Heterogeneous models matching for consistency management
13
0
0
Texte intégral
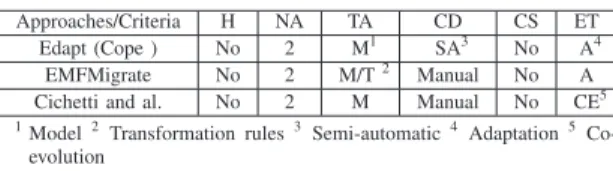
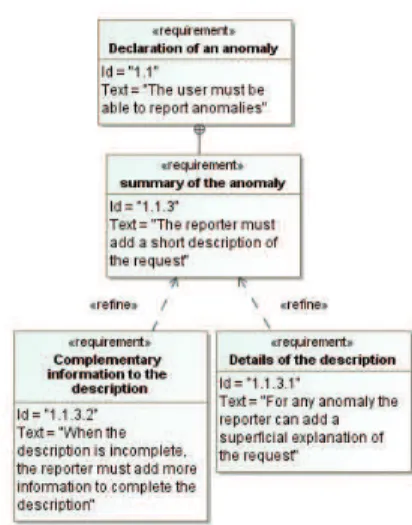
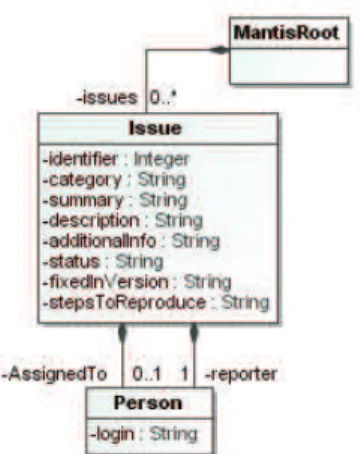
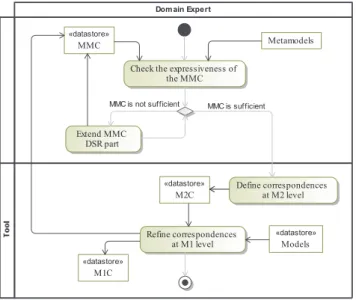
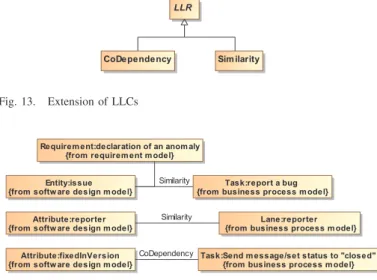
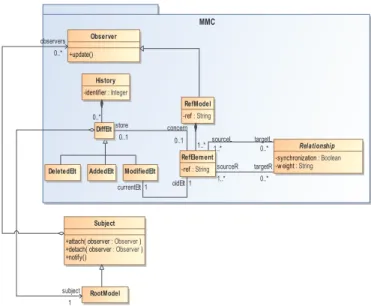
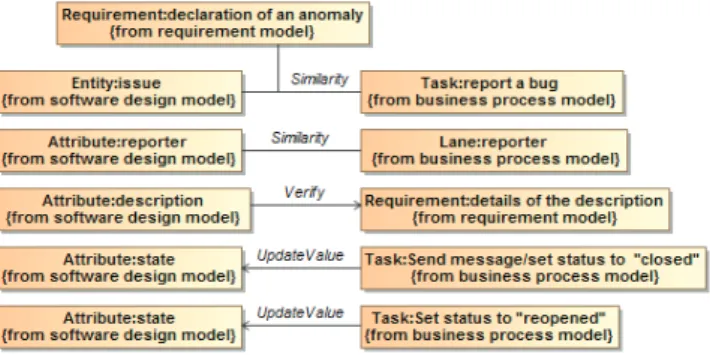
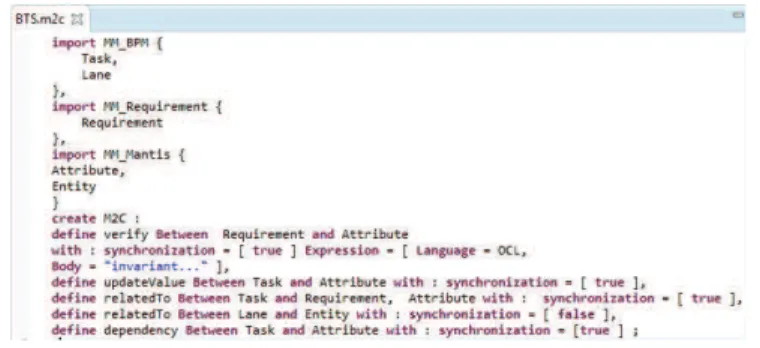
Figure
+7


Documents relatifs
