Thèse
Pour l’obtention du diplôme de Doctorat LMD - 3éme cycle
Domaine : Mathématiques et Informatique Filière : Informatique
Formation : Système d’information
Spécialité : TIVA (Traitement d’Images et Vision Artificielle)
ZIANI Amel
Devant le jury composé de :
Rapporteur Dr. AZIZI Nabiha Université Badji Mokhtar – Annaba
Président Pr. MEROUANI Hayet Farida Université Badji Mokhtar – Annaba
Examinateur Dr. SARI Toufik Université Badji Mokhtar – Annaba
Examinateur Pr. MESHOUL Souham Université Constantine 2 Examinateur Pr. BATOUCHE Mohamed Chawki Université Constantine 2
La recommandation via l’analyse d’opinions
République Algérienne Démocratique et PopulaireMinistère de l'enseignement Supérieur et de la Recherche Scientifique Université de Badji Mokhtar Annaba
Faculté des Sciences de l’Ingéniorat Département d’Informatique
REMERCIEMENTS
Je remercie tout d’abord Dieu tout puissant de m’avoir donné le courage, la force et la patience d’achever ce modeste travail.
Je tiens à exprimer ma profonde gratitude à Dr Nabiha AZIZI, pour avoir encadré et dirigé mes recherches. Je la remercie pour m'avoir soutenu et appuyé tout au long de ma thèse. Ses précieux conseils, son exigence et ses commentaires ont permis d'améliorer grandement la qualité de mes travaux.
Merci à Pr Yamina TLILI-GUIASSA, pour son co-encadrement de la thèse. Je la remercie pour ses conseils et sa collaboration durant mes premières années.
Je tiens également à remercier tous les membres du jury pour avoir accepté de rapporter mon travail et pour leurs remarques constructives.
A vous mes parents, mon oncle Abdelghani et sa famille, je dis un grand merci. Je vous suis infiniment reconnaissante pour votre soutien et vos encouragements. Je remercie également ma sœur qui m'a toujours encouragé et soutenu moralement.
A tous mes amis un grand merci. Merci à Soumaya, Nassira, Nawel, Nassim et Djeneba pour votre aide précieuse dans la relecture et la correction de ma thèse.
Mes remerciements vont aussi à tous ceux et celles qui ont participé de près ou de loin à l’élaboration du présent travail, à tous nos amis et collègues pour leur soutien moral tout au long de la préparation de ce travail.
صخلم
بببعلت بببمييقت ا ببب ا ا ببب ً واربببت ابببيمعلا اربببي عبببر بببمماً ام اً ودبببمعلا بببً خ ودبببمعلا ديبببتلات رت ببب ت ابببي لا عبببر عن بببم ت ا اببب ا لا وتبببت ربببتن ا ا بببملا شبببلن ا اببب ر ىا ربببتن تنربببخعا بببعتارما مبببائا آا تببببً ببببن علا عببببر بببب اا ببببم شببببلن يبببب لا ببببم صببببيتمت مببببت عل ببببحلا و ن بببب مل ببببي ار ولىا و بببب لا ببببيا ً يبببب ت يبببب ت يبببب لا ببببم ببببقت و ببببئا ببببيموا ببببً لعملا رر ببببت لوببببمً ببببً اببببً ع لا شببببلن تيً بببب ملا تبببً وربببيتولا بببيمولا تبببً اربببت تبببومن ةبببلا ببب ملا بببش و بببيت ا اربببي و ببب تا عبببر ن ببب ت عل ببب ل اا تيً ببب ملل ببب ملا ا بببيخ . ملا وا آ ةبببخ ربببت عن رببب لان اةببب ا بببن ت بببحا ببب ً يببب لا بببم عبببر بببت ن ا عبببر تيً ببب رن ببببمملا اببببيلح ل و ببببناد ملا بببيم لأا بببغلل ا من ببببلا عببببت بببب ً وا عا اببببيلحتا ي ببب ت بببب ً ام ببببن حتا ببببيارعلا عببلعا ا رببمت ببي ق لا ةبب ع ببمملا بب ئ ل امربب بب ملا اةبب عببر من يببت عببلعا ملع ببلا ببي قت ربب ر بب ببماً ببلشرم وا عا اي م ل صئ لا جار ا ع ا ات ً يلن ر وا عا ايلحت ً عر اتت مر صئ لا ص ق إ ًؤن ن تومن ك تًا ريغ لا م حلا او فةش صنرط تن لا واً رييغت شلإ صئ لا ات ً م ش صئ لا ة م تً ضعتلا ا ا ع ترولار تلالا يً ا خ علخا لا ملا ا ت ا كلوا ؛ًا حملا م حلا او صئ لا ات ً تً ن علا و م ى عئا معلا و عئا معلا و تلالا مل ع لأا علعا من لا عت ً ا يً ر ر رخآ ً ا ارقلا ور ت ةلاا . كلةل ن م إ مت ع لا صئ لل ينرلالا ن م ملا تً ن م ً ار ن و علعا من لا عت ً ار دخ ً تن و ت . ة تً ايلن حلا مت ع لا ع مملا ئ لا تً مغرلا شلن ا يً ا لا دندعت ات تً رخآ حار يا ةيلا ت مت حر قملا ا ملا ط تت ا رين عً س شلن ينرلالا صئ لا ات مل ل مر ي ي لا يً ا لا ا ا قا لا عل لل ن ي خ ا شل لً و ً ريغلا ينرلالا ن م ملا ا ا ًا عئا معلا و تلالا ً اتي تً ملا عئا معلا ةبببب ببببيتمقلا ببببن حت ببببيلمن تيبببب ح ل و ببببن ت ببببيل ً ادببببيً حاربببب يا تببببً بببب ومت ادببببيملا ريت ببببت اببببيلحت تببببً ببباا بببا م لا بببيدنا عبببارعلا بببم لا ابببيلحت تبببً و ش ببب ً صئ ببب لا بببيدعلاا اربببلا فاربببش بببيم شبببلإ ر ل صئ بببب لا بببب حل مع بببب ا ببببيدعلاا فارببببحلا ربببب ر بببب ر خا ببببقر ببببن غللا بببب ا لاا ببببيارعلا ببببغللا عببببر اببببت تببببً ي بببب لا ببببلشرً عببببر وا عا ص بببب اببببي م ل عبببب اوببببما صئ بببب لا ةبببب ا بببب ا م ببببيل بببشر قملا تً ا يلا ت م ع لا وا عا يتمي ن حت قييً ي ت و م ى ع ا ع لا لا اتي . ةيحاتفم تاملك ت يببب لا مببب ابببيلح عا وا ببببغللا بببي ي لا بببيً ا لا عئا بببمعلا و بببتلالا عبببلعا من بببلا عبببت ببب ً عارعلا م لا ايلحت يارعلا .Résumé
Les avis des clients sur les produits jouent un rôle primordial dans la décision du client d'acheter un produit ou d'utiliser un service. Les préférences et opinions des clients sont influencées par les avis des autres en ligne, sur les blogs ou sur les réseaux sociaux. Actuellement, les systèmes de recommandation ont été largement utilisés dans de nombreux sites de commerce électronique afin d’aider les utilisateurs à faire face au problème de surcharge d'informations. Les systèmes de recommandation fournissent des recommandations personnalisées aux utilisateurs et, par conséquent, aident à prendre de bonnes décisions concernant le produit à acheter parmi le vaste choix de produits proposés.
La prise en compte des opinions des utilisateurs dans les systèmes de recommandation est une nouvelle voix de recherche. Cela justifie l'importance croissante de l'analyse du sentiment et précisément le domaine de la classification des opinions. Le classifieur de Séparateurs à Vaste Marge représente la technique de classification la plus sollicitée dans ce domaine grâce à ses résultats encourageants. Cette technique est précédée par une phase importante d’extraction de multiples caractéristiques afin de représenter les textes de commentaires.
En fouille d’opinions, les systèmes de détection de polarité ont prouvé leur efficacité avec des vecteurs de taille restrictive. Ainsi, la réduction du vecteur de caractéristiques peut altérer les performances du système en supprimant celles qui sont pertinentes, notre idée est d'utiliser l'algorithme de sous espaces aléatoires ou Random Sub Space pour générer plusieurs vecteurs de caractéristiques de taille limitée ; tout en remplaçant le classifieur de base de Random Sub Space qui est l’arbre de décision par un autre plus précis qui est le classifieur des Séparateurs à Vaste Marge. De ce fait, chacun des sous-ensembles de caractéristiques générés sera l'entrée d'un classifieur individuel. Malgré les résultats encourageants obtenus de cette approche proposée, une autre proposition a été implémentée afin d'améliorer l'approche précédente en introduisant les algorithmes génétiques comme générateur de sous-ensembles de caractéristiques avec une fonction fitness basée sur des critères de corrélation pour éliminer la sélection aléatoire du Random Sub Space et empêcher l’utilisation des sous- ensembles de caractéristiques incohérente.
À partir de l'analyse de l'influence des caractéristiques, nous avons pu proposer de nouvelles caractéristiques sémantiques pour améliorer le processus de détection de polarité. Ces
caractéristiques s'inspirent du discours arabe et des relations rhétoriques. Compte tenu de l'importance des unités de phrase dans la langue arabe et des études linguistiques, nous avons sélectionné les marqueurs des unités et les relations les plus courantes pour calculer les caractéristiques proposées. Ces dernières ont été adoptées essentiellement pour représenter les opinions dans la phase de classification, afin de calculer les scores de polarité des opinions filtrées par le système de filtrage collaboratif dans le but de générer des recommandations pertinentes.
Mots clés
Les systèmes de recommandation, La fouille d’opinions, Les séparateurs à vaste marge, l’algorithme de sous-espaces aléatoires, Les algorithmes génétiques, La langue arabe, L’analyse de discours arabe.
Abstract
Customer product reviews play an important role in the customer’s decision to purchase a product or use a service. Customer preferences and opinions are affected by others’ reviews online, on blogs or over social networking platforms. Currently, recommender systems have been widely applied in many commercial e-commerce sites to help users deal with the information overload problem. Recommender systems provide personalized recommendations to users and, thus, help in making good decisions about which product to buy from the vast amount of product choices.
Taking users' opinions into account in recommendation systems is a new research area. That explains the growing importance of the Arabic sentiment analysis and precisely the opinions’ classification area. The Support Vector Machine classifier is the most popular machine learning technique in this field due to its encouraging results. This technique passes by an important phase of extracting multiple features in order to represent the reviews’ texts.
In opinion mining, the systems of polarity detection have proven their effectiveness with restrictive sized vectors. Though, reducing features’ vector can alternate the system performance by deleting some pertinent ones, our idea is to use the Random Sub Space algorithm to generate several limited size vectors of features; while replacing the basic Random Sub Space classifier which is the Decision Tree with another more precise one which is the Support Vector Machine. Therefore, each one of the generated features subsets will be the entry of an individual classifier. Despite the obtained encouraging results of this proposed approach, another proposition was implemented in order to enhance the previous algorithm by using the genetic algorithm as subset features’ generator based on correlation criteria to eliminate the random selection used by Random Sub Space and to prevent the use of incoherent features subsets.
From analyzing the influence of the features, we have been able to propose new semantic features to improve the polarity detection process. These features were inspired from the Arabic discourse parsing and the rhetoric relations. Looking to the importance of the phrase units in the Arabic language and the linguistic studies, we have selected the most common unit markers and relations to calculate the proposed features. These last were used basically to represent the reviews texts in the classification phase in order to calculate the score polarity of the filtered reviews by the collaborative system to generate accurate recommendations.
Key words
Recommendation systems, Opinion mining, Support Vector Machine, Random Sub Space, Genetic Algorithms, Arabic language, Arabic discourse parsing.
Sommaire
Introduction Générale ... 1
Chapitre 1. Les Systèmes de Recommandation ... 6
1.1. Introduction ... 6
1.2. La recherche d’information et le filtrage d’information ... 7
1.2.1. La recherche d’information ... 7
1.2.2. Le filtrage d’informations ... 8
1.2.3. Comparaison entre la recherche d’information et le filtrage d’information ... 8
1.3. Les systèmes de recommandation ... 10
1.3.1. Classification des techniques de recommandation... 11
1.4. Les systèmes de recommandation basés sur le filtrage collaboratif ... 14
1.4.1. Principe ... 14
1.4.2. Profil de l’utilisateur ... 15
1.4.3. Processus du filtrage collaboratif ... 16
1.5. L’évaluation des systèmes de recommandation ... 20
1.6. Conclusion ... 21
Chapitre 2. L’Analyse des Sentiments ... 23
2.1. Introduction ... 23
2.2. Définition de l’analyse des sentiments ... 24
2.2.1. Tache de l’analyse des sentiments ... 25
2.2.2. Caractéristiques de l'analyse des sentiments ... 27
2.3. Les opinions trompeuses (spams) ... 30
2.3.1. Types de spams et de spamming ... 32
2.4. L’analyse des sentiments en arabe ... 33
2.4.1. La langue arabe ... 33
2.4.2. Traitement du discours arabe ... 37
2.5. Conclusion ... 48
Chapitre 3. Classification d’Opinions ... 49
3.1. Introduction ... 49
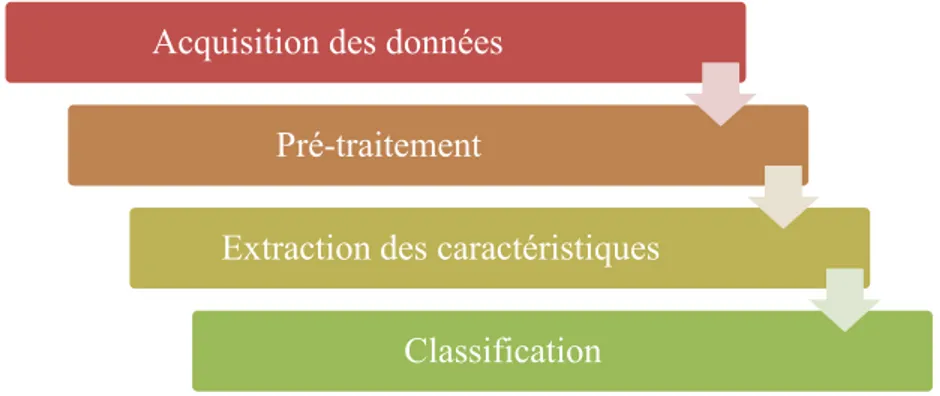
3.2. Processus de classification d’opinions ... 50
3.2.1. Acquisition du corpus ... 50
3.2.2. Prétraitement des données ... 51
3.2.3. Extraction des caractéristiques ... 52
3.2.4. Réduction de dimension ... 55
3.2.5. Classification ... 58
Chapitre 4. Combinaison de RSS-SVM avec les Algorithmes Génétiques pour
l'Analyse d’Opinions en Langue Arabe. ... 69
4.1. Introduction ... 69
4.2. Motivation ... 69
4.3. Le processus proposé pour la détection de polarité d’opinions ... 71
4.3.1. Collection des données ... 72
4.3.2. Prétraitement automatique ... 74
3 4 4 Extraction de caractéristiques ... 76
4.3.4. Classification ... 80
4.4. Résultats expérimentaux et évaluation ... 86
4.4.1. Expérimentation-A ... 87
4.4.2. Expérimentation B ... 90
4.4.3. Etude comparative ... 92
4.5. Conclusion ... 94
Chapitre 5. La Recommandation via la Détection d'Opinions Trompeuses (Spams) ... 95
5.1. Introduction ... 95
5.2. Motivation ... 96
5.3. Partie 1 : le processus de détection d’opinions spams en arabe ... 97
5.3.1. Acquisition des données ... 98
5.3.2. Extraction des caractéristiques ... 100
5.3.3. Détection des opinions spams ... 106
5.4. Partie 2 : la recommandation via l’analyse d’opinions ... 108
5.4.1. Le filtrage collaboratif ... 109
5.4.2. Elimination des spams et classification des opinions vraies ... 110
5.4.3. La recommandation ... 110
5.5. Résultats expérimentaux et évaluation ... 111
5.5.1. Expérimentation1.a ... 111
5.5.2. Expérimentation 1.b ... 112
5.5.3. Etude comparative ... 114
5.5.4. Expérimentation 2 ... 115
5.6. Conclusion ... 116
Conclusion générale et Perspectives ... 117
Liste des Publications ... 120
Liste des figures
Figure 1-1 Processus du filtrage d’informations [Béchet 2013]. ... 8
Figure 1-2 Processus du filtrage collaboratif [Nguyen 2006]. ... 16
Figure 2-1 Les données de Google Trends sur les tendances liées à l'analyse des sentiments1. ... 25
Figure 2-2 Tâches d'analyse des sentiments [Pozzi 2016]. ... 27
Figure 2-3 Flux des tâches de l'analyse des sentiments. ... 28
Figure 2-4 Les différents niveaux d'analyse. ... 29
Figure 2-5 Les dix premières langues d’internet2... 35
Figure 2-6 Les top 10 pays arabophones d’internet (Mars 2017)2. ... 36
Figure 3-1 Le processus général de classification d’opinions. ... 50
Figure 3-2 Le processus général de sélection de caractéristiques [Vincent 2011]. ... 56
Figure 3-3 Illustration du principe de la méthode Random Sub Space pour un ensemble d’arbres de décision [Bernard 2009]. ... 58
Figure 3-4 La taxonomie des techniques d’apprentissage automatique. ... 60
Figure 3-5 Principe des SVMs : Les vecteurs de supports sont encerclés [Dong 2013]. .. 62
Figure 4-1 Le processus général proposé pour la détection de polarité d’opinions. ... 72
Figure 4-2 L’interface du clavier arabe intelligent Yamli10 . ... 74
Figure 4-3 Le processus de prétraitement proposé. ... 75
Figure 4-4 Le processus de l’approche hybride : RSS-SVM. ... 82
Figure 4-5 Exemple de chromosome codé. ... 83
Figure 4-6 La technique du croisement. ... 84
Figure 4-7 La technique de mutation... 85
Figure 4-8 Histogramme représentant la précision totale de l'expérimentation A. ... 89
Figure 4-9 Histogramme représentant la précision totale de l'expérimentation B ... 92
Figure 5-1 Le processus proposé de détection d’opinions spams. ... 98
Figure 5-2 L’arbre généré par l’algorithme proposé de traitement du discours. ... 102
Figure 5-3 Les paramètres associés à chaque nœud ... 105
Figure 5-5 Histogramme représentant les résultats de l’expérimentation 1a. ... 112 Figure 5-6 Histogramme représentant les résultats de l’expérimentation 1b. ... 113
Liste des tableaux
Tableau 1-1 Comparaison entre la recherche d’information et le filtrage d’information. .. 9
Tableau 1-2 Comparaison entre les types de recommandation. ... 12
Tableau 1-3 Matrice de confusion. ... 21
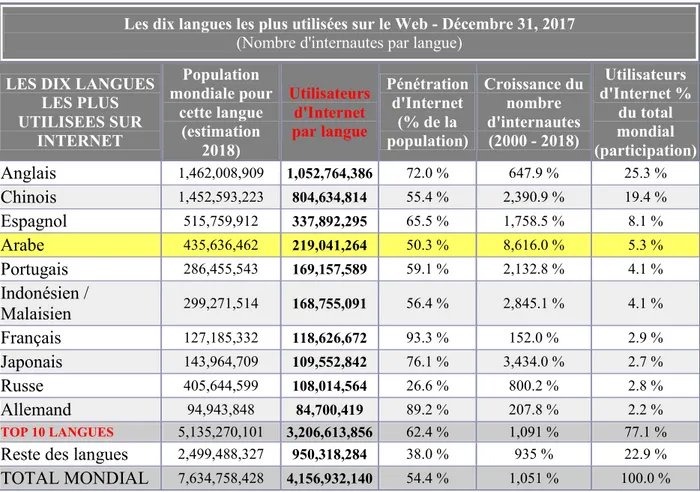
Tableau 2-1 Les dix langues les plus utilisées sur le Web. ... 34
Tableau 2-2 Les connecteurs de discours arabes utilisés dans ce travail. ... 38
Tableau 2-3 Lexique utilisée dans les techniques d’analyse du sentiment en arabe. ... 42
Tableau 2-4 Les corpus utilisés dans les techniques d’analyse du sentiment en arabe. .... 47
Tableau 4-1 Exemples de données collectées. ... 73
Tableau 4-2 Exemples d'opinions prétraités ... 75
Tableau 4-3 Exemples des mots de SenitWordNet. ... 76
Tableau 4-4 Exemples des mots de SentiWordNet avec etiquetage ... 79
Tableau 4-5 Exemples des mots d'adressage ... 79
Tableau 4-6 Exemples des mots de réflexivité... 80
Tableau 4-7 L'algorithme de fusion RSS, AG et SVM. ... 86
Tableau 4-8 La matrice de confusion pour la classe positive. ... 87
Tableau 4-9 La matrice de confusion pour la classe négative... 87
Tableau 4-10 La matrice de confusion pour la classe neutre. ... 88
Tableau 4-11 Les résultats de l'expérimentation A : RSS-SVM ... 89
Tableau 4-12 Les paramètres de l'algorithme amélioré. ... 91
Tableau 4-13 Les résultats de l’expérimentation B : RSS-SVM amélioré. ... 91
Tableau 4-14 Les résultats obtenus de tous les classifieurs utilisés. ... 92
Tableau 4-15 Étude comparative... 93
Tableau 5-1 Exemples des données traduites. ... 99
Tableau 5-2 Le vecteur des caractéristiques lexicales. ... 101
Tableau 5-3 Les caractéristiques sémantiques proposées ... 102
Tableau 5-4 Le vecteur de caractéristiques. ... 107
Tableau 5-6 Les résultats de l’expérimentation 1.b. ... 113 Tableau 5-7 Étude comparative... 114 Tableau 5-8 Les résultats expérimentaux. ... 115
Introduction Générale
"La connaissance des mots conduit à la connaissance des
choses."
Platon
Le Web 2.0 a fait son émergence, avec des espaces plus interactifs comme les sites sociaux, les blogs et les forums. Les utilisateurs qui étaient jusque-là passifs dans le Web 1.0, sont devenus actifs dans le Web 2.0. Où chacun peut ajouter des informations et partager ses opinions.
Pour cela, les systèmes de recommandation (SR) ont été introduits pour aider le public à s’adapter à ces changements par intégrer des aspects sociaux et focaliser sur le comportement des utilisateurs. Les systèmes de recherche d’informations attendent la requête de l’utilisateur pour agir, par contre les SR tentent d’anticiper les besoins des utilisateurs et leur proposent des items qu’ils sont susceptibles d’apprécier. En effet, les SR ont été introduits comme une nouvelle technique pour faire le filtrage d’information afin de recommander à un utilisateur des items jugés pertinents par rapport à ses goûts. L’objectif est à la fois de minimiser le temps passé à la recherche, et aussi de lui suggérer des ressources qu’il n’aurait éventuellement pas consultées ce qui améliore la qualité des services d’accès à l’information.
Pour déterminer les ressources à recommander, plusieurs approches sont utilisées. L’approche de filtrage par contenu qui compare le contenu sémantique de la ressource avec les goûts exprimés par l’utilisateur ; et l’approche de filtrage collaboratif qui constitue la technique la plus populaire. Le filtrage collaboratif consiste à recommander à un utilisateur des ressources susceptible de l’intéresser en se basant sur les avis des autres utilisateurs avec lesquels il partage les mêmes centres d’intérêts.
En effet, un système fondé sur le filtrage collaboratif utilise des notes afin d’évaluer les similarités entre les utilisateurs en exploitant les items déjà évalués. Ces similarités permettent d’identifier les voisins dont les appréciations sont combinées pour calculer les recommandations ; c’est le cas pour plusieurs sites des systèmes de recommandation qui contiennent des avis sous formes de commentaires textuelles sur des items variés et c’est un challenge d’attirer et fidéliser les clients dès la prise en main du service. L’exemple le plus célèbre sur les commentaires influents dans le monde des systèmes de recommandation est celui de l’internaute François qui a écrit le 8 février 2017 le commentaire suivant « Je ne sais pas
si vous le saviez mais on vit dans une société de consommation de masse. Et comme on achète plein de trucs, les gens et entreprises produisent plein de trucs. Cependant on a remarqué que certains produits devraient cesser d’être produits, parce qu’on a largement tout ce qu’il faut pour le restant de nos jours ». Ce commentaire a eu, par la suite, 2 kilo de partages et a
largement influencé l’opinion publique. En effet, des clients qui ont lu ce commentaire, ont cessé d’acheter les articles correspondants.
De ce fait, le nombre de documents contenant des informations exprimant des opinions, des sentiments ou des jugements d’évaluation devient de plus en plus important. Récemment, les chercheurs de différentes communautés, i.e. Fouille de textes, Linguistique, Traitement de Langage Naturelle, se sont intéressés à l’extraction automatique de ces données d’opinions sur le Web. La détection de subjectivité ou de polarité d’opinions est alors un domaine de recherche en pleine expansion. La plupart des ressources et des systèmes construits sont destinés à l'anglais ou à d'autres langues. Parmi ces langues naturelles qui doivent être supportées dans l'analyse des sentiments, nous distinguons la langue arabe. Cette dernière est la langue d'un nombre significatif de personnes qui sont sûrement intéressées à utiliser des systèmes de recommandation et des pages web d'opinions ; c'est l'une des langues les plus fortes, les plus riches et les plus aptes à s'articuler dans le monde.
Problématique
Notre étude s’articule autour de deux problématiques principales qui sont ; la classification d’opinions en langue arabe et la recommandation via l’analyse d’opinions.
À cet effet, les questions scientifiques que nous abordons dans le cadre de cette thèse sont les suivantes :
- Comment concevoir un système robuste d’analyse d’opinions en langue arabe ? - L’utilisation d’un nombre riche de caractéristiques avec une base de données limitée,
est-elle un avantage ou inconvénient pour le processus de classification d’opinions ? - Peut-on introduire un nouveau type de caractéristiques avec un aspect sémantique au
processus de classification pour mieux représenter les commentaires en arabe ? - Est-il possible d’améliorer le filtrage collaboratif en intégrant le système d’analyse
d’opinions proposé ?
Afin de répondre aux questions ci-dessus, nous avons pu cerner nos objectifs par les points suivants :
- Concevoir un système performant de classification d’opinion en langue arabe, en présentant une représentation lexicale et statistique des textes arabes.
- Comme il a été démontré en analyse d’opinions via l’apprentissage automatique qu’une représentation riche en caractéristiques de même type engendre une mauvaise compréhension du contenu des commentaires et influe négativement sur la précision de système de classification, notre objectif est d’essayer de trouver un compromis entre la prise en compte de toutes les caractéristiques et d’avoir à chaque fois un vecteur de taille limitée comme entrée au système de classification.
- Introduire l’aspect sémantique dans la représentation des commentaires. En effet, la phase d’extraction de caractéristiques influe directement sur la performance globale du système ; d’où la nécessité d’avoir une meilleure représentation de ces textes. - Intégrer le système de détection d’opinions proposé dans un système de
Plan de la thèse
Cette thèse est organisée selon deux parties :
La première partie clarifie les éléments nécessaires à la bonne compréhension des sujets
abordés dans la suite de cette thèse. Elle comporte trois chapitres :
Le chapitre 1 aborde la recommandation et les techniques des systèmes de recommandation en se focalisant sur la recommandation collaborative.
Le chapitre 2 est destiné à présenter le contexte général et la problématique de ce travail qui est le domaine de l’analyse des sentiments ou la fouille d’opinions. En mettant l’accent sur ses concepts fondamentaux et les travaux réalisés en langue arabe.
Le chapitre 3 est consacré à la description de processus de classification d’opinions en détaillant chaque phase et précisément la phase d’extraction de caractéristiques.
La seconde partie est consacrée à la proposition de deux contributions permettant de la
classification d’opinions en langue arabe et la recommandation via l’analyse d’opinions. Cette partie comprend deux chapitres :
Le chapitre 4 présente notre première contribution comportant deux méthodes ; la première pour la classification d’opinions en utilisant la combinaison du Random Sub Space (RSS) avec les Séparateurs à Vaste Marge (SVM) pour minimiser le vecteur de caractéristiques.
La deuxième méthode comporte des améliorations sur la sélection des caractéristiques en introduisant les algorithmes génétiques pour sélectionner celles qui sont corrélées et cohérentes.
Le chapitre 5 entame la seconde contribution qui est la proposition de nouvelles caractéristiques basées sur l’aspect sémantique et la structure discursive des textes arabes afin d’améliorer la détection des opinions spams pour construire un système de recommandation profond.
Chapitre 1. Les Systèmes de Recommandation
1.1. Introduction
La naissance du World Wide Web (WWW) en 1990 par Tim Berners-Lee a changé la façon dont nous menons nos activités quotidiennes de tous les jours. Le WWW est devenu une énorme source d'information et il continue d'augmenter en taille et en utilisation. Les gens vont de plus en plus sur le Web, non seulement pour s’informer, mais aussi pour d'autres usages comme la communication, la gestion, l'investissement, le magasinage, ainsi que pour l'éducation et le divertissement. L'un des usages les plus populaires du WWW est le magasinage en ligne, où l'achat et la vente des produits et des services sont effectués par voie électronique. De nos jours, de nombreuses entreprises offrent leurs produits et services via internet en utilisant des applications de commerce électronique. Un site Web de commerce électronique offre une multitude de produits ou de services à choisir, ce qui entraîne un problème de surcharge d'informations. Dans cette situation, les utilisateurs sont submergés par la grande quantité d'informations mise à leur disposition ainsi que la difficulté de choisir le produit qui leur intéresse. Les systèmes de recommandation (SR) ont émergé pour répondre aux problèmes de surcharge d'informations en apprenant des utilisateurs au sujet de leurs intérêts et en leur
les utilisateurs à décider quels sont leurs produits souhaités sur des sites de commerce électronique.
Actuellement, les principaux sites de commerce électronique utilisent les SR pour recommander divers produits, tels que : des livres, des films…etc., afin de servir des millions de consommateurs.
Avant de procéder à l’explication des systèmes de recommandation basés sur le filtrage collaboratif, il serait utile de présenter la recherche d’informations et le filtrage d’informations. Par la suite, l’ambiguïté sur les systèmes de recommandation est soulevée. A la fin de ce chapitre, nous détaillons les systèmes de recommandation basés sur le filtrage collaboratif dont nous nous sommes intéressés.
1.2. La recherche d’information et le filtrage d’information
La recherche d'information est étroitement liée au filtrage de l'information dans le sens où ils ont le même but qui est de retrouver l'information pertinente pour un certain utilisateur. 1.2.1. La recherche d’information
La recherche d’information est basée sur un principe d'indexation des données afin de répondre aux requêtes des utilisateurs. Plus spécifiquement, la recherche documentaire consiste à interroger une base de connaissance par le bais de requêtes écrites en langues naturelles ou bien sous forme de mots clefs (nommées requêtes ad hoc) [Béchet 2013]. Par conséquent, il peut y avoir une surcharge d'informations que l'utilisateur doit filtrer, (Figure 1-1).
Figure 1-1 Processus du filtrage d’informations [Béchet 2013].
1.2.2. Le filtrage d’informations
Le filtrage d’informations est utilisé pour décrire des processus servant à fournir aux utilisateurs les informations dont ils ont besoin [Belkin 1992]. Le filtrage est l’élimination des données désagréables sur un flux entrant, plutôt que la recherche de données spécifiques sur ce flux. Cette méthode est simple, rapide et a fait ses preuves en recherche d’information classique [Nouali 2011].
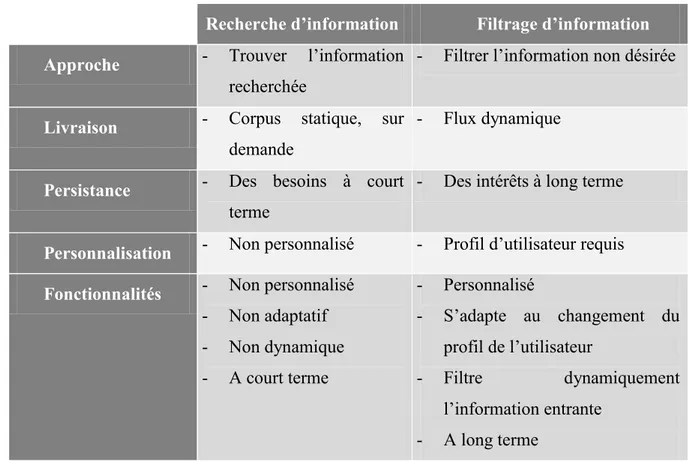
1.2.3. Comparaison entre la recherche d’information et le filtrage d’information Bien qu’ils soient proches (similaires) dans certaines fonctionnalités, la recherche d’information et le filtrage d’informations peuvent différer dans quelques points :
La recherche d’information est typiquement concernée par des utilisations singulières du système, avec une personne, un objectif et une requête à la fois, alors que le filtrage d’information concerne les usages répétitifs du système avec des buts et des intérêts à long terme ;
Producteurs de documents
Distributeurs de documents
Utilisateurs ou groupes
Besoins réguliers ou information
Distribution et représentation Présentation
Substituts de documents Profils
Comparaison ou filtrage Documents retrouvés
Usage et/ou évaluation
La recherche d’information reconnaît des problèmes inhérents à l’adéquation des requêtes comme représentation des besoins en informations. Le filtrage d’information fait lui l’hypothèse que l’évolution des profils peut compenser ces problèmes ;
Les fonctionnalités des systèmes de recherche d’informations sont la collection et l’organisation des documents, tandis que les systèmes de filtrage adoptent des fonctionnalités telles que la distribution des documents à des groupes ou à des individus ;
La recherche d’information permet la sélection des documents à partir d’une base relativement classique. Les systèmes de filtrage d’information sélectionnent ou éliminent des documents à partir d’un flux dynamique de données ;
La recherche d’information permet une interaction entre l’utilisateur et le document durant une session unique de recherche. De son côté, le filtrage d’information autorise des changements à long terme à travers des séries de session de recherche [Schafer 2001].
Le Tableau 1-1 ci-dessous résume cette comparaison :
Tableau 1-1 Comparaison entre la recherche d’information et le filtrage d’information.
Recherche d’information Filtrage d’information Approche - Trouver l’information
recherchée
- Filtrer l’information non désirée
Livraison - Corpus statique, sur
demande
- Flux dynamique
Persistance - Des besoins à court
terme
- Des intérêts à long terme
Personnalisation - Non personnalisé - Profil d’utilisateur requis Fonctionnalités - Non personnalisé
- Non adaptatif - Non dynamique - A court terme - Personnalisé - S’adapte au changement du profil de l’utilisateur - Filtre dynamiquement l’information entrante - A long terme
1.3. Les systèmes de recommandation
Burke dans [Burke 2000] a défini un système de recommandation (SR) comme un système informatique qui fournit des conseils aux utilisateurs sur les articles qu'ils pourraient vouloir acheter ou examiner. Un système de recommandation fournit une personnalisation individuelle à chaque utilisateur en personnalisant ses recommandations et en présentant les différents articles pour chaque utilisateur en fonction de ses goûts. En sélectionnant et en fournissant une liste de produits susceptibles offerts par des sites de commerce électronique pour répondre aux besoins d'un grand nombre d’utilisateurs, les systèmes de recommandation aident l'utilisateur à gérer la surcharge d'informations et à réduire le temps de recherche des articles intéressants afin d’améliorer l'efficacité de la prise de décision de l'utilisateur. En outre, les systèmes de recommandation permettent également aux marchandiseurs d’améliorer les ventes sur leurs sites de commerce électronique en convertissant les navigateurs en acheteurs, en augmentant les ventes croisées et en fidélisant les consommateurs [Schafer 1999]. Actuellement, pour recommander leurs divers produits tels que des livres, des CD, des films, des actualités…etc, un certain nombre de sites commerciaux comme Amazon, utilisent les techniques de recommandation via des applications pratiques.
Pour fournir un ensemble de recommandations personnalisées, un système de recommandation incorpore les souhaits d'un utilisateur dans un modèle d'utilisateur et exploite des algorithmes de recommandation appropriée pour mapper le modèle d'utilisateur en suggestions de produits ciblées [Ricci 2006]. Un système de recommandation comporte trois étapes : l'acquisition des préférences à partir des données d'entrée d'un utilisateur ; calcul de la recommandation en utilisant des techniques appropriées ; et enfin présentation des résultats de la recommandation aux utilisateurs [Wei 2007]. Il suggère également des produits en appliquant des techniques d'analyse de données à diverses connaissances provenant de différentes sources à savoir les profils des utilisateurs du système, les données sur les éléments recommandés, ainsi que du domaine de recommandation lui-même [Felfernig 2008]. Les éléments de connaissance peuvent être acquis explicitement ou implicitement à partir des sources. Des exemples d'éléments de connaissance qui peuvent être acquis explicitement auprès des utilisateurs sont ; des données démographiques, des données de classement et des exigences de produits déclarées par l'utilisateur dans un formulaire en ligne. Les connaissances sur les préférences des utilisateurs peuvent également être acquises implicitement à partir des données du
cette page. etc. Ces dernières réactions prouvent que l’utilisateur a aimé le produit ciblé [Wei 2007].
1.3.1. Classification des techniques de recommandation
La première mise en œuvre des systèmes de recommandation a été un système de recommandation de filtrage collaboratif appelé Tapestry [Goldberg 1992], qui a été développé au milieu des années 1990. Depuis lors, les systèmes de recommandation sont devenus un domaine de recherche important et indépendant. De nombreuses technologies de recommandation ont été développées en utilisant un large éventail de techniques statistiques, d'apprentissage automatique et de recherche d'information. Cependant, le filtrage collaboratif et les approches basées sur le contenu ont reçu beaucoup d'attention de la part de la communauté des systèmes de recommandation et ont été largement utilisés dans les systèmes commerciaux pour recommander des produits simples et fréquemment achetés. Il y a trois types de recommandation dont les plus utilisés dans la littérature sont la recommandation basée sur le filtrage par contenu et celle basée sur le filtrage collaboratif et leur hybridation.
1.3.1.1. Recommandation basée sur le filtrage par contenu
Les systèmes de recommandation basés sur le contenu s'appuient sur des évaluations effectuées par un utilisateur sur un ensemble de documents. L'objectif est alors de comprendre les motivations l'ayant conduit à juger comme pertinent ou non un document donné. Le système peut alors proposer à l'utilisateur un choix parmi de nouveaux documents jugés proches des documents qu'il a précédemment appréciés [Burke 2002]. Le choix des documents proposés est basé sur une comparaison des thèmes abordés dans les documents par rapport aux thèmes qui intéressent l’utilisateur [Bechet 2013].
1.3.1.2. Recommandation basée sur le filtrage collaboratif
Contrairement au filtrage basé sur le contenu, le filtrage collaboratif crée des communautés en comparant les utilisateurs entre eux sur la base de leurs évaluations passées et chaque utilisateur reçoit les documents jugés pertinents par sa communauté sans analyser le contenu des documents [Bechet 2013].
Il s’appuie alors sur les appréciations données (des notes, des comptes d’achats effectués, des nombres de visites, etc) par un ensemble d’utilisateurs sur un ensemble de documents [Poirier 2011].
Pour faire des prévisions basées sur des configurations des intérêts des utilisateurs, le filtrage collaboratif utilise des méthodes statistiques. Il n’y a donc pas d’analyse du contenu et un document n’est connu que par son identifiant [Bechet 2013].
1.3.1.3. Recommandation hybride
Comme le définit Burke dans son étude publiée dans [Burke 2002]. La recommandation hybride peut être vu comme étant une combinaison des méthodes traditionnelles précédemment présentées afin d'en palier les limites, ces dernières sont actuellement les plus représentées dans la littérature, notamment à cause du fait qu’elles soient jugées comme étant les plus efficaces. Selon ce dernier, un système hybride est généralement organisé en deux phases :
1. Effectuer de manière indépendante les filtrages des articles via des méthodes collaboratives ou par le contenu (ou autres).
2. Combiner ces ensembles de recommandations via des méthodes d'hybridations telles que des pondérations et des commutations [Burke 2002].
Le Tableau 1-2 présente les points forts et faibles de chacune des méthodes de recommandation détaillées ci-dessus.
Tableau 1-2 Comparaison entre les types de recommandation.
Type de recommandation Avantages Inconvénients Recommandation basée sur le filtrage par contenu
- Permet des recommandations de nouveaux articles.
- Un nouvel utilisateur peut recevoir des recommandations dès ses premières interactions avec le système
- La redondance thématique des propositions soumises à l'utilisateur (En revanche, un utilisateur ne se verra jamais proposer d'items qui n'auront pas été jugés similaires à ceux qu'il apprécie.)
- Proposer à un utilisateur des articles désagréables qui ne lui sont pas intéressant (par exemple si un utilisateur ne s'intéresse qu'aux articles
parlant de sport, il ne recevra jamais un article politique). - Le problème du nouvel
arrivant (un utilisateur qui n’a jamais utilisé le système ne
recevra pas des
recommandations pertinentes) [Burke 2002].
- Ainsi, on peut citer d’autres limitations des systèmes basés sur le contenu qui n’apparaissent pas dans ces nouveaux systèmes comme : difficulté d’indexation, incapacité à traiter d’autres critères [Berrut 2003].
- Nécessite une quantité importante de descripteurs sur les articles et/ou utilisateurs [Clemente 2015].
Filtrage Collaboratif
- Pas besoin de descripteurs sur les documents/utilisateurs. - Prend en considération les
relations entre les articles et/ou celle entre les utilisateurs.
- Problème de démarrage à
froid : pas de
recommandations possibles s’il n’y a pas suffisamment d’interactions
utilisateurs/documents [Clemente 2015].
- Dans le cadre de notes explicites, le pourcentage moyen des ressources pour lesquelles les utilisateurs ont fourni une appréciation est très bas.
Filtrage hybride - Combine les avantages de la
recommandation par contenu et celle basée sur le filtrage collaboratif.
- Problème de passage à l’échelle.
1.4. Les systèmes de recommandation basés sur le filtrage collaboratif
Comme nous l’avons mentionné ci-avant, le filtrage collaboratif s’appuie sur une collaboration directe ou indirecte entre les utilisateurs. Dans le cas d’une collaboration directe, ce sont les utilisateurs eux-mêmes qui s’échangent des articles, alors que dans la collaboration indirecte, c’est au système de générer des recommandations en se basant sur des degrés de similarité entre les usagers.
En effet, le filtrage collaboratif se base sur l’idée que les utilisateurs à la recherche d’informations devraient se servir de ce que d’autres ont déjà trouvé et évalué. Dans la vie quotidienne, si quelqu’un a besoin d’une information, il essaye de s’informer généralement auprès de ses amis, ses collègues, qui vont à leurs tours lui recommander des articles, des films, des livres, etc. Cette collaboration entre les gens permet d’améliorer l’échange des connaissances. Cependant, cela prend beaucoup de temps vu que cette ressource d’information ne peut pas toujours être à notre disposition. C’est à partir d’ici que l’idée de filtrage collaboratif est née, le besoin d’automatiser et de rendre l’échange des expériences et des avis personnels de certaines personnes utilisables par d’autres. Selon Golberg [Goldberg 2001] le filtrage collaboratif est l’automatisation des processus sociaux.
Le filtrage collaboratif est l'approche la plus utilisée pour produire des recommandations applicables dans beaucoup de domaines, il se base sur la similarité de comportement (achats, visites, clics, notes, etc.) entre les utilisateurs [Dragut 2017].
En résumé, les systèmes de filtrage collaboratif (SFC) fonctionnent en recueillant les commentaires des utilisateurs sous la forme des appréciations des éléments dans un domaine donné et exploiter les similarités de comportement entre plusieurs utilisateurs pour recommander un document.
1.4.1. Principe
alors possible de traiter n’importe quelle forme de contenu et de diffuser des ressources non nécessairement similaires à celles déjà reçues.
Pour ce faire, pour chaque utilisateur d’un système de filtrage collaboratif, un ensemble de proches voisins est identifié, et la décision de proposer ou non un document à un utilisateur dépendra des appréciations des membres de son voisinage [Berrut 2003].
En effet, le filtrage collaboratif emploie des méthodes statistiques pour faire des prévisions basées sur des configurations des intérêts des utilisateurs. Ces prévisions sont exploitées pour faire des propositions à un utilisateur individuel, en se basant sur la corrélation entre son profil et les profils des autres utilisateurs qui présentent des intérêts et des goûts similaires [Berrut 2003].
En effet, pour les systèmes de filtrage d’information collaboratifs, les utilisateurs fournissent des évaluations des documents, sous forme de notes, pour constituer leurs profils. Ces estimations sont comparées à celles des autres utilisateurs et les similitudes sont mesurées.
Des prévisions sont calculées comme une moyenne pondérée des avis d’autres utilisateurs avec des goûts soit semblables, soit complètement opposés. Il n’y a donc pas d’analyse du sujet ou du contenu et un document n’est connu que par son identifiant [Maltz 1995].
1.4.2. Profil de l’utilisateur
Il est nécessaire de construire un profil de l'utilisateur courant afin de faire de la recommandation collaborative. Les profils des utilisateurs peuvent être construits à partir d’informations collectées de deux manières :
- Construction passive : dans ce cas, on considère les documents sélectionnés par l’utilisateur en se basant sur son passif (les pages consultées, les produits achetés, etc). - Construction active : en proposant aux utilisateurs de remplir des questionnaires par
exemple, ou encore en permettant aux utilisateurs d’attribuer des notes aux documents reflétant leurs intérêts.
Selon la manière dont les informations ont été collectées, les profils des utilisateurs peuvent contenir soit les documents qu’ils ont appréciés ou non, soit des descripteurs. Ces descripteurs peuvent correspondre à des documents qu’ils ont notés, consultés ou être déduits des réponses au questionnaire.
Une fois les profils des utilisateurs et les documents sont construits, des mesures de similarités sont appliquées afin de comparer et trouver les documents correspondant le plus au profil des utilisateurs [Poirier 2011].
1.4.3. Processus du filtrage collaboratif
Comme il est illustré dans la Figure 1-2 , il y a trois étapes principales dans un processus de filtrage collaboratif : évaluation des recommandations, formation des communautés et production des recommandations [Nguyen 2006].
Figure 1-2 Processus du filtrage collaboratif [Nguyen 2006]. 1.4.3.1. Evaluation des recommandations
Selon le principe de base du filtrage collaboratif, les utilisateurs doivent fournir leurs évaluations sur des documents afin que le système forme les communautés. Evaluer une recommandation peut se faire de façon explicite ou implicite :
– Explicite : L’utilisateur donne une valeur numérique sur une échelle donnée ou une valeur qualitative de satisfaction, par exemple : mauvaise, moyenne, bonne et excellente.
– Implicite : Le système induit la satisfaction de l’utilisateur à travers ses actions [Clemente 2015, Poirier 2010]. Par exemple, le système estimera qu’une recommandation supprimée correspond à une évaluation très mauvaise, alors qu’une page de recommandation imprimée ou sauvegardée peut être interprétée comme une
Formations des communautés Production des recommandations Evaluation des recommandations Recommandations Evaluations
1.4.3.2. Formation des communautés
Le processus de formation des communautés est le noyau d’un système de filtrage collaboratif. Le système doit calculer la communauté pour chaque utilisateur. Cela se fait par la proximité des évaluations des utilisateurs en utilisant des mesures de similarités telles que les coefficients de Pearson, Spearman et Kendall qui vont être détaillées prochainement.
1.4.3.3. Production des recommandations
Une fois la communauté de l’utilisateur est créée, le système prédit l'intérêt qu'un document particulier peut être présenter pour l’utilisateur en s'appuyant sur les évaluations que les membres de la communauté ont faites sur ce même document. Lorsque l'intérêt prédit dépasse un certain seuil, le système recommande le document à l'utilisateur [Herlocker 2000, Herlocker 1999].
1.4.3.4. Méthodes de filtrage collaboratif
On distingue deux algorithmes de filtrage collaboratif : les algorithmes basés « mémoire » [Breese 2013] et les algorithmes basés « modèle » [Berrut 2003].
1.4.3.5.1 Les algorithmes basés « mémoire »
Généralement, la tâche du filtrage collaboratif est de prédire les votes d'un utilisateur particulier (nous appellerons cet utilisateur l'utilisateur actif) à partir d'une base de données de votes d'utilisateurs [Bechet 2013]. La base de données d’utilisateurs se compose donc d'un ensemble de votes 𝑣𝑖,𝑗correspondant au vote pour l'utilisateur 𝑖 sur l'item 𝑗. Si 𝐼𝑖 est l'ensemble
des items sur lesquels l'utilisateur 𝑖 a voté, on peut définir le vote moyen pour l'utilisateur 𝑖 comme suit [Breese 2013] :
𝑣̅
𝑖=
|𝐼1𝑖|
∑
𝑗∈𝐼𝑖𝑣
𝑖,𝑗(1.1)
Alors le but est de prédire les votes de l'utilisateur actif (indiqué par un indice 𝑎) sur la base d'informations partielles concernant l'utilisateur actif et d'un ensemble de poids calculés à partir de la base de données d’utilisateurs. Nous supposons que le vote prévu de l'utilisateur actif pour l'élément 𝑗, 𝑝𝑎,𝑗, est une somme pondérée des votes des autres utilisateurs [Breese 2013] :
𝑝𝑎,𝑗 =
𝑣
̅𝑎+ 𝑘 ∑𝑛 𝑤(𝑎, 𝑖)(𝑣𝑖,𝑗− 𝑣̅𝑖)𝑖=1
Où
𝑣̅
𝑎est le vote moyen de l’utilisateur 𝑎. 𝑤(𝑎, 𝑖) est un coefficient de corrélation ou de similarité entre l’utilisateur actif 𝑎 et l’utilisateur 𝑖, formule 1.3.
𝑘 est un coefficient de normalisation, ou la somme des poids égal à 1. 𝑛 est le nombre des utilisateurs considérés pour le calcul.
Le poids 𝑤(𝑎, 𝑖) est déterminé de façon variable, selon deux algorithmes : algorithme basé sur la corrélation et algorithme basé sur la similarité de vecteurs [Nguyen 2006].
Corrélation de Pearson
Le coefficient de corrélation de Pearson a été utilisé dans le contexte des systèmes de filtrage collaboratif pour la première fois dans les recherches du Group Lens Research Project [Nguyen 2006]. Il est calculé avec la formule 1.3:
𝑤(𝑎, 𝑖)
=
∑ (𝑣𝑗 𝑎,𝑗−𝑣̅𝑎)(𝑣𝑖,𝑗−𝑣̅𝑖) √∑ (𝑣𝑗 𝑎,𝑗−𝑣̅𝑎)2(𝑣𝑖,𝑗−𝑣̅𝑖)2(1.3)
Où :
𝑣𝑎,𝑗 est l’évaluation de l’utilisateur 𝑎 pour la ressource 𝑗. 𝑣̅𝑎 est l’évaluation moyenne de l’utilisateur 𝑎.
Corrélation de Spearman
La corrélation de rang de Spearman est un test non paramétrique qui est utilisé pour mesurer le degré d'association entre deux variables. Cette corrélation porte le nom de son inventeur. Le test de corrélation de rang de Spearman ne suppose aucune hypothèse sur la distribution des données et constitue l'analyse de corrélation appropriée lorsque les variables sont mesurées sur une échelle au moins ordinaire.
La formule 1.4 est utilisée pour calculer la corrélation de Spearman [Spearman 1906] : 𝑝 = 1 − 𝜎 ∑ 𝑑𝑖
2
𝑛(𝑛2− 1)
(1.4)
𝑛 est le nombre de valeurs dans chaque ensemble de données.
Corrélation de rang de Kendall
La corrélation de rang de Kendall est un test non paramétrique qui mesure la force de dépendance entre deux variables. Si on considère deux échantillons, 𝑎 et 𝑏, où chaque taille d'échantillon est 𝑛, le nombre total de couples avec 𝑎 et 𝑏 est alors égal à 𝑛 (𝑛 − 1) 2⁄ .
La formule 1.5 est utilisée pour calculer la valeur de corrélation de rang de Kendall [Kendall 1938] :
𝜏 =1𝑛𝑐− 𝑛𝑡 2 𝑛(𝑛 − 1)
(1.5)
Où :
𝑛𝑐 est le nombre de concordants, 𝑛𝑡 est le nombre de discordants.
1.4.3.5.2 Les algorithmes basés « modèle »
Les algorithmes basés modèle utilisent la base de données des évaluations des utilisateurs pour estimer ou apprendre un modèle qui est utilisé pour les prédictions. Du point de vue probabiliste, la tâche de prédiction d’une évaluation peut être vue comme le calcul de la valeur espérée d’une évaluation.
Supposons que les évaluations se fassent sur une échelle d’entiers de 0 à 𝑚. La valeur prédite sera alors :
𝑃𝑎,𝑗 = 𝐸(𝑣𝑎,𝑗) = ∑ 𝑃𝑟(𝑣𝑎,𝑗 = 𝑖|𝑣𝑎,𝑘, 𝑘 ∈ 𝐼𝑎)𝑖
𝑚
𝑖=0
(1.6)
Où la probabilité exprimée est celle dont l’utilisateur actif fera l’évaluation particulière 𝑖 pour l’item 𝑗 compte tenu des évaluations observées auparavant [Breese 2013]. Il existe trois modèles probabilistes : le modèle à base de clusters, k-moyennes et réseaux bayésiens :
Clustering
Le clustering est un outil statistique utilisé pour obtenir facilement et rapidement une analyse de données. L'idée de ce modèle est de regrouper (en clusters) les personnes ayant les
mêmes goûts, et de regrouper (en clusters) les articles portant sur les mêmes sujets, ou qui tendent à plaire aux mêmes personnes. Ainsi, pour prédire la note qu'un utilisateur donnera à un article, on pourra utiliser les avis des utilisateurs qui appartiennent à son groupe.
K-Moyennes
La méthode des K-moyennes est un outil de classification classique qui permet de répartir un ensemble de données en k classes homogènes.
L’idée principale de l’algorithme des K-moyennes est de classifier des objets en K classes. Cet algorithme commence par choisir au hasard K centres de gravité, puis construit les classes initiales autour de ces centres. Chaque objet appartient à la classe dont le centre est le plus proche. A chaque itération, il faut recalculer les centres en fonction de la variance entre les classes, et former les nouvelles classes jusqu’à l’obtention plus de changement de partition.
Réseaux bayésiens
Un réseau bayésien est un système représentant la connaissance et permettant de calculer des probabilités conditionnelles apportant des solutions à différentes sortes de problématiques. Il est possible d’utiliser les réseaux bayésiens dans le contexte du filtrage collaboratif [Nguyen 2006]. D’après Heckerman, un réseau bayésien est un graphe acyclique dirigé qui représente une distribution de probabilités de dépendance entre un ensemble de variables. Chaque nœud dans le graphe représente une variable, et chaque arc une dépendance directe entre variables. Ainsi, chaque variable est indépendante de ses non-descendants dans le graphe, vis à vis l'état de ses parents.
1.5. L’évaluation des systèmes de recommandation
Evaluer un système de recommandation permet de mesurer ses performances vis-à-vis de ses objectifs. De ce fait, le choix des mesures à utiliser diffère selon les objectifs fixés.
La mesure de l’erreur absolue moyenne (EAM ou MAE pour Mean Absolute Error en anglais) qui est la mesure la plus employée dans les systèmes de recommandation, elle estime la moyenne de la différence absolue entre les évaluations et les prédictions. Le système de recommandation collaboratif est jugé performant quand la valeur de MAE est petite. Dans notre système, plus le MAE est petit, plus l’analyse des opinions est
𝑀𝐴𝐸 =𝑛1∑𝑛 |𝑓𝑖− 𝑦𝑖|
𝑖=1 (1.7)
Où :
𝑛 est le nombre de prédictions,
fi est la prédiction i,
yi est l’évaluation originale (vote).
La précision correspond au nombre de commentaires bien classés par rapport à la totalité des commentaires contenus dans le corpus. Le système de recommandation collaboratif est jugé performant quand la valeur de la précision est élevée. Dans notre système, Plus la précision est élevée, plus l’analyse des opinions est efficace. La précision est mesurée, pour chaque classe, de la façon suivante :
𝑃𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑉𝑃 𝑉𝑃 + 𝐹𝑃
(1.8) Le rappel est une mesure d'exhaustivité qui détermine la proportion des items pertinents recommandés parmi tous les items pertinents. Un système de recommandation parfait doit avoir un rappel près de la valeur 1.
𝑅𝑎𝑝𝑝𝑒𝑙 = 𝑉𝑃
𝑉𝑃 + 𝐹𝑁
(1.9)
Tableau 1-3 Matrice de confusion.
Item Pertinent Non pertinent Recommandé Vrai positif (VP) Faux positif (FP)
Non Recommandé Faux négatif (FN) Vrai négatif (VN)
1.6. Conclusion
Tel que présenté dans ce chapitre, les systèmes de recommandation ont pris une place très importante dans le monde de la recherche d’information ainsi que celui du commerce électronique grâce à leur capacité d’attirer l’attention de l’utilisateur tout en lui recommander les articles qui conviennent au mieux à son goût et ses préférences.
En effet, nous avons présenté, tout au long, de ce chapitre les concepts de base des systèmes de recommandation tout en mettant l’accent sur la recommandation basée sur le filtrage
collaboratif qui nous intéresse dans notre travail et qui vise à recommander à un usager des ressources qui ont été jugées pertinentes par d’autres usagers ayant un goût similaire.
Le chapitre suivant, de ce manuscrit, présente un état de l’art de la fouille d’opinions ou l’analyse des sentiments en langue arabe qui est l’un des moyens permettant d’extraire des informations concernant les goûts et les préférences des utilisateurs des systèmes de recommandation.
Chapitre 2. L’Analyse des Sentiments
2.1. Introduction
Actuellement, les sites Web de commerce électronique permettent à leurs utilisateurs d'écrire des critiques ou des commentaires sur les produits qu'ils ont acheté. L'information provenant des commentaires des utilisateurs est cruciale pour aider d'autres utilisateurs potentiels à décider d'acheter ou non un article en fonction de l'expérience et des opinions des autres utilisateurs au sujet d'un produit particulier. En outre, les fabricants peuvent également recueillir les commentaires des utilisateurs à partir des évaluations en ligne afin d'améliorer leurs produits. Cependant, avec l'augmentation du nombre d’utilisateurs achetant des produits, le nombre de commentaires augmente également au fil du temps et il n'est pas possible pour les utilisateurs ou les fabricants de lire tous les commentaires pour connaître les opinions des utilisateurs précédents sur un certain produit. En outre, certains des commentaires sont longs, ce qui fait difficile pour les utilisateurs de reconnaître les bonnes et les mauvaises caractéristiques du produit lorsqu'il s'agit de décider si le produit vaut la peine d'être acheté ; ou pour les fabricants de décider si le produit doit être amélioré. Un processus d’analyse d’opinions, qui peut analyser si un utilisateur fournit un bon ou une mauvaise opinion sur un certain produit, est important et hautement souhaitable pour les utilisateurs potentiels et les
fabricants car il permet de recueillir facilement des informations utiles sur les produits à partir d'un grand nombre de commentaires, ce qui les aide à prendre des décisions basées sur les opinions des autres.
Ce chapitre présente une brève revue de littérature sur l’analyse des sentiments ou la fouille d’opinions, en mettant l’accent sur ses concepts de base et ses caractéristiques, et en se concentrant sur la fouille d’opinions en langue arabe.
2.2. Définition de l’analyse des sentiments
L'analyse des sentiments, qu’on appelle aussi la fouille d'opinions, est l'un des domaines de recherche les plus actifs dans le traitement du langage naturel depuis le début des années 2000 [Cambria 2016]. Le but de l'analyse des sentiments est de définir des outils automatiques capables d'extraire des informations subjectives à partir du texte en langage naturel, telles que les opinions et les sentiments, afin de créer des connaissances structurées et utilisables par un système d'aide à la décision ou par un décideur.
Comme on pouvait s'y attendre, il y a eu une certaine confusion parmi les chercheurs au sujet de la différence entre le sentiment et l'opinion, ce qui a donné lieu à un débat sur la question de savoir si le domaine devrait être appelé analyse des sentiments ou fouille d'opinion. Dans les dictionnaires français, le sentiment est défini comme une attitude, une pensée ou un jugement induit par le sentiment, alors que l'opinion est définie comme une vue, un jugement ou une évaluation formée dans l'esprit au sujet d'une question particulière. La différence est assez subtile, et chacune d'entre elles contient des éléments de l'autre. Les définitions indiquent qu'une opinion est davantage le point de vue concret d'une personne sur quelque chose, alors qu'un sentiment est plutôt un sentiment. Par exemple, la phrase "Je suis préoccupé par la situation politique actuelle" exprime un sentiment, alors que la phrase "Je pense que la politique ne va pas bien" exprime une opinion. Si quelqu'un dit la première phrase, nous pouvons répondre en disant "Je partage votre sentiment", mais pour la deuxième phrase, nous dirions normalement "Je suis d'accord ou pas d'accord avec vous".
Cependant, les significations sous-jacentes des deux phrases sont strictement liées car le sentiment représenté dans la première phrase est susceptible d'être un sentiment causé par l'opinion exprimée dans la deuxième phrase. Inversement, la première phrase de sentiment implique une opinion négative sur la politique, ce qui est exprimé dans la deuxième phrase.
certaines opinions ne le font pas, comme " je pense qu'il gagnera aux prochaines élections présidentielles".
Figure 2-1 Les données de Google Trends sur les tendances liées à l'analyse des sentiments1.
A partir de la définition de l'analyse des sentiments mentionnée ci-dessus, l'objectif de l'analyse des sentiments est donc de définir des outils automatiques capables d'extraire des informations subjectives afin de créer des connaissances structurées et exploitables
Grâce à sa forte applicabilité et son intérêt tant dans le domaine académique que dans le domaine industriel, l'analyse des sentiments est aujourd'hui un sujet d'actualité [Assiri 2015 ; Ravi 2015 ; Shiliang 2016 ; Sun 2017 ; Tanaya 2017]. La figure 2.1 représente les données de Google Trends relatives au mot-clé « Sentiment Analysis », démontrant clairement l'intérêt continu et croissant dans ce domaine.
2.2.1. Taches de l’analyse des sentiments
De nos jours, l'analyse des sentiments a gagné encore plus de valeur avec l'avènement des réseaux sociaux. Leur grande diffusion et leur rôle dans la société moderne représentent l'une des nouveautés les plus intéressantes de ces dernières années, captant l'intérêt des chercheurs, des journalistes, des entreprises et des gouvernements. L'interconnexion dense qui surgit souvent parmi les utilisateurs actifs génère un espace de discussion capable de motiver et d'impliquer les individus d'un espace plus large, reliant les personnes avec des objectifs communs et facilitant diverses formes d'action collective.
Les réseaux sociaux créent donc une révolution numérique, permettant l'expression et la diffusion des émotions et des opinions à travers le réseau, ouvrant une fenêtre sur les mondes des autres et fouillant dans leur vie. Les données d'opinion sur le net, si elles sont correctement
collectées et analysées, permettent non seulement de comprendre et d'expliquer de nombreux phénomènes sociaux complexes, mais aussi de les prédire.
Les progrès technologiques actuels permettent de stocker et de récupérer efficacement une énorme quantité de données, l'accent est désormais mis sur les méthodes d'extraction de l'information et de création de connaissances à partir de sources brutes. En effet, les réseaux sociaux représentent un nouveau secteur stimulant dans le contexte de big data : les expressions en langage naturel des gens peuvent être facilement rapportées par des textes de messages courts, créant rapidement un contenu unique de dimensions énormes qui doit être analysé de manière efficace pour créer des connaissances exploitables pour les processus de prise de décision.
Cependant, l'analyse des sentiments est souvent utilisée incorrectement lorsqu’on se réfère à la classification de polarité, qui est plutôt une sous-tâche visant à détecter la polarité des textes de sentiments ; positifs, négatifs ou neutres. Bien qu'une opinion puisse aussi avoir une polarité neutre (par exemple, "Je ne sais pas si j'ai aimé le film ou pas. Je devrais le regarder tranquillement."). La plupart des travaux d'analyse des sentiments ne supposent généralement que des sentiments positifs et négatifs pour des raisons de simplicité.
Figure 2-2 Tâches d'analyse des sentiments [Pozzi 2016].
Selon le domaine d'application, plusieurs noms sont utilisés pour l'analyse des sentiments (par exemple : fouille d'opinions, extraction d'opinion, fouille des sentiments, analyse de subjectivité, analyse de l'affect, analyse des émotions et analyse des avis). Une taxonomie des tâches d'analyse des sentiments les plus populaires est présentée par la Figure 2-2.
2.2.2. Caractéristiques de l'analyse des sentiments
L'analyse des sentiments est un domaine de recherche vaste et complexe. Dans ce qui suit, les principales caractéristiques qui constituent le processus d'analyse des sentiments sont décrites et discutées en détail.
2.2.2.1. Catégorisation des sentiments : phrases objectives versus phrases subjectives
Le premier objectif de l'analyse des sentiments consiste généralement à distinguer les phrases subjectives des phrases objectives. Si une phrase donnée est classée comme objective,
L'
an
al
yse
d
es
sen
ti
men
ts
Classification de subjectivité Detection de polaritéClassification des sentiments basée sur les aspects
Désambiguïsation de polarité contextuelle
Prédiction de notation de sentiment
Classification des sentiments inter-domaines
Classification des sentiments inter-langues Resumé d'opinions
Détection de sarcasme
Extraction d'entité porteuse d'opinions Résolution de conférence et désambiguïsation du sens des
mots
Génération de lexique des sentiments
Recherche et récupération d'opinion
![Figure 1-1 Processus du filtrage d’informations [Béchet 2013].](https://thumb-eu.123doks.com/thumbv2/123doknet/2030207.4080/21.892.117.779.96.560/figure-processus-filtrage-informations-bechet.webp)




![Tableau 2-3 Lexique utilisée dans les techniques d’analyse du sentiment en arabe [AlOwisheq 2016]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030207.4080/55.1262.108.1153.138.727/tableau-lexique-utilisee-techniques-analyse-sentiment-arabe-alowisheq.webp)
![Tableau 2-4 Les corpus utilisés dans les techniques d’analyse du sentiment en arabe [Korayem 2016]](https://thumb-eu.123doks.com/thumbv2/123doknet/2030207.4080/60.892.113.813.582.1142/tableau-corpus-utilises-techniques-analyse-sentiment-arabe-korayem.webp)