Routing and mobility in large heterogeneous packet networks.
213
0
0
Texte intégral
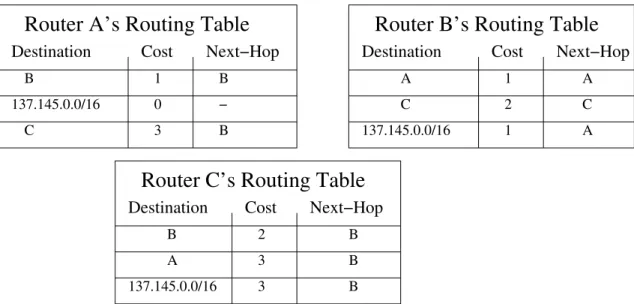
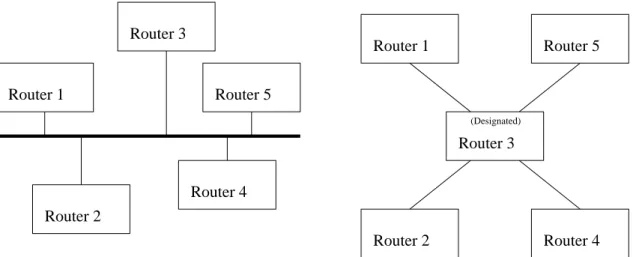
Figure

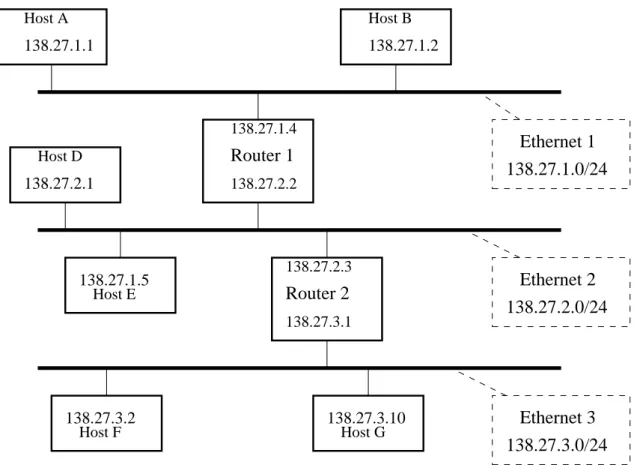
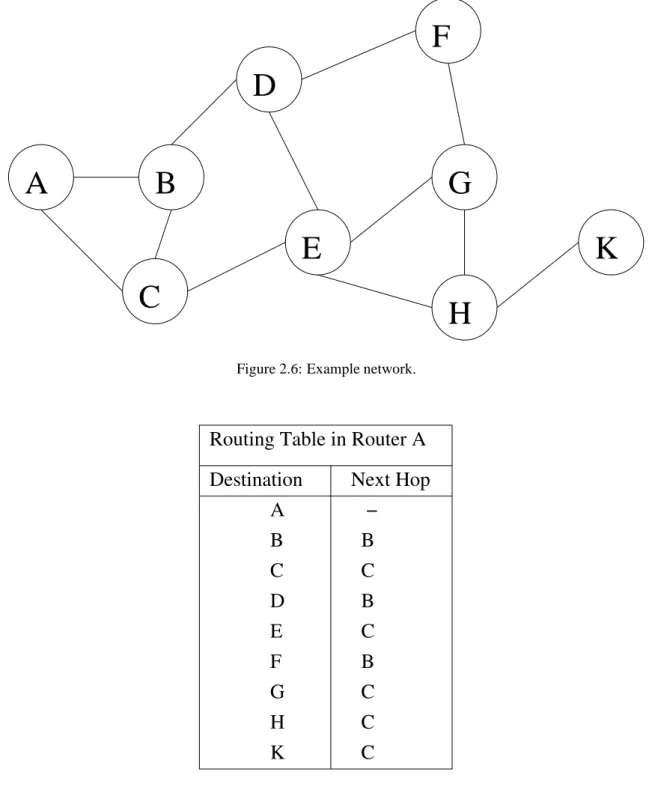
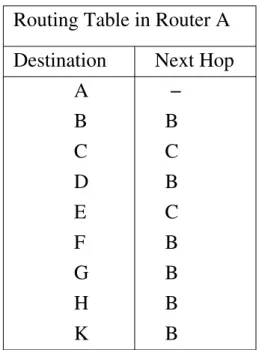
+7

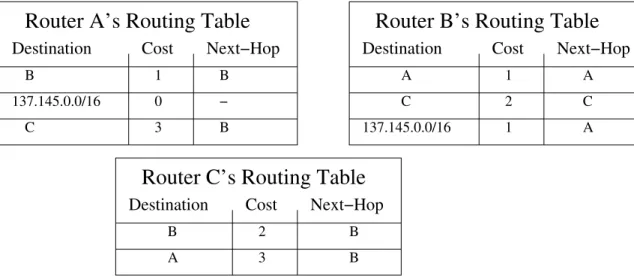


Documents relatifs