Reducing timing interferences in real-time applications running on multicore architectures
13
0
0
Texte intégral
Figure
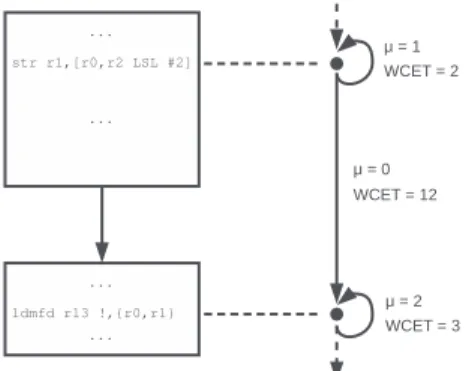
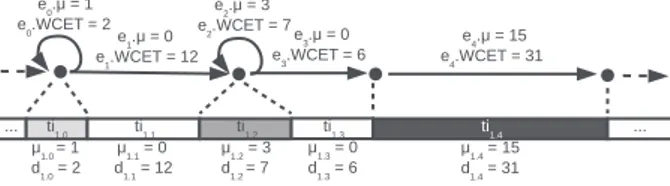

Documents relatifs