Autour de l'évaluation numérique des fonctions D-finies
223
0
0
Texte intégral
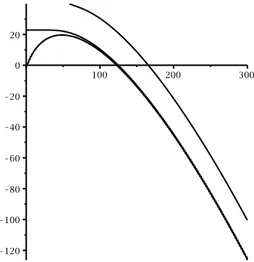
Figure

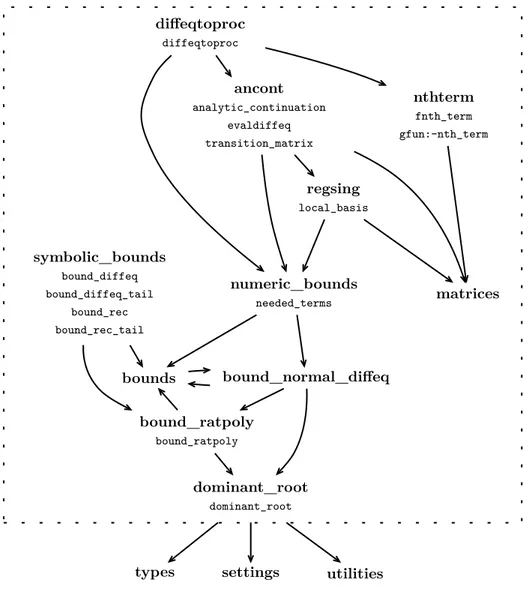


+7



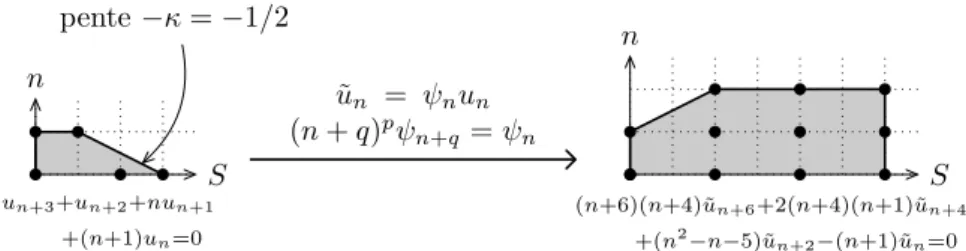

Documents relatifs