Digital Humanities in Society
Texte intégral
Figure





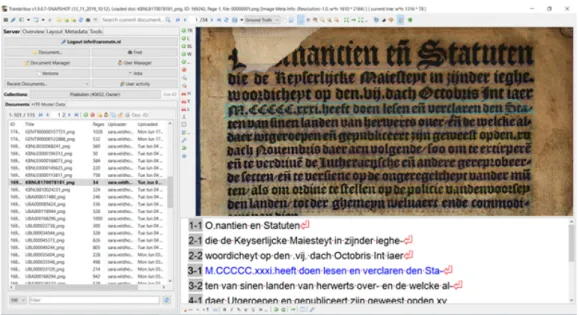



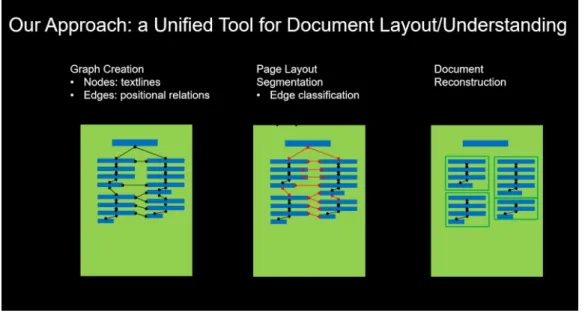
Documents relatifs
A progress report on traditional medicine and modem health care presented to the World Health Assembly in 1991 emphasized five major areas of concern: national
comprehensive, effective service to the whole population at a price the government can afford; how to measure its effectiveness and how to ensure that the service can be adapted
In 1991 , the Member States of WHO adopted a resolution at the World Health Assembly which set the goal of eliminating leprosy as a public health problem by the year
However, the rights approach has its own problems, especially in many countries in Asia. First, many rights result in conflicts not only between different persons but also in
Sex workers (female , male or transvestite), journalists, police, small shopkeepers, street vendors and so on are very important. to prevent sexually transmitted diseases
Bruno, the availability of modern methods in standard statistical software enables an autonomous use of those methods by humanity scholars (in Bruno’s paper, a R package for
Το ζήτηµα της ακαδηµαϊκής αναγνώρισης βρίσκεται στο κέντρο των ευρωπαϊκών και διεθνών πολιτικών συζητήσεων που αναπτύσσονται στο χώρο της ανώτατης
Focusing on the class of extreme value copulas, the authors study minimum distance estimators of the unknown Pickands dependence function (which characterizes the copula in
