7^
UNIVERSITE DE SHERBROOKE
Faculte des sciences appliquees
Departement de genie electrique et de genie informatique
^?
^
'e-7<7 7 y / ...,^ 0^
'-7?/^:iiETUDE SUR LE FILTRAGE ET LA COMPRESSION DES
DONNEES
Memoire de maitrise es sciences appliquees Specialite: genie electrique et genie informatique
Resume
Le filtrage des donnees est de plus en plus utilise dans les applications informatiques courantes, il facilite la recherche d'informations par Pintermediaire de requetes (une requ^te est composee d'un ou de plusieurs mots). Le temps de filtrage d'un fichier est lie a sa taille, une maniere d'ameliorer ce temps est de reduire la taille du fichier en Ie compressant. L'objectif de ce memoire est de combiner les deux operations: filtrage et compression, afin de concevoir un algorithme de filtrage des donnees compressees dont 1'efficacite serait meilleure que ceUe d'un algorithme de filtrage des donnees non compressees. Dans ce memoire, nous presentons tout d'abord une etude detaill^e de quelques algorithmes de filtrage et de compression avec leur mise en oeuvre. Nous presentons ensuite Ie developpement d'un systeme "Banc d'essai" qui, d'une part ofFre un environnement pour tester Fefficacit^ des algorithmes implantes dans Ie systeme, et d'autre part engendre des fichiers performance contenant les valeurs des parametres d'efficacit6 de chacun des algorithmes. Ces fichiers performance sont tres utiles pour analyse? la performance des algorithmes.
Remerciements
Je tiens d'abord a remercier mon directeur de maitrise, M. Ruben Gonzalez Rubio, pour m'avoir fourni 1'aide technique ainsi que les outils necessaires pour realiser mes
travaux.
Je voudrais aussi remercier certains etudiants de Pequipe de M. Ruben Gonzalez Rubio pour les observations precieuses qu'ils m'ont apportees.
Je suis aussi tres reconnaissante pour toutes les personnes autour de moi qui m'ont soutemie moralement lors de 1'elaboration de mon travail.
Enfin, j'aimerais remercier plus particulierement mes tres chers parents qui m'ont beaucoup encouragee pendant les momeots difficiles, et c'est a eux que je dedie mon
Table des matieres
Introduction 1
1 L'etat de Part en filtrage et compression de donn^es 4
1.1 Les algorithmes de filtrage de donnees... 4
1.1.1 Introduction ... 4
1.1.2 L'algorithme Straightforward (SF) ... 5
1.1.3 L'algorithme Knuth-Morris-Pratt (KMP) ... 5
1.1.4 L'algorithme Boyer-Moore (BM) ... 9
1.1.5 L'algorithme Aho-Corasick (AC) ... 13
1.1.6 Conclusion... 21
1.2 Les algorithmes de compression et de decompression ... 23
1.2.1 Introduction ... 23
1.2.3 Les algorithmes de compression et de decompression "HufFman
Dynamique"(HD) ... 30
1.2.4 L'algorithme de compression LZW ... 47
1.2.5 L'algorifchme de decompression LZW ... 50
2 Realisation d'un systeme "Banc d'essai" 56 2.1 Structure generale du banc d'essai ... 56
2.2 La conception et la realisation du banc d'essai ... 58
2.2.1 Etapes de traitement effectuees par Ie banc d'essai... 59
2.2.2 L'interface usager ... 61
2.2.3 Architecture modulaire du banc d'essai ... 66
2.2.4 Description de quelques fonctions utilisees dans Ie banc d'essai 67 2.2.5 Presentation de quelques structures de donnees du banc d'essai 71 2.3 Difficultes rencontrees lors de la mise en oeuvre des algorithmes ... 73
2.4 Possibilites d'extension du banc d'essai ... 74
2.5 Conseils a suivre lors de la mise a jour du banc d'essai ... 75
3 Evaluation de Pefficacite des algorithmes 77
3.1 Introduction ... 773.3 Les paramefcres d'efficacite ... 78
3.4 Le rapport de performance J... 79
3.5 Definition des caracteristiques d'un fichier ... 79
3.6 Regroupement des fichiers par categorie... 81
3.7 Les types des fichiers performance ... 82
3.8 Influence des caracteristiques d'un fichier sur Pefficacite des algorithmes 83 3.8.1 Introduction ... 83
3.8.2 Les types des fichiers requ^te ... 84
3.8.3 Presentation et interpretation des resultats des tests de filtrage 84 3.8.4 Presentation et interpretation des resultats des tests de com-pression ... 88
3.8.5 Conclusion generate ... 94
4 Le filtrage des donnees compressees 95 4.1 Introduction ... 95
4.2 Les noms des algorithmes ... 96
4.3 Le pseudo-code des algorithmes ... 96
4.4 Presentation et interpretation des resultats des tests de filtrage des donnees compressees ... 99
4.4.2 Interpretation des resultats de test8 ... 99
4.4.3 Illustration des resultats de test9 ... 101
4.4.4 Interpretation des resultats de test9 ... 102
4.5 Comparaison des resultats obtenus avec ceux du filtrage des donnees
non compressees ... 103
Conclusion 105
A Interface utilisateur 107
B Fichier interface 111
C Exemples de fichiers test a trailer 119
D Exemples de fichiers requete 131
Table des figures
1.1 Inegalite ^ t[k] ... 7
1.2 PAT doit ^tre decale ^ droite ... 7
1.3 Illustration de 1'usage de DELTA1 ... 10
1.4 Illustration de Pusage DELTA'2 ... 11
1.5 Decalage du PAT associe £L DELTA2 de la figure ci-avant ... 11
1.6 (a) Fonction g... ... 14
1.7 (b) Fonction /... 15
1.8 (c) Fonction output ... 15
^ 1.9 Etapes pour la construction du graplie ... 18
1.10 Fonction output partielle ... 19
1.11 Fonction next-move(6) ... 22
1.12 Construction de Parbre de "Huffman statique" ... 27
^
1.14 Etat de Parbre apres codage du ler caractere a.... ... 34
1.15 Etat de Parbre apres codage du ler caractere b . . ... 34
1.16 Etat de 1'arbre apres codage du ler caractere r. ... ... 35
1.17 Etat de 1'arbre apres codage du 2ieme caractere a ... 35
1.18 Etat de Parbre apres codage du ler caractere c. ... ... 36
^ 1.19 Etat de 1'arbre apres codage du 3ieme caractere a ... 36
1.20 Etat de Parbre apres codage du ler caractere d.. ... 37
1.21 Etat de 1'arbre apres codage du 4ieme caractere a ... 37
1.22 Etat de 1'arbre apres codage du 2ieme caractere b ... 38
1.23 Etat de Parbre apres codage du 2ieme caractere r ... 38
1.24 Etat de Parbre apres codage du 5ieme caractere a ... 39
1.25 Table chalne ... 51
1.26 La forme compressee du message ababcbababaaaaaaa ... 51
1.27 Forme alternative de la table chame ... 55
1.28 Decompression du message 124358110111 ... 55
2.1 Les deux modules moteur du banc d'essai... 57
2.2 Etapes pour concevoir Ie banc d'essai ... 58
2.4 Environnement general du banc d'essai ... 62
2.5 Architecture modulaire du banc d'essai ... 66
2.6 Les fonctions appelantes et appelees ... 71
Liste des tableaux
3.1 Les caracteristiques des fichiers test ... 81
3.2 Resultats de testl avec KMP ... 85
3.3 Resultats de testl avec BM ... 85
3.4 Resultats de testl avec AC ... 85
3.5 Resultats de test2 avec BM ... 86
3.6 Resultats de test2 avec KMP ... 87
3.7 Resultats de test2 avec AC. ... 87
3.8 Resultats de test3 avec BM ... 88
3.9 Resultats de test3 avec KMP ... 88
3.10 Les valeurs de 6 pour test3 ... 89
3.11 Resultats de test4 avec LZW ... 89
3.12 Resultats de test4 avec HD.. ... 89
3.14 Resultats de test5 avec HD... 91
3.15 Les valeurs de 8 pour test5 ... 92
3.16 Resultats de test6 avec LZW ... 92
3.17 Resultats de test6 avec HD... 92
3.18 Resultats de test? avec LZW ... 93
3.19 Resultats de test? avec HD... 93
4.1 Evaluation du parametre temps en secondes pour test8 ... 100
4.2 Evaluation du parametre e_/ pour test8 ... 101
4.3 Evaluation du parametre 8 pour test8 ... 102
4.4 Evaluation du parametre temps en secondes pour test9 ... 102
4.5 Evaluation du parametre e-/ pour test9 ... 103
Introduction
La quantite de documents "electroniques" ne cesse d'augmenter, par consequent un utilisateur fait face ^ deux problemes : d'une part trouver la "bonne" mformation parmi la masse d'iuformations, et d'autre part pouvoir stocker 1'information en mini-misant 1'espace memoire occupe.
Une des techniques pour trouver 1'information est Ie filtrage, et une autre pour reduire Pespace de stockage est la compression.
Le filtrage des donnees" permet de trouver un document parmi un ensemble d'autres documents, si celui-ci repond bien aux criteres demandes. Un critere est verifie lors-qu'un motif de la requ^te existe dans Ie document.
La compression sans perte d'informations est tres utilis^e dans les domaines d'ar-chivage, car elle permet de stocker des fichiers electroniques en reduisant la taille occup^e. Elle est souvent utilisee dans les applications de transmission de donnees pour augmenter la vitesse de transmission. La compression est avantageuse lorsque les flchiers contiennent beaucoup de redondances (c'est-a-dire repetition de caracteres, de mots ou de morceaux de textes). Cependant, si 1'algorithme de compression n'est pas adapte au type de redondance dans Ie fichier, cette operation n'a aucun interet car eUe peut doubler ou tripler Ie volume du fichier.
Le temps de filtrage d'un fichier depend en grande partie de sa taille. II y a bien sur d'autres facteurs qui interviennent, mais la taille a un impact majeur sur Ie temps
necessaire pour efFectuer 1'operation de filtrage. C'est la raison pour laquelle nous avons pense a la methode de filtrage des donnees compressees. Celle-ci consiste a reduire d'abord la taille du fichier par compression avant de proceder a son filtrage. Le filtrage des donnees compressees est realise en combinant un algorithme de filtrage de donnees non compressees et un algorithme de decompression. Ce filtrage qui opere sur un fichier compresse est efFectue simultanement avec la decompression.
Nous avons implante un ensemble d'algorithmes de filtrage et de compression sur notre systeme "Banc d'essai", que nous appellerous plus simplement Banc d'essai. Ce systeme nous permet de mesurer 1'efficacite des algorithmes, et d'etablir 1'influence des caracteristiques du fichier, autres que la taille, sur les parametres d'efficacite. Nous avons implante quelques algorithmes de filtrage des donnees compressees, et compare leur efficacite avec des algorithmes de filtrage des donnees non compressees.
Notre objectif etait de concevoir un algorithme qui filtre les donnees compressees. Notre motivation etait la suivante : filtrer les donn6es compressees plus rapidement que les donnees non compress6es.
Les deux aspects importants li^s ^ la conception d'un algorithme sont sa fonctionnalite et son efficacite. Le systeme "Banc d'essai" execute les algorithmes et garde une trace des statistiques permettant d'analyser l'efficacit6 de chacun des algorithmes.
La suite de ce document est organisee de la maniere suivante:
• Le chapitre 1 est consacre aux algorithmes classiques de filtrage et de com-pression; il s'agit des algorithmes Boyer-Moore, Knuth-Morris-Pratt et Aho-Corasick pour Ie filtrage et Lempel-Ziv-Welch, et HufFman dynamique pour la
compression.
• Le chapitre 2 presente Ie developpement du Banc d'essai avec 1'implantation des algorithmes presentes au chapitre 1. Ce systeme offre un environnement pour tester PejBB.cacite des algorithmes de filtrage et de compression.
Le chapitre 3 illustre les resultats et Panalyse des performances de chacun des algorithmes.
Le chapitre 4 presente la comparaison des performances des algorithmes de filtrage des fichiers compresses et des algorithmes de filtrage des fichiers non compresses, avec illustration des resultats.
Chapitre 1
L etat de 1'art en filtrage et
compression de donnees
Ce chapitre presente les resultats d'une recherche bibliographique, concernant les algorithmes de filtrage et les algorithmes de compression.
1.1 Les algorithmes de filtrage de donnees
1.1.1 Introduction
Soient PAT et TXT deux tableaux qui contienuent des elements de type caractere. Le premier represente la chame de caracteres cherchee, appelee motif, et Ie deuxieme represente Ie texte dans lequel Ie motif est cherche. Soient m et n les longueurs en caracteres de PAT et TXT. PAT est represente par pi.. .pm et TJCT par ^i...
^-1.1.2 I/algorithme Straightforward (SF)
Straightforward est 1'algorithme Ie plus primitif de filtrage de donnees. II decale Ie motif d une position a chaque fois qu'une inegaUte est rencontree. Nous parlons d'inegalite lorsqu un caractere du texte et un caractere du motif compares sont dif-ferents. L? inconvenient avec 1'algorithme SF est qu'un caractere peut etre compare plusieurs fois, alors que les autres algorithmes presentes ci-apres reduisent Ie nombre de comparaisons, et par consequent Ie temps de filtrage.
1.1.3 I/algorithme Knuth-Morris-Pratt (KMP)
Introduction
La version originale de 1'algorithme KMP est pr6sent6 dans [1]. Lors de la presentation
de Palgorithme KMP, nous nous sommes inspires de Particle [2j.
L'algorithme de filtrage KMP 1.1.2 compare les caracteres du texte et du motif, et decale Ie motif a droite lorsqu'une inegalite entre ces caracteres est detectee. Le decalage est donne par Ie tableau FAILQ qui est calcule par 1'algorithme 1.1.1. Cette operation de decalage se r^pete jusqu'a ce qu'on trouve une occurence du motif ou que Ie texte soit entierement parcouru. Get algorithme localise une occurence du motif dans Ie texte, si elle existe, ou indique qu'aucune occureuce n'existe.
Pour amorcer Ie filtrage avec 1'algorithme KMP, PAT et TXT sont initialement places Pun au-dessus de 1'autre, de telle sorte que les premiers caracteres, a partir de la gauche, de PAT et de TXT soient align6s. Ces caracteres sont compares. Soit ils sont identiques et dans ce cas on compare les deux caracteres suivants, soit Us sont difFerents et dans ce cas on decale Ie PAT d'un nombre de positions, calcul6 ^ 1'aide du tableau FAILQ, de telle sorte que la comparaison suivante soit entre un caractere
caractere du texte ou 1'inegalite a lieu. L'algorithme de filtrage KMP est effectue en deux etapes :
• Etape 1 : L'algorithme 1.1.1 calcule un tableau, nomme FAIL[]^ qui fait corres-pondre, a chaque position dans PAT, ou Finegalite a lieu lors de la comparaison avec TXT, la nouvelle position dans PAT, qui sera comparee avec Ie caractere courant de TXT, ou I'inegalite a eu lieu. Dans Ie processus iteratif de compa-raison, lorsqu'il y a echec (c'est-a-dire iuegalite lors de la comparaison), il est possible dans certains cas de tenir compte des caracteres deja traites et de faire un glissement du motif de plus d'un cran. Le role de FAIL[] est alors de fournir Ie nombre de crans lors du glissement, pour ensuite entamer et continuer a la bonne iteration.
• Etape 2 : L'algorithme 1.1.2 effectue Ie filtrage du texte TXT, en utilisant Ie
tableau FAILQ calcule ^ 1'etape 1.
Mise en oeuvre
Soit FAILQ un tableau de dimension m + 1 qui contient des elements de type entier
et qui correspond a un motif donne. L'indice du tableau represente la position dans Ie motif ou Pinegalite peut avoir lieu, lors de la comparaison entre Ie texte et Ie motif. L'element du tableau determine la position, dans Ie motif, qui s'alignera avec Ie caractere du texte ou 1'inegalite a eu lieu, pour realiser une nouvelle operation de
Algorithme 1.1.1
calcul du tableau FAILQ : begin
j= 1; i = FAJL[1] = 0; while (j < m) do
while i > 0 A PAT[j] ^ PAT[t] do
i = FAJL[t]-, od; i=ii-l;j=J+l;
if(PAT[j-]==PAT[i])
thenFAIL\j] = FAIL[z];
elseFAIL\j\=u
fi; od; end t-t ... ^fc-J+1 .. . ^fc-1 ^ • • •$ $ ^
Pl ••• Pj-1 Pj ••'FIG. 1.1 - Inegalite a t(k]
t-i ... th-j+i .. . tk-i+i ... tk-1 tk ...
$ $ ?
pl ... p,_l p, ... pj ...
FIG. 1.2 - PAT doit etre decale a droite
La figure 1.1 illustre Ie cas ou il y a echec, et ou Ie PAT doit alors ^tre decale. Quant ei la figure 1.2, elle illustre la position du PAT apres son decalage d'un nombre de positions fourni par FAILQ. D'apr^s la figure 1.1, tk i=- pj apres comparaison des
il faut done trouver Ie caractere pi qui s'alignera avec tk apres decalage du PAT, avec
les conditions pi -^ pj, p^. ..pz-i == tk-i+\ ... tk-i et i Ie plus grand possible. II s'agit
au fait de decaler Ie motif, d'un nombre de positions determine a partir du tableau FAILQ qui est calcule par Falgorithme 1.1.1. Celui-ci permet de trouver 1'indice i a partir de Pindice j sachant que FAIL [j] = i. Une condition supplementaire est que
0 ^ i = FAIL[j] < j.
Algorithme 1.1.2 algorithme de filtrage KMP : begin j == k = 1; while {k <. n) dowhile CJ > 0 A TXT[k] ^ PAT[j]) do
j=FAIL[j]
od; if [j === m) thenpnnt{ "PAT est trmzve a",k - (m - 1)); exit;
else
k = k+1; j =j+ 1;
fi;
od;
print{ "PAT n'existe pas"); end
Conclusion
L'algorithme KMP examine done chaque caractere du texte au moins une fois, mais sans decrementer la position dans Ie texte; contrairement ^, 1'algorithme SF qui recule dans Ie texte.
1.1.4 I/algorithme Boyer-Moore (BM)
Introduction
La version originale de Palgorithme BM est presente dans [5j. Lors de la presentation de Palgorithme BM, nous nous sommes inspires de Particle [2].
Le principe de 1'algorithme BM est de parcourir Ie motif de la droite vers la gauche,
contrairement a KMP qui lui parcourt Ie motif de la gauche vers la droite. Avec cette approche, nous obtenons plus d'informations sur Ie texte dans lequel Ie motif est cherche. En recueillant ces informations, Ie motif est decale plus loin et certaines chaTnes de caracteres du texte ne sont jamais examinees, sachant qu'elles ne peuvent contenir Ie motif. Get algorithme localise une occurence du motif dans Ie texte si elle existe, ou indique qu'aucune occurence n'existe. Le filtrage avec 1'algorithme BM est efFectue en deux etapes :
• Etape 1 : L'algorithme 1.1.4 calcule les tableaux DELTAl et DELTA2. Le
tableau DELTA1 presente un decalage a faire subir au motif PAT. Ce decalage est calcule en fonction du caractere de TXT ou 1'inegalite a lieu lors des com-paraisons des caracteres de TXT et de PAT. Ce tableau est de dimension 256
(256 represente Ie nombre de caracteres ASCII). Le tableau DELTA2 presente
un autre decalage possible, a faire subir au motif PAT. Ce decalage est calcule en fonction du rang du caractere dans Ie PAT ou 1'inegalite a lieu. C'est Ie plus
grand des deux decalages, fournis par DELTA1 et DELTA1, qui est applique
au motif PAT.
• Etape 2 : L'algorithme 1.1.5 efFectue Ie filtrage du texte TXT. Get algorithme
Mise en oeuvre
Pour amorcer Ie filtrage avec Palgorithme BM, Ie motif et Ie texte sont alignes sur leur
extreme gauche. La comparaison commence a pm, entre pm et tm, ensuite pm-i et ^m-i 3
et ainsi de suite jusqu'a rencontrer une occurence ou une inegalite. Si 1'inegalite est detectee, Ie motif est decale a droite. Ce decalage correspond a la valeur maximale des deux decalages calcules par les tableaux DELTA! et DELTA2. Le decalage calcule par DELTA! depend du caractere dans TXT ou 1'inegalite a lieu, tandis que
Ie decalage calcule par DELTA2 depend de la position dans PAT ou 1'inegalite a
lieu.
Algorithme 1.1.3
calcul du tableau DELTAlQ :
beein
if ( c n existe pas dans Ie motif )
then
DELTAl[c] == m;
else
DELTAl[c] = j avec j Ie plus petit tel que (0 <: j <m et pm-j 7^ c);
fc
endou.:
DELTAl[c] = min{j \ j =m ou (0 < j < m et pm-j = c)}
t\ ... tr tr+i ... ... ... ti-.i i^-^+l ... ti
t t $
Pl ... pm-j Pm-j+1 • • • Pm-l Pm-l+1 • •• Pm
< DELTA1 [ ii-i ] =j >
FIG. 1.3 - Illustration de Fusage de DELTA!
D'apres la figure 1.3, les r premiers caracteres du texte examines ne contiennent pas d'occurences du motif (i = r + m). La position du motif aligne avec Ie (r + l)ieme
caractere illustre une inegalite entre les caracteres ^_/ et pm-i- Le motif est done decale a droite de telle fa^on que pm-j soit aligne avec ^_;, 1'indice m — j est calcule
^ partir de la valeur fournie par DELTAl[ti-i] (DELTAl[ti-i] = j). La comparaison
ulterieure sera entre tg et pm (s = i —I -\- DELTAl[ti-i]). Le decalage calcule par DELTA1 est done efFectue sans avoir examine les m — j caracteres successifs a ii-m.
< 5 »
ti ... ti-m+1 ••• ••• ••• ••• ti-l ti-l+l ••• ••• •• • ti
t $ $
Pl • • • Pd Pd+1 • • • Pm-l Pm-l+i • • • Pd+l ••• Pm.
« s » < 5 »
< DELTA2[m - 1] == m- d (if pd. ^ pm-i) »
FIG. 1.4 - Illustration de Pusage DELTA2
< s »
t\ ... ti-m+l • • • • •. ti-l ti-l+1 • " ti • • • ti-l+DELTA2(m-l)
$ $ ?
Pl ••• Pd Pd+l ... Pd+l ••• Pm
< 5' >
FIG. 1.5 - Decalage du PAT associe a DELTA2 de la figure ci-avant
D'apres la figure 1.4, Ie motif aligne avec Ie caractere ti-m+i illustre une in^galite ^
pm-i- Soit 5' une sous-chaine telle que S = pm-i+i • • -Pm- Le motif est done decale 21
droite de telle sorte qu'une autre sous-chame S dans Ie motif, la plus ^ droite possible, s'aligne avec la sous-chame S du texte. La nouvelle sous-chatne S du motif ne doit pas etre pr6cedee du caractere pm-i- La- figure 1.5 illustre la nouvelle position du motif apres son decalage, Ie caractere ti-i est aligne avec Ie caractere pd. L'iudice d est
calcule a partir de la valeur fournie par DELTA2[m - 1} (DELTA2[m -1] == m — d),
la comparaison a lieu entre tu et pm (u = i— ljr DELTA2[m —I]). Pour une inegalite a pj, 0 < j <: m, D£'Z/TA2[j] peut etre defini comme suit :
DELTA2[j] = min{k +m— j \ k>_ 1 A [(A; ^ i ou pi-k = pi) pour j <i <, m]
A [k >_j oupj-k ^Pj]}
Algorithme 1.1.4
calcul de DELTA1 et DELTA2 :
begin
for (c== 0 to 255 step 1) do DELTA1
[c]=m,-od;
calcul de DBLTA1 et initialisation de DELTA2
for (^" == m to 1 step — 1) do
if {DELTA\[PAT\j}} == m)
thenDELTAl[PAT[j}} =m-j;
fi;
DELTA2\j] = 2*m-j; od; calcul DELTA2 J = m; t==m+l;while (j > 0) do
f[j]=t;
while {t<, m A PAT[j] + PAT[t]) do
DELTA2[t] = min{DELTA2[t], m - j); t = f[t];
od; J=J-1; t = t-1; od; for (fc = 1 to t step 1) doDELTA2[k] = min{DELTA2[k], m+t-k);
od;Les etapes suivantes out ete ajoutees par Mehlhorn [9]
tp = f[t], while {t <^ m) do while {t <, tp) do DELTA2[t\ := min{DELTA2[t], tp -1 + m); t=t+l; od; tp = f[tp}: od; end
Algorithme 1.1.5 algorithme de filtrage BM : begin k = m; while {k <^ n) do J=.m;
k parcourt Ie texte et j Ie motif
while {j > 0 A TXT[k] == PAT[j]) do
J=J-1; k^k-1; od;ifCj==0)
thenpnnt("PAT est trouve a",k+l); exit;
else
k = k + max{DELTAl[TXT[k}}, DELTA2[j]};
fc
od;
print ("PAT n'existe pas"); end
Conclusion
L'algorithme de filtrage BM 1.1.5 permet de calculer la nouvelle valeur de 1'indice k
qui indexe Ie texte pour comparer TXT[k] et PAT[m], 1'inegalite ayant eu lieu entre
Ie caractere de position k dans Ie texte et un caractere du motif. La valeur de k est
choisie la plus grande possible afin de decaler Ie motif Ie plus loin possible.
1.1.5 L'algorithme Aho-Corasick (AC)
Introduction
L'algorithme AC est presente dans [6]. 11 est simple, efficace et permet de localiser dans un fichier texte toutes les occurences d'un nombre fini de mots cles, contrairement aux algorithmes KMP et BM qui trouvent juste une occurence d'un seul mot de a la fois. Le filtrage avec Palgorithme AC est effectue en deux etapes:
• L'etape 1 consiste a construire une machine a etats finis a partir des mots cles. Cette machine est dictee par trois fonctions g, f et output dont les fonctionna-lites seront decrites durant la description de la machine ^ etats finis.
• I/etape 2 consiste a filtrer Ie texte en utilisant 1'algorithme 1.1.6. Cette etape utilise la machine a etats finis calculee a Fetape 1.
Description de la machine a etats finis
FIG. 1.6 - (a) Fonction g
La machine ^L etats finis est un ensemble d36tats et de transitions, ou chaque etat est represente par un nombre. Cette machine traite Ie texte x en lisant successivement les symboles dans x et en efFectuant des transitions d'etats. Elle affiche Ie mot de lorsqu'il est repere dans Ie texte. Soit K = {yi, 2/2,. • -VK} un ensemble de mots cles et soit x un texte constitue d'une chame de caracteres. L'objectif est alors de localiser toutes les sous-chaines de x qui sont des mots cles dans K.
Les figures 1.6, 1.7 et 1.8 Ulustrent un exemple de machine a etats finis pour K == {he, she, his, hers}. Le comportement de cette machine est dicte par les trois fonctions g^ f et output qui sont respectivement calculees par les algorithmes 1.1.7,
1.1.8 et 1.1.9.
machine, en fonction de Petat courant et du caractere lu sur Ie texte. La fonctiou
g retourne ec/iec, si g(etat-courant^ caractere-lu} n'a pas d'image. Par exemple,
d'apres la Figure 1.6 g(2,e) = echec, g(l,o~) = echec pour tous les symboles cr qui sont difFerents de e et de i et par definition g(0,o~) -f- echec quelque soit Ie symbole a. Sur la figure 1.6, <{h,s} signifie Ie complementaire de {h,s}.
• La fonction / repr6sentee par la figure 1.7 est invoquee lorsque la fonction g retourne echec. Cette fonction / calcule 1'etat vers lequel bascule la machine en fonction de son etat courant. Si, par exemple, la machine associee a la figure 1.6 est £L 1'etat 4 et que Ie caractere lu est different de e, alors la machine bascule a
P6tat 1, Petat 1 est calcule par la fonction / (/(4) =1). La machine repete Ie
m^me cycle avec Petat 1 et Ie dernier caractere lu.
• La fonction output representee par la figure 1.8 associe a chaque etat possible de la machine, un ensemble vide ou un ensemble de un ou plusieurs mots cles. Cette fonction determine si a un etat donne, un sous ensemble de 1'ensemble K est rep6re dans Ie texte ou pas. Dans Ie cas positif, la machine affiche les mots cl6s reperes.
i 123456789
f(i) 0,00120303
FIG. 1.7 - (b) Fonction /
i output (i)
2 {he}
5 {she, he}
7 {his}
9 {hers}
AIgorithme 1.1.6
algorithme de filtrage AC : begin
etat = 0;
for (z = 1; ? <= n; z + +) do while (g{etat, a;) == echec) do
etat = f(etat}\ od;
etat = g{etat, a,)
if {output{etat) ^ vide) then
print{i);
print{output(etat});fi;
od; endLes fonctions necessaires a la construction de la machine a etats finis
Dans cette section, nous allons voir comment construire les fonctions g, f et output ^ partir d'un ensemble de mots cl6s. La construction de ces fonctions est divisee en deux parties:
• Parfcie 1 : nous determinons les etats, calculons la fonction g et une partie de la fonction output.
• Partie 2 : nous calculons 1^. fonction / et completons la construction de la fonction output.
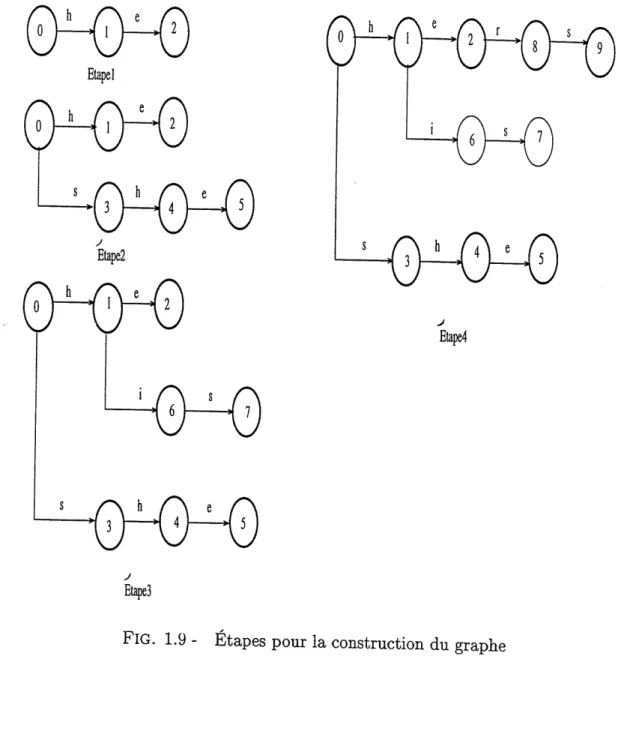
Pour construire la fonction g^ la machine s'initialise a l'6tat 0 et insere tous les mots cles successivement, en ajoutant une fleche et un etat pour chaque caractere d'un mot de. La figure 1.9 illustre les etapes de construction du graphe correspondant a
K = {/ie, s/ie, /i%s, hers}. Lorsqu'un mot de est entierement introduit dans Ie graphe, 1'etat qui termine ce mot cl6 est associe a ce mot de par la fonction output. Une premiere partie de cette fonction output est illustre sur la figure 1.10. Durant Ie calcul de la fonction /, la fonction output est mise a jour. Des que f(s) = 5!, output(sl) est ajoute a output(s). L'etat final de la fonction output est represente par la figure 1.8.
La fonction / construite a partir de la fonction g calcule la valeur associee a 1'etat de profondeur d, sachant que toutes les valeurs associees aux etats de profondeur d-1 ont ete calculees. La profondeur d'un etat s dans Ie graphe est la longueur du plus petit chemin de 1'etafc 0 a 1'etat s. f(s) =0 pour tous les etats s de profondeur 1 et / n'est pas defini pour 1'etat 0. La fonction / calculee pour K == {/ie, she, his, hers} est representee sur la figure (1.7). Les actions a suivre pour calculer la fonction / pour les etats de profondeur d>=2 sont les suivantes.
Pour tout etat r de profondeur d-1, faire:
• Si g(r, a) = echec quelque soit a, ne rien faire.
• Autrement, pour chaque symbole a tel que g(r, a) = s, faire les actions suivantes:
— (a) faire etat = f(r).
— (b) executer Finstruction etat = f(etat) zero, une ou plusieurs fois, jusqu'a obtenir une valeur de etat telle que g(etat^ a) / echec. II est demontre que cette solution existe toujours [6].
- (c) faire f(s) = g{etat^a).
La fonction / diminue I'efl&cacite de cet algorithme, dans Ie sens ou certaines transi-tions sont inutiles. Comme dans 1'exemple de la figure 1.7 ou /(4) = 1, sila machine est a 1'etat 4 et que Ie caractfere In est different de e, la machine a etats finis bascule done vers 1'etat 1. Or si Ie mot de his n'existait pas, la machine devrait basculer di-rectement a 1'etat 0, sans passer par 1'etat intermediaire 1, sachant qu'une transition de la machine vers Petal ^(l,e) est impossible. Pour eviter ces transitions inutiles, un automate ^, etats finis base sur une fonction next-move(} sera congu. next.move() est calculee a partir des precedentes fonctions g et /; elle determine 1'etat vers lequel transite la machine sans faire appel ^. la fonction /. L'algorithme 1.1.10 calcule la fonction next-move() qui est symbolisee par (6).
La fonction next-move() calculee pour K = [he^ she, his, hers} est representee sur la figure 1.11. Pour chaque etat de cette figure, Ie caractere point (.) represente un symbole d'entree qui regroupe un ensemble de caracteres complementaires aux symboles d'entree de 1'etat courant, par exemple Ie caractere point pour 1'etat 0 regroupe tous les caracteres de 1'alphabet excepte les caracteres {h,s}.
h r\ e
^ '
r\
-^ 3\J
Etape4
y Etape3output(2) = {he}
output(5) = {she}
output(7) = {his}
output (9) = {hers}
FIG. 1.10 - Fonction output partielle
Algorithme 1.1.7
calcul des fonctions g et output:
begin
nouveau-etat = 0;
k designe Ie nombre de mots cles
for {i = 1; i <= k; i + +) dp, call enter {yi)
od;
for (tout a tel que g(0, a) = echec) do
5(0, a) =0;
od; end
Algorithme 1.1.8
la procedure enter (ai as .. . am) :
beein
m designe la taille du mot de etat = 0;
J=l;
while {g{etat,a,j} ^ echec) do
etat = g{etat,aj); J=^+l; od; for CP == 3', P <=m: p + +) do nouveau-etat = nouveaujetat + 1; g{etat,ap) = nouveau-etat; etat = nouveau-etat'^ od;
output{etat) = {aia2 .. . am}; end
Algorithme 1.1.9
calcul de la fonction f et une partie de la fonction output begin
file est vide\
for {chaque a tel que (^(0,a) = s) 7^ 0) do a j outer a file I element {s};
,(5) = 0;
od;
while (file -^ vide) do
r va etre Ie prochain etat dans la file; enlever a file I'element {r};
od;
for (chaque a tel quo (g(r, a) = s) ^ echec) do a j outer a file I'element {s};
etat = /(r);
while [g(etat^ a) == echec) do etat = f(etaf);
od;
/(s) = g{etat,a);
aj outer a output(s) output{f{s)) od;
end
Algorithme 1.1.10
calcul de la fonction next-moveQ : begin
file est vide;
for (chaque symbole a) do
J(0, a) =p(0, a);
if(^(0,a)^0)
then
ajouter a file I'element {5(0,0)};
fi
od;
while {file ^ vide) do
r est Ie futur etat dans la file', enlever a file i'element {r};
for {chaque symbole a) do if ((^(r, a) == s) ^ echec)
then
aj outer a file I element {s};
J(r,a) ==s; else
J(r,a)=J(/(r),a);
fi
od; od; endAlgorithme 1.1.11 begin
algorithme de filtrage AC : etat = 0;
for (z = 1; z <= n; t + +) do etat = 8{etat, a,i)
if {output{state) / vide) then
print{i};
prin t{output(etat));fi;
od; end1.1.6 Conclusion
II est clair qu'aucun des algorithmes presentes n'est optimal dans toutes les
circons-tances.
En fonction de la longueur de 1'alphabet utilise dans Ie texte, de la longueur du motif, de la position du motif dans Ie texte et de la composition du motif, un algorithme adequat parmi ceux qui sont cites ci-dessus est choisi. Je citerai ci-dessous quelques avantages et inconvenients de chacun d'eux.
La performance de Palgorithme BM est pauvre pour des motifs de petites lon-gueurs (longueur < 4) et lorsque Ie motif est trouve rapidement (position du mo-tif dans Ie texte < 100 caracteres). Dans les autres cas, il est de loin Ie meilleur algorithme ^ utiliser.
Lorsque Palgorithme BM est mefficace, nous avons tendance a choisir 1'algorithme SF par rapport ^ 1'algorithme KMP. Ce dernier est desavantageux lorsque la position du motif est proche du debut du texte. Mais 1'algorithme KMP peut ^tre plus performant
que Palgorithme SF lorsque la taille de Palphabet qui constitue Ie texte est petite,
par exemple un texte binaire.
symbole d'entree etat suivant
etat 0: h 1
s 3
0
etat 1: e 2i 6
h 1
s 3
0
etat 9: etat 7: etat 3: h 4
s 3
0
etat 5: etat 2: r 8h 1
s 3
0
etat 6s 7
h 1
0
etat 4 e 5
i 6
h 1
s 3
0
etat 8s 9
h , 10
alors qu'avec Palgorithme BM Ie nombre de caracteres compares est toujours inferieur au nombre de caracteres parcourus. Ce point fort de Palgorithme BM. est du au parcours du motif de la droite vers la gauche. Cette strategie permet de rassembler des informations sur Ie texte qui nous evitent d'examiner certaines chatnes de caracteres qui ne contiennent pas de motifs.
L'algorithme AC presente un avantage par rapport aux algorithmes KMP et BM, il trouve toutes les occurences en une seule passe, mais il est beaucoup plus lent que les
algorithmes KMP et BM.
1.2 Les algorithmes de compression et de
decom-pression
1.2.1 Introduction
Les techniques de compression sont souvent utilisees pour les fichiers texte ou certains caracteres apparaissent plus souvent que d'autres. Par exemple, les fichiers pour coder les images, les fichiers pour la representation numerique du son et d'autres signaux analogiques qui contiennent un certain nombre de motifs repetes.
La taille de Pespace sauve par ces methodes varie et depend principalement des ca-racteristiques du fichier. Par exemple, la taille des fichiers texte peut etre reduite de
20 % ^50 % alors que la taille des fichiers de type binaire peut etre reduite de 50 %
a 90 %. II est aussi interessant de noter que la methode de compression n'est pas toujours avantageuse car, dans certains cas, Ie fichier engendre peut ^tre plus grand que Ie fichier d'origine.
1.2.2 L algorithme de compression HufFman "statique"
Introduction
Le codage "Huffman" exploite la propriete que les symboles ou caracteres des fichiers texte n'ont pas la meme frequence. Alors, au lieu de coder tous les caracteres avec un nombre fixe de bits, une methode de codage differente est utilisee dans laquelle les caracteres de frequence plus elevee sont codes sur un nombre de bits moins eleve que les caracteres de frequence plus faible. II faut done tout d'abord determiner la fr^quence de chaque caractere dans la chame a compresser.
Explication du principe
La version originate de cet algorithme est present^ dans [7]. Lors de la presentation de cet algorithme, nous nous sommes inspires de Pouvrage [10]. Le principe du code HufFman se resume comme suit:
• Etape 1 : Evaluer la frequence de chaque caractere dans Ie message ^ coder. L'algorithme 1.2.1 calcule Ie tableau countQ qui contient la firequence de chaque caractere alphabetique dans Ie message a compresser.
Algorithme 1.2.1
calcul du tableau count Q :
b_egin for (z = 0 to 26 step 1) do count[i] = 0; od; for (z = 0 to M — 1 step 1) do
count[index{a[i}}} + +;
od; endindex() est une fonction tres simple dont la mise en oeuvre n'est pas illustr^e dans cette section. Elle prend comme argument un caractere de Palphabet et
retourne un entier indiquant Ie rang de ce caractere dans la liste alphabetique
{a,b,...,z}.
count[i] = j signifie que Ie ieme caractere de 1'alphabet existe j fois dans la chaine a coder. Ce tableau est calcule par 1'algorithme 1.2.1.
• Etape 2 : Cette etape s'efFectuera en plusieurs sous-6tapes. En partant d'une file de priorites constituee d'elements du tableau countQ, qui sont disposes selon un certain ordre que nous n'expliquerons pas ici, nous obtenons un arbre appele arbre de codage "HufFman" qui code chaque caractere du message. Chaque noeud terminal de 1'arbre est associe a un caractere qui se trouve dans Ie message, avec sa frequence a Pinterieur du noeud. Le caractere correspondant est code en partant de la racine de 1'arbre, avec la branche droite codee comme 1 et la branche gauche codee corn me 0.
- La lere sous-etape consiste ^ constuire une file de priorites, qui est une succession de noeuds. Chaque noeud contiendra la frequence d'un caractere dans Ie message a coder, Pordre de succession de ces noeuds ne releve pas de la discussion courante.
— La 2ieme sous-etape consiste 21 trouver deux nceuds de plus petites quences pour creer un nouveau noeud de valeur la somme des deux fre-quences. Les deux noeuds deviennent les fils de ce nouveau noeud. Par consequent, les deux noeuds descendent d'un niveau dans Parbre.
— Les sous-etapes suivantes : On continue de la meme fa^on que la 2ieme sous etape, en cherchant toujours les deux plus petits noeuds pour creer un nouveau noeud qui sera Ie pere des deux autres noeuds. On augmente ainsi Ie nombre de sous-arbres en engendrant un sous-arbre EL partir de deux noeuds. Le meme processus est repete jusqu'a fusionner tous les
sous-arbres en un seul arbre.
Le code HufFman est derive de 1'arbre "HufFman" en remplaQant les frequences dans les noeuds qui sont tout a fait en bas de Parbre, appeles nceuds terminaux, par les
caracteres associes. Ainsi 1'arbre est vu comme un arbre de codage, avec Ie codage
de toute branche droite en 1 et de toute branche gauche en 0.
A titre de remarque, les noeuds d'un arbre qui representent les caracteres de frequences elevees sont situes proches de la racine, contrairement aux noeuds qui representent les caracteres de frequences faibles et qui sont situes loin de la racine. Le nombre de bits, pour coder un caractere, est proportionnel a la distance qui separe Ie noeud de la racine de Parbre.
II a ete prouve que la meilleure strategie consiste a choisir en premier les deux noeuds de poids Ie plus faible. C'est pourquoi Ie code Huffman est considere comme Ie meilleur code. Un autre point fort du code Huffman est que Ie poids externe de Farbre "HufFmaa" est egal a la longueur du message code. II n y a pas unicite d'arbre
car a chaque etape il peut y avoir plus de deux noeuds de poids Ie plus faible [10].
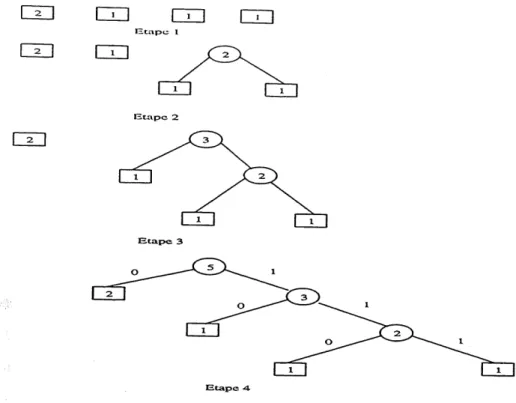
Un exemple illustrant revolution de Parbre de "HufFman statique"
Soit QZQYA une chame de caracteres a coder. La file de priorites contient quatre noeuds. Un noeud de frequence 2 pour Ie caractere Q, un noeud de frequence 1 pour Ie caractere Z, un noeud de frequence 1 pour Ie caractere Y et un nceud de frequence 1 pour Ie caractere A. La figure 1.12 illustre les etapes a suivre, pour construire 1'arbre
de "HufFman statique" a partir de la file de priorites 2111. A 1'etape 4 de la figure
1.12, Parbre de codage HufFman est construit. II est done possible, a partir de cet arbre de coder les caracteres du message. Je rappelle que Ie code de chaque caractere, est determine par Ie chemin de la racine au noeud terminal, associe ^ ce caractere. D'apres Parbre de Huffman, Ie caract^re Q etant de frequence 2, son code est done unique, c'est Ie bit 0. Quant aux caracteres Z, Y et A, ils sont tous de frequence 1, alors Ie code possible pour chacun des 3 caracteres est 10, 110, ou 111, avec la contrainte que deux caracteres difFerents ne peu vent pas avoir un m^me code.
cm
IScapu I
Etapc 2
Etape 3
Etape -4.
FIG. 1.12 - Construction de 1'arbre de "HufFman statique"
Mise en oeuvre
Soit PQ une classe dont 1'interface est definie ci-dessous, avec Ie developement de ses methodes en langage C++. pq est une instance de la classe PQ, appelee file de priorites des frequences. Cette file de priorites pq est construite a partir d'elements du tableau county.
class PQ{
private:
int *a, *p, *info, int N;
public:
/*le constructeur de la classe PQ*/
PQ(int size) {
a=new int[size];
p=new int [size]; info=new int[size];
N=0;
>
/*le destructeur de la classe PQ*/
~PQO {
delete a;
delete p; delete info;
}
/*insere un. nouveau noeud dans la file de priorite pq*/
void insert(int x, int v) { a[++N]=v;
p[x]=N; info[N]=x;
>
/^change la priorite d'un noeud*/ void change (int x, int v) {
a[p[x]]=v;
>
/*deplace Ie plus grand noeud d)im bloc vers Ie bloc de poids superieur*/ int remove() -[
int j, min=l;
for(j=2; j<=N; j++)
if (a [j ] <a [min] ) min=j ;
swap(a, min, N); swap(info, min, N); p[info[min]]==min; return info[N--];
>
/*verifie si la file de priorite pq est vide*/
int empty() {
return (N<=0);
3-};
L'algorithme 1.2.2 construit la file de priorites pq, a partir du tableau county (county contient les occurences des caracteres utilises dans Ie texte). II calcule aussi Ie tableau
dadQ, a partir de la file de priorites pq, les deux plus petits elements de la file de priorites sont 6tes de la file, pour etre remplaces par un element dont la valeur est la somme de ces deux elements. Ce meme processus est repete jusqu'a vider la file. dadQ associe a un numero de noeud dans Farbre Ie numero de son noeud p ere. Les codes associes aux caracteres sont representes par les tableaux /en[] et codeQ qui sont calcules par Palgorithme 1.2.3, ou code[k] est la representation decimale de la kieme
lettre de Palphabet, et len[k] est Ie nombre de bits utilises pour coder cette kieme
lettre.
Algorithme 1.2.2 calcul du tableau dadQ : begin for (a = 0; i <, 26; i + +) do
If {count[i} ^ 0)
then pq.insert(ccyunt[i], i)fi;
od; for (a = 0; -fpq.emptyQ; i + +) do tl = pq.remove(); t2 = pq.remove()dad[i] = 0; dad[tl] = i; dad[t2] = -i; count[i] = count[tl] + count[t2]; if (-^pq.emptyff) then pq.insert{count[i], i};
fi;
od; end Algorithme 1.2.3calcul des tableaux lenQ et codeQ:
begin
for (k = 0; k <, 26; k + +) do
i ==0; a; = 0; j = 1;
If (caunt[k} ^ 0)
then
for (* = dad[% t; t = dad[t]J+ = j,i + +) do
if (t < 0)
then x = a; +j; t = —t;fi;
od; ft; code[k] = x; len[k] = i; od; endConclusion
Le code HufFman" est efficace lorsque la distribution des frequences qui correspond aux caracteres est grande et aussi lorsque la chaine de caracteres du texte a compresser est longue. Dans Ie cas des fichiers ou les frequences des caracteres sonfc approxima-tivement egales, Ie code n'est pas avantageux (ce cas est represente par un arbre de codage balance), puisque Ie nombre de bits pour coder un caract^re est sensiblement
Ie meme d'un caractere a 1'autre.
1.2.3 Les algorithmes de compression et de decompression
"HufFman Dynamique"(HD)
Introduction
Ces algorithmes sont presentes dans 1'article [8]. Le codage "HufFman" souvent utilise dans les applications de transmission des donnees necessite la connaissance de la table de codage, de la part de 1'emetteur et du recepteur. Dans Ie cas des applications de compression et de decompression, cette table doit etre connue de la part de 1'encodeur et du d6codeur. La methode alternative permet a Femetteur et au recepteur, ou bien a Pencodeur et au decodeur, de construire 1'arbre de "Hufifanan dynamique", au fur et a mesure que les caracteres sont emis ou re^us. Cette methode est connue sous Ie nom de codage "Huifman dynamique" .
Le principe de base du codage "HufFman dynamique"
Void un rappel de la strategic de Falgorithme "Huffman" avant d'amorcer la proce-dure de mise a jour de Parbre de HufFman dynamique. Soit (wi,W2,W3 .. .Wn) des poids non mils qui representent des frequences de caracteres dans un texte. L'algo-rithme "HufFman" permet de constmire, a partir de la suite (wi,W2,zu3.. .Wn), un
arbre binaire avec n nceuds terminaux et n — 1 noeuds non terminaux, ou les noeuds terminaux sont etiquetes avec les poids {w^.w^^w^.. .Wn) suivant un certain ordre.
Un noeud terminal de niveau / correspond a une chaine de 0 et de 1 (ou Ie bit 0 cor-respond a la branche gauche dans 1'arbre et Ie bit 1 corcor-respond a la branche droite). La correspondance entre 1'arbre et Ie code est simple, il suffit de representer Ie chemin de la racine au noeud terminal.
L'algorithme Huffman" combine les deux noeuds de plus petits poids pour les rem-placer par un sous-arbre dont Ie poids du noeud racine est la somme de ces deux noeuds. Ce processus est repete jusqu'a fusionner les sous-arbres en un seul arbre. Cette strategic peut aboutir a difFerentes structures d'arbres qui sont toutes opti-males. Cependant, lorsqu'on augmentera Ie poids d'un noeud terminal, un arbre sera optimal par rapport a 1'autre en fonction du noeud cible. C'est pourquoi la procedure de mise a jour de Parbre "HufFman dynamique" doit pouvoir basculer d'une possibilite ^ Pautre.
Le processus de I'algorithme "Huf&nan" qui combine les poids des noeuds conduit a une sequence de noeuds terminaux et non terminaux de poids croissants
(;ci, a;23 ^3 5- • • 5^2n-i)- Cette sequence est la m@me pour tous les arbres de
"Huff-man" pour (wi, wz, Ws... Wn) donne. La procedure qui met a jour Parbre depend de Petat de 1'arbre et du nouveau caract^re. En effet, comme nous allons voir plus tard, Palgorithme qui maintient 1'arbre de HufEman a jour est un algorithme en temps reel.
L'algorithme de compression (respectivement de decompression) code (respectivement decode) la lettre ak en se basant sur Petat courant de 1'arbre, et met a jour Parbre. Cette mise ^ jour de Parbre est basee sur Ie dernier caractere code (respectivement decode). La taille de Palphabet a coder (respectivement a decoder) est une donnee connue par Palgorithme de compression (respectivement de decompression).
Les operations de codage, de decodage et de mise a jour sont realisees a Paide des fonctions et procedures : encode () calculee par 1'algorithme 1.2.7, decode() calculee
par Palgorithme 1.2.8, et updateQ calculee par 1'algorithme 1.2.9. Ces operations sont presentees dans la partie traitant de la mise en ceuvre.
La fonction de codage encode(), qui associe un code £L un caractere, verifie si Ie caractere existe dans Parbre ou dans la liste des noeuds a poids nuls. Cette liste englobant tous les caracteres a poids nuls est representee dans 1'arbre par un noeud a poids nul. Si la premiere alternative est vraie, Ie code est directement lu sur Parbre. Sinon, Ie code est calcule en fonction des parametres (m, e, r) qui sont determines par resolution de Pequation m = 2e + r (ou m repr^sente Ie cardinal de la Uste des noeuds a poids nuls, (e, r) est la solution de Fequation avec e Ie plus grand possible tel que
2e <= m).
Tout caractere a coder est repr6sente par une lettre Ok (k e [l,n] ou n est Ie cardinal de la liste de Falphabet ^ coder). La lettre Ok est codee sur e +1 bits, comme representation binaire de k — 1 si 1 <= k <= 2r, et sur e bits comme representation binaire de k—r— 1 si k > 2r. Le code final de a/c est precede du code du nosud ^L poids mil.
La procedure de decodage decode() associe un caractere au code lu. La lecture du code se fait bit par bit. II y a deux possibilites, soit la suite de bits lus correspond au code du noeud vide, et dans ce cas il s'agit d'un nouveau caractere dont Ie code est la suite de bits qui succedent au code du noeud vide, soit la suite de bits lus correspond a -un code dans Farbre, et dans ce cas il s'agit d'un caract^re dej^, existant. Le caractere est obtenu a partir de 1'arbre "HufFman".
La procedure de mise a jour update() met a jour 1'arbre, soit en introduisant un uouveau noeud dans 1'arbre, et ce noeud represente Ie dernier caractere code ou decode, soit en incrementant d'une unite Ie poids d'un noeud dej^i existant et cette fois pour augmenter Ie nombre d'occurences du caractere code ou decode. Cette procedure verifie si tous les noeuds sont a leurs positions optimales. Si oui, 1'arbre reste inchange, sinon 1'arbre est modifie. Les noeuds d'un arbre sont a leurs positions optimales si la
liste engendr6e a partir de 1'arbre, en procedant du bas vers Ie haut et de la gauche vers la droite, est une liste croissante.
Un exemple illustrant 1'evolution de Parbre de "HufFman dynamique"
La constante n fbcee au depart, represente Ie cardinal de la liste de 1'alphabet utilisee dans Ie texte a coder, elle est choisie arbitrairement. II serait utile de presenter un exemple de codage "HufFman dynamique" avant d'entamer la partie mise en oeuvre. Dans notre exemple, n = 27, cette valeur est connue par Ie codeur et Ie decodeur, la liste de 1'alphabet utilise est {a,b,c,d,e,...z,!}. II s'agit de coder Ie message abracadabra.
L'etat initial de Parbre (Fig. 1.13) est represente par une branche et un noeud eO, ce noeud eO est unique dans 1'arbre et sa position varie au cours de revolution de Parbre.
.0
0
FIG. 1.13 - Etat initial de 1'arbre
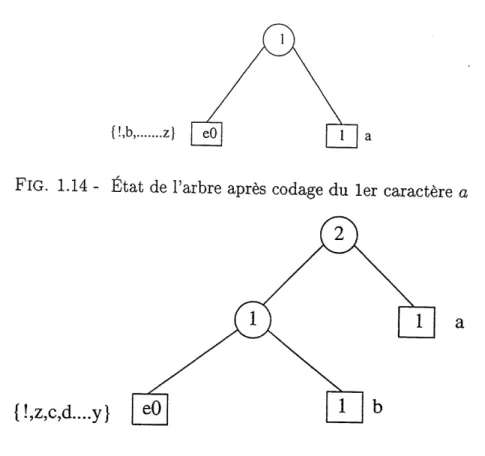
Lecture du caractere : a
Le code associe a a : m=27=24+ll , e=4, r = 11 , a=ai ^ 00000
L'etat de Parbre apres sa mise a jour est represente sur la figure 1.14.
Lecture du caractere : b
Le code associe a b : m=26=24+ 10, e = 4, r = 10, 6=02 -^000001, car Ie code de eO est 0.
{!,b,...z} | eO
I I a
FIG. 1.14 - Etat de Parbre apr^s codage du ler caractere a
2
{!,z,c,d....y}
FIG. 1.15 - Etat de Parbre apres codage du ler caractere b
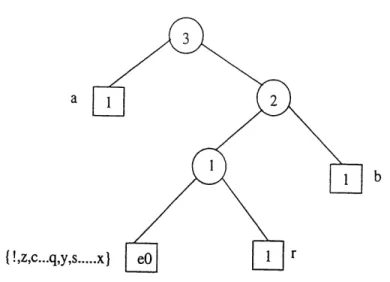
Lecture du caractere : r
Ie code associe ar: m==25=24+9,e=4,r=9,r=ai8—>- 0010001, car Ie code de eO est 00.
L'etat de 1'arbre apres sa mise a jour est represente sur la figure 1.16.
Lecture du caractere : a
D'apres 1'etat courant de 1'arbre, Ie code associe a a —> 0.
L'etat de Parbre apres sa mise a jour est represente sur la figure 1.17.
Lecture du caractere : c
Le code associ^ ac: m=24=24+8,e=4,r=8,c=a3^- 10000010, car Ie code de eO est 100.
{!,z,c...q,y,s...x}
FIG. 1.16 - Etat de 1'arbre apres codage du ler caractere r
(!,z,c...q,y,s...x)
FIG. 1.17 - Etat de 1'arbre apres codage du 2ieme caractere a
L'etat de 1'arbre apres sa mise EL jour est represente sur la figure 1.18.
Lecture du caractere : a
D'apres Petat courant de 1'arbre, Ie code associe a a —>• 0.
L'etat de 1'arbre apres sa mise ^b jour est represente sur la figure 1.19.
Lecture du caractere : d
2
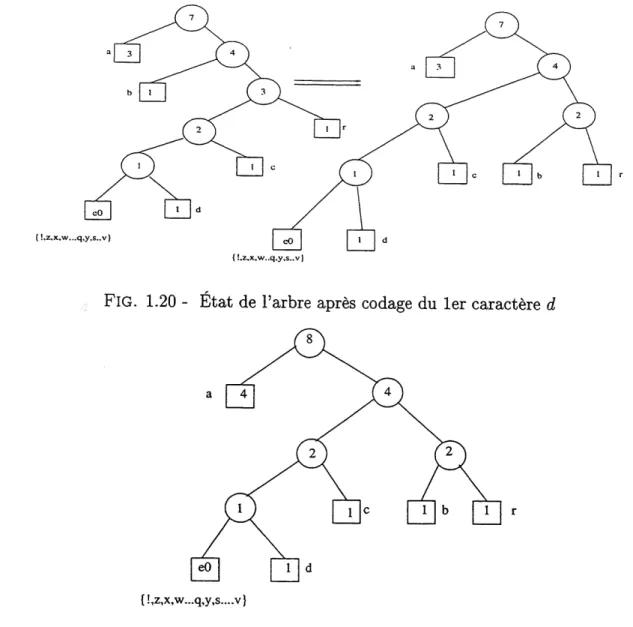
b 1
(!,x,,x...q.y,s...w)
FIG. 1.18 - Etat de 1'arbre apres codage du ler caractere c 6
{!,z,x,d....q,y,s...w} | s0
FIG. 1.19 - Etat de 1'arbre apres codage du 3ieme caractere a
de eO est 1100.
L'etat de 1'arbre apres sa mise a jour est represente sur la figure 1.20.
Lecture du caractere : a
D'apres Fetat courant de 1'arbre, Ie code associe ^ a —^ 0.
L'etat de Parbre apres sa mise a jour est represente sur la figure 1.21.
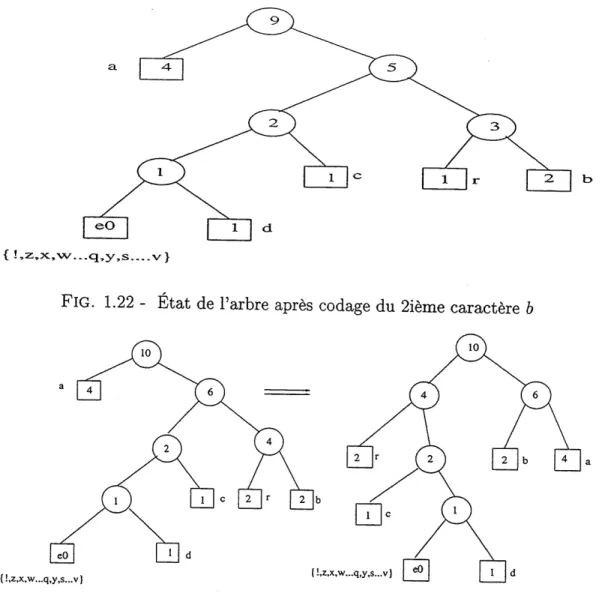
Lecture du caractere : b
eO
I
I c
(!,z,x.w...q,y,s..v) cO
I
1 d
I c I I
(!,z,x,w.,q,y.s..v)
FIG. 1.20 - Etat de Farbre apres codage du ler caractere d
1 |c I 1 I b | I | r
{!,z,x,w...q,y,s....v}
FIG. 1.21 - Etat de 1'arbre apres codage du 4ieme caractere a
D'apres Petat courant de 1'arbre, Ie code associe a b -> 110.
L'etat de 1'arbre apres sa mise a jour est represente sur la figure 1.22.
Lecture du caractere : r
D'apres Petat courant de 1'arbre, Ie code associe ^ r —> 110.
L'etat de 1'arbre apres sa mise £L jour est represente sur la figure 1.23.
1 d
I c 1 r 2
{ !,z,:K,w...q,y,s....v}
FIG. 1.22 - Etat de Parbre apres codage du 2ieme caractere b
Ib C.Z.X.l |r 1 y,s.. c V) 2 eO 1 |d {!,z,x,w...q,y,s...v}
FIG. 1.23 - Etat de Parbre apres codage du 2ieme caractere r
D'apres 1'etat courant de 1'arbre, Ie code associe a a —?• 0.
L'etat de Parbre apres sa mise a jour est represente sur la figure 1.24.
Mise en oeuvre
Des structures de donnees sont utilisees pour realiser les operations de compression et de decompression. Elles representent 1'etat de 1'arbre (c'est-a-dire Ie poids de chaque noeud, Fassociation entre un caractere et un noeud, et d'autres informations reliees
{!,z,x,w...q,y,s...v}
FIG. 1.24 - Etat de Parbre apres codage du 5ieme caractere a
^ 1'arbre). Des fonctions et procedures sont utilisees pour realiser les operations de compression et de decompression, ou chaque procedure ou fonction realise une tache determinee.
Cette section consiste a presenter 1'algorithme de compression 1.2.4 et Falgorithme de d^compression 1.2.5, ainsi que les procedures et fonctions invoquees par ces derniers. Les structures de donn6es et variables sont presentees ci-dessous:
int n : la fcaille de 1'alphabet utilise dans les fichiers a compresser ou 21 decompresser.
unsigned int S[Sdim] : un tableau qui transporte 1c code de chaque caractere (une
suite de bits 0 et 1);
int Sdim : la dimension du tableau S [].
struct doimee{
int M : Ie nombre de caracteres ^ poids mil (c'est-a-dire Ie cardinal de la liste des
poids nuls);
int R : la solution de 1'equation M = 2E + R;
int Z=2n-l : Ie numero du noeud qui est racine de 1'arbre;
int H : Ie numero du bloc de plus petit poids (un bloc regroupe un ensemble de noeuds de meme poids, tous les noeuds de Farbre sont regroupes en blocs );
int A[n+1] : la representation d'un caractere dans 1'arbre (c'est-a-dire Ie numero du noeud associe au caractere dans 1'arbre);
int C [2*n] : contient les numeros des noeuds fils dans 1'arbre, par exemple, si k est un noeud interne, et si les num^ros des noeuds fils sont 2j - 1 et 2j alors C[k] = j: cependant si k est un noeud externe alors 11element du tableau represente la ler.tre a'c[k] ;
int L[2*n] : un element L[k] de ce tableau d6signe Ie numero du bloc, Ie plus
proche du bloc k et de plus petit poids;
int G[2*n] : un element G[k] de ce tableau d^signe Ie numero du bloc, Ie plus
proche du bloc k et de plus grand poids;
int W[2*n] : un element de ce tableau, par exemple W [k], contient Ie poids du bloc
k;
int D [2*n] : un element de ce tableau, par exemple D [k], designe Ie noeud qui a Ie plus grand numero dans Ie bloc k;
int P[n+l] : contient les numeros des noeuds peres dans 1'arbre, par exemple Ie noeud pere des noeuds 2j-l et 2j est Ie noeud P[j];
int B[2*n] : tous les noeuds de meme poids out la meme valeur B[j], avec j Ie
numero d?un noeud;
}:
Algorithme 1.2.4 fonction de compression: beein int c, nbbitecriTe, k\ call initialise;ouverture du fichier a compresser-,
ouverture du fichier de sortie;
for (k = 0; k < Sdim; k + +) do
S[k] = 0;
od;
while (c caractere lu sur fichier d'entree -^ EOF) do
fe=(c+l);
nb_bit_ecrire = call encode(Jc); call update(k}-,
od;
if (nb_ bit_ecrire ^ 0)
then
ecriture sur fichier de sortie un octet du tableau 5Q;
fi;
end
L'algorithme de decompression 1.2.5 decompresse un fichier pour restituer Ie fichier texte d'origine.
Algorithme 1.2.5
fonction de decompression: begin
ouverture du fichier d'entree;
copier Ie fichier d'entree dans un tableau d'entiers'^ ouverture du fichier de sortie;
call initialise'^ call decode; end
La procedure d'initialisation (ALG. 1.2.6) initialise les structures de donnees avant de demarrer Poperation de compression et de decompression.
Algorithme 1.2.6
la fonction d initialisation des structures de donnees : beein int i\ M =0; E=Q\ R= -1; ^ = 2 * n - 1; for (i = 1; i <= n; z + +) do M=M+1; R=R+1; if (2 * A == M) then £7+=1; ^=0;
fc
A[i\ = i; C[i\ = n
od;H = 1; L[H] = H; G[H] = H; W[H] = 0; D[H] = Z; A[0] = Z\ V =2;
for (i = V; i <= Z - 1; i + +) do G[i} ==?+!; od;G[Z] = 0; P[n] = 0; C[Z] = 0; B[Z] = ff;
endLa fonction de codage encode() (ALG. 1.2.7) code la lettre a^ en se basant sur 1'etat
Algorithme 1.2.7
int encode(int k) :
begin
int j, g, t, ind, decalage, nb bit; static int i = 0;
int w=288, nb bit_ total, nb bit code, bit ecr, bit lee, ind lee, ind ecr;
unsigned int bit = 0,code = Q,Sl[Sdim];
for (j = 0; ; < Sdim; j + +) do Sl\j] = 0, od; q = A[k]; if (g <= M) then g=g-l; if (g < 2 * 2?)) then t=B+l; else q =q-R; t= E; fi; for {j = 1; j <= t; j + +) do
bit = q%2; ind = (w - 1)/32; decalage = (32 * (znd+ 1)) - w;
Sl[ind} = (Sl[ind] | (bit < decalage));
w- -; q = (g/2); od;
9=A[0];
fi;
while {q < Z) do
bit = (g + l)51[md] = (S'l[m<| | (bit < decalage}}-, w - -;
g=P[(g+l)/2];
od;
nb_bit_code = (288-w); bit_ecr = (i+1); bit_lec = (w+1);
while {bit_lec < 288) do
lnd_lec = (bj't_7ec - 1)/32; decalage = (32 * (Jnd_Jec +1)) - b'it_lec)\ bit = (Sl[ind_lec] » decalage)& 1; ind_ecr = (bit_ecr - l)/32; decalage = (32 * (ind ecr + 1)) — bit ecr;
S[ind ocr] = S[indecr]) | (bit <^ decade);
bit lec++; bit ecr++; od;
nb_ bit_ total = (i + nb_bJt_code); if ({nb_bit_total%8) == 0)
then
write(desc,S,nb bit total/8); i = 0;
for {] = 0; j < Sdim; j + +) do S[j]=0; od; else if {nb_bit_total > 8) then write{desc, (ptr— > 5),jib_bit_totaJ/8);
i = (nb_bit_tota.l%S); bit_lec = 1 + (nb_ bit_ total - i}; w = 1; nb bit = 0;
while (nb bit < z) do nb bit++;
ind = (bit_lec - l)/32; decalage = (32 * (md+ 1)) - bit_lec; bit = {S[ind\ » decalage)^.!; blt_lec++;
decalage = (32 — w); code = code | (&zt ^. decalage); w + +; od; for {j = 0; j < Sdim\ j + +) do 5[7]=0; od; S[0] = code; else i= nb bit total; fi; ft; return i; end
La procedure de decodage decode() (ALG. 1.2.8) a Ie meme principe que celui de la fonction encodeQ (ALG. 1.2.7), mais en sens inverse.
Algorithme 1.2.8
decode(unsigned int * ptr, unsigned int dernier) :
begin
int j, indice, decalage, k, kl, bit a lire=l; unsigned int bit, q; char K\
while (bit a lire <^ dernier) do q=Z;
while (bit a lire <; dernier A A[CI[g]] ^ q) do
indice = bit_a,_lire-l/22;
decalage = {{indice + 1) * 32) — bit_a,_lire-,
bit = {ptr[indice] S> decaZage)&l;
q = ((2 * C[q\) - 1) + bit; bit_a_lire + +;
od;
if(C'[g] == 0 A bit a lire <= dernier)
then
9=0;
for (j = 1; j <== E A bit a lire <= dernier; j + +) do indice = bit a lire-1,32;
decaiage = {{indice + 1) * 32) — bit_a_lire; bit = (ptr[indice] ~^> decalage)&il;
q= ((2 *q)+ bit); bit_a,_lire + +; od;
if (g < R A bit_a_lire<=dernier) th^n
indice -= bit_a._lire-l/32,
decalage == ((zndice + 1) * 32) — bit a Hre\ bit = {ptr[indice] :» decalage)^.!;
q= ((2 *q) + bit); bit_a_lire + +; g = (g + 1); else q= q+R; q=q+l; fi; if (<? >. 1 A <7 ^ M) then A;l=l; while (A[kl] ^ q) do kl + +; od; k=kl; else
print("q n'est pas comprise entre [1 et M/");
fc
else if (g >= 0 A q <= (2 * n) - I) then fc=C[g]-, fi; fi; if (fc ^ 1 A k<, 256) then K=k-l; write(descl,&Jf,l); call update(A;); k = 0;fc
od; endAlgorithme 1.2.9 update(int k) : begin int q; q = call set _ q(fc); while {q > 0) do q = call move_q(g); q = call transfer _q{q)'i
<?=P[(g+l)/2];
od; end
La fonction set-q() (ALG. 1.2.10) afFecte ^ la variable q, soit Ie numero du noeud qui correspond fi la lettre ajfc, soit Ie rang de la lettre a,k dans la liste des poids mils. Dans ce deruier cas un nouveau noeud terminal de poids mil est ajoute ^ 1'arbre, ainsi qu'un
nouveau noeud non termiual. AIgorithme 1.2.10 int set-q(int k) : begin int g;
g=A[fc];
If {q <= M)
thenA[C[M]]=q;C[q]=C[M^
if {R == 0)
thenR = M/2;
if {R > 0)
then E-=l;fi;
fi;
M- = 1; R- = 1;if (M > 0)
thenq = A[0] - 1; A[0] = q - 1; A[k] == q; C[q] = k;
if (M > 1)
then €'[<?-1]=0;fi;
P[M] =(q+ 1); C[q + 1] = M; B[g] = ff;
B[q-l]=H;fi;
&
return g; end(c'est-a-dire Ie plus grand numero sera afFecte au nceud q), a moins que Ie noeud q et son pere ne soient deja a Pextreme droite. Cette fonction invoque la procedure exchange (ALG. 1.2.12). Algorithme 1.2.11 int move-q(mt q) : begin
!f (g < D[B[q\] A £)[B[P[(g + 1)/2]]] > q + 1)
thencall exchange^, D[B[q]});
q = D[B[q}];
fi;
return q; endLa procedure exchange() (ALG. 1.2.12) ^change deux sous-arbres de m^me poids.
Algorithme 1.2.12
exchange(int q, int t) :
beein
int ct, eg, acq;
ct = C\t}\ cq = C[q]; acq = A[c<f];
lf(A[ct]!=t)
thenP[ct] = q;
elseA[ct] = g;
&
if (acg! = 9) then P[cq] = (; elseA[cq] = t;
fi;
C[t] = cq; C[q] = ct;
endLa fonction transfer-q() (ALG. 1.2.13) transfere Ie noeud q au bloc Ie plus proche du bloc auquel appartient Ie noeud q et de poids superieur.
Algorithme 1.2.13 int transfer-q(int q) : beein
int j, u, gu, lu, x,t, qq\
u = B[q}\ gu = G[u}\ lu = I/[u], a; = W[u]; 99 = I?[uj; if (W[gu] == x + 1)
then
B[q] = gu; B[qq] = gu;
if {{D[lu] ==q- 1) V {u==H A q == A[0]))
then
G[lu] = gu\ L[gu] == lu;
if(fi-==u) then H ==gu;
fi;
G[u] =V;V=u; else D[u} =g-l;fi;
else If {{D[lu} ==?-!) V (u == H A ^ === A[0])) then W[u] = x + 1; else t= y; v = qv]; L[t] = u; GM = gu; L[gu] = t; C?H = <; W[t] = x + 1; £>% = D[u]; £»M = q - 1; 5[g] = t; B[qq\ = t;fi;
fi;
<1=W; return g; end1.2.4 I/algorithme de compression LZW
IntroductionLa version originale de Palgorithme LZW est presentee dans [3] et [4]. Lors de la
presentation de 1'algorithme LZW, nous nous sommes inspires de Particle [11]. L'al-gorithme de compression LZW 1.2.14 est organise autour d7une table de translation, appelee aussi table chame. Cette table associe ^ une chaine de caracteres un code de longueur fixe, Ie code utilise est de longueur 12 bits. La propriete de ce code est que Ie prefixe de chaque chaine dans la table est une chaine qui existe aussi dans la table. Autrement dit, si la chaine wk, composee de la chatne w et du caractere k, existe dans
la table, alors w existe aussi dans la table, et k est appele Ie caractere cT extension de la chame wk. Au depart, la table est initialisee pour contenir toutes les chaines a un seul caractere. La table est construite pendant Poperation de compression, et evolue tout au long de cette operation. Cette table est constituee de chames deja rencon-trees dans Ie message a compresser. Lorsqu'une nouvelle chaine est rencontree dans Ie message a compresser, elle est ajoutee a la table. Un identificateur unique appele code est associe a cette chaine. Les codes sont assignes en sequences aux nouvelles chaines. La table associee a 1'exemple suivant est illustree sur la figure 1.25.
Mise en ceuvre
Le prmcipe de Palgorithme de compression LZW est explique ci-dessous et mis en
oeuvre dans 1.2.14.
1. La table est initialisee pour qu'elle contienne toutes les chames ^ un seul
carac-tere.
2. Le premier caractere est lu et sauv6 dans w (w est appele prefixe).
3. S'il n'y a pas de caractere suivant, on finit. Sinon, Ie caractere suivant est lu et sauv6 dans k. Deux cas sont alors possibles :
• ler cas : Soit wk existe dans la table, et alors wk devient prefixe, elle est
sauvee dans w. goto 3.
• 2ieme cas : Soit wk n'existe pas dans la table, et alors Ie code de w est ecrit sur Ie fichier de sortie. wk est insere dans la table, k devient prefixe, elle est sauve dans w. goto 3
Algorithme 1.2.14
algorithme de compression LZW : begin
Initialiser la table afin quelle contienne les chaines a un seul caractere; Lire Ie premier caractere de la chaine d entree;
chatne prefixe w == Ie premier caractere de la chaine dentree; PAS : lire Ie prochain caractere k;
if (pas de k {entree epuisee)}
then
ecrire code (w) sur fichier sortie; exit;
fi;
if (wk existe dans la table chalne) then
w = wk; repeter PAS;
else
ecrire code (w) sw fichier sortie; ajouter wk a table c/iatne; w = A;
repeter PAS;
fi;
end
Exemple
Soit ababcbabababaaaaaaa une chalne de symboles a compresser. Cette chaine utilise 3 caracteres : a,b et c. La table de la figure 1.25 est initialisee avec les codes: 1,2 et 3 de ces 3 caracteres. Le code 1 pour Ie caractere a, Ie code 2 pour Ie caractere b et Ie code 3 pour Ie caractere c. Les codes assignes aux nouvelles chaines, EL inserer dans la table (Fig. 1.25), seront attribues dao5 1'ordre sequentiel (c'est-a-dire Ie code de la nouvelle chame inseree dans la table sera 4 et ainsi de suite). La chaine de caracteres est lue de la gauche vers la droite.
• Lire Ie ler caractere a de la chaine et Ie sauver dans w. Lire Ie 2ieme caractere b de la chaine et Ie sauver dans k.
• Verifier si la chaine ab existe dans la table (Fig. 1.25). Ce n'est pas Ie cas, ecrire done Ie code 1 du caractere a sur Ie fichier de sortie, ajouter la chaine ab a la table (Fig. 1.25) avec Ie code 4, et sauver Ie dernier caractere lu dans w, d'ou
w = b.
La nouvelle chame commence done par Ie prefixe w = b. Lire Ie 3ieme caractere a (k = a), verifier si la chame ba existe dans la table (Fig.1.25). Ce n'est pas Ie cas, ecrire alors Ie code 2 du caractere b sur Ie fichier de sortie, ajouter la chaine ba ^ la table (Fig. 1.25) avec Ie code 5, et sauver Ie dernier caractere lu dans w,
d'ou w == a.
La nouvelle chame commence par Ie prefixe w = a. Lire Ie 4ieme caractere 6 (k = 6), verifier si la chame a6 existe dans la table (Fig. 1.25). C'est Ie cas,
sauver alors la chame ab dans w, d'ou w = ab.
Lire Ie 5ieme caractere c (k = c) de la chaine, V^rifier si la chatne abc existe dans la table (Fig. 1.25). Ce n'est pas Ie cas, ecrire Ie code 4 de la chame ab sur Ie fichier de sortie, ajouter la chaine abc b la table (Fig.1.25) avec Ie code 6, et
sauver Ie dernier caract^re lu dans w, d'ou w = c.
Le meme processus est repet6 jusqu'a obtenir Ie message compresse (Fig.1.26).
1.2.5 L?algorithme de decompression LZW
Introduction
L'operation de decompression est necessaire pour recuperer Ie message d'origine. La d6compression LZW calculee par 1'algorithme 1.2.15 utilise la m^me table que celle de la compression. Cette table est construite au fur et a mesure que Ie message compresse est transmis. Chaque code re^u est translate en un prefixe et un caractere d'extension. Le prefixe est decompose lui aussi en un prefixe et une extension. Cette operation de decomposition est repete jusqu5^, reduire Ie prefixe a un caractere unique. La mise a jour de la table est faite pour chaque nouveau code re^u, excepte Ie premier. Lorsqu'un nouveau code est re<;u, une nouvelle chame est ajoutee ^ la table. Cette
chame a
b
cab
ba
abccb
bab
baba
aa 0,0,0, aaaa code1
2
3
4
5
6
7
8
9
10
11
12
FIG. 1.25 - Table chaine
nouvelle chaine est constituee d'un prefixe qui est Ie code precedent re^u, et d une extension qui est Ie caractere final a 1'extreme gauche du code precedent. A cette nouvelle chaine est assignee un code unique qui est Ie meme que celui qui lui est assignee lors de la compression.