Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
UNIVERSITE D'ADRAR
Faculté des Sciences et de la Technologie
Mémoire
de fin d’étude pour l’obtention du
diplôme de Master en Informatique
Option : Réseaux et Systèmes Intelligents
Présenté par
Ould Bahammou Abdelaziz
Bouchareb Bachir
Devant le jury composé de
Président :
Mr. Touabi Abdelkader Maître assistant à l’université d'Adrar
Examinateur :
Mr. Chougar Djillali Maître assistant à l’université d'Adrar
Directeur de mémoire :
Mr. Elmir Youssef Maître assistant à l’université d'Adrar
Dédicace
«
بينأ
هيلاو تلكوت هيلع للهاب لاإ يقيفوت ام
و
»
dédie ce modeste projet qui est le fruit d’un travail fait
avec beaucoup de volonté et de persévérance à mes
parents pour leur soutien permanent.
A mes sœurs Souaad, Leila. A mon frère Abbas et le
petit Mohamed.
A mes amis Bachir, Abdeljabar,
Ammar
,
Abderazak, Mohamed, Ahmed, Abdelkader …
A mes cousins et cousines Kamel, Jouhara, Omar,
Abdelkader et Moussa…
A toute la famille Ould Bahammou.
Ainsi qu’à tous ceux qui aiment Abdelaziz
A tous ceux que l’encre a oublié mais le cœur n’oublie pas.
Abdelaziz
J
ءادهلإا
«
نونمؤملاو هلوسرو مكلمع الله ىريسف اولمعإ ل ق
»
بيطت لاو كتعاطب لىإ راهنلا بيطي لاو كركشب لاإ ليللا بيطي لا يلهإ
لاإ ةرخلآا بيطت لاو كركذب لاإ تاظحللا
لاإ ةنلجا بيطت لاو كوفعب
كتيؤرب
الله
هللاج لج
ىدأو ةلاسرلا غلب نم لىإ
لىإ ةملأا حصنو ةناملأا
نمياعلا رونو ةمةرلا ي ن
دممح انديس
ملسو هيلع الله ىلص
ةبيلهاب الله هللك نم لىإ
راختفا لكب هسمأ لمةأ نم لىإ راظتنا نودب ءاطعلا نيملع نم لىإ راقولاو
ديم نأ الله نم وجرأ
ىقبتسو راظتنا لوط دعب اهفاطق ناح دق ًاراثم ىترل كرمع في
يلا ابه يدتهأ مونج كتاملك
دبلأا لىإو دغلا فيو مو
يدلاو
زيزعلا
نانلحا نىعم لىإو بلحا نىعم لىإ ةايلحا في يكلام لىإ
دوجولا رسو ةايلحا ةمسب لىإ نيافتلاو
انهانحو يحانج رس اهئاعد ناك نم لىإ
بيابلحا ىلغأ لىإ يحارج مسلب
ةبيبلحا يمأ
اهدوجوب نم لىإ تيايح ةملظ يرنت ةدقتم ةعشم لىإ
ةايلحا نىعم اهعم تفرع نم لىإ اله دودح لا ةبمحو ةوق بستكأ
تيجوز
ةيلاغلا
ةيجدخ ةتوكتكلا تينبا لىإ
تييرشعو يلهأ لىإ
،
تيذتاسأ لىإ
يقيدص لىإ ،
زيزعلا دبع ومحاب دلو
بيرد قيفر
تيلايمزو يئلامز لىإ
،
عومشلا لىإ
نيرخلآل ئضتل قترتح تيلا
،
افرح نيملع نم لك لىإ
ه يدهأ
لىوميا نم ًايجار عضاوتميا ثحبلا اذ
،
حاجنلاو لوبقلا ديج نأ لجو زع
ر يشب
Remerciements
ous tenons à témoigner notre profonde gratitude à notre directeur de
mémoire Monsieur. Elmir Youssef, enseignant en informatique à
l’université d'Adrar, qui a accepté de diriger notre mémoire et à bien voulu
nous faire profiter de sa compétence, de sa rigueur scientifique, de ses
remarques pertinentes et de ses conseils judicieux.
Nous présentons tous nos vifs remerciements au Monsieur Le chef de
la daïra d’Adrar qui nous a aidé à la réalisation de notre base de données en
mettant à notre disposition les différentes équipements biométrique
disponible au niveau de la daïra d'Adrar, ainsi nous n'oublions pas de
remercier l'ensemble des membres du jury qui ont accepté d’évaluer ce
travail.
Nos vifs remerciements s’adressent à tous ceux qui nous ont aidés à la
réalisation de ce modeste travail.
À tous nos professeurs de l'université d'Adrar pour leurs contributions
à notre formation académique scientifique.
Résumé
a Biométrie multimodale est un domaine qui attire de plus en plus l’attention
des équipes de recherche et des différentes structures de sécurité des états mais
il reste encore un problème vaste et ouvert en comparaison avec les résultats
obtenus dans le domaine de la biométrie monomodale.
Dans ce mémoire, le problème de l'identification biométrique multimodale des
personnes est abordé en utilisant une base de données multimodale réelle à travers les
visages et les empreintes des personnes vivantes des étudiantes et enseignants auprès de
l'université d'Adrar; Une approche d'identification biométrique basée sur la fusion
multimodale, est proposée de façon de combiner les informations biométrique du
visage et de l'empreinte.
Ce système est structuré comme suit: la codification des visages et des
empreintes, la fusion des informations résultantes et l'apprentissage du système et enfin
le module de décision.
Enfin, SBM est un système d'identification biométrique multimodal, qui fournit à
l’utilisateur une interface graphique, il est basé sur le visage et l'empreinte digitale, il
aide l’utilisateur à identifier des personnes réelles a partir d'une base biométrique
Multimodale.
Mots-clés : Biométrie multimodale, visage, empreinte
digitale, filtre de Gabor.
Abstract
ultimodal biometrics is a field that attracts increasing attention from research
groups and different structures of state security but there is still a huge
problem and open compared to the results obtained in the field of unimodal biometrics.
In this report, the problem of multimodal biometric identification of individuals is
addressed using a base of real multimodal data through faces and fingerprints of living
persons student and teachers from the University of Adrar;
a biometric identification
approach based on multimodal fusion is proposed in order to combine the biometric
information of the face and fingerprint.
This system is structured as follows: the coding of faces and fingerprints, merging
the resulting information and learning system, and finally the decision module.
Finally, SBM is a multimodal biometric identification system, which provides the
user with a graphical interface, it is based on face and fingerprint and it helps the user
to identify real people from a multimodal biometric database
.Keywords
:
multimodal biometrics, face, fingerprint, Gabor Bank filters
.
M
صخلم
لامج
يتريمويبلا
جذامنلا ددعتم
موي دعب موي بليج
مامتها
دعلا
ينثحابلا نم دي
ةينملأا تائيلها و
،
هنكل
ىقبي
لااكشإ
عساو
ا
و
حوتفم
ا
لصوت ابم ةنراقم
هيلإ
لامج
.جذومنلا يداحأ يتريمويبلا
ن
لوانت
ثحبلا اذه في
ةيلاكشإ
ددعتلما ةيترمويبلا ةيولها ديدتح
ة
امنلا
جذ
ب
نم ةيقيقح تانايب ةدعاق مادختسا
للاخ
صئاصخ
جولا
عباصلأا تامصبو ه
ةذوخألما
ل
بلاط
و
ةذتاسأ
راردأ ةعماج
.
ثحبلا اذه في
انمدق
فرعتلا جنه
ىلع
جامدإ مادختساب ةيولها
تامولعم
تامصبو هجولا
عباصلأا
نم
دعاق
ة
لا
تانايب
لا
ةيترمويب
.
لا اذه
ماظن
اساسأ دنتسي
ت ىلع
يرفش
روص
جولا
عباصلأا تامصبو ه
و
جامدإ
م
تهامولع
ام
ماظنلا بيردت اذكو
صاخشلأا ىلع فرعتلا ىلع
.
راصتخاب
،
(
SBM
وه )
ىلع لمعي ماظن
فرعتلا
ىلع
ةيولها
جذامنلا ةددعتم ةيتريمويبلا
و
مدقي يذلا
لىإ
تسم
هيمدخ
هجاو
ىلع دمتعت ةينايب ة
روص لاخدإ
عباصلأا تامصبو هجولا
في صاصتخلاا لهأ دعاست
ىلع فرعتلا
للاخ نم ينيقيقح صاخشأ
ةدعاق
تايطعم
جذامنلا ةددعتم ةيتريمويب
.
ةيسيئرلا تانايبلا
:
جذامنلا ددعتم يتريمويبلا
،
عباصلأا تامصبو هجولا
،
ةدعاق
تايطعم
ةيتريمويب
.
نإ
Sommaire
Introduction Générale ... 01
CHAPITRE I:
Le Système d’Identification Multibiométriques
1. La classification et la comparaison de La Biométrie ………..………052. Système multimodalité………..……….…....……….06
3.
Fusion………...……….……….073.1. L’intérêt de la fusion de données ………...……….08
3.2. Définition de la fusion de données ………...………..………….……08
3.3 Les types de fusion ………...………..……….…...09
3.4. Les différents niveaux de fusion………..……….…………..……….10
3.4.1. Avant le Matching………..………..………..…………..10
3.4.1.1. Niveau Capteur (Sensor Level)………...………10
3.4.1.2 Niveau Caractéristiques (Feature Level)……….………11
3.2.2
. Après le Matching………...………..………..123.2.2.1. Niveau Décision (Decision Level) ……….………...……….…………..12
3.2.2.2. Niveau Rang (Rank Level) ………..……….12
3.2.2.3. Niveau Score (Score Level) ……….13
4.
L’identification Multibiométrique………...………...…164.1
Système d’identification ………...………..………....174.2 Normalisation de score………...………...18
4.5 Les différentes techniques de normalisation de scores….……….………..…...20
4.6Approche par classification de scores ……..………22
4.7 Approche par combinaison de scores…..……….……….………....23
5. Conclusion ……….………....23
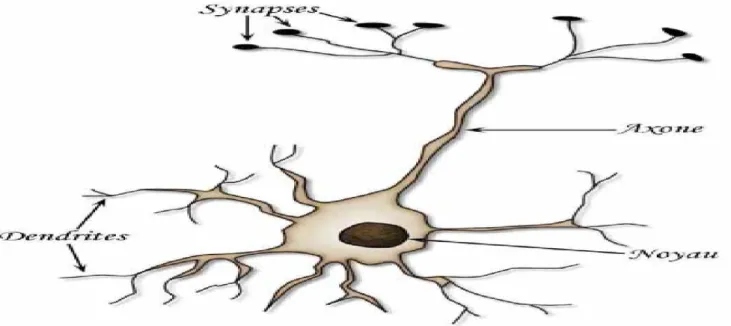
Chapitre II: Réseaux de neurones et les Algorithmes de reconnaissance 1. Neurone réel (Biologique) ………...……….. 24
2. Neurone formel ………..……….25
2.1. Avantage des réseaux de neurones ……….25
2.2. Inconvénients ………...……..25
3. Modélisation d’un neurone formel ………..……...26
3.1.
Les entrées ………..………....263.2.
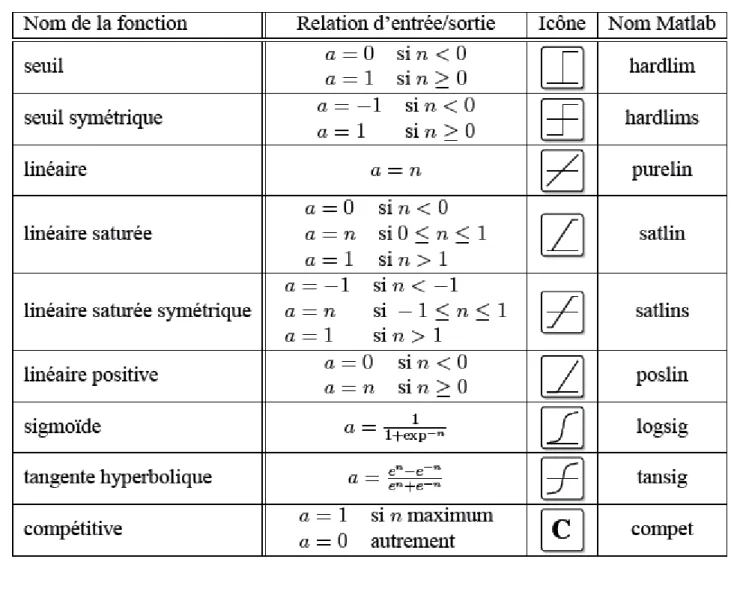
Fonction d’activation ……….…….263.2.1.
Fonction binaire a seuil ……….……….…….273.2.2.
Fonction linéaire ………...273.2.3.
Fonction linéaire à seuil ou multi-seuils ………....…...273.2.4.
Fonction sigmoïde ………..……….273.3.
Fonction de sortie ……….…..………..274.
Architecture des réseaux ………..………..……274.1.
Réseau monocouche ………...….274.2.
Réseau multicouche ………...285.
Apprentissage ……….295.1.
Apprentissage supervisé ………...295.2.
Apprentissage non supervisé ……….296.
Mise en œuvre des réseaux neuronaux ……….……...297.
Les fonctions de l’algorithme de reconnaissance sous Matlab ………..….……...307.1.
Création d’un réseau ……….……...…….307.2.
Apprentissage ……….……...……...321.Collection des bases des données biométriques multimodales . ... ...….……...34
2.Conception des bases des données biométriques multimodales……….……...…..………..35
3.Extraction des caractéristiques.... ...….……... ...….……... ...36
3.1 Chargement des caractéristiques……….……...………...36
3.2 Codage des caractéristiques ……….……...………....36
3.3Normalisation ……….……...……… ... ..37
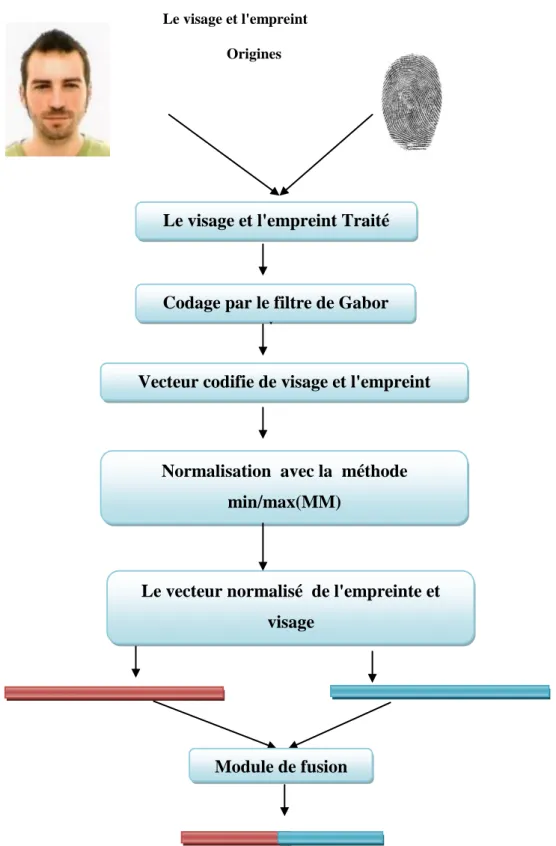
3.4. La fusion……….……...………...37
4. L’environnement d'expérimentation……... ...….……... 39
5.Résultats expérimentaux ...….……... ... ...41
5.1 Phase d’apprentissage ……...……….……...………..…………42
5.1.1 Apprentissage Avec bruit (network1)………...…… ….……...………….………..43
5.1.2 Apprentissage sans bruit (network2)………..……… ….……...…………..………44
5.2 La Reconnaissance du Système……….……...…………...…….45
6.La résistance contre bruit ... ...45
7. Partie application……….……...…....………47
7.1 La phase de chargement de l’empreint et le visage……….……...……… .... …..47
7.2 La phase codification ……….……...………..……47 7.3 La phase normalisation……….………….……...………...….48 7.4 La phase de fusion ………..……….……...………...…..49 7.5 La phase de reconnaissance……….……...………....………..50 . 7 Conclusion …...……….……...………...51 Conclusion générale…... …...52
Listes des figures
CHAPITRE I: Le Système d’Identification MultibiométriquesFigure 1. La classification de la Biométrie. ……… ……… 5
Figure 2. Fusion au niveau score dans un système biométrique multimodal ……….. ...11
Figure3. Les différents niveaux de fusion ………..……….14
Figure 4. Système d’identification ………..17
CHAPITRE II
: Réseaux de neurones et les Algorithmes de reconnaissance Figure 1. Schéma d’un neurone réel ………25Figure2. Schéma d’un neurone formel……….25
Figure 3. Schéma de réseaux Monocouche………..28
Figure 4. Schéma de réseaux Multicouche………...29
CHAPITRE III : Réalisation et Mise en œuvre Figure1.Caméra photo numérique………36
Figure2. Capteur mono-doigt………..36
Figure3.L’architectures pour la conception d’une base de données multimodale………..37
Figure 4. Transformation l’image vers la forme vectorielle………38
Figure 5. L'extraction des caractéristiques (visage et l'empreinte) et la fusion…...………39
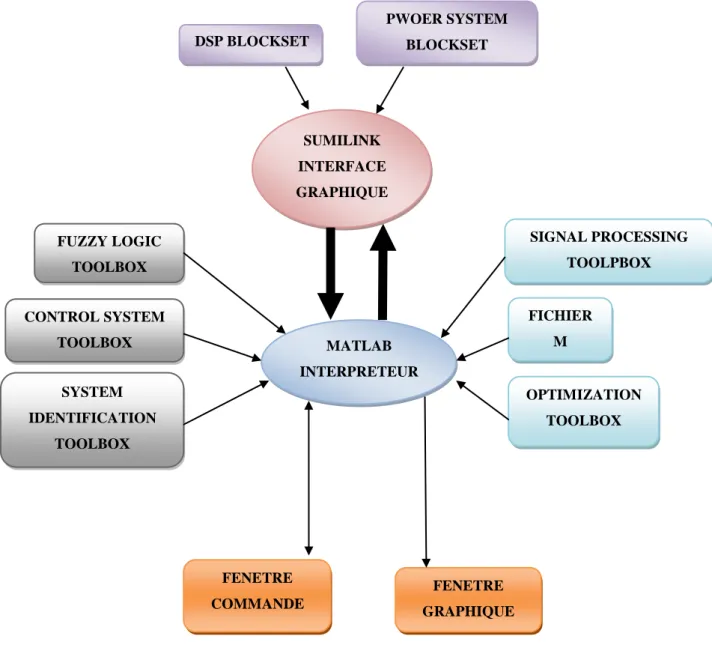
Figure 6. Différent fonctionne de L'environnement MatLab………40
Figure 7. Système de Reconnaissance de l’image et l’empreints sur le Réseau de Neurones ……….42
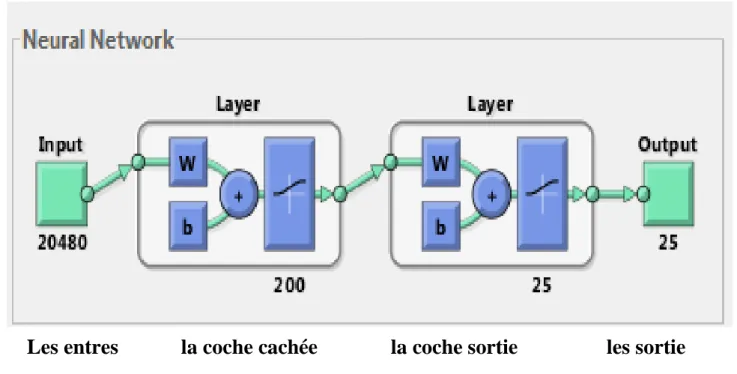
Figure 8. Architecture du Réseau de Neurones……….……..44
Figure 9. Processus d’apprentissage du RN (network1) ………..………..45
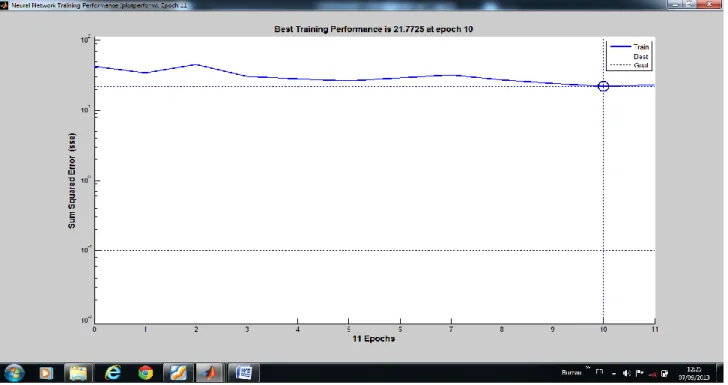
Figure 10.Processus d’apprentissage du RN (network2) ……….………45
Figure 11. La performance des deux systèmes ……….……….46
Figure12. Phase de chargement ………..….48
Figure13. Phase codification ……….………….….49
Figure14. Phase normalisation ... ………...49
Figure15. Phase de fusion ………50
Listes des tableaux
CHAPITRE I: Le Système d’Identification Multibiométriques
Tableau 1. Comparaison de diverses technologies biométriques ; haut, moyen, Et bas sont dénotés
par H, M, et B, respectivement. ……….….. 6
CHAPITRE II: Réseaux de neurones et les Algorithmes de reconnaissance
Tableau 1. Analogie entre le neurone biologique et le neurone formel ………..25 Tableau 2. Les différentes fonctions ………...………32
Introduction Générale
epuis plusieurs années, des efforts importants sont fournis dans le domaine de recherche de la biométrie. Ce constat s’explique par la présence d’un contexte mondial dans le quel les besoins en sécurité deviennent de plus en plus importants Les applications biométriques sont nombreuses et permettent d’apporter un niveau de sécurité supérieur en ce qui concerne des accès logiques (ordinateurs, comptes bancaires, données sensibles, etc.) ou des accès physiques (bâtiments sécurisés, aéroports, etc.).
Ce mémoire commence tout naturellement par la présentation de quelques définitions de base puis les détails des objectifs de ce travail qui porte sur la reconnaissance biométrique par fusion multimodale.
Le terme biométrie vient des mots Grecs bios (vie) et metrikos (mesure ou distance) selon (Delac, 2004), qui veut dire distances biophysiques de l’être humain, ou en d’autre terme, c’est l’anthropométrie. Il existe plusieurs définitions de la biométrie, en voici quelques-unes :
Définition 1 : La biométrie est la science qui étudie à l’aide des mathématiques (statistiques, probabilités) les variations biologiques ou biophysiques à l’intérieur d’un groupe déterminé de personnes (Robert, 1987).
Définition 2: Les mesures biométriques sont celles qui concernent l’ensemble des caractéristiques distinctives d’une personne. Elles peuvent être lues par des systèmes informatiques et utilisées afin d’identifier cette personne.
Définition 3 : La biométrie permet l’identification d’une personne sur la base de caractères physiologiques ou de traits comportementaux automatiquement reconnaissables et vérifiables (Larousse, 2002).
Les objectifs de cette mémoire est de réaliser un système biométrique multimodal de reconnaissance de visage et de l’empreinte digitale en utilisant des algorithmes de reconnaissance des formes et de classification développés sous MATLAB, ainsi, la collection d’une base des données pour l’exploiter en utilisant des techniques d’extraction des caractéristiques tel que les filtres de Gabor et de
classification comme le réseau de neurones, ce dernier est développé par l’ensemble des algorithmes de codification et de reconnaissance associés spécifiquement à ce système.
Le travail est consacré au développement des algorithmes de codification et de reconnaissance appliqués sur des bases des données des étudiantes (visage et empreinte) collectés dans le cadre d’une convention signée avec la daïra d’Adrar.
Ce mémoire est organisé de la manière suivante, le premier chapitre présente la notion et l’importance du système biométrique multimodal en concentrant d’abord sur la fusion des données biométriques et ses différents niveaux possibles. L’identification biométrique et plus précisément le système d’identification qui composent de deux phases importantes : l’apprentissage et l’identification, ensuite la fusion aux niveaux des caractéristiques est présentée, ainsi que la fusion au niveau de scores. Enfin les différentes techniques de normalisation de score.
Le deuxième chapitre est consacré pour les réseaux de neurones, sa modalisation et son apprentissage de neurone formel. Enfin Les fonctions de l’algorithme de reconnaissance sous Matlab.
Le troisième chapitre décrit la collection de la base des données biométrique multimodale, ainsi que le système d’acquisition dans un environnement réel, en insistant tout particulièrement sur la conception et la manipulation de bases de données biométriques multimodales pour l’extraction des caractéristiques du visage et de l’empreinte. Finalement, les résultats expérimentaux sont présentés ainsi que la résistance contre le bruit.
La dernière partie conclut l’ensemble du travail présenté et illustre quelques perspectives du système biométrique multimodal réalisé.
Le Système d’Identification
Multibiométrique
La biométrie, qui consiste à identifier un individu à partir de ses caractéristiques physiques ou comportementales, connait depuis quelques années un renouveau spectaculaire dans la communauté du traitement du signal. Elle a aussi reçu une attention accrue de la part des médias depuis les tragiques événements du 11 septembre 2001.
La biométrie est une alternative mode d’identification aux deux traditionnellement manières d’identifier un individu, La première méthode est basée sur une connaissance. Cette connaissance correspond par exemple au mot de passe utilisé au démarrage d’une session Unix ou au code qui permet d’activer un téléphone portable. La seconde méthode est basée sur une possession (token-based). Il peut s’agir d’une pièce d’identité, une clef, un badge, etc. Ces deux modes d’identification peuvent être utilisés de manière complémentaire afin d’obtenir une sécurité accrue comme pour la carte bleue. Elle consiste `a identifier une personne à partir de ses caractéristiques physiques ou comportementales. Le visage, les empreintes digitales, l’iris, etc. sont des exemples de caractéristiques physiques. La voix, l'ecriture, le rythme de frappe sur un clavier, etc. sont des caractéristiques comportementales. Ces caractéristiques, qu’elles soient innées comme les empreintes digitales ou bien acquises comme la signature, sont attachées `a chaque individu et ne souffrent donc pas des faiblesses des méthodes basées sur une connaissance ou une possession. À notion de la biométrie Les techniques d'identification par la biométrie servent principalement à des applications dans le domaine de la
Chapitre
sécurité, comme le contrôle d'accès automatique, un tel dispositif étant qualifié de système de contrôle biométrique.
Dans la théorie tout trait de l’être humain (physiologique ou comportemental) peut être employé comme caractéristique biométrique pour la reconnaissance des personnes aussi longtemps qu’il répond aux conditions suivantes (Jain ,2004) :
Universalité : ceci signifie que chaque personne devrait avoir le trait.
Unicité : ceci indique que deux personnes quelconques devraient être suffisamment différentes en termes de leurs traits biométriques.
Permanence : ceci signifie que le trait devrait être suffisamment invariable sur une certaine période de temps.
Collecte : ceci indique que le trait peut être mesuré quantitativement.
Dans la pratique, il y a d’autres problèmes importants qui doivent être pris en considération, incluant :
Performance : qui se rapporte à l’exactitude et la vitesse d’identification, les ressources requises pour obtenir l’exactitude d’identification et la vitesse désirées, aussi bien que les facteurs opérationnels et environnementaux qui les affectent.
Acceptabilité : ce qui indique le point auquel les gens sont disposés à accepter l’utilisation d’un trait biométrique particulier dans leurs vies quotidiennes.
Vulnérabilité (Mise en échec) : ce qui reflète à quel point il est facile de tromper le système par des méthodes frauduleuses.
Un système biométrique pratique devrait avoir une exactitude, et une vitesse d’identification acceptables avec des besoins raisonnables de ressources, il devrait être inoffensif aux utilisateurs, admis par la population prévue, et suffisamment robuste aux diverses méthodes et attaques frauduleuses.
La biométrie est un domaine émergeant, où la technologie améliore la capacité à identifier une personne. La protection des gens contre la fraude ou le vol est l’un des buts de la reconnaissance par la biométrie. L’avantage de la reconnaissance biométrique est que chaque individu a ses propres caractéristiques physiques qui ne peuvent être changées, perdues ou volées. La méthode de reconnaissance biométrique peut aussi être utilisée en complément ou remplacement des mots de passe.
Plusieurs raisons peuvent motiver l’usage de la reconnaissance par la biométrie :
Une haute sécurité : en l’associant à d’autres technologies comme le cryptage.
Confort : en remplaçant juste le mot de passe, exemple pour l’accès à un système d’exploitation, la biométrie permet de respecter les règles de base de la sécurité (ne pas
inscrire son mot de passe à coté du PC, ne pas désactiver l’écran de veille pour éviter des saisies de mots de passe fréquentes). Et quand ces règles sont respectées, la biométrie évite aux administrateurs de réseaux d’avoir à répondre aux nombreux appels pour perte de mot de passe (que l’on donne parfois au téléphone, donc sans sécurité).
Sécurité/Psychologie : dans certains cas, particulièrement pour le commerce électronique, l’usager n’a pas confiance. Il est important pour les acteurs de ce marché de convaincre le consommateur de faire des transactions. Un moyen d’authentification connu comme les empreintes digitales pourrait faire changer le comportement des consommateurs.
Les systèmes d’authentification biométriques suppriment donc :
La duplication.
Le vol.
L’oubli.
La perte.
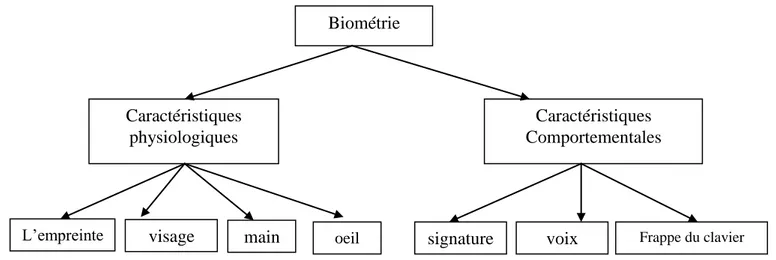
1. La classification et la comparaison de La Biométrie
Selon Miller la biométrie comprend des caractéristiques physiologiques et comportementales (Miller, 1994). La figure 1 illustre cela pour un nombre de biométries les plus fréquemment utilisées.
Figure 1. La classification de la Biométrie.
Un trait physiologique est relativement stable tel que l’empreinte digitale, la géométrie de la main, l’iris, la rétine. En effet, toutes ces caractéristiques sont fondamentalement invariables sans trauma (blessure) à l’individu. Un trait comportemental d’autre part, a une certaine base physiologique, mais reflète également l’état (émotif) physiologique d’une personne (Verlinde,1999).
Biométrie Caractéristiques physiologiques Caractéristiques Comportementales main visage
La comparaison entre ces différentes techniques est faite dans le tableau suivant (Jain ,2004):
Trait Biométrique Universalité Unicité Permanence Collecte Performance Acceptabilité Mise en
Echec ADN H H H B H B B Démarche M B B H B H M Empreint Digitale M H H M H M M Frappe du clavier B B B M B M M Iris H H H M H B B Main M M M H M M M Odeur H H H B B M B Oreille M M H M M H M Rétine H H M B H B B Signature B B B H B H H Visage H B M H B H H Voix M B B M B H H
Tableau. 1 Comparaison de diverses technologies biométriques ;haut, moyen et bas sont dénotés par H, M, et B, respectivement.
2. Le Système Multimodal
La multimodalité est l'utilisation de plusieurs modalités biométriques. La combinaison de plusieurs systèmes a pour objectif d'en diminuer les limitations. En effet, l'utilisation de plusieurs systèmes a pour but premier d'améliorer les performances de reconnaissance. En augmentant la quantité d'informations discriminante de chaque personne, on souhaite augmenter le pouvoir de reconnaissance du système. De plus, le fait d'utiliser plusieurs modalités biométriques réduit le risque d'impossibilité d'enregistrement ainsi que la robustesse aux fraudes.
Les systèmes biométriques multimodaux diminuent les contraintes des systèmes biométriques monomodaux en combinant plusieurs systèmes. On peut différencier 5 types de systèmes multimodaux selon les systèmes qu'ils combinent On les appelle :
Multi-capteurs lorsqu'ils associent plusieurs capteurs pour acquérir la même modalité, par exemple un capteur optique et un capteur capacitif pour l'acquisition de l'empreinte digitale.
multi-instances lorsqu'ils associent plusieurs instances de la même biométrie, par exemple l'acquisition de plusieurs images de visage avec des changements de pose, d'expression ou d'illumination.
multi-algorithmes lorsque plusieurs algorithmes traitent la même image acquise, cette multiplicité des algorithmes peut intervenir dans le module d'extraction en considérant plusieurs ensembles de caractéristiques et/ou dans le module de comparaison en utilisant plusieurs algorithmes de comparaison.
multi-échantillons lorsqu'ils associent plusieurs échantillons différents de la même modalité, par exemple deux empreintes digitales de doigts différents ou les deux iris. Dans ce cas les données sont traitées par le même algorithme mais nécessitent des références différentes à l'enregistrement contrairement aux systèmes multi-instances qui ne nécessitent qu'une seule référence.
multi-biométries lorsque l'on considère plusieurs biométries différentes, par exemple visage et empreinte digitale.
Un système multimodal peut bien sûr combiner ces différents types d'associations, par exemple l'utilisation du visage et de l'empreinte mais en utilisant plusieurs doigts. Tous ces types de systèmes peuvent pallier à des problèmes différents et ont chacun leurs avantages et inconvénients. Les quatre premiers systèmes combinent des informations issues d'une seule et même modalité ce qui ne permet pas de traiter le problème de la non-universalité de certaines biométries ainsi que la résistance aux fraudes, contrairement aux systèmes "multi-biométries".
3. Fusion
Bien que le concept de fusion de données ait explosé relativement récemment dans la littérature scientifique, il est utilisé depuis fort longtemps dans la nature : ainsi les animaux eux-mêmes exploitent l’information auditive et visuelle pour se protéger contre d’éventuels risques.
On peut aussi citer la vision humaine pour illustrer les bénéfices de la fusion de données. Les deux yeux d’un homme observent les objets sous des angles légèrement différents, et cette stéréovision permet la perception du relief. Exploiter conjointement deux yeux étend donc les capacités données par deux fois un œil. Un autre avantage est la robustesse liée à la redondance. Si l’un des yeux est défaillant, la vision est encore possible, bien qu’en mode dégradé. On peut citer un deuxième exemple dans notre vie quotidienne, les systèmes biologiques. Le système humain utilise ses cinq sens pour percevoir son environnement (au sens très large). Les capteurs de notre corps acquièrent des informations par la vue, l’odorat, le toucher, l’ouïe et le goût. Les données acquises sont traitées par le cerveau. Pour ce faire, le cerveau va en plus utiliser d’autres sources d’information : sa mémoire, son expérience, et ses connaissances a priori. En faisant appel à ses capacités de raisonnement, le cerveau « fusionne » toutes les informations, et effectue des déductions afin de produire éventuellement une représentation de cet environnement et d’ordonner des actions.
3.1 L’intérêt de la fusion de données
Les progrès permanents de la science et de la technologie et aussi de l’informatique permettent de disposer d’informations de plus en plus nombreuses et complexes, de nature et de fiabilité différente. Il est de plus en plus demandé aux systèmes d’information et de communication ou de décision d’aider ou de coopérer avec les experts du domaine applicatif dans le but de décider. La fusion de données permet de répondre à ces demandes et de résoudre ces problèmes.
La fusion de données est un sujet de plus en plus actuel, car susceptible d’aider efficacement les scientifiques à extraire des informations de plus en plus pertinentes et Précises. D’après (Waltz, 1990) la fusion de données offre de nombreux avantages :
Robustesse et fiabilité ; le système est opérationnel même si une ou plusieurs sources d’informations sont défectueuses.
Augmentation de la couverture spatiale et temporelle de l’information et des déductions.
Accroissement du nombre de dimensions de l’espace des observations, menant à un accroissement de la qualité des déductions, et à une réduction de la vulnérabilité du système.
Réduction de l’ambiguïté des déductions : des informations plus complètes ou plus précises permettent un meilleur choix entre les différentes hypothèses.
Apport d’une solution à l’explosion de la quantité d’informations disponibles aujourd’hui.
3.2 Définition de la fusion de données
Le concept de la fusion de données est facile à comprendre, mais il est difficile d’en trouver une définition qui rende compte de ce cadre formel et de ses multiples facettes. La difficulté d’une définition exacte de la fusion de données persiste à cause d’une bataille de mots entre les experts du domaine. Même le sens exact de la fusion varie d’un scientifique à l’autre. Plusieurs mots peuvent être cités qui sont employés pour désigner la fusion comme« merging », « combinaison », « synergie », « intégration », etc. Quelques scientifiques disent que le mot « merging » ne correspond pas à la fusion ou plus précisément que la fusion désigne un domaine plus vaste que merging. Un autre mot, très souvent utilisé à la place de fusion, est « agrégation ». Il est vrai que la fusion et l’agrégation ont pour objectif le même but c’est-à-dire un résultat final plus pertinent et plus robuste à partir d’une variation de données disponibles. Le terme « agrégation » est plutôt utilisé pour les données numériques et/ ou des objets (critères) ordonnés.
Les définitions de fusion de données sont souvent restreintes à un ensemble d’outils ou de méthodes, voire à un ensemble d’informations. Il est rarement question de qualité et la notion de concept est totalement exclue. En effet, la difficulté de considérer une définition unique est due au fait
que la fusion de données est un domaine très appliqué et dans des circonstances très variées. Elle est multidisciplinaire dans un sens et elle se trouve au carrefour de plusieurs sciences. Nous décrivons maintenant deux définitions proposées par deux groupes de spécialistes.
La définition proposée par les directeurs conjoints des laboratoires(JDL), du ministère de la défense aux Etats-Unis d’Amérique (JDL,1991) est un cas à part. Elle est appelée « le modèle JDL » et a fait l’objet de nombreuses études. Ce modèle définit la fusion de données comme un processus multi-niveaux à facettes multiples ayant pour objet la détection automatique, l’association, la corrélation, l’estimation et la combinaison d’informations de sources singulières et plurielles. Le modèle JDL est extrêmement populaire dans le domaine militaire. Malgré sa popularité et son importance pour le développement de la fusion de données, ce modèle ne constitue pas pour autant une définition de la fusion de données et, en aucun cas, ne fait référence à un cadre conceptuel (Wald, 2002).
Le groupe européen SEE (Société d’électricité et d’électronique), la branche française de l’Institute of Electric and Electronics Engineers (IEEE), et la branche européenne de l’International Society for Photogrammetry and Remote Sensing (ISPRS) ont proposé la définition suivante : la fusion de données constitue un cadre formel dans lequel s’expriment les moyens et techniques permettant l’alliance des données provenant de sources diverses. Cette définition met clairement l’accent sur le concept et non plus sur les méthodes, techniques ou stratégies (Wald, 2002). La définition ajoute que la fusion de données vise à l’obtention d’information de plus grande qualité ; la définition exacte de l’expression « plus grande qualité » dépendra de l’application. La qualité est un mot générique indiquant que le résultat de la fusion est plus satisfaisant pour l’usager que l’ensemble de l’information originale.
3.3Les types de fusion
Un système de fusion est généralement composé de sources d’information, de moyens d’acquisition d’information, de moyens de communication et de capacités à traiter l’information. Il peut être par conséquent très complexe. Il est fréquent et pratique, lors de l’étude ou de la présentation d’un système, de séparer les aspects topologiques et les aspects traitement d’informations, même s’il existe des interconnexions. La topologie a une influence importante sur le choix de l’architecture du système de fusion, sur les choix d’outils, des méthodes de traitement et de communication.
On peut trouver dans la littérature plusieurs manières de classer les différentes étapes ou types de fusion. Cette différence provient principalement du niveau où l’opération de fusion est accomplie, de l’objectif de cette opération, du type de sources (ou capteurs) et de l’application considérée.
On peut par exemple reprendre la classification générale proposée par (Dasarathy,1997) qui considère trois principaux niveaux de fusion :
fusion de mesures ou des pixels en traitement d’images, on dit aussi bas niveau ; il concerne la fusion d’informations directement issues des capteurs.
fusion d’attributs, on dit aussi niveau intermédiaire ; il concerne la combinaison d’informations extraites après diverses phases de traitement et d’analyse des mesures.
fusion de décisions, on dit aussi haut niveau, celui-ci concerne la combinaison des décisions obtenues à partir de chaque source. La décision finale est prise en fonction des décisions de tous les capteurs.
3.4 Les différents niveaux de fusion
Dans un système typique de reconnaissance de formes, la quantité d’informations disponible devient compressée à mesure que l’on progresse du module de capture vers le module de décision. Dans un système biométrique multimodal, la fusion peut se faire en utilisant l’information disponible dans n’importe quel de ces modules. Nous allons maintenant détailler ces niveaux de fusion que l’on peut répartir en deux grandes familles, la fusion avant la correspondance (“matching”) et la fusion après la correspondance (Sand ,2002).
3.4.1 Avant le Matching
Avant le « Matching », l’intégration d’informations peut avoir lieu soit au niveau capteur, soit aux niveaux caractéristiques.
3.4.1.1 Niveau Capteur (Sensor Level)
Les données brutes (“raw data”) provenant des capteurs sont combinées par fusion au niveau capteur (Lyen ,1995). La fusion au niveau capteur peut se faire uniquement si les diverses captures sont des instances du même trait biométrique obtenu à partir de plusieurs capteurs compatibles entre eux ou plusieurs instances du même trait biométrique obtenu à partir d’un seul capteur. De plus, les captures doivent être compatibles entre elles et la correspondance entre les points dans les données brutes doit être connue par avance. Par exemple, les images de visage obtenues à partir de plusieurs caméras peuvent être combinées pour former un modèle du visage. Un autre exemple de fusion au niveau capteur consiste à mettre en mosaïque plusieurs images d’empreintes digitales afin de former une image d’empreinte digitale finale plus complexe (Ross,2002) (Moon ,2004). La fusion au niveau capteur n’est généralement pas possible si les instances des données sont incompatibles (par exemple, il est peut être difficile de fusionner des images de visages provenant de caméras ayant des résolutions différentes).
3.4.1.2 Niveau Caractéristiques (Feature Level)
La fusion au niveau caractéristiques consiste à combiner différents vecteurs de caractéristiques (“feature vectors”) qui sont obtenus à partir d’une des sources suivantes plusieurs capteurs du même trait biométrique, plusieurs instances du même trait biométrique, plusieurs unités du même trait biométrique ou encore plusieurs traits biométriques.
Quand les vecteurs de caractéristiques sont homogènes (par exemple, plusieurs images d’empreinte digitale du doigt d’un utilisateur), un unique vecteur de caractéristiques résultant peut être calculé comme une somme pondérée des vecteurs de caractéristiques individuels.
Lorsque les vecteurs de caractéristiques sont hétérogènes (par exemple, des vecteurs de caractéristiques de différentes modalités biométriques comme le visage et la géométrie de la main), nous pouvons les concaténer pour former un seul vecteur de caractéristiques. Cependant, la concaténation n’est pas possible lorsque les ensembles de caractéristiques sont incompatibles. Par exemple, les minuties d’empreintes digitales et les coefficients de visage issus du PCA (“eigen-face coefficients”).
Les tentatives de Kumar (Kuma, 2003) qui ont combiné des caractéristiques de l’empreint palmaire et de la géométrie de la main d’une part, et Ross (Ross, 2005) qui ont combiné des caractéristiques du visage avec celles de la géométrie de la main d’autre part, n’ont rencontré qu’un succès limité.
Les systèmes biométriques qui intègrent l’information à une étape en amont du traitement sont censés être plus efficaces que les systèmes qui opèrent une fusion à un niveau plus abstrait. Puisque les caractéristiques issues d’une entrée biométrique sont supposées contenir une information plus riche qu’un score de correspondance ou la décision d’un matcher (module de reconnaissance) biométrique, la fusion au niveau caractéristiques devrait fournir de meilleurs résultats de reconnaissance que les autres niveaux d’intégration.
Cependant, la fusion au niveau caractéristique est difficile à atteindre en pratique à cause des raisons suivantes :
1. La relation entre les espaces de caractéristiques (“feature spaces”) de différents systèmes biométriques n’est pas forcément connue. Dans le cas où la relation est connue par avance, on doit prendre soin d’éliminer les caractéristiques qui sont fortement corrélées. Cela requiert l’application d’algorithmes de sélection de caractéristiques avant l’étape de classification, 2. La concaténation de deux vecteurs de caractéristiques peut engendrer un vecteur de
caractéristiques ayant une grande dimension, menant au fameux problème de la "malédiction de la dimensionnalité". Bien que ce soit un problème général dans la plupart des applications
de reconnaissance de forme, cela est encore plus marquant dans les applications biométriques à cause du temps, de l’effort et du coût impliqués dans la collecte de grandes quantités de données biométriques.
3. La plupart des systèmes biométriques commerciaux ne fournissent pas l’accès aux vecteurs de caractéristiques qui sont utilisés dans leurs produits. Ainsi, très peu de chercheurs ont étudié la fusion aux niveaux caractéristiques et la plupart d’entre eux se tournent généralement vers les schémas de fusion après le matching.
3.4.2 Après le Matching
Les schémas d’intégration de l’information après l’étape de la classification ou de correspondance peuvent être divisés en quatre catégories : sélection dynamique de classifieurs, fusion au niveau décision, fusion au niveau range fusion au niveau score.
Un schéma de sélection dynamique de classifieurs choisit les résultats d’un classifieur qui est le plus à même de donner la décision correcte d’un modèle d’entrée spécifique (Wood,1997). Ceci est aussi connu sous le nom d’approche “winner-take-all” et le système qui effectue cette sélection est appelée “associative switch” (Chen,1997)
3.4.2.1. Niveau Décision (Decision Level)
L’intégration d’information au niveau abstrait ou au niveau décision peut être mis en place lorsque chaque matcher biométrique décide individuellement de la meilleure correspondance possible selon l’entrée qui lui est présentée. Les méthodes comme le “majority voting” (Lam ,1997), le “behavior knowled gespace” (Lam,1995), le “weighted voting” basé surla théorie Dempster-Shafer (Xu ,1992),les règles ET et OU (Daug,1998), etc. peuvent utilisées afin d’arriver à la décision finale.
3.4.2.2. Niveau Rang (Rank Level)
Quand la sortie de chaque “matcher” (module de reconnaissance) biométrique est un sous-ensemble de correspondances possibles triées dans un ordre décroissant de confiance, la fusion peut se faire au niveau rang. Ho et al.(Ho ,1994) décrivent trois méthodes pour combiner les rangs assignés par différents matchers. Dans la technique “high estrank method”, on assigne à chaque correspondance possible le meilleur (minimum) rang calculé par différents matchers. En cas d’égalité, on en retient un seul au hasard afin d’arriver à un ordre de rang strict et la décision finale est prise selon les rangs combinés. La méthode “Borda count” utilise la somme des rangs assignés par les matchers individuels afin de calculer les rangs combinés. La méthode de régression logistique est une généralisation de la méthode “Borda count” où une somme pondérée des rangs individuels est calculée et les poids sont déterminés par régression logistique.
3.4.2.3. Niveau Score (Score Level)
Il existe deux approches pour combiner les scores obtenus par différents matchers. La première approche est de voir cela comme un problème de classification, tandis que l’autre approche est de traiter le sujet comme un problème de combinaison. Il est important de noter que Jain et al.ont montré que les approches par combinaison sont plus performantes que la plupart des méthodes de classification (Jain 2005) (Ross 2003).
Dans l’approche par classification, un vecteur de caractéristiques est construit en utilisant les scores de correspondance donnés en sortie par les matchers individuels ; ce vecteur est ensuite attribué à une des deux classes : "accepté" (utilisateur authentique ou “genuine user”) ou "rejeté" (utilisateur imposteur ou “impostor user”). En général, le classifieur utilisé pour cette opération est capable d’apprendre la frontière de décision sans tenir compte de la manière dont le vecteur de caractéristiques a été généré. Ainsi, les scores en sortie de différentes modalités peuvent être non-homogènes (mesure de distance ou de similarité, différents intervalles de valeurs prises, etc.) et aucun traitement n’est requis avant de les envoyer dans le classifieur.
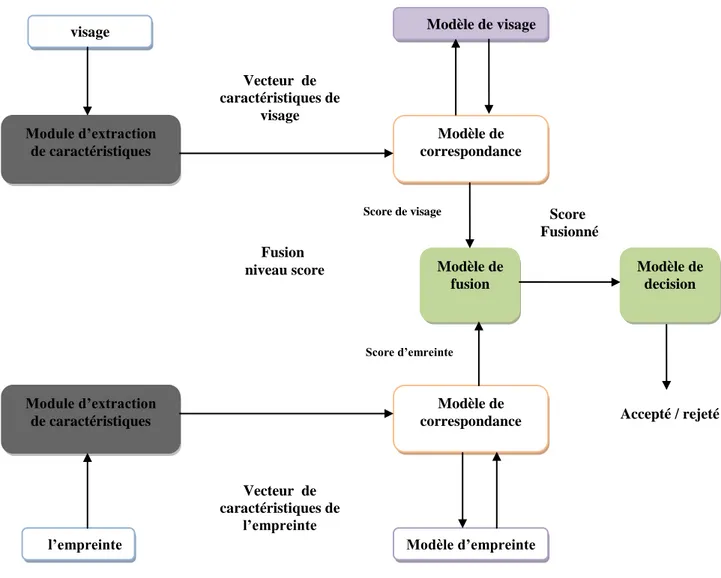
Dans l’approche par combinaison, les scores de correspondance individuels sont combinés de manière à former un unique score qui est ensuite utilisé pour prendre la décision finale. Afin de s’assurer que la combinaison de scores provenant de différentes modalités soit cohérente, les scores doivent d’abord être transformés dans un domaine commun: on parle alors de normalisation de score, la figure2 illustre la fusion au niveau score:
Figure 2.Fusion au niveau score dans un système biométrique multimodal Modèle d’empreinte Modèle de correspondance Modèle de visage l’empreinte visage Vecteur de caractéristiques de l’empreinte Vecteur de caractéristiques de visage Modèle de fusion Modèle de correspondance Module d’extraction de caractéristiques Module d’extraction de caractéristiques Modèle de decision Accepté / rejeté Score de visage Score d’emreinte Fusion niveau score Score Fusionné
On peut illustre les différents niveaux de fusion par le schéma suivent (figure 3)
Figure3. Les différents niveaux de fusion
Score Extraction des Caractéristiques Capture de la biométrie Score Extraction des Caractéristiques Capture de la biométrie Décision Décision Donnée biométrique numérisée Score de similarité Vecteur de caractéristiques Décision Fusion au niveau des décisions Fusion au niveau des score Fusion au niveau des caractéristiques Fusion au niveau capture
4. L’identification Multibiométrique
L’identification automatique de l'homme basée sur la reconnaissance biométrique est en passe de transformer notre société. La biométrie s’impose de plus en plus comme le moyen sécurisé le plus sûr au monde. Cette technologie d’identification et d’authentification consiste à transformer une caractéristique biologique, morphologique ou comportementale en une empreinte numérique.
L’objectif de la biométrie est d’attester l’unicité d’une personne à partir de la mesure d’une partie inchangeable ou immaitrisable de son corps.
Chaque technique biométrique inclut des avantages et des inconvénients, en termes de performances, acceptation de la part des utilisateurs, coûts, universalité d’utilisation, etc. Ce qui ne garantit pas avec certitude une bonne identification. Ainsi, de plus en plus de recherches se focalisent sur la fusion d’indicateurs biométriques multiples. En effet, plusieurs travaux ont montré que la combinaison de différentes signatures biométriques permet d’améliorer de manière significative les performances des systèmes basés sur une seule modalité : La biométrie multimodale permet de palier certains inconvénients de la mono modalité, mais surtout d’augmenter les performances (Ros ,2004). Les systèmes biométriques différents font en général des erreurs différentes, et il est possible de tirer parti de cette complémentarité afin d’améliorer la performance globale du système.
4.1 Système d'identification
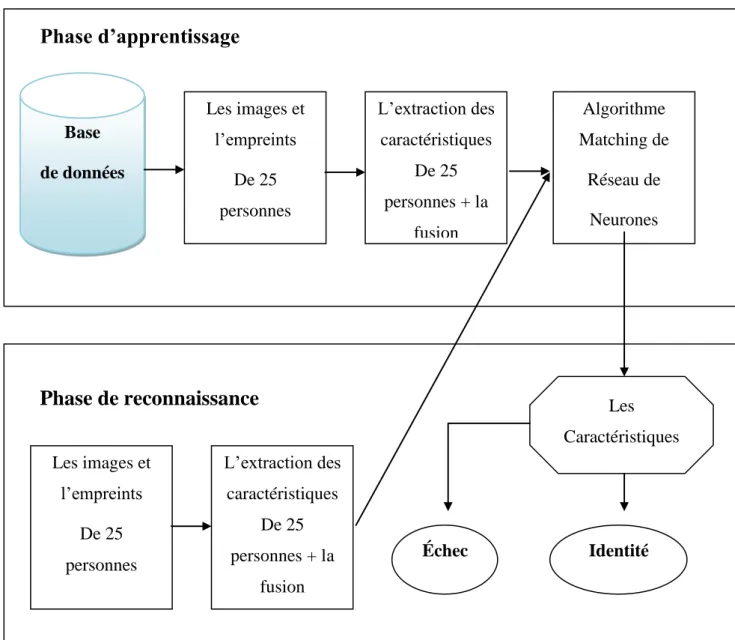
Un Système d’identification multimodal Un système d’identification a pour but de découvrir l’identité a priori inconnue d’un individu. Il comprend deux phases distinctes :
Phase d’enregistrement/enrôlement: cette phase consiste en l'enregistrement des données
biométriques d'une personne en lui associant un identifiant dans une base de données comme montré dans la figure 4.
Phase d’identification: dans cette phase les caractéristiques biométriques de la personne
à identifier sont acquises et comparées à celles de l’ensemble des clients connus du système et stockées dans une base de données. C’est une comparaison un à plusieurs (1:N).
Figure4. Système d’identification
Indvidu1 Indvidu N
Acquisition des données biométriques
traitement
Profils biométriques de la population + identifiant Indvidu
Acquisition des donnes biométriques Données brutes Caractéristiques biométriques acquises Données brutes traitement Comparaison + avis Caractéristiques biométriques acquises
Extraction des profils candidats
Identifiant Au rejet
4.2 Normalisation de score
Considérons un système de vérification biométrique multimodale qui adopte une approche de fusion par combinaison, au niveau score. Le cadre de travail théorique développé par Kittler et al.(Kitt,1998) utilise une approche probabiliste qui peut être appliquée à ce système seulement si la sortie de chaque modalité est de la forme P{authentique|X}, c’est-à-dire la probabilité a posteriori qu’un utilisateur soit "authentique" sachant l’échantillon d’entrée biométrique X. En pratique, la plupart des systèmes biométriques donnent en sortie un score de correspondances. Verlinde et al. ont proposé que ce score de correspondances soit lié à P{authentique|X}comme suit (4.1) :
{ | } ) )
Où f est une fonction monotonique et η est l’erreur faite par le système biométrique qui dépend de l’échantillon d’entrée biométrique X.
Cette erreur η peut être due au bruit introduit par le capteur pendant l’acquisition du signal biométrique et les erreurs faites par l’extraction de caractéristiques et les processus de correspondance.
Si l’on suppose que η = 0, il est raisonnable d’approximer P{authentique|X} par P{authentique|s}. Dans ce cas, le problème revient à calculer P{authentique|s}et cela requiert l’estimation des densités conditionnelles P(s|authentique)etP(s|imposteur).
Les techniques de fusion de Snelick et al.(Snel, 2003) utilisent l’approche probabiliste de Kittler et al. en se servant d’un ensemble de données d’entraînement composé de 100 personnes afin d’estimer les probabilités a posteriori des authentiques P{authentique|s};
Pour ce faire, ils utilisent la moyenne et la variance des scores authentiques et imposteurs provenant de cet ensemble de données d’entraînement en supposant une distribution normale pour leurs densités conditionnelles respectives P(s|authentique) et P(s|imposteur). Cependant, leur approche possède deux inconvénients majeurs. Tout d’abord, l’hypothèse d’une distribution normale pour les scores n’est pas valide dans certains cas, en particulier pour les scores authentiques. D’autre part, cette approche n’utilise pas les probabilités apriori des utilisateurs authentiques et imposteurs qui pourraient être disponibles au sein du système. En effet, la formule que Snelick et al. utilisent pour estimer P{authentique|s} (Snel, 2003) n’est vraie que dans le cas où l’on considère les probabilités a priori(c’est-à-dire les fréquences des classes)équiprobables; dans le cas contraire, on doit directement appliquer le Théorème de Bayes avec des densités de probabilités (4.2) :
{ | } | ) { }
| ) { } | ) { } )
Pour ces raisons, une méthode d’estimation de densité par fenêtre de Parzen a été proposée dans (Duda, 2001) cette technique permet d’estimer la véritable densité conditionnelle des scores authentiques et imposteurs.
Ainsi, bien que la technique d’estimation de densité par fenêtre de Parzen réduise de manière significative l’erreur sur l’estimation deP{authentique|s}(en particulier lorsque les densités conditionnelles ne sont pas gaussiennes), l’estimation de densité possède toujours des inexactitudes dues à la taille finie de l’ensemble des données d’entraînement et aux problèmes liés au choix de la largeur de fenêtre optimale pendant le processus d’estimation de densité. De plus, l’hypothèse selon laquelle la valeur de η dans l’équation (3.1) est nulle n’est pas valide, d’un point de vue pratique, dans la plupart des systèmes biométriques. Puisque η dépend de l’échantillon d’entrée biométrique X, il est possible d’estimer η seulement si le système biométrique donne une mesure de confiance (qui prend en compte la nature de l’entrée X) sur le score de correspondance en plus du score lui-même. En l’absence de cette mesure de confiance, la valeur calculée de P{authentique|s} n’est pas un bon estimateur de P{authentique|X}et cela peut amener à une faible performance de reconnaissance du système multimodal.
En conclusion, lorsque les sorties des modalités individuelles sont des scores de correspondance sans aucune mesure qui quantifierait la confiance de ces scores, il est préférable de combiner directement ces scores de correspondance sans les convertir en probabilités.
4.3 Pourquoi normaliser les scores ?
Trois problèmes important sont besoin d’être considérés avant même de combiner les scores de correspondance en un seul et unique score. Tout d’abord, les scores de correspondance au niveau des sorties des matchers individuels peuvent ne pas être homogènes. Par exemple, un matcher peut donner en sortie une mesure de distance (dissimilarité) pendant qu’un autre donne en sortie une mesure de proximité (similarité). Ensuite, les sorties des matchers individuels ne sont pas nécessairement inclus dans le même intervalle. Enfin, les scores de correspondance en sortie des matchers peuvent suivre différentes distributions statistiques. A cause de ces raisons, la normalisation de score est essentielle pour transformer les scores des matchers individuels dans un domaine commun avant de les combiner. La normalisation de score est une étape critique dans la conception d’un schéma de combinaison pour la fusion au niveau score.
4.4 Identification d’une technique de normalisation de scores
La normalisation de score consiste à changer les paramètres de position (moyenne) et d’échelle (écart-type) des distributions de scores de correspondance en sortie des matchers individuels, de manière à ce que les scores de correspondance de différents matchers soient transformés dans un domaine commun. Quand les paramètres utilisés pour la normalisation sont déterminés en utilisant un ensemble de données d’entraînement fixé, on parle de normalisation de score fixée (Brun,1995). Dans ce cas, la distribution des scores de correspondance de l’ensemble des données d’entraînement est examinée et un modèle cohérent est choisi pour "coller" à la distribution. A partir de ce modèle, les paramètres de normalisation sont déterminés. Dans la normalisation de score adaptative, les paramètres de normalisation sont estimés en se basant sur le vecteur de caractéristiques actuel. Cette approche à la faculté de s’adapter aux variations de la donnée en entrée. Pour avoir un bon schéma de normalisation, les estimateurs des paramètres de position et d’échelle de la distribution de score de correspondance doivent être robustes et efficaces. La robustesse se réfère à l’insensibilité à la présence de valeurs aberrantes (“outliers”). L’efficacité se réfère à la proximité de l’estimateur obtenu par rapport à l’estimateur optimal lorsque la distribution des données est connue. Huber (Hube, 1981) explique les concepts de robustesse et d’efficacité de procédures statistiques. Finalement, bien que de nombreuses techniques peuvent être utilisées pour la normalisation de score, le défi réside dans l’identification d’une technique qui serait à la fois robuste et efficace.
4.5 Les différentes techniques de normalisation de scores
La technique de normalisation la plus simple est la normalisation Min-Max. Elle est la plus adaptée dans le cas où les bornes (valeurs minimales et maximales) des scores produits par un matchers sont connues. Dans ce cas, on peut facilement translater les scores minimums et maximums respectivement vers 0 et 1. Cependant, même si les scores de correspondance ne sont pas bornés, on peut estimer les valeurs minimales et maximales pour un jeu de scores de correspondance donné et appliquer ensuite la normalisation Min-Max. Soit sij le j ème score de correspondance de sortie de la
ième modalité, où i = 1,2,...,R et j= 1,2,...,M (R est le nombre de modalités et M le nombre de scores de correspondance disponibles dans l’ensemble de données d’entraînement). Le score normalisé Min-Max pour le score de test sikest donné par : S’ik
{ })
{ }) { })
)
Où{s ij}={s i1 , si2 ,...,siM } Quand les valeurs minimales et maximales sont estimées à partir du
jeu d’entraînement de scores donné, cette méthode n’est pas robuste (c’est-à-dire que cette méthode est fortement sensible aux valeurs aberrantes dans les données utilisées pour l’estimation). La normalisation Min-Max conserve la distribution de scores originale à un facteur d’échelle près et
transforme tous les scores dans l’intervalle [0,1]. Les scores relatifs à des mesures de distance peuvent être transformés en des scores de similarité en soustrayant le score normalisé à 1.
La méthode de “decimals caling” peut être appliquée lorsque les scores de différents matchers évoluent selon une échelle logarithmique. Par exemple, si un matcher à des scores dans l’intervalle [0,1]et l’autre matcher a des scores dans l’intervalle[0,100], la normalisation suivante peut être appliquée :
)
Où n = log10 max({si.}). Les problèmes avec cette approche sont le manque de robustesse et
l’hypothèse selon la quelle les scores de différents matchers varient d’un facteur logarithmique .
La technique de normalisation de score la plus employée est certainement la Z-Score qui utilise la moyenne arithmétique et l’écart-type des données. On peut s’attendre à ce que cette méthode fonctionne bien si on a une connaissance a priori du score moyen et des variations de score d’un matcher. Si on n’a pas de connaissance a priori sur la nature de l’algorithme de reconnaissance, nous devons alors estimer la moyenne et l’écart-type des scores à partir d’un jeu de scores de correspondance donné. Les scores normalisés sont donnés par :
)
Où µ est la moyenne arithmétique et σ l’écart-type des données. Cependant, la moyenne et l’écart-type sont tous les deux sensibles aux valeurs aberrantes et donc cette méthode n’est pas robuste. De plus, la normalisation Z-Score ne garantit pas un intervalle commun pour les scores normalisés provenant de différents matchers. Si la distribution des scores n’est pas gaussienne, la normalisation Z-Score ne conserve pas la distribution d’entrée en sortie. Cela est simplement dû au fait que la moyenne et l’écart-type sont les paramètres de position et d’échelle optimaux seulement pour une distribution gaussienne. Pour une distribution arbitraire, la moyenne et l’écart-type sont respectivement des estimateurs raisonnables de position et d’échelle, mais ne sont pas optimaux.
La médiane et l’écart absolu médian (MAD) sont insensibles aux valeurs aberrantes et aux points aux extrémités d’une distribution. Ainsi, une méthode de normalisation utilisant la médiane et la MAD serait robuste et est donnée par:
)
Où MAD=median ({|s i. −median ({si. })|}).Cependant, les estimateurs issus de la médiane et de
la MAD ont une faible efficacité comparée aux estimateurs issus de la moyenne et de l’écart-type, c’est-à-dire que lorsque la distribution de score n’est pas gaussienne, la médiane et la MAD sont de pauvres estimateurs des paramètres de position et d’échelle. Ainsi, cette technique de normalisation ne conserve pas la distribution d’entrée et ne transforme pas les scores dans un intervalle commun.
4.6 Approche par classification de scores
Plusieurs classifieurs ont été utilisés pour combiner les scores de correspondance afin d’arriver à une décision.
Wang (Wang, 2003) considèrent les scores provenant de modules de reconnaissance faciale et de reconnaissance par l’iris comme un vecteur de caractéristiques à deux dimensions. Une analyse discriminante linéaire de Fisher (LDA) et un classifieur par réseau de neurones combiné à une fonction de base radiale (RBF) sont ensuite utilisés pour la classification.
Verlinde (Verl, 1999) combinent les scores provenant de deux modules de reconnaissance faciale et d’un module de reconnaissance de la parole avec l’aide de trois classifieurs : un premier classifieur utilisant la méthode des "k plus proches voisins" (“k-nearestneighbor algorithm”, “k-NN”) avec une quantification vectorielle, un deuxième classifieur basé sur un arbre décisionnel et un dernier classifieur basé sur un modèle de régression logistique.
Chatzis (Chat, 1999) utilisent une méthode de regroupement (“clustering”) appelée “fuzzy k-means” et une quantification vectorielle floue (“fuzzyvectorquantization”), couplée à un classifieur de réseau de neurones de RBF médiane pour fusionner les scores obtenus à partir de systèmes biométriques basés sur des caractéristiques visuelles (visage) et acoustiques (empreinte).
Sanderson(Sand, 2002) utilisent un classifieur basé sur une Machine à Vecteurs de Support (SVM) pour combiner les scores issus d’un module de reconnaissance faciale et d’un module de reconnaissance de la parole. Ils montrent que la performance d’un tel classifieur se détériore en la présence de conditions de bruit en entrée. Afin de sur monter ce problème, ils implémentent des classifieurs résistants au bruit structurel comme un classifieur linéaire définit par morceau (“piece-wiselinear classifier”) et un classifier Bayésien modifié.
Ross et Jain (Ross,2003) utilisent un arbre décisionnel et des classifieurs discriminants linéaires pour combiner les scores des modalités du visage, d’empreinte digitale et de géométrie de la main.