Audio watermarking via EMD
Texte intégral
Figure
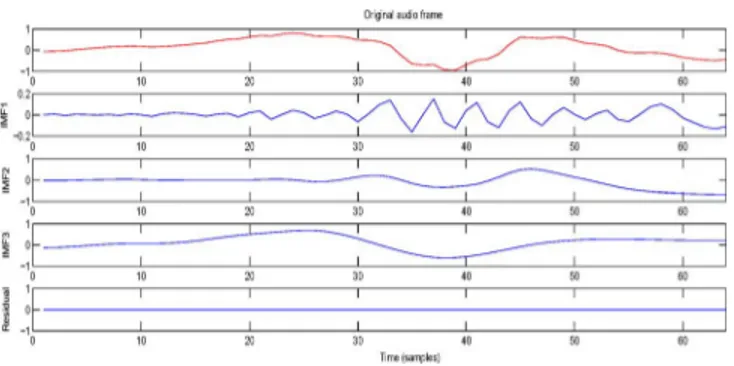
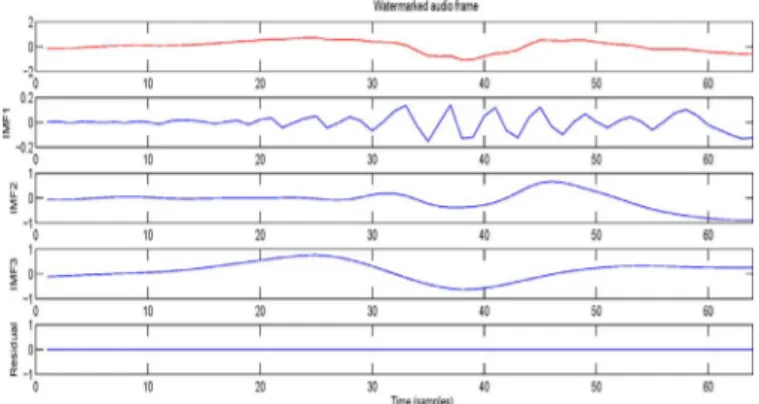
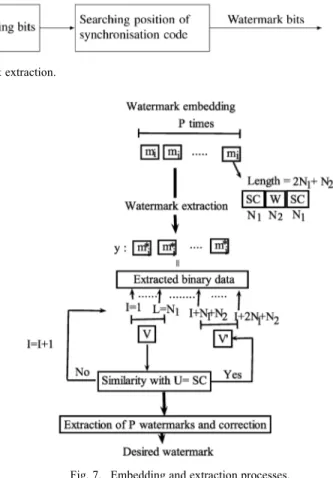
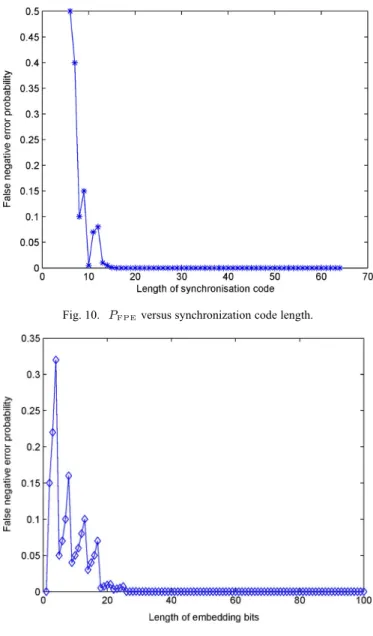
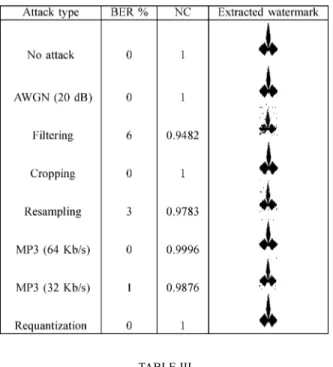
Documents relatifs
Based on the analyzed mono audio signals, the obtained results show that the proposed coding scheme outperforms the MP3 and the wavelet-based coding methods and performs slightly
Pour identifier les activités d’un groupe d’acteurs spécifique, il suffit simplement de “superposer“ l’ensemble des processus, puis de “découper“, dans
Esta vez, Ruiz Pérez acomete la tarea respaldado por un impresionante equipo de cervantistas de tan diversa procedencia e in- tereses que el volumen se puede
(16a) (16b) Desynchronization experiments, including real audio signals sampled at 44.1 kHz show that is most of the time very close to unity and that for a jitter square deviation ,
Leptin induces cell migration and the expression og growth factors in human prostate cancer cells. Vascular endothelial growth factor and its correlation with angiogenesis and
Following the methodology of existing datasets, the GAD dataset does not include the audio content of the respective data due to intellectual property rights but it includes
iPBA: a tool for protein structure comparison using sequence alignment strategies.: Structural Al- phabet Alignment... iPBA: a tool for protein structure comparison using
In this paper, we propose using speculation to unleash the parallelism when it is uncertain if some tasks will modify data, and we formalize a new methodology to enable
