UNIVERSITÉ DU QUÉBEC À RIMOUSKI
ORDONNANCEMENT SOUS INCERTITUDE
MÉMOIRE PRÉSENTÉ
COMME EXIGENCE PARTIELLE DE LA MAÎTRISE EN GESTION DE PROJET
PAR RA V ARY JÉRÔME
UNIVERSITÉ DU QUÉBEC À RIMOUSKI
Service de la bibliothèque
Avertissement
La diffusion de ce mémoire ou de cette thèse se fait dans le respect des droits de son
auteur, qui a signé le formulaire « Autorisation de reproduire et de diffuser un rapport,
un mémoire ou une thèse ». En signant ce formulaire, l’auteur concède à l’Université du
Québec à Rimouski une licence non exclusive d’utilisation et de publication de la totalité
ou d’une partie importante de son travail de recherche pour des fins pédagogiques et non
commerciales. Plus précisément, l’auteur autorise l’Université du Québec à Rimouski à
reproduire, diffuser, prêter, distribuer ou vendre des copies de son travail de recherche à
des fins non commerciales sur quelque support que ce soit, y compris l’Internet. Cette
licence et cette autorisation n’entraînent pas une renonciation de la part de l’auteur à ses
droits moraux ni à ses droits de propriété intellectuelle. Sauf entente contraire, l’auteur
conserve la liberté de diffuser et de commercialiser ou non ce travail dont il possède un
exemplaire.
R.EMERCIEMENTS Il
REMERCIEMENTS
Je tiens à remercier tout paliiculièrement
Monsiem Philippe Dai Santo, Directeur Adjoint du CER ENSAM Angers, sans qui je n'aurais jamais pu partir au Québec pour y suivre mon master.
Monsieur Jean Pasco, Directeur Adjoint du CER ENSAM Châlons-en-Champagne, sans qui également mon séjour au Québec n'aurait pas existé, mais également pour son soutien tout au long du séjour.
Monsieur Daniel Rousse, vice recteur de l'université du Québec à Rimouski et Monsieur Jean Yves Lajoie, professeur à l'UQAR de Lévis, pour m'avoir accueilli au sein de leur université.
Monsieur Bruno Urli, mon Directeur de recherche, pour son aide, ses conseils et sa grande sympathie.
Messieurs Michel Gagnon, Ph.D, professionnel au Centre de recherche Val Cartier et Didier Urli, professeur à l'UQAR, pour leurs remarques et commentaires fOl1 pertinents, et pour avoir accepté d'agir comme membre du comité d'évaluation.
Et finalement ma famille, mes parents, mon frère et ma sœm, pom m'avoir soutenu durant toute la durée de mes études.
TABLE DES MATIÈRES III
TABLE
DES
MATIÈRES
REMERCIEMENTS ... 1I
TABLE DES MATlÈRES ... [11
LISTE DES FIGURES ... V LISTE DES TABLEAUX ... VI RÉSUMÉ ... VI[ INTRODUCTION ... 1
CHAPITRE [ LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS INCERTITUDE ... 4
1.1 La méthode réactive ... 5
1.2 La méthode PERT ... 5
1.3 La méthode stochastique ... 7
lA L'ordonnancement flou ... 9
1.5 La méthode robuste ... 10 1.6 L'analyse de la sensibilité ... Il 1 .7 La méthode de la chaîne critique ... 12 1.8 La méthode GERT ... 12 1.9 Conclusion ... 13 CHAPITRE II MÉTHODE DES INTERVALLES ... 15 2.1 La méthode des intervalles ... 17 2. 1.1 revue de 1 ittérature appliquée à la méthode ... 17 2.2 Traitement du problème ... 20
2.2.1 L'étude des scénarios ... 20
2.2.2 Méthode Monte Carlo ... 24
TABLE DES MATIÈRES IV
2.2.4 Conclusion ... 41
CHAPITRE III COMPARAISON DES MÉTHODES ... 42
3.1 Résultats ... 43 3.1.1 le temps d'exécution ... 43 3.1.2 Précision ... 44 CONCLUSION ... 48 RÉFÉRENCES APPENDICE A LES RÉSEAUX ... 54 APPENDICE B LES CODES SOURCES ... 64
APPENDICE C LES RÉSULTATS ... 83
LISTE DES FIGURES Figure Figure 1.1 Figure 1.2 Figure 1.3 Figure lA Figure 2.1 Figure 2.2 Figure 2.3 Figure 2A Figure 2.5 Figure 2.6 Figure 2.7 Figure 2.8 Figure 2.9 Figure 3.1 Figure 3.2 Figure 3.3 Figure 3A Figure 3.5 Figure 3.6
v
LISTE DES FIGURES
Page Distribution Bêta avec les paramètres a
=
5; b = 20; m = 13 ... 6 Distribution Bêta avec les paramètres a=
5; b = 20; m = 8 ... 6 Distribution Bêta avec les paramètres a=
5; b = 20; m = 17 ... 7 Représentation du nombre flou en six points. (Hapke et al. 1999).9 Algorithme de calcul des scénarios (code Gray) ... 24 Calcul des scénarios pour la méthode Monte carlo ... 26 Cheminement des fourmis ... 27 Algorithme de calcul de la date de début au plus tôt minimale ... 32 Algorithme de calcul de la date de début au plus tôt minimale ... 32 Algorithme de calcul de la date de début au plus tard minimale. 36 Algorithme de calcul de la date de début au plus tard maximale. 37 Algorithme de calcul de la marge minimale ... 40 Algorithme de calcul de la marge maximale (Ant system) ... 41 Temps de calculs en fonction des méthodes et du nombre de tâches... 43 Légende des graphiques ... 44 Pourcentage d'erreur sur le calcul de la date de début au plus tard minimale ... 45 Pourcentage d'erreur sur le calcul de la date de début au plus tard maximale ... 45 Pourcentage d'erreur sur le calcul de la marge minimale ... 46 Pourcentage d'erreur sur le calcul de la marge maximale ... 46
LISTE DES TABLEAUX VI
LISTE DES TABLEAUX
Tableau Tableau 2.1 Tableau 2.2 Tableau 3.1
Page Temps de calcul par la méthode d'étude des scénarios ... 21 Comptage en code Gray ... 23 Les configurations testées ... 42
RÉSUMÉ VI
RÉSUMÉ
Tout projet est soumIs à de l'incertitude et ce, à plusieurs aspects, comme la disponibilité des ressources et la durée certaine des tâches. Jusqu'à ce jour, pom appréhender l'inceliitude, l'attention s'est portée sur l'ordonnancement des projets pour lesquels nous pouvons attribuer une durée probable aux différentes tâches. Mais souvent, le gestionnaire de projet ne peut recomir aux méthodes stochastiques usuelles parce que les données historiques ou la connaissance des temps d'exécution des nouvelles tâches sont manquantes. Ce mémoire propose un modèle d'ordonnancement qui traite de l'inceliitude reliée à la durée des tâches, grâce à une formulation définie à l'aide d'un intervalle de temps borné par une dmée minimale et une durée maximale. Cette nouvelle formulation de l'incertitude conduit à une nouvelle forme de problème. Trois méthodes sont ici proposées afin de calculer ce nouveau problème. Premièrement un calcul brut de tous les scénarios, deuxièmement l'utilisation de la méthode Monte Carlo et finalement l'utilisation d'une métahemistique et plus précisément, il s'agit d'un algorithme d'optimisation de la colonie de foum1is. Ces différentes méthodes conduisent à des résultats différents en termes de précision, de rapidité et de niveau d'information de gestion fournie au gestionnaire de projet. La comparaison de ces différentes méthodes a été effectuée à partir de quatre ensembles de problèmes tests comprenant 25, 60, 90 et 120 tâches, respectivement et provenant de la librairie PSPLI B disponible sur lntemet (l1ttp://1 79.187. J 06.23 J /psplib/).
fNTRODUCTlON
INTRODUCTION
L'ordonnancement de projet vise à organiser temporellement la réal isation des différentes tâches d'un projet, en tenant compte des contraintes au niveau des ressources, en respectant les liens de précédence et finalement en tenant compte du temps requis pour chaque tâche.
Le projet est donc un ensemble de tâches qu'il faudra organiser dans le temps. L'ordonnancement permettra d'optimiser l'organisation du projet pour le rendre plus perfonnant en terme de temps et de coûts et pem1ettra aussi de pouvoir évaluer les ressources nécessaires à l'exécution de ce projet. Dans un deuxième temps l'ordonnancement a pom but d'organiser les activités en lien avec l'extérieur telles que la maintenance, les activités en sous traitance et les approvisionnements avec les différents fournisseurs.
Les tâches sont définies par lem dmée respective, leurs besoins en ressources (humaines, matières premières, matériels ... ) et par lems relations de précédence - c'est à dire les relations temporelles qu'une activité possède avec les activités qui lui sont directement successeurs ou prédécessems.
Malhemeusement, et quelle que soit la nature du projet auquel on a affaire, il y a souvent de l'incertitude. Les somces d'incertitudes sont nombreuses et variées. Les ressomces peuvent venir à manquer, le matériel peut être livré hors délais, et les tâches peuvent prendre plus ou moins de temps que prévu.
Ainsi, lors de la définition de la durée des tâches, le gestionnaire est régulièrement confronté à des éléments d'incertitude car il n'est pas sûr de l'avenir par exemple, ou à des sources d'imperfection de l'information. Conséquemment, les mesmes des durées des tâches ne sont pas précises et on travaille alors avec des estimations. Le gestionnaire de projet devra
INTRODUCTION 2
alors opter pour une modélisation qui permettra de représenter cette incertitude et il y aura toujours un compromis à faire entre compréhensibilité et représentation de la réalité.
L'origine de l'imperfection de l'information peut avoir plusieurs sources et on considère généralement (Bouchon-Meunier, 1995) les 3 sources suivantes:
*
L'incertitude: l'événement s'est-il produit, ou va-t-il se produire?.... L'imprécision: la mesure est réalisée mais on n'est pas sûr de sa validité, ou il n'y a pas de mesure effectuée mais on se base sur une estimation.
"*-
L'incomplétude: il y a des informations qui ne nous sont pas accessibles.Ces différents types d'imperfection peuvent, bien entendu, être combinés et on peut, par exemple, avoir à faire une estimation (imprécision) alors que nous sommes déjà en manque d'information (incomplétude).
Quelque soit le type d'imperfection de l'information auquel le gestionnaire fera face, il faudra utiliser une modélisation qui est réaliste, en ce sens qu'elle devra reposer sur des infomlations dont le gestionnaire pourra raisonnablement disposer.
Il existe différents types de modélisations de l'imperfection de l'information et les principales sont les suivantes:
w- La théorie des probabilités, qui est la méthode la plus ancienne et la plus communément utilisée. Elle est employée lorsque l'on fait face à une incertitude de type aléatoire. Cette méthode nécessite l'utilisation d'une distribution de probabilité et sa difficulté réside dans la définition de la bonne distribution. w- La théorie des ensembles flous. Toutes les imperfections ne sont pas d'origine
aléatoire, la théorie des ensembles flous permet de gérer les incertitudes dues à de l'information incomplète ou imprécise. La logique floue repose sm le concept des ensembles flous. Ici, contrairement à la notion d'ensemble strict, il y a une transition entre deux ensembles, on parle de fonction d'appartenance. Cette
INTRODUCTION 3 modélisation pennet de prendre en compte des descriptions non chiffj-ées et des mesures Imprécises .
..,. La modélisation par intervalles est utilisée dans le cas ou les données sont imprécises mais que l'information est tellement pauvre que l'on ne peut même pas donner de fonction d'appat1enance. On ne peut définir qu'une valeur minimale et une valeur maximale pour le paramètre à estimer, ici la durée de la tâche .
.". La théorie des possibilités. Cette modélisation permet de gérer des informations imprécises sur lesquelles il peut également y avoir de l'incertitude. Il faut bien faire la distinction avec la théorie des probabilités: ici on cherche juste à définir dans quelle mesure un évènement est possible et dans quelle mesure il est certain. Sans disposer pour autant de la distribution de probabilité de l'évènement.
.". La fonction de croyance, qui est une modélisation plus polyvalente que la théorie des possibilités et celle des probabilités. lei on affecte une masse de croyance à des éléments d'un ensemble d'événements possibles.
Il Y a donc plusieurs modélisations possibles, et il importe alors de trouver celle qui correspond le mieux au type d'imperfection auquel on fait face (Ben Amor et Martel, 2004).
L'ensemble de ces modélisations conduit à un ensemble de méthodes adaptées pour résoudre les problèmes d'ordonnancement sous incertitude. Le chapitre suivant sera donc dédié à un exposé de ces différentes méthodes existantes.
CHAPITRE 1
LES
DIFFÉRENTES
APPROCHES
D'ORDONNANCEMENT SOUS INCERTITUDE
4ous pouvons distinguer dans la littérature un certain nombre de méthodes différentes pour gérer l'incertitude dans l'ordonnancement. Elles sont en partie liées aux différentes formes de modélisation de l'imperfection de l'information, également au fait que l'incertitude puisse provenir de différentes sources: de la durée des tâches, de la disponibilité des ressources ou encore du fait qu'une tâche ait besoin d'être exécutée ou non. Les différentes méthodes sont les suivantes (Hen'oelen et Leus, 2005): 'é)o La méthode réactive 'é)o La méthode PERT 'é)o La méthode stochastique 'é)o La méthode utilisant les nombres flous 'é)o La méthode robuste
'é)o L'analyse de la sensibilité 'é)o La méthode de la chaîne critique 'é)o Le GERT
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS lNCERTITUDE 5
1.1
La méthode
réactive
La méthode réactive n'essaye pas de combattre l'incertitude en créant un plan d'ordonnancement capable d'anticiper d'éventuelles incel1itudes, mais revoit et ré optimise l'ordonnancement lors qu'un événement se produit.
Les principaux auteurs sur le sujet sont Sabuncuoglu et Bayiz (2000), Szelke et Kerr (1994) et Vieira et al. (2003).
L'ordonnancement réactif nécessite des règles d'actions pow' "réparer" le plan d'ordonnancement. Un exemple type de ces méthodes est la « right shift rule » (règle de mise au plus tard) (Sadeh et al., 1993; Smith, 1994). Cette règle repousse à plus tard les tâches affectées par l'évènement imprévu. Cette méthode ne peut mener qu'a des résultats médiocres, car elle ne revoit pas l'ordonnancement complet des activités.
Une autre approche consiste en un ré ordonnancement complet des activités. Cette technique fait appel à une heuristique spéciale afin que le nouveau plan d'ordonnancement diffère le moins possible du plan original. Il faut donc introduire une stratégie de perturbation minimale. Une telle technique requiert l'utilisation d'algorithmes exacts ou sub-optimaux utilisant des fonctions minimisant la somme des différences des dates de début des activités entre le plan initial et le nouveau plan. (El Sakkout and Wallace, 2000). Alagoz and Azizoglu(2003), Calhoun et al. (2002) proposent un ré ordonnancement des activités en ayant pour but de minimiser le nombre d'activités changées entre le progranID1e initial et le programme final.
1.2
La méthode PERT
PERT est une abréviation anglaise de « Program Evaluation and Review Technique», ce qui signifie progranune d'évaluation et d'examen de projet. Dans la méthode PERT les durées des tâches sont le plus souvent représentées par des distributions Bêta.
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNA CEMENT SOUS INCERTITUDE 6
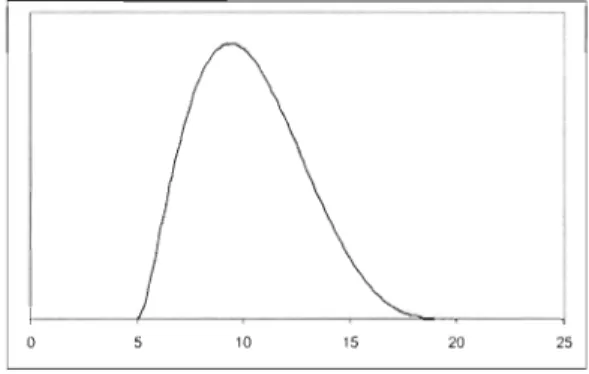
Une distribution Bêta est définie sur un intervalle fini, donc elle possède une bome inférieure et une bome supérieure. Son mode, c'est-à-dire la valeur maximale de sa distribution peut se situer n'importe où dans cet intervalle.
Ainsi on défini la distribution de la durée des tâches grâce à trois estimations: '{)< La durée minimale (a)
'{)< La durée la plus probable Cm) '{)< La durée maximale Cb)
On obtient les représentations suivantes;
10 15 20 25
Figure 1.1 Distribution Bêta avec les paramètres a = 5; b = 20; m = 13.
10 15 20 25
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS INCERTITUDE 7
10 15 20 25
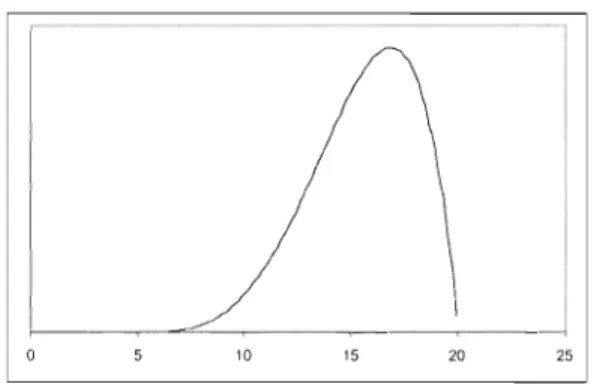
Figure 1.3 Distribution Bêta avec les paramètres a
=
5; b = 20; m = 17. L'analyse de l'ensemble du réseau se fera suivant une loi normale, en effet suivant le théorème central limite, la distribution de la somme de variables indépendantes s'approche de la loi normale à mesure que croit le nombre de variables. Ainsi la durée moyenne du projet sera considérée égale à la somme des durées moyennes des tâches qui composent le chemin critique et la variance égale à la somme des variances de ces mêmes tâches.1.3
La méthode stochastique
L'ordonnancement stochastique permet de planifier les tâches d'un projet avec des durées incertaines, afin de minimiser la durée du projet attendu sans contrainte de ressources renouvelables et avec des relations de précédence.
La méthode consiste en une génération aléatoire de tous les scénarios possibles en fonction des distributions de probabilités des durées des tâches.
Afin de faire le tri dans l'ensemble des scénarios générés, il faut mettre en place des stratégies d'ordonnancement. L'objectif général consiste à créer une politique d'ordonnancement qui minimise la durée attendue du projet. Fernandez (1995), Fernandez et al. (1996, 1998) et Pet-Edwards et al. (1998) ont modélisé le problème d'optimisation correspondant sous la forme d'une programmation stochastique multi étape.
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS [NCERTITUDE 8
Radermacher (1985) a défini les «early start policies » (politique du début au plus tôt). Ce concept minimise les solutions interdites, c'est à dire l'exécution de deux tâches sans relation de précédence simultanément alors qu'elles utilisent les mêmes ressources.
Igelmund and Radermacher (l983a,b), ont introduit les politiques pré-sélectives (PRS). Le principe est que pom chaque solution interdite il faut faire en sorte que l'une des activités commence quand l'autre est terminée.
Mohring et Stork (2000) ont introduit une représentation de présélection appelée «waiting conditions» (conditions d'attente). Ces conditions peuvent être modélisées par des conditions de précédences formulées avec des fonctions booléennes OU et ET.
Il faut savoir que les politiques pré-sélectives sont limitées par la capacité de calcul des ordinateurs.
Ainsi Mohring and Stork (2000) ont défini les politiques de pré-sélections linéaires (LIN). Cette méthode vise à planifier dans un premier temps les ensembles d'ordonnancement qui respectent les conditions de précédence originelles.
Au lieu d'utiliser des politiques d'ordonnancement pour trier les différents scénarios générés aléatoirement, on peut faire appel à des méthodes heuristiques. (Pet-Edwards, 1996; Golenko-Ginzburg and Gonik, 1997; Tsai and Genm1il, 1998). Ces techniques sont encore émergentes.
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEME T SOUS INCERTITUDE 9
1.4
L'ordonnancement flou
Les partisans de l'ordonnancement flou justifient l'util isation du nombre flou par le fai t que les distributions de probabilités des durées des tâches nécessitent un certain historique.
Comme son nom l'indique cette méthode utilise la théorie des sous-ensembles flous utilisée en intelligence artificielle. C'est à dire des fonctions d'appartenance au lieu de fonctions de distribution.
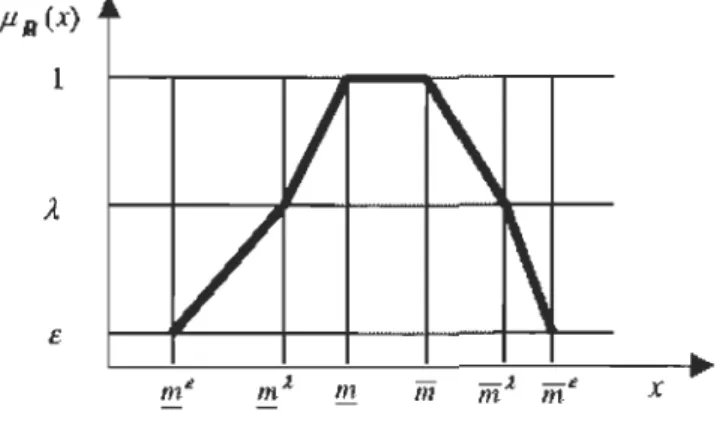
Les durées des activités sont représentées par un nombre flou, ce qui est très complexe à réaliser. Hapke et al., 1999 a défini une méthode pour définir ce nombre flou.
L'expert n'aura qu'à définir trois intervalles de durée:
'!Jo Le premier intervalle pour lequel il est sûr que la durée de l'activité se situera à
l'intérieur. On lui affecte une appartenance de 1.
'!Jo Un deuxième intervalle où il y a de bonne chance que la durée effective de la tâche en fasse pal1ie. On lui affecte le niveau d'appartenance À.
'!Jo Un dernier intervalle pour lequel il y a peu de chance que la durée de la tache en fasse partie. On lui affecte le niveau d'appartenance ë.
f.J1il (x)
1
E
m"
m.t m m -.1, - "m
m
x
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS INCERTITUDE 10
L'étude de l'ordonnancement à l'aide de nombre flou a été initiée par Hapke et al. (1994) et Hapke and Slowinski.( 1996).
Wang (1999) a développé une approche floue pour planifier les projets de développement de production ayant des durées imprécises. Le projet a une date de début floue, une date de fin floue et des durées de tâches floues, toutes décrites par des représentations floues trapézoïdales.
L'objectif est de déterminer le début de chaque tâche, en tenant compte des dates de début et de fin floues, des durées et des relations de précédence.
Il y a une procédure de recherche de réseaux basée sur la génération de groupes d'activités tels que leurs durées satisfassent les conditions de ressources. Ensuite on génère les dates de début au plus tôt en se basant sur la théorie des possibilités.
Wang (2002) a présenté une procédure de recherche de réseaux qui résolvent le problème d'ordonnancement en ayant pour objectif de minimiser les risques.
1.5
La méthode robuste
La méthode robuste consiste en la création d'un ordonnancement robuste c'est-à-dire qu'il est sensé supporter les imprévus, c'est ce qu'on appelle la tolérance aux fautes. Cette tolérance est générée par des redondances, au niveau des ressources, avec des ressources en stand-by (Ghosh, 1996), au niveau du temps en incluant des tâches "réserves" qui donnent du temps en cas de problème. (Ghosh et Al., 1995).
La pure redondance des ressources est plutôt irréaliste dans un environnement projet, car celles-ci feraient doubler les coûts. Une redondance sur le temps semble plus adéquate, mais dans un environnement multi-projet on est loin d'une étude sur un seul projet.
CHAPlTRE l: LES DlFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS LNCERTlTUDE Il
Gao (1995) a développé la méthode de protection temporelle, basée sur la probabilité non nulle de panne des ressources. La durée des activités est égale à la durée originelle des activités augmentée de la durée probable des pannes sensées se produire durant son exécution. Cette technique est basée sur les statistiques propres aux ressources (mean time failure, mean time to repair) (temps moyen d'apparition des défauts, temps moyen de réparation), ce qui rend cette approche difficilement applicable si la plus part des ressources des tâches sont humaines.
Davenport et al. (2001) proposent une méthode d'amélioration de la protection temporelle, grâce à ses techniques: « time windows slack» (fenêtre de temps creux) et « focused time windows slack » (fenêtre de temps creux limitée). Cette technique n'inclut pas le tampon de temps dans la durée de la tâche. Ainsi le tampon de temps n'est pas utilisé pour une tâche mais pour plusieurs, le tampon de temps est placé aux endroits où il y a le plus de risque.
1.
6
L'analyse de la sensibilité
De nombreuses recherches récentes portent sur l'analyse de sensibilité des ordonnancements de machines (Hall et Posner, 2000 a,b). L'analyse de sensibilité cherche à
répondre aux questions du type "qu'est ce qui se passe si ... ? " ou encore:
~ Quelle est la limite si je modifie un paramètre pour que la solution reste optimale? ~ Pour un changement de paramètre donné, quel est le nouveau coût optimal?
~ Pour un changement de paramètres donnés, quelle est la nouvelle solution optimale? ~ Quand est-ce qu'un ordonnancement est optimal?
~ Quand est-ce que la valeur de la fonction objective devient optimale?
~ Quel type d'analyse de sensibilité est adéquat pour évaluer la robustesse d'un ordonnancement?
~ Quel type d'analyse de sensibilité peut être utilisé sans utiliser l'ensemble des détails de la solution?
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS INCERTITUDE 12
Ce type d'ordonnancement vise à établir un ordonnancement qui ne craint pas ou très peu les sources d'incertitude.
1.
7
La méthode de la chaîne critiq ue
La méthode de la chaîne critique a été développée par Goldratt (1997). C'est une approche 'pratique' de gestion des projets. Cette méthode utilise les mêmes hypothèses que les autres méthodes, c'est-à-dire des tâches avec des durées déterministes, des relations de précédence et des besoins en ressources. Dans cette approche, les ressources ont une disponibilité limitée, ce qui pourrait laisser à penser que la durée du projet sera plus longue qu'avec la méthode du chemin critique.
M. Goldratt propose une approche globale de la gestion des projets reposant sur le constat qu'il est plus important de finir un projet dans les temps que de s'attacher à respecter les dates de fin de tâches intermédiaires.
Cette méthode s'appuie sm plusieurs lois telles que celle de Parkinson qui dit que tout temps prévu pour une tâche sera consommé en entier. Il est donc ainsi proposé de minimiser le temps allouer à chaque tâches. Les durées des tâches sont fixées par rapport aux estimations les plus optimistes et des tampons secours sont placés en fin de projet, servant à protéger non pas la tâche mais le projet dans son ensemble car c'est bien la fin effective du projet qui importe. De plus les chemins critiques seront protégés, en disposant adéquatement des tampons de temps sur les branches. Cette méthode relève de ce que l'on appelle la planification proactive et, même si elle est très récente, certains auteurs ont déjà noté certaines simplifications exagérées dans cette méthode (Herroelen et al.,. 2001).
1.8
La méthode GERT
La méthode GERT (Graphical evaluation and review technique) est une technique qui tient compte des possibilités de l'évolution des enchaînements des tâches, c'est-à-dire que le
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNA CEMENT SOUS INCERTITUDE 13
réseau peut évoluer. Cette technique permet de gérer la modélisation de tâches qUl ne se suivent pas, conm1e des activités qui peuvent être bouclées (i.e. industrie pharmaceutique), ou permet l'insertion de ramifications conditionnelles, c'est-à-dire que l'enchaînement des activités peut évoluer. On utilise les probabilités pour traiter les liaisons et pour représenter les durées. Ainsi, il est possible que certaines activités ne soient pas exécutées ou même que d'autres le soient plusieurs fois (boucles). Cette méthode a été décrite en 1966 par Pritsker et Happ.
1. 9
Conclusion
Le nombre de techniques déployées pour gérer l'incertitude est élevé, pourtant on peut se rendre compte que très peu de ces techniques sont employées. Une étude récente (Pollack, Johnson & Liberatore, 2003), montrait que 70% des utilisateurs de logiciel de planification utilisaient la méthode du chemin critique, et seulement 17% utilisent des logiciels de planification permettant des analyses ou des simulations probabilistes, c'est-à-dire acceptant un indéterminisme des dOlmées de base de la planification.
La raison souvent évoquée est que les différentes techniques employées sont trop complexe à mettre en œuvre, ce qui peut dérouter le gestionnaire de projet. De plus les techniques qui utilisent des méthodes probabilistes nécessitent des données statistiques, et il faut donc avoir un certain historique. Les méthodes utilisant les nombres flous ne requièrent pas d'historique, mais nécessitent une certaine connaissance du domaine pour faire les différentes estimations nécessaires. Cette exigence rend difficile leur utilisation pour l'ordonnancement d'un projet innovant pour lequel on ne dispose pas de données statistiques, ni de connaissances accumulées sur d'autres projets pennettant d'estimer la durée des tâches.
Compte tenu de ces remarques, il semble intéressant de considérer une modélisation moins 'riche' de l'information concernant la durée des tâches. La modélisation de l'imperfection de l'information choisie dans notre mémoire est celle de l'intervalle de temps et s'applique par exemple à un projet totalement nouveau ou utilisant des technologies encore inutilisées. Ce type de modélisation de l'incertitude est simple et sera facile à exploiter pour
CHAPITRE 1: LES DIFFÉRENTES APPROCHES D'ORDONNANCEMENT SOUS INCERTITUDE 14
des expelis devant définir les bomes de ces intervalles. Les relations de précédence étant
fixes et les ressources étant connues et disponibles en quantités suffisantes en tout temps,
l'objectif consiste à développer une méthode de planification de projets dont le modèle
d'ordonnancement des tâches est basé sur les intervalles de temps des tâches. Le prochain
chapitre est consacré à la présentation de cette méthode ainsi qu'à une revue de littérature des
15
CHAPITRE
II
MÉTHODE
DES
INTERVALLES
Un projet est un ensemble de tâches qui doivent être réalisées dans le respect d'un certain ordre donné par les relations de précédence. Ces relations définissent quelles tâches doivent être complètement terminées avant que celles qui suivent puissent être à leur tour réalisées, on parlera dans se cas de réalisation séquentielle; des tâches pourront être réalisées en même temps, on parlera dans ce cas de réalisation en parallèle. Cet ensemble de relations série et parallèle peut être représenté par un réseau ou les nœuds représentent les tâches et les arcs reliant les différents nœuds représentent les relations de précédence. Cette représentation s'appelle « Project Evaluation and Review Technique» (PERT). Elle a été crée vers la fin des années 50. Quand il n'y a pas d'incertitude quant à la disponibilité des ressources ni d'incertitude concernant la durée des tâches, il est possible d'appliquer la méthode du chemin critique (Critical Path Method CPM). Le but de cette méthode est donc de trouver le chemin critique du réseau, c'est-à-dire l'ensemble des tâches critiques. Une tâche est critique lorsque tout retard pris sur cette tâche retarde d'autant la fin du projet. La méthode CPM permettra donc d'identifier les tâches critiques, mais aussi de calculer les marges des autres tâches, c'est-à-dire la différence entre la date de début au plus tôt de la tâche et la date de début au plus tard de la tâche. La marge représente le temps en plus disponible pour réaliser la tâche, on peut l'utiliser pour commencer la tâche plus tard ou l'utiliser au cas où la tâche pourrait prendre plus de temps. La méthode CPM se déroule en deux temps: premièrement la phase qu'on appellera ascendante, puis deuxièmement la phase descendante. Lors de la phase ascendante on recherche la date de début au plus tôt pour chaque tâche, celle-ci correspond au maximum des dates de début au plus tôt des prédécesseurs auxquelles on ajoute leur durée.
CHAPITRE Il: MÉTHODE DES INTERVALLES 16
L'opération est effectuée de tâche en tâche dans l'ordre topologique, c'est-à-dire qu'une tâche donnée doit être traitée avant l'un de ses successeurs. Pour pouvoir effectuer ce calcul il faut assigner la date de début au plus tôt de la première tâche à zéro. Puis lors de la phase descendante on calcule la date de début au plus tard, celle-ci correspond au minimum de la date de début au plus tard de l'ensemble des tâches précédentes auxquelles on retire la durée de la tâche en question. Cette opération est effectuée dans l'ordre inverse du tri topologique. Pour pouvoir effectuer ce calcul il faut assigner à la dernière tâche une date de début au plus tard identique à sa date de début au plus tôt. En résumé:
Si di représente la durée de la tâche i, li représente sa date de début au plus tôt et Ti sa date de début au plus tard, on obtient:
t = max
(
t
.
+
d
)
Équation 2.11 jEpred(i) J J
T
= min(r -
d
)
Équation 2.2 1 jesucc:(i) J 1Ainsi la méthode CPM nous permet de définir la date de début au plus tôt, la date de début au plus tard ainsi que la marge de chaque tâche et permet de définir la date de fin au plus tôt du projet.
Malheureusement lorsqu'il y a de l'incertitude sur la durée des tâches, le chemin critique évolue, car en modifiant leur durée, certaines tâches non critiques utilisent toute leur marge devenant ainsi des tâches critiques, ou certaines tâches critiques voyant leur durée diminuer deviennent non critiques. En effet la difficulté de faire de l'ordonnancement sous incertitude est que le chemin critique évolue. Hors les tâches critiques sont les tâches auxquelles il faut apporter le plus d'attention car c'est elles qui peuvent faire prendre du retard au projet. Ainsi la difficulté résidera dans la recherche du chemin critique.
CHAPITRE Il: MÉTHODE DES INTERVALLES 17
2.1
La méthode des intervalles
Dans cette méthode nous avons choisi de traiter de l'imperfection de l'information concernant la durée des tâches. Les ressources seront considérées sans incertitude, c'est-à-dire disponible tout le temps et en quantité voulue, les relations de précédence elles aussi seront
considérées fixes, c'est-à-dire qu'une tâche ne changera pas de prédécesseur(s) ni de successeur(s) au cours de la réalisation du projet.
La modélisation de l'imperfection de l'information choisie pour cette méthode est celle de l'intervalle, modèle utilisé lorsque l'information est incomplète ou imprécise, comme par exemple lors du lancement d'un projet totalement nouveau ou utilisant des technologies encore inutilisées. Ce type de modélisation est simple et sera facile à exploiter pour des experts devant définir les bornes de cet intervalle. Les relations de précédence étant fixes, les ressources étant connues et parfaitement disponibles, il est alors possible la méthode CPM comme mode de représentation du problème. Cependant les durées des tâches étant définies
par des intervalles, le chemin critique évolue et il est donc impossible d'appliquer la méthode CPM de façon classique et celle-ci nécessite alors d'être modifiée.
2.1.1 revue de littérature appliquée à la méthode
Ce sont les auteurs travaillant sur l'ordonnancement flou qui ont été les premiers confrontés à ce problème d'adaptation de la méthode du CPM à des situations où les durées des activités sont modélisées sur des intervalles. En effet, lors de la réalisation de la phase descendante de la méthode CPM en nombres flous, Dubois, Fargier et Galvagnon (2003) furent confrontés à des problèmes pour le calcul de la date de début au plus tard et de la
marge. Le problème vient du fait que lorsque l'on commence la phase descendante on égalise
la date de début au plus tard et la date de début au plus tôt de la dernière tâche. Ils ont donc eu l'idée pour simplifier leur problème de faire les calculs d'abord avec des intervalles plutôt
CHAPITRE Il: MÉTHODE DES fNTERVALLES 18
qu'avec des nombres flous (Chanas, Dubois et Zielifiski, 2002), c'est-à-dire en affectant à chaque tâche une durée minimale et une durée maximale.
La première constatation fut que les différentes valeurs recherchées, c'est-à-dire la date de début au plus tôt, la date de début au plus tard et la marge, pour une tâche donnée, se trouvent dans les configurations extrêmes. Ainsi pour atteindre les valeurs extrêmes des intervalles des différentes valeurs cherchées il faudra assigner aux différentes tâches du réseau: soit leur durée maximale, soit leur durée minimale, ce qui donne un nombre de configuration possible à 2"ombre de lâches, c'est-à-dire que le problème est «NP-hard ». Le calcul
de la date de début au plus tôt a l'aide d'intervalles ne pose pas de problèmes particuliers et ce calcul est de complexité linéaire. Il suffit d'assigner la durée minimale à toutes les tâches précèdent une tâche donnée pour obtenir sa date de début au plus tôt minimale, et inversement les durées maximales pour obtenir la date de début au plus tard maximale. Par contre, calculer les marges des tâches et définir leur criticité est chose bien moins facile, et calculer la marge demeure un problème NP-dur (Chanas et Zelinski, 2003). Récemment des algorithmes polynomiaux capable de trouver des dates de début au plus tôt ont été mis au point (Zelinski, 2005). Ce n'est que récemment qu'un groupe d'auteurs (Chanas, Dubois et Zielifiski, 2002) ont développé des configurations, c'est-à-dire l'affectation des durées des différentes tâches du réseau, pemlettant de trouver les bornes des intervalles des marges. Les configurations définissant les différentes valeurs pour une tâche donnée sont les suivantes:
.". Pour le calcul de la date de début au plus tôt minimale:
a Assigner la durée de l'ensemble des tâches à leurs valeurs minimales .". Pour le calcul de la date de début au plus tôt maximale:
a Assigner la durée de l'ensemble des tâches à leurs valeurs maximales . .". Pour le calcul de la date de début au plus tard minimale:
a Assigner la durée de toutes tâches à leur durée minimale sauf sur un chemin allant de la tâche étudiée jusqu'à la fin du réseau où là la durée assignée sera maximale.
CHAPITRE Il: MÉTHODE DES INTERVALLES 19
'1>- Pour le calcul de la date de début au plus tard maximale:
o Assigner la durée des tâches à leurs valeurs minimales sauf sur un chemin allant du début du réseau jusqu'à la fin.
9- Calcul de la marge minimale:
o Assigner la durée de toutes les tâches à leurs valeurs minimales sauf sur un chemin allant du début à la fin du réseau et passant par la tâche étudiée.
9- Calcul de la marge maximale
o Assigner la durée des tâches à leurs valeurs minimales sauf sur un chemin allant du début à la fin du réseau.
L'ensemble de ces résultats permet donc de calculer les différents intervalles des valeurs recherchées avec des algorithmes polynomiaux. En effet, il suffit maintenant d'énumérer les différents chemins possibles afin de trouver les bornes des différentes valeurs cherchées.
Les calculs sont donc possibles quelque soit la taille du réseau. Néanmoins les infoll11ations que l'on tire de ces calculs ne sont pas forcément très significatives pour un gestionnaire de projet. En effet les informations fournies par ces calculs ne sont que des intervalles. Ensuite, au niveau de la criticité des tâches, il n'y a que peu d'infoIl11ation: soit elle seront toujours critiques, c'est-à-dire marge minimale égale à la marge maximale égale à zéro, soit elles ne sont jamais critiques, c'est-à-dire marge minimale différente de zéro et finalement possiblement critique, c'est-à-dire parfois critique parfois non suivant les configurations. Le problème principal reste toujours le même: définir la criticité des tâches exactement comme dans une méthode CPM "classique". La notion de criticité est indispensable au gestionnaire de projet pour savoir où porter le plus d'attention et savoir où se trouvent les dangers en cas de prise de retard. Il faut donc essayer de traiter le problème différemment afin d'essayer de fournir un peu plus d'information au gestionnaire de projet.
CHAPITRE Il: MÉTHODE DES INTERVALLES 20
2.2
Traitement du problème
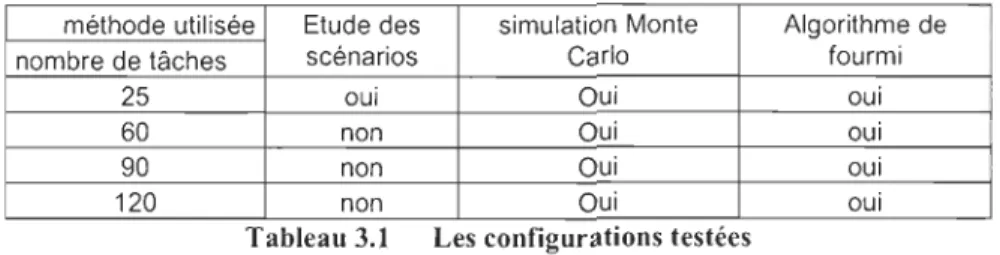
Pour traiter ce problème, nous avons vu qu'il fallait travailler avec des configurations de durées, c'est-à-dire qu'il faut affecter aux tâches une durée avant d'utiliser la méthode CPM. Ensuite nous avons vu qu'il fallait travailler avec les valeurs extrêmes des intervalles si nous voulions trouver les bornes des valeurs recherchées et finalement qu'il existe des configurations pour lesquelles on est sûr d'obtenir les valeurs cherchées. Nous allons donc utiliser ces différentes constatations dans les trois approches avec lesquelles nous allons traiter le problème, les trois approches choisies sont:
'1>- Une étude des scénarios, c'est-à-dire l'étude de toutes les configurations possibles du problème.
'!>- Une mise en place de la méthode Monte-Carlo appliquée au problème.
'1>- Une mise en place d'un algorithme de fourmis pour le calcul du réseau en utilisant les configurations décrites ci-dessus.
2.2.1 L'étude des scénarios
L'étude de tous les scénarios ne sera pas "gratuite", en effet le nombre de scénarios croît rapidement avec le nombre de tâches du réseau. Cependant le but de l'étude des scénarios a son importance; il s'agit de retirer le maximum d'information possible afin de guider au mieux le gestionnaire de projet. Les informations que nous souhaitons obtenir de cette méthode sont:
'1>- Les bornes de l'intervalle de la date de début au plus tôt de chaque tâche
'!>- Les bornes des intervalles des dates de début au plus tard de chaque tâche
CHAPITRE Il: MÉTHODE DES INTERVALLES 21
<!Jo La criticité relative des différentes tâches
<!Jo La répartition des différentes durées possibles du projet.
Ainsi grâce à ces différentes informations le gestionnaire de projet aura plus de facilité à identifier les tâches auxquelles il doit porter plus d'attention ( criticité des tâches), puis saura détenniner avec plus de facilité la durée probable du projet grâce à la répartition des
durées possibles du projet.
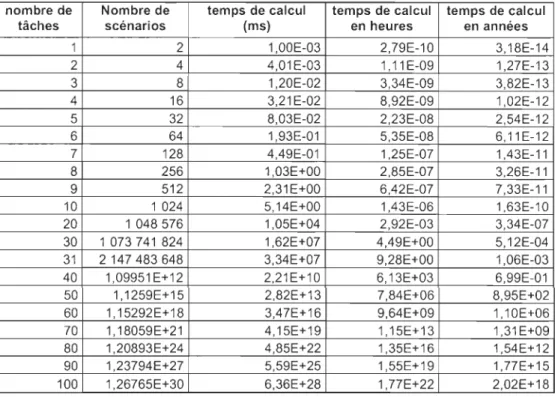
Dans cette approche par scénarios, on s'aperçoit rapidement que le calcul des scénarios atteindra vite ses limites car le nombre de scénarios est égal à 2"ombre de tàchcs ce qui conduit vite à des nombres qui ne sont même pas manipulables par des ordinateurs. En effet, même les ordinateurs sont rapidement dépassés par le nombre de scénarios possibles alors que les
temps de calculs croissent exponentiellement (tableau 2.1).
Tableau 2.1 Temps de calcul par la méthode d'étude des scénarios
nombre de Nombre de temps de calcul temps de calcul temps de calcul
tâches scénarios (ms) en heures en années
1 2 1,00E-03 2,79E-10 3,18E-14
2 4 4,01 E-03 1,11E-09 1,27E-13
3 8 1,20E-02 3,34E-09 3,82E-13
4 16 3,21 E-02 8,92E-09 1,02E-12
5 32 8,03E-02 2,23E-08 2,54E-12
6 64 1,93E-01 5,35E-08 6,11E-12
7 128 4,49E-01 1,25E-07 1,43E-11
8 256 1,03E+00 2,85E-07 3,26E-11
9 512 2,31E+00 6,42E-07 7,33E-11
10 1 024 5,14E+00 1,43E-06 1,63E-10
20 1 048576 1,05E+04 2,92E-03 3,34E-07
30 1073741824 1,62E+07 4,49E+00 5,12E-04
31 2147483648 3,34E+07 9,28E+00 1,06E-03
40 1,09951E+12 2,21 E+10 6,13E+03 6,99E-01
50 1,1259E+15 2,82E+13 7,84E+06 8,95E+02
60 1,15292E+18 3,47E+16 9,64E+09 1,10E+06
70 1,18059E+21 4,15E+19 1,15E+13 1,31 E+09
80 1,20893E+24 4,85E+22 1,35E+16 1,54E+12
90 1,23794E+27 5,59E+25 1,55E+19 1,77E+15
CHAPITRE Il: MÉTHODE DES INTERVALLES 22
En effet, dès 31 tâches on arrive déjà à plus de 9h de calcul, ce qui limite beaucoup les calculs envisageables, de plus le nombre de scénarios atteint la limite de capacité des ordinateurs. Un ordinateur peut compter avec des entiers sur quatre octets soit 32 bits ce qui correspond à un nombre allant de - 2 147 483 647 à 2 147 483 647. Pour notre étude nous nous limiterons donc à l'étude de réseau n'excédant pas 25 tâches.
Le nombre de scénarios est égal à 2"ombre de tâches. En effet il y a deux durées possibles
par tâches, et on peut alors représenter les différentes configurations par un nombre binaire d'une longueur égale au nombre de tâches. Le zéro représentera le choix de la durée minimale et le 1 représentera le choix de la durée maximale. Ainsi en déroulant la numérotation binaire de zéro jusqu'à 2"ombre de tâches on est sûr d'avoir énuméré l'ensemble de tous les scénarios.
L'utilisation de la numérotation binaire semble intéressante pour ne pas oublier de configurations mais pouvoir compter sur un nombre binaire de 30 bits (projet de 30 tâches) n'est pas simple car les modifications de configuration ne sont pas optimales. En effet à chaque fois que l'on passe un nouveau bit, c'est-à-dire lorsque l'on arrive à dénombrer une configuration égale à une puissance de deux, il faut changer toutes les durées des bits inférieurs.
Configuration n° 127: 000 ... 0 1111111
Configuration n° 128: 000 ... 10000000
'-y-l
Les bits de niveau inférieur changent
Ces changements consomment beaucoup de temps, ainsi pour gagner du temps et pour faciliter le comptage, il faut utiliser un système de comptage différent. L'utilisation du
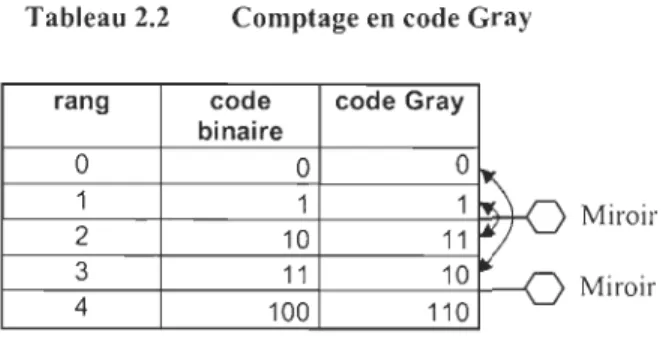
comptage binaire en code Gray semble présenter les avantages recherchés. En effet, lors du comptage en code Gray, il n'y a qu'un seul bit qui change à chaque fois, cette numérotation
CHAPITRE Il: MÉTHODE DES INTERVALLES 23
utilise l'effet miroir. À chaque fois que l'on alTive à un nombre égal à une puissance de deux,
on recopie les nombres précédents précédés d'un 1. (http://fr.wikipedia.org/wiki/Code_Gray) Tableau 2.2 Comptage en code Gray
rang code code Gray binaire 0 0 O ~ 1 1 1
~
\
2 10 11"'/
3 11 10 ~ 4 100 110 Miroir MiroirLe comptage en binaire est donc simple, du moins à la main, mais il va falloir qu'un ordinateur génère lui-même ce code binaire. Il faudra donc utiliser l'algorithme de génération du code Gray. L'algorithme est le suivant:
On passe d'un nombre au suivant en changeant un seul bit:
'1>- Le demier si le nombre de "1" est pair
.". Celui à gauche du "1" le plus à droite sinon
Puis lorsqu'on arrive à une puissance de deux, on change le premier bit.
Nous avons maintenant les capacités de générer les différentes configurations. Il faudra exécuter la méthode CPM pour chaque configuration testée. Les bomes des différentes valeurs seront réévaluées à chaque exécution de la méthode CPM afin de trouver les valeurs extrêmes. À chaque exécution de la méthode nous vérifieront la marge de chaque tâche puis les tâches ayant une marge nulle seront comptées conm1e critiques. À la fin du calcul nous calculerons le pourcentage de fois où chaque tâche s'est retrouvée critique par rapport au nombre total de configurations. En même temps la durée totale du projet sera notée afin de
CHAPITRE Il: MÉTHODE DES rNTERVALLES
L'algorithme utilisé par le logiciel peut s'écrire ainsi:
Algorithme de calcul des scénarios
Mettre en configuration de base (durée minimale pour toutes les tâches)
Cpm (exécution de la méthode cpm) Enregistrer résultats
Compter les tâches critiques Enregistrer la durée du projet Rang_configuration 1
Répéter
Incrémenter en code Gray rang_configuration
24
Changer la durée à changer (en codage Gray une seule durée change) Cpm (exécution de la méthode cpm)
si résultats meilleurs: enregistrer résultats Compter les tâches critiques
Enregistrer la durée du projet
Jusqu'à rang conf iguration = 2nombre de tâches Fin
Figure 2.1 Algorithme de calcul des scénarios (code Gray)
2.2.2 Méthode Monte Carlo
La méthode de Monte Carlo est une méthode qui tire son nom des jeux de hasard
pratiqués à Monte Carlo. En effet, la méthode Monte Carlo est une méthode de simulation probabiliste. Lors des simulations, les différents scénarios sont générés de façon aléatoire en
respectant les distributions de probabilité des différents éléments foumis. Cette méthode est répandue dans de nombreuses applications et pas seulement l'ordonnancement. Néanmoins parmi les méthodes d'ordonnancement sous incertitude, la méthode Monte Carlo est de loin la plus utilisée.
En ordonnancement sous incel1itude avec la méthode Monte Carlo, différents scénarios sont générés de façon aléatoire. Pour cela il faut définir la fonction de distribution des
CHAPITRE Il: MÉTHODE DES INTERVALLES 25 éléments d'incertitude, tous les éléments incertains se verront affecter une fonction de distribution. Les distributions possibles sont très variées (triangle, discrète, normale, .... ). Ensuite un tirage aléatoire est fait dans l'intervalle d'incertitude des différentes variables incertaines (coût, dmée, ressomces, ... ), le tirage aléatoire respecte la fonction de distribution des variables. À l'issue d'un certain nombre d'itérations, il est possible de faire une étude statistique sm les différents résultats que l'on souhaite connaître lors de la simulation: coûts, dmée, date de début au plus tôt, date de début au plus tard, etc. Il est ainsi possible de tracer leurs courbes statistiques respectives. Il faut bien noter que pour deux simulations différentes sur un même problème on obtient deux résultats différents.
Ici la simulation Monte Carlo sera plus simple, les ressources seront considérées parfaitement connues et disponibles, il n'y aura que sur les durées que qu'il y ama de
l'incertitude. Les durées étant modélisées par un intervalle les fonctions de distribution associées seront discrètes et de deux points d'égale probabilité de 50 % chacun.
La simulation se déroulera ainsi:
1) Choix pour chaque tâche de façon aléatoire soit de la durée maximale soit de la dmée minimale, ce choix sera réalisé de façon équiprobable.
2) Calcul du chemin critique et enregistrement des résultats. 3) Répétition des phases 1 et 2 jusqu'au nombre d'itérations désiré.
CHAPITRE Il: MÉTHODE DES INTERVALLES L'algorithme peut se traduire ainsi:
Algorithme de Monte Carlo
Pour i
=
1 à nombre d'itération Pour chaque tâche t de 1 à nChoisir de façon équiprobable la durée de la tâche
(minimale/maximale)
Fin pour
Cpm (exécution de la méthode cpm)
Si résultats meilleurs: enregistrer résultats
Compter les tâches critiques
Enregistrer la durée du projet
Fin pour Fin
Figure 2.2 Calcul des scénarios pour la méthode Monte carlo.
2.2.3
Algorithme de fourmi26
Cette méthode (Colomi et al. 1994) s'inspire du comportement des colonies de fourmis quand elles vont chercher de la nourriture. Elles sont capables de trouver le plus court chemin entre leur nid et la nourriture. Utilisé pour de nombreuses applications telles que le routage de réseau informatique, cet algorithme pOUlTa être utilisé pour trouver le chemin le plus court de la première à la demière tâche dans notre problème d'ordonnancement.
2.2.3.1
Fonctionnement PrincipeCHAPITRE Il: MÉTHODE DES INTERVALLES 27
On se sert ici de la façon dont les fourmis opèrent pour trouver le chemin le plus court entre leur nid et l'endroit où elles vont chercher leur nourriture .
..
(2)0---.-:
oL
.
·-.···-·~·_··~~f:
~~:~
9
.,
(l)Q--,*~.'\;
I
~.~.-~
~
~
~.~
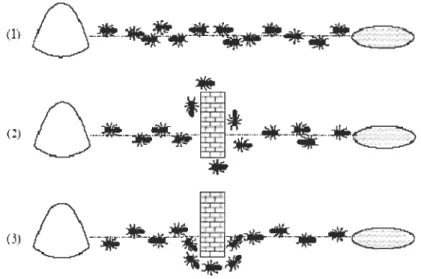
Figure 2.3 Cheminement des fourmis
Schéma 1 On aperçoit que la colonie de fOUJ111is va directement de son nid au tas de nourriture en ligne droite.
Schéma 2 On vient juste de placer un obstacle sur leur chemin, les fourmis vont donc
devoir trouver le nouveau chemin le plus court.
Schéma 3 Les founnis ont fini de trouver le chemin plus court.
Quand elles se déplacent de leur nid vers la nourriture, les fOUJ111is déposent des
phéromones qu'elles sont capables de sentir par la suite. Lorsque l'on dépose un obstacle sur
leur chemin les fourmis ont le choix de passer soit à gauche soit à droite. On suppose ici qu'il y a autant de chance pour qu'elles choisissent la gauche que la droite, du moins au départ car il n'y a pas de phéromones. Par la suite les fourmis qui seront passées par le chemin le plus
CHAPITRE Il: MÉTHODE DES INTERVALLES
28
court auront déposées plus de phéromones que les fourmis qui sont passées par le chemin le plus long car elles auront effectué plus de fois le trajet en un même temps, donc au moment de choisir par quel chemin passer (gauche, droite), les fourmis choisiront le chemin qui sent le plus les phéromones, le chemin le plus court. Par analogie, dans notre problème, La nourriture sera remplacée par l'ensemble de toutes les solutions du problème. Le but qui consiste à améliorer la quantité ou la qualité de la nourriture rapportée sera la fonction àoptimiser. Les phéromones seront remplacées par une mémoire adaptative.
Application au voyageur de commerce
Le problème du voyageur de commerce est un problème général dans lequel un voyageur doit visiter un ensemble de villes sans en oublier une seule et en passant une seule et unique fois dans chacune d'elles. La difficulté du problème est de définir l'ordre dans lequel le voyageur doit parcourir les villes afin de minimiser la distance parcourue. Initialement utilisé pour résoudre le problème du voyageur de commerce, nous allons voir comment l'algorithme a été implanté. L'analogie est facile à voir ici, comme les fourmis, le voyageur doit effectuer le chemin le plus court. L'algorithme illustré ici est l'algorithme de base « Ant System » (Colorni et al., 1992).
L'algorithme est opéré pour t itérations (t de 1 à tmax (nombre maximal d'itérations)). À chaque itération les fourmis parcourent le graphe des villes à leur manière. Le parcours de chaque founni ce construit ainsi:
l) la fourmi choisit une ville de départ au hasard
2) la fourmi choisit au hasard la ville suivante en fonction de:
a. la liste des villes non visitées, fourmi k sur ville i: J;k
b. l'inverse de la distance par rapport à la ville choisie, cette quantité est appelée la visibilité, cette grandeur sert à ce qu'une fourmi ne choisisse
1 pas une ville trop éloignée. Visibilité:
77
ij
=d.
CHAPITRE Il: MÉTHODE DES rNTERVALLES
29
c. la quantité de phéromones, paramètre qui évolue au passage des foul1l1is. intensité de la piste: ry(t)
La probabilité que la fourmi choisisse la ville est définie ainsi:
.. ·k
SI
JE Ji
.. ·kSIJrl.
J
i
I(
Til(t
))a.
(17
ij
)fJ
tEl
o
Équation 2.30. et (J sont deux paramètres fixant l'importance relative de la visibilité et de l'intensité de la piste.
3) L'étape deux est réitérée jusqu'à atteindre la première ville visitée.
4) On dépose une quantité de phéromones sur l'ensemble des pistes t, r~
(t)
,
cette quantité est fonction de la qualité de la solution trouvée par la fourmi:si(i,j)E Tk(t) si(i,j)tl. Tk(t)
Équation 2.4
Q
est un paramètre fixé,L
k(t )
représente la longueur du tour effectué par la fourmi k à l'itération l,T
k(t)
représente le chemin suivi par la fourmik
pendant sont itération t. (notons que cette quantité de phéromones est enregistrée, elle sera déposée une fois que toutes les fourmis de l'itération seront passées).5) Étape appelée évaporation des pistes, on décrémente la dose de phéromone des pistes, puis on ajoute les quantités de phéromones enregistrée. L'évaporation s'effectue suivant la fOl1lmle ci-dessous:
CHAPITRE Il: MÉTHODE DES fNTERVALLES 30
Équation 2.5
TiJt)
Représente la quantité de phéromone sur la liaison de la ville i à la ville) à l'itérationt, rhô est le paramètre d'évaporation, ,1T
iJ
t)
représente les quantités de phéromones entre la ville i et) accumulées au cours de l'itération t. L'algorithme AS appliqué au problème du voyageur de commerce peut se représenter ainsi:(source: Métaheuristiques pour l'optimisation difficile, Dréo, Pétrowski, Siarry et Taillard, 2003)
Algorithme de colonie de fourmis de base: le "Ant System".
Pour t = 1, ... , tmax
Pour (chaque fourmi k = 1, ... , m Choisir une ville au hasard Pour chaque ville non visité i
Jk
Choisir une ville j, dans la liste i des villes restantes,
selon la formule 2.3 Fin Pour
Déposer une piste ,1T~(t) sur le trajet
T
k
(t)
conformément à l'équation 2.4Fin Pour
Évaporer les pistes selon l'équation 2.5 Fin Pour
Ajustement des paramètres
Les paramètres à ajuster sont:
.". Q, pour le dosage des phéromones: il est conseiller de prendre une valeur proche du meilleur chemin possible, il faut donc faire une estimation.
CHAPITRE Il: MÉTHODE DES INTERVALLES 31
'1>- Le nombre de fourmi: pour mieux exploiter les capacités de cet algorithme, il
est conseillé de prendre un nombre de fOUimi égale au nombre de ville à
parcourir, l'algorithme n'est pas sensible au réglage fin du nombre de fourmi.
'1>- Les paramètres a et
fJ
sont à ajuster en fonction du problème, il faudra décidersi l'on favorise la visibilité ou l'intensité. 2.2.3.1 Adaptation au problème d'ordonnancement
La formulation du problème d'ordonnancement comme présenté en introduction nous amène à résoudre un problème combinatoire NP-dur, ainsi certains auteurs ont proposé une énumération des différents chemins possibles pour résoudre ce problème. Dans cette partie
nous allons résoudre ce problème en appliquant un algorithme de colonie de fourmis. ous procéderons en quelque sorte à une énumération des différents chemins, et ce
sont les founnis qui trouveront le meilleur chemin panni le réseau étudié.
Calcul de la date de début au plus tôt
Pour le calcul de la date de début au plus tôt il n'y a pas besoin de mettre en place une
métaheuristique, en effet ce calcul n'est pas NP-dur mais linéaire.
Pour calculer la date de début au plus tôt minimale, il suffit d'affecter à toutes les
tâches leur durée minimale et de faire le calcul du chemin critique complet, les dates de début au plus tôt trouvées sont les dates de début au plus tôt minimale pour chaque tâche.
Pour le calcul de la date de début au plus tôt maximale, c'est l'inverse, on affecte la
durée maximale à chaque tâche, puis après calcul du chemin critique complet on trouve la
CHAPITRE Il: MÉTHODE DES INTERVALLES
Les algorithmes peuvent se traduire ainsi:
Algorithme de colonies de fourmis de base: le "Ant System·. Calcul de la date de début au plus tôt minimale
Affecter la durée minimale à toutes les tâches.
Cpm (exécution de la méthode cpm)
Enregistrer résultat (date de début au plus tôt de chaque tâche date de début au plus tôt minimale)
Fin
Figure 2.4 Algorithme de calcul de la date de début au plus tôt minimale
Algorithme de colonies de fourmis de base: le "Ant System·. Calcul de la date de début au plus tôt minimale
Affecter la durée maximale à toutes les tâches.
Cpm (exécution de la méthode cpm)
Enregistrer résultat (date de début au plus tôt de chaque tâche date de début au plus tôt minimale)
Fin
Figure 2.5 Algorithme de calcul de la date de début au plus tôt minimale
Calcul de la date de début au plus tard
32
Ce calcul est un problème combinatoire NP-dur, si l'on souhaite le traiter en étudiant
tous les scénarios. J'ai donc décidé de mettre en place une métaheuristique en tenant compte
des hypothèses publiées dans l'article de Dubois, Fargier et Fortin (2005). Les hypothèses sont les suivantes:
.". Calcul de la date de début au plus tard minimale
Dans les conditions suivantes il existe un chemin p qui permet de minimiser la date de début au plus tard.
CHAPITRE Il: MÉTHODE DES INTERVALLES
33
a Durées de toutes les tâches affectées à la valeur minimalea Les tâches du chemin p allant de la tâche en question jusqu'à la fin du réseau se voient affecter la durée maximale (tâche étudiée comprise).
'1>- Calcul de la date de début au plus tard maximale
Dans les conditions suivantes il existe un chemin p qui permet de maximiser la date de
début au plus tard.
a Durées de toutes les tâches affectées à la valeur minimale
a Les tâches du chemin p allant du début du réseau à la fin se voient affecter la durée maximale.
L'objectif est donc de trouver le chemin en question, c'est là que j'utilise l'algorithme
des colonies de fourmis.
Calcul de la date de début au plus tard minimale
Pour le calcul de la date de début au plus tard minimale il faut donc trouver le chemin
allant de la tâche étudiée jusqu'à la fin du réseau, qui minimise la date de début au plus tôt de
la tâche choisie. L'analogie avec le voyageur de commerce est donc envisageable. L'adaptation se fera comme suit:
L'algorithme est opéré pour t itérations (1 de 1 à Imax). À chaque itération les fourmis parcourent le graphe des tâches à leur manière. Le parcours de chaque fourmi ce construit
ainsi:
1) la fourmi pal1 de la tâche étudiée: i (tâche 0)
2) la fourmi choisi au hasard la tâche suivante (j) en fonction de:
a. la liste des successeurs:
s
u
cc(i)
CHAPITRE Il: MÉTHODE DES INTERVALLES 34 c. la quantité de phéromones, paramètre qui évolue au passage des founnis.
C'est l'intensité de la liaison.
r;Jt)
La probabilité que la fourmi choisisse la tâche est définie ainsi:
Équation 2.6
si
jE
suee(i)si j il suee(i)
a et fJ sont deux paramètres fixant l'importance relative de la visibilité et de l'intensité de la liaison.
3) L'étape deux est réitérée jusqu'à atteindre la demi ère tâche.
4) On dépose une quantité de phéromones sur l'ensemble des pistes (relation de précédence entre deux tâches) .1r~ (t), elle, est fonction de la qualité de la solution trouvée par la fourmi:
si (i,j)E pk (t)
si (i,j) il P\ I)
Équation 2.7
Le terme
Lst
k(1)
représente la longueur du tour effectué par la foum1ik
à l'itération1
.
Q
est un paramètre fixé au départ égale à Ls
t
1 (J), la longueur du trajet de la première foull11i. Le terme pk (t) représente le chemin suivi par la fourmi k pendant son itération 1 (notons que cette quantité est enregistrée, elle est déposée seulement une fois que toutes les foull11is de l'itération sont passées). J'ai rajouté (+ 1) au numérateur et au dénominateur de la fonnule par rapport à l'algorithme de base, car les premières tâches ont en général une date deCHAPITRE Il: MÉTHODE DES fNTERVALLES 35 début au plus tard égale à zéro, et un paramètre
Q
égale à zéro ne permettrait pas de faire de comparaison entre les différentes solutions testées.5) Étape appelée évaporation des pistes, elle s'effectue à la fin d'une itération quand toutes les foum1is ont terminé. On décrémente la dose de phéromone des liaisons,
puis on ajoute les quantités de phéromones enregistrées. L'évaporation s'effectue suivant la formule ci-dessous:
r
ij(t
+
1
J
= (
1 -
P
J
.
r
ij(t
J
+
Lir
ij(
t
J
Équation 2.8
Le terme T
urt)
représente la quantité de phéromones sur la 1 iaison de la tâche i à la tâche)à l'itération t.
p
est le paramètre d'évaporation et LIT ij(
t
)
représente les quantités de phéromones entre la ville i et) accumulées au cours de l'itération t.L'algorithme peut se traduire ainsi:
Algorithme de colonies de fourmis de base: le "Ant System". Calcul de la date de début au plus tard minimale
Mettre en configuration de base (durée minimale pour toutes les
tâches sauf celle étudiée)
Cpm (exécution de la méthode cpm) Q = lst(i)
Enregistrer résultat (date de début au plus tard minimale)
Pour t
=
1._ .. tmaxPour chaque fourmi k
=
1, . mMettre en configuration de base
Tâche actuelle = tâche étudiée
Répéter
Choisir une tâche parmi les successeurs de la tâche
CHAPITRE Il: MÉTHODE DES INTERVALLES
Affecter la durée maximale à la tâche choisie Tâche actuelle = tâche choisie
Jusqu'à tâche choisie = dernière tâche du réseau Cpm (exécution de la méthode cpm)
Déposer phéromones
Si résultat meilleur enregistrer résultat
Fin pour
Évaporer les pistes Fin pour
Figure 2.6 Algorithme de calcul de la date de début au plus tard minimale
Calcul de la date de début au plus tard maximale
36
Pour le calcul de la date de début au plus tard maximale il faut trouver le chemin allant
du début jusqu'à la fin du réseau, qui maximise la date de début au plus tôt de la tâche choisie (cf. calcul de la date de début au plus tard).
L'adaptation de l'algorithme de fourmis se fera comme celle du calcul de la date de
début au plus tard minimale, sauf que la fourmi partira de la première tâche du réseau, pour se rendre à la demière. La quantité de phéromones déposée est également calculée
différemment (cf. étape 4 calcul de la date de début au plus tard minimale):
si
(
i,j)
E p
k
(t)
si(i,j)
ri p
k
(t
)
Équation 2.9
On conserve le (+ 1) au dénominateur, car certaines tâches peuvent avoir une date de