HAL Id: tel-00132471
https://tel.archives-ouvertes.fr/tel-00132471
Submitted on 21 Feb 2007HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de
Contributions en automatique non-linéaire
André Monin
To cite this version:
André Monin. Contributions en automatique non-linéaire. Automatique / Robotique. Université Paul Sabatier - Toulouse III, 2003. �tel-00132471�
Contributions en Automatique Non-Linéaire
A. Monin
Laboratoire d’Analyse et d’Architecture des Systèmes Centre National de la Recherche Scienti¿que
7 Avenue du Colonel Roche - 31077 Toulouse cedex 4 - France Tel: (33) 5.61.33.62.95 / email: [email protected]
Habilitation à Diriger des Recherches soutenue le 8 janvier 2003 devant le jury composé de :
Gérard Authié, Président Michèle Basseville, Rapporteur Michel Fliess, Rapporteur Eric Moulines, Rapporteur
Table des matières.
Introduction.
...5Chapitre 1 Travaux à caractère fondamental.
...71 Représentation des systèmes non-linéaires déterministes. ...7
1.1 Introduction. ...7
1.2 Représentations exponentielles et commandabilité. ...8
1.3 Topologie de chemins et prolongement continu...9
2 Filtrage optimal de Volterra a horizon in!ni. ...11
1.1 Introduction. ...11
1.2 Réalisabilité en dimension !nie de l’estimateur de Volterra. ...12
1.3 Observabilité stochastique. ...13
1.3.1 Observabilité linéaire des systèmes bilinéaires. ...13
1.3.2 Observabilité quadratique...13
1.4 Exemples en simulation...14
1.4.1 Estimation de la variance d’un bruit dynamique...14
1.4.2 Système linéaire non-gaussien. ...14
3 Réalisation et identi!cation en treillis ARMAX. ...16
1.1 Introduction. ...16
1.2 Réalisation en treillis ARMA. ...16
1.3 Identi!cation en treillis ARMA...18
1.4 Exemples en simulation...20
1.4.1 Approximations optimales de !ltres passe-bas idéaux. ...20
1.4.2 Identi!cation de systèmes linéaires...20
1.4.3 Identi!cation adaptative. ...20
4 Filtrage linéaire optimal sur un domaine borné...22
1.1 Introduction. ...22
1.2 Evolution de la densité de probabilité conditionnelle...22
1.3 Termes de normalisation...22
1.4 Expression de l’estimateur...23
5 Filtrage non-linéaire particulaire...24
1.1 Introduction. ...24
1.1.1 Approximation de la densité a priori. ...24
1.2 Procédures de régularisation...26
1.3 Exploitation de la métrique de la vraisemblance...27
1.3.1 Distribution initiale. ...28
1.3.2 Redistribution diffuse. ...28
1.4 Parallélisation de l’algorithme...29
Chapitre 2 Travaux à caractère appliqué.
...321 Détection et discrimination de multi-émissions sur une même porteuse. ...32
2.1 Introduction. ...32
2.2 Distingabilité des multi-émissions...32
2.3 Modélisation du signal modulé...34
2.4 Test d’hypothèse. ...34
2.5 Applications en simulation. ...35
2.5.1 Distingabilité entre 1 et 2 émissions. ...36
2.5.2 Distingabilité entre 2 et 3 émissions. ...36
2.5.3 Extension à d’autres modulations. ...37
2 Traitement optimal du signal LORAN-C...38
2.1 Introduction. ...38
2.2 Modélisation. ...39
2.2.1 Modèle du porteur. ...39
2.2.2 Modèle du signal d’observation. ...39
2.3 Algorithme d’estimation...40
2.4 Résultats sur données réelles. ...43
2.4.1 Contexte des enregistrements...43
2.4.2 Paramètres de l’algorithme...43
2.4.3 Résultats. ...44
2.5 Exploitation sur antenne immergée. ...45
2.6 Conclusion. ...47
Chapitre 3 Prospective.
...491 Développements fondamentaux. ...49
3.1 Identi!cation de systèmes bilinéaires. ...49
3.2 Filtrage à maximum de vraisemblance des systèmes échantillonnés à bruit ponctuel...49
2 Application - Valorisation...49
Références.
...51Mémoires et diplômes dirigés
...57Introduction.
L’objet du présent mémoire est de présenter un aperçu de nos activités de chercheur depuis 1985. Nous avons pris le parti de découper cet exposé en deux parties principales. La première décrit les résultats à caractère fondamental les plus importants à notre sens obtenus au long de cette période alors que la deuxième s’attache à exposer quelques applications industrielles qui mettent en oeuvre ces résultats. Il nous paraît en effet important de ne pas réduire l’activité d’un chercheur à ses travaux purement académiques. La réalisation d’applications industrielles accompagnée de son transfert technologique vers l’industrie fait partie de notre mission et permet de valoriser dé!nitivement la pertinence des résultats théoriques obtenus quand ils sont expérimentés sur données réelles.
On pourra constater que le dénominateur commun de ces résultats réside dans l’intérêt porté aux systèmes dynamiques non-linéaires. Le premier centre d’intérêt a été sur la réalisation des systèmes non-linéaires déterministes où apparaît clairement le rôle fondamental que jouent les algèbres de Lie des champs de vecteurs, que se soit pour des problèmes de commandabilité, d’observabilité ou de réalisation. Les résultats connus à cette époque s’appuyaient essentiellement sur la géométrie différentielle et les développements algébriques de Michel Fliess [16] ne faisaient pas apparaître la série canonique des crochets de Lie des champs de vecteur intervenant en commandabilité. C’est pourquoi nous avons cherché, à partir d’outils mathématiques fondamentaux en algèbre, à construire des représentations explicites de ces systèmes où les séries de Lie apparaissent naturellement en dualité avec les intégrales itérées de l’entrée du système qui en sont les coef!cients.
Nous nous sommes par la suite intéressés aux systèmes dynamiques non-linéaires stochastiques, principalement sous l’angle de l’estimation dynamique : le !ltrage non-linéaire. Les premiers résultats dans ce domaine faisaient apparaître la relative pauvreté des techniques de !ltrage optimal opérationnelles pour les applications. La théorie établit en effet que de tels !ltres ne sont pas en général réalisables en dimension !nie ce qui constitue une obstruction dif!cile à contourner. Cependant, il existait, pour des systèmes analytiques, quelques techniques de type Volterra à horizon !ni (FIR) qui s’appuyaient sur la recherche de !ltres sous-optimaux dans une classe réduite d’estimateurs. L’objection principale qu’on pouvait faire à cette approche réside dans son caractère incomplet qui empêche le !ltre de Kalman d’être le cas particulier linéaire de ces !ltres de Volterra. Nous nous sommes donc appliqués à rechercher des classes de !ltres réalisables en dimension !nie et plus générales que celles-ci. Nous avons abouti à l’étude de fonctionnelles de Volterra à horizon in!ni (IIR) réalisables par des !ltres bilinéaires nilpotents et avons pu montrer que ces !ltres étaient récursivement calculables pour tous les systèmes stochastiques bilinéaires. Une extension aux systèmes généraux analytiques a été proposée par application de méthodes de type particulaires au calcul des paramètres de ces !ltres, méthode mise en oeuvre hors ligne.
L’approche projective que nous avons utilisée pour le calcul des !ltres de Volterra IIR nous a guidés dans la résolution optimale du problème classique de réduction de modèle, dans le cas particulier des systèmes linéaires. En effet, l’approche que nous utilisons peut être considérée comme une forme de réduction entre le !ltre optimal (de dimension in!nie) et le !ltre de Volterra (réalisable). C’est alors que nous avons abordé le problème de réduction optimale de modèle dont nous avons établi qu’il mettait en jeu un calcul héréditaire. A noter que cette technique de réduction peut s’appliquer à la réduction d’un système in!ni-dimensionnel (systèmes répartis, systèmes fractionnaires,...) à un système !ni-dimensionnel. Ces résultats ont été, dans un premier temps, développés en utilisant des réalisations sous forme canoniques pour être, par la suite, étendues aux structures en treillis, célèbres pour leurs qualités numériques. Nous avons donc abouti à la construction d’algorithmes de réalisation optimale de systèmes linéaires sous forme treillis (à partir des fonctions d’autocorrélations de la sortie ou d’intercorrélations entrée/sortie) puis, par utilisation
de critères de type maximum de vraisemblance, à la construction d’algorithmes d’identi!cation optimale (à partir des trajectoires de sortie ou des trajectoires entrée/sortie).
Bien que n’ayant été que partiellement impliqué dans la genèse de la théorie du !ltrage particulaire en 1989 [56], nous avons eu l’occasion de participer pleinement à ses développements. C’est surtout dans le traitement d’applications concrètes à caractère industriel que nous avons pu apporter notre contribution à la mise en oeuvre de cette technique très générale de !ltrage non-linéaire. En particulier, nous nous sommes intéressés à l’optimisation des méthodes de redistributions en faisant apparaître la métrique de la vraisemblance sur l’espace d’état qui permet une meilleure utilisation des particules pour le remplissage de l’espace, que se soit au niveau de la distribution initiale ou au niveau des redistributions. Nous avons également contribué à la parallélisation de l’algorithme particulaire, par nature coûteux en temps de calcul et dif!cilement implémentable dans sa version séquentielle pour une application temps réel.
Nous avons retenu deux applications qui nous semblent d’une part bien illustrer la pertinence des résultats théoriques exposés plus haut et qui démontrent par ailleurs la nécessité de faire évoluer les méthodes dans le contexte des problèmes de l’ingénieur. Il s’agit d’abord de la discrimination de multi-émissions sur une même porteuse, problème ardu soumis par le CELAR (Centre Electronique de L’Armement). Nous avons construit, pour résoudre ce problème, un test de détection original basé sur l’estimation non-linéaire du module des signaux par !ltrage de Volterra IIR. Cette méthode a été appliquée avec succès en simulation puisque nous avons pu, dans certaines conditions, détecter jusqu’à quatre signaux simultanément présents.
La deuxième application que nous présentons est le traitement non-linéaire du signal de radionavigation LORAN-C par le !ltrage particulaire, problème soumis par DCN/Ingénierie. Pour établir les limites de portée du système, il nous a fallu réaliser une modélisation !ne du problème permettant, par une approche globale, de traiter au mieux toutes les informations disponibles. Cette application nous semble tout à fait intéressante dans la mesure où elle a traité des données réelles récoltées au cours de la campagne en mer du «Langevin» au printemps 1997. On a pu ainsi démontrer en quoi l’approche utilisée était saine et !able tout en donnant à l’opérateur des informations sur la qualité des résultats fournis. Ces résultats ont abouti à la réalisation d’une maquette réalisée par la société DIGINEXT pour le compte de la Direction des Constructions Navales (DCN), actuellement embarquée à bord d’un sous-marin .
Chapitre 1 : Travaux à caractère fondamental.
1. Représentation des systèmes non-linéaires déterministes.
1.1. Introduction.
Les premiers résultats fondamentaux d’automatique non-linéaire, notamment en commandabilité et réalisation [24] [34], furent obtenus par une approche géométrique. L’utilisation par Michel Fliess des séries en variables non-commutatives a permis, depuis, une approche algébrique de la représentation entrées-sorties des systèmes analytiques [17] [20] [19] [18]. Un tel système est décrit par une équation différentielle du type suivant :
!! " "#! # $ $ (1)
% " &#! (2)
où ! désigne l’état interne du système étudié (! ! ! ), $ l’entrée du système et % la sortie de celui-ci. La fonction " est supposée analytique en ses deux arguments. On dé!nit alors l’opérateur de transport temporel sur l’intervalle %&# '' comme agissant sur toute fonction analytique de la manière suivante :
"( ! ) # (#! $ " * (# (3)
où ! désigne l’état initial, supposé connu. Si on introduit le champ de vecteur associé à la dynamique :
+ " ,#-$
,! " #!# $$ (4)
il est alors aisé d’établir l’équation différentielle que véri!e l’opérateur de transport, soit : !
* " * + (5)
avec comme condition initiale * " ., l’opérateur identité.
Examinons le cas particulier des systèmes à contrôle linéaire, soit :
" #!# $$ "!/ #!$$ (6)
Associons à chacune des fonctions / #!$ les champs de vecteurs dé!nis de la manière suivante : 0 " ,#-$
,! / #!$ (7)
L’intégration itérée de Picard de l’équation (5) permet de développer l’opérateur de transport dans l’algèbre non-commutative des champs de vecteur sous la forme suivante :
* " . (! ! 0 ---0 . #1 ---1 $ (8)
où les coef!cients de cette série sont les intégrales itérées de Chen [12] [13] [11] construites sur les trajectoires d’entrées : . #1 ---1 $ " " " ---" $ ---$ 23 ---23
Si une telle expression (8) atteint bien l’objectif de représentation entrées-sorties !xé, celle-ci n’est pas minimale dans le sens où il n’y a pas biunivocité entre l’ensemble des intégrales itérées et l’ensemble des trajectoires d’entrées. En effet, il est aisé de montrer que cet ensemble n’est pas algébriquement libre (intégrations par parties).
L’originalité des travaux présentés ici est de donner des représentations explicites de ces systèmes dans l’algèbre de Lie des champs de vecteurs sous forme de l’exponentielle d’une série. La représentation ainsi développée permet de «coder» de manière minimale les chemins d’entrée dans une algèbre de Lie duale dite «intégrale». Ces représentations permettent, entre autres, de prolonger la classe des entrées admissibles des systèmes non-linéaires à celle des mesures grâce à l’introduction d’une topologie sur les chemins d’entrées ad-hoc. En outre, cette approche permet de redémontrer, par la voie algébrique, les théorèmes de commandabilité des systèmes non-linéaires en mettant en évidence de manière explicite comment la combinatoire des chemins d’entrée permet d’exploiter les directions induites par les crochets de Lie des champs de vecteurs.
Ce travail a donné lieu aux publications suivantes : [27] [26] [28] [25] [30] [29].
1.2. Représentations exponentielles et commandabilité.
Les travaux de Chen [12] ont montré que l’exponentielle formelle de la série décrite par l’équation (8) appartient à l’algèbre de Lie engendrée par les champs de vecteur . La loi de l’algèbre de Lie est nommée «crochet de Lie» et dé!nie par :
%0# 4' " 04$ 40 (9)
Théorème 1 L’opérateur de transport s’exprime comme exponentielle d’une série de Lie à
coef!-cients réels dont la structure est la suivante :
* " )*+#! , 5
!
%0 # %0 # ---# %0 # 0 '---'6 #%7 ---7 '$ (10)
où l’ensemble des éléments 6 #%7 ---7 '$ possède une structure d’algèbre de Lie dé!nie par :
% "8 " ,---9# 6 #%8'$ " . #8$
% 6 #%7 ---7 '$ " 6 #%7 ---7 '7 $$ 6 #%7 ---7 '7 $
!
Ce théorème a été établi en utilisant la projection de l’algèbre associative dans l’algèbre de Lie [7] dé!nie par :
"0 # ---# 0 # :#0 ---0 $ " 02 ---02 0 (11)
où 02 désigne l’opérateur adjoint dé!ni par :
02 4 " %0# 4' (12)
et en exploitant les propriétés des algèbres de mélanges [53].
L’utilisation de la propriété générique de la fonction exponentielle permet d’obtenir un autre type de représentation, cette fois comme produit d’exponentielles de champs de vecteurs.
Théorème 2 L’opérateur de transport admet une décomposition factorisée en produits d’exponentielle
* "&$#)*+#4 ; $ (13)
où les éléments 4 forment une base de Hall de l’algèbre de Lie engendrée par les champs de vecteurs'0 # ---# 0 ( [7] et où les paramètres ; sont des réels dé!nis à partir d’un ensemble de
Hall construit sur les indices',# ---# 9( par :
% "8 " ,---9# ; "$ $ 23
% Si ; est le 5-ième élément de l’ensemble de Hall, il s’écrit ; " #; # ; $ et s’obtient par ; " <
"
; !; 23 (14)
où < est une constante ne dépendant que de la structure de 4 .
!
A partir de ces deux théorèmes, il est possible de montrer que les familles de coef!cients des deux séries sont des familles algébriquement indépendantes et que, par conséquent, elles sont en relation biunivoque avec le codage des trajectoires d’entrées. On en déduit immédiatement une nouvelle démonstration (constructive) des théorèmes de commandabilité des systèmes analytiques jusqu’alors obtenus par des considérations géométriques [24].
1.3. Topologie de chemins et prolongement continu.
La classe des entrées admissibles est classiquement restreinte à l’ensemble des fonctions continues par morceaux et à variations bornées. Une telle hypothèse est en effet suf!sante pour assurer unicité et continuité de la solution sous l’hypothèse que les champs de vecteurs soient Lipschitz [16] [21]. Or, on sait que pour les systèmes linéaires, il est possible d’étendre la classe des entrées admissibles à celle des mesures à variations bornées " ceci permet en particulier d’introduire la notion de réponse impulsionnelle.
Pour ce faire, il a été nécessaire d’étudier les conditions de convergence des développements exponentiels présentés plus haut [30].
Théorème 3 La série :
(#! $ " #&$#)*+#4 ; $$(#!$# (15)
converge s’il existe % et = tels que )! $ !) * % * = (où ! désigne un point à l’intérieur du
domaine de convergence des développements de Taylor des fonctions analytiques) et si :
!
#; # )4 ) > ? ( ,= #,$ %
=$ (16)
où ? désigne la dimension du système et où :
)4 ) " -.+ ! #< #= (17)
désigne la norme du champ de vecteur considéré (les coef!cients < étant les termes du développement de Taylor des composantes de ce champ de vecteur).
!
système analytique à un ensemble de fonctions dont les primitives sont à variations bornées par l’introduction d’une nouvelle topologie.
Théorème 4 La fonctionnelle entrée-sortie d’un système analytique à contrôle linéaire est continue
sur l’espace des entrées généralisées pour la topologie sur les chemins induite par la distance @ dé!nie par :
@#$ # $ $ " !#; $ ; # )4 ) (18)
où les termes ; et ; sont les intégrales itérées dé!nies dans le théorème 2.
!
A noter que l’ensemble des résultats de représentation et de topologie présentés a été généralisé aux systèmes analytiques à contrôle non-linéaire [25] [29].
2. Filtrage optimal de Volterra a horizon in!ni.
2.1. Introduction.
Dans de nombreux problèmes pratiques (modèles non-linéaires ou/et non-gaussiens), il peut s’avérer que l’information recherchée sur l’état d’un système dynamique se trouve être non-linéairement liée aux observations, ce qui rend inef!cace, voire sans objet, l’application de la théorie linéaire. Par ailleurs, il n’est pas toujours possible ou désirable, à cause de contraintes de temps réel ou de coût, de mettre en oeuvre la puissance de résolution du !ltrage optimal non linéaire général qui fournit, au prix de nombreux calculs et en général sous forme d’approximation numérique, la densité de probabilité de l’état recherché, conditionnellement aux observations (!ltrage à minimum de variance).
C’est la raison pour laquelle une formulation intermédiaire, investiguée de longue date, consiste à restreindre l’espace de projection hilbertienne que représente le !ltrage optimal classique, à la classe des fonctionnelles polynomial dites de Volterra. Cette approche convient particulièrement aux problèmes non linéaires suf!samment réguliers (modèles analytiques), notamment aux problèmes ayant, en terme de probabilité conditionnelle, une solution unimodale. Comme dans cette formulation on cherche à approcher l’espérance conditionnelle de l’état, celle-ci n’a d’intérêt que si la probabilité conditionnelle possède un seul maximum. Il y a en effet dans ce cas proximité entre la moyenne conditionnelle et le maximum de probabilité a posteriori (l’égalité est atteinte quand la densité de probabilité est symétrique). De nombreuses tentatives ont été faites en ce sens dans le passé. Leurs développements suivirent essentiellement deux voies.
La première approche (Wiener [59] [60], Zadeh [61], Pugatchev [52],...) consiste à considérer les fonctionnelles de Volterra les plus générales. On cherche alors à décrire le système qui engendre les noyaux de cette fonctionnelle, équations que l’on peut considérer comme une extension des équations de Wiener-Hopf du cas linéaire. Malheureusement, dans cette formulation et à l’exception de cas très particuliers, le système qui réalise les noyaux n’est pas de dimension !nie, la solution est donnée sous forme d’équations intégrales, ce qui rend inapplicable une telle méthode, la dif!culté étant du même ordre que celle du problème initial de !ltrage.
La deuxième approche (Kailath [14], Duvaut [15], ...) considère des fonctionnelles à horizon !ni. Le calcul du nombre !ni de paramètres que sont les valeurs des noyaux pour les valeurs possibles de retards retenus est alors naturellement, par construction, !ni-dimensionnel. L’inconvénient majeur de cette technique réside dans le fait que les estimateurs n’utilisent qu’un passé tronqué des observations (!ltres connus sous le nom de !ltres transverses) et que, inversement, le nombre de paramètres nécessaires croit exponentiellement avec la valeur de l’horizon. Notons au passage que le !ltre de Kalman-Bucy n’est pas un cas particulier de ce type de !ltre.
Notre approche se situe à l’intermédiaire de ces deux formulations classiques [46]. Nous utilisons une classe d’estimateurs réalisable en dimension !nie mais à horizon in!ni. Cette classe correspond à l’ensemble des fonctionnelles de Volterra de degré !ni où les noyaux sont séparables, c’est à dire égaux à des sommes de produits de fonctions de chacune de ses variables. Notons que cette restriction aux fonctionnelles à noyaux séparables ne nuit pas à la généralité puisqu’elles sont denses, au sens A , dans la classe des fonctionnelles générales. Il est de plus aisé de véri!er que le !ltre linéaire optimal de Kalman-Bucy est inclus dans cette formulation.
! " " #! # B $
% " & #! $ ( C (19)
où ! désigne l’état interne du système, B et C sont des bruits blancs indépendants et où % désigne le signal d’observation. L’objet est d’estimer une fonction de l’état (#!$ aux vues des observations sur l’intervalle %&# ''. Un tel estimateur est recherché dans la classe des fonctionnelles de Volterra de degré !ni.
Ce travail a donné lieu aux publications suivantes : [6] [46] [37] [46]
2.2. Réalisabilité en dimension !nie de l’estimateur de Volterra.
Une série de Volterra de degré !ni est réalisable par un système bilinéaire si ses noyaux sont séparables, c’est à dire dé!nis comme somme de produits !nis de fonctions de chacune des variables. Elle peut en particulier être réalisée par un système bilinéaire.
Théorème 5 La fonctionnelle de Volterra de degré 7 :
%
( " ! ! ---!D #'# 3 # ---# 3 $% ---% (20)
peut être réalisée par le système bilinéaire nilpotent suivant :
& ' ' ( ' ' ) E " 0 E ( 0 % E " 0 E ( E % ---E " 0 ---E ( E % (21) % ( " E ! La classe d’estimateur étant ainsi déterminée, le calcul des paramètres optimaux est obtenu par projection de la variable à estimer sur cette classe, soit en minimisant la variance de l’erreur d’estimation F%)( $ %() '.
Théorème 6 Les paramètres du !ltre optimal du système bilinéaire du type :
! " + ! ( #G! ( H$B
% " *! ( C (22)
sont récursivement calculables en dimension !nie et véri!ent le système d’équations linéaires suivant :
"8 " &---7#!0 F%E #E $ % ' " F%( #E $ % ' (23)
! On observe alors que pour de tels systèmes, toutes les espérances nécessaires au calcul des paramètres optimaux sont de degré* /7.
2.3. Observabilité stochastique.
Dans la mesure où l’optimalité n’est pas une condition suf!sante pour assurer la convergence et la stabilité de l’estimateur, il est nécessaire d’introduire un concept d’observabilité adapté à ce nouveau contexte.
Dé!nition 1 La fonction (#!$ est stochastiquement observable à partir des moments d’ordre 2 du
signal d’observation si l’application :
I#! $$+ 'F%% ---% #I #!' $'# 3 , ' ( (24)
est bijective. !
2.3.1. Observabilité linéaire des systèmes bilinéaires.
Nous nous sommes limités ici aux systèmes purement bilinéaires (H " &) dans (22). Avec cette dé!nition, on retrouve la condition d’observabilité classique des systèmes linéaires, soit :
Théorème 7 Un système bilinéaire est linéairement observable si le rang de la famille de vecteurs :
'J #' $ ' $* # ' , ' ( " '#+ $ * # 8 , &( (25)
est égal à la dimension du système. J désigne la matrice de transition associée à la matrice dynamique + .
!
2.3.2. Observabilité quadratique.
En ce qui concerne les fonctionnelles quadratiques de l’observation, on s’intéresse à l’estimation de fonctions quadratiques de l’état du type ! ! .
Théorème 8 Un système bilinéaire est quadratiquement observable si l’espace engendré par les
matrices :
'#G ---G $* *J#3 $ 3 $G ---G # 3 , 3 , &# 8 ---8 " &# ,( (26)
(où G " + et G " G par convention) coïncide avec l’espace engendré par les matrices
symétriques de dimension ?.
! Cette famille est de la forme suivante :
'* *# + * *+# G * *G# + * *+ +# G * *+ G# + + * *+ +# ---( (27)
On établit alors le lien entre observabilité et convergence de l’estimateur en introduisant une hypothèse d’ergodicité :
Théorème 9 Si un système bilinéaire est ergodique et quadratiquement observable, l’estimateur de
(#!$ " !! converge au sens de A #K $.
2.4. Exemples en simulation.
2.4.1. Estimation de la variance d’un bruit dynamique.
Considérons un système linéaire pour lequel la variance du bruit de dynamique est inconnue. Pour représenter cette nouvelle variable, il suf!t d’augmenter l’état du système. On obtient alors le système bilinéaire suivant :
*
L " L
! " + ! ( L B (28)
% " *! ( C (29)
où L désigne l’écart type inconnu du bruit de dynamique. On peut alors montrer que M " L L est quadratiquement observable. La comparaison, dans le cas scalaire, entre un !ltre à horizon !ni du type :
+
M " 0 % ( 0 % % ( 0 % ( N et un !ltre à horizon in!ni ayant le même nombre de paramètres (0) :
*
E " 0 E ( 0 % %
M " 0 %M ( E % ( N (30) est illustrée !gure 1. Apparaît clairement sur cette !gure le béné!ce obtenu par utilisation du !ltrage à horizon in!ni. On peut de plus constater que, dans cette simulation, les écarts types théoriques sont conformes aux valeurs prévisibles par le calcul des variances d’erreur a priori.
2.4.2. Système linéaire non-gaussien.
On considère un système linéaire tel que le bruit de dynamique est de type «à sauts» de fréquence O connue. Le test en simulation a été réalisé en construisant successivement les !ltres de degré , (!ltre linéaire de Kalman), /, 1 et 0. Les résultats obtenus en termes d’erreur moyenne d’estimation sont illustrés !gure 2. On constate ici le gain progressif qu’il y a à utiliser des !ltres de degré croissant qui savent exploiter la nature particulière de la distribution. A nouveau, les erreurs expérimentales sont conformes aux valeurs théoriques calculées a priori.
Ecart type (horizon Þni)
Ecart type (horizon inÞni) FIR
IIR
!gure 1 : Estimation de la variance d’un bruit dynamique.
Lin aire Cubique T tra•que Quadr atique
3. Réalisation et identi!cation en treillis ARMAX.
3.1. Introduction.
Pour ses bonnes propriétés numériques, le !ltrage par identi!cation en treillis est familier des traiteurs de signaux. Toutefois, les résultats exacts d’optimalité ne concernent que les !ltres FIR ou, ce qui revient au même, l’identi!cation AR. C’est pourquoi ce treillis classique s’avère une récriture de la régression linéaire au sens des moindres carrés et constitue un !ltre prédicteur calculable en dimension !nie mais dépourvu de "feed-back". Or, il est bien connu que la simple prise en compte des bruits de mesures dans un modèle néanmoins purement AR suf!t à le rendre ARMA. C’est la raison pour laquelle on s’est attaché à la réalisation et à l’identi!cation en treillis ARMA, c’est à dire celle du !ltre prédicteur IIR dont la dif!culté, connue de longue date, réside dans une non linéarité implicite.
L’objet poursuivi ici est donc de construire le prédicteur optimal de dimension !xée sous la forme treillis ARMA quand on connaît soit la fonction d’autocorrélation d’un signal [43] [44], soit une trajectoire de celui-ci [45]. Plusieurs solutions approchées ont été proposées dans le passé [4] [3] [32] [51] [50] conduisant à l’algorithme classique des moindres carrés étendus [57]. Rappelons que ces solutions, par nature, ne sont pas optimales dans le transitoire [35]. Citons de plus les algorithmes récursifs basés sur le gradient stochastique [5] [22] [57] qui présentent, dans certaines situations, des problèmes de convergences, en particulier si la dimension de la réalisation est inférieure à la dimension du système réel qui engendre la fonction d’autocorrélation.
Tout d’abord, en examinant le problème dit de réalisation du prédicteur optimal d’ordre ? !xé à partir de fonctions d’autocorrélation quelconques, il a été montré que ce treillis ARMA de prédiction optimale s’obtient par un calcul héréditaire (c’est à dire à mémoire croissante) mais rapidement convergeant avec l’horizon de corrélation [43].
La prise en compte de corrélations lointaines (l’algorithme de calcul des paramètres s’alimente de l’ensemble des autocorrélations dé!nies sur tout l’horizon temporel considéré) est la caractéristique principale de ce résultat de nature exacte, par opposition à d’autres solutions de nature approchée. Sa supériorité s’est révélée essentielle dans les situations à spectre fréquentiel fortement irrégulier (correspondant à des fonctions d’autocorrélations très étalées). C’est notamment le cas pour la synthèse de !ltres idéaux tels que "passe-bande" ou le treillis prédicteur ARMA, vu en tant que modèle, s’avère approximateur optimal au sens de A #P$ du problème de synthèse.
Ce travail a donné lieu aux publications suivantes : [43] [36] [44] [45].
3.2. Réalisation en treillis ARMA.
Soit % le signal à réaliser par un système linéaire de dimension !nie ? !xée. Une réalisation ARMA de ce processus peut se construire à partir du prédicteur optimal à un pas dé!ni sous la forme suivante :
%
% "!/%% ( N%, (31)
où,% " % $ %% est un bruit blanc. La réalisation du signal s’obtient alors par :
% "!/ #% ( Q $ ( N Q ( Q (32)
Il s’agit par conséquent de projeter le signal à l’instant sur son propre passé ainsi que sur ses prédictions passées, soit :
E " K %% #% # ---# % # E # ---# E ' (33)
où E désigne le prédicteur à un pas du signal et K le projecteur dé!ni au sens du produit extérieur -!#%. " F%!% ' (projection au sens du minimum de variance).
Théorème 10 La réalisation d’ordre ? du prédicteur à un pas d’un signal % sous forme de treillis
ARMA (non normalisé) est obtenue par le système linéaire suivant :
"8 " ,---? $ ,# * R " R $ S E E " E $ #7 $ R avec R " -% $ E E . (34)
où la sortie E est dé!nie par :
E "! /7 0 R (35)
et où les paramètres'7 # S ( sont donnés par : "8 " &---? $ ,#
*
7 " F%R % '#F%R #R $ '$
S " F%R % 'TF%#E $ ' (36) !
La structure induite par ce système est illustrée !gure 3.
+ + -y t zt X1 z1 q0 k0 k0 + + --X2 z2 q1 k1 k1 z-1 + znÐ2 -X nÐ1 knÐ2 z-1 + qnÐ2 knÐ1 z-1 + + ++ + + z0 X0 z-1
!gure 3 : Structure de treillis non normalisé
Le calcul effectif des paramètres du treillis'7 # S ( fait appel à deux types de quantités. Les éléments F%R #R $ ' et F%#E $ ' sont calculables récursivement à partir du système (34) alors que les termes F%R % ' sont héréditaires et font intervenir les autocorrélations du signal d’entrée d’ordre ' : "3 " ,---' $ ,# & ' ' ' ' ( ' ' ' ' ) F%R % ' " -F%% % '$ F%E % ' F%E % ' . F%R % ' " F%R % '$ S F%E % '#"8 " ,---? $ , F%E % ' " #7 $ F%R % '
F%E % ' " F%E % ' ( #7 $ F%R % '#"8 " ? $ /---&
Il apparaît en effet la nécessité de mémoriser toutes les valeurs passées des paramètres
!! " # " $ ! "%%%& " "# pour obtenir les valeurs !nales des espérances '#( ) $ qui permettent de calculer, à travers (36), les valeurs actualisées de!! " # #%
On constate alors que dans cette formulation, la norme des résidus ( décroît fortement avec *. Aussi, a!n d’améliorer encore le conditionnement numérique du calcul du prédicteur à un pas, il est intéressant de normaliser les résidus ( , c’est à dire de les remplacer par des quantités + telles que '#+ %+ & $ ! ,, la matrice identité. La version normalisée de ce treillis, est donnée par :
Théorème 11 La réalisation d’ordre du prédicteur à un pas d’un signal ) sous forme de treillis
ARMA normalisé est obtenue par le système linéaire suivant :
* ! "%%%-" "" !
+ ! %, " . %. & & %+ " . / &
/ ! %," %. & . & %/ " %. & + & (38)
avec : + ! " %'#%) " 0 & $& ' ' %'#%0 & $& # " ) " 0 0 # (39)
où les paramètres!. # sont donnés par :
$* ! '%%%- " "" . ! '#+ / $
et où :
'#%0 & $ !$'#%+ & ) $'#) + $ (40)
! Le calcul des paramètres du treillis est également héréditaire à travers le calcul des éléments '#) + $.
3.3. Identi!cation en treillis ARMA.
Dans une deuxième étape, a été mis au point l’algorithme d’identi!cation en treillis proprement dit, c’est à dire construit à partir des données brutes : fondé sur la détermination du prédicteur optimal au sens du maximum de vraisemblance, cet algorithme est quelque peu différent de ce que laisserait présager l’ergodicité dans l’algorithme de réalisation précédent en remplaçant la fonction d’autocorrélation par les produits de corrélation expérimentaux. A noter toutefois une sensible différence dans le régime transitoire due au traitement de l’initialisation qui préserve l’optimalité transitoire, contrairement à l’équivalent ergodique qui laisse subsister les classiques "effets de bords".
De fait, les projections sont limitées à chaque instant aux variables effectivement pertinentes. Là encore, le calcul d’optimisation des paramètres du treillis est de nature héréditaire en fonction des données. A chaque étape, toute la trajectoire de prédiction doit être mémorisée. Ceci traduit, une fois de plus, la prise en compte !ne des corrélations d’ordre élevé.
Soit!) " $ ! "%%%&# la trajectoire du processus à identi!er. L’objectif est de construire à l’instant & un prédicteur à un pas de ce processus, c’est à dire une trajectoire de prédiction) qui minimise% l’erreur quadratique suivante :
' #%) " %) & $ ! " &
$
%) " %) & (41)
suf!t de remplacer le critère (41) par exemple par : ' #%) " %) & $ ! " 1
$
%) " %) & (42)
Dé!nissons l’opérateur de projection de la trajectoire ( sur la trajectoire 2 par :
3 #( %2 $ ! ' #( %2 & $%' #2 %2 & & 2 " $$ ! "%%%& (43)
La trajectoire de prédiction du processus ) est alors dé!nie par : %
) ! 3 #) %&) "%) " %%%"&) ")% $"$$ ! "%%%& (44) Théorème 12 La trajectoire du prédicteur à un pas d’ordre - d’un signal ) sous forme de treillis
ARMA (non normalisé) est obtenue par le système linéaire suivant :
$* ! "%%%- " "" ! ( ! ( " # 0 0 ! 0 " %! & ( avec ( ! " ) " 0 0 # (45)
où la sortie est dé!nie par :
%
) ! 0 !$ '! ( ( (46)
et où les paramètres!! " # # sont donnés par : $* ! '%%%- " ""
!
! ! '#( 0 $4'#%0 & $
# ! '#0 %( & $%'#( %( & $ (47) !
La version normalisée de ce treillis est donnée par :
Théorème 13 La trajectoire du prédicteur à un pas d’ordre - d’un signal ) sous forme de treillis
ARMA normalisé est obtenue par le système linéaire suivant :
$* ! "%%%- " "" !
+ ! % %," 5 %5 & & %+ " 5 / &
/ ! %, " %5 & 5 & %/ " %5 & + (48)
avec : + ! " %' #%) " 0 & $& ' ' %' #%0 & $& # " ) " 0 0 # (49)
où la sortie est dé!nie par :
% ) ! 0 ! ) $ ' ! ( + * + ' #%0 & $ (50)
et où les paramètres!5 # sont donnés par :
$* ! '%%%- " "" 5 ! ' #+ / $ (51)
! L’extension de cette technique à des systèmes comportant des entrées multidimensionnelles (ARMAX) a été réalisée. L’aspect purement technique de cette extension ne sera pas exposé ici.
3.4. Exemples en simulation.
3.4.1. Approximations optimales de !ltres passe-bas idéaux.
Un !ltre passe-bas idéal est tel que l’autocorrélation du signal de sortie est la transformée de Fourier inverse de la fenêtre indicatrice! , soit :
'#) ) $ ! ()*%+67 $ &
+67 $ , 89 %$ & (52) où 8 correspond à la variance du bruit blanc additif !xant le taux de réjection hors bande. Les résultats obtenus par l’algorithme sont illustrés !gure 4. On constate ici qu’au-delà de - ! "-, l’approximation est quasi parfaite. A noter que la formulation du problème (prédiction à minimum de variance) n’interdit pas les dépassements dans la bande comme l’imposerai une formulation de type gabarits. Ce phénomène peut être apparenté au phénomène de Gibbs bien connu en analyse harmonique. Module Fr quence n = 2 n = 4 n = 12 n = 6
!gure 4 : Approximation d’un passe-bas idéal - n = 2, 4, 6, 12
3.4.2. Identi!cation de systèmes linéaires.
La supériorité de notre approche sur les algorithmes approchés que sont RML (Recursive Maximum Likelihood), ELS (Extended Least Square) et GNBD (Gauss-Newton Block Data) de la toolbox MATLAB a été largement démontrée et trouve une illustration de ses performances !gure 5 sur un système de dimension +.
3.4.3. Identi!cation adaptative.
La mémoire héréditaire assurant l’optimalité théorique de la convergence peut être volontairement tronquée, a!n de parer aux situations de dérives lentes des paramètres du modèle. On a pu ainsi obtenir d’excellentes performances dans la poursuite paramétrique simultanée de raies spectrales SONAR (passif) multiples et rapprochées (décalage des fréquences dû à l’effet Doppler). Sur la !gure 6 sont représentés les densités spectrales de puissance des données (trait pointillé) comparées aux densités spectrales de puissance des systèmes identi!és à différentes étapes du calcul.
HER (-.)
ELS (--) RML (..)
HER (-.)
GNBD (--)
!gure 5 : Comparaisons entre ELS, RML et HER - Ordre n = 4
4. Filtrage linéaire optimal sur un domaine borné.
4.1. Introduction.
Il est des situations où une variable d’état est, par nature, limitée à un certain intervalle. On peut montrer alors que si le modèle de cette variable est linéaire gaussien, l’estimateur optimal de celle-ci est calculable récursivement en dimension !nie [47].
Supposons qu’un paramètre !xe : & " soit linéairement observé par un processus ) & " entaché d’un bruit blanc additif gaussien ; . Le modèle linéaire correspondant, en prenant un pas d’échantillonnage unitaire, est alors :
: ! : (53)
) ! <: , ; (54)
Prenons l’hypothèse supplémentaire que ce paramètre est astreint à rester dans un domaine ' & " . Plus précisément, considérons que la densité de probabilité de : à l’instant initial est une distribution gaussienne "tronquée" sur le domaine, soit :
. %:& ! "
= ! > (55)
où ! est la fonction indicatrice du domaine ' (" si : & ', ' sinon). Le coef!cient de normalisation = est tel que :
= ! !
> ?: (56)
Ce travail a donné lieu à la publication suivante : [48].
4.2. Evolution de la densité de probabilité conditionnelle.
Intéressons-nous à la densité de probabilité de l’état : conditionnellement aux observations 2 ! !) " %%%" ) #. On peut alors montrer que cette densité de probabilité est également une gaussienne tronquée de la forme (55).
Théorème 14 Si la densité initiale d’une variable aléatoire est de la forme (55), alors cette structure
est conservée dans le temps et on a :
.%:%2 & ! "
= ! > (57)
où : et 3 sont respectivement les moyennes et variances du !ltre de Kalman de l’état : et où :
= ! !
> ?: (58)
!
4.3. Termes de normalisation.
On constate que le calcul de la vraisemblance de la trajectoire d’observation fait appel aux termes de normalisation = de la densité de probabilité gaussienne tronquée. Si la variable "tronquée" est scalaire, ces coef!cients peuvent être calculés à partir de la fonction "erreur" dé!nie par :
./0%:& ! (" -6
!
> ?@ (59)
Supposons que le domaine' soit dé!ni par :
' ! !: & ," %: " %%%" : & & " # (60)
où : désigne la *-ième composante du vecteur : & " et où , ! #A" B$ représente l’intervalle auquel la première composante du vecteur est assujettie. On peut alors montrer que le terme de normalisation s’écrit : = ! %./0%"B" 1: 3 &" ./0%A"" 1: 3 &&#%-6& %3 % (61) 4.4. Expression de l’estimateur.
L’estimateur$: de l’état : à l’instant & s’obtient simplement en calculant la moyenne de sa densité de probabilité, soit : $ : ! 1: " % 3 -6 > " > ./0%( &" ./0%( & (62) On constate à l’examen de la formule (62) que l’estimateur "tronqué" de l’état s’obtient en corrigeant l’estimateur linéaire classique d’un terme proportionnel à une sorte de distance entre l’estimateur de Kalman 1: et l’intervalle #A" B$.
5. Filtrage non-linéaire particulaire.
Bien que n’ayant pas participé directement à la genèse du !ltrage particulaire en 1989 [56], j’ai eu l’occasion de participer pleinement à son développement. Les évolutions apportées à l’algorithme initial de !ltrage particulaire ont été le plus souvent inspirée par le traitement d’applications (GPS [9] [10], LORAN-C [42]). Ces travaux ont essentiellement porté sur les procédures de redistribution, de réalisation de la distribution initiale des particules et sur la parallélisation de l’algorithme de !ltrage particulaire [8].
5.1. Introduction.
Considérons le modèle à temps discret très général non linéaire suivant :
: ! 7 %: " C & (63)
) ! D %: & , ; (64)
où C et ; sont des bruits blancs (non nécessairement gaussiens). La technique de résolution particulaire repose sur la reconstruction de la densité de probabilité de l’état à estimer :
conditionnellement à l’ensemble des observations 2 ! !) " %%%" ) # accumulées sur l’intervalle de temps #'" &$, soit la densité de probabilité .%:%2 &. Cette densité est approchée par une mesure ponctuelle du type :
.%:%2 & )!&E 9 %: & (65)
où 9 %: & désigne la mesure de Dirac au point support : . C’est une approximation faible de cette densité que nous construisons ainsi, la convergence ayant le sens suivant :
$F 2 " "* "" 3)4 &E F%: & ! '#F%: &%2 $ (66) 5.1.1. Approximation de la densité a priori.
Dans un premier temps, on cherche à construire une approximation par une mesure ponctuelle du type (65) de la densité a priori .%: &. Pour ce faire, on réalise un tirage de G particules conformément à la distribution initiale .%: &. On a alors une approximation de cette densité par :
.%: & )!& "
G9 %: & (67)
où : désigne la position de la particule *. Pour obtenir une approximation de .%: &, on fait évoluer chacune des particules indépendamment et conformément au modèle de prédiction de l’état, c’est à dire (63). Les particules évoluent donc selon :
: ! 7 %: " C & (68)
où C est obtenu par tirage aléatoire conforme à la loi supposée connue du bruit C . Après & itérations de ce type, on obtient une approximation de la densité de probabilité a priori par :
.%: & )!& "
La !gure 7 illustre cette évolution où les traits pointillés représentent la trajectoire de chaque particule. p x! "t p x! 0" t xt x0
!gure 7 : Evolution a priori
On peut alors montrer, en utilisant la loi des grands nombres, qu’il y a convergence faible de l’approximation ponctuelle quand le nombre de particules tend vers l’in!ni.
5.1.2. Approximation de la densité conditionnelle.
La probabilité conditionnelle peut s’obtenir, en utilisant récursivement la règle de Bayes : .%:%2 & )!&E 9 %: & avec E ! '.%)%: &%%%.%) %: &
.%) %: &%%%.%) %: & (70) La !gure 8 illustre la construction de la densité de probabilité conditionnelle où les #èches représentent les poids des particules.
Dans l’hypothèse où le bruit blanc d’observation ; est gaussien de variance 8, les poids peuvent se calculer explicitement. En effet, on a :
.%)%: & ! ("
-68> (71)
La vraisemblance de la trajectoire s’obtient alors par : + !""
-&
%) " D(: &) 48 (72)
Les poids peuvent alors s’obtenir par :
E ! '>
p x! t Y0t"
p x! 0"
t
xt x0
!gure 8 : Evolution de la densité conditionnelle et l’estimateur particulaire en calculant la moyenne de cette densité, soit :
$
: !&E : (74)
L’inconvénient majeur la technique telle qu’elle a été exposée ici réside dans son défaut de convergence uniforme. En effet, pour un nombre de particules donné, lorsqu’on accumule les observations, on peut montrer qu’il y a dégénérescence de la représentation dans le sens où le rapport de poids entre deux particules distinctes diverge en moyenne. Ainsi, au bout d’un certain temps, une particule, et une seule a un poids qui temps vers " alors que toutes les autres ont un poids quasi nul et deviennent, par conséquent, inutiles à la représentation. Par ailleurs, si le système est instable, le nuage de particules a tendance à s’éparpiller dans l’espace d’état. La représentation de la probabilité devient alors dégénérée. Plusieurs procédures de régularisation ont été envisagées.
5.2. Procédures de régularisation.
Pour pallier ce défaut de convergence uniforme de l’estimateur particulaire vers l’estimateur optimal, il est nécessaire de modi!er l’algorithme de base en réalisant périodiquement une redistribution des particules conformément à la densité de probabilité obtenue. Ainsi, les zones de l’espace d’état qui comportent les particules les plus probables se voient renforcées par un nombre de particule plus grand après redistribution au détriment des zones moins probables. L’objectif des redistributions est en effet de maintenir la représentation de la mesure de probabilité conditionnelle aux observations proche d’une représentation où tous les poids sont peu différents de "4G , ceci a!n de se maintenir dans le cadre d’application de la loi des grands nombres. Il s’agit donc de poursuivre deux objectifs : minimiser la distance entre représentations de la densité de probabilité avant et après redistribution" maintenir les poids proches de "4G .
l’algorithme en tirant aléatoirement les positions des particules!%: " E &" * ! "%%%G# conformément à la loi obtenue et à réinitialiser les poids des particules à "4G [23]. L’avantage de cette technique est de garantir la convergence uniforme de l’algorithme au prix d’un nombre prohibitif de particules. En effet le "bruit" introduit lors des redistributions purement aléatoires impose l’utilisation en pratique d’un nombre très élevé de particules.
A!n de limiter les effets perturbateurs de redistributions trop fréquentes, on a alors introduit un critère de déclenchement des redistributions à base de quanti!cation des particules dites "ef!caces" [54] [33].
Nous avons alors introduit une procédure de redistribution déterministe de type fractionnaire : on affecte autoritairement à chaque position : le nombre H%E G&, où la fonction H désigne la valeur arrondie à l’unité. Au terme de cette procédure, il peut y avoir dé!cit ou bien excédant de particules. Dans le premier cas, on affecte le nombre requis de particules aux positions où la différence E G " H%E G& I ', ceci par ordre décroissant de cette différence. Dans le cas où il y aurait excédant, on retire les particules là où la différence E G " H%E G& J ', toujours par ordre décroissant. A!n de minimiser la distance entre représentation de la distribution avant et après redistribution, les poids des particules redistribuées ne sont pas !xés à "4G mais à E 4- où - est le nombre de particules alloué à la position : . Cette redistribution est déclenchée quand au moins une particule a un poids inférieur à "4-G (H%E G & ! ') et au moins une particule a un poids supérieur à 54-G (H%E G & ! -). A noter que si le rapport signal/bruit du système est faible, un nombre réduit de particules est redistribué à chaque étape et la plupart de la représentation particulaire est inchangée par la procédure. Cette technique nous semble allier les deux avantages des méthodes précédentes : maintenir à chaque étape les poids proches de "4G tout en évitant l’introduction de trop fortes perturbations dans le processus de !ltrage en permettant une intégration des observations sur un horizon qui s’adapte automatiquement aux conditions d’observabilité.
De plus, dans l’objectif de parallélisation de l’algorithme, nous avons introduit un type de redistribution qui accepte une certaine #uctuation du nombre total de particules utilisées pour l’estimation tout en assurant une stabilité de ce nombre autour de la valeur G désirée. Soit G le nombre de particules à l’instant &. Si on décide de redistribuer le réseau de particules à cet instant, on affecte autoritairement à chaque position : le nombre H%E G &, indépendant de G . On peut alors montrer que la variance du nombre de particules autour de la consigne G tend vers ' quand le nombre de particules tend vers l’in!ni.
5.3. Exploitation de la métrique de la vraisemblance.
Dans une mise en oeuvre pratique, il est crucial d’utiliser au mieux l’ensemble des particules allouées à une application dans un simple souci d’économie de temps de calcul. Une des voies possibles consiste à distribuer initialement le réseau de particules conformément aux sensibilités directionnelles de l’état du système. En effet, pour un problème donné, certaines directions de l’espace d’état du système sont plus «observables» dans le sens où, pour un nombre d’itérations donné, la variance de l’estimateur dans cette direction décroît plus vite que pour des directions orthogonales à celle-ci.
Si on considère le problème d’observabilité intrinsèque du modèle (63) pour lequel le bruit blanc de dynamique est nul, on peut exprimer cette vraisemblance en fonction de la condition initiale par utilisation de la fonction de transition du système, soit :
+ %: & !""
-&
où K%&" :& ! 7 %K%&" "" :&" '& et K%'" :& ! :.
Intéressons-nous à présent aux variations de cette vraisemblance autour de son maximum, c’est à dire au voisinage d’une trajectoire d’observation pour laquelle la vraisemblance est nulle : $$" ) ! D %K%$" : &&. L’objectif est ici de calculer le paraboloïde local approximant + %: & autour de son maximum. Pour ce faire, il suf!t d’en calculer le Hessien :
< %: & ! L + %: & L: ! & LD %K%$" : && L: LD %K%$ " : && L: (76)
L’approximation locale de la vraisemblance prend alors la forme quadratique suivante :
+ %: & )! : < : (77)
Réalisons la diagonalisation de la matrice < %: &. Dans la base des vecteurs propres, l’approximation locale de vraisemblance prend la forme suivante :
+ %: & )!&M %0 & (78)
où 0 désigne les coordonnées du point : dans cette nouvelle base.
Une ligne de niveau de cette approximation locale de la vraisemblance peut alors être vue comme une hyper-ellipse dont les axes sont portés par les directions propres de la matrice < %: & et dont la longueur des demi-axes est proportionnelle à "4(M . On réalise ainsi l’approximation locale de la vraisemblance par une fonction quadratique, ce qui est équivalent à considérer une approximation locale de la probabilité par une distribution gaussienne.
5.3.1. Distribution initiale.
L’exploitation des sensibilités directionnelles pour le remplissage initial de l’espace consiste à construire une grille locale dont les directions correspondent aux directions propres de la matrice de sensibilités < %: & et dont les dimensions sont proportionnelles à "4(M . Ainsi, la densité des particules sera plus forte dans les directions pour lesquelles l’estimateur est le plus sensible.
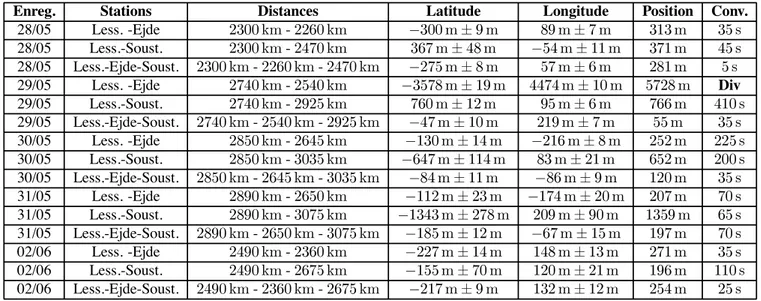
Cette procédure a été appliquée avec succès au traitement sur données réelles du signal LORAN-C en radionavigation [47] [39] [42]. Dans ce problème, la sensibilité de la détermination de la position du récepteur dépend de la géométrie de l’ensemble des stations observées comme l’illustre la !gure 9. Le remplissage résultant de l’utilisation des stations Ejde et Lessay est représenté !gure 10.
5.3.2. Redistribution diffuse.
Comme il a été souligné plus haut, le développement quadratique de la vraisemblance donne une approximation locale de la probabilité par une distribution gaussienne. Au moment d’une redistribution, on affecte en chaque position retenue un nombre de particules donné autour de la position retenue. Dans le but d’optimiser l’utilisation des particules, il s’avère intéressant de réaliser une diffusion conforme à cette distribution gaussienne. On connaît, au moment de déclencher une redistribution, quelle était la topologie du nuage de particules au coup précédent à travers le rectangle élémentaire dont est constituée la grille. Si une particule doit se multiplier, celle-ci doit chercher à remplir l’espace inexploré par le nuage au coup précédent. La tache de redistribution doit donc respecter les directions propres de la matrice de sensibilité et les écarts types de diffusion doivent égaler la dimension des pas de la grille précédente a!n de couvrir au mieux les intervalles laissés inexplorés.
!gure 9 : Analyse des sensibilités -10 -5 0 5 10 -10 -8 -6 -4 -2 0 2 4 6 8 10 km k m
!gure 10 : Exemple de distribution initiale.
lignes de position distantes d’une longueur d’onde, distance correspondant à une pseudo-ambiguïté.
5.4. Parallélisation de l’algorithme.
Les impératifs de traitement en temps réels des applications sont souvent dif!cilement compatibles avec une mise en oeuvre séquentielle de l’algorithme particulaire. En effet, malgré l’utilisation
de procédures qui visent à minimiser le nombre de particules, celui-ci peut néanmoins demeurer prohibitif.
Par nature, l’algorithme particulaire est hautement parallélisable. En effet, chaque particule à une évolution propre, indépendante des évolutions du reste du réseau. De même, le calcul de la vraisemblance de chaque particule peut se faire, au terme de normalisation près, à partir de la seule donnée qu’est le signal d’observation.
L’implantation parallélisée de l’algorithme peut donc être structurée de la manière suivante [8] : chaque processeur . traite un sous-ensemble de particules!: " * ! "%%%G # et traite localement l’exploration de l’espace par tirages aléatoires du bruit de dynamique. De même, chaque processeur calcule la vraisemblance (non normalisée) de chaque particule ainsi que l’estimateur local (non normalisé) et son terme de normalisation local, soit :
+ !"" -& %) " D%: && 4N (79) $ : !&> : (80) E !&> (81)
Une tâche maître se charge de recueillir chacun des termes: et E a!n de calculer l’estimateur$ global, soit : $ : ! ' $: ' E (82)
On constate que dans cette phase les quantités échangées entre processeurs se limitent à quelques réels (de l’ordre de la dimension du système) ce qui est très favorable aux performances de la version parallélisée qui peut, de ce fait, atteindre des accélérations quasi linéaires. A noter que, de plus, le calcul de l’estimateur peut se faire de manière périodique avec une période supérieure à la période d’échantillonnage.
Le traitement de la procédure de redistribution est légèrement plus délicat à traiter. L’utilisation de redistribution de type aléatoire proportionnel nécessite un échange complet des positions de particules entre processeurs, procédure à éliminer étant donné le nombre prohibitif des valeurs à échanger.
L’utilisation de redistribution de type aléatoire fractionnaire limite largement le nombre
d’échanges nécessaire. En effet, chaque processeur n’a besoin, pour calculer le nombre de particules à redistribuer sur une position donnée, que des termes de normalisation locale des autres processeurs (quelques réels). Cependant, le nombre de particules ainsi calculé diffère, en général, du nombre de particules souhaité. Si on souhaite maintenir le nombre de particules par processeur strictement !xe, il est alors nécessaire d’échanger les reliquats a!n de réorganiser la répartition entre processeurs.
L’utilisation de redistribution de type déterministe permet d’annuler totalement les échanges de positions de particules au prix d’une #uctuation du nombre de particules alloué. Cette procédure devient la plus performante si le coût de communication entre processeur est élevé ou si les redistributions doivent intervenir fréquemment.
Chapitre 2 : Travaux à caractère appliqué.
Nous présentons ici deux applications ayant fait l’objet de contrats de recherche qui nous ont donné l’occasion de mettre en oeuvre les différents outils théoriques développés précédemment. La première est une application du !ltrage polynomial de Volterra au test de détection multi-hypothèses. Il s’agit de la détection de multi-émissions sur une même porteuse associée à la recherche du nombre de celles-ci. La suivante est une application du !ltrage non linéaire pour la radionavigation et porte sur le traitement optimal du signal LORAN-C.
1. Détection et discrimination de multi-émissions sur une même porteuse.
1.1. Introduction.
Cette étude a été réalisée dans le cadre d’un contrat avec le Centre Electronique de l’Armement (CELAR) de Rennes, projet Clémentine [38] [49]. Le problème qui nous a été soumis est celui de la détection de la présence simultanée de plusieurs émissions de télécommunication sur une même porteuse et, le cas échéant, du décompte de celles-ci. Le signal analysé est en effet issu d’un satellite d’écoute qui peut, du fait de sa position, couvrir un domaine dans lequel se trouvent plusieurs émetteurs calés sur la même fréquence. Les types de modulation envisagés sont les modulations de phase, de fréquence et d’amplitude, de natures numériques ou analogiques.
La démarche retenue pour résoudre le problème de détection de multi-émissions comporte les étapes suivantes :
+ Réaliser l’inventaire de tous les types d’émissions attendues sur une même porteuse. Cette étape conduit à l’établissement d’une liste des différentes hypothèses qui devront être testées. En l’occurrence, cette liste doit non seulement distinguer les différents types de modulation rencontrés mais également la conjonction de ces modulations entre elles. Par exemple, pour un type de modulation donné, il faut envisager la présence d’une, de deux, trois,... modulations du même type présentes simultanément.
+ Modéliser précisément les différentes hypothèses traitées. Cela consiste à décrire les processus d’observation dans chacune des situations par l’analyse de leurs densités de probabilité ou de leurs fonctions caractéristiques.
+ Analyser la distingabilité des différentes hypothèses retenues à partir de l’analyse des caractéristiques statistiques d’ordre élevé des signaux envisagés.
+ Etablir un critère de décision et véri!er l’ef!cacité de celui-ci.
La mise en oeuvre complète d’un test de détection a été développée dans le cas particulier de la recherche du nombre de modulation de phase présentes dans un signal. Celui-ci a été construit à partir d’un !ltre quadratique de Volterra de la puissance instantanée du signal.
Ce travail a donné lieu à la publication suivante : [49].
1.2. Distingabilité des multi-émissions.
Pour chacun des types de modulation envisagés, nous considérerons l’hypothèse < comme correspondant à la présence simultanée de * modulations de ce même type. Le signal observé, représenté par le nombre complexe ) , sera alors dé!ni, sous chacune des hypothèses, selon :
< 2 ) ! O , ; !&: , ; (83)
où ; désigne le bruit blanc additif de sortie dé!ni par :
; ! ; , P; (84)
; et ; sont des bruits blancs gaussiens indépendants de variance 8 et où O désigne le signal non bruité comportant les * modulations : présentes potentiellement dans le signal observé.
L’objet est de déterminer quels sont les moments de probabilité du signal qui rendent le paramètre * (nombre de modulations) observable. Le calcul des différents moments de probabilité du signal d’observation révèle qu’il est nécessaire de monter jusqu’à l’ordre + pour faire apparaître une dépendance de la distribution avec le nombre * de modulations. Plus précisément, l’indépendance supposée entre les signaux : permet d’établir qu’en régime stationnaire et pour une somme de signaux modulés en phase ou en fréquence, on a la relation suivante :
'#**O ** $ !&'#**: ** $ , -&'#**: ** $'#**:** $ (85)
Supposons que les différents signaux : aient la même distribution. Notons Q le rapport entre moments du deuxième et quatrième ordre :
Q ! '# * *: ** $
'#**: ** $ (86)
On peut alors montrer que :
'#**O ** $ ! Q , -%*" "& * %'#
*
*O ** $& (87)
La distorsion de la distribution de probabilité du module du signal%O % en fonction du nombre de signaux présents * est donc mise en évidence par les statistiques d’ordre + du signal. C’est cette propriété que nous utiliserons pour construire le test de détection du nombre de signaux. Cette propriété, visible "à l’oeil nu" en absence de bruit blanc additif, est illustrée !gure 12. On constate que le nuage de points correspondant à - modulations est moins dilué autour de la moyenne du module carré (unitaire en l’occurrence) que celui correspondant à 5 signaux.
!gure 12 : Dispersion du module autour de la moyenne pour 2 et 3 signaux présents Plus précisément, le !ltre optimal du module carré du signal prenant en compte les moments de probabilité du signal de degré inférieur ou égal à +, celui-ci sera différent pour chacune des hypothèses sur le nombre de signaux présents. Par conséquent, les innovations des différents !ltres
construits sous chacune des hypothèses s’écarteront plus ou moins de leurs valeurs théoriques selon que l’hypothèse est correcte ou non.
Le principe de distingabilité retenu repose donc sur l’estimation du module carré du signal, sous chacune des hypothèses, suivie de la comparaison entre les innovations expérimentales et leurs valeurs théoriques. L’hypothèse retenue sera alors celle pour laquelle l’innovation expérimentale est la plus proche de sa valeur théorique.
1.3. Modélisation du signal modulé.
Selon de type de modélisation considéré, les systèmes obtenus seront soit bilinéaires, soit polynomiaux. Soit : le signal démodulé (après suppression de porteuse). Pour une modulation de phase, le modèle de : est bilinéaire du type suivant :
: ! : C (88)
où : représente l’état du système (complexe) et C est un bruit blanc décrivant l’incrément de phase entre deux échantillons.
Pour une modulation de fréquence, on obtient le modèle non-linéaire suivant : +
0 ! 0 %"" 6G & , C 6G
: ! : 0 (89)
où 0 désigne l’incrément de phase du signal, celui-ci ne pouvant plus, dans ce contexte, être considéré comme un bruit blanc. Le processus 6G représente l’incrément d’un processus de comptage qui régit les sauts de phase alors que C est un bruit blanc de type gaussien.
En!n, une modulation d’amplitude peut être modélisée selon : +
0 ! 0
: ! : %"" 6G & , 0 C 6G (90) où 0 est un nombre complexe de module unitaire, initialement équi-distribué sur le cercle de rayon unité et représentant le déphasage initial entre la porteuse et l’oscillateur de démodulation local, 6G est le processus de comptage qui gouverne les sauts d’amplitudes et C est un bruit blanc de type gaussien.
1.4. Test d’hypothèse.
Comme nous l’avons souligné plus haut, le test de détection repose sur la construction du !ltre du module carré du signal conditionné par chacune des hypothèses «nombre de signaux présents». Le !ltre retenu est un !ltre polynomial à horizon in!ni de dimension - et de degré -. En effet, il est aisé de véri!er que dans le cas d’une multi-émission, la dynamique de la variable 7 ! %O % est de dimension - car elle fait appel à la seule variable supplémentaire :
8 !& **: ** (91)
On peut alors montrer que, les variables à estimer étant réelles, le prédicteur à un pas polynomial de Volterra du vecteur #7 " 8 $ se réduit à la forme suivante [46] :
+
. ! H . , H )
0 ! H 0 , . ) , . ) (92)
où ) désigne le signal (complexe) d’observation () son conjugué) et . l’état interne linéaire du !ltre. A noter que les paramètres H sont également réels. Ceux-ci sont calculés récursivement,