Plus-value hydrologique du post-traitement de la prévision météorologique d'ensemble
94
0
0
Texte intégral
Figure
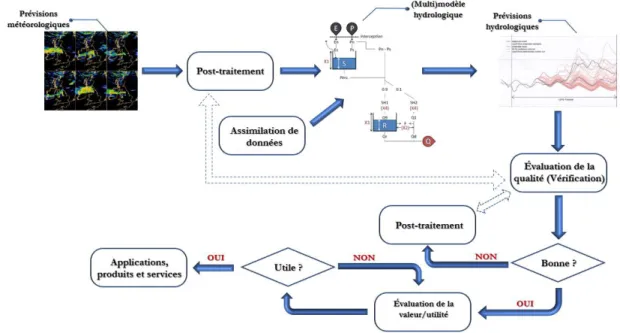



+7
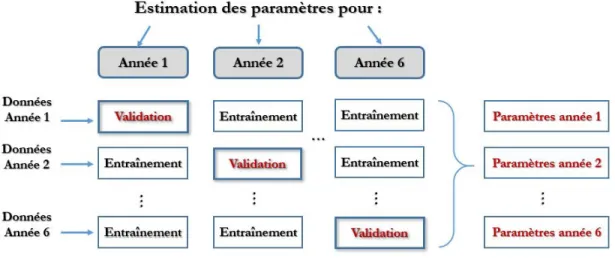
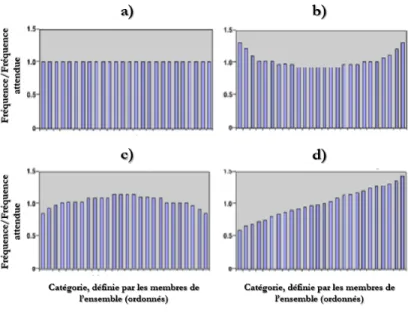

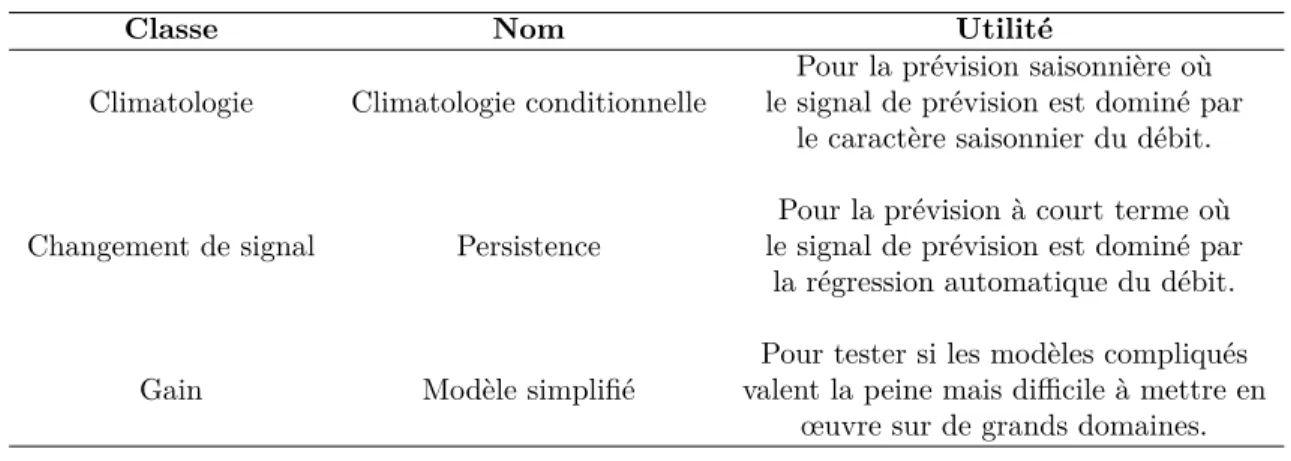
Documents relatifs
