UNIVERSITÉ DU QUÉBEC
À
MONTRÉALUTILISATION D'UNE ONTOLOGIE ET DU RÉSEAU SOCIAL FACEBOOK POUR LA
MODÉLISATION DU CONTEXTE POUR LES APPLICATIONS MOBILES
DÉPENDANTES DU CONTEXTE
MÉMOIRE
PRÉSENTÉ
COMME EXIGENCE PARTIELLE
DE LA MAÎTRISE EN INFORMA TIQUE
PAR
AHMED SAlO LOUBIRI
Service des bibliothèques
·
A vertissenient
La
diffusion de ce mémoire se fait dans le' respect des droits de son auteur, qui a signé
le formulaire
Autorisation de reproduire.
et de diffuser un travail de recherche de
.
cycles
supérieurs
(SDU-522- Rév.01-2006). Cette autorisation stipule que <<conformément
à
l'article 11 du Règlement no 8 des études de cycles supérieurs, [l'auteur] concède
à
l'Université du Québec
à
Montréal une licence non exclusive d'utilisation et de
.
publication
~ela totalité ou d'une partie importante de [son]
.
travail de recherche pour
des fins pédagogiques et non commerciales.
Plus précisément, [l'auteur] autorise
l'Université du Québec
à
Montréal
à
reproduire, diffuser, prêter, distribuer ou vendre des
.
·
copies de
.
[son] travail de recherche
à
des fins non commerciales sur quelque support
que ce soit, y compris l'Internet. Cette licence et cette autorisation n'entraînent pas une
renonciation de [la] part [de l'auteur]
à
[ses] droits moraux ni
à
[ses] droits de propriété
intellectuelle. Sauf entente contraire, [l'auteur] conserve la liberté de diffuser et de
commercialiser ou non ce travail dont
[il]
possède un exemplaire .
.
>>REMERCIEMENTS
Je tiens à remercier sincèrement toutes les personnes qui m'ont appo1té leur aide et qui ont contribué à l'élaboration de ce mémoire ainsi qu'à la réussite de ce formidable cursus universitaire.
Je souhaite, en prem1er lieu, adresser mes remerciements les plus chaleureux à mon directeur de recherche, Monsieur Obaid Abdellatif, pour m'avoir donné la chance de réaliser ce travail et s'être toujours montré à l'écoute et très disponible tout au long de la réalisation de ce mémoire. Il a toute ma reconnaissance pour l'inspiration, l'aide et le temps qu'il a bien voulu me consacrer et sans lui, ce mémoire n'aurait jamais vu le jour.
Mes remerciements s'adressent également à ma codirectrice Madame Fatiha Sadat pour sa générosité et son suivi rigoureux.
J'exprime ma gratitude à tous les professeurs de 1 'UQAM qui m'ont accompagné pendant ces années et m'ont permis d'avoir une formation de qualité. Je remercie notamment mes deux directeurs de programme, Monsieur Étienne Gagnon et Monsieur Roger Villemaire, pour leur encadrement rigoureux. Je remercie aussi Monsieur Petko Valtchev, directeur de mon laboratoire de recherche, pour sa disponibilité et ses précieux conseils et recommandations.
Je tiens aussi à remercier tout l'ensemble du personnel de I'UQAM, surtout Madame Lise Arsenault et Madame Louise Tremblay pour leur soutien tout au long de la maitrise.
Je remercie également Madame Cynthia
Li
sée, pour m'avoir appris les règles et les techniques de recherche et surtout d'avoir eu la gentillesse de lire et réviser la bibliographie et la qualité de la langue de ce mémoire.J'adresse autant mes plus sincères remerciements à mes parents et ma famille pour tous les sacrifices consentis afin de me donner les moyens d'avoir cette formation et leur soutien tout au long de ces dures années d'études.
Enfin, je remercie tous mes proches et amis, qui m'ont toujours soutenu et encouragé au cours de la réalisation de ce travail, ainsi que tout ceux qui ont contribué de près ou de loin à l'élaboration de ce mémoire.
TABLE DES MATIÈRES
LISTE DES FIGURES ... vii
LISTE DES TABLEAUX ... ix RÉSUMÉ ... x CHAPITRE I INTRODUCTION ... 1 1.1. Problématique ... 2 1.2. Objectifs ... 3 1.3. Méthodologie ... 3 1.4. Organisation du mémoire ... .4 CHAPITRE Il CONCEPTS DE BASE ... 6 2.1. La notion de contexte ... 6
2.2. Les systèmes dépendants du contexte ... 7
2.3. Les réseaux sociaux ... 8
2.4. Les ontologies ... 8
2.5. Langages et outils de conception des ontologies ... 12
CHAPITRE JJl ÉTAT DE L'ART ... 14
3 .1. Introduction ... 14
3.2. Quelques modèles existants ... 16
3.2.1. Le Service-Oriented Context-Aware Middleware (SOCAM) [15] ... 16
3.2.2. Le modèle Context Broker Architecture (CoBrA) [ 1 0] ... 19
3.2.3. Context-Awarness Sub-Structure (CASS) [18] ... 22
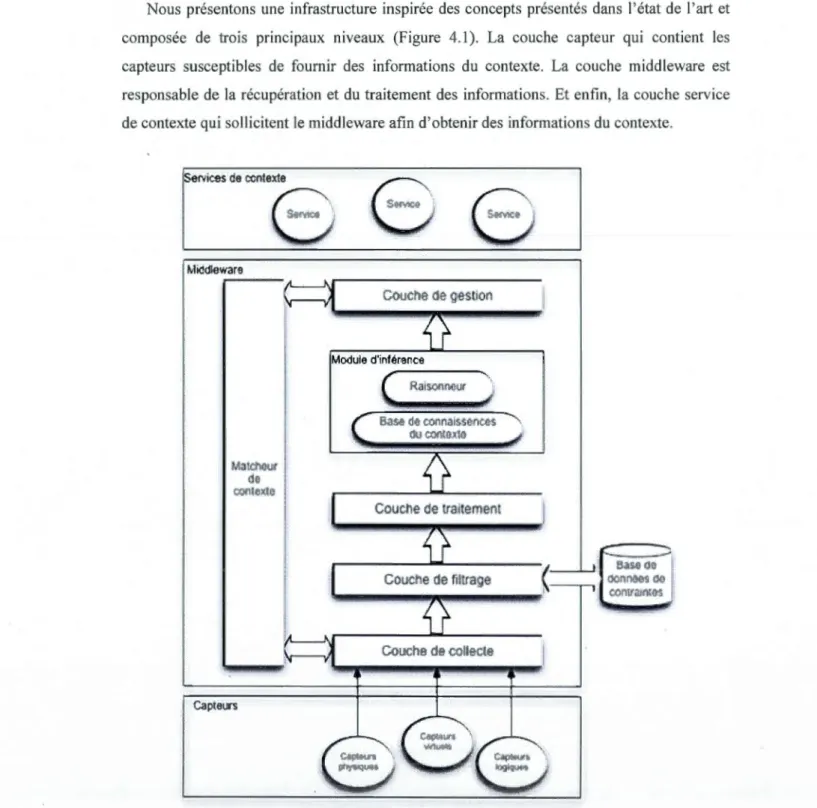
3.2.4. Le projet Hydrogène [19] ... 24 3.2.5. Architecture Smart-M3 [20] ... 26 CHAPITRE IV ARCHITECTURE ... 29 4.1. Introduction ... 29 4.2. Architecture proposée ... 30
4.2.1. La couche Capteurs ... 31
4.2.2.1. La couche de collection des données ... 32
4.2.2.2. La couche de filtrage des données ... 33
4.2.2.3. La couche de traitement des données ... 33
4.2.2.4. Module d'inférence ... 34
4.2.2.5. La base de connaissance du contexte ... 34
4.2.2.6. Le raisonneur ... 35
4.2.2.7. La couche de gestion du contexte ... 36
4.2.2.8. Le module de correspondance de contexte ... 36
4.2.3. Les services du contexte ... 36
4.3. Plan de validation de l'architecture ... 37
CHAPITRE V MODÉLISATION DE L'ONTOLOGIE FACEBOOK ... 38
5.1. Introduction ... 38
5.2. Contexte social et réseaux sociaux en ligne, cas de Facebook ... 39
5.2.1. Les liens ... .40 5.2.2. Les événements ... .40 5.2.3. Les préférences ... 40 5.2.4. Les emplacements ... 41 5.2.5. La présence en ligne ... .41 5.2.6. La personnalité ... .41 5.2.7. Le marquage ... .42 5.3. Le graphe Facebook ... .42
5.3.1. Le protocole Open Graph ... .42
5.3.2. Le Graphe Socia1 ... .43
5.4. L'ontologie de Facebook ... .45
5.4.1. Modélisation de l'ontologie ... .45
5.4.1.1. Les objets de Facebook ... .46
5.4.1.2. Les propriétés des objets ... 48
5.4.1.3. Les relations ... .49
5.4.1.4. L'ontologie ... 51
CHAPITRE VI MODÉLISATION DU CONTEXTE ... 53
6.1. Introduction ... ., ... 53
6.2. Conception de l'ontologie du contexte ... 53
YI
6.2.2. Étape B: Extension de l'ontologie de haut niveau par les concepts du domaine ... 57
6.2.3. Étape C: Couplage de l'ontologie du contexte et de l'ontologie Facebook ... 60
6.2.4. Étape 0: Raisonnement et inférence du contexte ... 63
6.3. Raisonnement ontologique ... 63
6.4. Simulation des règles d'inférence ... 67
CHAPITRE VII CONCLUSION ... 72
Figure Page
2.1 Catégorisation de Guarino pour les ontologies ... 12
3.1 Architecture SOCAM ... 17
3.2 Ontologie du modèle de contexte SOCAM ... 18
3.3 Architecture CoBrA ... 20
3.4 Architecture CASS ... 22
3.5 Modèle de contexte CASS ... 23
3.6 Architecture Hydrogène ... 24
3.7 Modèle de contexte Hydrogène ... 25
3.8 Architecture Smart-3 ... 26
3.9 Modèle d'ontologie Smart-3 ... 28
4.1 Architecture de notre système dépendant au contexte proposé ... 30
5.1 Open Graph de Facebook ... 43
5.2 Graphe Social des réseaux d'amis de Facebook généré par touchgraphe.net . ..... 44
5.3 Capture écran des classes de Facebook sous Protégé ... .48
5.4 Capture d'écran Les relations sous Protégé ... 51 5.5 Ontologie de Facebook ... , ... 52
6.1 Approche de modélisation du contexte ... ., ... 55
6.2 Ontologie du haut niveau se basant sur CONON ... , ... 56
6.3 Classification des différents états physiologiques ... 58
6.4 Classification des appareils ... 59
6.5 Ontologie du domaine ... 61 6.6 Ontologie du contexte ... : ... 62
6.7 Classification des personnes selon l'âge ... 65
6.8 Règles définissant les niveaux de température corporelle de l'utilisateur ... 66
6.9 RèJ?;les d'inférence des niveaux de glycémie de l'utilisateur. ... 67
6.10 Capture d'écran- Initiation de la description d'un individu ... 68
6.12 Initiation de l'individu Fana ... : ... 70 6.13 Individu Fana après inférence ... 70
Tableau Page
5.1 Objets de Facebook ... 47 5.2 Propriétés des objets de Facebook ... 49 5.3 Relations entre les objets de Facebook ... 50
RÉSUMÉ
L'informatique dépendante du contexte est un paradigme de l'informatique qui tient en considération les éléments de l'environnement d'une entité (utilisateur, périphérique, etc.).
Ce paradigme, qui prend une place de plus en plus importante grâce au développement rapide des technologies mobiles, a mené à la mise en place de différentes architectures et de divers modèles qui fournissent l'information sur le contexte.
Au niveau des architectures plusieurs solutions ont été proposées mais présentent tout de même certaines limites notamment, au niveau de la modélisation du contexte. De nombreux modèles ont été proposés dépendamment des taches à réaliser, mais se concentrent sur les capteurs physiques comme source principales des données de contexte et ignorent les informations qu'on pourrait acquérir de la fouille des différents profils en ligne d'un uti 1 i sateu r.
Dans ce travail, nous proposons une architecture middleware pour le traitement et la gestion des informations du contexte pour un usager mobile en exploitant les données de Facebook comme source d'informations de contexte. Ainsi, nous analysons le réseau Facebook et le représentons sous forme de modèle ontologique. Nous fusionnons, ce modèle avec une ontologie du contexte relative à une simple application du domaine médical. Le modèle obtenu constitue notre solution proposée pour l'exploitation des données disponibles sur les réseaux en ligne dans la modélisation d'un contexte médical simplifié.
Mots-clés : informatique mobile, modélisation du contexte, application dépendantes du
contexte, architecture middleware, réseaux sociaux, modélisation de l'ontologie, ontologie du contexte.
INTRODUCTION
L'informatique mobile se repose sur les appareils portatifs et les réseaux sans fils. Cette
technologie permet à 1' utilisateur d'exécuter des tâches informatiques et d'accéder à l'information à n'importe quel endroit et n'importe quel moment. Durant ces dernières années, l'informatique mobile a remarquablement participé
à
l'amélioration de la viequotidienne des personnes en leur permettant de faire différents traitements et d'avoir un
accès permanent à l'information indépendamment de leurs déplacements. La mobilité des
utilisateurs et des périphériques a donné naissance
à
un nouveau paradigme en informatique appelé informatique sensible au contexte ou informatique dépendante du contexte.Le développement rapide des technologies de communication mobile, en l'occurrence des réseaux et appareils, et leur capacité et performance a engendré une augmentation
exponentielle de son utilisation. Le marché des téléphones mobiles intelligents (smart phones) et des tablettes a connu une explosion des ventes dans les dernières années. Ces
machines sont devenues aujourd'hui quasi indispensables
à
la vie de tous les jours.Les téléphones intelligents disposent actuellement de meilleures capacités de traitement et
une meilleure connectivité, leur permettant d'exécuter des tâches de plus en plus complexes et d'intégrer de nouvelles fonctionnalités.
Les applications mobiles sont des logiciels qui offrent à 1 'utilisateur différents services offerts par l'application comme la messagerie instantanée, la téléphonie IP, la commande à distance d'appareils et autres traitements dont certains peuvent dépendre du contexte de
2
Une
n
o
uv
e
ll
e
gé
nération d
'a
pplicati
o
ns mobile
s a
donc
vu
le j
o
ur
comme conséquence
d
e
l
'évo
luti
on
de
ces
t
ec
hn
o
logies
.
Il
s'ag
it de
s
app
l
ications
mobil
es
d
é
p
e
ndant
es
au contexte.
Ces app
li
cations
off
rent des
services
mieu
x
adaptés
à
la
situat
i
o
n
de
l
'
utili
sate
ur
et
qui
ti
e
nn
e
nt
co
mpt
e
d
e certa
in
s
caractéristiques
co
nt
ext
u
e
ll
es te
ll
es
que
ses
préférences
personn
e
ll
es
,
so
n
environnement
phy
si
que
, so
n
emplacement
géogra
phiqu
e,
ses
déplacem
e
nt
s, etc.
1.1 Problématique
Les
diff
ére
nt
es ava
nc
ées
dan
s
le
domaine
d
e
l
'
inf
o
rm
at
iqu
e
mobile
o
nt
co
nduit
a
u
dé
ve
l
o
ppem
ent
d
e systè
m
es
dépendant
s
du
contexte.
L
'
ob
j
ect
if
de
ces systè
m
es éta
nt
de
fournir
d
es
informations
qui d
é
pend
e
nt
de
l
'
e
nvir
o
nn
e
m
e
nt d
e
l
'
utili
sate
ur
afi
n
d
'
a
m
é
li
o
r
e
r
so
n int
e
racti
o
n
avec
l
'
apparei
l m
o
bil
e.
De
ce fait
,
plu
s
i
e
ur
s arc
hit
ec
tur
es o
nt
été
proposées
e
t div
e
r
s
m
o
d
è
l
es
d
e co
nt
exte o
nt
été
dé
ve
lopp
és
.
Ce
p
e
ndant
,
nou
s
pouvon
s
id
e
ntifier
l
es
difficulté
s s
uiv
a
nt
es
par rappo
1
t
à
l
a
m
odé
li
sat
i
o
n
et
l
'
utili
sat
i
o
n d
es
d
on
n
ées
du
co
nt
exte,
dont:
•
•
Absence
d
e
formalisme
et d
'
int
e
lli
ge
n
ce;
No
n
ex
ploit
a
ti
o
n des réseaux
soc
iau
x e
n li
g
n
e :
l
es
mod
è
l
es
d
e co
nt
ex
t
e ex
i
sta
nts n
e
ti
e
nnent p
as
compte de
la
g
rand
e
qu
a
ntit
é
d
'
inf
o
rm
a
ti
o
n
s
contextue
ll
es
qui
ex
i
s
t
e
nt
déjà dans
l
es réseaux sociaux en
li
gne te
l
s
que
Facebook1;•
No
n-in
tégrat
i
o
n de
s
mod
è
l
es
d
'
int
e
lli
ge
n
ce (e
n
particulier
ce
u
x
b
asés s
ur l
es
o
ntol
og
i
es)
dan
s
l
es
r
ésea
u
x socia
u
x e
n
l
igne dans
l
a
modélisation
du
co
n
texte:
il
n
'
ex
i
ste
p
as
d
e g
rand
s
trav
a
u
x
de représentation
d
es
r
ésea
u
x soc
i
a
u
x so
u
s
forme
o
nt
o
l
og
iqu
e
pour
d
es
fins
d
'
int
égrat
i
o
n
dans
l
es
m
odè
l
es
d
e
contexte
;
•
A
b
se
n
ce
de
li
e
n
e
n li
g
n
e e
ntr
e ces
in
for
m
at
i
o
n
s
et
l
es
applications
d
é
p
enda
n
tes du
co
n
texte
les plus
u
t
il
es (te
ll
es que
les
applications
médical
es.
En effet,
il exi
ste
plusieurs
app
li
catio
n
s
dans
l
e
domaine médical
,
mais
e
ll
es
ne
font pas
l
e
lien
entre
l
es
1
https:/
/www.facebook.com
-informations sur le patient et son médecin traitant, lesquelles informations se trouvent déjà en grande partie dans les profils des réseaux sociaux comme Facebook.
1.2 Objectifs
Afin de remédier aux problèmes soulevés dans la problématique, nous nous sommes fixés les objectifs suivants pour la réalisation de notre mémoire :
• Création d'un modèle de contexte relatif au domaine d'application, en 1 'occurrence le domaine médical;
• Utilisation des ontologies pour la représentation du contexte;
• Présentation d'une architecture dépendante du contexte capable de gérer les informations captées et de les fournir à des applications mobiles;
• Couplage de l'environnement de l'utilisateur avec des informations tirées des réseaux sociaux en ligne comme Facebook;
• Utilisation dans le cadre d'une application simple dans le domaine médical qui utilise des données physiologiques mesurées pas le biais de capteurs corporels;
• Établissement de liens entre les profils Facebook d'un utilisateur et son médecin en vue de réagir aux changements des données physiologiques captées;
•
Définition d'un ensemble de réactions dépendantes du contexte physiologique et spatio-temporel de l'utilisateur. (Non réalisé)1.3 Méthodologie
Pour notre travail, nous allons adopter une méthodologie qui est basée sur la formalisation de la notion d'ontologie et son emploi dans le cas d'une application autour de 1 'environnement Face book. Cette méthodologie s'articule autour des éléments suivants :
• Étude des infrastructures dépendantes du contexte par une revue de la littérature des systèmes déjà existants;
• Conception d'une architecture de gestion des informations du contexte inspirée des modèles existants et des différentes critiques de ces modèles;
• Étudier la structure du réseau social en ligne Facebook: ses objets et les relations entre eux;
• Conception d'une ontologie qui représente les éléments de Facebook et les relations entre ces éléments;
• Choix d'une ontologie de contexte de haut niveau qui représente les concepts généraux indépendants du domaine;
• Extension de l'ontologie de haut niveau avec les concepts du domaine choisi. Nous développerons notre modèle dans le cadre médical;
• Intégration de l'ontologie du domaine et de l'ontologie de Facebook afin d'avoir un modèle de contexte général;
•
•
•
Implémentation du modèle du contexte avec Protégé2 comme outil d'édition des ontologies;
Définition des règles de raisonnement pour l'inférence du contexte;
Simulation du raisonnement ontologique et des règles d'inférence .
1.4 Organisation du mémoire
Notre mémoire est organisé de la manière suivante :
4
Le premier chapitre présente les notions de base de notre travail. Ainsi, nous définirons la notion de contexte et les systèmes dépendants du contexte. Nous introduirons les ontologies, comme outil de représentation des connaissances contextuelles. Nous les définirons, délimiterons leurs domaines d'utilisation et déterminerons leurs caractéristiques, leurs critères de conception et leur classification;
2
Le chapitre II est un état de l'ati. C'est une revue de littérature des infrastructures dépendantes du contexte existantes. Nous donnerons plusieurs classifications possibles de ces infrastructures. Nous présenterons quelques systèmes existants tout en analysant leurs architectures et leurs modèles de contexte;
Dans le chapitre III nous suggérerons notre propre architecture en nous basant sur les exemples exposés dans la revue la littérature et l'analyse des avantages et limites de ces systèmes;
Le chapitre IV est un chapitre de réalisation. Nous parlerons des réseaux sociaux en ligne et des avantages de leur utilisation pour des systèmes dépendants du contexte. Nous prendrons Facebook comme exemple. Nous analyserons son architecture, les objets qui le constituent et les relations entre eux. Nous représenterons cette architecture sous forme d'ontologie que nous implémenterons sur un éditeur d'ontologies (Protégé);
A travers le chapitre V, nous expliquerons notre approche pour la conception d'un modèle de contexte pour le domaine médical. Nous intégrerons ce modèle avec l'ontologie développée pour Facebook afin de l'enrichir avec les informations disponibles de ce réseau social en ligne. Enfin, nous définirons des règles d'inférence pour ce modèle de contexte, qu'on testera par la suite.
CHAPITRE II
CONCEPTS DE BASE
2.1 La notion de contexte
L
a
n
o
ti
o
n du
co
nt
ex
t
e a é
t
é
utili
sée e
n lin
g
ui
s
tiqu
e e
t p
syc
h
o
l
og
i
e av
ant d
'ê
tr
e a
d
o
pt
ée e
n
inf
o
rmatiqu
e,
m
a
i
s a
au
ss
i un
e o
ri
g
in
e
l
o
int
a
in
e e
t un
e
l
o
n
g
u
e
hi
s
t
o
ir
e e
n phil
oso
phi
e
[1]. L
a
m
o
bilit
é a
d
o
nné une dim
e
n
s
i
o
n imp
o
rt
a
nt
e
au c
o
nt
ex
t
e
qui
a
t
o
u
c
h
é
àd
e
n
o
mbr
e
u
x
champ
s
d
'a
ppli
ca
ti
o
n
e
n inf
o
rm
a
tiqu
e co
mm
e
1'
inf
o
rm
a
tiqu
e
ubiquit
a
ir
e,
1'int
e
lli
ge
n
ce a
rtifi
c
i
e
ll
e,
l
e
tr
a
it
e
m
e
nt d
e
la lan
g
u
e
n
a
tur
e
ll
e,
l
'
in
te
r
ac
ti
o
n p
e
r
so
nn
e
-m
ac
hin
e e
t l
a séc
urit
é
inf
o
rm
a
tiqu
e
,
e
tc
.
Il
ex
i
s
t
e
plu
s
i
e
ur
s
d
é
finiti
o
n
s
du
co
nt
ex
t
e,
qui
va
ri
e
n
t se
l
o
n l
e
d
o
m
a
in
e
d
'
utili
sa
ti
o
n
e
t d
e
l
'o
bjecti
f
fin
a
l de
so
n
a
ppli
ca
ti
o
n. L
a
d
é
finiti
o
n
co
ur
a
nt
e
l
a
plu
s
utili
sée es
t
ce
ll
e
d
e
D
ey
et
a
l.
[
2
] qui d
é
finit le c
o
nt
ex
t
e co
mm
e é
t
a
nt :
«
Toute information qui peut être utilisée pour caractériser la ..situation d'uneentité. Une entité est une place, une personne, un ou objet qui est considéré pertinent à l'interaction entre un utilisateur et une application, incluant
l'utilisateur et l'application eux-mêmes » [N
o
tr
e
tr
a
du
c
ti
o
n]
.
U
n
e
d
é
fini
t
i
o
n plu
s gé
n
éra
l
e a été
pr
o
p
osée
p
a
r
Za
in
o
l
et
N
a
k
a
t
a [ 1
] qui
co
n
s
id
è
r
e
«
qu'une information est dite de contexte quand elle désigne une situation qui est pertinente2.2 Les systèmes dépendants du contexte
Les systèmes dépendants du contexte ont été largement étudiés en informatique et plusieurs ont tentés de définir cette catégorie d'applications.
Dans [3], les auteurs affirment qu'en informatique dépendante du contexte, un utilisateur
«do
it
être capab
l
e
d'accomplir facilement une action qui peut possiblement
inclur
e
un
e
co
opération
et
un
e
collaboration avec d'autres
utilisateurs
en
utilisant de
multipl
es
périphériques
et
r
éseaux
alors
qu'il
se déplace dans
l
'env
ironn
eme
nt
»
[Notre traduction]. Les périphériques et applications doivent alors s'adapter automatiquement aux besoins courants de 1 'uti 1 isateur.Les auteurs de [1] proposent une définition des systèmes sensibles au contexte qUI
«
perm
ette
nt
aux
périphériques d
'
exp
l
oiter
l
eurs
informations
env
ir
onnantes e
t
d
'
adap
t
er
leur
comportement selon
la
situation actuelle de
1
'u
tili
sa
t
eur»
[Notre traduction]. La situation actuelle de l'utilisateur caractérise donc son contexte. Afin de pouvoir fournir l'information appropriée, et donc pertinente,à
l'utilisateur, les systèmes ont besoin de collecter et d 'uti 1 iser des informations de contexte.Une définition plus généraliste a été proposée dans [2]. Les auteurs affirment qu'un système est dépendant au contexte
«s
'il
utilise
l
e co
nt
ex
t
e
pour fournir une
inf
orma
tion
pertinente ou/et des services
à1
'
utilis
ateu
r
,
où
la
pertinence dépend de
la
tâche de
l'utilisateur»
[Notre traduction]. Cette définition est étroitement liée à celle que les mêmes auteurs ont proposée pour définir le contexte. Nous pouvons remarquer que ces auteurs utilisent la« pertinence» qui reste une notion subjective et peu tangible.Les systèmes dépendants du contexte ont besoin de collecter différentes informations relatives au contexte de l'utilisateur à partir de diverses sources afin de s'adapter à sa situation ou même ses intentions. Ces sources peuvent être distribuées et souvent n'ont pas de relations ou de liens de connexions directes entre elles.
8
Les applications sensibles au contexte, permettent d'améliorer l'interaction personne -machine et n'ont pas besoin d'une intervention humaine pour s'adapter au contexte de 1' uti 1 isateur.
Il est alors très important de définir et modéliser le contexte de l'utilisateur afin d'offrir une information de contexte aux systèmes dépendants du contexte. Cette démarche nous pousse à concevoir des modèles susceptibles de représenter les différentes composantes du contexte et les relations qui existent entre elles. La plus prometteuse de ces méthodes repose sur les ontologies.
2.3 Les réseaux sociaux
Les réseaux soc1aux en ligne ont envahi la toile au cours de ces dernières années, déclenchant un phénomène sans précédent. Ces réseaux comme Twitter3ou Facebook
grandissent d'une manière exponentielle en termes de nombre d'utilisateurs. Ces services permettent aux personnes de créer des liens virtuels avec d'autres utilisateurs et de maintenir des relations définissant un réseau. Vu la popularité des réseaux sociaux et le nombre important des utilisateurs, il est primordial d'étudier leurs structures et fonctionnement.
L'analyse de ces réseaux peut nous conduire à des résultats intéressants puisqu'ils contiennent un nombre important de données personnelles et d'informations sur les utilisateurs et leurs relations sociales en ligne. L'aspect le plus intéressant des ces réseaux est qu'ils peuvent représenter un vrai reflet des relations sociales. Les personnes interconnectées sur un réseau social sont souvent des personnes qui ont des liens familiaux ou qui fréquentent le même travail, école, association ou qui partagent les mêmes passions ou visions politiques.
2.4 Les ontologies
Comme nous avons basé notre travail sur
1
'approche ontologique pour la modélisation du contexte, nous définissons ci-dessous les ontologies et nous présentons leurs domaines3
9
d
'
utili
sa
ti
o
n
,
l
e
ur
s ca
r
ac
t
é
ri
s
tique
s
,
l
e
ur
s
cla
ss
ifi
ca
ti
o
n
s
am
s
t qu
e
l
es c
rit
è
r
es
de l
e
ur
c
o
nc
e
pti
o
n.
L
'o
ri
g
in
e
du t
e
rm
e o
ntol
og
i
e
vi
e
nt d
e
l
a
phil
oso
phi
e.
Il
s'
a
g
it d
e
l
'é
tud
e
d
e ce
qui
ex
i
s
t
e:
l
'ê
tr
e
,
ses
m
o
d
a
lit
és e
t
ses
pr
o
pri
é
t
és. Cette
b
ra
n
c
h
e es
t c
o
n
s
id
é
r
ée co
mm
e
p
a
rti
e
d
e
l
a
m
é
t
a
ph
ys
iqu
e. Ce
p
e
nd
a
nt
,
l
o
ngt
e
mp
s,
l
a
n
ot
i
o
n d'
o
ntol
og
i
e a s
u
sc
it
é
l'
in
té
r
êt des
a
cad
é
mi
c
i
e
n
s
d
a
n
s
d'
a
utr
es
d
o
maine
s
t
e
l
s
qu
e
l
a
lin
g
ui
s
tiqu
e e
t
s
ut
to
ut 1
'
in
fo
rm
at
iqu
e.
E
n inf
o
rm
a
tiqu
e,
une d
é
finition fr
é
qu
e
nt
e es
t
ce
ll
e
d
e
Grub
e
r [
4
] qui d
é
finit l'
o
nt
o
l
og
i
e
co
mm
e é
t
a
nt
«une spécification explicite d
'
un
e
conceptualisation
»
[N
o
tr
e t
r
a
du
c
ti
o
n]. Plu
s
ex
pli
c
it
e
m
e
nt,
l'
o
n
to
l
og
i
e est
l
a
r
e
pr
ése
nt
at
i
o
n d
es o
bj
ets
d'
un d
o
m
ai
n
e do
nn
é et
l
es
diff
é
r
e
nt
es
r
e
l
at
i
o
n
s
qui
ex
i
s
t
e
nt
e
ntr
e
c
es o
bj
ets
.
Les o
nt
o
l
og
i
es se
b
ase
n
t s
ur un
voca
bul
a
ir
e
pr
é
d
é
fini qui r
e
nd
ce
tt
e
r
e
pr
ése
nt
a
ti
o
n f
o
rm
e
ll
e.
L
es
ont
o
l
og
i
es so
nt
a
lor
s
tr
ès
imp
o
rt
a
nt
es
p
o
ur la r
e
pr
és
ent
a
ti
o
n d
es co
nn
a
i
ssa
n
ces
d
'un
dom
a
in
e
d
o
nn
é. E
ll
es off
r
e
nt
, e
n plu
s
,
un l
a
n
gage fo
rm
e
l. L
es o
nt
o
l
og
i
es so
nt n
écessa
ir
es
p
o
ur l
e
p
a
rt
age
d
es co
nn
a
i
ssa
n
ces.
L
es o
nt
o
l
og
i
es so
nt utili
sé
e
s
d
a
n
s
dif
fé
r
e
nt
s
d
o
main
es
d
e
l'
inf
o
rm
a
tiqu
e
,
e
t
ce
,
particuli
è
r
e
m
e
nt
e
n int
e
lli
ge
n
ce
artifi
c
i
e
ll
e (
T
A)
,
o
ù
e
ll
es
p
e
rm
e
tt
e
nt d
e fo
urnir d
es s
tructur
es
pour f
ac
iliter l
a
r
e
pr
ése
nt
a
ti
o
n d
es
c
o
nn
a
i
ssa
n
ces e
t l
e
pr
o
c
ess
u
s
d'
in
fé
r
e
n
ce. Les o
nt
o
l
ogies
ont
é
t
é
utili
sées
d
a
n
s
l'
in
gé
ni
e
ri
e
d
e
l
a
c
o
nn
a
i
ssa
nc
e
,
l'
a
ppr
e
nti
ssage a
u
to
m
a
tiqu
e e
t
a
u
ss
i
pour l
a
dé
sa
mbi
g
uï
sa
ti
o
n dan
s
l
e
trait
e
m
e
nt
a
ut
o
m
a
tiqu
e
du l
a
n
gage
[
5]. Les o
n
to
l
og
i
es o
n
t
é
t
é
au
ss
i util
es
d
a
n
s
l
a
r
ec
h
e
r
c
h
e
d
'
in
fo
rm
a
ti
o
n
e
t l
a
f
o
uill
e
d
e
t
e
x
te.
D
a
n
s
l'
in
gé
ni
er
i
e
l
og
i
c
i
e
ll
e,
l
es o
nt
o
l
o
gi
es fo
urni
sse
nt d
es s
upp
01ts
in
té
r
essa
n
ts
p
o
ur l
e déve
l
o
pp
e
m
e
n
t
l
og
i
c
i
e
l.
Avec
l'
é
m
e
r
ge
n
ce
du W
e
b
sé
m
a
n
t
iqu
e
,
l
es o
n
to
l
og
i
es
j
o
u
e
n
t
un r
ô
l
e c
ru
c
i
a
l d
a
n
s ce
domain
e. E
ll
es
p
e
rm
e
tt
e
nt d
e s
tru
ct
ur
e
r l
es
in
fo
rm
a
ti
o
ns du m
o
d
è
l
e sé
m
a
n
t
iqu
e e
t d
e
su
pp
o
rt
e
r l'
i
n
te
r
o
p
é
r
a
bili
té. Le
W
e
b
sé
m
a
ntiqu
e
d
é
p
e
nd
esse
nti
e
ll
e
m
e
nt d
e
l'
int
ég
r
a
tion d
es
d
o
nn
ées séma
n
t
i
q
u
es q
u
i
d
é
p
e
nd
e
nt d
e
l
a d
i
spon
ibili
t
é
d
'un
e o
n
to
l
o
gi
e [6]
.
Une o
n
to
l
og
i
e est const
i
t
u
ée gé
n
éra
l
ement
de concepts (les différents objets et c
l
asses),
l
eur
s a
ttribut
s (
pr
o
pr
ié
t
és, carac
t
é
ri
s
tiqu
es) e
t l
es
r
e
l
at
i
o
n
s
qui l
es
li
e
nt.
10
Les principales caractéristiques des ontologies sont [7] :
• Formelles : elles sont exprimées dans une langue qui a une syntaxe bien définie et compréhensible par la machine de façon à ce qu'elles puissent être traitées automatiquement par les programmes appropriés. Les ontologies permettent le raisonnement logique et supportent des règles d'inférence. Contrairement au modèle relationnel (ER) et UML qui sont des langages semi-formels, les ontologies peuvent être directement traitées par la machine.
• Lisibles par les humains : autre que les programmes informatiques, les ontologies peuvent être comprises et développées par les informaticiens.
• Vastes : les ontologies couvrent largement les champs de connatssance d'un domaine donné.
• Partageables : les ontologies sont relativement faciles
à
combiner età
fusionner même si elles sont développées séparément. Les ontologies permettentà
différents systèmes hétérogènes de partager diverses informations.Les performances des systèmes basés sur les ontologies dépendent fot1ement de la qualité de la conception du modèle ontologique. Afin d'améliorer la conception de ces modèles, certains chercheurs [8] ont essayé de mettre en place un processus de développement des ontologies ainsi que certains critères de conception.
Pour le processus [8], le développement des ontologies obéit à une méthodologie définissant les étapes et les règles à suivre. Les activités énoncées sont, dans l'ordre : l'étude de faisabilité, 1 'acquisition des connaissances, la spécification des exigences de 1 'ontologie et finalement la définition de cycle de vie de l'ontologie et les ressources humaines nécessaires pour ce projet d'ontologie qu'on appelle la phase de plan.
Concernant les critères de conception des ontologies, Gruber [4] considère qu'ils dépendent de 1 'objectif final de leur développement et propose un ensemble de critères pour qui sont comme suit:
• Clarté: les termes de l'ontologie doivent être définis de manière claire, objective et complète. C'est-à-dire, que la définition des termes doit être efficacement communiquée par l'ontologie et qu'un prédicat doit être défini par des conditions
« n
écessaires et suffisantes».• Cohérence : les ontologies doivent inférer des faits qui sont cohérents avec la définition informelle de 1' ontologie. Les classes et les relations du modèle ontologique doivent suivre une certaine logique.
• Extensibilité : nous pensons que l'extensibilité est l'une des caractéristiques majeures des ontologies. Gruber définit l'extensibilité de l'ontologie comme étant le fait «d'être en mesure de définir de nouveaux termes pour une utilisation spéciale basée sur le vocabulaire d'une ontologie existante sans pour autant avoir recours à la révision des définitions existantes » [Notre traduction].
• Biais d'encodage minimal: les ontologies sont souvent partagées par des sources hétérogènes et dont les langages de programmation diffèrent d'un système à un autre. De ce fait, et afin qu'elles soient compréhensibles et traitables par tous les systèmes, les ontologies doivent être développées indépendamment des langages d'implémentation.
•
Engagement ontologique minimal : l'engagement d'une ontologie doit être minimisé en se contentant juste d'énoncer les principes liés à un domaine donné, et ce en définissant juste les termes essentiels du vocabulaire et en évitant ceux qui sont hors domaine.Les ontologies sont différentes et peuvent être classifiées selon leurs n1veaux de généralité représentés par la Figure 2.1 ci-dessous [9] :
•
•
Les ontologies de haut-niveau (top-leve! ou upper-leve! ontologies) : représentent des concepts généraux et universels, qui ne dépendent pas d'un domaine particulier. Par exemple, une date.
Les ontologies du domaine : sont des ontologies de moindre p01tée que les ontologies de haut-niveau. Elles spécialisent les ontologies de haut-niveau en représentant des concepts liés à un domaine donné comme l'ontologie pour les soins de santé (health care domain ontology).
12
• Les ontologies de tâche:
ell
es spécialise
nt aussi les onto
logies
de
haut-ni
veau
en
décri
vant un
e tâche ou un
événement gé
nériqu
e co
mme
la ve
nte.
• Les ontologies d'application: so
nt plu
s
restreintes
que
les ontologies
du domaine ou
de
tâche et décrivent des co
ncepts
qui
so
nt propres
d'
un domain
e
ma
is aussi d
'
une
tâche particulière.
Ontologies de haut-niveau
Ontologies du domaine Ontologie de tache
Ontologie d'application
Figure 2.1 :
Catégorisation de Guarino pour les ontologies [9].2.5 Langages et outils de conception des
ontologies
Il
existe
plusieurs
langages
pour la
défini
tion des onto
logies do
nt:
RDF
(Resource Description Framework )4,RDFS
(RDF Schema )5,et OWL (Web Ontology Language
t
4
http://www. w3 .org/RDF/ 5
http://www. w3 .org/TR/rdf-schema/ 6
Dan
s
n
o
tr
e
pr
o
j
e
t
,
nou
s avo
ns
choisi
d
e
tr
ava
ill
e
r
avec
le l
a
n
gage
OWL
pour l
es
diff
ére
nt
s
avantages
qu
'
il n
o
u
s fourni
[10]:
•
OWL est
l
e
l
a
n
gage
le plu
s ex
pr
ess
if parmi l
es autres é
n
o
nc
és
précédemment;
•
OWL
n
ous
permet de
raj
o
ut
er
d
es co
ntr
a
int
es
de cardinalité
s
s
u
r
l
es c
l
asses
,
ce
qui
n'
es
t p
as
possible avec
RDF
,
RDF
s et
RDF
a
.
;
•
OWL
s
upp
o
rt
e
l
a
réutili
sa
tion
,
l
e
mapp
age
(fusion, alignement
,
int
ég
r
a
ti
o
n
) et
l
'
inter
o
p
é
rabilit
é
de l
'
ontolo
g
ie
. Ce
qui
est
important dan
s
n
ot
r
e cas
,
pui
s
qu
e
n
o
u
s
e
n
v
i
sageo
n
s
d'
e
nrichir un
e o
nt
o
l
og
i
e ex
i
stante avec ce
ll
e
qu
e
n
o
u
s avo
n
s développés
;
•
JI
existe divers
o
util
s
di
s
p
o
nible
s
p
o
ur l'
int
égra
ti
o
n d
es o
nt
o
l
og
i
es
OWL dans
l
e
développement des a
pplic
atio
n
s
l
ogicie
ll
es tel
qu
e Proté
g
é.
P
o
ur l'
out
il
d
'
é
diti
o
n
des
o
nt
o
l
og
i
es
,
nous avons choisi de travailler
avec
l
e
l
og
i
c
i
e
l
Protégéqui
est
un
é
dit
e
ur libre d
éve
lopp
é e
n Jav
a
par
l
'U
niv
e
r
s
it
é
d
e Sta
nf
or
d
et
qui
est
un
des plu
s
popul
a
ir
es
dan
s
l
e
dom
a
in
e
.
Nous
avo
n
s c
h
o
i
s
i
cet o
util p
o
ur
so
n
ex
t
e
n
s
ibilit
é
,
sa
flexibilité
et
l
a co
n
v
i
via
lit
é
des
interfac
es
d
'
utili
sat
i
o
n.
De
plu
s
,
il
off
r
e
l
a
possibilité de
l
e co
mbin
e
r
avec
un m
ote
ur
d
'
inf
ére
n
ce
.
CHAPITRE III
ÉTAT DE L'ART
3.1 Introduction
La mobilité a pris une place très importante dans la recherche en informatique, et les systèmes Dépendants du contexte suscitent désormais un intérêt majeur au sein de la communauté des chercheurs.
Durant la dernière décennie, de nombreuses infrastructures dépendantes du contexte ont été développées pour gérer ces systèmes. Cependant, ces infrastructures diffèrent beaucoup dans leurs architectures et leurs implémentations. Elles dépendent des exigences des systèmes et du processus d'acquisition, de transformation et de traitement de l'information de contexte. Ces systèmes sont différents non seulement dans 1' architecture, qui est généralement organisée en couches, mais aussi du modèle du contexte adopté.
En se basant sur la méthode d'acquisition de l'information, on peut distinguer trois approches
[1
1]:
l'acquisition directe, l'utilisation du middleware et l'utilisation des serveursde contexte :
a) L'acquisition directe consiste à récupérer directement les informations des capteurs de la pa1t du client mobile. Les pilotes des capteurs sont installés dans le client et les capteurs sont souvent intégrés dans le périphérique.
b) L'approche du middleware est la plus souvent utilisée. Elle se base sur une architecture organisée en couches et permet l'utilisation des méthodes d'encapsulation. Les avantages de cette approche sont certainement la gestion de l'hétérogénéité de l'information et l'extensibilité facile du système.
c) L'utilisation du serveur de contexte étend l'approche du middleware et permet au
client d'accéder à des sources de données distantes et distribuées. Cette structure
permet d'alléger la charge du traitement de l'appareil mobile et d'avoir de meilleures performances pour la gestion du contexte.
D'un autre côté, en se basant sur la coordination des composantes et des processus dans ces applications, on peut distinguer deux approches différentes: le modèle dit de vvidget, et le
modèle de blackboard [12].
Le modèle widget permet aux applications d'accéder aux informations du contexte par
une requête directe à un widget particulier qui constitue un intermédiaire entre une source de
données et une application. Un widget est« une petite application multimédia interactive qui
peut être trouvée dans les appareils mobiles» [13] [Notre traduction]. Ces applications
doivent s'inscrire auprès du widget pour pouvoir accéder à ces informations. Cependant,
l'inscription et la désinscription des applications auprès des widgets est moins robuste et moins flexible en cas de changement rapide du contexte.
Le modèle blackboard permet aux applications d'accéder aux informations du contexte
pas le biais d'une inscription à un élément centralisé qui est le blackboard. Cet élément gère
le traitement interne des informations et notifie l'application quand un événement prédéfini
se produit. Le blackboard est un modèle dont 1 'architecture est centrée sur les données.
L'avantage de ce modèle est la facilité d'ajouter ou échanger des capteurs ainsi qu'une configuration flexible pour les changements dynamiques.
Les infrastructures différèrent aussi par leur modèle de contexte. Le modèle du contexte est une composante majeure des systèmes dépendants du contexte. Elle permet de modéliser, définir et interpréter le contexte. On peut les classer en trois catégories [
1
4]:
1
'approche axée sur l'application, 1 'approche axée sur le modèle et 1 'approche basée sur les ontologies :16
a) Le
modèle axé sur 1 'applicationm
o
d
é
li
se
l
e co
nt
exte
p
o
ur d
es a
ppli
ca
ti
o
n
s
s
p
éc
i
fi
qu
es. C'es
t-
à
-dir
e,
qu
e
l
e co
nt
ex
t
e es
t r
e
pr
ése
nt
é
p
a
r
un
m
o
d
è
l
e
unif
o
rm
e
qui
n
'es
t p
as exte
n
s
ibl
e o
u
a
ppli
ca
bl
e
p
ar
d
'a
u
tres resso
ur
ces.
D
e ce fa
it
,
ce
m
odè
l
e
so
u
ff
r
e
d
'
un
e fa
ibl
e ex
pr
ess
i
v
it
é e
t
off
r
e
un
fo
rm
a
li
s
m
e
limit
é.
b
)
L'approche basée sur le modèlem
o
d
é
li
se
l
e co
nt
ex
t
e e
n
l
e
r
e
pr
ése
n
ta
n
t
p
a
r d
es
m
o
d
è
l
es co
n
cept
u
e
l
s gra
phiqu
es o
u
o
ri
e
nt
és-o
bj
et te
l
s
q
ue
l
e
m
o
d
è
l
e e
n
t
i
té-assoc
i
a
tion
o
u
U
M
L.
L
e
m
o
d
è
le
du
co
n
tex
t
e est
r
e
pr
ése
nt
é e
n u
t
ili
sa
nt d
es
di
ag
r
a
mm
es e
t d
es
b
ases
d
e
d
o
nn
ées
r
e
l
a
ti
o
nn
e
ll
es.
c)
L'approche basée sur les ontologiesutili
se
l
es o
nt
o
l
og
i
es
p
o
ur
l
a
r
ep
r
ése
nt
a
ti
o
n du
co
nt
exte et
p
o
ur l
e
p
a
rt
age
d
es co
nn
a
i
ssa
n
ces e
n
t
r
e
l
es so
ur
ces
di
st
ribu
ées
d
e
d
o
nn
ées
.
Les o
nt
o
l
og
i
es
d
é
fini
sse
nt
l
es co
n
ce
pt
s e
t
l
es
r
e
l
a
ti
o
n
s e
ntr
e e
u
x. E
ll
es
off
r
e
n
t
un
e a
lt
e
rn
at
i
ve
tr
ès
int
é
r
essa
nt
e
p
o
ur
l
a
m
o
d
é
li
sat
i
o
n du
co
n
texte g
r
âce à
l
e
ur
fo
1
ie ex
pr
ess
i
vité,
l
e
ur
exte
n
s
ibili
té faci
l
e et
l
es
t
ec
hniqu
es
d
e
r
a
i
so
nn
e
m
e
n
t q
u
'
o
n
p
e
ut y appliqu
e
r
.
L
es o
nt
o
l
og
i
es
p
e
rm
et
t
e
nt au
ss
i
d
e s
urp
asse
r
l
e
pr
o
bl
è
m
e
d
'
h
étérogé
n
é
i
té
d
es so
ur
ces
d
'
in
for
m
at
i
o
n
.
Ces
m
o
d
è
l
es
u
t
ili
sent
l
e
l
a
n
gage OWL
(Web Ontpolgy Language)7
p
o
ur
l
a
d
é
finiti
o
n d
es o
n
to
l
og
i
es
.
3.2 Quelques modèles existants
N
o
u
s é
num
é
r
o
n
s c
i-d
esso
u
s ce
rt
a
in
es
d
e ces a
r
c
hit
ec
tur
es.
3.2.1 Le Service-Oriented Context-Aware Middleware (SOCAM)
1151
S
O
CA
M
es
t
un
e a
r
c
hit
ec
tur
e
intr
o
duit
e
qui
fo
urnit l
es
in
fo
rm
a
ti
o
n
s
d
e co
nt
ex
t
e a
u
x
se
r
vices mo
bil
es
d
épe
n
dants
du
contexte. SOCAM est
un
e arc
h
itect
u
re en
mi
dd
l
ewa
r
e q
u
i se
b
ase s
ur l
'
a
ppr
o
ch
e o
ri
e
nt
ée se
r
v
i
ces
.
Ce
tt
e a
ppr
oc
h
e
p
e
rm
et a
u
x a
ppli
cat
i
o
n
s d'
in
tég
r
e
r
plu
sie
ur
s services e
n li
g
n
e
p
o
ur l
e
u
rs
d
o
m
a
in
es s
p
éc
i
fi
qu
es
d
e co
n
texte.
Le midd
l
eware offre
l
a possibi
l
ité d'
intégrer et de ré
u
ti
li
ser aisé
m
ent des composa
n
tes
dans
le
système
telles
que
des
nouvea
ux
capteurs
. Il permet aussi de fa
ir
e abstractio
n
de
71 'hétérogénéité des sources de données. Ce système consiste en des composantes organisées
en modules qui permettent d'effectuer des tâches spécifiques. Ces modules communiquent et
interagissent entre eux et permettent d'acquérir les informations du contexte à partir de
différentes sources distribuées, de traiter et d'inférer le contexte en se basant sur un module
de raisonnement et de livrer l'information du contexte aux services du contexte localisés en
haut de l'architecture.
Context-aware application
,_ Cl>r---- - -- - - - (Ë
~--+---c. ,_Context reasoner
Cl);:
~============::::: 1111 • Dataflow
-..···--···-...Internai
context
provider
Figure 3.1 : Architecture SOCAM [15, fig 1]
L'architecture est organisée en trois couches (Figure 3.1) : la couche de captage du
contexte, le middleware et la couche des applications dépendantes du contexte :
La couche de captage est constituée des différents capteurs utilisés pour saisir les données
du contexte. Ces capteurs peuvent être physiques comme un GPS ou un détecteur de
mouvement, ou virtuels comme un service Web.
a) La couche Middleware est constituée des différents modules. Les fournisseurs du
contexte récupèrent les données de différentes sources de contexte constituées des
capteurs physiques et des capteurs virtuels. Le fournisseur du contexte s'enregistre
alors dans un registre de services afin d'être intégré à la plateforme. Les fournisseurs
du contexte peuvent être externes ou internes. Ils permettent notamment de
18
du contexte est un autre module du système qui permet de traiter le contexte à l'aide d'un raisonnement logique. La fonction de ce module est d'inférer le contexte de haut niveau à partir des informations de contexte de bas niveau comme la géo-localisation. Ce module est composé d'un raisonneur et une base de connaissance du contexte. Le raisonneur est constitué des règles d'inférence qui sont prédéfinies par les experts du domaine en forme de logique de premier ordre. La base de connaissances du contexte contient les ontologies du contexte et leurs instances. Le middleware contient aussi une base de données du contexte où sont stockés les ontologies du contexte et un historique des contextes inférés précédemment. Le service de localisation des services est le module qui permet aux clients de localiser les fournisseurs du contexte et les interprétateurs du contexte pour un domaine donné.
b) La couche supérieure est la couche d'applications dépendantes du contexte. Elle contient des serveurs d'applications dépendantes du contexte qui demandent les informations du contexte en s'inscrivant au service de localisation des services.

![Figure 2.1 : Catégorisation de Guarino pour les ontologies [9].](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/23.901.63.837.118.1131/figure-catégorisation-guarino-ontologies.webp)
![Figure 3.1 : Architecture SOCAM [15, fig 1]](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/28.902.86.801.138.747/figure-architecture-socam-fig.webp)
![Figure 3.2: Ontologie du modèle de contexte SOCAM [15 , fig 2]](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/29.901.58.850.576.1145/figure-ontologie-du-modèle-contexte-socam-fig.webp)
![Figure 3.3: Architecture CoBrA (10, fig!].](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/31.901.146.815.234.1050/figure-architecture-cobra-fig.webp)
![Figure 3.4 : Architecture CASS [ 18].](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/33.901.87.763.391.830/figure-architecture-cass.webp)
![Figure 3.5: Modè le de contexte CASS [ 18].](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/34.901.82.850.72.624/figure-modè-le-contexte-cass.webp)
![Figure 3.6 : Architecture Hydrogène [ 19].](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/35.900.63.774.179.766/figure-architecture-hydrogène.webp)
![Figure 3.9 : Modèle d'ontologie Smart-3 [20]](https://thumb-eu.123doks.com/thumbv2/123doknet/3400811.98492/39.900.107.810.125.570/figure-modèle-d-ontologie-smart.webp)