A parametric Bayesian combination of local and regional information in flood frequency analysis.
Texte intégral
Figure

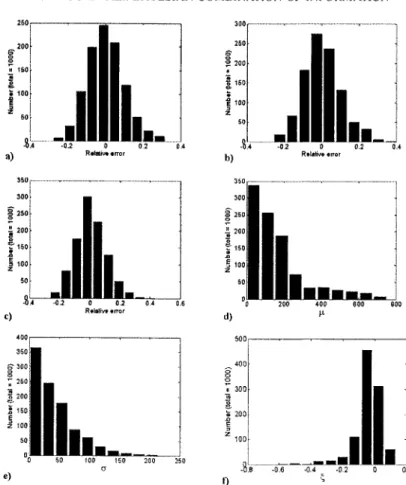
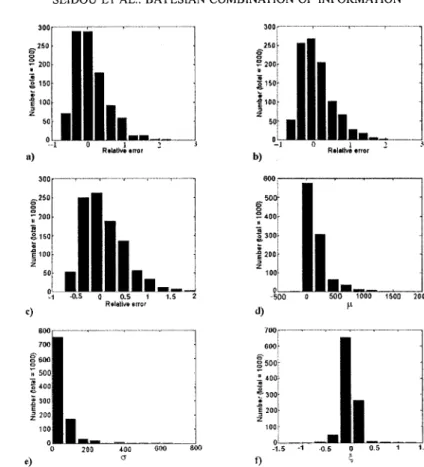
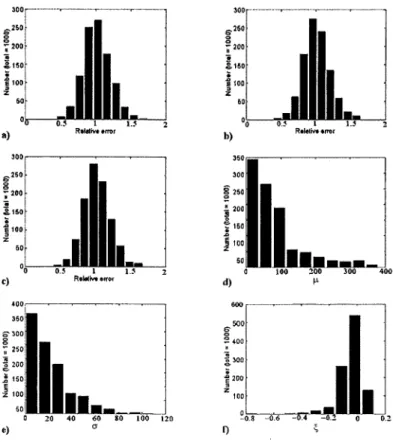
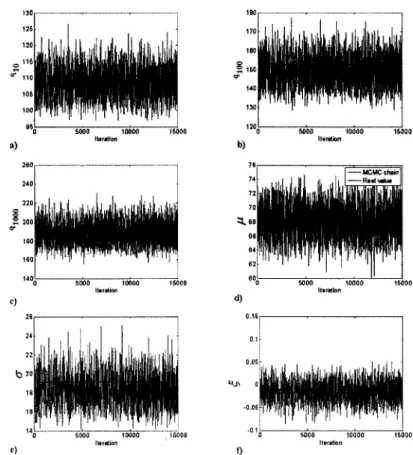



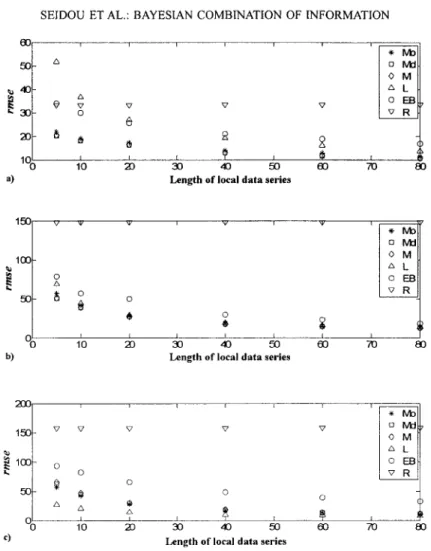
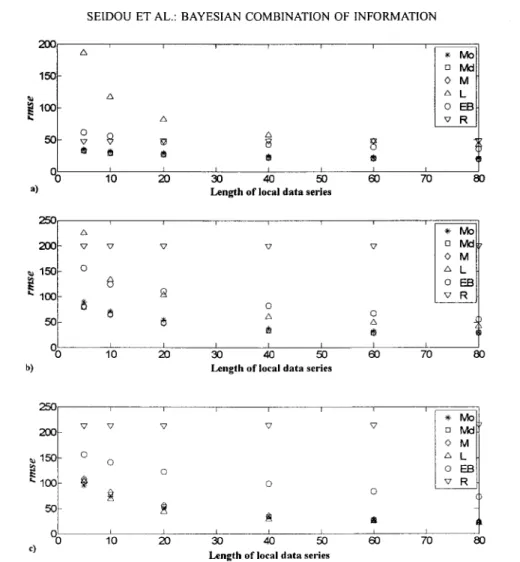
Documents relatifs
Three classes of multivariate extreme value distributions are scrutinised: the well-known model obtained from discrete spectral measures, the generalized logistic model and
Embrechts et al. In practice, we need to choose a block size large enough to ensure a good approximation of the GEV distribution but allowing also.. enough maxima observations to
Information about the scale parameters of the minimum ex- treme value distributions such as the Gumbel and the Weibull distributions can help researchers to choose the most
When the number of data points is large enough, it indicates that the distribution of the maxima might behave as a GEV distribution, independently of the distribution F..
En fait, il convient de distinguer les formes spontanées de croissance urbaine des formes planifiées. Les premières résulteront de la loi de l'offre et de la demande qui guide
Deux moyens ressortent, parmi ceux mis en œuvre par les 12 directions d’établissement scolaire interrogées, pour motiver leur personnel à composer avec les changements dus à la
Bien avant le relativisme galiléen, c’est encore un exemple frappant de perroquet-volubilis : limpide, l’arsenal conceptuel épicurien assoit une subjectivité collective
Based on these data in the max-domain of attraction of the logistic distribution we estimate the dependence parameter θ using our Bayes estimator and compare it to the
