© Gabriel Frazer-Mckee, 2020
The semantics and pragmatics of proper names in
adverbial degree constructions in English : A
corpus-driven contribution
Mémoire
Gabriel Frazer-Mckee
Maîtrise en linguistique - avec mémoire
Maître ès arts (M.A.)
The semantics and pragmatics of proper names in adverbial
degree constructions in English: A corpus-driven contribution
Mémoire
Gabriel Frazer-McKee
sous la direction de:
iii
RÉSUMÉ
Ce mémoire est une contribution empirico-théorique à l'étude des constructions de degré nominaux-adverbes (anglais : ANDC) -constructions mettant en vedette des formes nominales plutôt que des adjectifs (ce bar fait très San Francisco). Située globalement dans le cadre de la linguistique cognitive, notre étude -la première étude quantitative sur corpus portant sur ces objets- examine le sens en usage de 4 noms propres (environ 1500 tweets) provenant de quatre catégories ontologiques : LIEU, TEMPS, PERSONNE et FILM. Si plusieurs modèles ont déjà été proposés pour rendre compte des ANDC, trois de nos résultats empiriques soulignent la nécessité d'une explication alternative. Premièrement, il n'y a aucune raison de croire que les noms propres dans les ANDC sont nécessairement adjectivaux, car 1) presque tous les diagnostics classiques pour l'adjectivalité admettent de vrais SNs; et 2) les noms propres dans les ANDC présentent des caractéristiques nominales (par exemple, la référence anaphorique). Deuxièmement, les ANDC génèrent des interprétations qui ne peuvent pas être expliquées par les modèles existants. Outre la notion de comparaison (votre sourire fait très Mona Lisa), les ANDC expriment la typicalité (la pizza, c’est très New York), l'inclinaison (je suis d'humeur très Harry Potter) et la quantification (2017 a été très Kurt Cobain), pour ne nommer que ceux-ci. Enfin, loin de se lexicaliser, les noms propres sont exploités dans les ANDC pour leur potentiel encyclopédique, étant utilisés pour évoquer pratiquement n'importe quelle structure encyclopédique (graduelle ou non) située dans le réseau encyclopédique du signe nominal (C’est très Harry Potter → emplacements / personnages / accessoires / météo / musique / intrigue des films Harry Potter). Nous réconcilions ces divers faits en proposant qu’un SN peut participer dans un ANDC comme 1) point d'accès à un réseau de connaissances qui 2) s'associe au cours du processus de combinaison conceptuelle à une échelle R qui est significative, graduelle et pragmatique. C'est R qui est intensifié plutôt que le nom propre en tant que tel.
iv
ABSTRACT
This thesis is an empirical and theoretical contribution to the study of Adverb-Nominal Degree Constructions (ANDCs) –adverbial degree constructions featuring nominal forms rather than adjectives (e.g. That is so you; This bar is very San Francisco). Situated broadly within the framework of Cognitive Linguistics, our study –the first large corpus-based investigation into ANDCs— investigates the expressed meaning of four proper names (1,500+ usage events) from four ontological categories: PLACE, TIME, PEOPLE, and FILM. While several competing models have already been proposed to handle ANDCs, three of our empirical findings highlight the need for an alternate account. Firstly, there are no grounds on which to claim that proper names in ANDCs are necessarily adjectival, as 1) almost all classic diagnostics for adjectivehood actually admit true N(P)s; and 2) proper names in ANDCs exhibit nouny characteristics (e.g. anaphoric binding). Secondly, ANDCs yield interpretations that cannot be accounted for by existing models. In addition to comparison (e.g. Your smile is very Mona Lisa), ANDCs express typicality (e.g. Pizza is very New York), inclination (e.g. I am in a very Harry Potter mood), and quantification (e.g. 2017 has been very Kurt Cobain), amongst others. Lastly, far from lexicalizing, proper names are exploited in ANDCs for their encyclopaedic potential, typically being used to metonymically evoke virtually any knowledge structure (gradable or otherwise) in the nominal sign’s encyclopaedic network (e.g. It’s very Harry Potter → locations / characters / props / weather / music / plot points from the Harry Potter films). We reconcile these observations by proposing that true N(P)s can participate in ANDCs as 1) access points to knowledge networks that 2) become associated with a meaningful, gradable, pragmatic scale R during the process of conceptual combination. It is R that is intensified rather than the N(P) itself.
v
TABLE OF CONTENTS
RÉSUMÉ ... iii ABSTRACT ... iv TABLE OF CONTENTS ... v LIST OF FIGURES ... xiLIST OF TABLES ... xiii
LIST OF ABBREVIATIONS ... xv
ACKNOWLEDGEMENTS... xvii
INTRODUCTION ... 1
CHAPTER 1 HOW DO N(P)s AND DEGREE ADVERBS INTERACT?... 10
1.1 Introduction ... 10
1.2 Can (degree) adverbs interact with nominals? ... 10
1.2.1 The complementarity claim ... 11
1.2.2 Theories that predict nominal-(degree)-adverb non-interaction ... 13
1.2.2.1 The Theory of Incidence ... 13
1.2.2.2 The Degree Approach ... 14
1.2.3 Challenging the complementarity claim: Recent empirical findings ... 16
1.2.3.1 Other “degree adverb + nominal” constructions ... 16
1.2.3.2 The adverbial degree intensification of (true?) N(P)s ... 18
vi
1.3.1 The boundedness hypothesis ... 32
1.3.2 The override hypothesis ... 35
1.3.3 The (non-)lexical scale hypothesis ... 41
1.3.4 The quantificational hypothesis ... 45
1.3.5 The enriched composition hypothesis ... 48
1.4 How empirically adequate are current accounts? ... 53
1.4.1 The attraction problem ... 57
1.4.2 The logical non-equivalence problem ... 58
1.4.3 The comparison-by-analogy problem ... 61
1.4.4 The outcomes problem ... 64
1.5 Summary of Chapter 1 ... 65
CHAPTER 2 THE CATEGORY STATUS OF THE FORMS IN ANDCs ... 68
2.1 Introduction ... 68
2.2 The diagnosis of category status in Linguistics ... 69
2.2.1 The Distributional Method (DM) ... 69
2.2.2 Applying DM to nominal forms in ANDCs ... 71
2.2.3 Skepticism regarding the diagnostics’ interpretation ... 73
2.3 The hypotheses to be tested ... 75
2.3.1 H1: Recategorization ... 76
2.3.2 H3: Dual-class membership ... 77
2.3.3 H5: Category maintenance ... 78
2.4 Diagnostics for adjectivehood ... 78
2.4.1 Acceptance of un- prefixation ... 81
2.4.2 Acceptance of synthetic degree suffixes ... 82
2.4.3 Attributive and predicative use ... 84
2.4.4 Occurrence after an indefinite pronoun ... 85
vii
2.4.6 Co-occurrence with analytic comparatives and superlatives ... 88
2.4.7 Co-occurrence with adverbial intensifiers ... 89
2.5 Diagnostics for N(P)-hood ... 91
2.5.1 Acceptance of nominal suffixes ... 91
2.5.2 Acceptance of determiners ... 92
2.5.3 Pronoun substitution and anaphoric binding ... 93
2.6 Discussion ... 95
2.7 Summary of Chapter 2 ... 101
CHAPTER 3 PARAMETERS, DATA, AND METHODS ... 102
3.1 Introduction ... 102
3.2 The study’s key parameters... 103
3.2.1 The semantics of degree adverbs ... 108
3.2.2 The semantics of proper names ... 112
3.2.3 Summary of subsection 3.2 ... 119
3.3 The study’s dataset ... 119
3.3.1 Choice of data source ... 121
3.3.1.1 ANDCs in existing corpora ... 121
3.3.1.2 Twitter, the fruitfly of internet data ... 124
3.3.2 Choice of degree adverb ... 128
3.3.2.1 Very, the prototypical degree adverb ... 128
3.3.3 Choice of nominals ... 131
3.3.3.1 The proper names to be investigated ... 132
3.3.4 Usage event selection, exclusion and reproduction criteria ... 136
3.3.4.1 Exclusion criteria ... 136
3.3.4.2 Inclusion and reproduction criteria ... 138
3.3.5 Summary of subsection 3.3 ... 140
viii
3.4.1 Method 1: Encyclopaedic Network Mapping ... 141
3.4.1.1 Step 1: Extraction of knowledge structures from corpus data ... 144
3.4.1.2 Step 2: Construction of a co-occurrence matrix ... 151
3.4.1.3 Steps 3 & 4: Generation and evaluation of the encyclopaedic network .... 152
3.4.2 Method 2: Multifactorial usage-feature analysis (MFA) ... 155
3.4.2.1 Step 1: Identification of outcomes ... 157
3.4.2.2 Step 2: Identification of linguistic usage-features ... 160
3.4.2.3 Step 3: Multiple Correspondence Analysis ... 165
3.4.3 Summary of subsection 3.4 ... 167
3.5 Summary of Chapter 3 ... 168
CHAPTER 4 DATA ANALYSIS ... 169
4.1 Introduction ... 169
4.2 The VERY CELEBRITY construction ... 169
4.2.1 The encyclopaedic network of “Kurt Cobain” ... 170
4.2.2 The observed semantico-pragmatic outcomes ... 173
4.3 The VERY FILM construction ... 177
4.3.1 The encyclopaedic network of “Harry Potter” ... 177
4.3.2 The observed semantico-pragmatic outcomes ... 179
4.4 The VERY TIME construction ... 182
4.4.1 The encyclopaedic network of “1950s” ... 183
4.4.2 The observed semantico-pragmatic outcomes ... 185
4.5 The VERY PLACE construction ... 190
4.5.1 The encyclopaedic network of “New York” ... 190
4.5.2 The observed semantico-pragmatic outcomes ... 192
4.6 The VERY PROPER NAME construction: general observations ... 196
4.6.1 The encyclopaedic networks of proper names ... 197
ix
4.7 Summary of Chapter 4 ... 204
CHAPTER 5 TOWARDS A MODEL OF CONCEPTUAL COMBINATION ... 206
5.1 Introduction ... 206
5.2 ANDCs seen through Marr’s Tri-level Hypothesis ... 206
5.2.1 The computational level of ANDCs ... 207
5.2.2 The algorithmic level of ANDCs ... 209
5.3 What a new algorithmic model must (not) do ... 210
5.3.1 The model’s (current) scope ... 210
5.4 Solving the revised scalarity requirement ... 215
5.4.1 The case of NN compounds ... 216
5.4.2 The case of predicated N(P)s... 219
5.5 Congruence with existing theories ... 221
5.5.1 The semantics-pragmatics boundary ... 223
5.5.2 The process of conceptual combination ... 227
5.6 Summary of Chapter 5 ... 229
CHAPTER 6 LOOKING BACK, LOOKING FORWARD ... 231
6.1 Introduction ... 231
6.2 Revisiting the thesis’ objectives ... 231
6.2.1 The evaluational objectives ... 232
6.2.2 The observational objectives ... 235
6.2.3 The theoretical objectives ... 236
6.3 Limitations and future research avenues ... 237
6.3.1 The study’s limitations ... 237
6.3.2 Intra-linguistic research avenues ... 240
6.3.3 Inter-linguistic research avenues ... 241
CONCLUSION ... 244
x
ANNEX A ... 270
ANNEX B ... 271
ANNEX C ... 278
xi
LIST OF FIGURES
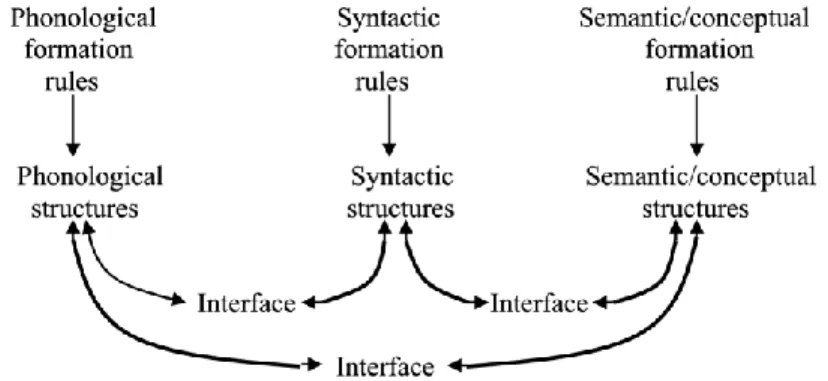
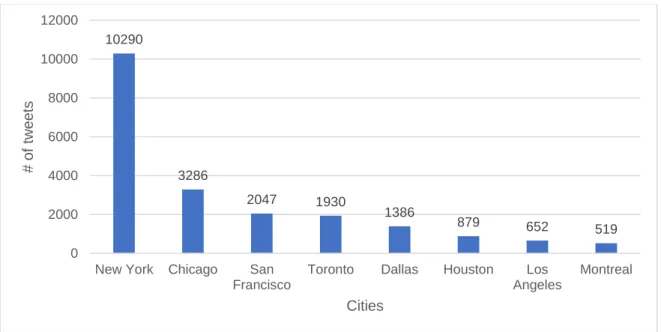
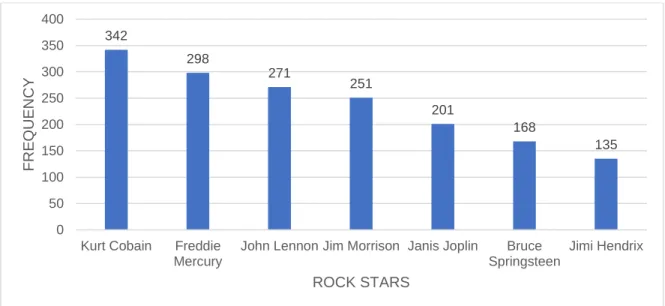
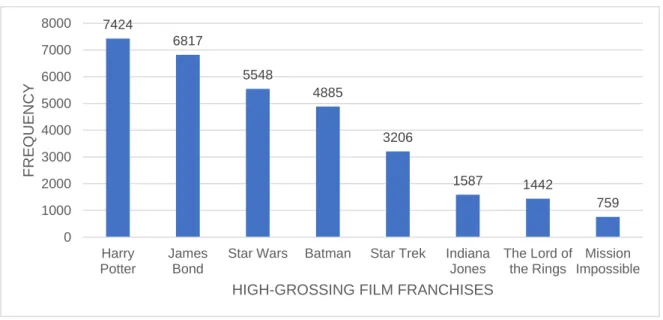
Figure 1.1 The degree saturation of a gradable predicate ... 15 Figure 1.2 The box representation o the DEGREE ADVERB + N(P) constructionCxG ... 40 Figure 1.3 Nominal elements as NPs in a DegP structure, according to Sant (2018) ... 46 Figure 1.4 The Tri-Partite Parallel Architecture (reproduced from Jackendoff & Audring, 2019) ... 51 Figure 3.1 Common ontological categories of the proper names participating in ANDCs in COCA (1990-2017) that feature either the degree adverb too, so or very .... 130 Figure 3.2 Absolute frequency of a subset of city names participating in VERY CITY in raw Twitter data (2007-2017) ... 133 Figure 3.3 Absolute frequency of a subset of rock star names participating in VERY CELEBRITY in raw twitter data (2007-2017) ... 134 Figure 3.4 Absolute frequency of a subset of decades participating in VERY DECADE in raw Twitter data (2007-2017) ... 134 Figure 3.5 Absolute frequency of a subset of high-grossing film franchises participating in VERY MOVIE in raw Twitter data (2007-2017) ... 135 Figure 3.6 Schematization of the process of creating a semantic network from raw linguistic data ... 143 Figure 3.7 The unweighted encyclopaedic network of EINSTEIN ... 152 Figure 3.8 Schematization of the multifactorial usage-feature analysis method... 156 Figure 3.9 Examples of the basic-level categories of the DULCE ontology (reproduced from Gangemi et al., 2002) ... 165 Figure 3.10 Conceptualization of the biplot’s sample space ... 167 Figure 4.1 Themes evoked by VERY KURT COBAIN in a sample of Twitter data ... 170
xii
Figure 4.2 The encyclopaedic network of KURT COBAIN in a sample of Twitter data (2007-2017) ... 171 Figure 4.3 Rank-frequency distribution of KURT COBAIN’s knowledge structures in a sample of Twitter data (2007-2017) ... 172 Figure 4.4 Symmetric correspondence biplot of the expressed meanings and other linguistic usage features of VERY KURT COBAIN ... 176 Figure 4.5 Themes evoked by VERY HARRY POTTER usage events in Twitter data ... 177 Figure 4.6 The rank-frequency distribution of HARRY POTTER’s knowledge structures in a sample of Twitter data (2007-2017) ... 178 Figure 4.7 The reduced encyclopaedic network of HARRY POTTER, based on a sample of Twitter data (2007-2017) ... 179 Figure 4.8 Symmetric biplot of the expressed meanings and usage features of VERY HARRY POTTER in a sample of Twitter data (2007-2017) ... 181 Figure 4.9 Themes evoked by VERY 1950s usage events in a sample of Twitter data .. 183 Figure 4.10 Rank-frequency of the 1950s encyclopaedic knowledge structures in a sample of Twitter data (2007-2017) ... 184 Figure 4.11 The reduced encyclopaedic network of the 1950s, based on a sample of Twitter data (2007-2017) ... 185 Figure 4.12 Symmetric biplot of the expressed meanings and usage features of VERY 1950s in a sample of Twitter data (2007-2017) ... 187 Figure 4.13 Symmetric biplot of the expressed meanings and subject- /nominal
head-specific features of VERY 1950s in a sample of Twitter data (2007-2017) ... 189 Figure 4.14 Rank-frequency of New York’s encyclopaedic knowledge structures in a sample of Twitter data (2007-2017) ... 190 Figure 4.15 Rank-frequency of NEW YORK’s encyclopaedic knowledge structures in a sample of Twitter data (2007-2017) ... 191 Figure 4.16 The reduced encyclopaedic network of NEW YORK in a sample of Twitter data (2007-2017) ... 192 Figure 4.17 Symmetric biplot of the expressed meanings and other usage features of VERY NEW YORK in a sample of Twitter data (2007-2017) ... 194 Figure 4.18 Symmetric biplot of the expressed meanings and select usage features of VERY NEW YORK in a sample of Twitter data (2007-2017) ... 195
xiii
LIST OF TABLES
Table 1.1 A formally valid and a formally invalid syllogism ... 60
Table 1.2 A formally valid and sequentially invalid syllogism ... 61
Table 3.1 Totality modifiers and scalar modifiers combined with levels of degree (reproduced from Paradis, 2001) ... 109
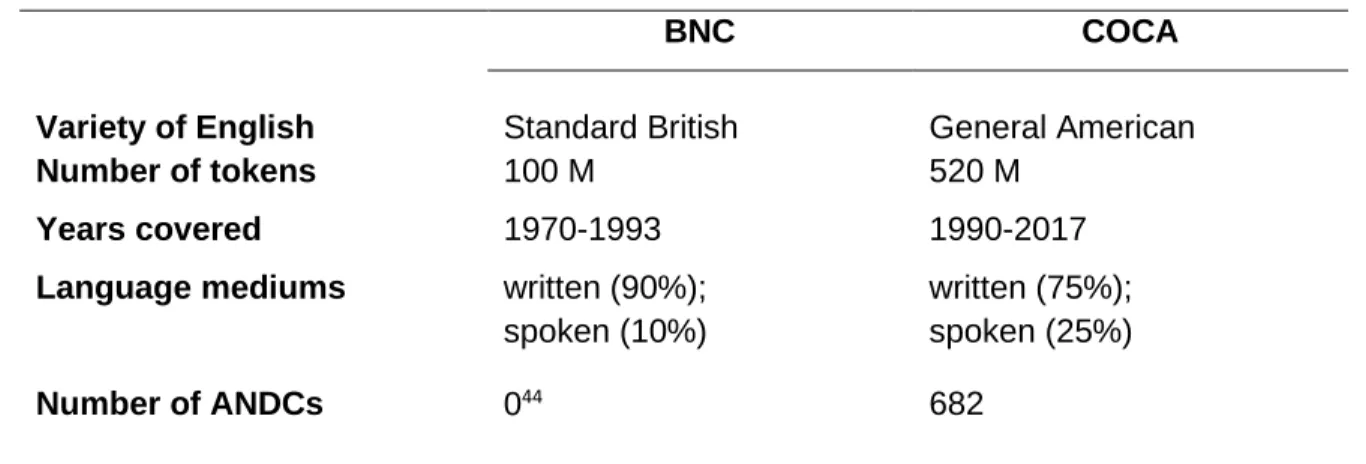
Table 3.2 Absolute frequency of ANDCs in two commercial mega-corpora ... 122
Table 3.3 Ontological categories and subcategories taken into consideration ... 132
Table 3.4 Extracting knowledge structures from raw usage events ... 148
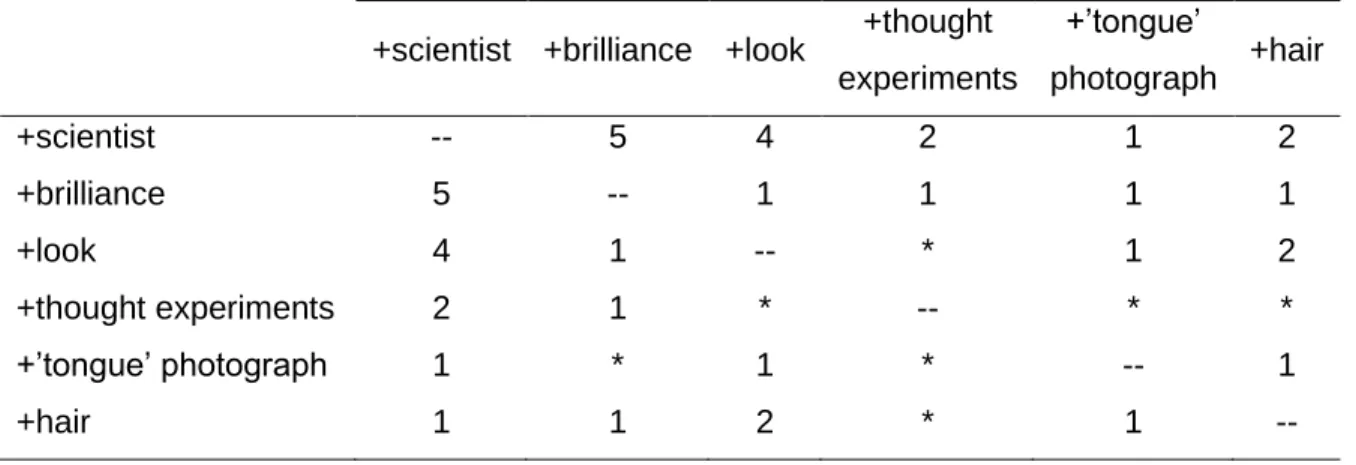
Table 3.5 Co-occurence matrix of six of EINSTEIN’S knowledge structures ... 151
Table 3.6 The schematic paraphrases used to categorize a usage event’s expressed meaning ... 159
Table 3.7 Illustrative examples of the study’s basic-level ontological categories ... 163
Table 4.1 The absolute frequency of the expressed meanings of VERY KURT COBAIN in a sample of Twitter data (2007-2017) ... 173
Table 4.2 The absolute frequency of the expressed meanings of VERY HARRY POTTER in a sample of Twitter data (2007-2017) ... 180
Table 4.3 The absolute frequency of the expressed meanings of VERY 1950s in a sample of Twitter data (2007-2017) ... 186
Table 4.4 The absolute frequency of the expressed meanings of VERY NEW YORK in a sample of Twitter data (2007-2017) ... 193
Table 4.5 The types of expressed meanings observed across four instances of the VERY PROPER NAME construction in a sample of Twitter data (2007-2017)... 199
Table 4.6 The binary cooccurrence matrix of EXPRESSED MEANINGS and SYNTACTIC CONSTRUCTIONS in Twitter data (2007-2017) ... 201
xiv
Table 4.7 The binary cooccurrence matrix of EXPRESSED MEANINGS and frequently occurring VERBS in Twitter data (2007-2017) ... 202 Table 4.8 The binary cooccurrence matrix of EXPRESSED MEANINGS and the subject/head noun’s ONTOLOGICAL CATEGORY in a sample of Twitter data (2007-2017) ... 202 Table 4.9 The binary cooccurrence matrix of EXPRESSED MEANINGS and the subject/head noun’s PERCEIVED SPECIFICITY and DOMAIN-NESS in a sample of Twitter data (2007-2017) ... 203
xv
LIST OF ABBREVIATIONS
** infelicitous/unnatural utterance. Adj(P)
Adjective (Phrase). Adv(P) Adverb (Phrase).ANDC
Adverb-Nominal Degree Construction.API
Application Programming Interface.BNC
British National Corpus.COCA
Corpus of Contemporary American English.Cx
DegAdv+N(P) construction.CxG
Construction Grammar.DegP
Degree Phrase. DM Distributional Method.DOM
Degree of Membership.ENM Encyclopaedic Network
Mapping.
LCS Lexical Conceptual Structure.
LTM
Long-term memory.MFA
Multifactorial usage-feature analysis.MCL
Mainstream
Cognitive Linguistics.MGG
Mainstream
Generative Grammar.NN
noun-noun compound.N(P)
Noun (Phrase).OED
Oxford English Dictionary. PdE Present-day English.PP
Preposition Phrase. R Logico-pragmatic relation. SVO Subject-Verb-Object.xvi
***
To my grandfather, George –who always believed in me
***
xvii
ACKNOWLEDGEMENTS
Printed and bound, this thesis weighs about the same as one of the many large-sized cups of coffee that have fueled my research over the last 4 years. Yet in a very real sense this thesis has been quite a load at times –one whose shouldering was, fortunately, eased by many helping hands, hearts, and minds. I wish here to name and recognize these hands, these hearts, these minds.My thanks go firstly to the man who guided me on this intellectual journey –my research director Dr Patrick Duffley. He (very) patiently coaxed a first (highly inadequate) attempt to model ANDCs’ semantics-pragmatics that I submitted for a class in April of 2016 into this –what is hopefully an empirico-theoretical contribution that is worth pursuing further. I should also like to thank him for the many teaching opportunities with which I was provided during my time as a graduate student in the Linguistics Department at University Laval.
Thanks go to the late Dr Walter Hirtle, the model scientist. It is he who first impressed upon me the importance of observation to theory in a science of language and who first encouraged me to investigate the present phenomenon –a phenomenon, to his eternal credit, that problematizes some of his own claims.
I should also like to thank Dr Bruno Courbon and Dr Claudia Borgonovo for not only accepting to evaluate this thesis but also for their encouraging initial feedback on the project proposal. Additional thanks go to Dr Courbon for wisdom dispensed on a cold winter night in 2017 as well as his extensive comments on the evaluated version of this thesis, and to Dr Borgonovo for the many opportunities to publicly present preliminary findings within the Department of Linguistics at University Laval (many of which have actually not even made the final cut).
xviii
My sincere thanks go to Dr Elizeveta Bylinina, Dr Carita Paradis, Dr Galit Sassoon, and (future Dr) Charlotte Sant for taking the time to reply to my email enquiries regarding their respective theoretical models and related matters. Thanks also to Dr Graeme Trousdale for his very complete reply to my email enquiry regarding one of his articles.
Thanks go as well to Dr Victor Thibaudeau –whose classes and writings sparked my interest in formal logic— and to Dr Jacques Ladouceur –whose infectious love for computer science I contracted. The tools first acquired in your superbly crafted classes proved invaluable to me in this study.
Particular thanks and recognition go to friends and colleagues who read (bits of) chapters over the years and/or commented the clarity of my own proposed model to handle the phenomenon under investigation here. In particular, thanks go to Kendall Vogh (now of York University) –who bravely read many of these chapters in draft form and whose many insightful comments have greatly benefitted the final product found here.
Lastly, I would like to extend my sincere thanks to the Fondation André Jacob for the very generous grant I received in the summer of 2016.
1
INTRODUCTION
English, like all languages, contains syntactic patterns (or constructions) of varying degrees of productivity. Some of these, such as “determiner + N(P)” (e.g. a dog; the hound of the Baskervilles) are cornerstones of English and have rightly been the focus of hundreds of articles, dissertations, and volumes (e.g. Abney, 1987; Langacker, 2016, amongst many others). It is these common constructions that are used to characterize English (e.g. “English is an SVO language”) and that tend to have immediate real-world applications (e.g. language pedagogy; natural language processing, etc.). Many other constructions, however, are quite rare and, in more than a few cases, hardly studied. Such is the case of this thesis’ object of study (cf. Sant, 2018, p. 1): proper names –nouns that designate a single entity within a basic category (see Chapter 3, subsection 3.2.2 for a full definition)— that participate in adverbial degree constructions. These sequences –here-called adverb-nominal degree constructions (ANDCs)— are typically subject complements comprised of a degree adverb (e.g. so, very) and what appears to be a non-adjectivized N(P) rather than the expected Adj(P). The construction1 is predicated of a grammatical or a logical subject, usually by means of an expressed copular verb (e.g. be; feel):(0.1) This bar is very San Francisco! (0.2) Love your smile –very Mona Lisa!
While ANDCs have existed in English peripherally since at least the 18th century (see Chapter 1, subsection 1.2.3.2), they have only recently begun to attract attention in the
1 It should be noted that we use the term construction in an atheoretical manner to designate recurring (presumably stored) thsequences of syntactic categories in a language, rather than in the strongly framework-specific “form-meaning combination” sense in which it is used by most tenants of Construction Grammar (for details, see Chapter 1, subsection 1.3.2).
2
English language literature. One reason that they have likely gone unnoticed until only recently is their statistical infrequency. These constructions are entirely absent from many corpora –even some very large ones, such as the 100-million-word British National Corpus (BNC)— and are rare or uncommon even in those corpora in which they do appear, unlike degree adverb/adjective combinations. For example, ANDCs occur approximately once every 185,000 tokens between the years 2010-2017 in the spoken sub-corpus of the Corpus of Contemporary American English (COCA; Davies, 2009) (for details, see subsection 3.3.1.1 of this thesis). While one can always argue that the construction is under-represented in existing corpora (sampling issues, accidental gaps, etc.), it clearly cannot be described as a central feature of English on par with, say, subject-auxiliary inversion in question formation. Quite the contrary, our object of study is likely amongst the statistically rarest productive syntactic n-grams in native-speaker Englishes. And therein lies a potential conundrum. Whereas the study of common structures has obvious value and applications, of what value is the study of something so peripheral, other than ticking the “empirical exhaustiveness” box that can be used to justify the study of even the trivial (McCain, 2016)?
Looking to the literature, we find that linguists’ attitudes towards the study of peripheral patterns are informed by both their research objectives and their theoretical commitments.
In applied fields such as language description, linguists seeking to provide a representative “snapshot” of their object of study (e.g. English or a dialect thereof) generally feel that describing an infrequent phenomenon is non-obligatory (e.g. Hoffmann, 1989, p. 113) or at least deeply questionable (e.g. Szmrecanyi, 2014, p. 92). For such linguists, merely acknowledging an infrequent phenomenon’s existence entails the risk of giving undue importance to an uncharacteristic, possibly ephemeral linguistic feature, thereby yielding a distorted view of the object. Best then to “reconsider the importance” of such phenomena (Sinclair, 1997, p. 31) and to focus on core structures, as this is what is required/expected of the analyst anyway.
In the theoretically-oriented literature, two well-known and diametrically opposed positions on peripheral constructions have been articulated.
Chomsky (1981) argues that Linguistics should be concerned with a language’s common structures (“the core”) rather than its rare, marked elements (“the periphery”) because it is in the core that Universal Grammar –the hypothesised biological foundation of
3
language— manifests itself most clearly; the periphery is said to be a “relaxed” extension of the core (Chomsky, 1981, p. 8), as it is not characterizable by the core’s high-level linguistic generalizations. It follows that accounting for non-core patterns is largely extraneous to mainstream generative linguistic theory (Chomsky, 1981, 1995). Small wonder, then, that core structures have not “attracted more intense attention among [generative] linguists” (Joseph, 1997, p. 197; see also Culicover & Jackendoff, 1999).
Goldberg (2003, p. 222; see also Fillmore, 1988), on the other hand, argues for the study of rare constructions in the following terms, contrasting her own empiricist framework with Chomsky’s nativist/rationalist one: “Constructionist approaches […] have zeroed in on these [peripheral] constructions, arguing that whatever means we use to learn these patterns can easily be extended to account for so-called “core” phenomena”. Rare constructions are worth studying, argues Goldberg, because “whatever means we use to learn” all language patterns can thereby be showed to be one and the same: they are stored as experience-derived constructions (in the sense intended by Goldberg (1995, 2006)) in the human brain. Goldberg thus finds value in the study of non-core patterns, but this value resides in such phenomena’s collective ability to serve as evidence that buttresses a particular framework (her own). Such an argument does little to convince non-constructionists of the importance of investigating rare constructions, let alone any specific peripheral pattern.
We would argue, pace Goldberg, that there are excellent theory-independent reasons to investigate peripheral constructions in general and, for that matter, ANDCs in particular.
First amongst these is the observation that there is no simple correlation between phenomenon frequency and theoretical importance in Linguistics, let alone any scientific field. Consider, by way of example, the Higgs boson –a sub-atomic particle whose study not only requires a highly sophisticated instrument (i.e. a particle collider) but that only occurs approximately once every trillion (1012) proton-proton collisions (ATLAS collaboration et al., 2012). The discovery of this particle is nevertheless one of the most important scientific findings of our time, as its existence confirms the essential correctness of the Standard Model of Particle Physics. Rare phenomena therefore need not be automatically avoided for fear of committing scientific resources to what are a priori unimportant or uninteresting objects.
4
Admittedly, it is, as Lindstrom and Eklund (2009, p. 1026) put it, “opportunistic to deal with high-frequency phenomena, since these […] constitute the bulk of observed linguistic patterns”. However, linguists engaged in theoretical or applied-theoretical endeavours (i.e. the activities of most cognitive and generative linguists) are ultimately concerned not merely with frequent patterns but with “the speaker’s tacit knowledge of language” itself (Evans & Green, 2007, p. 15). Since both common and rare patterns are manifestations of linguistic knowledge, phenomena of any frequency constitute legitimate objects of study. As Barðdal and Eythórsson (2006, p. 167) remind us, “all occurring structures, both frequent and infrequent, have [their] place in the language system” (see also Culicover & Jackendoff, 1999). On this view, non-core constructions are not a priori more or less interesting/important than core ones. Quite the contrary, rare phenomena “show what is possible” in language (Adli et al., 2015, p. 18) and may thereby lead to refinements or outright revisions of linguistic models and linguistic theories (cf. Rijkhoff, 2010, p. 223). In turn, these revisions and refinements provide Cognitive Science –of which cognitively-concerned Linguistics is a subfield (Jackendoff, 2007; Sinha, 2007)— with an improved understanding of the mental architecture underpinning language –or at the very least what that mental architecture must be able to account for (cf. Croft, 1998; Sandra, 1998; Taylor, 2012).
Indeed, it is precisely on these grounds that the study of ANDCs is worthwhile, necessary even. What do ANDCs express? What are the mental representations and operations likely underlying these construction’s expressed meanings? These are the fundamental questions with which this thesis is concerned and to which there are currently no satisfactory answers. Long-standing models that posit semantic mechanisms that preclude ANDCs (for details, see subsection 1.2 of Chapter 1 of this thesis) are inevitably giving way to models (or at least foundations thereof) that seek to accommodate recent empirical observations (see examples (0.1) and (0.2) above). Yet these “second-wave” models ultimately only increase the phenomenon’s curiosity for the simple reason that –far from collectively proposing anything resembling a consensus view— they advance completely dissimilar claims on key issues –even relatively theory-neutral ones. Regarding the category status of the N(P)-forms that participate in ANDCs, it has been suggested that they are adjectivizing (Breban, 2018; Gonzálvez García, 2014), gradable predicates of an undefined nature (Bylinina, 2011) or N(P)s (Paradis, 2008; Sant, 2018). Turning to claims regarding ANDCs’ expressed meaning, we find similar broad disagreements: tenants of Construction Grammar (CxG) propose that ANDCs’ nominal form is reduced to a gradable
5
property associated with the nominal referent (Audring & Booij, 2016; García Velasco, 2016, p. 934; Gonzálvez García, 2014), whereas formal semantic theories assume that ANDCs produce comparison statements of the type “X has many properties of N(P)” (Beltrama, 2016; Bylinina, 2011; Sant, 2018). Paradis (2008), on the other hand, suggests that ANDCs grade DOM –Degree of (category) Membership (i.e. the extent to which a grammatical subject actually is an instance of N). Considering such basic disagreements amongst scientists committed to elucidating the human capacity for language, further investigation of a language phenomenon –be it core or otherwise— is not only warranted but clearly required.
This thesis thus has three broad sets of objectives pertaining to what we believe to be the most important empirical and theoretical aspects of ANDCs.
Given that language scientists advance conflicting claims regarding N(P)s modified by degree adverbs, this thesis’ first objective will be to determine to what extent these (and other) competing hypotheses account for the phenomenon under investigation in the first place. That is to say, it is our goal…
RESEARCH OBJECTIVE 1: To determine to what extent existing language models are empirically adequate…
a. …with respect to their claims regarding the construction’s expressed meaning; b. …with respect to their claims regarding the category status and associated
semantics of nominals participating in ANDCs;
c. …with respect to their claims regarding ANDCs’ (non-)compositionality.
Over the course of the second and third chapters, it will become apparent that existing models all fall short of empirical adequacy on one or more of the above points. For all effective purposes, this means that language science currently has no adequate model to explain either the existence or the mechanisms underpinning the phenomenon of interest. The overriding aim of this thesis will therefore be to lay the foundations of an empirically-anchored, psychologically plausible account of the mental architecture recruited in the processing of ANDCs. Specifically, we will endeavour…
6
RESEARCH OBJECTIVE 3 2: To determine what types of mental representations and operations likely underlie the expressed meanings yielded by ANDCs, as formulated by a cognitively plausible model that reconciles corpus findings and theory from both Linguistics and Cognitive Psychology, in accordance with The Cognitive Commitment (Lakoff, 1990);
a. To determine with what element the ANDC’s degree adverb interacts; b. To determine whether predicative and attributive ANDCs are handled via
similar operations and representations;
c. To determine whether the operations involved in ANDCs’ processing are construction-specific.
As Science ultimately aims to provide explanations, and explanations must appeal to models (van Fraassen, 1980), we consider this theoretical objective to be primary amongst all of our objectives. However, we also take this type of theorization to be the crowning step of a rigorous empirical process: one cannot account for a phenomenon on a theoretical level if one does not know what one is accounting for in the first place (cf. Eddington, 2008; Geeraerts, 2010; Sampson, 2002). In this way, we seek not only to articulate the foundations of an empirically-motivated theory but to contribute to the redressing of one of the unfortunate tendencies of contemporary (Cognitive) Semantics. Not only is there currently “an excessive focus on hypothesis formulation […] at the expense of hypothesis testing” in (Cognitive) Semantics (Dabrowska, 2016, p. 479), hypothesis formulation is often insufficiently empirically-anchored to begin with (cf. Stefanowitsch, 2011, p. 304). ANDCs are a case in point: a paucity of systematic observational data and all of the limitations associated therewith is precisely the main limitation that theoretical investigation of ANDCs currently faces. Such investigation has only really become possible with the advent of the Internet, in particular social media and the associated massive quantities of relatively spontaneous linguistic usage data now available to researchers. It is thus perhaps not altogether surprising that only a handful of studies have examined authentic uses of ANDCs, and only cursorily at that (i.e. Bylinina, 2011; Gonzálvez García, 2014; Sant, 2018; Wee & Tan, 2008). While existing studies should certainly be recognized for drawing attention to the phenomenon and making many valid remarks, it must also be noted that no existing
2 Research Objective 2 is found below. The objectives are inversed in order to underscore the tendency in (Cognitive) Linguistics to engage in theorization without a solid empirical basis (cf. Stefanowitsch, 2011).
7
study has investigated any given nominal form’s behaviour in ANDCs in any appreciable depth. We will see that an in-depth investigation of a linguistic form’s behaviours in ANDCs is essential to understanding these constructions on a theoretical level, for two reasons. Firstly, N(P)s are exploited in ANDCs for their encyclopaedic potential (e.g. very Harry Potter → scenes, music, props, etc. associated with the Harry Potter films), and a clear picture of a nominal form’s encyclopaedic semantics can only emerge via extensive observation. Secondly, and even more importantly, ANDCs yield many types of expressed meanings (e.g. comparison, inclination, typicality, etc.) –some of which are statistically quite rare and are likely to appear only in large datasets. We will show that most of these types of expressed meanings (or in Duffley’s (2014) parlance, messages) have, in fact, never even been commented, let alone accounted for on a theoretical level. In short, before a theoretical account of ANDCs can be laid, it will be necessary…
RESEARCH OBJECTIVE 2: Based on a sizeable “disposable corpus” of authentic usage events, to describe the expressed meaning of ANDC-participating N(P)s from several ontological categories;
a. To document each investigated noun’s encyclopaedic potential using an appropriate methodology (i.e. semantic networks);
b. To identify (clusters of) formal/qualitative features that correlate with different types of expressed meanings using an appropriate methodology (i.e. MFA – Multifactorial Usage-Feature Analysis).
The empirical and theoretical objectives outlined above will be met over the course of this thesis’ five chapters.
In the first chapter, we review the extant literature on ANDCs. We begin by enquiring whether (degree) adverbs can modify N(P)s in the first place. It is showed that until very recently there was a well-established cross-paradigmatic belief in Linguistics to the effect that (degree) adverbs cannot modify N(P)s. Claims and theories regarding (degree) adverb-noun non-interaction are showed to be at odds with recent empirical findings. Recent proposals to account for the semantics-pragmatics of ANDCs are then introduced, operationalized, and tested against authentic usage. While none of the null hypotheses are rejected, we do identify one model that proves to be a promising (albeit incomplete) avenue.
8
Given the importance of parts of speech to (psycho)linguistic theory, the most pressing issue for a psychologically-concerned study is to determine the category status of nominal forms that participate in ANDCs. We therefore critically assess proposed diagnostics for nounhood, adjectivehood, and mixed category status in the second chapter. Having showed that true N(P)s indisputably participate in adverbial degree constructions in Chapter 2 (cf. Sant, 2018), the third chapter presents our theoretical framework, the methods that instantiate it, and the data to which these methods were applied. Following Langacker (1987, 2008) and Croft (1993), we adopt an encyclopaedic approach to the meaning of proper names, an approach that proves to be particularly well-suited to the description of proper name’s behaviour in ANDCs. We justify our choice of data source (Twitter) and selected dataset (four proper names drawn from four ontological categories), and describe the custom computer algorithms used to extract, store, and pre-process usage events. We also justify and describe the detailed manual annotation processes to which raw corpus data was subjected, as well as the cluster analyses used to identify patterns of (dis)association in the annotated data.
Chapter 4 presents the main results of the qualitative and quantitative analyses conducted. Key findings include the observations that 1) ANDCs are pragmatically much more complex and varied than has been previously reported and 2) that N(P)s in ANDCs are exploited for their encyclopaedic potential (as previously mentioned), potentially evoking almost any knowledge structure in the encyclopaedic network associated with the linguistic sign.
Considering our empirical findings, we then build on existing proposals in Pragmatics and Psycholinguistics to lay the foundations of an empirically- and psychologically-motivated theory to account for ANDCs’ expressed meaning (Chapter 5). In so doing, we find it necessary to break with one of the cornerstone assumptions of Mainstream Cognitive Linguistics, namely that there is no principled distinction between semantics and pragmatics (Croft & Cruse, 2004; Evans & Green, 2007; Langacker, 1987, 2008). In line with psycholinguistic models (Popov et al., 2017; Popov & Hristova, 2015) and recent linguistic theories (e.g. Duffley, 2014; Recanati, 2004, 2010), we argue that the most parsimonious, most cognitively plausible theoretical account of ANDCs is one that posits a sub-sentential boundary between semantics and pragmatics during the process of conceptual combination. We provide a concise formalization of the resulting data-driven model.
9
Lastly, Chapter 6 summarises our thesis’ main contributions and limitations and proposes several future research avenues. By way of conclusion, we reflect upon the relation between empirical findings and scientific theorization.
10
CHAPTER 1
HOW DO N(P)s AND DEGREE ADVERBS INTERACT?
1.1 Introduction
In this first chapter, we review the extant literature on ANDCs in English, starting from the long-standing assumption that (degree) adverbs and nouns cannot interact. We cover two traditional models that predict non-interaction and empirical findings that problematize these models. Care is taken not only to describe the phenomenon’s (known) (extra)linguistic features but also to distinguish the phenomenon from other sequences involving degree adverbs and nominals. Five recent proposals designed to account for –or that can be repurposed to account for— the existence and the semantics-pragmatics of ANDCs are then presented. The empirical validity of these models is assessed against some of the observational data introduced earlier in the chapter.
1.2 Can (degree) adverbs interact with nominals?
That certain (degree) adverbs such as quite can interact with determiner-fronted NPs –a syntactic structure containing a head of the lexical category N— has long been known. Even before Fillmore (1967, p. 126) drew attention to NPs that “accept types of modification usually associated with adjectives” (e.g. quite an idiot), 19th-century grammarians had documented the existence of sequences such as that found in (1.1) below. In the following, the degree adverb quite modifies the NP a gentleman:
(1.1) He is quite a gentleman. (from Sweet, 1891, p. 124; cited in Payne, Huddleston, & Pullum, 2010, p. 34) [emphasis added]
11
Direct interaction, on the other hand, between (degree) adverbs and the noun itself –the nucleus of “the nominal onion”, to borrow Löbner’s (2015) striking phrase— has long been held to be impossible, with the exception of a few notable dissenting analyses, such as Quirk et al.’s (1985, p. 485) analysis of postmodifying “adverbs” such as here in the house here; for a critical discussion of this claim, see section 4 of (Payne et al., 2010).
1.2.1 The complementarity claim
It has been long and widely assumed in language science that adverbs (under which degree adverbs are traditionally classified3) are in complementary distribution with adjectives –an assumption that Payne, Huddleston and Pullum (2010, p. 32) term the Complementarity Claim: “In modifier function, the choice between adjective and adverb is fully predictable from the category that is modified: adjectives modify nouns, and adverbs modify all other categories”. Stated as such, the Complementarity Claim should be understood as a specific reification of the widespread assumption that different parts of speech will occur in different unique environments (e.g. Tallerman, 2011, p. 39, amongst many others). Statements in the literature that express some form of support for the Complementarity Claim have been made repeatedly in the last four decades by linguists from various frameworks operating in various linguistic subfields (e.g. syntax; semantics; typology). Whereas some statements issue blanket declarations regarding noun-adverb interaction, others4 single out types of adverbs
3 The soundness of positing the existence of a unified adverb category has often been questioned (e.g. McCawley, 1986), as has the inclusion of degree adverbs in this category on distributional grounds (i.e. this class’ almost complete lack of interaction with verbs). For these (and other) reasons, a number of analysts refer to degree adverbs using labels that refer to all types of degree words and expressions. A whole host of terms for these umbrella categories can be found in the literature, of which the most popular are intensifier (e.g. Bolinger, 1972; Allerton, 1987; Athanasiadou, 2007), and degree modifier (e.g. Paradis, 1997; Kennedy & McNally, 2005; Morzycki, 2016). However, as we wish to make clear exactly which degree modifiers/intensifiers we have in mind, for clarity’s sake we will refer to linguistic units such as very, too and so using the traditional nomenclature. 4 Logically, the claim that degree adverbs do not modify nouns does not preclude the possibility that other types of adverbs do. However, to our knowledge, no linguist has made this argument. Rather, it seems to be the case that the non-interaction of degree adverbs with nouns is used to exemplify the general lack of interaction between these two parts of speech (e.g. Hirtle, 2009).
12
(especially degree adverbs) or specific types of behaviours (e.g. nominal premodification), as can be seen in the following (all emphases5 are ours):
(1.2) [A]djectives modify only nouns, while adverbs never modify nouns but modify other things instead (Nobel, 1982, p. 171);
(1.3) [A]dverbs […] may be used to modify a head which is not nominal […]. (Hengeveld, 1992, p. 41);
(1.4) In the grammar of English and many similar languages, an adverb is effectively a word that modifies anything other than a noun. (Matthews, 1997, p. 10);
(1.5) [A]djectives, but not nouns or verbs, occur with degree modifiers […]. (Bhat, 2000, p. 48);
(1.6) [Adverbs] characteristically modify verbs and other categories except nouns […] (Huddleston & Pullum, 2002, p. 563);
(1.7) This is predictable because adverbs do not modify nouns. (Traugott, 2005, p. 1710);
(1.8) Nouns are not premodifiable by adverbs (Arnaud, 2010, p. 306);
(1.9) [M]odification by degree words is ruled out (a *very apple pie) […] (Taylor, 2014, p. 168; reprinted from Taylor, 1999);
(1.10) Degree modifiers like very and slightly are well-behaved in the sense that they occur where we would expect expressions with such meanings to occur: in the vicinity of an adjective. (Morzycki, 2016, p. 253);
(1.11) Degree morphemes that classically combine with gradable adjectives are, by and large, incompatible with nouns […] (e.g. #Ducker; #Duckest; #too duck; #very duck) (Sassoon, 2018, p. 292).
Evidence adduced for these emphatic claims is of the negative variety. This implies that linguists have accepted in this case that an “absence of evidence” constitutes “evidence of absence”. That is to say, they are operating on the principle that it is reasonable to assume qualified investigators would not fail to notice the occurrence of a particular phenomenon, and that, consequently, the lack of positive evidence can be regarded as evidence that the phenomenon has not occurred (for a discussion, see Copi, 2013). Thus,
5 Unless explicitly noted otherwise, it should henceforth be assumed that all italics and bold characters
13
for example, it was noted that sequences such as extremely big, big dog, and extremely big dog are all attested in English, while sequences such as extremely dog are not (Hirtle, 2009, p. 23). In addition to the apparent lack of adverb-noun occurrences in naturally occurring data, many linguists have appealed to grammaticality judgements, commenting that (degree) adverb-noun combinations sound unnatural and therefore such combinations must be precluded by English speakers’ grammar. The case of Taylor (1999/2014) above (example 1.10) is representative of this modus operandi –a modus operandi which is not without merit but that does assume that the analysts’ intuitions accurately reflect pre-theoretical grammatical knowledge (cf. Labov, 1975; Dabrowska, 2010) and that these intuitions can be unproblematically generalized from the analyst to an entire community of speakers (cf. Schütze, 1996).
1.2.2 Theories that predict nominal-(degree)-adverb non-interaction
On the strength of one or more of these pieces of negative evidence, linguists from various frameworks enunciated models –structured representations of scientific knowledge (Rosenblueth & Wiener, 1945)— that aim to capture the apparent non-interaction of (degree) adverbs and nouns. Above and beyond this goal, these models are ultimately concerned with explaining linguistic distribution (where parts of speech occur) and well-formedness (the quality exhibited by sequences allowed by the model’s theorized grammar). While these models appeal to very different mechanisms, it is worth noting that they all posit semantic explanations rather than a “hard” syntactic constraint (i.e. the bald stipulation that certain parts of speech simply cannot be combined; for a discussion regarding the role of “hard” syntax in various formal frameworks, see (Zeevat, 2014). Specifically, traditional models that predict (degree) adverb-noun non-interaction share the assumption that the semantic characteristics of the lexical units involved in ANDCs somehow precludes their direct interfacing. For concision’s sake, we will cover only two exemplars of such models –a cognitively-oriented one and a model-theoretic one. The first model assumes that the make-up of degree adverbs in the mental grammar is such that they cannot select for nouns, while the second stresses that N(P)s are not eligible for adverbial degree modification to begin with.
1.2.2.1 The Theory of Incidence
Tenants of Psychomechanics –a cognitively-oriented theory of language articulated by the French linguist Gustave Guillaume (1883-1960)— argue that adverb-noun
14
combinations are ruled out by the grammatical characteristics of these two parts of speech (e.g. (Hirtle, 2009). For example, Hirtle, a tenant of Psychomechanics, contends that adverb-noun non-interaction can be explained by the theory of incidence. In Psychomechanics, incidence (broadly identifiable with predication/attribution in other frameworks) is regarded as language’s fundamental process, being the process whereby a word’s meaning is applied to that of another word (Hirtle, 2009, p. 23). Incidence is either an “internal” or an “external” process in lexical units (Hirtle, 2009, p. 30). For instance, in the substantive (an umbrella category that includes nouns) incidence is said to be internal. The import of meaning being found within the substantive itself, it is a part of speech whose meaning is applied to itself (Hirtle, 2009, p. 30). The adjective and adverb, on the other hand, cannot express or denote quiddity, the essence of a thing (Hirtle, 2009, p. 34). They are therefore characterized by mental mechanisms of external incidence (i.e. their meaning must be made incident to a syntactic support). Adverb and adjective diverge, however, with regards to the type of external incidence they exhibit. According to Hirtle (2009, p. 26), the heterogeneous adverb class is characterized by its “capacity for external incidence” of the second degree. That is to say, the mental make-up of an English adverb is such that it cannot directly qualify a word with internal incidence (i.e. substantives). Rather, the adverb possesses a grammatical mechanism that selects lexical units that, like members of its own class, necessarily do not possess internal incidence, namely other adverbs, verbs, and adjectives. On Hirtle’s (2009, p. 20) account, the capacity to qualify the substantive is a defining cognitive characteristic of the adjective: “no other type of word has the capacity to intervene in the process of thinking the substantive’s lexeme, to influence the way we call it to mind”.
1.2.2.2 The Degree Approach
In model-theoretic semantics (also known as formal semantics), degree adverbs are treated as degree operators that can combine with linguistic units equipped with the required gradable structure. Gradability (sometimes also called scalarity) is a particularly intense locus of research in model-theoretical semantics, such that several explanatory models have been proposed to handle gradable phenomena (for overviews, see Chapter 1 of Constantinescu (2011); and Chapter 6 of Morzycki (2016)). For concision’s sake we will limit
15
our discussion to the most widely accepted of these models: The Degree Analysis, also known as The Degree Approach6 (Castroviejo et al., 2018, p. 5).
In the Degree Approach, gradable predicates instantiate a relation between an entity (or a set thereof) and a degree –an abstract measurement that holds of its argument (e.g. Kennedy, 1999, amongst many others; for other classic references, see Castroviejo, McNally, & Sassoon, 2018). In this model, DEGREE is included amongst the primitives of natural language’s semantic ontology. Gradable adjectives (sometimes called scalar adjectives) are the prototypical case:
(1.12) John is tall. (1.13) It’s expensive.
Each gradable adjective’s lexical entry is comprised of three components: a unidimensional scale, an ordering relation, and a degree argument. The scale (or dimension) is the kind of measurement (e.g. height; cost) presupposed by the adjective, whereas the ordering relation encodes the adjective’s position on the scale (e.g. short v. tall; cheap v. expensive). The degree argument represents the measurement returned by the adjective when it is saturated. The degree argument can be saturated either by a default value (on many accounts, a phonologically-null morpheme known as pos; for details see Chapter 1 of Rett, 2015) or by a phonologically-realized degree operator (such as a degree adverb, as in very tall):
Figure 1.1 The degree saturation of a gradable predicate
Individual-denoting expressions are not mapped to degrees, however. Nouns are, rather, functions from entities to truth values rather than of degrees to predicates –that is to say,
6 The Degree Approach is actually an umbrella term for two types of models which both view gradable predicates not as inherently vague entities but as the mapping of degrees to predicates. For details, see Castroviejo, McNally & Sassoon (2018) and Sassoon (2007).
16
they denote sets of entities (cf. Portner, 2005). Nouns therefore lack the degree architecture that allows adjectives to interact with adverbial (degree) modifiers (cf. Baker, 2003; Kennedy, 1999), hence the judgements regarding the (un)acceptability of the following:
(1.14) John is very tall.
(1.15) **John is very New York.
1.2.3 Challenging the complementarity claim: Recent empirical findings
But the inherent limitation of negative evidence –the type of evidence on which the above models rest— is that it is easily refuted and therefore affords findings and theories reduced epistemic status compared to positive evidence: a conclusion reached via negative evidence can be invalidated by a single positive instance (for a detailed discussion, see Macagno & Walton, 2011). For example, the centuries-old claim regarding the inexistence of black swans was refuted by the discovery of a flock of black swans in Australia in the late 17th century. And just as further documentation of the physical world ultimately led to the revision of a persistent European belief, so too have linguists –“the masters of observation” (Eddington, 2008, p. 8)— brought to light hitherto unknown data that challenge decades-old scientific assumptions regarding what is (im)possible in language. Recent studies have showed that adverbs can, in fact, both pre- and post-modify N(P)s in English. For concision’s sake, we will limit our discussion to this thesis’ object of study: ANDCs featuring a degree adverb in prenominal position. Readers interested in the (non-degree) adverbial post-modification of nominal heads are referred to Payne, Huddleston and Pullum’s 2010 study.
1.2.3.1 Other “degree adverb + nominal” constructions
First, however, the construction of interest must be distinguished from other DEGREE ADVERB + NOMINAL sequences, namely 1) “pragmatic” uses of degree adverbs, 2) nominalized adjectives, and 3) adjectivized nouns.
A number of linguists have noted that some adverbial degree modifiers (such as the intensifiers totally and so) do not invariably modify the lexical unit that follows. Consider:
(1.16) You should totally click on that link. (from Beltrama, 2016, p. 4)
What is intensified in the above is not the degree to which the link should be clicked on, but the speaker’s commitment towards the proposition: their belief that the link ought to be
17
clicked on at all is strengthened. This phenomenon has been described as a “pragmatic use” of intensifiers, because the intensifier interacts with pragmatic (a belief/attitude) rather than lexical material (the verb click) (for details, see Beltrama, 2016, 2018). Examples provided in the literature typically involve verbs, modal auxiliaries, and various types of clauses, but observation of usage7 shows that the adverbial degree modifier’s left-hand collocate can also be a (pro)noun) (cf. Stange, 2017), as in (1.17):
(1.17) 𝜏 [I]t was totally you that I saw [there].
(1.18) You should totally click on that link. (from Beltrama, 2016, p. 4)
That the pronoun you and the verb click are not the actual targets of degree intensification in the contexts above can be showed by the fact that totally –like so— can occur pre-verbally with little shift in expressed meaning (cf. Irwin, 2014):
(1.19) You totally should click on that link. (cf. You so should click on it) (1.20) It totally was you that I saw there. (cf. It so was you that I saw there)
Care must also be taken to distinguish between N(P)s that occur within the scope of intensification and lexical units that receive degree intensification while appearing in characteristically nominal positions, such as immediately after the definite article (e.g. participles and adjectives). In the intensification of nominalised adjectives (so called because they co-occur with a determiner), the quality denoted by their head is shifted up or down from the lexical unit’s assumed default value:
(1.21) Statistics for the completely terrified.
(1.22) Let me tell you about the very rich. (F. Scott Fitzgerald, The Rich Boy, 1926) One well-known reason to doubt the noun-status of nominalised adjectives is the fact that they generally refuse pluralisation (pluralisation being a clear indication of nounhood); those few nominalised adjectives that do accept pluralization (e.g. the ignorants; the innocents) do
7 Diacritics are employed throughout this thesis to indicate the means whereby Web data was obtained. Following Laurence Horn (e.g. Horn, 2013), the “Google gamma” (γ) is used to mark attested examples found via the Google search engine. Inspired by Horn, we introduce in this thesis the “Twitter tau” (𝜏) to indicate that a usage event was found on the social networking website Twitter.
18
not accept adverbial degree modification (at least in this environment). All examples are ours:
(1.23) **Statistics for the very terrifieds. (1.24) **Let me tell you about the very riches.
(1.25) **The supremely ignorants. (cf. the supremely ignorant)
(1.26) **The massacre of the very innocents. (cf. The massacre of the very innocent) Some analysts (e.g. Huddleston & Pullum, 2002; Günther, 2018) have hypothesised that “nominalised” adjectives actually qualify an elliptical noun –the very rich (people), for example. On this account, nominalised adjectives refuse pluralisation a priori, as they are clearly adjectives, not nouns (but see Aarts, 2007, pp. 135–137 for a dissenting view); in mother tongue Englishes, adjectives do not grammatically concord with the noun that they qualify (e.g. **statistics for the very terrifieds people).
Lastly, like nominalized adjectives, adjectivized nouns also denote a scalar property (or one that can be construed as such), irrespective of the presence or absence of a degree adverb. Such forms –which are sometimes described as “weakened” nouns (cf. (Denison, 2013)— typically come to accept adverbial degree modification as one of the last steps (if not the last step) in the adjectivization process. Well-known examples include key (Denison, 2001; de Smet, 2012) and fun (Algeo, 1962; Bolinger, 1963). These adjectivized forms share linguistic form with a noun, but can be readily substituted for other gradable properties whose meanings approximate their own:
(1.27) Controlling your stress is (so) key. (vital / important / crucial) (1.28) The evening was (very) fun. (enjoyable / entertaining)
1.2.3.2 The adverbial degree intensification of (true?) N(P)s
The phenomenon with which we are concerned, on the other hand, involves nominal forms and noun phrases that not only occur within the adverbial degree modifier’s scope but that are not typically thought of as denoting or providing access to encoded gradable content per se (e.g. New York; California; you); their presence in an adverbial degree construction is therefore not straightforwardly predictable based on their semantics. It should be noted that this section does not, however, directly deal with the matter of the category status of the nominal forms in ANDCs, this being a contentious (theoretical) issue (cf. the theories presented in section 1.3 of this thesis) that we will address in Chapter 2 once the relevant
19
literature has been reviewed and the existing positions identified. For now, we will simply introduce the known (or readily knowable) empirical facts surrounding ANDCs. As ANDCs are a little studied phenomenon, it will be necessary to occasionally highlight gaps in the literature and submit token empirical evidence that has gone unreported. Some of this additional evidence will be leveraged in our critical assessment of existing theories in section 1.4.
Little is currently known about ANDCs’ synchronic extralinguistic features. To our knowledge, no empirical study has investigated the characteristics of the speakers8 who use ANDCs, the types of contexts in which ANDCs occur, their frequency of use, and the (national) varieties of English in which they are attested, to name but these. Studies that have investigated the sociolinguistic parameters of intensifiers (e.g. Ito & Tagliamonte, 2003; Tagliamonte & Roberts, 2005) do not offer even oblique evidence on the subject. It is widely assumed, however, that ANDCs are a rare (Stratton, 2018), recent (Beltrama, 2016; Bylinina, 2011; Gonzálvez García, 2014; Zwicky, 2006), American innovation (Bylinina, 2011; Gonzálvez García, 2014) that has most likely spread to other national varieties such as British and Canadian English (Gonzálvez García, 2014; Stratton, 2018). The scope of this thesis does not permit us to investigate the matter further, but it should be noted that, pace the rather impressionistic claims found in the literature, ANDCs appear to be neither a recent nor even an (exclusively) American innovation. (It seems likely, however, that their productivity has increased in Englishes over the last few centuries, although a quantitative study is needed to demonstrate this). The oldest instance of the construction we have identified occurs towards the middle of the 18th century in a well-known London-based publication –The Gentleman’s Quarterly (the world’s first magazine):
(1.29) Thousands have taken the same fruitless and expensive journey, because they have heard that it is very John Trott not to have visited France, and that
8 Sant (2018, Appendix B) gathered basic sociodemographic data on the 208 English-speaking respondents to her digitally-distributed questionnaire on the naturalness of N(P)s modified by degree adverbs. However, it was not established that the respondents actually employed ANDCs themselves (this question lying outside the scope of the study). Moreover, the sample of respondents is fortuitous and, likely owing to its digital distribution to the analyst’s own extended social network, over-represents certain sociodemographic characteristics (e.g. young adult speakers; UK-based speakers). Sant’s data cannot therefore be taken as being representative of English-speakers more broadly, but it can reasonably be interpreted as evidence that (younger) English-speakers of many “inner-circle” English-speaking countries recognize the naturalness of the construction.
20
a person who has not been abroad has Seen Nothing (The Gentlemen’s Quarterly, 1754, p. 223).
ANDCs are also marginally attested in British English throughout the 19th century, especially with the degree adverbs quite and enough. We leave this interesting but tangential diachronic dimension to a future study9.
Like many rare constructions, ANDCs are thought to be quite marked –in two senses of the word. Firstly, they are marked syntagmatically (Trousdale, 2018, p. 291) in that nominals are not expected to co-occur with degree adverbs. Extensive evidence amassed over the last three decades in both psycholinguistics and cognitive neuroscience shows that native speakers of a language are very good at anticipating plausible word combinations (e.g. Otten & Van Berkum, 2008) and that unexpected syntactic combinations are processed differently, and more difficultly than expected ones (e.g. Coulson, King, & Kutas, 1998). ANDCs –being unexpected combinations— may therefore strike the hearer as being quite peculiar, non-standard even. This markedness may, however, constitute a compelling reason to use ANDCs in the first place: per Haspelmath’s Maxim of Extravagance (“talk in such a way that you are noticed”), it may well be that speakers’ choose to employ these marked constructions to convey “a sense that for a long time has successfully been expressed by different means” (Haspelmath, 1999, p. 1057) precisely in order to draw attention to themselves (or at least to the form used to convey the speakers’ message). In this, ANDCs are reminiscent of other emerging constructions that coordinate unexpected elements in order to achieve a striking expressive effect, such as the “BECAUSE X” slang construction, as in Leaving, because bored or Of course evolution is true, because science (Kanetani, 2019; Walla, 2016). Secondly, ANDCs are marked in terms of register. Beltrama (2016, p. 232), for instance, suggests that the use of ANDCs “tend[s] to come across as younger and markedly informal as opposed to more canonical uses with gradable predicates like tall” [italics added]. Informalisms, ANDCs are thought to occur most frequently in speech, particularly in low-register or colloquial speech, though they are not exclusive to either this medium or to this register (cf. Gonzálvez García, 2014; Zwicky, 2006; section 3.3.1.1 of this
9 For a diachronic investigation of ANDCs in another well-known Indo-European language (French), see Lauwers (2018). Lauwers shows that ANDCs (or to use his term, “Degree adverb + N constructions”) are attested in French as early as the 17th century.