Quand la recommandation rencontre la personnalisation. Ou comment générer des recommandations (requêtes MDX) en adéquation avec les préférences de l’utilisateur
20
0
0
Texte intégral
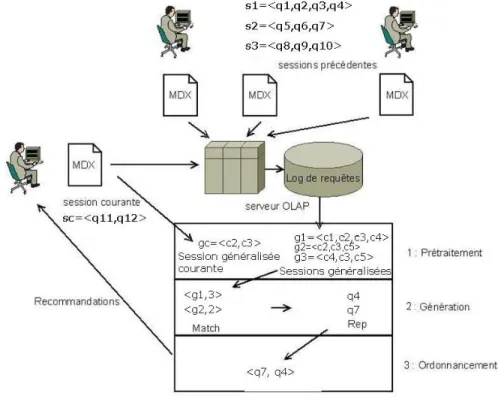
Figure


Documents relatifs