Repérage et identification automatiques de noms de lieux avec variations d'écriture dans des corpus
Texte intégral
Figure





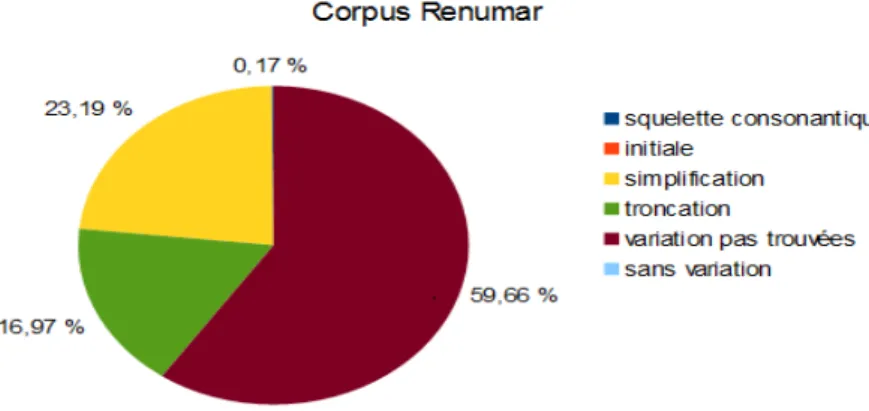
Documents relatifs
Dans tous les cas où la Commission partage sa compétence quant au choix du nom, elle conserve cependant son pouvoir exclusif d’officialisation, c’est-à-dire qu’elle peut refuser
Dans le cadre du classement bipartite mentionné ci-dessus, je consacrerai la première partie de ma présentation à des problèmes posés par les évolutions
*Chalbatore serait devenue par glissement phonétique *Chalbatare, *Chibraltare, puis Gibraltar, bien qu'il n'existe, de l'aveu même de cet auteur, aucun document
Une enquête sociolinguistique menée en 1994 sur le district BAB, réalisée à la demande du Conseil Général des Pyrénées-Atlantiques par l'institut Média-Pluriel-Méditerranée,
Les noms de famille portés par les ressortissants de la nation « nation Juive » de Bayonne sont en règle générale des patronymes espagnols, portugais ou
Bayonne, Menjongo (< suffixe diminutif -ko) autrement de Lartigau, Truhele / Truhelle autrement Petit maison noble de Silhouette. b) noms problématiques, origine
Dans un précédent article 1 nous avons déjà expliqué pourquoi le toponyme Chiberta, un nom désignant un lac d'Anglet, est l'avatar populaire du nom très connu
En effet, bien que les notaires aient toujours tendance à franciser les noms de baptême de leurs clients, surtout les formes populaires, la paroisse d’Anglet offre
