Identification de la relation sémantique sous-jacente des noms composés
158
0
0
Texte intégral
Figure
+7


Outline
Description des corpus utilisés
Les patrons et leur expression régulière
Regroupements de patrons
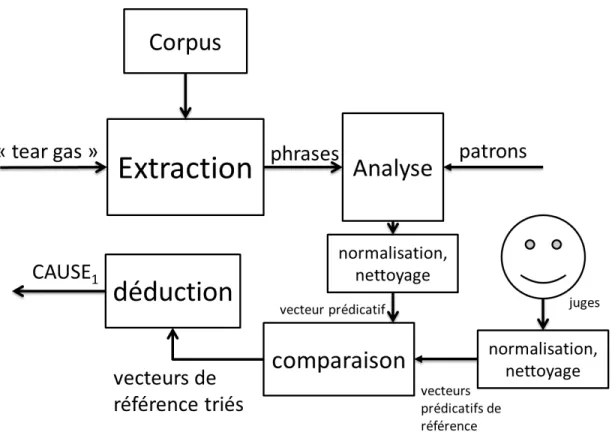
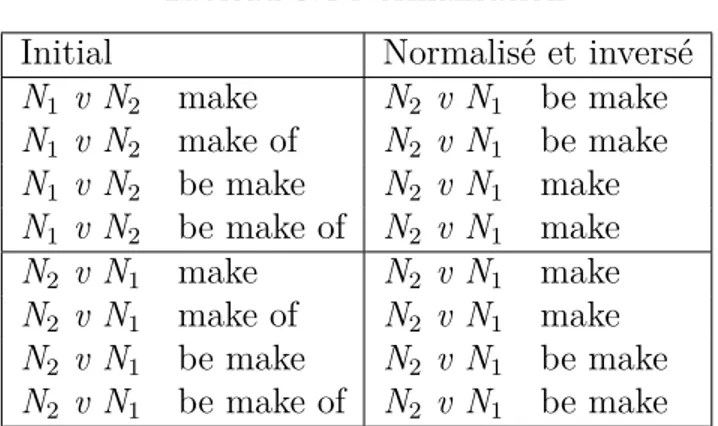
Normalisation et nettoyage des éléments prédicatifs
Identification de la relation
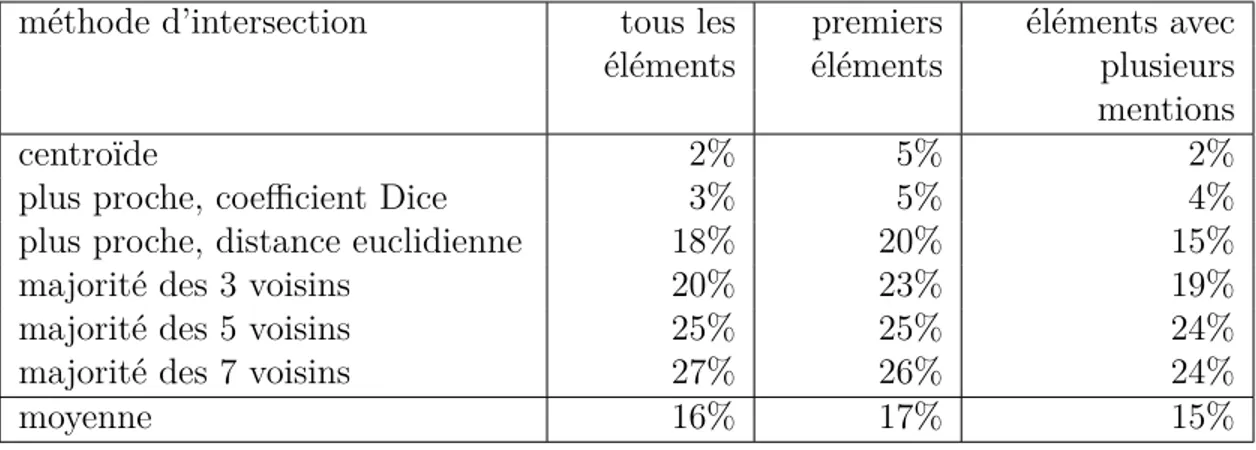
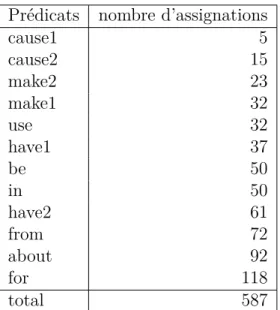
Résultats aux différentes méthodes d’évaluation
Approche par synonyme
Analyses supplémentaires
Conclusions
CONCLUSION ET TRAVAUX FUTURS
Documents relatifs