Exploitation d'une hiérarchie de subsomption par le biais de mesures sémantiques
Texte intégral
Figure
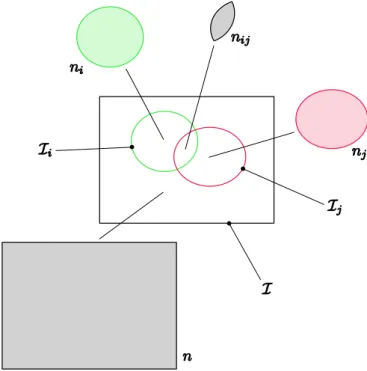
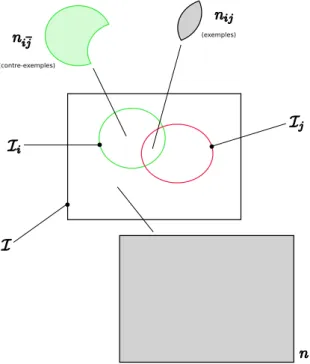

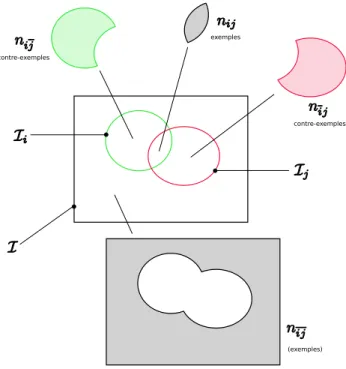


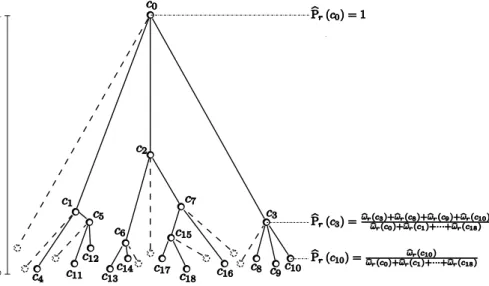
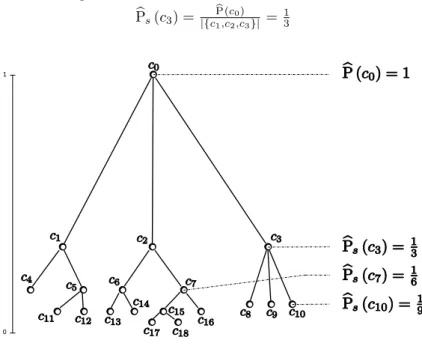
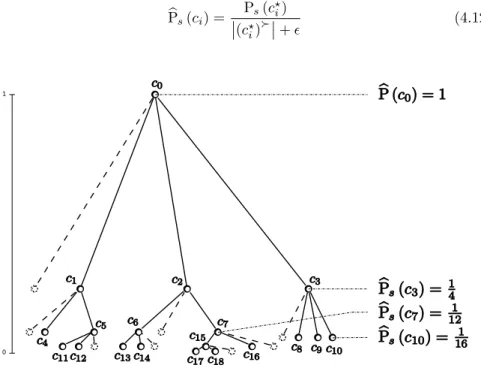
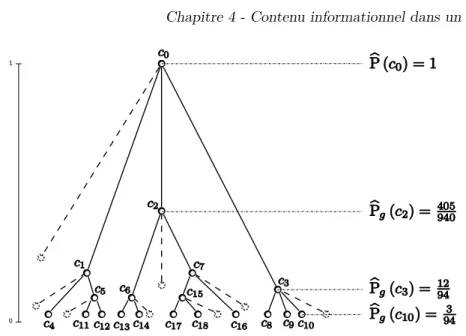
Documents relatifs
Dans cette méthode, on essaye de reformuler un problème d’optimisation quelconque comme un Pro- blème Généralisé des Moments (PGM), soit un problème d’optimisation linéaire
Appeler le professeur pour qu’il valide ou en cas de difficulté Comme pour les fentes d’Young, l’interfrange i est calculé par la relation i =
[r]
Puis convcrtis les mesurcs donn&s dcns I'unitë
Ce stage consiste à réaliser le déploiement d’un de ces algorithmes sur les plateforme de mesures PlanetLab Europe http://planet-lab.eu et EdgeNet http://edge-net.org/,
Key words: Hausdorff measure; Packing measure; Hausdorff dimension; Tricot dimension; Lower and upper dimension; Multifractal analysis.. Code matière AMS
Disons pour simplifier que le couple ((t2, E, p), £) possède la propriété (P) si toute application Pettis-intégrable bornée de Q dans £ définit une mesure dont l'image
Si f ' j est la mesure produit fyfifj» alors fj=fj et fj=fj- Si de plus, on pose g =f et gj=fj/ le nuage N(l) est exactement celui qui est considéré dans l'analyse des
