Balancing signals for semi-supervised sequence learning
Texte intégral
Figure
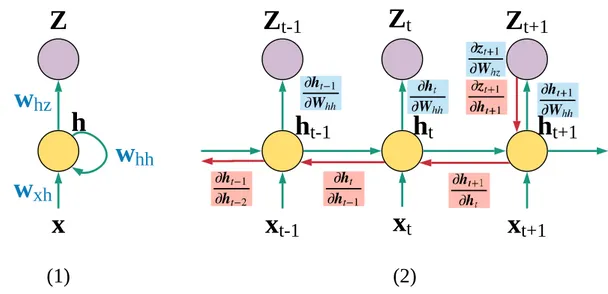
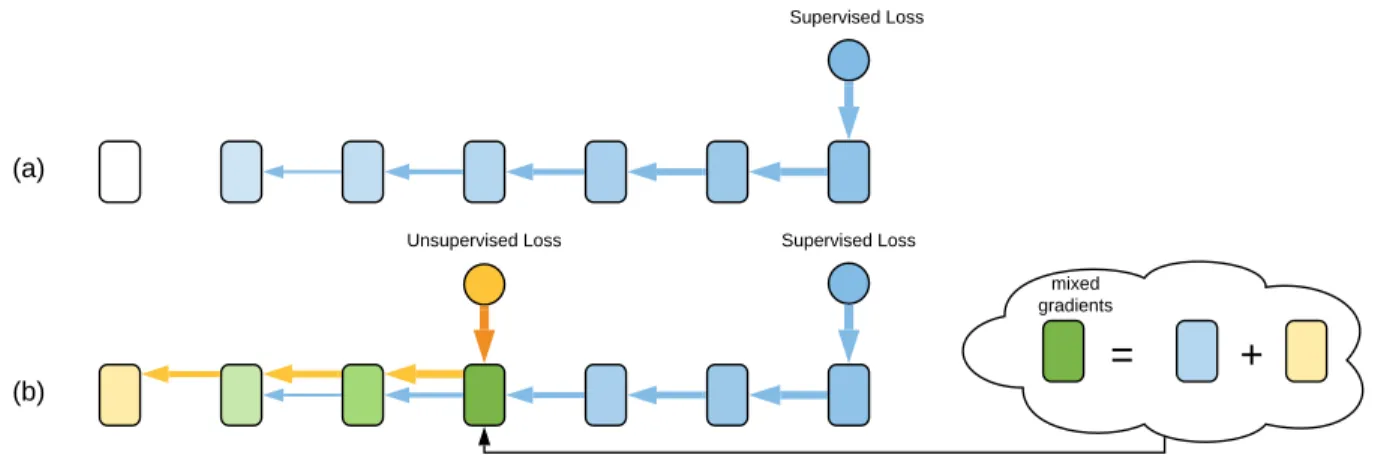
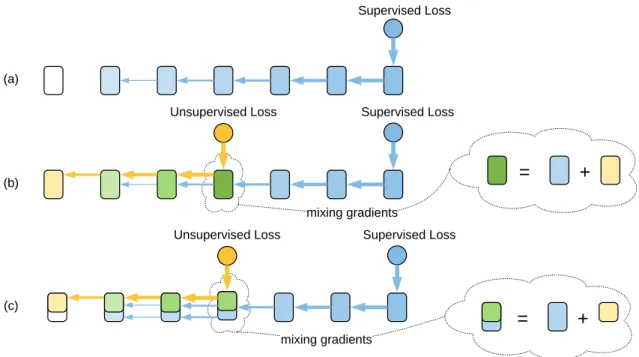
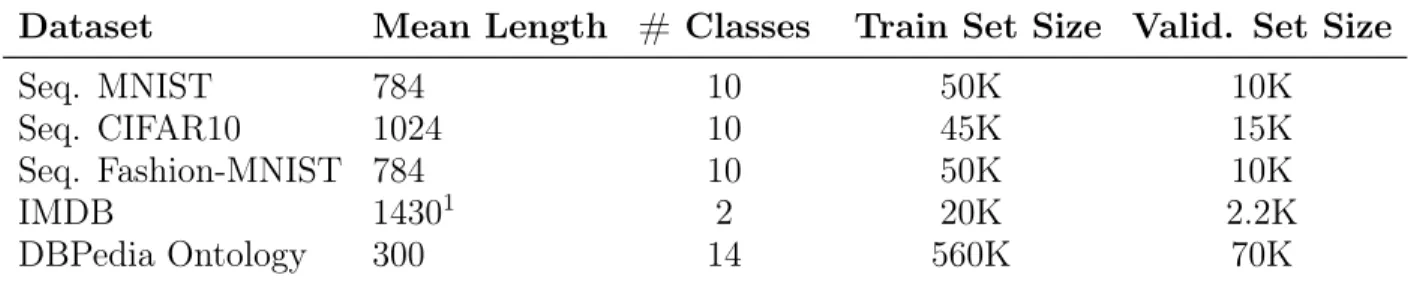

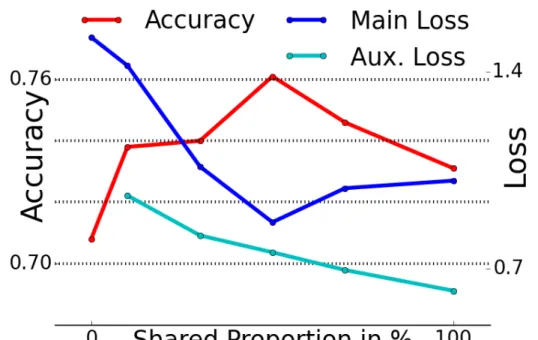
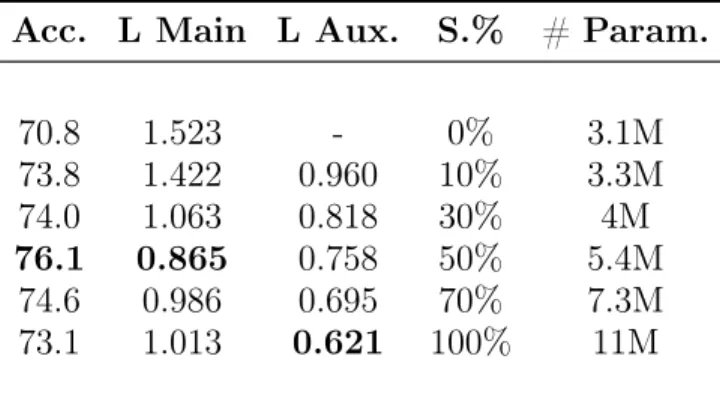


Documents relatifs
As the study of the risk function L α viewed in Equation (6) does not provide any control on the probability of classifying, it is much more difficult to compare the performance of
With a set of 1, 000 labeling, the SVM classification error is 4.6% with SVM training set of 60 labels (1% of the database size), with no kernel optimization nor advanced
In our last experiment, we show that L γ - PageRank, adapted to the multi-class setting described in Section 2.3, can improve the performance of G-SSL in the presence of
Features from Asset Data: Number of assets, Number of critical assets, Number of assets per category (C1..C9), Number of users, Data type, Capability, Volume, Confidentiality 1
A typical scenario for apprenticeship learning is to have an expert performing a few optimal (or close to the optimal) trajectories and use these to learn a good policy.. In this
The Inverse Reinforcement Learning (IRL) [15] problem, which is addressed here, aims at inferring a reward function for which a demonstrated expert policy is optimal.. IRL is one
topology of the configurations in the training set and the testing set are identical. Changes in the topology was outside the scope of the study, as, in the design of critical
▶ Our encoder transforms the data into feature representations, from these representations we infer a Gaussian latent variable to provide more robust set of features and a
