Étude comparative de nouveaux indices de détection de réponses inappropriées
Texte intégral
Figure







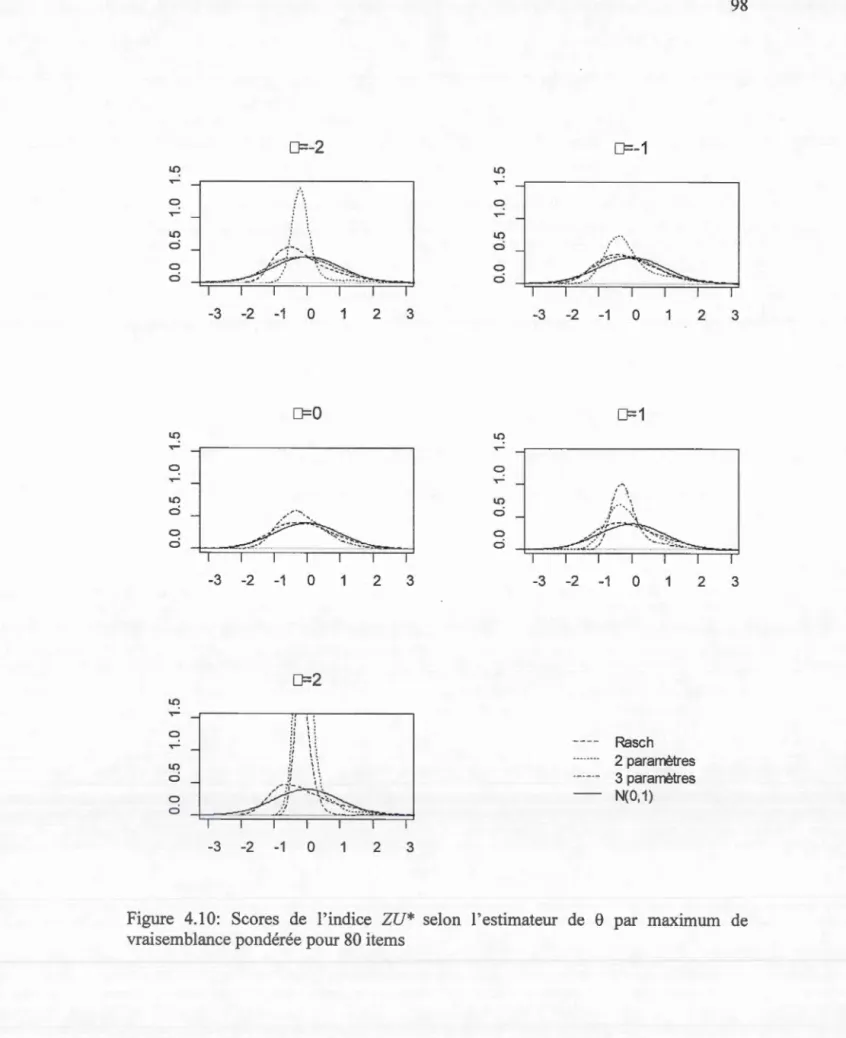
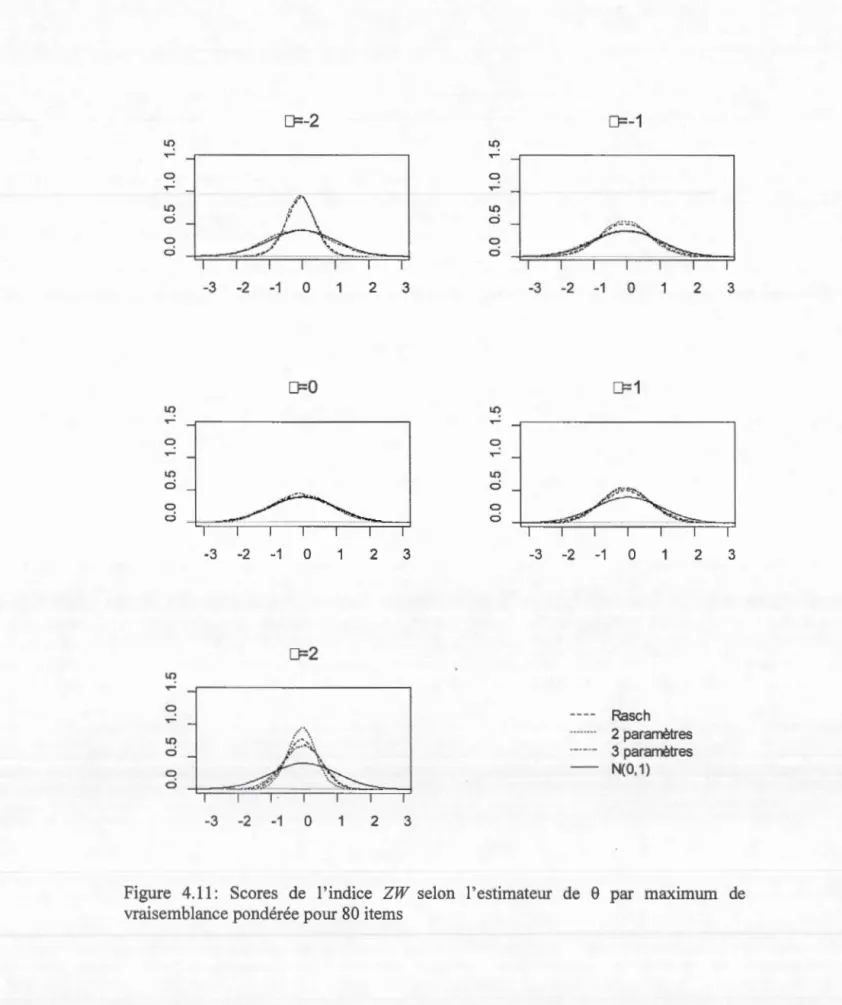

Documents relatifs
Afin de caractériser les interactions entre ondes guidées et discontinuités et ainsi de prévoir le comportement des ondes dans les structures aéronautiques saines, trois
Nous avons établi que les enfants atteints d’une SPR isolée n’avaient pas plus de troubles du comportement alimentaire, entre l’âge de 2 et 6 ans, que les enfants
Comportement et attitude n’ont été pris en compte que pour trois des quatre premiers élèves signalés : se montre attentif et vif, participe beaucoup plus, est assez enthousiaste,
Poussant plus loin l ' analyse , dans la présente recherche , nous remarquons que les élèves référés pour troubles de la conduite et du comportement ou les deux à
L’étude de la corrélation entre les résultats d’analyse du phosphore assimilable obtenus par les trois méthodes employées dans les sols calcaires et la matière sèche produite
Durant ces trois années de thèse plusieurs sujets ont été développés avec pour objectif de mieux comprendre et maîtriser l’injection, la détection et la manipulation électriques
En effet, elle ne cesse d'y penser et de faire des projets à ce sujet (« Cette boutique commençait à lui tourner la tête »). Bref, tout, dans son comportement et ses pensées,
Dans cet article, nous présentons un rapide historique du problème des indices de prix et ensuite nous développons « l'indice linéaire » et « l'indice exponentiel » avec des
