WYNER-ZIV CODING FOR DEPTH MAPS IN MULTIVIEW VIDEO-PLUS-DEPTH
Texte intégral
Figure

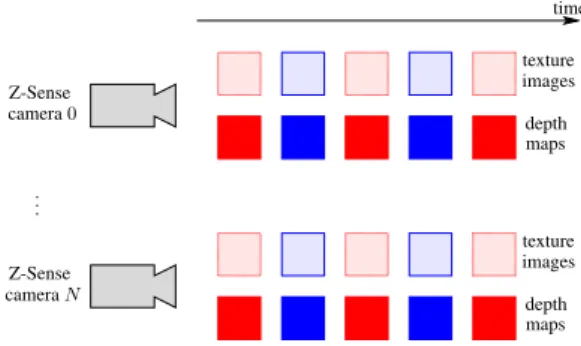
![Table 4. Rate-distortion performance for ballet and breakdancers by Bjontegaard metric [11]](https://thumb-eu.123doks.com/thumbv2/123doknet/12298895.323856/5.892.154.375.209.598/table-rate-distortion-performance-ballet-breakdancers-bjontegaard-metric.webp)
Documents relatifs
Attendu que le premier juge a néanmoins retenu à bon droit la responsabilité de la s.a. Nixdorf a attendu jusqu'au 10 mars 1978 pour proposer le remplacement de
The numerous mechanisms by which the primary tumor induces the production, activation and aggregation of platelets (also known as tumor cell induced platelet aggregation, or TCIPA)
Calcule le pourcentage d'élèves qui ont voté pour chacun de ces deux délégués?. Sachant qu'Éric, qui n'a pas été élu, a eu entre 15 % et 20 % des suffrages, détermine
Ces entretiens ont été recueillis auprès de salariés (cadres, employés et ouvriers) ayant hérité depuis peu et r és idant en milieu urbain, dans de s
Too Cruel, Not Unusual Enough: An Anthology Published by the Other Death Penalty Project. Journal of Prisoners
mention de prix qui entre dans cette rubrique semble d6pass6e• "Bien gSrer son stock, c*est sans doute maitriser les diff6- rentes opdrations que nScessite le passage du livre
Néanmoins, nous allons montrer dans ce chapitre que nous pouvons rendre possible cette séparation en nous basant sur les échantillons à des instants où les hypothèses d’ana- lyse
[r]
