INEX Tweet Contextualization Task: Evaluation, Results and Lesson Learned
24
0
0
Texte intégral
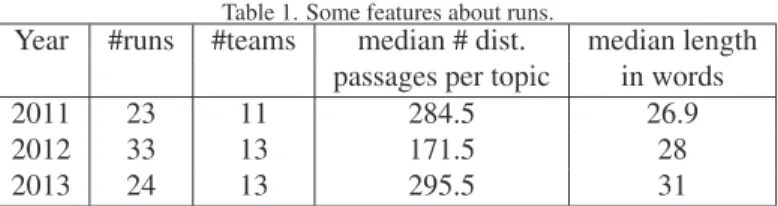
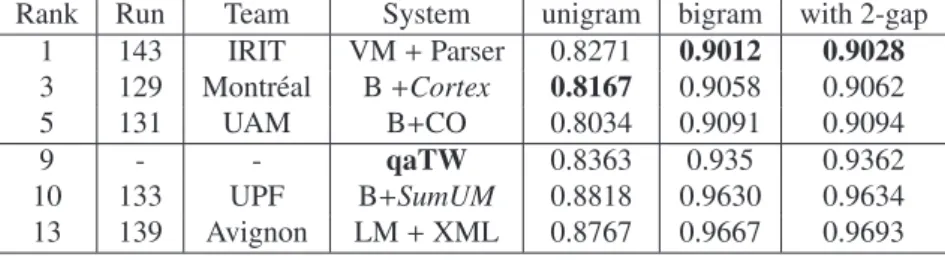
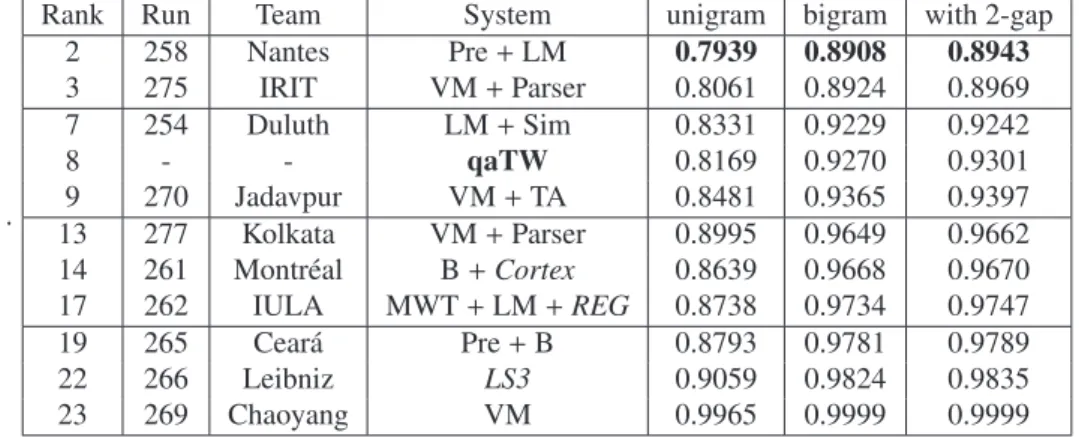
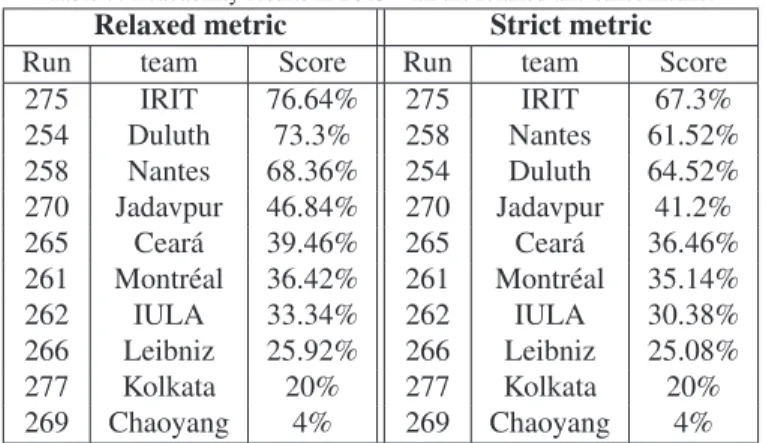
Figure


+4
Documents relatifs