Applying quantum machine learning approach for detecting chaotically generated fake usernames of accounts
Texte intégral
Figure
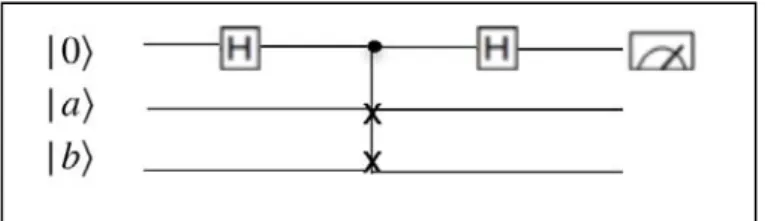


Documents relatifs
In this study we perform a way to classify the Zwicky Transient Facility Public Data Release 1 catalog onto variable stars of different types.. As the priority classes we set
In this paper we research two modifications of recurrent neural net- works – Long Short-Term Memory networks and networks with Gated Recurrent Unit with the addition of an
A quantum hybrid Helmholtz machine use quantum sampling to improve run time, a quantum Hopfield neural network shows an im- proved capacity and a variational quantum
However the situation is dual to the classical one: in our case test examples correspond to fixed subsets and probabilistically generated formal concepts must fall into selected
Using the MetaRTL flow described in Section 2.1, different hardware designs can be generated from the same meta-model. To this end, a meta-model is defined first in the MoT layer
This shows that the quantity of the aggressive tweets (the class of interest) was the half of the non- aggressive tweets. This is usual in many text classification problems.
Even if we were able to correctly classify each Twitter user, we would not be able to make a reliable estimate of the voting results as (i) several Twitter users may not vote,
This study will also establish a quantitative way to predict popularity of post with images on social media platforms like twitter just before uploading it based on transactional
