IMPACT DE L’HYPERPARAM `ETRE ALPHA SUR L’ALGORITHME D’ANALYSE DE TEXTES LATENT DIRICHLET ALLOCATION
´
EMILE DUCROCQ
D´EPARTEMENT DE G´ENIE INFORMATIQUE ET G´ENIE LOGICIEL ´
ECOLE POLYTECHNIQUE DE MONTR´EAL
M ´EMOIRE PR´ESENT´E EN VUE DE L’OBTENTION DU DIPL ˆOME DE MAˆITRISE `ES SCIENCES APPLIQU´EES
(G ´ENIE INFORMATIQUE) D´ECEMBRE 2014
c
´
ECOLE POLYTECHNIQUE DE MONTR´EAL
Ce m´emoire intitul´e :
IMPACT DE L’HYPERPARAM `ETRE ALPHA SUR L’ALGORITHME D’ANALYSE DE TEXTES LATENT DIRICHLET ALLOCATION
pr´esent´e par : DUCROCQ ´Emile
en vue de l’obtention du diplˆome de : Maˆıtrise `es sciences appliqu´ees a ´et´e dˆument accept´e par le jury d’examen constitu´e de :
M. GAGNON Michel, Ph.D., pr´esident
M. DESMARAIS Michel C., Ph.D., membre et directeur de recherche M. ROBILLARD Pierre N., D.Sc., membre
REMERCIEMENTS
Je souhaiterais remercier toutes les personnes qui m’ont aid´e durant le d´eroulement de la maˆıtrise. Tout d’abord, je veux exprimer ma gratitude envers M. Desmarais qui m’a propos´e un sujet de recherche `a la fois int´eressant et comportant des applications industrielles im-portantes. Je souhaite aussi souligner son implication, sa pers´ev´erance et son soutien mˆeme quand des difficult´es sont apparues, malgr´e les inconv´enients et le risque financier que cela comportait. Je remercie aussi les autres ´etudiants de mon laboratoire, qui m’ont permis de montrer d’autres aspects du domaine de recherche.
Merci aussi `a M. Catillon, PDG de l’entreprise Soar-media, qui m’a montr´e quelles pou-vaient ˆetre les applications pratiques que pouvait avoir le traitement de texte dans l’industrie, sans oublier l’organisme MITACS qui a permis dans un premier temps la collaboration avec l’entreprise. Le travail effectu´e en partenariat avec l’entreprise n’aurait pas ´et´e r´ealisable sans la contribution de ses employ´es, qui m’ont donn´e un aper¸cu plus complet des d´efis rencontr´es par une entreprise tentant d’exploiter le filtrage collaboratif dans des pages web.
Je remercie aussi les professeurs M. Gagnon, M. Robert et M. Robillard d’avoir accept´e d’ˆetre dans le jury de la pr´esentation de mon m´emoire, et tout particuli`erement M. Gagnon d’avoir pris la responsabilit´e suppl´ementaire d’en ˆetre le pr´esident. De plus, la flexibilit´e et la disponibilit´e de M. Robillard a ´et´e fortement appr´eci´ee, d’autant plus que les circonstances g´en´erales auraient pu ˆetre plus favorable.
J’ai aussi beaucoup appr´eci´e le soutien que ma famille m’a apport´e, le goˆut qu’ils m’ont transmis pour les ´etudes scientifiques et les encouragements que j’ai re¸cus tout au long de ma scolarit´e.
Je souhaite aussi remercier toutes les autres personnes qui m’ont apport´e leur aide ou leur soutien, de pr`es ou de loin, dans tous les aspects de ma vie.
R´ESUM´E
L’algorithme de classification non supervis´ee de documents Latent Dirichlet Allocation (LDA) est devenu en l’espace d’une dizaine d’ann´ees l’un des plus cit´es dans la litt´erature du domaine de la classification. Cet algorithme a la particularit´e de permettre `a un docu-ment d’appartenir `a plusieurs th´ematiques dans des proportions variables. Celui-ci se base sur un hyper-param`etre encore peu ´etudi´e dans la communaut´e scientifique, le param`etre α qui contrˆole la variabilit´e des th´ematiques pour chaque document. Ce param`etre correspond `
a l’unique param`etre de la distribution de Dirichlet. Il d´efinit la probabilit´e initiale des do-cuments dans le contexte du LDA. `A chaque extrˆeme du spectre des valeurs que l’on peut assigner `a ce param`etre, il devient possible de limiter chaque document `a une seule th´ ema-tique, jusqu’`a forcer tous les documents de partager toutes les th´ematiques uniform´ement. Le pr´esent m´emoire tente d’illustrer le rˆole du param`etre α et de d´emontrer l’effet qu’il peut avoir sur la performance de l’algorithme.
Le param`etre α est un vecteur dont la longueur correspond au nombre de th´ematiques et qui est g´en´eralement fix´e `a une valeur constante. Cette valeur peut ˆetre soit d´etermin´ee arbitrairement, soit estim´ee durant la phase d’apprentissage. Une valeur faible am`ene la classification vers un petit nombre de th´ematiques par document, et `a l’inverse une valeur ´
elev´ee am`ene `a assigner plusieurs th´ematiques par documents.
Certains travaux de Wallach et coll. ont d´emontr´e que des distributions non uniformes `
a ce param`etre pouvaient am´eliorer la mesure de classification de l’algorithme LDA. Ces travaux ont ´et´e effectu´es avec des donn´ees r´eelles pour lesquelles nous ne connaissons pas la distribution des th´ematiques sous-jacentes. Ces donn´ees ne permettent donc pas de valider si l’am´elioration obtenue provient du fait que la distribution des th´ematiques correspond effectivement `a une distribution non uniforme dans la r´ealit´e, ou si au contraire d’autres facteurs li´es `a des minimums locaux du LDA ou d’autres facteurs circonstanciels expliquent l’am´elioration.
Pour ´etudier cette question, notre ´etude porte sur des donn´ees synth´etiques. Le LDA est un mod`ele g´en´eratif qui se prˆete naturellement `a la cr´eation de documents synth´etiques. Les documents sont g´en´er´es `a partir de param`etres latents connus. L’hypoth`ese naturelle qui est faite est ´evidemment de pr´esumer qu’en arrimant le param`etre α utilis´e avec l’algorithme LDA `a la fois pour la g´en´eration des donn´ees et pour l’apprentissage, la performance sera la meilleure.
Les r´esultats d´emontrent que, contrairement aux attentes, la performance du LDA n’est pas n´ecessairement optimale lorsque les α de la g´en´eration et de l’apprentissage sont
iden-tiques. Les performances optimales varient selon les valeurs α du corpus. Les diff´erences les plus marqu´ees se trouvent lorsque le corpus tend `a ˆetre compos´e de documents mono-th´ematiques, auquel cas les α d’apprentissage uniformes fournissent les meilleures perfor-mances. Les diff´erences de performance s’amenuisent `a mesure que les valeurs de α deviennent grandes et que les corpus sont compos´es de th´ematiques multiples. On observe alors moins de diff´erences de performance et aucune tendance claire ne surgit quant `a la performance optimale.
Wallach et coll. ont d´emontr´e qu’une distribution non uniforme pour α pouvait donner de meilleurs r´esultats, ce qui ne corrobore pas les conclusions de cette ´etude. Cependant, les raisons de l’am´elioration obtenues demeurent encore hypoth´etiques. D’une part, les r´esultats proviennent de corpus r´eels, qui peuvent s’av´erer plus complexes ou relativement diff´erents du mod`ele du LDA. D’autre part, la diff´erence peut aussi provenir de l’approche utilis´ee pour l’entraˆınement des variables latentes, ou encore parce que l’asym´etrie du param`etre α ´etait plus faible que pour notre ´etude. L’am´elioration de leur performance pourrait provenir d’un maximum local. Car, contrairement `a notre ´etude, il est difficile avec des donn´ees r´eelles de tenter d’explorer l’espace des param`etres latents d’un corpus puisqu’ils sont inconnus.
Une autre contribution de cette ´etude est d’am´eliorer la performance du LDA par l’ini-tialisation d’un de ses param`etres latents, la distribution des mots par th´ematique (la ma-trice β). Nous utilisons une m´ethode de classification non supervis´ee bas´ee sur l’algorithme bay´esien na¨ıf. Il en est ressorti un gain de performance substantiel dans le cas de corpus mono-th´ematiques en plus d’une meilleure fiabilit´e par des r´esultats plus stables.
Une derni`ere contribution aborde la probl´ematique de la comparaison de classifications selon leur repr´esentation des th´ematiques. Cela a amen´e `a d´efinir une mesure de similarit´e de matrices qui est robuste `a la permutation et `a la rotation. Ce travail est toujours en cours, mais nous rapportons les r´esultats partiels, car ils fournissent une contribution non n´egligeable. En plus de notre contexte, cette mesure peut avoir des applications dans plusieurs autres domaines o`u il faut ´evaluer et comparer des r´esultats d’algorithmes non supervis´es, notamment comme la factorisation de matrices par valeurs non n´egatives (NMF), ou tout autre contexte o`u les r´esultats d’un algorithme s’expriment sous forme matricielle, mais o`u le r´esultat escompt´e peut ˆetre transform´e par rotation et par permutation ce qui complexifie la comparaison.
ABSTRACT
Latent Dirichlet Allocation (LDA) is an unsupervised text classification algorithm that has become one of the most famous and quoted algorithm within the last ten years. This algorithm allows documents to belongs to several topics. LDA relies on an hyperparameter that is generally fixed and received little attention in the scientific community. This variable, α, is a vector that controls the proportions of topics in documents. It is the sole parameter of the Dirichlet probability distribution and it defines the initial probability of documents in the LDA model. Through α, one can force every documents to be composed of a single topic, or conversely make every document share the same mixture of topics. This thesis investigates the role of the α hyperparameter on the document classification performance of LDA.
The α vector’s length corresponds to the number of topics, which is initially defined to a constant value. This value can either be defined arbitrarily, or estimated during the learning phase. A small value leads to a small number of topics per document and vice-versa.
Work by Wallach and al. has demonstrated that non-uniform distributions of this vector parameter could enhance the classification performance of the LDA algorithm. This work has been conducted with real data, for which the underlying distribution of topics is unknown. Therefore, it does not allow to verify if the the improvement effectively comes from a better fit of the α parameter to real data, or if it comes from some other reasons such as better avoidance of local minima.
To investigate this question, our study is conducted with synthetic data. The LDA is a generative model and the generation of documents from an underlying LDA latent parameter configuration is straightforward. The documents are generated from known distributions of topics. The obvious hypothesis is to expect that the best performance of the classification will be obtained when the vector α for the corpus generation is identical to the one of the LDA training.
Contrary to expectations, results show that the performance is not better when α of the corpus is identical to the training one. The performances vary across the range of corpora α parameter. The strongest differences are observed when the corpus tends to be composed of mono-topics documents, in which case a uniform α tends to give better performance. The differences become smaller as α values get larger, until the corpus is composed of multiple well-distributed topics. In that case, we find smaller performance differences, and no clear performance trend emerges.
These results run against Wallach and al. results who have demonstrated that a non-uniform distribution for α can lead to better results. However, the reasons for their
improve-ments remain unclear. On one hand, they were relying on real corpus, that can be more complex or be relatively different from the LDA model. On the other hand, the differences could be related to the LDA latent variable training algorithm, and their improvements could be due to a local maximum, or because the α parameter distribution was flatter than in our study. Unlike our study, it is hard to explore the space of latent variable of a corpus with real data and therefore to rule out the possibility that the real data is subject to local tendencies. Another contribution of this study is the improvement of the LDA through the initializa-tion of one of its latent parameter, namely the distribuinitializa-tion of words per topic (the β matrix). We use an unsupervised classification method based on the naive Bayes algorithm. It yields a substantial improvement of performance in the case of uni-topic corpus, in addition to a greater reliability as the results are more stable across simulation runs.
A last contribution of our work addresses the problem of comparing classifications along their topic representation. This lead us to define a new similarity measure, which is resilient to permutation and rotation. This is still ongoing work, but we present partial results as an appendix of this document, since we believe it is a significant contribution. In addition to its use in our own context, this measure can have applications in several other fields where we require to evaluate and compare results coming from unsupervised algorithm results, such as the non-negative matrix factorization (NMF), or any other applications where the results can be expressed as a matrix that can be subject to permutations and rotations of its dimensions, which makes the comparison complex.
TABLE DES MATI`ERES
REMERCIEMENTS . . . iii
R´ESUM´E . . . iv
ABSTRACT . . . vi
TABLE DES MATI`ERES . . . viii
LISTE DES TABLEAUX . . . xi
LISTE DES FIGURES . . . xii
LISTE DES ANNEXES . . . xiii
LISTE DES SIGLES ET ABR´EVIATIONS . . . xiv
CHAPITRE 1 INTRODUCTION . . . 1
1.1 D´efinitions et concepts de base . . . 1
1.2 El´´ ements de la probl´ematique . . . 1
1.3 Objectifs de recherche . . . 3
1.4 Plan du m´emoire . . . 3
CHAPITRE 2 REVUE DE LITT´ERATURE . . . 4
2.1 L’analyse de texte . . . 4
2.1.1 Repr´esentation d’un document . . . 5
2.1.2 Etapes pr´´ eliminaires `a la classification de texte . . . 7
2.2 Classification de texte . . . 11
2.2.1 Supervision . . . 12
2.2.2 Le type de r´eponse souhait´ee . . . 12
2.2.3 L’apprentissage purement probabiliste versus l’approche avec informa-tion lexicale . . . 13
2.3 L’approche bay´esienne . . . 15
2.3.1 Principe et int´erˆet de l’apprentissage probabiliste . . . 15
2.3.2 Les diagrammes de plaques . . . 16
2.3.4 Esp´erance-Maximisation (E.M.) . . . 20
2.3.5 Exemple simple : la classification bay´esienne na¨ıve . . . 23
2.4 Cas particulier du LDA . . . 25
2.4.1 Forme du mod`ele . . . 25
2.4.2 Distribution de probabilit´e de Dirichlet . . . 29
2.4.3 Cas d’utilisations du LDA . . . 31
2.4.4 Difficult´e d’apprentissage . . . 32
2.4.5 D´eclinaisons de l’algorithme . . . 34
CHAPITRE 3 M ´ETHODOLOGIE . . . 37
3.1 M´ethodologie . . . 37
3.1.1 Approche g´en´erale . . . 37
3.1.2 G´en´eration du corpus de document synth´etique . . . 38
3.2 Critiques de la m´ethode . . . 39
3.2.1 Avantage de l’approche . . . 39
3.2.2 Inconv´enients de la m´ethode . . . 39
3.3 Importance de la mesure de performance . . . 40
CHAPITRE 4 CHOIX DE LA MESURE POUR L’´EVALUATION DE LA PERFOR-MANCE . . . 42
4.1 Adaptation du LDA au protocole exp´erimental . . . 42
4.2 Etablissement de la mesure de l’erreur `´ a utiliser . . . 43
4.2.1 Liste des m´etriques possibles . . . 43
4.2.2 Comportement des m´etriques . . . 51
CHAPITRE 5 R´ESULTAT DES EXP ´ERIMENTATIONS SUR LE PARAM`ETRE α . 60 5.1 Impact du param`etre α . . . 60
5.2 Initialisation de la matrice β par le bay´esien na¨ıf . . . 64
5.3 Analyse des r´esultats . . . 69
5.4 Compl´ement d’analyse . . . 70
CHAPITRE 6 CONCLUSION . . . 72
6.1 Synth`ese des travaux . . . 72
6.2 Limitations de la solution propos´ee . . . 73
6.3 Am´eliorations futures . . . 73
LISTE DES TABLEAUX
Tableau 4.1 Valeur des param`etres fix´es lors de l’´etude de l’impact du vocabulaire sur le LDA . . . 53 Tableau 4.2 Valeur des param`etres fix´es lors de la comparaison des r´esultats des
m´etriques avec le LDA et sa r´ef´erence . . . 55 Tableau 4.3 Valeur des param`etres fix´es lors de la comparaison entre la similarit´e
de perplexit´e et celle de cat´egorisation . . . 56 Tableau 4.4 Valeur des param`etres fix´es lors de la comparaison entre la similarit´e
de perplexit´e et celle de cat´egorisation . . . 58 Tableau 4.5 Valeurs de α(corpus) explor´ees . . . 58
Tableau 5.1 Diff´erentes valeurs de α explor´ees pour ´etablir son impact sur les per-formances du LDA . . . 60 Tableau 5.2 Evolution de la similarit´´ e de perplexit´e en fonction des α . . . 61 Tableau 5.3 Impact du param`etre α(corpus) sur les performances de la classification
na¨ıve bay´esienne . . . 66 Tableau 5.4 Evolution de la similarit´´ e de perplexit´e du LDA en fonction des α,
apr`es initialisation de la matrice β par la classification bay´esienne na¨ıve 66 Tableau 5.5 Am´elioration relative apport´ee par l’initialisation de la matrice β(app)
du LDA par celle du bay´esien na¨ıf . . . 68 Tableau A.1 Evolution de la cat´´ egorisation du LDA en fonction des α . . . 79 Tableau A.2 Evolution de la cat´´ egorisation du bay´esien na¨ıf en fonction de α(corpus) . 79
Tableau A.3 Evolution de la cat´´ egorisation du LDA initialis´e par le bay´esien na¨ıf en fonction des α . . . 81 Tableau B.1 Evolution de la cat´´ egorisation du LDA en fonction des α . . . 83 Tableau B.2 Evolution de la cat´´ egorisation du bay´esien na¨ıf en fonction de α(corpus) . 83 Tableau B.3 Evolution de la cat´´ egorisation du LDA initialis´e par le bay´esien na¨ıf en
LISTE DES FIGURES
Figure 2.1 Sch´ema explicatif du fonctionnement de la g´en´eration d’un document par le Labeled - LDA . . . 18 Figure 2.2 Proc´edure de g´en´eration d’un document par le Labeled - LDA . . . 19 Figure 2.3 G´en´eration d’un document par le classificateur bay´esien na¨ıf . . . 24 Figure 2.4 G´en´eration d’un document par le Indexation S´emantique Latente
pro-babiliste (pLSI) . . . 27 Figure 2.5 Proc´edure de g´en´eration d’un document par le LDA . . . 28 Figure 2.6 G´en´eration d’un document par le LDA (LDA) . . . 28 Figure 2.7 Cartes thermiques de la distribution de Dirichlet avec diff´erentes valeurs
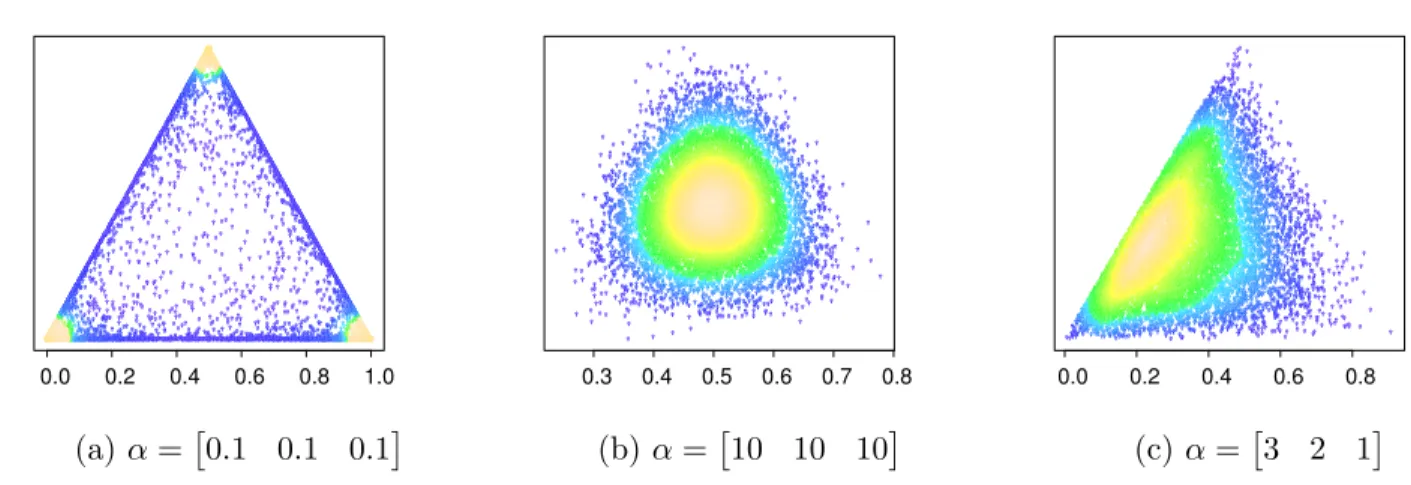
de α . . . 31 Figure 2.8 Mod`ele de l’inf´erence variationnelle pour le LDA . . . 32 Figure 4.1 Illustration du fonctionnement de l’erreur de rappel . . . 47 Figure 4.2 Comparaison de l’erreur quadratique avec la similarit´e de perplexit´e
pour une erreur par rapport `a un vecteur de probabilit´e repr´esent´e par le point noir dans le triangle de probabilit´es. La couleur repr´esente les diff´erentes valeurs prises par les m´etriques dans l’espace de probabilit´es. 52 Figure 4.3 Comportement des m´etriques quand le vocabulaire est ´etendu . . . 54 Figure 4.4 Comparaison des m´etriques vis-`a-vis de la r´ef´erence . . . 55 Figure 4.5 Effet de la variance du nombre de mots par documents suivant la m´
e-trique choisie . . . 56 Figure 4.6 Effet de la similarit´e de perplexit´e en fonction de α(corpus) . . . 59
Figure 5.1 Relation entre l’´ecart type des m et la performance du LDA . . . 62 Figure C.1 Gradation de la sensibilit´e de la m´etrique en fonction du bruit gaussien 99 Figure C.2 Gradation de la sensibilit´e de la m´etrique en fonction du bruit gaussien 100 Figure C.3 Relation entre l’´ecart-type des α et la performance du LDA selon perf(6)
appliqu´e sur la matrice θ . . . 103 Figure C.4 Relation entre l’´ecart-type des α et la performance du LDA selon perf(6)
LISTE DES ANNEXES
Annexe A Impact du param`etre α sur la matrice θ d’apr`es la nouvelle m´etrique . 78 Annexe B Impact du param`etre α sur la matrice β d’apr`es la nouvelle m´etrique . 82 Annexe C Mesure de corr´elation de matrices . . . 86
LISTE DES SIGLES ET ABR´EVIATIONS
LDA Latent Dirichlet Allocation
AUC (de l’anglais Area Under The Curve) : aire sous la courbe d’un graphe de type ROC
ROC (de l’anglais Receiver Operating Characteristic) : mesure de perfor-mance d’un algorithme de recherche d’information, pr´esent´e sous forme d’une courbe.
I.A. (de Intelligence artificielle) : Domaine de l’informatique qui tente de simuler un comportement et raisonnement humain face `a un pro-bl`eme.Russell et al. (2010)
SVD (de l’anglais Singular Value Decomposition) : M´ethode de factorisation de matrice en produit de trois matrices, dont une diagonale et deux sous formes de matrices orthogonales.
expert Nom g´en´eralement donn´e `a une personne (voire un groupe de per-sonnes) qui sont cens´es pouvoir donner le r´esultat qu’un algorithme id´eal devrait donner. Cette m´ethode de v´erification ou de mesure est g´en´eralement utilis´ee l`a o`u l’humain, avec sa connaissance et son dis-cernement, est consid´er´e comme ´etant le meilleur syst`eme intelligent possible.
racinisation R´eduction des mots pour obtenir le radical, et ce de fa¸con algorith-mique.
lemmatisation Mise sous forme canonique des mots. divergence de
Kullback Leibler Mesure de dissimilarit´e entre deux fonctions de densit´e de probabilit´es. α, β et θ Variables de l’algorithme LDA (cf. 2.4.1)
w et (w) Variables d´esignant respectivement un mot et un vecteur de mots v et V Valeurs repr´esentant respectivement un mot du vocabulaire et en
capi-tale la taille du vocabulaire
k et K Variables d´esignant respectivement une th´ematique et en majuscule le nombre total de th´ematiques consid´er´es
N Valeur repr´esentant le nombre de mots d’un texte M Variable d´esignant le nombre de documents d’un corpus
d Nombre r´ef´erant un document
R C’est le mod`ele de repr´esentation interne du corpus de document (que ce soit `a l’´etape de g´en´eration du corpus synth´etique ou `a l’apprentissage par le LDA). Autrement dit, c’est `a dire la matrice P (w|d).
Afin de simplifier les notations, le formalisme suivant a ´et´e adopt´e : — Les variables en gras repr´esentent des vecteurs ou des matrices.
— Certains param`etres varient dans un intervalle d’entiers naturels. La borne sup´erieure de la variable est repr´esent´ee en capitale.
CHAPITRE 1
INTRODUCTION
Avec l’apparition de l’informatique, le monde a vu apparaˆıtre de nouvelles probl´ematiques complexes, dont la science tente de trouver des solutions. Le calcul num´erique est devenu rapide, fiable et facilement accessible. Mais les ordinateurs sont de tr`es bonnes machines pour ex´ecuter des op´erations pr´ed´efinies, mais a contrario d’un ˆetre pourvu d’un cerveau, les outils informatiques ne sont pas capables de r´eflexion et d’analyse par elle-mˆeme. Une des sciences s’est ainsi d´evelopp´ee autour du terme d’Intelligence Artificielle (I.A.) afin de simuler un comportement intelligent face `a des probl`emes donn´es.
Cette tˆache a de nombreuses sous-disciplines, comportant des int´erˆets et applications particuliers pour chacune d’entre elles. L’une d’elle, tr`es connue avec l’´emergence de g´eants du web comme Google et Yahoo ! est le traitement et l’analyse de textes. Ces entreprises tentent de r´epondre au mieux aux besoins d’informations de leurs utilisateurs, cela en leur proposant les pages web correspondant au mieux `a leurs requˆetes. D’autres compagnies en ont fait leur mod`ele : les entreprises de publicit´es en ligne, qui tentent de montrer le contenu qui correspond le mieux `a la situation, bas´e sur le type de page visionn´e et aussi selon l’historique de navigation de l’internaute.
1.1 D´efinitions et concepts de base
Ce pr´esent m´emoire s’appuie sur de nombreux concepts introduits au fur et `a mesure de l’´evolution de l’Intelligence Artificielle, principalement dans le domaine de classification automatis´ee de documents. L’algorithme phare de l’´etude est l’algorithme connu sous le nom de LDA. Cependant, pour comprendre son fonctionnement, il est n´ecessaire de se familiariser avec de nombreux concepts `a la fois math´ematiques et statistiques, qui seront d´efinis au cours de la revue de litt´erature.
1.2 El´´ ements de la probl´ematique
Certaines entreprises sont r´eguli`erement int´eress´ees pour classifier automatiquement des documents selon leurs sujets. Celles-ci op`erent g´en´eralement sur des textes ´ecrits en langues naturelles, c’est `a dire dans un langage pr´evu pour s’adresser `a des ˆetres humains, en respec-tant une structure complexe, mais pr´ecise, faisant appel `a des connaissances externes. Ainsi,
une personne attribue un sens `a des mots et des phrases, suivant le contexte et le raisonne-ment logique. Certains mots n’ont pas de significations propres, mais sont importants pour donner une structure `a la phrase. D’autres ont un sens qui varie selon le contexte et son utilisation. Certains mots n’ont pas qu’une seule forme et des subtilit´es peuvent apparaˆıtre selon leur d´eclinaison. Par exemple, il y a une grande diff´erence de sens entre “J’aime” et “J’aimerais”, mˆeme si les mˆemes mots sont utilis´es. Tout cela rend le probl`eme de classifica-tion de documents tr`es complexe. Et ce sont loin d’ˆetre les seules probl´ematiques rencontr´ees dans le domaine de la classification de texte.
De nombreuses approches existent, suivant les moyens mis en œuvre et selon les situa-tions. Tous les algorithmes de classification de textes ont leurs faiblesses, dont les chercheurs tentent de s’´emanciper au fur et `a mesure de l’avanc´ee de l’´etat de l’art. Cela peut ˆetre des restrictions impos´ees par les choix faits lors de la mod´elisation des documents, ou de d´efis qui n’ont pas encore ´et´e r´esolus. Parmi les contraintes les plus connues, il y a les probl`emes rencontr´es avec les mots qui ont une utilit´e grammaticale sans ˆetre porteurs de sens, comme les d´eterminants. Un ˆetre humain est capable de les isoler et d’interpr´eter leur utilit´e dans la phrase pour affiner le sens donn´e par l’expression, mais ce n’est pas le cas d’un ordinateur, qui se contente d’interpr´eter des instructions pr´ed´efinies. Afin de d´epasser ces limitations, qui sont intrins`eques aux algorithmes de classification, le corpus de texte subit g´en´eralement un traitement pr´eliminaire qui ´elimine ces mots. Cependant, cette ´etape n’apporte pas une v´eritable solution au fond du probl`eme, qui est l’incapacit´e des algorithmes `a g´erer ces mots de faible importance.
Le LDA se base un hyper-param`etre, nomm´e α, qui semble appropri´e pour g´erer la pro-bl´ematique des mots peu importants. Certains chercheurs ont tent´e de d´emontrer son im-portance, en tˆatonnant et en explorant diff´erentes valeurs (McCallum et al., 2009) pour ce vecteur. Ces ´etudes, qui se basent sur des corpus r´eels, font la supposition n´ecessaire de conformit´e des corpus de documents vis-`a-vis du mod`ele suppos´e en interne par le LDA. Cependant, travailler avec des corpus r´eels ne permet pas de connaˆıtre les variables cach´ees et les param`etres latents.
L’hyper-param`etre jouant un rˆole crucial dans l’entraˆınement de l’algorithme, il est n´ eces-saire de s’assurer et de comprendre son impact. Afin d’apporter une rigueur suppl´ementaire `
a l’´etude du rˆole du vecteur α, nous allons mettre en place une m´ethodologie qui permettra d’´evaluer son effet sur les performances du LDA.
1.3 Objectifs de recherche
L’objectif de la recherche est d’estimer la pertinence et l’importance de l’hyper-param`etre α. Cette variable est n´ecessaire `a la g´en´eration des vecteurs repr´esentant la proportion des th´ematiques pour chaque document, selon le mod`ele fix´e par Blei et al.. L’id´ee g´en´erale avanc´ee par l’auteur de l’algorithme est que les documents d’un corpus proviennent d’un α, et suivant celui fourni lors de l’entraˆınement de l’algorithme, les r´esultats pourront ˆetre radicalement diff´erents. Il faudrait ainsi adapter ce param`etre `a chaque corpus de documents et certains papiers ont tent´e d’´etablir la pertinence de ce param`etre.
L’objectif fix´e par ce m´emoire est de fournir une analyse exp´erimentale pour estimer les effets de ce param`etre. Si celui-ci a un impact positif sur la performance de classification, il devient n´ecessaire de conduire une ´etude syst´ematique de cette variable pour l’adapter `a un probl`eme sp´ecifique. Un apprentissage du param`etre α s’av´ererait alors n´ecessaire. Dans le cas contraire, si le α n’a aucune influence, il est possible de consid´erer que ce param`etre n’a d’importance que pour le fonctionnement interne de l’algorithme sans pour autant avoir d’im-pact sur les performances globales. Sous cette hypoth`ese, un simple vecteur fix´e conviendrait `
a toutes les applications et il serait inutile d’allouer des ressources `a l’´etude de ce param`etre pour une utilisation sp´ecifique.
1.4 Plan du m´emoire
Dans un premier temps, les concepts mis en œuvre dans ce domaine sont complexes et n´ecessitent de poser les bases scientifiques n´ecessaires `a la compr´ehension des notions et des enjeux de cette ´etude. Cela permettra ensuite d’´elaborer un protocole exp´erimental et une m´ethodologie appropri´ee `a l’´etude. Ensuite, une analyse compl`ete des diff´erentes m´etriques envisag´ees sera effectu´ee. Enfin, l’application pratique du mode op´eratoire pr´ec´edemment mis en place permet d’obtenir certains r´esultats qui autorisent l’´evaluation de l’importance de l’hyper-param`etre α.
CHAPITRE 2
REVUE DE LITT´ERATURE
Le sujet de ce pr´esent m´emoire est un algorithme particulier d’Intelligence Artificielle, mais pour comprendre le travail effectu´e, il est n´ecessaire de poser les bases de la classification automatique de texte et de balayer les possibilit´es qu’offre cette m´ethode. La d´emarche dans laquelle s’inscrit ce m´emoire n’est plus `a justifier dans le monde des moteurs de recherches, de la gestion bibliographique ou encore de la publicit´e cibl´ee, cependant il est important de connaˆıtre le fondement de celui-ci, `a commencer par la question pr´eliminaire : qu’est-ce que l’Intelligence Artificielle ?
2.1 L’analyse de texte
Le besoin de traitement automatique de documents, rendu possible avec l’informatique, a ´et´e particuli`erement flagrant avec l’´emergence de technologies de l’information, dont la principale de nos jours est le web. Les premiers utilisateurs se sont alors vu offrir une quantit´e astronomique de pages web offrant du contenu int´eressant certaines personnes, mais pas tout le monde et pas en tout temps. Il fallait donc cr´eer des sortes d’index ou de table des mati`eres pour retrouver une page qui correspond au besoin des utilisateurs au moment donn´e. Ce fut l’´emergence des moteurs de recherches, qui ´etaient de simples filtres au tout d´ebut, puis avec l’´evolution des m´ethodes d’Intelligence Artificielle, se sont perfectionn´ees pour r´epondre `a des requˆetes de plus en plus complexes et de plus en plus proches de la langue naturelle.
D’autres applications s’en sont suivis : la reconnaissance de langue suivit des traductions automatiques pour que le contenu renseign´e soit pertinent dans plusieurs langues, l’extrac-tion d’informal’extrac-tion, la classifical’extrac-tion de contenu, l’analyse syntaxique, les correcteurs orthogra-phiques et grammaticaux intelligents, etc. Les domaines d’applications sont devenus tellement vastes et diversifi´es que des m´ethodes sp´ecifiques ont ´et´e d´evelopp´ees et sont en constante am´elioration. Les contraintes changent aussi avec le temps, notamment en terme de puissance de calculs. Bien entendu, ce pr´esent ouvrage ne pr´etend pas couvrir ces sujets, mais il existe des m´ethodes importantes et des probl`emes `a pr´esenter pour comprendre les d´efis auxquels la classification de texte doit faire face.
2.1.1 Repr´esentation d’un document
Dans le cas d’´etude, les documents sont sous forme textuelle, ´eventuellement accompagn´es d’une image ou d’une autre forme de transmission d’informations. Cependant, l’analyse ne porte que sur la succession des mots qui les composent ; le traitement des images, vid´eos et sons est complexe et appartient `a des domaines de recherches diff´erents. En outre, la finalit´e des algorithmes propos´es et ´etudi´es est de travailler sur des textes en langue fran¸caise (ou ´
eventuellement anglaise), ce qui r´eduit le champ de recherche. Cela ne suffit malheureusement pas `a aboutir `a un domaine d’analyse simple.
La complexit´e de la langue
La langue est un moyen de communication, structur´e par des r`egles (de conjugaison, de grammaire, etc.) qu’un groupe de personnes choisit d’adopter pour ´echanger de l’information. Il existe plusieurs langues et chacune a ses sp´ecificit´es qui la rendent unique. En revanche, un certain nombre de ph´enom`enes structurels se retrouvent dans la majorit´e des langues, dont le mot, qui est l’unit´e de base.
En premier lieu, un texte souhaitant faire passer un message peut ˆetre ´ecrit de nombreuses fa¸cons. Il peut y avoir des m´ethodes plus ou moins directes de donner une information, avec des niveaux de langue et des styles d’´ecriture qui diff`erent. Tout cela fait en sorte que deux phrases signifiant la mˆeme chose peuvent n’avoir presque aucun mot en commun. La composition d’un texte peut donc varier drastiquement alors que le contenu est le mˆeme. Les synonymes et paraphrases, qui sont commun´ement utilis´es pour ´eviter les r´ep´etitions, augmentent la diversit´e lexicale d’un texte, ce qui contribue `a la richesse de la langue d’un texte. Ce ph´enom`ene de divergence lexicale s’amplifie quand plusieurs dialectes se confrontent. Mˆeme s’il est av´er´e que la diversit´e lexicale est un ´ecueil du traitement automatique de la langue naturelle, celui-ci est loin d’ˆetre le seul. La polys´emie est un autre danger qui peut avoir des effets plus insidieux. Il est r´ecurrent que des mots aient plusieurs sens pouvant n’avoir aucun rapport th´ematique. Un mot impliqu´e dans une expression n’a g´en´eralement rien `a voir avec le sens d’origine du terme. Cela peut se trouver par un usage dans le cadre d’expressions particuli`eres `a la langue, ou tout simplement de l’´evolution de la signification d’un mot. L’ambigu¨ıt´e de la langue est un ph´enom`ene r´ecurrent qui n´ecessite bien souvent de se r´ef´erer au contexte. Autrement, un risque de quiproquo peut survenir `a l’instar des c´el`ebres pi`eces de Moli`ere.
`
A cela s’ajoute un aspect hi´erarchique dans la langue. Le sens commun permet de donner une liaison d’inclusion entre “automobile”, “roue” et “jante”. Cette information d’holonymie (ou de m´eronymie si l’on consid`ere l’autre sens de l’inclusion) est souvent utilis´ee dans la
litt´erature pour ´eviter des r´ep´etions inutiles de mots. C’est un proc´ed´e tr`es souvent utilis´e pour all´eger le style d’´ecriture. Les hyperonymes, comme “chapeau” pour d´esigner un “haut-de-forme”, permettent aussi d’obtenir ce genre d’artifice. Le sens oppos´e de cette relation s’appelle “hyponymie”.
Cette complexit´e apparente est `a relativiser sur le grand nombre. Il est ´evident que plus il y a de documents dans le corpus traitant d’un mˆeme sujet avec des mots diff´erents, plus il est ais´e de trouver des relations entre les mots, et ainsi de trouver les mots faisant partie de la mˆeme th´ematique. Apr`es cela, il existe d’autres pi`eges dont il faut prendre en compte. L’un d’eux concerne l’impact n´egatif des mots peu porteur de sens, comme “le”, “la”, “a”, dans les m´ethodes actuelles.
La repr´esentation en sac de mots
Quand un ˆetre humain lit un texte, il associe un sens `a chacune des phrases, comprend la logique de celle-ci et est capable d’extraire le message global du paragraphe. Cependant, en l’´etat actuel de l’Intelligence Artificielle, il n’est pas possible d’´emuler le fonctionnement de la compr´ehension. Et cela n´ecessiterait dans tous les cas de pouvoir int´egrer `a l’ordinateur, une notion du sens des mots. Par exemple, quand une personne parle d’une “voiture”, un ˆetre humain comprends que c’est un moyen de transport compos´e de roues, et ayant un moteur, etc. Un ordinateur ne voit qu’une succession de lettre. Or, `a l’´etat actuel de la science, l’´emulation de la compr´ehension humaine n’est pas encore quelque chose d’envisageable. Cela explique que, pour pouvoir analyser un document, il est n´ecessaire de faire un certain nombre d’hypoth`eses simplificatrices.
Selon la d´efinition du dictionnaire de fran¸cais Larousse, un texte est un ensemble des termes, des phrases constituant un ´ecrit, une œuvre ´ecrite. Ainsi, l’´el´ement unitaire ayant une utilit´e s´emantique, est le mot (les morph`emes sont difficiles `a reconnaˆıtre automati-quement) ; une lettre alphab´etique seule ne porte pas de sens tandis qu’un mot en a un. Du fait de la complexit´e d’un document, il est n´ecessaire de faire des simplifications de fonctionnement, dans le but de capturer toute l’information qui peut ˆetre exploitable. En effet, selon la r`egle de la chaˆıne, un statisticien qui voudrait alors calculer la probabi-lit´e d’un texte ne contenant que la phrase “Il fait beau.” devra ˆetre capable de calculer P (“Il f ait beau.00) = P (“Il00)P (“f ait00|“Il00)P (“beau00|“Il00, “f ait00). Il est ´evident que cette
r`egle ne peut ˆetre appliqu´ee sur un document de grande taille.
La r`egle de la chaˆıne, quoique plus pr´ecise en th´eorie, est bien trop sp´ecifique. Il faudrait pour cela ˆetre capable de calculer toutes les probabilit´es conditionnelles, ce qui est impos-sible en pratique. Cela n´ecessiterait aussi de disposer de quantit´e ´enorme de m´emoire pour enregistrer ces probabilit´es. Certaines simplifications sont alors obligatoires. Cela passe dans
un premier temps dans la mani`ere de voir et de repr´esenter un corpus. La repr´esentation en sac de mots est une des simplifications qui est tr`es souvent faite.
Cette hypoth`ese consiste `a consid´erer qu’il est possible de connaˆıtre le sujet du texte uniquement par son vocabulaire. Cela revient `a consid´erer les documents comme un groupe-ment de mots, peu importe l’ordre des mots. C’est ce que l’on appelle le mod`ele de “sac de mots”. Dans le cas ´enonc´e pr´ec´edemment, le mot est l’´el´ement unitaire, ce qui est un mod`ele qualifi´e d’unigramme, mais ce n’est pas toujours le cas. Certains mod`eles fonctionnent mieux en tenant compte de plusieurs mots. `A ce moment-l`a, le vocabulaire du corpus n’est plus vraiment le nombre de mots diff´erents, mais plutˆot le nombre de N-gramme diff´erents.
L’ind´ependance des probabilit´es est aussi une autre conjecture commun´ement faite pour les algorithmes probabilistes, d’autant plus qu’elle rejoint l’id´ee du sac de mots. Il est consid´er´e que la probabilit´e d’obtenir un mot ne d´epend pas de celui qui a ´et´e trouv´e pr´ec´edemment. Toutes ces hypoth`eses reviennent `a s’imaginer que le document est g´en´er´e en tirant au hasard et avec remise, des mots d’un sac.
2.1.2 Etapes pr´´ eliminaires `a la classification de texte
Souvent, pour simplifier le probl`eme d’analyse de texte, un certain nombre de transforma-tions sont appliqu´ees. Celles-ci varient suivant le type de corpus, le mod`ele de document et l’usage pr´evu de celui-ci. Par exemple, dans le cas o`u les documents sont vus comme des sacs de mots, il importe peu de savoir l’ordre des mots. Il est donc possible de faire simplifications et de ne tenir en compte que de l’importance des mots.
Correction orthographique et ´eventuellement grammaticale
Suivant la source du corpus, il peut ˆetre compos´e de textes ´ecrits dans une faible qua-lit´e orthographique et grammaticale. C’est g´en´eralement le cas des textes compos´es par des utilisateurs d’un site web. Il est donc tr`es commun d’avoir recours `a des correcteurs orthogra-phiques pour essayer d’obtenir des documents qui sont plus ou moins corrects, en se basant sur des m´ethodes plus ou moins sophistiqu´ees. Le but de ce m´emoire n’est pas de d´etailler les diff´erentes m´ethodes de correction orthographique, mais il convient de parler de l’algorithme le plus populaire.
Il est souvent consid´er´e que l’utilisateur a eu le droit `a des cours qui expliquent comment ´
ecrire les mots, avec le respect des r`egles de conjugaison et de grammaire. Il resterait donc principalement des fautes de frappe. La m´ethode de correction la plus commune, principale-ment grˆace `a la simplicit´e de sa mise en œuvre, consiste `a comparer les mots selon une liste de mots possibles et correctement orthographi´es. Si le mot appartient `a la liste, il est conserv´e ;
s’il en est absent, il y a une faute et on le remplace par le mot de la liste le plus proche. Cela n´ecessite donc de d´efinir une notion de proximit´e ou de distance, ce qui est fait par la distance de Levenshtein (Soukoreff et MacKenzie, 2001). Cette m´etrique prend en compte les diff´erentes fautes communes qui peuvent ˆetre commises lors de l’appui d’une touche.
Bien entendu, cette ´etape pr´eliminaire n’est pas n´ecessaire si l’on consid`ere que le corpus est ´ecrit dans une belle prose. Il faut aussi consid´erer que cette ´etape doit ˆetre adapt´ee au contexte, c’est-`a-dire selon la langue et aussi selon la m´ethode d’entr´ee des textes. `A l’heure actuelle, quasiment tous les documents sont saisis sur un clavier, ce qui rend la distance de Levenshtein appropri´ee, mais si cela a ´et´e fait par une reconnaissance vocale, une correction par phon´etique peut ˆetre consid´er´ee comme plus adapt´ee.
Le succ`es de cette ´etape peut ˆetre plus ou moins hasardeux. Tout d’abord, la liste peut ˆ
etre incompl`ete, parce que non adapt´ee `a une expertise, ou que le vocabulaire d’usage n’est pas celui qui se trouve dans le dictionnaire. `A cela s’ajoute le probl`eme induit par les noms propres et marques, dans le sens o`u il ne faudrait pas qu’ils soient corrig´es, mais il n’est pas toujours possible de les distinguer des noms communs.
R´eduction du vocabulaire
L’´etape la plus courante est la r´eduction du vocabulaire : celui-ci ´etant le plus probl´ e-matique lors de l’analyse des textes. Plus le vocabulaire du corpus est ´etendu, plus il faut rassembler de documents pour entraˆıner un mod`ele statistique, afin que celui-ci soit capable de faire le rapprochement entre des mots qui n’ont a priori rien `a voir. De plus, il faut s’as-surer que l’algorithme ne sur consid`ere pas des mots qui n’ont pas d’importance. Cela pose des probl`emes d’optimisation en ce qui concerne la vitesse de traitement, mais aussi souvent de pr´ecision : la majorit´e des m´ethodes sont sujettes `a des probl`emes de traitement, comme les “maximums locaux”, qui sont des erreurs d’apprentissage de l’algorithme. Ce d´efi est aussi connu comme la mal´ediction des dimensions (Bishop, 2006, p.34). Or, il y a une partie du vocabulaire qui est souvent consid´er´ee comme peu porteuse de sens. Il peut ˆetre judicieux de les retirer (c’est les cas des mots comme le, la, il, etc. ; ils sont g´en´eralement appel´es mots vides ou encore mots-stops). Comme l’aspect grammatical n’influe pas dans ce genre de mod`ele, cela ´evite de prendre en compte cette sorte de “bruit” qui risque de perturber inuti-lement l’algorithme. Cependant, avoir la n´ecessit´e de recourir `a ce proc´ed´e revient `a avouer que la m´ethode d’analyse de texte n’est pas parfaite et se laisse distraire inutilement par des mots sans importance. Un algorithme fiable, id´ealement recherch´e, n’aurait th´eoriquement pas besoin de ce genre d’´etape.
La ponctuation n’a par ailleurs aucun effet dans les approches courantes d’analyse de corpus, dont le mod`ele des sacs de mots, donc elle est bien souvent retir´ee du corpus ´etudi´e.
Il y va de mˆeme des mots en majuscules : peu d’algorithmes prennent en compte la diff´erence de casse dans les mots. Il est d’usage de mettre tous les mots en minuscule, et ce sans distinctions : un nom propre est souvent diff´erentiable autrement que par la majuscule et savoir qu’un mot est en d´ebut ou milieu de phrase importe peu.
Les autres transformations majeures qui sont sp´ecifiques aux langages et qui permettent de r´eduire le vocabulaire sont la racinisation et la lemmatisation. Elles se basent sur le fait que certains algorithmes, dont principalement ceux bas´es sur le sac de mots, n’accordent pas d’importance `a la conjugaison des mots, s’ils sont au pluriel ou non, etc. Les proc´ed´es bas´es sur les statistiques, comme la m´ethode du bay´esien na¨ıf, en sont des c´el`ebres exemples. Cependant, si un mot, comme conducteurs, apparaˆıt dans un document, il serait consid´er´e comme diff´erent de conducteur. Ce genre de distinction n’est g´en´eralement pas n´ecessaire et cela constituerait une perte d’information : les statistiques des algorithmes probabilistes seraient moins pr´ecises et les performances globales seraient amoindries.
La racinisation est un algorithme, g´en´eralement form´e sous une s´erie de r`egles, qui consiste `
a transformer tous les mots sous leur forme radicale, qui est cens´ee repr´esenter le sens. De cette fa¸con, conducteur, conducteurs, conductrices et conduction pourraient tous ˆetre raccourcis en conduct, ce qui repr´esenterait l’id´ee de transport. Bien sˆur, le r´esultat pr´esent´e ici ne donne pas un autre mot existant dans la langue fran¸caise, comme c’est g´en´eralement le cas avec le proc´ed´e de racinisation. Le mot est alors r´eduit a une sorte d’´etiquette, ce qui g´en´eralement suffisant pour faire des statistiques. Il existe plusieurs versions de ce processus, suivant le but atteindre et la langue du texte. Le plus connu, adapt´e pour la langue anglaise, est appel´e Porter ; les francophones utilisent plutˆot celui nomm´e Carry.
A contrario de la racinisation, la lemmatisation met tous les mots sous leur forme cano-nique, qui est est par exemple l’infinitif pour un verbe, et la forme singuli`ere pour un nom. Mais pour mettre en œuvre un tel m´ecanisme, il faut un logiciel sp´ecifique qui transforme tous les mots suivant une base de donn´ees. Cette op´eration est plus gourmande en temps de calcul, en espace m´emoire, etc. Mais elle `a l’avantage de pouvoir faire la distinction entre un nom, un verbe, un adjectif et un adverbe, ce qui peut avoir son importance dans certains cas. Il est aussi g´en´eralement possible d’avoir ces informations compl´ementaires dans une va-riable suppl´ementaire, tout en faisant moins d’erreurs de confusions entre les mots. Il est ainsi possible de faire la distinction entre un nom commun, un nom propre ou mˆeme parfois une expression. Cette derni`ere op´eration s’appelle l’´etiquetage morphosyntaxique. TreeTagger est un des logiciels phares qui effectue ces op´erations.
La r´eduction de vocabulaire passe aussi par des m´ethodes plus statistiques, comme le Term Frequency-Inverse Document Frequency. Le principe de cette m´ethode consiste `a affecter des poids sur chacun des mots des documents. Il se base sur le constat qu’un mot qui se
trouve dans beaucoup de documents du corpus a probablement peu d’int´erˆet dans celui-ci (c’est la partie IDF de la m´ethode). En effet, il devient peu discriminant pour reconnaˆıtre un corpus par exemple (`a l’instar des mots vides). En revanche, un mot qui est r´ecurrent dans un document, `a forte chance de tenir un rˆole important et est probablement fortement repr´esentatif du contenu du document (c’est le but du facteur TF). La d´efinition commune du Term Frequency-Inverse Document Frequency est la suivante :
tfidfi,j= tfi,j· idfi=
ni,j
P
knk,j
· log |D| |{dj : ti ∈ dj}|
o`u ni,j correspond au nombre d’occurrences du mot ti dans un document, |D| au nombre
total de documents dans le corpus et |{dj : ti ∈ dj}| au nombre de documents o`u le terme ti
apparaˆıt.
Enfin, d’autres proc´ed´es sont utilis´es pour r´eduire le vocabulaire : il s’agit de passer par des banques de synonymes, m´eronymes et ´equivalents pour rassembler des mots de sens voisins. Cependant, elles sont pr´esentes de mani`eres anecdotiques dans la litt´erature scientifique, comparativement aux m´ethodes d´ecrites pr´ec´edemment. Dans la mˆeme optique, il peut ˆetre possible d’essayer de trouver les expressions (Salton et Lesk, 1965) et de les remplacer par des mots ou phrases qui ne risquent pas de faire des donn´ees ambigu¨es dans le texte. Mais rares sont les personnes qui tentent de le faire.
Ce chapitre fait bien sˆur un bref ´etat des m´ethodes les plus communes de la r´eduction de vocabulaire. En effet, c’est un domaine tr`es sensible de la R´ecup´eration d’Information qui a fait l’objet de moult d´eveloppements, suivant le jeu de donn´ees et les informations connexes (s’il est multi-lingues par exemple (Rojas et al., 2007)).
Interpr´etation de symboles et mots n’appartenant pas `a la langue
Aussi, avec l’extension des r´eseaux sociaux, de plus en plus de chercheurs se sont pos´e la question du traitement des ´emoticˆones et des interjections. Ce ne sont pas `a proprement parler des mots, donc des entit´es qui peuvent ˆetre consid´er´ees comme faisant partie du vocabulaire, cependant, cela fait partie d’un remplacement du langage non verbal, qui ne peut pas toujours trouver de substitut et qui peut avoir plus de sens que le reste de la phrase. Ainsi, dans un dialogue, la phrase “Je suis super content :-)” a assur´ement un sens profond´ement diff´erent de “Je suis super content :’-(”; la seconde phrase ´etant vraisemblablement ironique. Les algorithmes qui cherchent `a ´etablir une cˆote de popularit´e d’un candidat politique doivent tenir compte de ce genre de contenu, ce qui explique qu’il est commun de convertir ces caract`eres en des mots repr´esentatifs de l’esprit qui est communiqu´e (Agarwal et al., 2011a), ´
2.2 Classification de texte
La classification de texte est une discipline qui ´etait indispensable dans les biblioth`eques et librairies, o`u il fallait s’assurer que les livres soient faciles `a trouver. `A ce moment, retrouver un document par son titre n’´etait pas ais´e car il supposait que le lecteur sache le titre du livre. Le plus simple ´etait encore d’avoir un classement des documents en cat´egories, pour que ceux qui avaient besoin d’informations sur un sujet sachent o`u chercher.
Ce genre de classification est encore tr`es pr´esente de nos jours : la structure mˆeme d’un certain nombre de sites web conserve une structure logique d’un point de vue th´ematique. L’aspect juridique non reli´e au service propos´e est g´en´eralement regroup´e dans la partie men-tion l´egale par exemple. Cependant, ce carcan est fait manuellement, parce que g´en´eralement peu contraignant `a faire de cette mani`ere et aussi plus sˆur. Apr`es tout, le contenu est fait par des humains, pour d’autres personnes ayant approximativement les mˆemes facult´es et m´ e-canismes de compr´ehension. Cependant, sur certains sites web, cette approche ne peut ˆetre faite par un administrateur. C’est notamment le cas de documents incorporant du contenu utilisateur, comme les forums de discussions, les sites de petites annonces en ligne, etc. La solution la plus commune est d’opter pour une classification faite par l’utilisateur qui poste le message, mais cette classification est g´en´eralement peu fiable et incompl`ete. De plus, per-sonne n’est prˆet `a renseigner b´en´evolement le th`eme du contenu post´e par les utilisateurs pour les compagnies publicitaires, notamment parce que ce serait un travail fastidieux et que personne n’est int´eress´e pour fournir cette information `a des entreprises qui ne jouissent pas n´ecessairement d’une image de marque rayonnante. Cependant, ces derni`eres ont d’un cˆot´e des publicit´es associ´ees `a un th`eme qu’elles doivent associer `a des pages web dont elles ne connaissent pas toujours le type de contenu. Une approche automatique de classification, en conservant celle impos´ee par les fournisseurs des publicit´es, est alors n´ecessaire.
D’un point de vue purement matriciel ou math´ematique, si on consid`ere un document comme un vecteur de mots, le corpus devient alors une matrice de mots par documents. La classification de documents peut alors ˆetre vue comme une factorisation de matrices suivie d’une r´eduction de dimension (la matrice de mots par documents est approxim´ee par la multiplication d’une matrice de th´ematiques par documents et d’une matrice de mots par th´ematiques). Cependant, l’espace des factorisations possibles est excessivement grand et il est pour ainsi dire impossible de conclure quoi que ce soit dans cette repr´esentation. Il faut donc ´etablir un certain nombre d’hypoth`eses r´ealistes et suivre un mod`ele.
La classification de texte est elle-mˆeme une discipline vaste qui se d´ecoupe en plusieurs sous-domaines, et les possibilit´es de solutions peuvent changer radicalement suivant l’ap-proche utilis´ee. `A titre d’illustration, doit-on consid´erer que l’algorithme de classification a
besoin de respecter des cat´egories pr´ed´efinies qui sont connues par l’utilisateur ? Si oui, com-ment les sp´ecifier `a l’algorithme pour qu’il sache faire la liaison et surtout qu’il respecte le motif dessin´e par l’utilisateur ?
2.2.1 Supervision
Suivant le but recherch´e en utilisant un algorithme de classification, les besoins varient, donc les approches aussi. Parmi ces diff´erentes approches, la question de l’utilisation d’un algorithme supervis´e par rapport `a un autre non-supervis´e, fait partie des choix les plus im-portants `a faire. Dans certains cas, l’utilisateur a une id´ee des cat´egories finales et veut les sp´ecifier, pour que l’algorithme de classification sache quelles sont les classes qui doivent ˆetre obtenues. Cette attente peut ˆetre mat´erialis´ee, dans le cas de la classification de documents, `
a une liste de mots-clefs discriminatifs, ou encore une liste de documents types de chaque cat´egories. Ainsi, les algorithmes supervis´es sont g´en´eralement initialis´es par un corpus d’en-traˆınement qui est reli´e `a une classification id´eale. L’algorithme de classification doit alors comprendre le mod`ele qui se cache derri`ere la classification id´eale de l’utilisateur pour ˆetre capable de l’´etendre `a d’autres documents.
L’approche supervis´ee peut, suivant le contexte consid´er´e, ˆetre une grande simplification ou au contraire, susciter plus de probl`emes qu’il n’en r´esout. Suivant les cas, une simple classification par r`egles et mots-clefs peut suffire `a faire une classification des documents. Cela est g´en´eralement suffisant quand l’on veut ˆetre capable de classifier les documents par langues respectives. Pour ´eviter les probl`emes li´es aux mots pouvant appartenir `a plusieurs langues, ou encore les fautes de frappe, et finir par avoir des documents qui peuvent ˆetre ou sont mal classifi´es, les m´ethodes actuelles sont g´en´eralement bas´ees sur un mod`ele bay´esien na¨ıf (cf. section 2.3). La performance atteinte actuellement est telle que le probl`eme est souvent consid´er´e comme r´esolu (Russell et al., 2010, p.911).
Dans les cas les plus complexes de classification supervis´ee, un appel `a un algorithme plus complexe, comme le supervised LDA (sLDA), est n´ecessaire. Le choix de l’algorithme d´epend principalement du mod`ele du corpus et de la forme pr´esuppos´ee des corpus. Dans le cas de la supervision, il convient aussi de savoir si un document doit ˆetre consid´er´e comme ne faisant partie que d’un th`eme ou ˆetre un m´elange de plusieurs d’entre eux.
2.2.2 Le type de r´eponse souhait´ee
Suivant le contexte de l’utilisation d’une m´ethode de classification, un type de r´eponse peut ˆetre plus souhaitable qu’un autre. Dans certains cas, l’utilisateur veut faire des cat´egories distinctes et savoir quel est le th`eme le plus important pour chaque document. Il se peut donc
que l’on souhaite simplement connaˆıtre les mots qui appartiennent `a des cat´egories diff´erentes. Dans d’autres cas, il suffit de savoir dans quelle cat´egorie appartient un document, pour savoir ceux qui traitent un mˆeme th`eme en ne s’int´eressant pas `a la th´ematique par elle-mˆeme. Il convient aussi de savoir si les diff´erents th`emes sont mutuellement exclusifs ou non. Il peut aussi y avoir une sorte de hi´erarchie entre les diff´erents th`emes, ou des ´evolutions de ceux-ci `
a travers le temps. `A cela s’ajoute la possibilit´e d’essayer de trouver des styles de langues, etc.
Prenons le cas o`u les documents sont consid´er´es comme uniquement compos´es de m´elanges de plusieurs th`emes. Dans ce cas, la r´eponse sera alors formul´ee soit sous forme binaire, soit en coefficient de proportion ou encore sous forme de distribution de probabilit´e de r´epartition des th`emes. Le choix de l’algorithme d´epend ´evidemment de la forme de la r´eponse souhait´ee, mais aussi selon le mod`ele des documents. Une explication plus d´etaill´ee se trouve dans le chapitre qui fait ´etat des diff´erents algorithmes 2.4.1.
2.2.3 L’apprentissage purement probabiliste versus l’approche avec information lexicale
Plusieurs approches ont ´et´e envisag´ees et sont pr´esentes dans la litt´erature pour essayer de faire de la classification de texte. La plus utilis´ee `a l’heure actuelle, parce que la plus performante, est l’approche statistique. Elle a en effet l’avantage de ne pas n´ecessiter de corpus ou donn´ees ext´erieures que les documents ´etudi´es, ce qui all`ege consid´erablement le travail et facilite grandement la mise en œuvre. Cela permet en plus d’ˆetre plus flexible sur les cas d’utilisations.
Cependant, l’approche statistique, qui consiste principalement `a compter le nombre d’oc-currences des mots des documents dans le corpus, ne peut faire la relation directe entre un texte parlant de “l’augmentation du prix de l’essence” avec “l’´evolution du cours du p´etrole dans le Moyen-Orient”. Il faut n´ecessairement que le vocabulaire entre ces deux textes se croise ou qu’un autre document du corpus permette de faire le pont entre les id´ees, ce qui n’est pas n´ecessairement le cas. Pourtant, un ˆetre humain parlant le fran¸cais est capable de savoir que l’essence est d´eriv´ee du p´etrole, donc que les textes ont des points communs, du moins plus qu’un autre article parlant de “l’´elevage des escargots”. Certains ont donc eu l’id´ee de rajouter des connaissances ext´erieures pour tenter d’am´eliorer les correspondances entre les mots, et de faire comme une personne le ferait instinctivement avec des associations d’id´ees.
Certaines personnes ont d´evelopp´e des dictionnaires relationnels, qui d´ecrivent les liaisons entre les mots, ou plus pr´ecis´ement entre les groupes de sens (appel´es synsets). Le principal est con¸cu pour la langue de Shakespeare et s’appelle Wordnet et une version traduiteR
en fran¸cais existe : Wolf . Ces deux dictionnaires ne sont malheureusement pas encoreR
termin´es. Malgr´e cela, il est d’ores et d´ej`a possible de relier de nombreux mots communs `
a partir de cette source, que ce soit par antonymie, m´eronymie, adjectif-nom-verbe, etc. Cette information peut ˆetre utile pour grouper des mots d’un sens voisin et ainsi r´eduire le vocabulaire. D’autres articles plus innovateurs tentent de prendre parti de la structure en arbre, pour calculer des distances entre les mots (par exemple avec les distances de Wu et Palmer ou encore de Leacock et Chodorow (Budanitsky et Hirst, 2006)) pour ensuite la transformer en distance entre les textes. Une fois la distance entre les textes trouv´ee, le rˆole du classificateur revient `a grouper les documents les plus similaires, au besoin selon des groupes pr´ed´efinis. Malheureusement, la performance de cette m´ethode n’est pas toujours au rendez-vous et peu de chercheurs s’y int´eressent (Agarwal et al., 2011b).
Une m´ethode autre a ´et´e d´evelopp´ee pour calculer des distances entre les mots ou concepts, mais cette fois-ci en se basant sur des moteurs de recherches (Cilibrasi et Vitanyi, 2007). Ceux-ci ont des bases de donn´ees tr`es larges de textes informatiques et donc contiennent un corpus bien plus satisfaisant pour obtenir des probabilit´es avec une grande pr´ecision. C’est le principe exploit´e dans la distance Google (Vitanyi, 2005) qui se base sur le nombre de documents qui contiennent les mots consid´er´es. L’inconv´enient majeur de cette m´ethode, c’est qu’il est n´ecessaire d’avoir une connexion Internet, et que les r´esultats sont variables dans le temps et selon le moteur de recherche. Il faut aussi prendre en compte que des requˆetes r´ep´et´ees peuvent conduire `a une mise sur liste noire de l’adresse IP de l’ordinateur faisant un usage abusif de cette distance.
La distance Google, par le fait qu’elle se base sur des statistiques faites sur des tr`es grands corpus de documents, peut ˆetre vue comme une sorte de m´ethode probabiliste. Mais elle n’est pas la seule : l’approche bay´esienne est sans conteste la plus utilis´ee de cette grande famille `
a ce jour. La section 2.3 d´edi´ee `a ce sujet d´etaille plus en profondeur ce concept. Et cette grande famille ne s’arrˆete pas l`a. Certains algorithmes, qui travaillent toujours uniquement sur les nombres d’occurrences de mots dans chaque document, adoptent une approche vec-torielle. Le corpus, grˆace `a la simplification des sacs de mots, est repr´esentable sous forme d’une matrice de documents et de termes. Les valeurs `a l’int´erieur de la matrice deviennent alors des nombres d’occurrences, des fr´equences ou des poids (comme ceux calcul´es avec le Term Frequency-Inverse Document Frequency). Ainsi, cette op´eration permet d’effectuer des op´erations matricielles communes, comme la factorisation et r´eduction de matrices par le D´ecomposition en Valeurs Singuli`eres (SVD). Cette op´eration est le fondement de l’algo-rithme Latent Semantic Analysis (LSA) 2.4.1 Il est aussi possible de calculer des corr´elations entre des documents ou entre des mots, avec la similarit´e cosinus (Singhal, 2001). Ce der-nier point permet d’ouvrir les perspectives `a de nombreux algorithmes de partitionnement
de donn´ees, tel que le tr`es c´el`ebre algorithme des K-moyennes ou celui des K-m´edo¨ıdes.
2.3 L’approche bay´esienne
L’approche bay´esienne (souvent qualifi´e de statistique ou de probabiliste) est la famille d’algorithme d’Intelligence Artificielle probabiliste qui est la plus utilis´ee de nos jours, et ce dans un panel tr`es vari´e d’application. Elle se trouve dans le traitement d’image, analyse de texte, prise de d´ecision, etc. Certains chercheurs se sont par ailleurs attel´es `a trouver une explication pour son succ`es (Zhang, 2004). En pratique, de nombreuses raisons ont propuls´e cette th´eorie `a un tel rang de succ`es ; il est actuellement impossible d’envisager parler d’In-telligence Artificielle sans mentionner cette famille. Le paragraphe suivant explique la raison d’ˆetre de cette m´ethode et son origine.
2.3.1 Principe et int´erˆet de l’apprentissage probabiliste
A l’´emergence de l’I.A., les ordinateurs ´etaient tr`es peu accessibles et avaient une tr`es faible puissance de calcul. L’histoire raconte mˆeme que Arthur Samuel, un des piliers fon-dateurs de cette discipline, travaillait la nuit dans les locaux d’IBM pour pouvoir mettre au point son programme qui jouait aux dames. `A ce moment, les diff´erents programmes qui ´
etaient consid´er´es comme pseudo-intelligent ´etaient bas´es sur un syst`eme de r`egles, comme des arbres de d´ecisions, majoritairement cr´e´es `a la main. Mais la discipline ´evolua pour r´epondre `a un besoin d’apprentissage automatis´e. Tr`es rapidement, des m´ethodes sont ap-parues, comme des classificateurs lin´eaires, pour s´eparer les donn´ees et inf´erer des r`egles ou des d´ecisions. L’apprentissage ´etait n´e. Cependant, un probl`eme de bruit et d’incertitude s’est manifest´e, que l’on associe maintenant au sur-apprentissage. Certaines valeurs peuvent ˆ
etre surprenantes, parce qu’il peut y avoir des erreurs de capteurs ou encore que certains param`etres sont inconnus. Il devient alors n´ecessaire de travailler avec une incertitude, et des param`etres cach´es.
La solution choisie pour r´epondre `a ce manque de l’I.A. a ´et´e de travailler avec ce qui repr´esente l’incertitude en math´ematique : le domaine des statistiques et des probabilit´es. Une mod´elisation permet alors de prendre une d´ecision coh´erente, grˆace `a des fonctions de probabilit´es. De plus, cela permet de travailler dans des domaines o`u la r´eponse appropri´ee a une infinit´e de valeurs possibles. Les valeurs cach´ees repr´esentent alors les param`etres de la fonction de r´epartition de la distribution de probabilit´e choisie pour repr´esenter le probl`eme. Le rˆole de l’apprentissage probabiliste revient alors, une fois le mod`ele choisi, `a essayer de maximiser la vraisemblance du mod`ele de probabilit´e.
bas´e sur des fonctions param´etriques, mais ce n’est pas toujours le cas. Dans certaines situa-tions, la fonction de densit´e peut-ˆetre obtenue par des fonctions de noyaux, qui donne des fonctions de densit´e ne correspondant `a aucun mod`ele statistique connu. ´Etant donn´e que les mod`eles bay´esiens utilis´es dans ce m´emoire sont toutes param´etriques, le fonctionnement des fonctions de noyaux ne sera pas expliqu´e plus en d´etail.
Dans le domaine de la classification de texte, l’approche bay´esienne est une des plus communes. Elle se base sur le mod`ele de sac de mots 2.1.1, ce qui permet de faire des statistiques dans chaque document. L’ensemble des mots possibles constitue le vocabulaire. Il est aussi important de noter que l’appellation de mot et vocabulaire est abusive : mˆeme si dans la majeure partie des cas, le mot est l’entit´e de base du document et de la m´ethode, il arrive que l’apprentissage par un mod`ele bay´esien soit effectu´e sur des N-grammes. Le mot de l’approche bay´esienne devient alors plusieurs mots dans le sens linguistique. Cependant, mˆeme si le travail sur des N-grammes peut apporter une am´elioration de la performance de l’algorithme (Kondrak, 2005), il reste moins pratiqu´e que le travail sur des unigrammes. La raison principale de ce choix est souvent la simplification de la mise en œuvre, d’autant plus que la recherche de N-grammes n´ecessite souvent un travail sur des corpus de grandes tailles. Certaines entreprises vendent des dictionnaires de N-grammes pour travailler sur des corpus de tailles inf´erieurs tout en tirant avantage de l’apport de pr´ecision des N-grammes.
Les mod`eles bay´esiens n´ecessitent au moins deux variables : un vecteur ou une matrice qui affectent `a chaque document un th`eme en plus d’une matrice qui contient la probabilit´e de chaque mot du vocabulaire pour chaque th`eme. Celui-ci fait parti de la famille des algorithmes g´en´eratifs, dans le sens o`u un mod`ele parfait est suppos´e ˆetre capable de re-g´en´erer avec une haute probabilit´e les documents qui ont compos´e son jeu apprentissage. Contrairement aux m´ethodes discriminatives, qui se focalisent sur les donn´ees d’entr´ees pour essayer de trouver les variables cach´ees, les m´ethodes g´en´eratives essayent de trouver la valeur de la variable qui permet de mieux g´en´erer le corpus. Le but de la maximisation de la vraisemblance travaille par ailleurs dans ce sens. Si elle a ´et´e r´eussie, les param`etres optimums calcul´es lors de l’apprentissage permettent d’obtenir, pour chaque document, un vecteur de probabilit´e de mot. Il suffit alors de re-g´en´erer le document en respectant ce vecteur de probabilit´e de mot. L’hypoth`ese faite dans cette famille de classificateur est que plus la probabilit´e de g´en´erer un document du corpus est ´elev´ee, plus le mod`ele est appropri´e `a la situation.
2.3.2 Les diagrammes de plaques
La performance d’une approche bay´esienne d´epend grandement du mod`ele sous-jacent, des fonctions probabilistes et des hypoth`eses qui sont faites. Dans certains cas, il est raisonnable d’estimer qu’un document ne contient qu’un seul th`eme, mais sur certains corpus, c’est une
supposition trop radicale. Avec cette hypoth`ese r´eductrice, qui peut ne pas permettre de bien s´eparer le contenu des documents, certains probl`emes peuvent survenir sur des textes qui sont issue de plusieurs th´ematiques, o`u encore ceux qui ne traitent qu’un aspect d’une th´ematique. C’est g´en´eralement le cas des essais philosophiques, qui ne peuvent pr´etendre r´epondre `a toutes les questions d’un th`eme, sans faire des restrictions de sujet, en pr´ecisant la signification de chacun des mots du th`eme abord´e. D’un autre cˆot´e, la d´efinition d’un mot n’est pas vraiment cens´ee aborder une multitude de sujets dans un texte, mais plutˆot essayer de se concentrer sur une signification du mot. Cependant, la polys´emie reste envisageable et est g´en´eralement trait´ee en plusieurs points dans un dictionnaire.
Afin de surpasser toutes ces limitations, des algorithmes bay´esiens se basent sur plusieurs ´
etapes compos´ees de variables cach´ees, qui sont cens´ees raffiner la repr´esentation des do-cuments. Ainsi, suivant le mod`ele choisi, il peut ˆetre possible de choisir de repr´esenter un document comme une multitude de sujets, ou encore de surpasser d’autres probl`emes de repr´esentations. Un choix de distributions statistiques est n´ecessaire pour permettre le m´ e-canisme de g´en´eration des documents selon le sch´ema pr´e-´etabli. Les variables cach´ees sont `
a ce moment-l`a les param`etres des diff´erentes fonctions de probabilit´es.
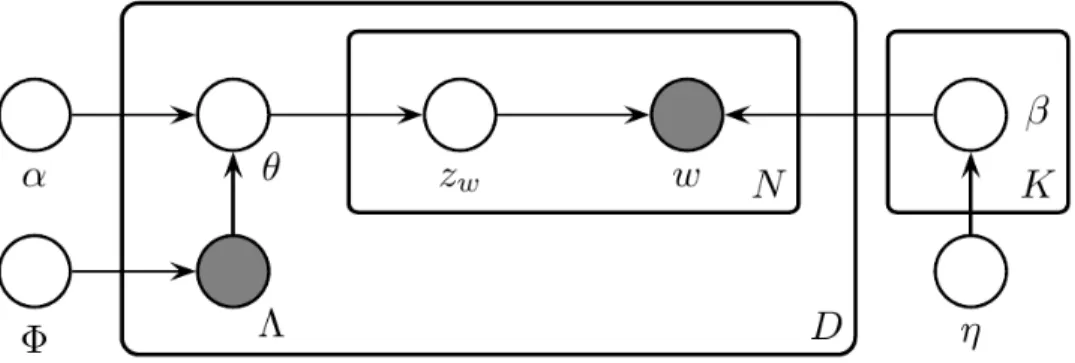
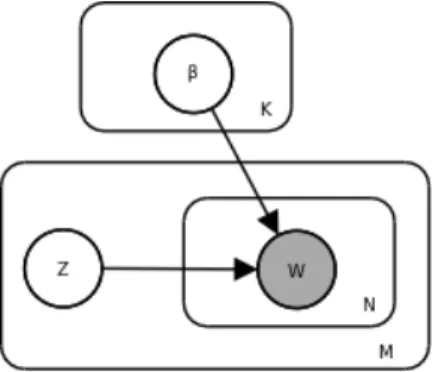
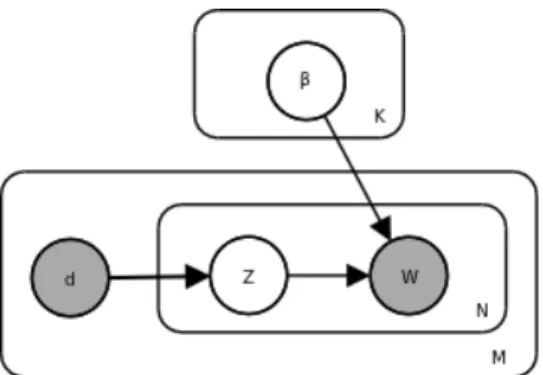
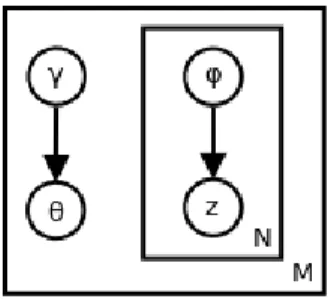
Puisque le mod`ele joue un rˆole significatif, une repr´esentation est apparue et commun´ e-ment admise dans la litt´erature scientifique. Elle est souvent compos´ee de deux parties : un graphique qui donne le mod`ele, et une autre qui donne les ´etapes successives de g´en´eration, avec les fonctions de probabilit´es respectives. `A titre d’illustration, nous allons rapidement mentionner l’algorithme du Labeled - LDA (L-LDA). Ce n’est pas le mod`ele le plus simple, qui est le bay´esien na¨ıf 2.3.5, mais le L-LDA contient un mod`ele qui illustre bien la majorit´e des cas de figures qui peuvent ˆetre rencontr´es. De plus, la complexit´e du sch´ema permet de comprendre pourquoi il est important d’avoir une repr´esentation graphique claire qui ex-plique le mod`ele g´en´eratif visuellement. Son algorithme est d´enot´e par l’auteur lui-mˆeme par le sch´ema 2.1.
Cette repr´esentation graphique est constitu´ee de trois types de symboles, qui sont des cercles, des rectangles et des fl`eches. Chacune de ces formes ont leur utilit´e pour se donner un visuel sur le fonctionnement de l’algorithme consid´er´e.
— Les cercles, qui sont parfois gris´es, repr´esentent des variables du mod`ele. Un label leur est associ´e et repr´esente leur nom qui sera utilis´e dans la description du mod`ele. Ainsi, dans le cas sp´ecifique du Labeled - LDA, les variables sont au nombre de huit, et certaines sont tr`es souvent utilis´ees dans les mod`eles. Ainsi, la variable w repr´esente commun´ement un mot du document, zw la th´ematique associ´ee `a ce mot et β la
probabilit´e d’un mot pour une th´ematique. Une autre information est aussi fournie par l’interm´ediaire des cercles : dans le cas o`u un cercle est gris´e, la variable est