d’utiliser une autre interface utilisateur si désiré.
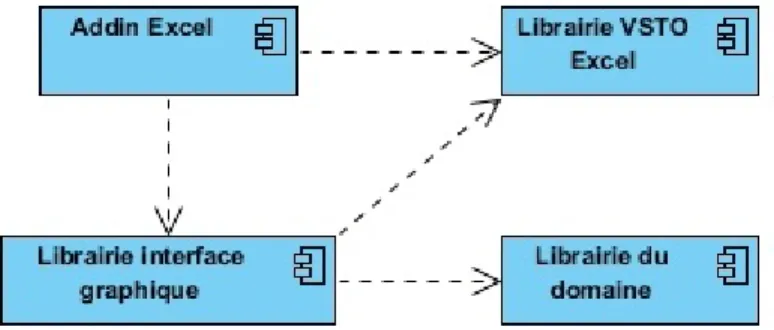
Pour bien séparer la logique applicative de la logique d’affichage, l’application est divisée en deux librairies. La première contient la logique applicative, c’est-à-dire les algorithmes et tout ce qui est nécessaire à la manipulation des différents fichiers. La deuxième librairie permet
d’in-(a) L’utilisateur sélectionne une cellule.
(b) L’utilisateur change une valeur.
teragir avec l’utilisateur par l’intermédiaire d’Excel. Cette séparation permet donc de réutiliser les algorithmes dans d’autres projets et de limiter les dépendances lors de la compilation. Ces deux librairies sont par la suite utilisées par le plugiciel Excel. Cette composante représente en quelque sorte l’exécutable (main) d’une l’application. C’est cette dernière composante qui est installée sur le poste de l’utilisateur et qui est exécutée par Excel. Le diagramme de composants UML de la figure 3.4représente les dépendances entre ces différents composants.
Une tâche importante du plugiciel Excel est de détecter les modifications aux cellules compor-tant des références vers la feuille Data pour modifier l’état de notre application en conséquence. Il est possible de demander d’être informé des actions associées à différents évènements (event ) d’Excel. Grâce à ces différents évènements, il est possible de détecter l’ajout de préférences par l’utilisateur en observant les changements de certaines cellules contenant une valeur spécifique. Nous détectons d’abord le changement de sélection de cellules (lorsque l’utilisateur clique sur
(c) Toutes les valeurs ont été modifiées.
Figure 3.3 – Exemple d’une modification d’un utilisateur.
Figure 3.4 – Dépendances entre les composantes et les librairies de notre extension. une nouvelle cellule). Si elle contient une référence vers la colonne de la solution courante, nous conservons en mémoire cette référence. Lorsqu’une modification survient (la valeur change) dans cette cellule, la nouvelle valeur est stockée. Si elle est valide, l’heuristique triangulaire de Hamel est alors utilisée pour obtenir la nouvelle solution. Par la suite, la colonne de la solution courante est mise à jour avec la nouvelle solution. Pour terminer, la référence effacée est remise à sa valeur initiale. Le diagramme d’activité UML de la figure 3.5 représente les différentes étapes permettant de modifier la valeur d’une variable.
Ces différentes actions sont possibles, car notre application communique librement avec Ex-cel. Cependant, d’un point de vue architectural, il est souhaitable de limiter les dépendances vers cette technologie car elle peut changer sans préavis. Le graphique de la figure3.4montre bien la direction des dépendances entre les composantes. Ce que nous pouvons remarquer est l’inversion des dépendances entre la librairie de l’interface et celle de la logique applicative. C’est un effet désirable, car notre composante qui risque de changer (l’interface) dépend de notre composante stable (notre algorithme). Cependant, pour y parvenir, nous avons
implé-Figure 3.5 – Étape exécutée lors de la modification d’une variable.
menté certaines portions à l’aide de patrons de conception classiques. Dans les prochaines sous-sections, nous allons détailler quelques utilisations intéressantes de ces patrons et nous allons expliquer les problèmes auxquels ils satisfont.
3.2.1 Patron Contrôleur
Dans un premier temps, nous voulons isoler notre composante applicative (domaine d’affaires) de l’interface pour nous protéger des changements fréquents de cette dernière. Cependant, certaines fonctionnalités de notre domaine doivent être utilisables à l’extérieur vers un point d’accès unique. L’objet responsable d’exposer ces fonctionnalités est nommé ModelController.
Ainsi, lorsque l’on veut effectuer des modifications sur le domaine, l’interface utilisateur doit obligatoirement utiliser les méthodes exposées par cette classe.
Cette indirection permet donc de fournir un point d’entrée unique pour toutes les classes désirant utiliser notre librairie. Puisque tous les autres objets doivent utiliser le même chemin, le programmeur ne devrait pas oublier d’appeler des méthodes ni les appeler dans le désordre.
3.2.2 Patron Observateur
Puisque notre contrôleur est l’unique point d’entrée de notre domaine, toutes les classes de l’interface modifiant le domaine doivent l’utiliser. Cependant, les objets de l’interface ne savent pas déterminer le moment où la solution doit être réaffichée. Pour simplifier l’implémentation, nous voudrions que le contrôleur détermine le moment opportun du réaffichage et en avertisse l’interface utilisateur. Cependant, nous ne voulons pas créer une dépendance entre les classes du domaine et les classes de l’interface. Pour y parvenir, l’utilisation du patron de concep-tion de l’Observateur [6] est toute indiquée. Ce patron permet d’informer différents objets de changements sans créer de couplage au niveau du code entre les classes.
Pour notre cas, le contrôleur est l’objet qui est observé, (l’observable). Il gère une liste d’obser-vateurs qui seront informés lorsqu’une nouvelle solution sera disponible. Cependant, comme le type de ces objets est masqué par l’usage d’une interface, nous ne connaissons pas leurs implé-mentations. Ceci permet donc d’utiliser des objets provenant d’autres librairies sans créer de dépendance vers celle-ci. De plus, en enregistrant différents types d’objets, il serait possible de modifier le comportement du système. Par exemple, lorsqu’une nouvelle solution est calculée nous pourrions facilement l’écrire dans un fichier en créant un observateur dont ce serait le travail. Ce patron est représenté par le diagramme de classe UML à la figure 3.6.
Figure 3.6 – Modélisation du patron de l’Observateur.
Avec les deux patrons expliqués précédemment, nous avons été en mesure de gérer et d’inverser les dépendances entre nos différentes composantes. Cependant, certains comportements ont posé problème, principalement lors de l’initialisation. Pour y répondre correctement, nous
avons utilisé deux autres patrons qui seront expliqués dans les sous-sections suivantes.
3.2.3 Patron État
Le premier défi est de bien représenter l’état de la feuille Data tout en limitant la complexité cyclomatique lors de sa modification. Nous voulons limiter les if/else et localiser la connaissance de l’état de la feuille en un seul endroit.
Cette feuille peut prendre trois états différents : 1. Non chargée 2. Chargée correctement 3. Une erreur s’est produite lors du chargement. Ces trois états et les transitions possibles sont représentés à l’aide du diagramme d’état UML de la figure3.7.
Figure 3.7 – Diagramme d’état de la feuille représentant la Data.
Pour représenter les différents états de la feuille Data, le patron de conception « État » (en anglais State Pattern) [6] a été utilisé. Ce patron demande d’implémenter une classe par état possible. Ainsi, les détails d’implémentation se trouvent isolés dans les différentes classes. Pour permettre à la classe utilisatrice (Client) d’interagir avec l’état courant sans en connaître le type, une interface spécifie les différentes actions disponibles pour tous les états. De plus, une méthode permet d’obtenir le prochain état, mais toujours par l’intermédiaire de l’interface. Ainsi, la classe utilisatrice conserve une référence vers une interface représentant l’état courant et met à jour la référence au besoin. L’implémentation de ce patron pour notre feuille Data confère donc trois classes différentes et est représentée par le diagramme de classe UML de la figure 3.8.
Figure 3.8 – Modélisation du patron du State Pattern.
3.2.4 Patron Null Object
Un autre problème demandant un patron de conception est l’initialisation d’un nouveau clas-seur Excel. Certaines classes requièrent l’utilisation d’objets qui ne seront disponibles que lorsqu’un fichier sera chargé. Pour ce faire, le patron « Null Object » [6] a été utilisé. Ce pa-tron permet d’utiliser les méthodes d’un objet sans savoir que l’objet n’est pas initialisé. Cette méthode est utilisée pour permettre d’initialiser l’application et ce, même si des erreurs se produisent à son ouverture. Dans notre cas, la classe SolutionSpace implémente ce patron. Cette classe est responsable de contenir les données provenant des optimisations (le fichier .fnj) et par la suite d’appliquer la méthode de Hamel.
Avec l’aide de ce patron, il est facile de représenter un espace de solutions qui n’est pas encore initialisé et de pouvoir utiliser ses méthodes sans obtenir d’erreur. Ainsi, si une erreur se produit lors du chargement et qu’une instance de la classe SolutionSpace ne peut être initialisée, une instance de la classe NullSolutionSpace est retournée. Cette dernière classe simule la classe SolutionSpace en retournant des valeurs par défaut valide pour toutes les méthodes. Sans ce patron, la valeur null devrait être retournée et ceci crée un risque de déréférencer cette référence invalide.
Pour que l’implémentation de ce patron fonctionne, les méthodes de la classe rendue null doivent retourner des classes possédant une valeur par défaut. La classe SolutionSpace re-tourne toujours des objets suffisamment simples pour permettre un tel comportement. Comme il s’agit de structures de donnée natives (liste ou dictionnaire) de l’environnement .net, il est facile de retourner des instances vides. Par la suite, si des traitements doivent s’effectuer sur ces collections vides, aucune référence null n’existera. Ceci a du sens conceptuellement parlant, puisqu’un espace de solutions non chargé est vide et donc il devrait retourner des collections vides.
Un désavantage de ce patron est que l’on doit réassigner un objet lorsque l’espace de solutions est chargé. Ceci ne permet donc pas d’utiliser des variables membres readonly exposant ainsi
un risque d’oubli lors de la mise à jour des références. Comme ce patron est utilisé lors de la création d’objets avec l’opérateur new, toutes les anciennes références doivent être modifiées pour conserver l’état du système cohérent. Pour réduire le risque d’erreur, il faut limiter le nombre d’objets contenant une référence vers l’objet initialement créé. Pour ce faire, nous limitons les références à un seul objet qui est responsable d’effectuer des opérations sur cette classe. Le changement sera donc localisé et facile à prendre en main.
Grâce à l’utilisation de ces différents patrons, nous avons été en mesure de résoudre certains problèmes lors de la conception de notre application. Leurs utilisations peuvent rendre la conception plus complexe, mais dans les bonnes circonstances, limitent les erreurs possibles. Ceci facilite également la maintenance de l’application.
3.3
Accélérer le moteur de prétraitement de données
Lors de la génération de l’espace des solutions pour des modèles industriels contenant plus de 2000 variables d’intérêts, le nombre d’optimisations nécessaires sera très élevé. Rappelons qu’il faudra un maximum de2nm + 1 optimisations où n est le nombre de variables d’intérêts etm le nombre de seuils de tolérance différents à supporter. Il était donc impératif de trouver une méthode pour réduire le nombre d’optimisations requises.
Généralement, dans un modèle, certaines variables possèdent des bornes, c’est-à-dire une limite inférieure ou supérieure sur leurs valeurs possibles. Ainsi, si lors du calcul d’une solution une variable prend la valeur de sa borne minimale, la solution minimisant cette variable vient d’être automatiquement trouvée. Symétriquement, cette logique s’applique pour la solution maximisant la variable lorsqu’elle se trouve à sa borne maximale.
Par exemple, supposons un modèle contenant deux variables, respectivementx1 etx2. Si lors des optimisations pour trouver le minimum ou le maximum de x1, x2 prend la valeur de sa borne minimale, nous venons de déterminer « gratuitement » la solution minimisant x2. Ceci permet donc de ne pas devoir effectuer d’optimisation supplémentaire pour déterminer le minimum de x2. Cette économie s’applique également pour la prise en charge des seuils de tolérances. Lorsqu’une borne est atteinte, il est possible d’éviter toutes les optimisations pour les tolérances supérieures à la solution trouvée. En reprenant l’exemple de notre modèle contenant deux variablesx1 etx2, si la solution trouvée a une tolérance de 0 (est optimale), la solution minimale avec un seuil de 10% sera la même. Cette stratégie de filtrage est représentée à la figure 3.9sous la forme d’un diagramme d’activité UML.
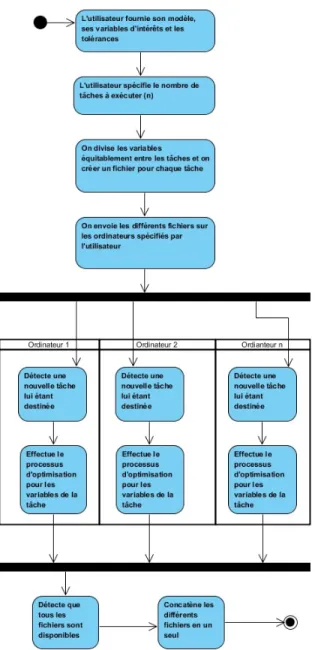
Pour accélérer davantage le processus d’optimisation, le système peut tirer avantage du paral-lélisme. En effet, le résultat d’une optimisation n’influencera pas le résultat de l’optimisation suivante. En profitant de cette indépendance entre les solutions, il est possible pour un utili-sateur de spécifier le nombre de tâches à exécuter simultanément. Notre système divise donc
Figure 3.9 – Diagramme d’activité représentant l’algorithme de filtrage.
équitablement les différentes variables à optimiser entre ces différentes tâches. Une fois le tra-vail accompli, les différentes solutions trouvées sont concaténées pour former un seul espace de solutions contenant tous les minimums et les maximums requis.
Pour permettre une meilleure modularité, notre système peut aussi utiliser des ordinateurs connectés en réseau pour exécuter ces différentes tâches. Ceci procure un avantage majeur, car certains solveurs tels que CPLEX peuvent utiliser l’entièreté des processeurs d’un ordinateur pour résoudre des modèles complexes. Ainsi, la division sur plusieurs ordinateurs augmente grandement la rapidité du système lors de l’utilisation sur un modèle industriel. L’utilisation
Figure 3.10 – Diagramme montrant les étapes lors de la séparation des tâches entre différents ordinateurs.
de cinq ordinateurs a permis de réduire le temps nécessaire par un facteur de cinq dans un tel contexte.
3.4
Application industrielle
Notre système de tableau de bord est destiné à être utilisé pour supporter la prise de décision en contexte industriel. À titre de preuve de concept, nous l’avons appliqué au cas réel d’une entreprise forestière canadienne. Nous voulions déterminer si notre système était suffisamment réactif et flexible pour s’adapter aux besoins d’une entreprise. Pour ce faire, le modèle uti-lisé [15] contient approximativement 64000 variables dont près de 2000 sont d’intérêt pour le
décideur.
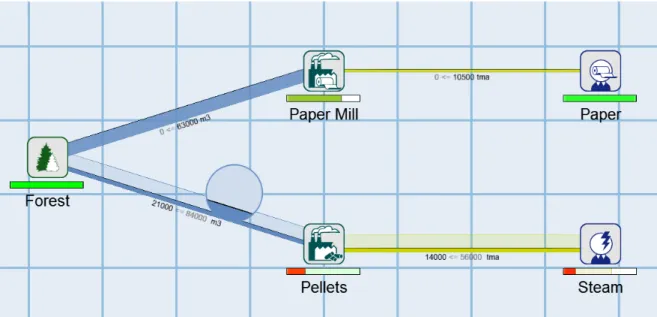
Le problème résolu par le modèle est l’allocation de blocs de coupes vers des usines [13]. La forêt est divisée en 50 blocs de coupe qui alimentent 5 scieries. Le transport vers les usines peut s’effectuer soit à l’aide de camions routiers ou par des camions forestiers hors normes. Les variables de décisions concernent la quantité de bois récolté dans chaque bloc, le choix de longueur de coupe, l’allocation des différents produits aux usines et le mode de transport utilisé. De plus, même si différentes usines étaient alimentées avec le même bois, un panier de produits différents sera produit en raison des configurations internes de chaque usine. Ceci complexifie la planification globale du réseau, car chaque changement aura une répercussion sur l’ensemble du réseau et sur la qualité de la solution.
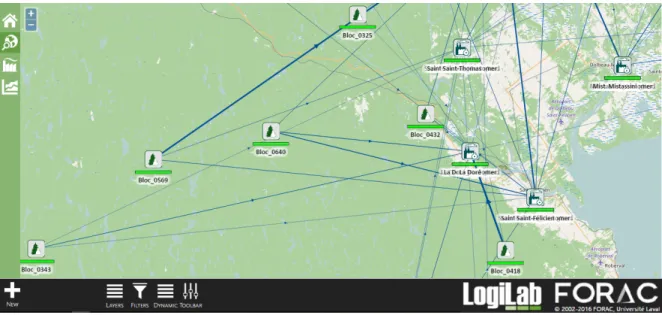
Ce problème est un bon cas d’utilisation pour notre système, puisque le décideur peut ajuster beaucoup de variables de décision. Par exemple, pour se conformer aux récents évènements et aux contraintes informelles, le décideur pourrait décider d’ajuster les choix de coupes et ainsi les ajustements à effectuer sur l’ensemble du réseau seraient calculés automatiquement. Pour visualiser son réseau, l’entreprise utilise LogiLab, un logiciel spécialisé dans l’optimisa-tion des réseaux d’approvisionnement forestier. La figure 3.11 montre un exemple de réseau présenté par LogiLab. Pour permettre une analyse plus approfondie, un tableau de bord Excel (figure3.12) est généré à l’aide des résultats de l’optimisation. L’entreprise nous a donné accès à son classeur Excel actuellement utilisé pour que nous puissions y ajouter l’interactivité.
Figure 3.11 – Exemple d’un réseau représenté par LogiLab.
C’est avec ce point de départ que nous avons transformé le tableau de bord « statique » en un tableau de bord « dynamique ». La première étape a été d’identifier les variables d’intérêt dans le modèle. Cette étape a mis l’emphase sur l’importance d’ajouter des variables d’agrégation pour représenter certains concepts. Par exemple, la sortie d’une usine correspond à l’ensemble
Figure 3.12 – Exemple d’une page d’un tableau de bord contenant différents graphiques. de la sortie de ses différents processus. Pour pouvoir modifier la sortie totale d’une usine, une variable représentant la somme de tous les processus est alors introduite dans le modèle. Une deuxième considération est l’identification des variables à même le classeur. Comme envi-ron 2000 variables peuvent être modifiées, il est impératif de fournir un système de recherche convivial à l’utilisateur. Ainsi, pour retrouver efficacement les variables, un système de filtre a été mis en place. La figure 3.13 montre un exemple de feuille permettant la modification des variables de transport. Chaque ligne représente une variable et chaque colonne une information relative à cette variable. Pour facilement identifier les variables pertinentes, des filtres (à droite du tableau) permettent de montrer uniquement les variables respectant certains critères. Par exemple, il est possible de montrer uniquement les variables représentant le transport d’un bloc de coupe particulier.
En ce qui a trait aux performances, l’étape de prétraitement des données est la plus exigeante. En effet, pour effectuer les différentes optimisations, environ 52 heures sont nécessaires lors-qu’effectuées sur un ordinateur personnel à l’aide du solveur CPLEX. En utilisant un super ordinateur, il est possible d’exécuter la même tâche en moins de 10 heures. Cependant, une fois ces optimisations effectuées, l’interaction avec l’utilisateur s’effectue en temps réel et sans aucun délai de latence.
Figure 3.13 – Feuille montrant les variables de transport présentes dans le modèle.
Lors de l’utilisation de notre classeur, la situation où la valeur d’une variable se fait continuel-lement effacer (voir section 2.3.2) se présente quelquefois. Ainsi, la possibilité de contraindre une variable à une valeur s’avère nécessaire pour obtenir une expérience utilisateur conviviale. Pour ce faire, nous avons développé un algorithme permettant de « verrouiller » la valeur d’une variable et il fera l’objet du chapitre4. Lors de l’utilisation de cet algorithme sur ce pro-blème, les performances se sont révélées intéressantes. Bien qu’il demande environ 10 minutes pour s’exécuter, notre algorithme est nettement plus rapide que les 52 heures nécessaires pour obtenir le même résultat en utilisant notre engin de prétraitement des données.
Chapitre 4
Ajout de contraintes pour converger
vers la solution désirée
Lors de l’explication de la méthode de Hamel au chapitre 2, nous avons soulevé un pro-blème d’instabilité pouvant survenir lors de l’ajout de préférences. Certaines préférences sont constamment « effacées » par les modifications subséquentes, empêchant ainsi l’utilisateur de tendre vers la solution réellement désirée. Pour contrer ce problème, nous proposons un algo-rithme qui obligera une variable choisie à conserver sa valeur malgré toutes les modifications suivantes.
L’algorithme que nous proposons à cette fin est différent de l’approche qui consisterait à faire une réoptimisation totale à chaque fois. Cependant, l’espace de solutions accessible par l’algorithme est un sous-ensemble de l’espace de toutes les solutions réalisables. Malgré cet effet, nous pensons que la dégradation est suffisamment petite pour que notre algorithme soit utilisable.
Dans le reste de ce chapitre, nous allons dans un premier temps décrire cet algorithme. Par la suite, nous allons mesurer expérimentalement la performance de l’algorithme.
4.1
Description de l’algorithme
L’algorithme est utilisé dans le contexte suivant. Si l’utilisateur est satisfait de la valeur d’une variable, il peut alors demander qu’elle soit « verrouillée » de manière à ce qu’elle ne puisse plus changer même s’il modifie ensuite d’autres variables. L’algorithme prend en entrée une variable (x) et sa valeur (v) et produit un espace de solutions tel que cette variable conserve cette valeur pour toute solution.
Sans l’utilisation de cet algorithme, il faudrait réoptimiser le modèle original en y ajoutant la contrainte supplémentaire x = v. Par la suite, le coûteux processus trouvant les minimums
et les maximums devrait être exécuté à nouveau. Rappelons que pour des modèles industriels étudiés au chapitre 3, plus de 48 heures peuvent être nécessaires pour cette étape.
L’algorithme proposé permet donc de réaliser cette tâche sans délai (mais au prix d’une ré-duction artificielle de l’espace des solutions accessibles). Le texte suivant décrit l’approche proposée.
Géométriquement, un problème contenant n variables représente un espace linéaire à n di-mensions. Chaque point représente une solution et chaque composante d’un point correspond à la valeur d’une variable. Une contrainte d’égalité supplémentaire correspond à un hyperplan traversant cet espace. Lors d’un verrouillage, nous devons donc déterminer l’intersection entre le polytope et l’hyperplan ajouté. Cette opération peut aussi être perçue comme la réduction d’une dimension de notre espace, c’est-à-dire de passer de n dimensions à n− 1 dimensions.
X
Y
𝑠
𝑣
Figure 4.1 – Représentation d’un ajout de contrainte. Sur cette figure, la variable X est contrainte à une valeur v.
Nous déterminons cette intersection en identifiant les points de croisement entre notre polytope et l’hyperplan en utilisant les solutions min et max qui définissaient déjà les sommets de notre polytope. Ainsi, pour chaque paire de sommets, nous devons déterminer si une droite reliant ces deux points croise l’hyperplan.
Y
X
𝑠 𝑣 𝑠𝑘 𝑠𝑙 𝑠′(a) Exemple d’intersection trouvée grâce à l’utilisation des min et max du polytope.
Y
X
𝑠 𝑠𝑘 𝑠𝑙 𝑣(b) Exemple de recherche d’intersection ne menant à aucun résultat, puisqu’elle n’existe pas.
![Figure 2.2 – Processus itératif d’optimisation. Inspiré de Hamel [ 9]](https://thumb-eu.123doks.com/thumbv2/123doknet/3493860.102150/15.918.134.783.487.659/figure-processus-itératif-optimisation-inspiré-hamel.webp)