Méthodes pour favoriser l’intégralité de l’amélioration dans le simplexe en nombres entiers - Application aux rotations d’équipages aériens
161
0
0
Texte intégral
Figure

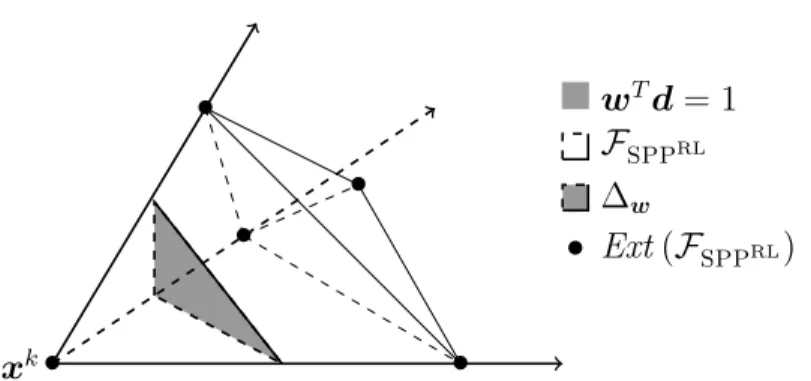
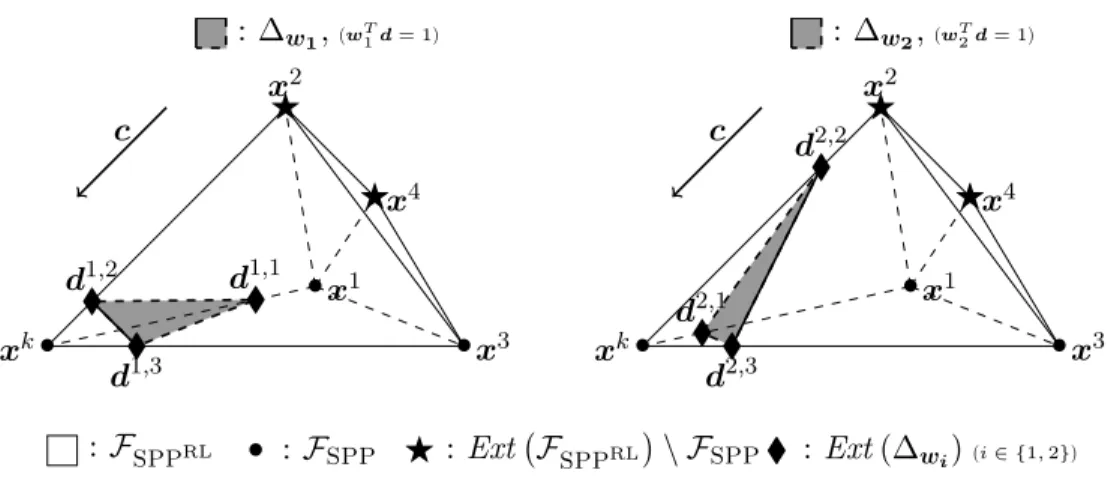
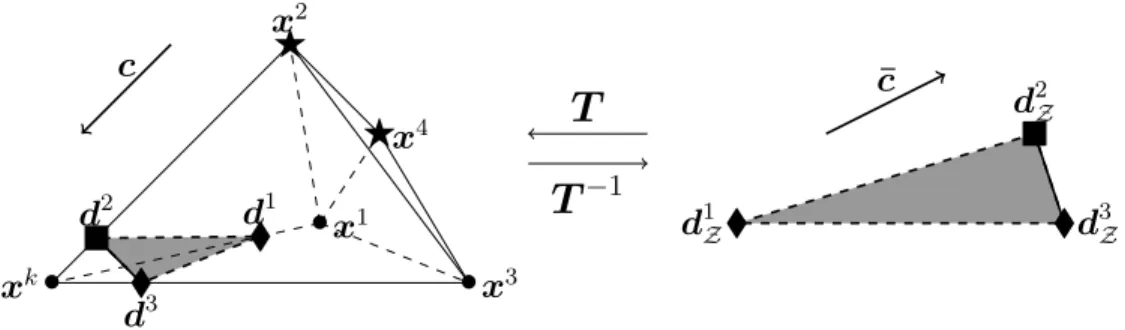
+7

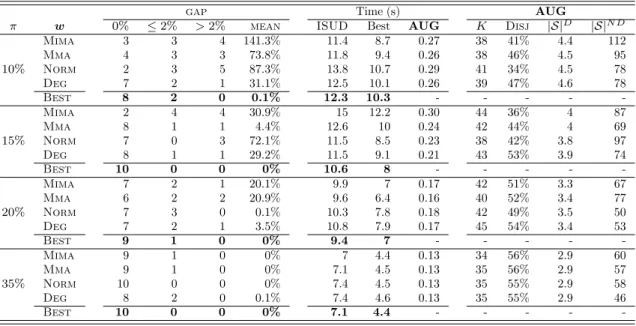
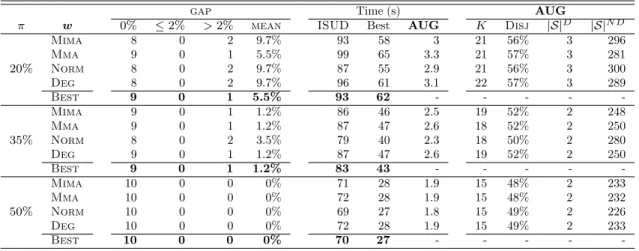
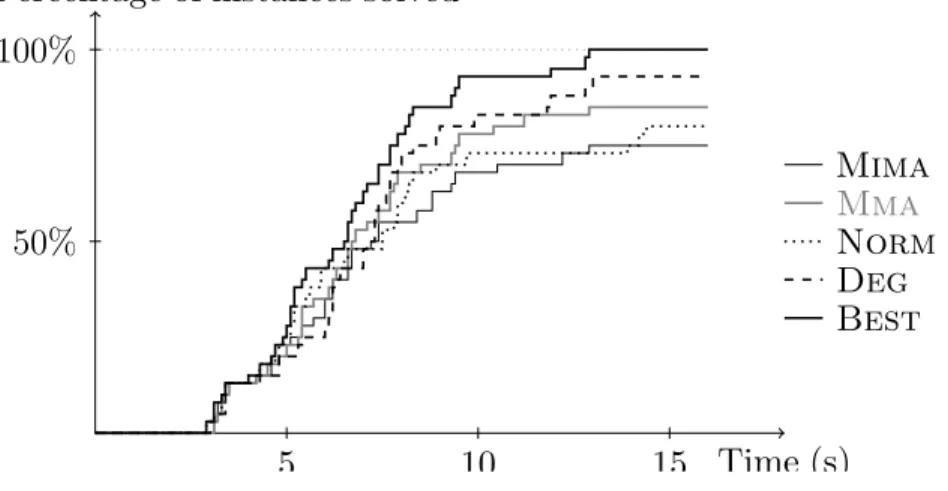
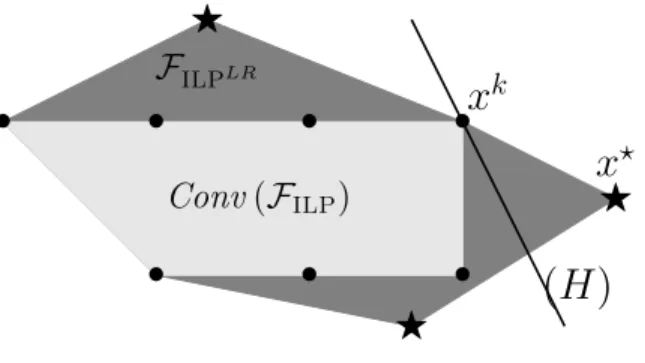

Documents relatifs